目录
- 一、Azure AI 信息检索系统介绍
- 二、采用 Azure AI 搜索的 RAG 方法
- 三、适合 Azure AI 搜索的自定义 RAG 模式
- 四、Azure AI 搜索中的可搜索内容
- 五、Azure AI 搜索中的内容检索
- 构建查询响应
- 按相关性排名
- 适用于 RAG 方案的 Azure AI 搜索查询的示例代码
- 六、集成代码和 LLM
- 七、如何开始使用
检索增强生成 (RAG) 是一种体系结构,通过添加提供数据的信息检索系统来增强大型语言模型 (LLM)(如 ChatGPT)的功能。 添加信息检索系统可在 LLM 规划响应时控制由其使用的数据。 对于企业解决方案,RAG 架构意味着你可以将自然语言处理限制为源自向量化文档、图像、音频和视频的企业内容。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
一、Azure AI 信息检索系统介绍
决定使用哪种信息检索系统至关重要,因为它将决定对 LLM 的输入。 信息检索系统应提供:
-
按所需频率为所有内容进行大规模加载和刷新的索引策略。
-
查询功能和相关性优化。 系统应以满足 LLM 输入的令牌长度要求所需的简短格式返回_相关_结果。
-
数据和操作的安全性、全球影响力和可靠性。
-
与 LLM 集成。
Azure AI 搜索是 RAG 体系结构中一种可靠的信息检索解决方案。 它提供索引和查询功能,并且具有 Azure 云的基础设施和安全性。 通过代码和其他组件,你可以设计一项全面的 RAG 解决方案,其中包括基于专有内容的生成式 AI 的所有元素。
二、采用 Azure AI 搜索的 RAG 方法
Microsoft 具有多个内置实施,用于在 RAG 解决方案中使用 Azure AI 搜索。
-
Azure AI Studio,[将数据用于 Azure OpenAI 服务]。 Azure AI Studio 与 Azure AI 搜索集成,用于进行存储和检索。 如果已有搜索索引,可以在 Azure AI Studio 中连接到它,并立即开始聊天。 如果没有索引,则可以使用 Studio,[通过上传数据来创建一个索引]。
-
Azure 机器学习,可用作[矢量存储]的搜索索引。 可以[在 Azure 机器学习提示流中创建矢量索引],该流使用 Azure AI 搜索服务进行存储和检索。
但是,如果需要自定义方法,则可以创建自己的自定义 RAG 解决方案。 本文的其余部分将探讨如何将 Azure AI 搜索融入自定义 RAG 解决方案。
三、适合 Azure AI 搜索的自定义 RAG 模式
该模式的高级摘要如下所示:
- 从用户问题或请求(提示)开始。
- 将其发送到 Azure AI 搜索以查找相关信息。
- 将排名靠前的搜索结果发送到 LLM。
- 使用 LLM 的自然语言理解和推理功能生成对初始提示的响应。
Azure AI 搜索提供 LLM 提示符的输入,但不训练模型。 在 RAG 体系结构中,没有额外的训练。 LLM 是使用公共数据预先训练的,但它会生成由检索器中的信息扩充的响应。
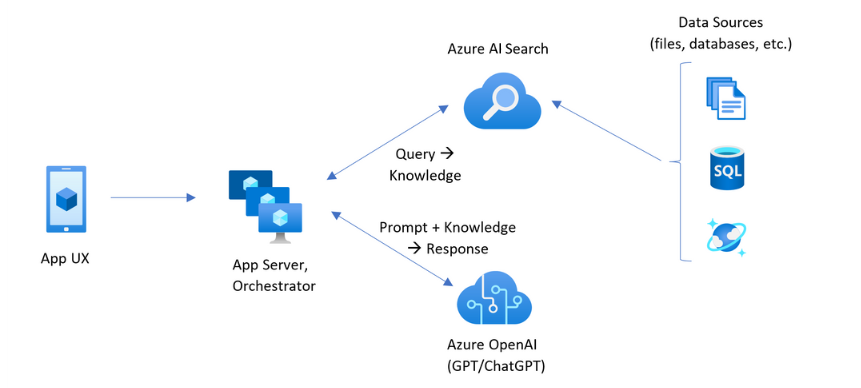
包含 Azure AI 搜索的 RAG 模式具有下图所示的元素。
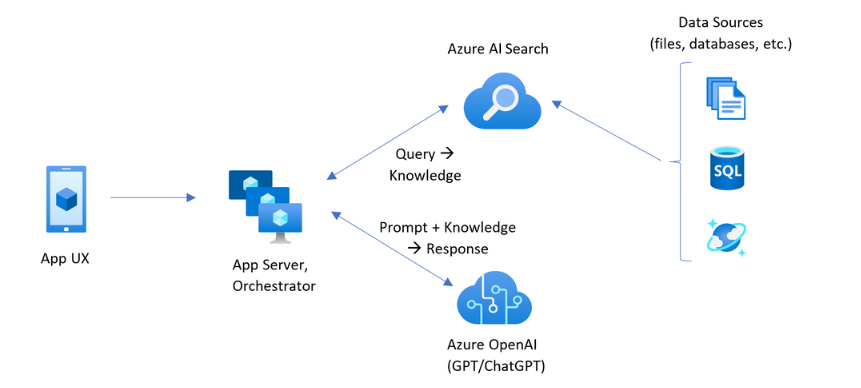
- 提供用户体验的应用 UX(Web 应用)
- 应用服务器或协调器(集成和协调层)
- Azure AI 搜索(信息检索系统)
- Azure OpenAI(适用于生成式 AI 和 LLM)
Web 应用提供用户体验,其中提供演示文稿、上下文和用户交互。 用户的问题或提示从此处开始。 输入通过集成层,首先转到信息检索以获取搜索结果,还会转到 LLM 以设置上下文和意向。
应用服务器或业务流程协调程序是协调信息检索和 LLM 之间交接的集成代码。 一个选项是使用 LangChain 协调工作流。 LangChain 与 Azure AI 搜索集成,使你能够更轻松地将 Azure AI 搜索作为检索器包含在工作流中。
信息检索系统提供可搜索索引、查询逻辑和有效负载(查询响应)。 搜索索引可以包含向量或非向量内容。 尽管大多数示例和演示都包含向量字段,但这不是必要的。 查询使用 Azure AI 搜索中的现有搜索引擎执行,该搜索引擎可以处理关键字(或术语)和矢量查询。 该索引根据你定义的架构预先创建,并使用从文件、数据库或存储中获取的内容加载。
LLM 收到原始提示以及 Azure AI 搜索的结果。 LLM 分析结果并制定响应。 如果 LLM 为 ChatGPT,则用户交互可能是你来我往的对话。 如果使用 Davinci,则提示可能是完全组合的答案。 Azure 解决方案最有可能使用 Azure OpenAI,但对此特定服务没有硬性依赖。
Azure AI 搜索不提供原生 LLM 集成、Web 前端或矢量编码(嵌入),因此需要编写处理解决方案这些部分的代码。 可以查看演示源 (Azure-Samples/azure-search-openai-demo),了解完整解决方案的蓝图。
四、Azure AI 搜索中的可搜索内容
在 Azure AI 搜索中,所有可搜索内容都存储在云中的搜索服务所托管的搜索索引中。 搜索索引专为具有毫秒级响应时间的快速查询而设计,因此其内部数据结构旨在支持该目标。 为此,搜索索引将存储_索引内容_,而不是整个内容文件(如整个 PDF 或图像)。 在内部,数据结构包括标记化文本的倒排索引、嵌入的矢量索引,以及需要逐字匹配情况下的未更改文本(例如,在筛选器、模糊搜索、正则表达式查询中)。
为 RAG 解决方案设置数据时,可以使用在 Azure AI 搜索中创建和加载索引的功能。 索引包括复制或表示源内容的字段。 索引字段可能是简单的转移(源文档中的标题或描述成为搜索索引中的标题或描述),或者字段可能包含外部过程的输出,例如生成图像的表示形式或文本描述的矢量化处理或技术处理。
你可能知道你想要搜索哪种类型的内容,因此请考虑使用适合每种内容类型的索引功能:
| 内容类型 | 已编制索引为 | 功能 |
|---|---|---|
| text | 令牌,未更改的文本 | 索引器]可以从其他 Azure 资源(如 Azure 存储和 Cosmos DB)中拉取纯文本。 你还可以向索引[推送任何 JSON 内容]。 若要修改使用中的文本,请使用[分析器和[规范化器]在编制索引期间添加词法处理。 如果源文档是可能在查询中使用的丢失的术语,则[同义词映射]会非常有用。 |
| text | 矢量 1 | 文本可以在外部分块和矢量化,然后在你的索引中[作为矢量字段编制索引]。 |
| 图像 | 令牌,未更改的文本 2 | OCR 和图像分析的[技能]可以处理图像以实现文本识别或图像特征。 图像信息转换为可搜索文本并添加到索引。 技能具有索引器要求。 |
| 图像 | 矢量 1 | 图像可以在外部矢量化以获得图像内容的数学表示形式,然后在你的索引中[作为矢量字段编制索引]。 |
| 视频 | 矢量 1 | 视频文件可以在外部矢量化以获得视频内容的数学表示形式,然后在你的索引中[作为矢量字段编制索引]。 |
| audio | 矢量 1 | 音频文件可以在外部矢量化以获得音频内容的数学表示形式,然后在你的索引中[作为矢量字段编制索引]。 |
1[矢量支持]以公共预览版提供。 目前,它要求调用其他库或模型进行数据分块和矢量化。 有关调用 Azure OpenAI 嵌入模型以矢量化内容和查询,并演示数据分块的示例,请参阅[此存储库]。
2[技能]是对 [AI 扩充]的内置支持。 为了进行 OCR 和图像分析,索引管道对 Azure AI 视觉 API 进行内部调用。 这些技能将提取的图像传递到 Azure AI 以进行处理,并接收输出作为由 Azure AI 搜索编制索引的文本。
矢量提供了对不同内容(多个文件格式和语言)的最佳适应性,因为内容以数学表示形式通用表达。 矢量还支持相似性搜索:在与矢量查询最相似的坐标上匹配。 与在标记化术语上匹配的关键字搜索(或术语搜索)相比,相似性搜索更加细致。 如果内容或查询中存在歧义或解释要求,这是更好的选择。
五、Azure AI 搜索中的内容检索
数据进入搜索索引后,就可以使用 Azure AI 搜索的查询功能来检索内容。
在非 RAG 模式中,查询从搜索客户端进行往返。 提交查询、在搜索引擎上执行查询,然后向客户端应用程序返回响应。 响应或搜索结果仅包含索引中找到的逐字匹配内容。
在 RAG 模式中,会在搜索引擎和 LLM 之间协调查询和响应。 用户的问题或查询会作为提示转发给搜索引擎和 LLM。 搜索结果从搜索引擎返回,然后重定向到 LLM。 返回给用户的响应是生成式 AI,即 LLM 的求和或答案。
Azure AI 搜索中没有(甚至语义搜索或矢量搜索也没有)任何查询类型可以构成新的答案。 只有 LLM 提供生成式 AI。 以下是 Azure AI 搜索中用于构建查询的功能:
| 查询功能 | 目的 | 使用原因 |
|---|---|---|
| [简单或完整的 Lucene 语法] | 对文本和非矢量数值内容的查询执行 | 全文搜索最适合精确匹配项,而不是相似匹配项。 全文搜索查询使用 [BM25 算法]排名,并支持通过计分概要文件进行相关性优化。 它还支持筛选器和 facet。 |
| [筛选器]和 [facet] | 仅适用于文本或数字(非矢量)字段。 根据包含或排除条件减少搜索外围应用。 | 提高查询的精准率。 |
| [语义排名] | 使用语义模型对 BM25 结果集重新排名。 生成可用作 LLM 输入的简短描述文字和答案。 | 比计分概要文件更简单,根据你的内容,对相关性优化来说是更可靠的方法。 |
| [矢量搜索] | 对矢量字段执行查询以实现相似性搜索,其中查询字符串是一个或多个矢量。 | 矢量可以用任何语言表示所有类型的内容。 |
| [混合搜索] | 合并了以上任意或所有查询技术。 矢量查询和非矢量查询并行执行,并在统一的结果集中返回。 | 在精确度和召回率方面取得的最显著的增益是通过混合查询实现的。 |
构建查询响应
查询的响应向 LLM 提供输入,因此搜索结果的质量是决定成功与否的关键因素。 结果为表格行集。 结果的构成或结构取决于:
- 用于确定响应中包含索引部分的字段。
- 表示索引匹配项的行。
当属性“可检索”时,字段将显示在搜索结果中。 索引架构中的字段定义具有属性,这些属性确定字段是否在响应中使用。 仅在全文或矢量查询结果中返回“可检索”字段。 默认情况下,将返回所有“可检索”字段,但可以使用“选择”指定子集。 除了“可检索”之外,该字段没有限制。 字段可以是任意长度或类型。 对于长度,Azure AI 搜索中没有最大字段长度限制,但 [API 请求的大小]有限制。
行与查询匹配,按相关性、相似性或两者设置排名。 默认情况下,全文搜索的结果限制为前 50 个匹配项,矢量搜索限制为前 50 个 k 最近邻匹配项。 可以更改默认值,以增加或减少最多 1,000 个文档的限制。 还可以使用top 和skip 分页参数将结果检索为一系列分页结果。
按相关性排名
处理复杂流程、大量数据和预期的毫秒级响应时,每个步骤都必须增加价值并提高最终结果的质量,这一点至关重要。 在信息检索方面,_相关性优化_活动可以提高发送给 LLM 的结果的质量。 结果中应尽包含最相关或最相似的匹配文档。
相关性适用于关键字(非矢量)搜索和混合查询(基于非矢量字段)。 在 Azure AI 搜索中,对相似性搜索和矢量查询没有相关性优化。 [BM25 排名]是全文搜索的排名算法。
通过增强 BM25 排名的功能支持相关性优化。 这些方法包括:
- [计分概要文件],如果在特定搜索字段或其他条件中找到匹配项,可提高搜索分数。
- 对 BM25 结果集重新排名的[语义排名],使用来自必应的语义模型对结果重新排序,以获得适合原始查询的更好语义。
在比较和基准测试中,包含文本和矢量字段的混合查询(与 BM25 排名结果的语义排名相补充)会产生最相关的结果。
适用于 RAG 方案的 Azure AI 搜索查询的示例代码
以下代码是从演示站点中的 retrievethenread.py 文件复制的。 它从混合查询搜索结果中为 LLM 生成 content。 可以编写更简单的查询,但此示例包含带有语义重新排名和拼写检查的矢量搜索和关键字搜索。 在演示中,此查询用于获取初始内容。
# Use semantic ranker if requested and if retrieval mode is text or hybrid (vectors + text)
if overrides.get("semantic_ranker") and has_text:
r = await self.search_client.search(query_text,
filter=filter,
query_type=QueryType.SEMANTIC,
query_language="en-us",
query_speller="lexicon",
semantic_configuration_name="default",
top=top,
query_caption="extractive|highlight-false" if use_semantic_captions else None,
vector=query_vector,
top_k=50 if query_vector else None,
vector_fields="embedding" if query_vector else None)
else:
r = await self.search_client.search(query_text,
filter=filter,
top=top,
vector=query_vector,
top_k=50 if query_vector else None,
vector_fields="embedding" if query_vector else None)
if use_semantic_captions:
results = [doc[self.sourcepage_field] + ": " + nonewlines(" . ".join([c.text for c in doc['@search.captions']])) async for doc in r]
else:
results = [doc[self.sourcepage_field] + ": " + nonewlines(doc[self.content_field]) async for doc in r]
content = "\n".join(results)
六、集成代码和 LLM
包含 Azure AI 搜索的 RAG 解决方案需要其他组件和代码才能创建完整的解决方案。 前面的部分介绍了如何通过 Azure AI 搜索进行信息检索以及使用哪些功能来创建和查询可搜索内容,本部分将介绍 LLM 集成和交互。
演示存储库中的笔记本是一个很好的起点,因为它们显示了将搜索结果传递到 LLM 的模式。 RAG 解决方案中的大多数代码都由对 LLM 的调用组成,因此你需要了解这些 API 的工作原理,但本文并未涵盖这些内容。
chat-read-retrieve-read.ipynb 笔记本中的以下单元格块显示聊天会话上下文中的搜索调用:
# Execute this cell multiple times updating user_input to accumulate chat history
user_input = "Does my plan cover annual eye exams?"
# Exclude category, to simulate scenarios where there's a set of docs you can't see
exclude_category = None
if len(history) > 0:
completion = openai.Completion.create(
engine=AZURE_OPENAI_GPT_DEPLOYMENT,
prompt=summary_prompt_template.format(summary="\n".join(history), question=user_input),
temperature=0.7,
max_tokens=32,
stop=["\n"])
search = completion.choices[0].text
else:
search = user_input
# Alternatively simply use search_client.search(q, top=3) if not using semantic ranking
print("Searching:", search)
print("-------------------")
filter = "category ne '{}'".format(exclude_category.replace("'", "''")) if exclude_category else None
r = search_client.search(search,
filter=filter,
query_type=QueryType.SEMANTIC,
query_language="en-us",
query_speller="lexicon",
semantic_configuration_name="default",
top=3)
results = [doc[KB_FIELDS_SOURCEPAGE] + ": " + doc[KB_FIELDS_CONTENT].replace("\n", "").replace("\r", "") for doc in r]
content = "\n".join(results)
prompt = prompt_prefix.format(sources=content) + prompt_history + user_input + turn_suffix
completion = openai.Completion.create(
engine=AZURE_OPENAI_CHATGPT_DEPLOYMENT,
prompt=prompt,
temperature=0.7,
max_tokens=1024,
stop=["<|im_end|>", "<|im_start|>"])
prompt_history += user_input + turn_suffix + completion.choices[0].text + "\n<|im_end|>" + turn_prefix
history.append("user: " + user_input)
history.append("assistant: " + completion.choices[0].text)
print("\n-------------------\n".join(history))
print("\n-------------------\nPrompt:\n" + prompt)
七、如何开始使用
-
[使用 Azure AI Studio 和“自带数据”]来试验现有搜索索引上的提示。 此步骤可帮助你确定要使用的模型,并演示如何在 RAG 方案中使用现有索引。
-
“与数据聊天”解决方案加速器,创建自己的 RAG 解决方案。
-
查看 azure-search-openai-demo 演示,了解包含 Azure AI 搜索的有效 RAG 解决方案,并研究生成体验的代码。 此演示对其数据使用虚构的 Northwind 健康状况计划。
下面是来自 Azure OpenAI 团队的类似的端到端演示。 此演示使用非结构化 .pdf 数据,其中包含 Microsoft Surface 设备上的公开可用文档。
-
[查看索引概念和策略]以确定引入和刷新数据的方式。 决定是使用矢量搜索、关键字搜索,还是混合搜索。 需要搜索的内容类型以及要运行的查询类型将决定索引设计。
-
[查看创建查询],以了解更多搜索请求语法和要求。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。











![[github配置] 远程访问仓库以及问题解决](https://img-blog.csdnimg.cn/083e22ef77cd4326a05791a0b41e9c51.png)
