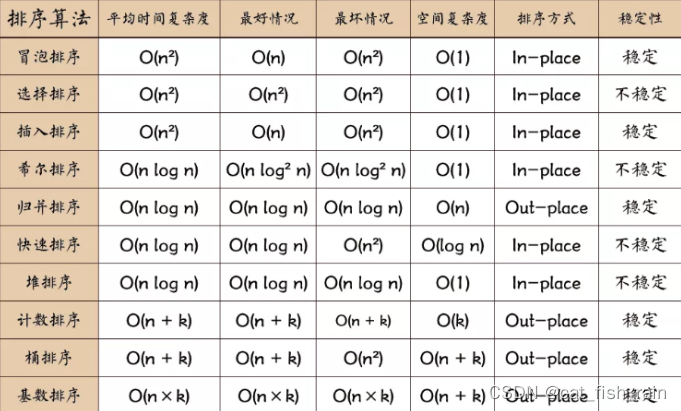
展示了一个完整的问答系统的实现,使用了Flask来构建Web界面、langchain进行文档处理和检索,以及OpenAI的语言模型。代码的复杂性在于集成了多种高级技术和处理大型数据集和语言模型。
- LangChain 实现给动物取名字,
- LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字
- LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄
- LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索Indexes for information retrieve
运行效果如下:
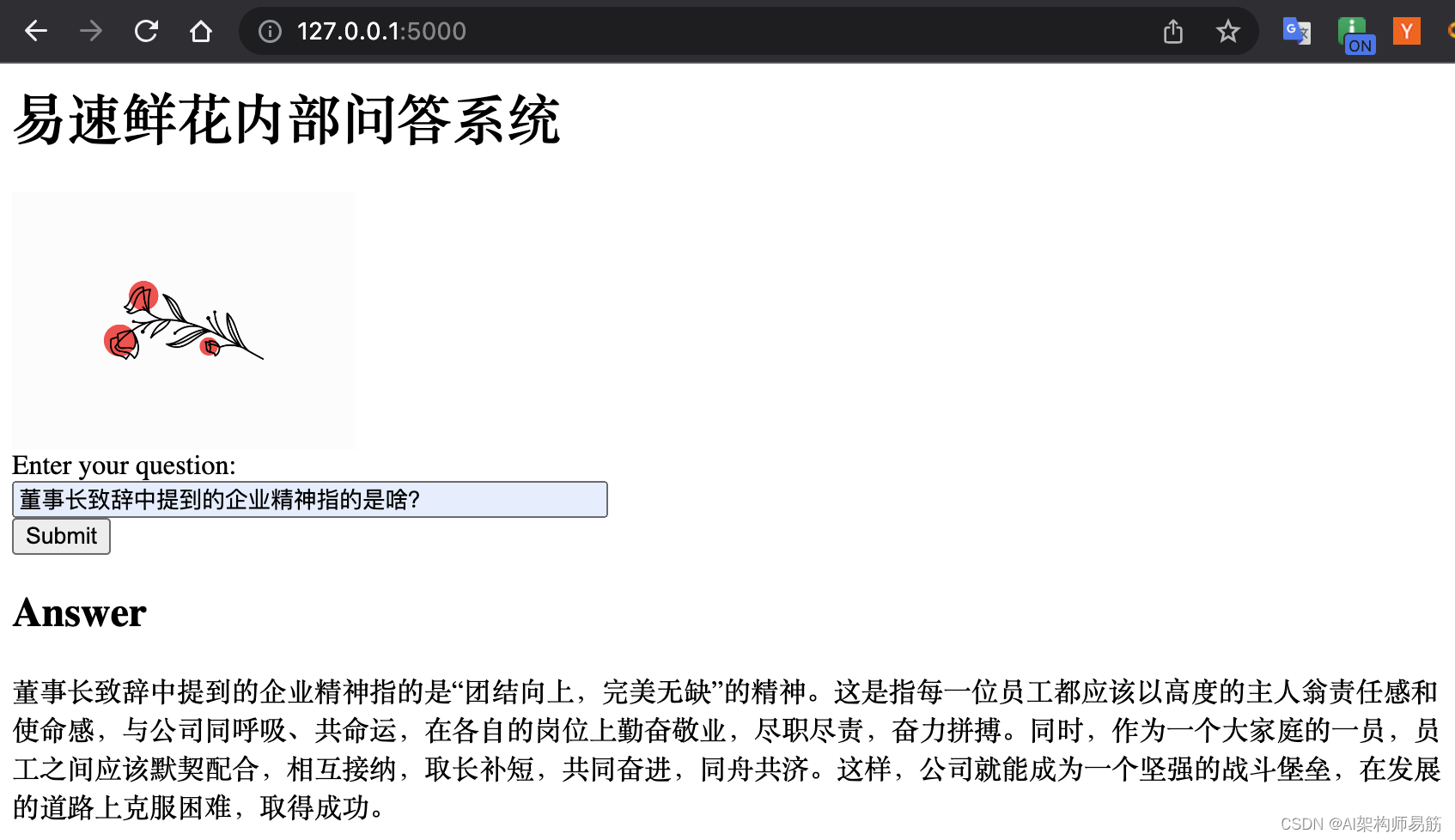
代码以及注释如下(代码为黄佳老师的课程Demo,如需要知道代码细节请读原文):
import os # 导入os模块,用于与文件系统交互
# 从langchain导入各种文档加载器
from langchain.document_loaders import PyPDFLoader # 加载PDF文档的加载器
from langchain.document_loaders import Docx2txtLoader # 加载DOCX文档的加载器
from langchain.document_loaders import TextLoader # 加载纯文本文档的加载器
from dotenv import load_dotenv # 导入dotenv,用于管理环境变量
load_dotenv() # 从.env文件加载环境变量
# 从指定目录加载文档
base_dir = './OneFlower' # 存储文档的目录
documents = []
for file in os.listdir(base_dir):
file_path = os.path.join(base_dir, file) # 构建完整的文件路径
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path) # 加载PDF文件
documents.extend(loader.load())
elif file.endswith('.docx'):
loader = Docx2txtLoader(file_path) # 加载DOCX文件
documents.extend(loader.load())
elif file.endswith('.txt'):
loader = TextLoader(file_path) # 加载文本文件
documents.extend(loader.load())
# 将文档分割成块以便嵌入和向量存储
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
# 在Qdrant向量数据库中存储分割和嵌入的文档
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Qdrant.from_documents(
documents=chunked_documents,
embedding=OpenAIEmbeddings(),
location=":memory:",
collection_name="my_documents",)
# 设置模型和检索链
import logging
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.chains import RetrievalQA
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) # 初始化一个大型语言模型工具 - OpenAI的GPT-3.5
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm) # 初始化一个MultiQueryRetriever
qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever_from_llm) # 初始化一个RetrievalQA链
# 使用Flask实现问答系统的UI
from flask import Flask, request, render_template
app = Flask(__name__) # 创建Flask应用
@app.route('/', methods=['GET', 'POST'])
def home():
if request.method == 'POST':
question = request.form.get('question') # 接收用户输入作为问题
result = qa_chain({"query": question}) # RetrievalQA链 - 读取问题,生成答案
return render_template('index.html', result=result) # 返回模型答案以渲染网页
return render_template('index.html') # 渲染网页
if __name__ == "__main__":
app.run(host='0.0.0.0',debug=True,port=5000) # 运行Flask应用

代码
- https://github.com/zgpeace/pets-name-langchain/tree/feature/docQA
参考
- https://github.com/huangjia2019/langchain/tree/main/02_%E6%96%87%E6%A1%A3QA%E7%B3%BB%E7%BB%9F




![[机缘参悟-119] :反者道之动与阴阳太极](https://img-blog.csdnimg.cn/a12b98b151cb497e841363d9869bb3d2.png)