Linux系统编程 day03 Makefile、gdb、文件IO
- 1. Makefile
- 2. gdb
- 3. 文件IO
1. Makefile
Makefile文件中定义了一系列规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至更加复杂的功能操作。Makefile就像一个shell脚本一样,也可以执行操作系统的命令,Makefile带来的好处就是可以实现自动化编译,一旦写好只需要一个make命令就可以让整个工程完全自动编译,极大地提升了软件开发的效率。
make是一个命令工具,是专门解释Makefile文件中的指令的命令工具。大多数IDE中都有这个命令。Makefile文件中会使用gcc编译器对源代码进行编译,最重生成可执行文件或者是库文件。Makefile文件的命名为Makefile或者makefile。
Makefile文件由一些列规则组成,规则如下:
目标: 依赖
(tab)命令
这里必须是tab键,输入空格无效。Makefile的三要素分别是目标、规则以及命令。目标为要生成的目标文件,依赖为目标文件由哪些文件生成,命令是由依赖文件生成目标文件的一系列命令。
如在当前目录下有main.c、add.c、sub.c、mul.c、dive.c、head.h这几个文件,head.h文件中存放的是add.c、sub.c、mul.c、dive.c中函数实现的声明,main.c中调用其它C语言文件中的函数。由基本的规则编写一个Makefile文件生成可执行文件main,于是有第一个版本。
main: main.c add.c sub.c mul.c dive.c
gcc -o main add.c sub.c mul.c dive.c -I./
这个版本的Makefile文件效率低,修改一个文件,所有的文件都会全部重新编译。想要写好一个效率更高的Makefile文件,就需要知道Makefile的工作原理。
Makefile想要生成目标,需要检查规则中所有的依赖文件是否都存在。若有的依赖文件不存在,则向下搜索规则,看看是否有生成该依赖文件的规则,如果有规则生成该依赖文件,则执行规则中的命令生成依赖文件;若没有规则生成该依赖文件,则程序报错。
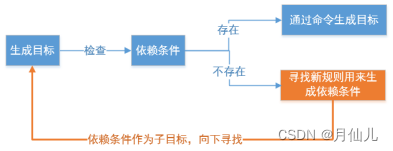
如果依赖文件都存在,则检查规则中的目标是否需要更新,如果目标的所有依赖中有一个被更新,则目标需要更新。这一点是根据哪个时间大进行决定的。如果目标时间大于依赖时间就不更新,目标时间小于依赖时间就更新。因为是先有依赖才有的目标,所以不需要更新的时候目标的时间一定是比依赖的时间大的。
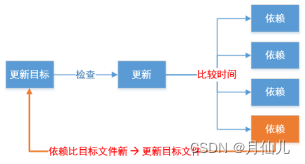
根据上面,于是我们有了第二个版本的Makefile文件。
main: main.o add.o sub.o mul.o dive.o
gcc -o main.o add.o sub.o mul.o dive.o
main.o: main.c
gcc -o main.o -c main.c -I./
add.o: add.c
gcc -o add.o -c add.c -I./
sub.o: sub.c
gcc -o sub.o -c sub.c -I./
mul.o: mul.c
gcc -o mul.o -c mul.c -I./
dive.o: dive.c
gcc -o dive.o -c dive.c -I./
可以发现这个版本里面虽然比上一个版本要稍微好点,但是里面有很多冗余,若C语言文件很多,编写起来会很麻烦。因此我们还需要继续寻找第三个更便捷的版本。既然上面有很多重复的部分,那么在Makefile中是否有相应的变量之类的东西去进行取代呢?
Makefile中也有变量的概念。Makefile中使用的变量类似于C语言中的宏定义,使用该变量相当于内容的替换,使用变量可以使Makefile易于维护,修改起来变得简单。Makefile中有三种类型的变量,分别是普通变量、自带变量、自动变量。
变量的定义是用=,使用的时候是$(变量名)。如下面语句定义了变量var1并将值赋值给了var2。
var1=main.c
var2=$(var1)
在编译器中也提供了一些变量供用户名使用,我们可以直接对其进行赋值。
| 自带变量名 | 作用 |
|---|---|
| CC | 编译器 gcc |
| CPPFLAGS | C预处理选项 -I |
| CFLAGS | C编译器选项 -Wall -g -c |
| LDFLAGS | 链接器选项 -L -l |
除此之外还有一些自动变量,自动变量只能用于规则的命令之中,而不允许在目标和依赖中使用,下面是一些自动变量。
| 自动变量名 | 含义 |
|---|---|
| $@ | 表示规则中的目标 |
| $< | 表示规则中的第一个条件 |
| $^ | 表示规则中的所有条件,组成一个列表,以空格隔开,如果有重复项会自动去重。 |
除了上述的变量之外还需要提及的是一个模式规则。模式规则用%,表示一个或者多个,依赖条件中同样可以使用%,依赖条件中的%的取值取决于其目标。
有了上述这些,我们可以写我们的第三个版本的Makefile。
target=main
objects=main.o add.o sub.o mul.o sum.o
CC=gcc
CPPFLAGS=-I./
main:$(objects)
$(CC) -o $@ $^
%.o:%.c
$(CC) -o $@ -c $< $(CPPFLAGS)
可以发现这个版本冗余的部分比上一个版本好了很多,但是在objects变量的地方我们需要写很多.o,所以还是麻烦,在Makefile中也提供了函数。
Makefile中的函数有很多,此处就说两个最常用的。
| 函数名 | 作用 | 示例 | 示例说明 |
|---|---|---|---|
| wildcard | 查找指定目录下指定类型的文件 | src=$(wildcard *.c) | 在当前路径寻找后缀为.c的文件,赋值给src |
| patsubst | 匹配替换 | objects=$(patsubst %.c, %.o, $(src)) | 将src变量中所有后缀为.c的文件换.o |
于是我们有了第四个版本的Makefile。
target=main
src=$(wildcard *.c)
objects=$(patsubst %.c, %.o, $(src))
CC=gcc
CPPFLAGS=-I./
$(target):$(objects)
$(CC) -o $@ $^
%.o:%.c
$(CC) -o $@ -c $(CPPFLAGS) $<
不过这个版本还有一个缺点,就是每次重新编译的时候都需要我们手动去清理掉中间的.o文件以及最终目标文件。但是我们使用make命令的时候只会去执行最终目标,如果有多个目标不会去执行。我们可以通过make 目标名去执行指定的目标。如果一个目标没有任何依赖,则永远是最新的,也就不会被执行,所以此时需要声明为伪目标,声明为伪目标之后,Makefile将不会再检查目标是否存在或者该目标是否需要更新。申明伪目标使用.PHONY 目标名进行声明。在命令中,我们在前面加入-表示此条命令出错,make也会继续执行后续命令。如果在命令的前面加入了@符号,则表示不显示命令本身,只显示结果。如果当前路径有多个makefile文件,则可以通过make -f 文件名执行对应的Makefile文件。
于是有了Makefile的第五个版本,也就是最终版本。
target=main
src=$(wildcard *.c)
objects=$(patsubst %.c, %.o, $(src))
CC=gcc
CPPFLAGS=-I./
$(target):$(objects)
$(CC) -o $@ $^
%.o:%.c
$(CC) -o $@ -c $< $(CPPFLAGS)
.PHONY:clean
clean:
-rm -rf *.o
rm -rf main
2. gdb
GDB是gcc的调试工具。GDB主要是帮忙完成以下四个方面的功能。
- 启动程序,可以按照你的自定义的要求随心所欲的运行程序。
- 可以让被调试的程序在你所指定的断点处停住(断点可以是表达式条件)。
- 当程序被停住时,可以检查此时你的程序中所发生的事。
- 动态地改变你程序的执行环境。
一般来说GDB调试的主要是C/C++程序。要调试C/C++程序,首先要在编译的时候将调试信息加到可执行文件中,这一点可以通过gcc的-g参数做到。如果编译的时候没有加-g,则在调试的时候看不到程序的函数名,变量名等,所替代的全是运行时的内存地址。
启动GDB在shell中执行gdb program,其中program为可执行程序的名字或者路径。下面给出一些关于启动时GDB的一些命令。
| 命令 | 作用 |
|---|---|
| set args | 指定运行时参数,如set args 10 20 30 |
| show args | 查看运行时参数 |
| run | 程序开始执行,若有断点则停在第一个断点处 |
| start | 程序向下执行一行,停在第一条语句处 |
| next | 单步跟踪,函数调用当做一条简单语句执行 |
| step | 单步跟踪,函数调用进入被调用函数体内 |
| finish | 退出进入的函数,如果出不去,看一下函数体内的循环是否有断点,如果有需要删掉或者设置无效 |
| until | 在循环体内单步跟踪的时候执行可以退出循环体 |
| continue | 继续执行程序,如果有断点则跳到下一个断点处 |
在调试的过程中,可以使用以下操作命令。
| 命令 | 作用 |
|---|---|
| list linenum | 显示第linenum行的上下文内容 |
| list function | 显示函数名为function的源程序 |
| list | 显示当前行后面的源程序 |
| list - | 显示当前文件开始处的源程序 |
| list file:linenum | 显示file文件中的第linenum行 |
| list file:function | 显示file文件中函数名为function的源程序 |
| set listsize count | 设置一次显示源代码的行数为count |
| show listsize | 显示当前listsize的设置 |
| break linenum | 设置断点在第linenum行 |
| break function | 设置断点在函数名为function的入口处 |
| break filename:linenum | 设置断点在filename文件中的第linenum行 |
| break filename:function | 设置断点在filename文件中函数名为function的入口处 |
| break where if condition | 当condition满足时候在where处设置断点,如break test.c:8 if i == 8 |
| info break | 查看所有断点 |
| delete num | 删除断点号为num的断点 |
| delete num1 num2 … | 删除多个断点,断点号为num1,num2… |
| delete num1-num2 | 删除多个连续断点,断点号为num1到num2 |
| delete | 删除所有断点 |
| disable num | 使断点号为num的断点无效 |
| disable num1 num2 … | 使断点号为num1,num2…的断点无效 |
| disable num1-num2 | 使在num1-num2中的连续断点无效 |
| disable | 使所有的断点无效 |
| enable num | 使断点号为num的无效断点有效 |
| enable num1 num2 … | 使断点号为num1,num2…的无效断点有效 |
| enable num1-num2 | 使在num1-num2中的连续无效断点有效 |
| enable | 使所有的无效断点有效 |
| display varname | 设置自动显示变量名为varname的值 |
| info display | 显示display中设置的自动显示信息 |
| undisplay num | 删除自动显示编号num的自动显示 |
| delete display num | 删除自动显示编号为num的自动显示 |
| delete display num1 num2 … | 删除自动显示编号为num1,num2…的自动显示 |
| delete display num1-num2 | 删除自动显示编号在num1-num2中连续的自动显示 |
| disable display num | 使自动显示编号为num的自动显示无效 |
| disable display num1 num2 … | 使自动显示编号为num1,num2…的自动显示无效 |
| disable display num1-num2 | 使自动显示编号在num1-num2中的连续自动显示无效 |
| enable display num | 使自动显示编号为num的无效自动显示有效 |
| enable display num1 num2 … | 使自动显示编号为num1,num2…无效的自动显示有效 |
| enable display num1-num2 | 使自动显示编号在num1-num2中的无效自动显示有效 |
| ptype varname | 打印变量名为varname的变量的类型 |
| print varname | 打印变量名为varname的值 |
| set var varname=value | 设置变量名为varname的变量值为value |
上述的很多命令都可以简写,简写列表如下。
| 命令全称 | 命令简写 |
|---|---|
| list | l |
| break | b |
| info | i |
| delete | d |
| disable | dis |
| enable | ena |
| run | r |
| next | n |
| step | s |
| until | u |
| continue | c |
| p |
这些简写都可以配合上面的命令混合使用。
3. 文件IO
首先学习文件IO就需要会C语言库中IO函数的工作流程,流程如下:
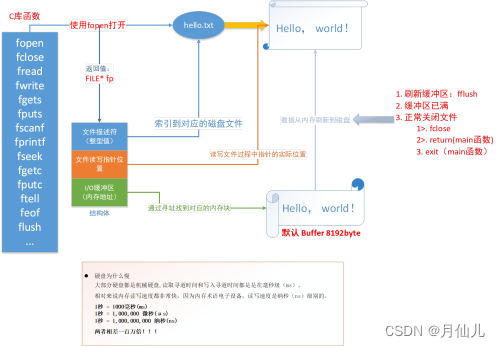
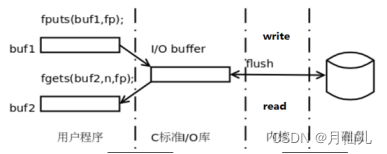
C语言中会使用fopen函数打开一个文件,会返回一个FILE *fp。
跟踪以下内核代码,我们可以发现是struct _IO_FILE定义为类型FILE。
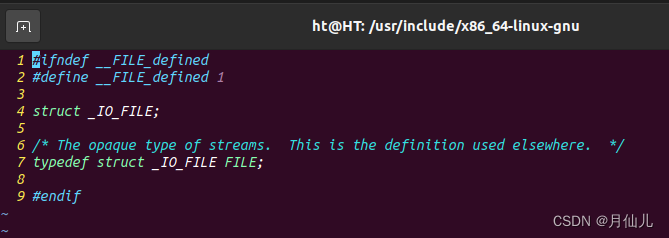
接下来我们看一下关于struct _IO_FILE的内容。
 在这个指针中,有三个部分是非常重要的。
在这个指针中,有三个部分是非常重要的。
- 文件描述符:通过文件描述符可以找到文件的inode,通过inode可以找到对应的数据块。代码中的
int _fileno存储的就是文件描述符。 - 文件指针:读和写共享一个文件指针,读或者写都会引起文件指针的变化。
- 文件缓冲区:读或者写会先通过文件缓冲区,主要是减少对磁盘的读写次数,提高读写磁盘效率。
在我们调用printf函数的时候,操作系统会先调用write函数,将文件描述符传递过去,然后操作系统会从用户态切换到内核态,通过调用系统调用sys_write()函数使设备驱动工作调用设备驱动函数显示printf函数中的内容。系统调用是由操作系统实现并提供给外部应用程序的编程接口。
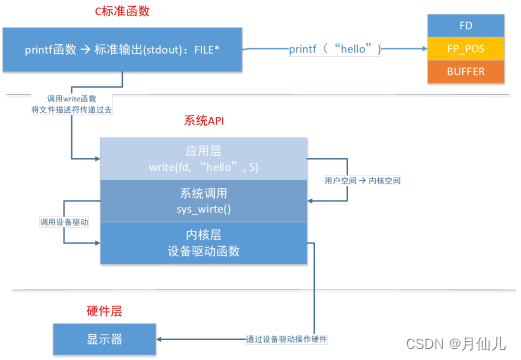
32位的Linux会为每一个运行的程序(进程)分配一个0~4G的地址空间。这个地址空间叫虚拟地址空间。进程的虚拟地址空间分为用户区和内核区。内核区是首保护的,用户不能对其进行读写操作。内核区中非常重要的是进程管理,进程管理中有一个区域是PCB(进程控制块)。在PCB中有文件描述符表,文件描述符表中存放着打开的文件描述符,涉及文件的IO操作都会用到这些文件描述符。用户区主要是存放环境变量、命令行参数、栈区、共享库加载区、堆区、.bss、.data、.text、受保护的地址区。其中受保护的区域用户也是不能操作的。
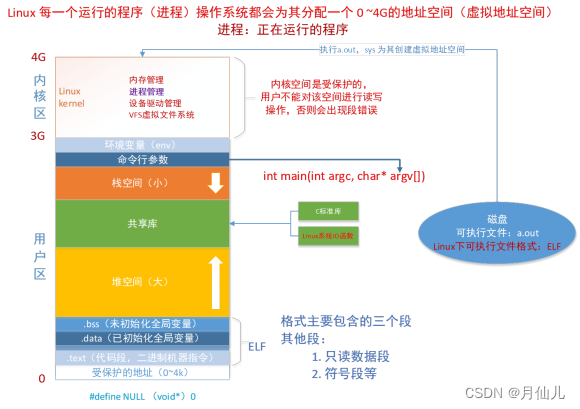
在PCB中存放的文件描述表可以存放1024个文件描述符。每个进程都默认打开三个文件描述符,分别如下。
- 标准输入,宏名为
STDIN_FILENO,值为0。 - 标准输出,宏名为
STDOUT_FILENO, 值为1。 - 标准错误。宏名为
STDERR_FILENO,宏名为2。
此后该进程每打开一个文件都会将该文件的文件描述符放在文件描述符表中最小的空位处。
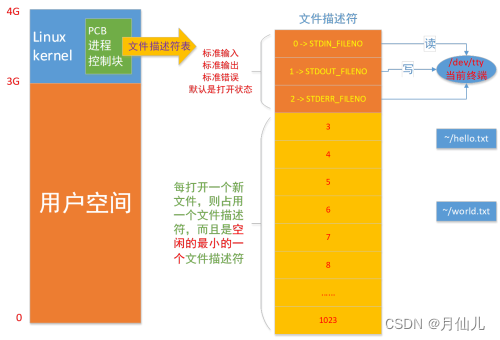
PCB是通过struct task_struct进行定义的。