文章目录
- 摘要
- 1 引言
- 2 问题描述
- 3 拟议框架
- 4 所提出方法的细节
- A.数据预处理
- B.变量相关分析
- C.MAG模型
- D.异常分数
- 5 实验
- A.数据集和性能指标
- B.实验设置与平台
- C.结果和比较
- 6 结论

摘要
异常检测是保证航天器稳定性的关键。在航天器运行过程中,传感器和控制器产生大量周期较长的多维时间序列遥测数据,以及及时准确地检测航天器内部异常的一个关键点是从大量遥测数据中提取基本特征。然而,由于遥测数据内的耦合关系和时间特征复杂,存在巨大的挑战。为了解决这个问题,我们提出了一种称为最大信息系数注意力图网络 (MAG) 的新方法。基本框架是一个图神经网络,它利用嵌入向量来描述每个维度的内在属性,相关性分析来研究长期依赖关系,这是一种用于确定维度之间短期交互的注意力机制,以及长短期记忆 (LSTM) 来提取时间特征。这些模块通过图神经网络的融合导致 MAG 模型的构建,允许对复杂的变量关系和时间特征进行全面分析,从而成功检测各种类型的异常。由于遥测数据具有异构的特点,我们采用了损失函数,设计了一种适用于MAG的无监督异常评分方法。为了验证该算法的有效性,我们使用两个公开的和两个新的可用航天器遥测数据集进行了实验,结果表明我们的算法在检测航天器数据异常方面比其他几种先进的方法更有效、更准确。
关键词:异常检测,异常评分,图神经网络(GNN),多变量时间序列,航天器遥测数据。
1 引言
由于航天器系统的复杂性和大小,其性能非常重要[1]。特别是,即使是微小的故障也会导致航天器发生灾难性破坏。因此,在开发故障时,航天器系统中异常行为的早期检测对于防止它加剧灾难性故障至关重要。
由于航天器遥测数据的维数相互关系和高维性质的复杂性,传统的建模技术在异常检测方面遇到了挑战。因此,依赖遥测数据的数据驱动方法受到了极大的关注[2]。鉴于异常通常很少见且数量少,仅使用正常遥测数据进行无监督学习以发现固有模式具有更大的价值。仅使用正常遥测数据的异常检测的关键是从多维时间序列数据中提取航天器正常运行状态的基本特征。然而,由于遥测数据之间的相互关系和时间特征复杂,这带来了重大挑战。
针对这一挑战,许多学者提出了各种经典的无监督异常检测模型,该模型在各个领域都表现出了优异的性能。这些包括局部离群因子(LOF)[3]、单类支持向量机(OC-SVM)[4]和支持向量数据描述(SVDD)[5]等[6]。此外,传统的机器学习方法不足以解决处理高维和大规模数据的挑战。随着人工智能的发展,深度学习越来越多地解决了这个问题[7]。例如,Su等人[8]和Song等人[9]分别提出了基于GRU-VAE和ST-GAN的异常检测方法。这些方法在公共可用数据集上表现出可靠的性能。
然而,前面提到的那些主要是为具有平移不变性的欧氏域数据设计的,而遥测数据更好地映射到非欧氏域数据,如图结构[10]。出于这个原因,图神经网络非常适合遥测数据,其中图节点代表检测窗口内变量的特征,图边描述维度之间的相关性。事实上,Deng等人[11]提出了一种基于偏差得分的异常检测算法,Xie等人[12]提出了一种结合小波变换和图神经网络的异常检测方法,两者在工业数据集上都表现出了令人称道的性能。
尽管如此,上述方法并不完全适合我们的问题。在复杂、多维和时间敏感的遥测数据的情况下,准确捕获每个检测窗口内每个变量的内在和时间特征至关重要,同时广泛检查它们复杂的非线性相互依赖性。此外,遥测数据表征了长周期属性,使得仅依靠短期窗口来提取相关能力的方法是不够的。此外,从航天器系统获得的遥测数据包含两个异构数据类型:模拟变量和状态变量(模拟变量是连续的,状态变量是二进制的),这使得单个损失函数不充分。
基于上述分析,本文提出了一种新的图神经网络框架。每个变量的内在和时间特征被表示为节点,而短期窗口内的长期关联分析和注意力被描述为边。最终,整个图结构都经过更新,最终实现异常检测过程。我们工作的主要贡献和优点如下。
1)本文旨在从三个方面表示遥测数据检测窗口中的有效特征:利用嵌入向量来描述每个维度的属性,使用图结构展示维度之间的关系,使用 LSTM 提取时间特征,并通过图神经网络融合各种组件。
2)为了考虑遥测数据的长周期,本文采用最大信息系数(MIC)来研究变量的长期关系,一种注意力机制来捕获窗口的短期关联,并最终结合这两种方法来构建图中表示关联的边。
3)本文解决了遥测数据的异质性以及边缘融合构造的特点,提出了一种新的损失函数。此外,还设计了一个适合网络结构的阈值分数。
本文的其余部分安排如下。第 II 节描述了航天器系统遥测数据异常检测的问题。第 III 节介绍了我们异常检测方法的总体框架。第四节详细描述了所提出的最大信息系数注意图网络(MAG)算法。实验结果报告在第 V 节中。最后,第六节对文章进行了总结。
2 问题描述
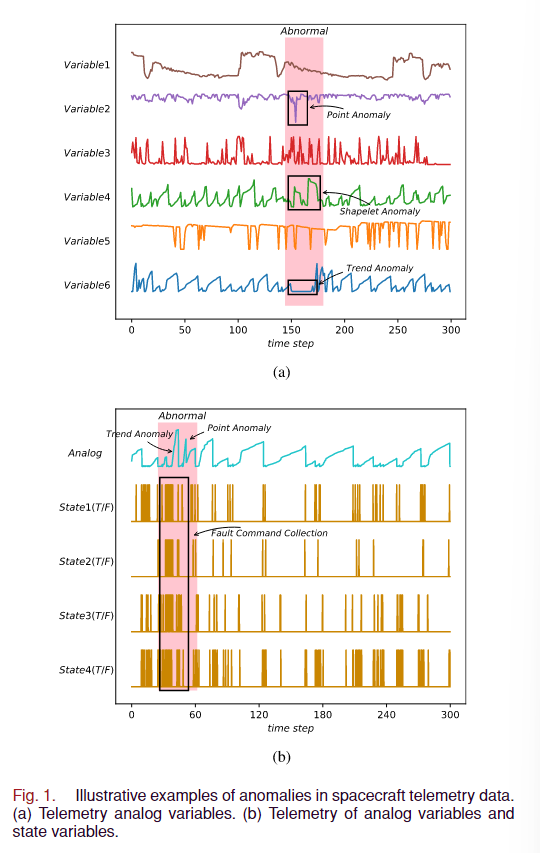
航天器遥测数据的类型可分为模拟变量(例如压电电压、加速度量)和状态变量(例如模块控制命令)。异常通常被指示为遥测数据中多个遥测变量的离群值或子序列,包括点异常、形状异常、趋势异常、上下文异常和多重集合异常。在图1(a)中,变量之间的期间存在不一致。特别是变量1的期间较长,可能超过用于检测的窗口长度。这个特性也突显了仅在检测时间窗口长度内分析相关性的不足。因此,必须对整个序列进行关联分析。由模拟变量和状态变量组成的异常如图1(b)所示。状态1到状态4是由控制台发送或接收的命令。在异常期间,由地面测试人员主动输入错误的模块命令得到的模拟变量观察到趋势异常和点异常。
实现实时异常检测的方法包括利用滑动窗口数据对多元时间序列进行实时预测,然后确定预测结果是否与观测值有较大的偏差。如果偏差太大,则预测被认为是异常的。将X={x(1),x(2),…,x(T)}定义为原始时间序列,该时间序列的时间跨度为T,将x^(T+1)定义为该时间序列在模型之后的时刻T+1的预测值,并将x(T+1)定义为在时刻T+1的真实遥测值,则其是否为异常可以用以下表达式表示:
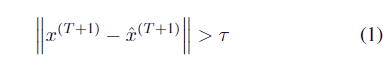
其中‖·‖表示计算ˆx(T+1)和x(T+1)偏差的规则,τ是预定义的异常阈值。^x(T +1) 和 x(T +1) 之间的偏差越大,x(T +1) 的异常概率越高。如图1中的数据异常所示,问题的关键是找到数据的时间和变量相关性。我们提出了模型 MAG 来解决这个问题并预测 ^x(T +1),并提出了一种新的公式来找到阈值 τ。
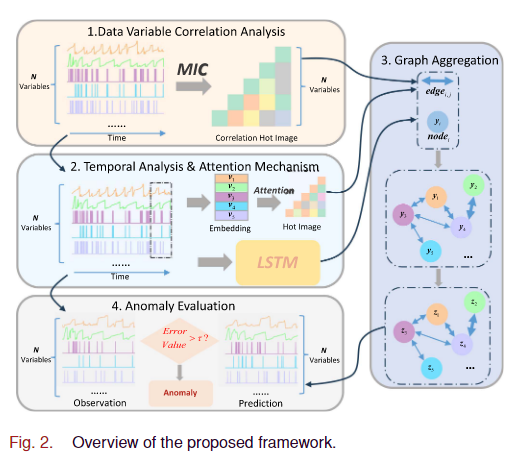
3 拟议框架
所提出的 MAG 框架旨在捕获遥测数据变量之间的相关性和时间特征,将它们集成到图中。随后,该框架利用来自图的聚合更新来预测未来的变量结果,并通过将它们与观测值进行比较来检测异常。
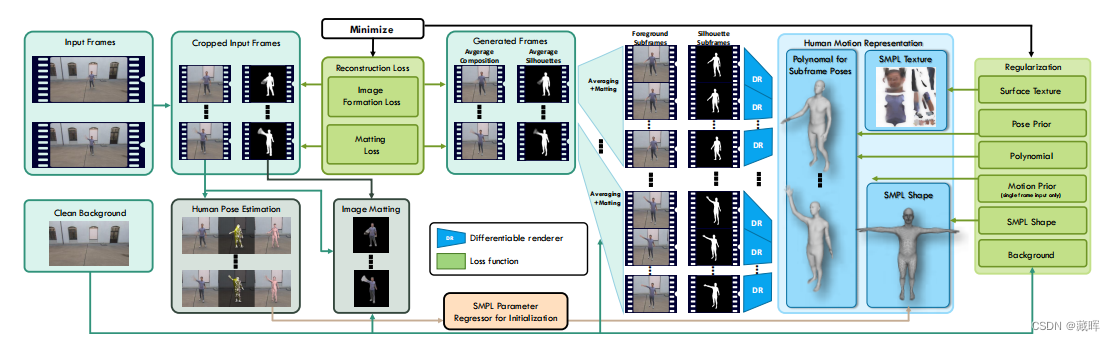
所提出框架的整体结构如图2所示。它由以下四个主要部分组成。
1)变量相关分析:利用MIC算法对航天器系统得到的遥测数据进行分析,得到相关系数矩阵,反映正常工况下变量之间的相关性。
2)时间分析和注意机制:数据经过滑动窗口分割。LSTM用于从窗口时间序列中提取时间特征,同时使用嵌入向量来捕获每个维度的固有属性。利用注意机制得到注意系数矩阵。
3)图聚合:将相关系数矩阵和注意系数矩阵整合为边,将时间特征节点和嵌入向量作为节点特征构建图。随后,整个网络通过迭代过程聚合和更新。
4) 异常评估:最终,MAG 网络预测下一个变量值并将其与观察值进行比较,生成错误分数。然后使用该分数来确定异常的存在。
4 所提出方法的细节
A.数据预处理
对多变量遥测数据进行分区对于实时计算是必不可少的,这需要建立实时计算检测窗口。首先,拆分多变量遥测数据 Φ ⊂ RT ×N。数据的总长度为 T,由 N 个变量组成,一组训练数据表示为 Φtrain ⊆ RT1×N ,一组测试数据表示为 Φtest ⊆ RT2 ×N。请注意,训练数据集中的所有数据点都必须正常。
接下来,训练数据集 Φtrain ⊆ RT1×N 被分割成一系列子序列 Xtrain = {Xi train, i = 1, 2,。, m} ⊆RSw ×N 通过滑动窗口,其中 Xitrain 表示当窗口大小设置为 sw 时 Xt−sw :t。给定步长 st,子序列的数量可以通过 m = (T1−sw)/st + 1 计算。类似地,测试数据集 Φtest ⊆ RT2 ×N 被划分为子序列 Xtest = {Xjtest, j = 1, 2,。, n} 通过滑动窗口,其中 n = (T2−sw)/st + 1。为了验证目的,测试数据集中的每个点都标有二进制数(0 表示正常,1 表示异常)。
B.变量相关分析
由于遥测变量的周期性质不一致,数据检测窗口不能覆盖整个周期。在滑动数据窗口之前,需要对原始训练数据进行相关性分析。MIC [13] 是一种测量两个变量之间相关性的有效方法。
对于给定的训练数据集 Φtrain ⊆ RT1×N ,对于任意两个具有 T1 元素的离散变量,A = {ai | i = 1, 之间的 MIC 值。, T1} 和 B = {bi | i = 1,., T1} 可以通过以下等式获得:
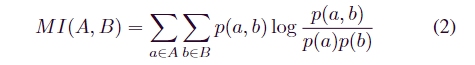
其中 p(a, b) 是变量 a 和 b 的联合概率密度,p(a) 和 p(b) 分别是由直方图估计方法计算的变量 a 和 b 的边际概率密度。
对于有限集 D = {(ai, bi),i = 1,。, n},给定一个网格 G,我们可以将 D 的 ai 值划分为 bin,将 D 的 bi 值划分为 b bin。MIC 由下式给出
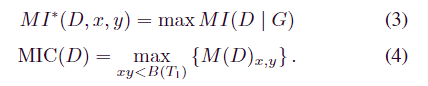
最大信息系数是特征矩阵中获得的最高归一化 MI 值。其中ω(1) < B(T1) < O(T 1−ε1)和0 < ε < 1。一般来说,当B(T1) = T 0.6 1时,MIC在实践中效果很好。计算后,可以得到N个遥测变量与相关矩阵M之间的MIC值。mij 表示遥测变量 i 和遥测变量 j 之间的相关性,其值在 0 到 1 之间。
C.MAG模型
在训练阶段,时间窗口内的每个遥测变量都表现出时间和内在属性特征。使用嵌入向量表示每个遥测变量的内在属性,从而实现后续反馈、性能差异和更新。此外,注意力机制可用于更有效地表达窗口内变量之间的关系。因此,我们为每个遥测变量引入一个嵌入向量来表示其特征vi∈Rd,对于i∈{1,2,。, N }。这些嵌入是随机初始化的,然后与模型的其余部分一起训练。这些嵌入 vi 之间的相似性代表了遥测变量的内在属性。
在 MAG 模型中,对于 Xtrain 或 Xtest 的子序列组合,将模型输入定义为历史子序列数据 x(t) := [x(t−w), x(t−w+1)。, x(t−1)] 对于在时间 t 的大小为 w 的滑动窗口。注意系数αi,ji的计算如下:
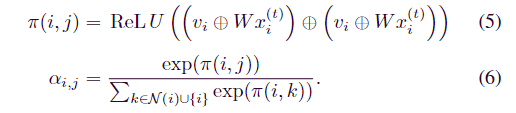
在计算注意系数αi,j后,结合相关系数mij形成每条边eij,构造邻接矩阵E
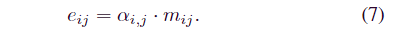
在边的构建之后,我们使用 LSTM 技术来提取时间关联特征。x(t) 受到 LSTM 网络以提取时间特征。时间特征可以通过 LSTM 网络提取,表示为

最后,利用图神经网络来整合子序列内的时间和空间关联。构建的图模型利用前面提到的 ei,j 来形成邻接矩阵。时间特征 y(t) 用作图神经网络的输入,能够从每个节点及其邻居聚合和更新信息,最终生成节点 i 的输出表示为 z(t)i,如下所示:
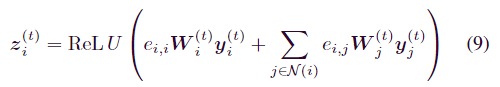
其中 y(t)i ∈ Rw 是节点 i 的时间输入特征,N (i) ={j | eij > 0} 是节点 i 的邻居集,W ∈ Rd×wi 是每个节点的共享线性变换的可训练权重矩阵。
从上面的特征提取器中,我们得到所有 N 个节点的表示为 {z(t)1 ,。, z(t)N }。对于每个 z(t)i ,我们将其乘以嵌入 vi 的相应时间序列的继续元素(表示为 ◦)。然后,我们使用所有节点的结果作为输出维度为 N 的堆叠全连接层的输入来预测时间步 t 的遥测值向量

模型的预测输出表示为 ^x(t)。我们将第二节中描述的模拟变量和状态变量分别表示为 x(t)a 和 x(t)s。考虑到这两种类型的异质性,采用了不同的损失函数。模拟变量利用均方误差,最小化预测输出ˆx(T)a与观测数据x(T)a之间的差异。另一方面,对于状态变量,使用了二元交叉熵损失。为了减轻过度拟合并确保滑动窗口内最终边缘的适当大小,我们引入了一个约束项。该术语考虑了相应图 [14] 的非循环性,并结合了相关分析的结果。最终的损失函数如下:

其中 λ 和 c 表示拉格朗日乘数和惩罚参数,并通过增广拉格朗日方法 [15] 求解。Ns表示状态变量的维数,Na表示模拟变量的维数。MAG的网络结构如图3所示。

D.异常分数
在通过网络获得图形结构之后,检测偏离正常模式的异常是下一步。该模型通过为每个遥测计算单独的异常值,然后将它们合并为每个时间戳的单个异常值来实现这一点。由于我们的检测算法选择了基于MAG的模型,因此还需要根据该模型的特征专门设计异常值确定规则。异常分数比较时刻t的预期行为与观察到的行为,并计算时刻t与真实遥测值之间的误差值Err(t)
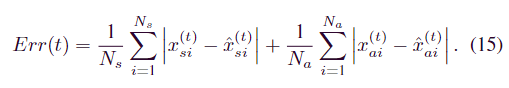
为了防止任何一个遥测值产生比其他遥测值过高的偏差,我们对每个遥测值的误差值Err(t)进行归一化,得到a(t)。
在阈值选择部分,为了避免引入额外的超参数,我们在实验中提出了一种计算方便的方法。通过计算训练集上每个时间戳的偏差atrain(t),我们可以通过以下等式计算阈值以获得:
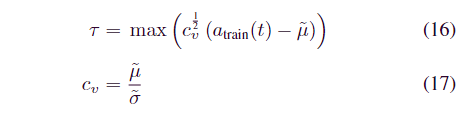
其中 cv 是变异系数,它是遥测数据中变化程度的统计度量。̃μ 和 ̃σ 分别是值 atrain(t) 的中值和四分位数范围 (IQR)。我们使用中位数和 IQR 而不是变异系数所需的均值和标准差,因为它们不假设数据分布,并且对模型的异常分数更稳健。最后,如果测试集的Err(t)超过任何固定阈值τ,则标记为异常的时间tis。
许多已发表的异常检测算法[16]使用3σ算法和峰阈值(POT)算法来挖掘阈值τ。POT是一种使用极值理论的阈值挖掘方法,假设时间序列中的峰值满足广义帕累托分布(GPD)。然而,当数据的分布特性与GPD不一致时,POT方法的适用性可能会受到限制。对于航天器系统的遥测数据,下一部分的实验表明我们的方法更具适应性。
基于MAG的模型算法的过程如算法1所示。

5 实验
A.数据集和性能指标
我们在两个新的遥测数据集和两个公共数据集上进行了实验。两个新的数据集 SCC-1 和 SCC-2 来自两个不同卫星系统的遥测数据。NASA为土壤水分主动被动(SMAP)卫星和火星科学实验室(MSL)漫游[17]提供了两个公共遥测数据集。四个数据集的详细信息如表 I 所示。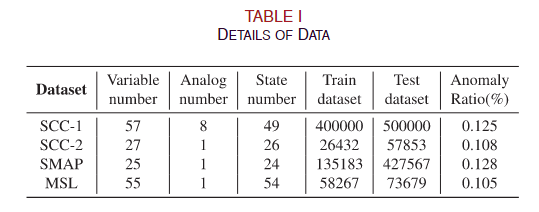
对于这些数据集,正常数据点标记为0,异常值标记为1。然后,将10%的训练数据集划分为验证数据集。请注意,训练数据集仅包含正常时间序列。我们使用常用的指标来评估我们提出的 MAG 算法的性能,即 Precision、Recall 和 F1 分数
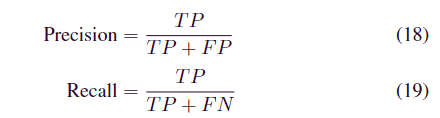

其中 TP 是预测的实际异常的数量,FP 是假阳性样本的数量,FN 是假阴性样本的数量。
B.实验设置与平台
在数据预处理阶段,我们设置窗口大小 w = 50 和步长 st = 1,然后将原始时间序列拆分为所需的子序列。在网络结构中,我们将嵌入向量维度设置为128,并将隐藏层设置为128。我们利用学习率为1 × 10−3的Adam优化器[18]来训练模型。我们使用了一种广泛使用的调整策略[19][20]:如果连续异常段中的某个时间点被检测到,那么该段中的所有异常都被认为被正确检测到。基于异常时间点会引发警报,并进一步使整个段在现实应用中被注意到的观察,这种策略是合理的。我们使用CUDA 11.6和PyTorch几何库[22],在PyTorch [21]版本1.9.1中实现了我们的方法和其变体。我们将训练模型设置为100个周期,并将早期停止设置为10。为了获得可靠的结果并减少训练阶段的随机性,样本被分别训练和测试了十次,然后计算了性能指标的标准偏差。最后,我们的算法在配备Intel® Xeon® CPU E5-2690 v4 @ 2.60 GHz和NVIDIA RTX 3090显卡的服务器上进行训练和测试。
C.结果和比较
1)窗口大小:为了确定适当的窗口大小 Sw,我们通过选择部分小数据集在三个数据集上进行了实验。窗口大小设置为 20、30、50、80、100、150 和 200。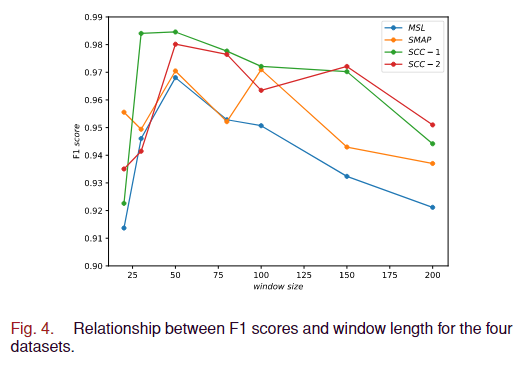
四个数据集的 F1 分数如图 4 所示。选择过长窗口会导致冗余信息、响应缓慢和计算复杂度增加。相反,选择太短的窗口长度将导致时间特征的捕获不足,导致稳定性不足。四个小数据集的实验结果表明,窗口大小为 50 是最优的。
2)基线比较:为了展示我们提出的算法的有效性,我们对其性能与其他基准无监督异常检测算法进行了比较分析。其中包括基于深度学习的模型,如AnomalyTransformer[19]、ST-GAN[9]、InterFusion[23]、GDN[11]和GRU-VAE[8];基于聚类的技术,如Deep-SVDD[24];以及OC-SVM[25]和IsolationForest[26]。值得注意的是,STGAN 和 AnomalyTransformer 代表最复杂的深度模型。我们在SCC-1、SCC-2、SMAP和MSL数据集上进行十轮评估,得出平均精确度、召回率和F1分数的结果。四种算法的比较结果如表II所示。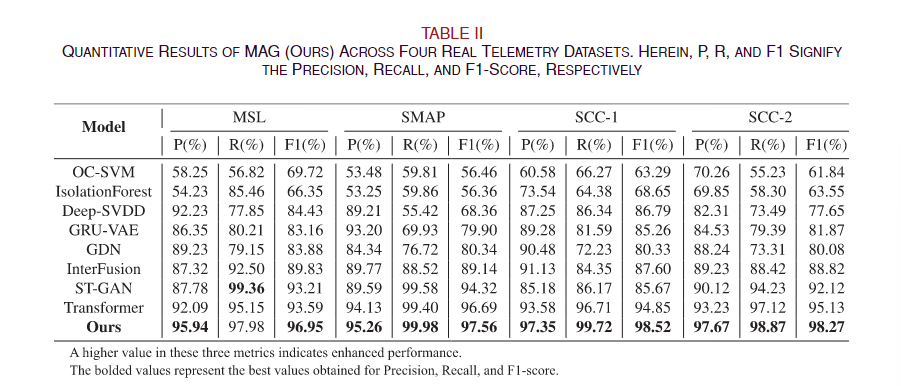
根据表 II,我们的方法在所有四个数据集上都获得了最高的 F1 分数,证明了平衡误报率和漏报率的最佳性能。此外,我们的方法在 SCC-1 和 SMAP 数据集上的召回率方面表现出最令人满意的结果,这表明在这两个数据集上产生误报的可能性最小。
3)消融比较:为了研究我们方法的每个组件的必要性,我们逐渐排除和替换这些组件并监控模型性能如何下降。实验结果如表III所示。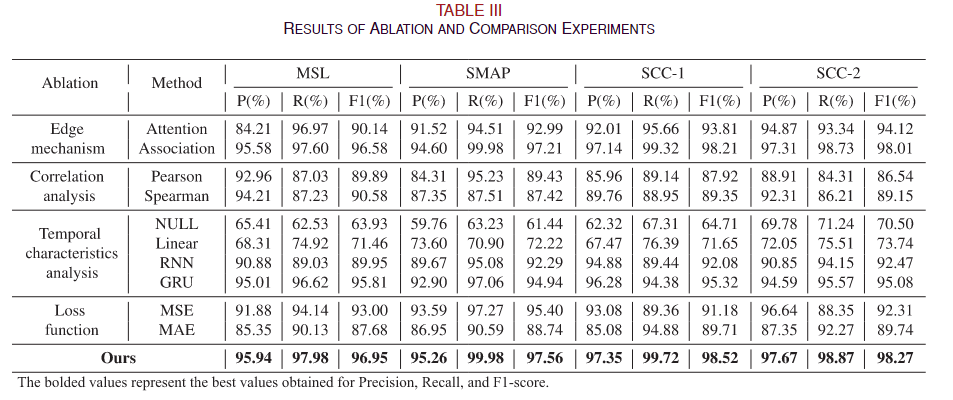
为了比较边缘机制的有效性,我们通过消除相关性分析或注意力机制进行了单独的实验。实验结果表明,这两种机制的融合产生了最有利的结果,因为相关分析后注意力机制的引入有效地提高了模型的适应性。然而,仅依靠注意力机制和窗口内的数据不足以有效捕捉长时间相关性和依赖性的程度。
此外,我们使用 Pearson 和 Spearman 方法 [27] 来比较相关性。实验结果表明,MIC 优于 Pearson 和 Spearman 相关系数。这种差异的出现是因为 Pearson 和 Spearman 相关系数假设线性相关,导致分析非线性关系时不准确。相反,MIC 不依赖于这样的假设,并且可以准确地捕获扩展周期内的线性和非线性相关性。
关于时间关系分析,我们使用消融实验比较了线性、RNN 和 GRU 层连接 [28]。研究结果表明,使用网络层或线性层会导致效率较低,这主要是由于无法提取时间特征。相比之下,结合 RNN、GRU 或 LSTM 的层连接会产生更有效的发现。具体来说,LSTM 具有比 GRU 和 RNN 更复杂和更稳健的结构,可以更好地控制信息流并实现长期依赖关系捕获。因此,LSTM 可以提取优越的时间特征,从而获得更好的结果。
关于损失函数,我们应用了均方误差(MSE)和均绝对误差(MAE)[29],并将它们与我们的方法进行了比较。实验结果表明,针对两种不同类型的数据采用两种混合损失函数可以显着提高模型的效率。
4)阈值比较:我们还评估了阈值 τ 对四个数据集的 F1 分数的影响。如图 5 所示,当阈值太小时,召回值会很低,导致 F1 分数降低。虽然如果阈值设置得太高,精度值会减小,导致 F1 分数下降。因此,适当地设置阈值以确保最佳 F1 分数至关重要。
我们对两种阈值方法进行了比较:基于高斯分布的 3σ 阈值和极值理论阈值 (EVT)。这些阈值对四个测试数据集的 F1 分数的影响如图 5 所示。结果表明,随着阈值 (τ) 的增加,F1 分数最初达到峰值,然后下降。我们提出的阈值方法非常接近通过穷举搜索获得的最佳阈值,从而证明了我们的异常阈值确定规则的有效性。这可能是因为 3σ 阈值和 EVT 方法都假设先验分布不适用于遥测数据。相反,我们的方法使用利用中值和四分位范围的公式,更稳健,不受数据分布形状的影响。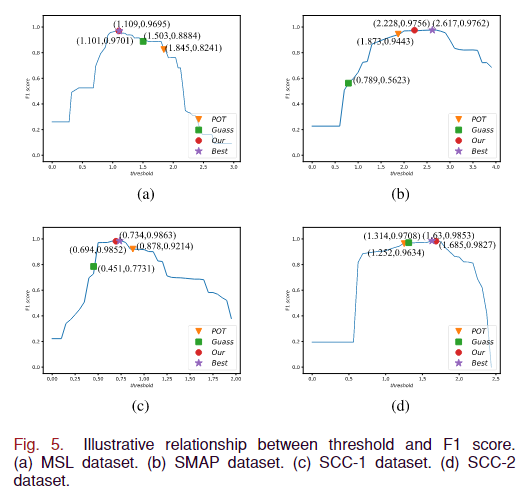
6 结论
本文提出了一种基于MAG结构模型的遥测数据异常检测算法。具体来说,该算法构建了一个图结构模型,使用嵌入向量描述每个维度的内在属性,进行相关性分析以研究长期依赖关系,通过注意力机制确定各维度之间的短期相互作用,并使用LSTM提取时序特征。最后,通过图神经网络融合这些模块,该模型有效地整合了这些序列的维度和时间特征之间的耦合关系,从而能够成功检测各种类型的异常。为了确定异常,引入了适应网络结构的异常分数。
为了确定我们提出的异常检测算法的有效性和优越性,我们在四个真实的遥测数据集上进行了实验,并将我们的方法与其他最先进的算法进行了比较,取得了最佳结果。此外,消融实验进一步证明了我们模型组件的有效性。与其他广泛使用的技术相比,我们提出的异常阈值表现出更高的准确性,并非常接近最佳阈值。
然而,虽然不影响实时异常检测的效率,但在相关分析计算过程中,计算成本随着数据量的增加而增加,保证了MIC计算效率的优化。此外,研究更多用于各种异常类型的基于 MAG 的异常检测算法并推进故障诊断提出了有前景的研究课题。


没代码