十六、Integrating Boxes and Masks: A Multi-Object Framework for Unified Visual Tracking and Segmentation
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Xu_Integrating_Boxes_and_Masks_A_Multi-Object_Framework_for_Unified_Visual_ICCV_2023_paper.pdf
github: https://github.com/yoxu515/MITS
1、摘要
在视觉目标跟踪(VOT)和视频目标分割(VOT,VOS)的共同目的。一些研究已经尝试过联合跟踪和分割,但在初始化和预测中往往缺乏box和mask的完全兼容性,主要集中在单对象场景上。为了解决这些限制问题,本文提出了一种用于统一跟踪和分割的多对象mask和box集成框架,称为MITS。首先,提出了统一的识别模块来支持初始化的box引用和mask参考,其中详细的对象信息从box中推断或直接从mask中保留。此外,还提出了一种新的精确框预测器,用于精确的多目标框预测,促进了面向目标的表示学习。所有目标对象从编码到传播和解码同时处理,作为VOT和VOS的统一管道。实验结果表明,MITS在VOT和VOS基准测试上都取得了最先进的性能。
2、方法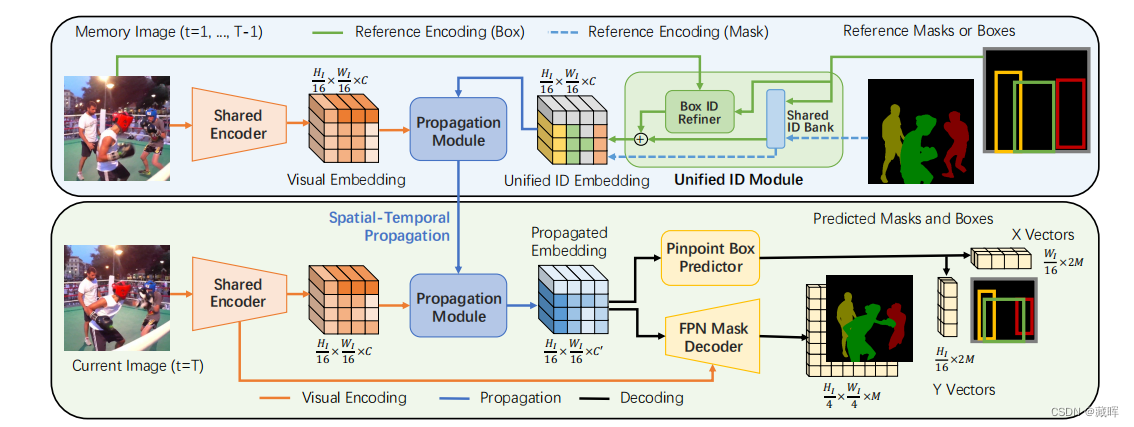
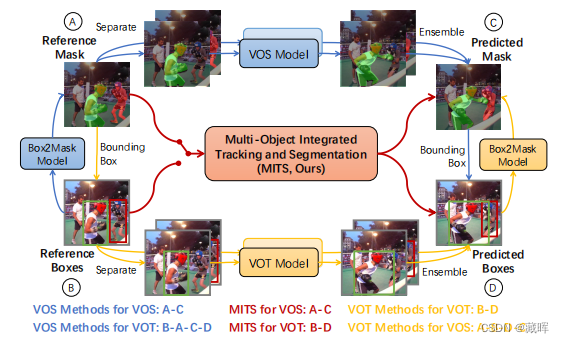
MITS中针对VOT和VOS任务的统一encoding-propagation-decoding pipeline。
首先box和mask参考都可以通过统一的ID模块进行编码(包括图像特征),得到历史帧统一ID embedding(用一个下采样16倍的tensor块表示)。
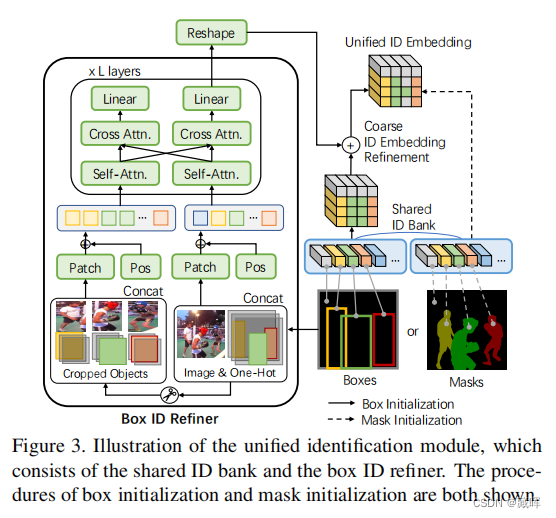
第二步,ID embedding和编码后的图像特征被送入传播模块中,在传播模块中,历史信息的ID embedding被设置为key,图像特征被设置为query,进行attention计算。
第三步,融合当前帧和过去帧历史信息的propagate embedding用于预测当前帧的mask 和box。
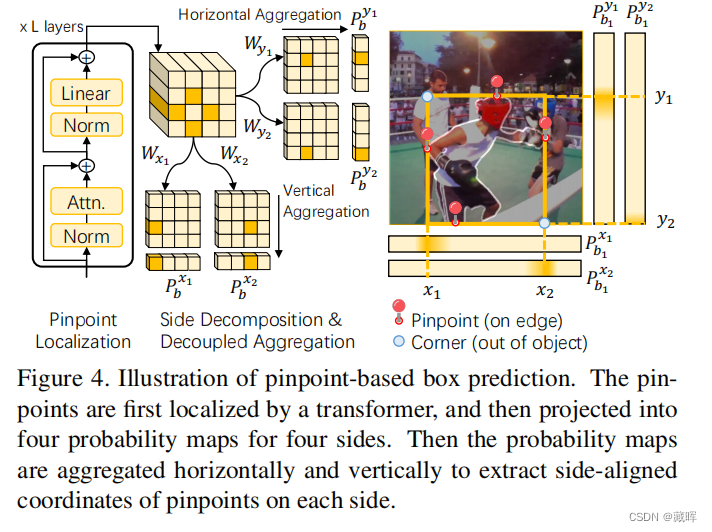
1)框预测如下图,先通过Transformer网络定位4个精确点,然后投影到四个边的概率映射中,将概率图水平和垂直聚合,提取每边的精确点坐标(作者文中提到这种做法是为了和mask更匹配)。
2)mask预测为一个常规的instance mask问题。
十七、3DMOTFormer: Graph Transformer for Online 3D Multi-Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Ding_3DMOTFormer_Graph_Transformer_for_Online_3D_Multi-Object_Tracking_ICCV_2023_paper.pdf
github: https://github.com/dsx0511/3DMOTFormer
1、摘要
准确、一致地跟踪三维物体对自动驾驶车辆至关重要,从而能够实现更可靠的下游任务,如轨迹预测和运动规划。基于近年来目标检测的实质性进展,检测跟踪范式因其简单和高效而成为一种流行的选择。最先进的3D多目标跟踪(MOT)方法通常依赖于非学习的基于模型的算法,如卡尔曼滤波器,但需要许多手动调整的参数。另一方面,基于学习的方法面临着适应在线设置的问题,导致训练与推理之间的分布不匹配以及次优表现。在这项工作中,我们提出了3DMOTFrorer,一个基于几何的Transformer 3D MOT框架架构。我们利用边缘增广图变换对跟踪检测二部图逐帧进行推理,并通过边缘分类进行数据关联。为了减少训练和推理之间的分布不匹配,我们提出了一种新的在线训练策略,具有自回归和递归前向传递以及顺序批量优化。
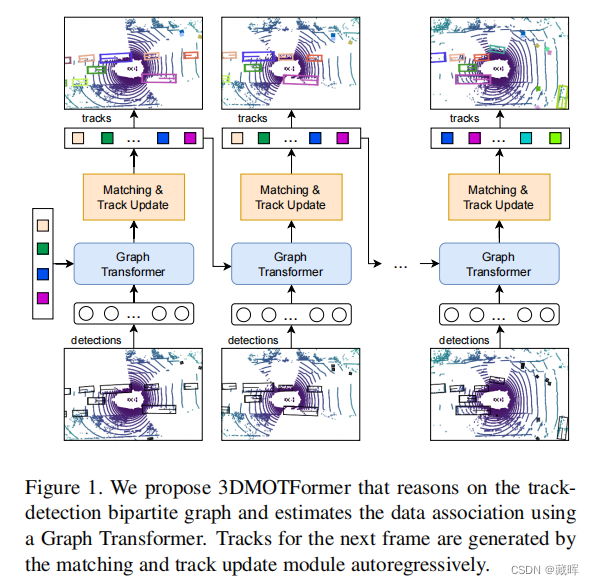
看着类似MOTR v2的输入和输出,但是做法有一定差异。
2、方法
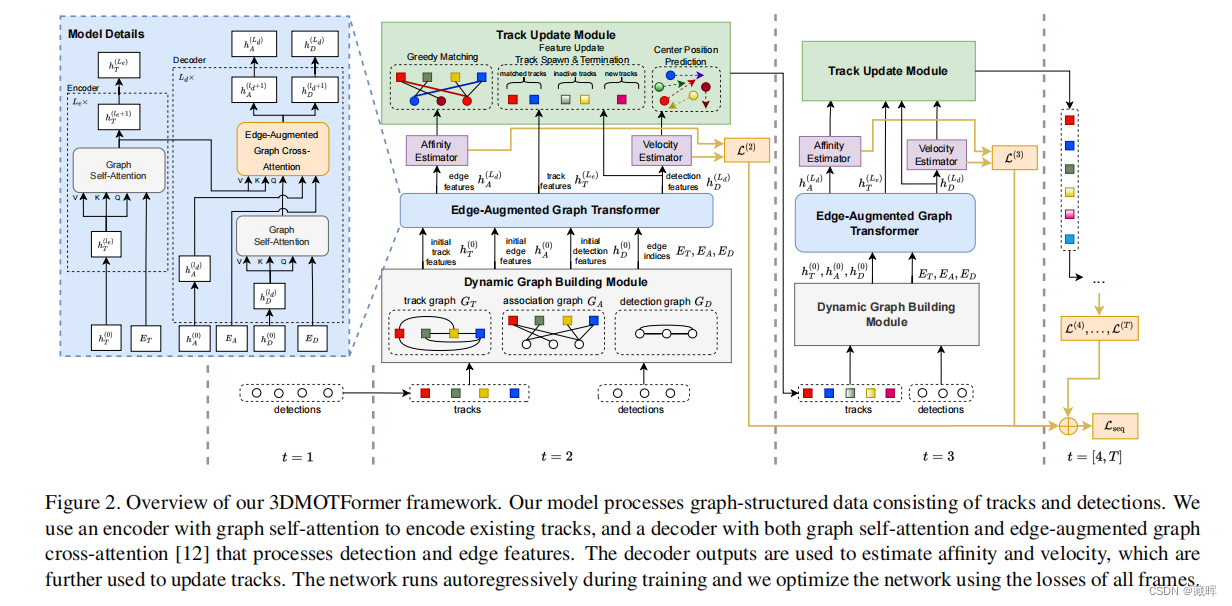
模型处理由轨迹和检测组成的图结构数据。
文中使用一个带有图自注意的编码器来编码现有的轨迹,以及一个同时带有图自注意和边缘增强图交叉注意的解码器来处理检测和边缘特征。与常规的self-attention网络不同,graph self-attention会将归一化的范围限制在graph设置的目标之间,避免目标数过多稀释了归一化数值。
解码器输出用于估计亲和度和速度(FFN),并进一步用于更新轨迹。
网络在训练过程中自动回归运行,我们使用所有帧的损失来优化网络(和MOTR的思路相同)。
十八、Object-Centric Multiple Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Zhao_Object-Centric_Multiple_Object_Tracking_ICCV_2023_paper.pdf
github: https://github.com/amazon-science/object-centric-multiple-object-tracking
1、摘要
无监督的以对象为中心的学习方法,允许在没有额外的定位信息的情况下将场景划分为实体,并且减少多目标跟踪(MOT)方法的标注负担。不幸的是,它们缺少两个关键属性:对象通常被分成几部分,并且不会随着时间的推移被一致地跟踪。事实上,最先进的模型通过依赖于监督对象检测和额外的ID标签,实现了像素级的准确性和时间一致性。本文提出了一种以视频对象为中心的MOT模型。它包括一个将以对象为中心的插槽调整为检测输出的索引合并模块和一个对象内存模块,该模块构建完整的对象原型来处理遮挡。受益于以对象为中心的学习,我们只需要稀疏检测标签(0%-6.25%)来进行对象定位和特征绑定。依赖于我们的自我监督的期望-最大化启发的对象关联损失,我们的方法不需要ID标签。我们的实验显著地缩小了现有的以对象为中心的模型和完全有监督的最先进状态之间的差距,并优于几个无监督的跟踪器。
2、方法
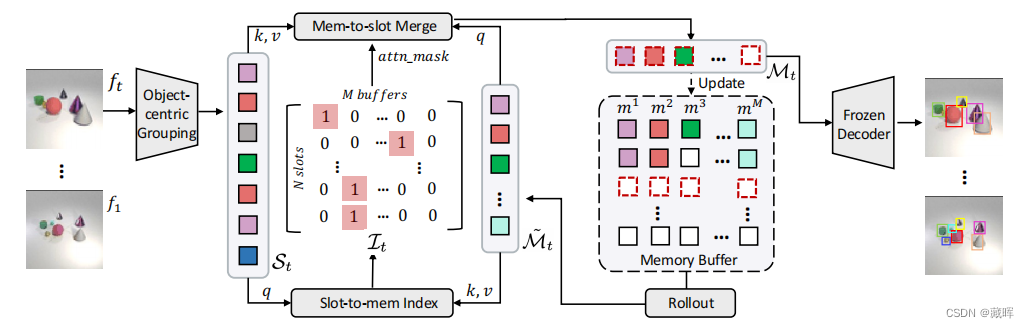
i) 一个索引合并模块,通过两个步骤将以对象为中心的插槽St调整为检测结果Mt。首先,通过一个可学习的索引矩阵将每个槽索引到内存缓冲区中,它指示所有的槽-存储分配。其次,通过重新计算被它向后掩盖的注意权重来合并分配给相同缓冲区的插槽。(简单来说就是在track query对应的位置学习或分配一个当前帧的detection/track结果)。
ii)一个对象内存模块,通过滚动对象关联的历史状态转发来提高时间一致性。对于MOT评估,我们通过以对象为中心的分组模块中的decoder将Mt解码为box或者mask。
不需要ID的原因是相同物体的相似性更高,可以通过卡阈值来获得匹配结果。
十九、TrajectoryFormer: 3D Object Tracking Transformer with Predictive Trajectory Hypotheses
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Chen_TrajectoryFormer_3D_Object_Tracking_Transformer_with_Predictive_Trajectory_Hypotheses_ICCV_2023_paper.pdf
github: https://github.com/poodarchu/EFG
1、摘要
3D多目标跟踪(MOT)对自动驾驶汽车和服务机器人等许多应用都至关重要。近年来,随着常用的检测跟踪模式,3D MOT取得了重要进展。然而,这些方法只使用当前帧的检测框来获得轨迹-框关联结果,这使得跟踪器不可能恢复被检测器遗漏的对象。在本文中,我们提出了一种新的基于点云的三维MOT框架。为了通过检测器恢复丢失的对象,我们使用混合候选框生成多个轨迹假设,包括时间预测框和当前帧检测框,用于轨迹-框关联。预测框可以将对象的历史轨迹信息传播到当前帧,因此网络可以容忍被跟踪对象的短期误检测。我们将长期物体运动特征和短期物体外观特征相结合,创建了每个假设的特征嵌入,从而减少了时空编码的计算开销。此外,我们引入了一个全局-局部交互模块来进行所有假设之间的信息交互,并建立它们的空间关系模型,从而得到对假设的准确估计。
2、方法
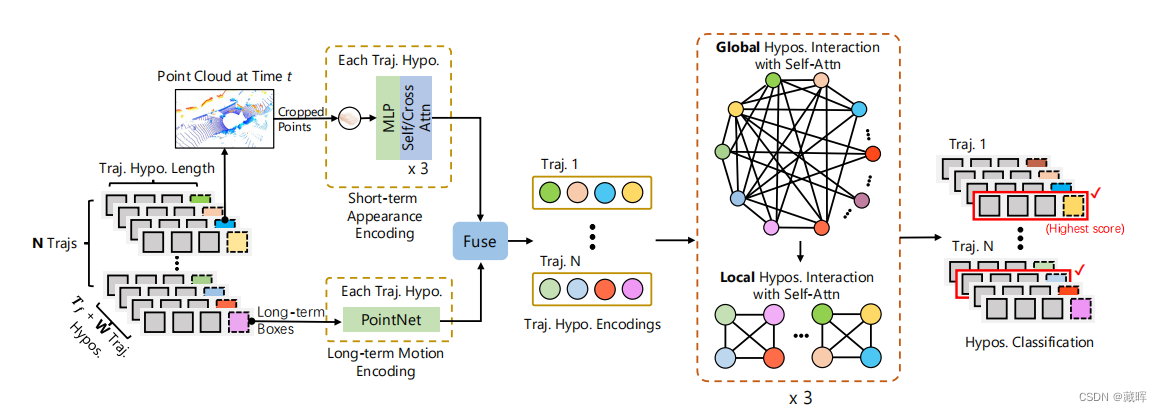
给定N个历史轨迹和输入点云,我们首先通过合并检测框W和时间预测框Tf,为每个历史轨迹生成多个轨迹假设。然后利用长-短假设特征编码模块对每个假设的外观和运动特征进行编码。
这些假设特征通过全局-局部假设交互模块进行进一步编码,从而在这些假设之间传播信息。最后,利用这些特征来预测每个假设的置信度,以选择最佳轨迹假设。
二十、MBPTrack: Improving 3D Point Cloud Tracking with Memory Networks and Box Priors
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Xu_MBPTrack_Improving_3D_Point_Cloud_Tracking_with_Memory_Networks_and_ICCV_2023_paper.pdf
1、摘要
几十年来,三维单目标跟踪一直是一个关键问题,如自动驾驶。尽管它的广泛使用,但由于跟踪目标之间的遮挡和大小差异造成了显著的外观差异,这项任务仍然具有挑战性。为了解决这些问题,我们提出了MBPTrack,它采用内存机制利用过去的信息,并利用第一帧给出的框先验以从粗到细的方案进行定位。具体来说,具有目标掩码的过去帧作为外部内存,并且基于转换器的模块将被跟踪的目标线索从内存传播到当前帧。为了精确定位各种大小的对象,MBPTrack首先通过霍夫投票预测目标中心。通过利用第一帧中给出的框先验,我们自适应地采样目标中心周围的参考点,它大致覆盖了不同大小的目标。然后,我们通过将点特征聚合到参考点中,得到密集的特征图,从而更有效地进行定位。
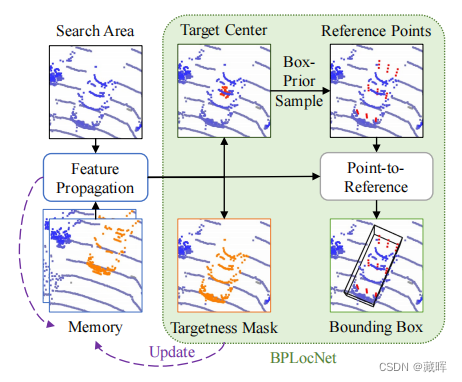
2、方法
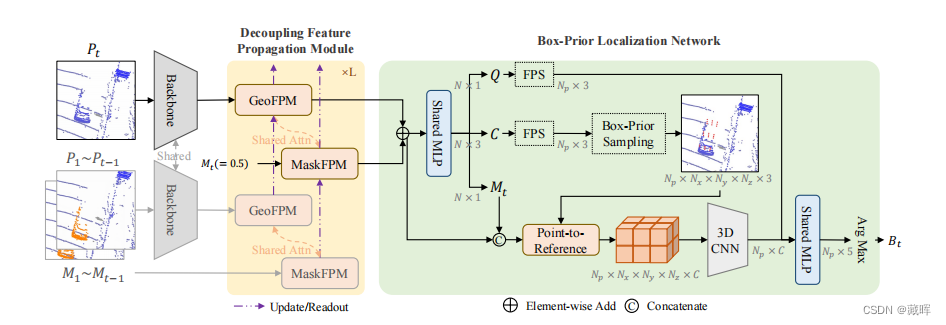
1、使用一个主干来提取几何特征。
2、过去的帧及其目标掩码作为外部内存,解耦特征传播模块(transformer模块)用于从历史帧中传播丰富的目标线索。
3、框先验定位网络:利用框先验来采样参考点,自适应地覆盖不同大小的目标,以进行精确定位。
二十一、Tracking Everything Everywhere All at Once
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Wang_Tracking_Everything_Everywhere_All_at_Once_ICCV_2023_paper.pdf
github: omnimotion.github.io
1、摘要
我们提出了一种新的测试时间优化方法来估计密集和远程运动的视频序列。先前的光流或粒子视频跟踪算法通常在有限的时间窗口内运行,努力通过遮挡进行跟踪,并保持估计的运动轨迹的全局一致性。我们提出了一个完整的和全局一致的运动表示,称为全动运动,它允许在一个视频中的每个像素的准确的,全长的运动估计。OmniMotion表示一个使用准三维规范卷的视频,并通过局部空间和规范空间之间的双射进行像素级跟踪。这种表示允许我们确保全局一致性,跟踪遮挡,并对相机和物体运动的任何组合进行建模。

🔺该方法是offline的,用了三维重建、nerf,和光流点提取等思路方法做到了tracking everypoint。
2、方法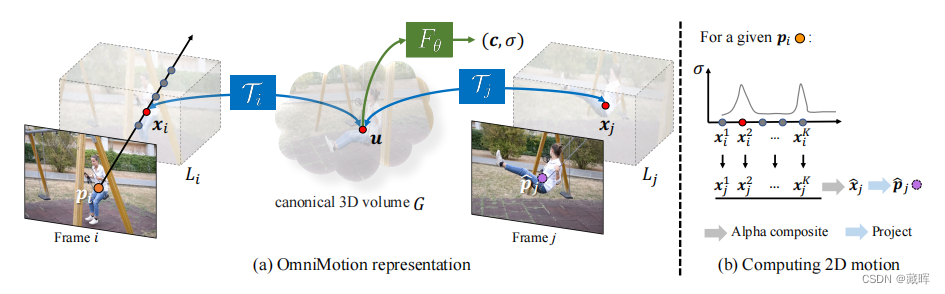
(a)我们的全方位表示是由一个规范的3d体积G和一组双射Ti映射之间的每一帧的本地卷李和规范卷G.任何本地3d位置xi帧我可以映射到相应的规范位置u通过Ti,然后映射回另一个帧jxj通过逆映射Tj−1。G中的每个位置u都与颜色c和密度σ相关联,使用基于坐标的MLP Fθ计算。
(b)计算相应的2d位置给定查询点皮映射从帧i到j,我们拍摄射线到样本一组点{x k i } K k=1,然后首先映射到规范空间获得密度,然后帧j计算相应的本地3d位置{x k j } K k=1。然后将这些点{xxkj}kk=1进行阿尔法合成并投影,得到二维对应的位置pˆj。
相当于offline学习了这一段视频中该物体的可运动三维表示,之前利用nerf查询的方式可以查询到每一帧相对于参考帧的点的位置。
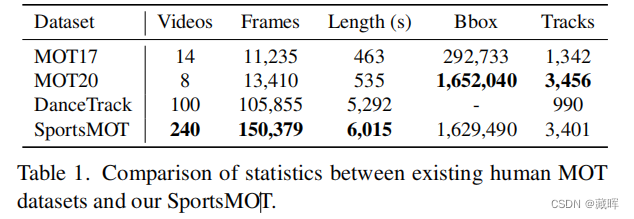
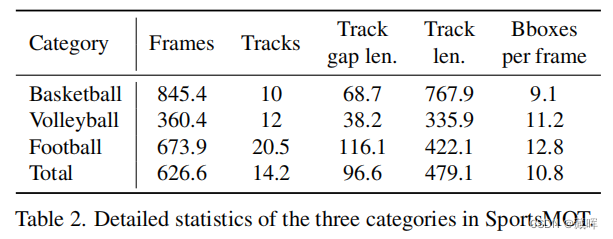
二十二、SportsMOT: A Large Multi-Object Tracking Dataset in Multiple Sports Scenes
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Cui_SportsMOT_A_Large_Multi-Object_Tracking_Dataset_in_Multiple_Sports_Scenes_ICCV_2023_paper.pdf
github: https://github.com/MCG-NJU/SportsMOT
1、摘要
体育场景中的多目标跟踪(MOT)在收集球员统计数据方面起着关键的作用,支持进一步的应用,如自动战术分析。然而,现有的MOT基准测试对这个领域很少引起关注。在这项工作中,我们提出了一个新的大规模多目标跟踪数据集在多个运动场景,称为SportsMOT,在球场上的所有球员都应该被跟踪。它由240个视频序列,超过150K帧(近15×MOT17)和超过16M边界框(3×MOT17),来自3个运动类别,包括篮球、排球和足球。我们的数据集有两个关键属性:1)快速和变速运动和2)相似但可区分的外观。我们希望SportsMOT鼓励MOT追踪器促进基于运动的联想和基于外观的联想。我们对几个最先进的跟踪器进行了基准测试,并揭示了SportsMOT的关键挑战在于对象关联。为了缓解这一问题,我们进一步提出了一种新的多目标跟踪框架,称为MixSort,引入一种混合格式结构作为辅助关联模型的检测跟踪跟踪器。通过将定制的基于外观的关联与原始的基于运动的关联相结合,MixSort在SportsMOT和MOT17上取得了最先进的性能。
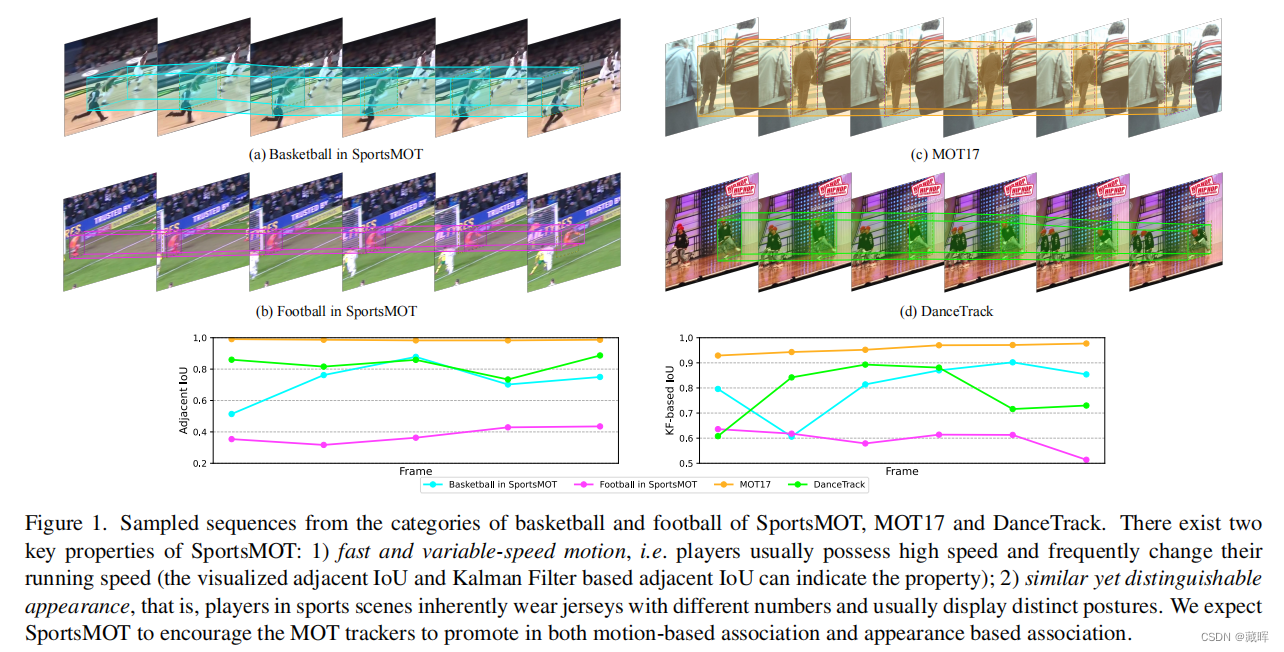
2、方法
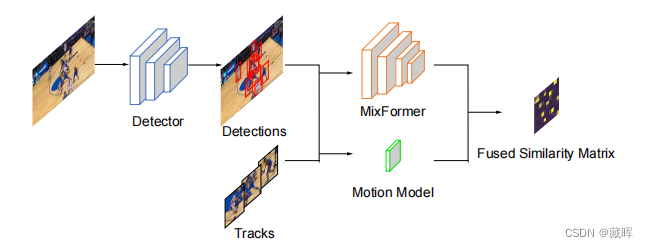
方法比较简单,用motion预测框做iou dist,再线性加权到外观的dist上。
二十三、Uncertainty-aware Unsupervised Multi-Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Liu_Uncertainty-aware_Unsupervised_Multi-Object_Tracking_ICCV_2023_paper.pdf
1、摘要
如果没有手动标注的身份,无监督的多对象跟踪器不如学习可靠的特征嵌入。它导致基于相似性的帧间关联阶段也容易出错,从而出现不确定性问题。逐帧累积的不确定性阻止了跟踪器学习针对时间变化的一致特征嵌入。为了避免这种不确定性问题,采用了最近的自我监督技术,而它们未能捕获时间关系。帧间的不确定性仍然存在。事实上,本文认为,虽然不确定性问题是不可避免的,但可以利用不确定性本身来提高学习的一致性。具体来说,开发了一个基于不确定性的度量标准来验证和纠正风险关联。由此得到的精确的伪轨迹提高了学习特征的一致性。精确的轨迹可以将时间信息纳入空间转换中。本文提出了一种轨迹引导的增强策略来模拟轨迹的运动,该策略采用基于分层不确定性的采样机制进行硬样本挖掘。
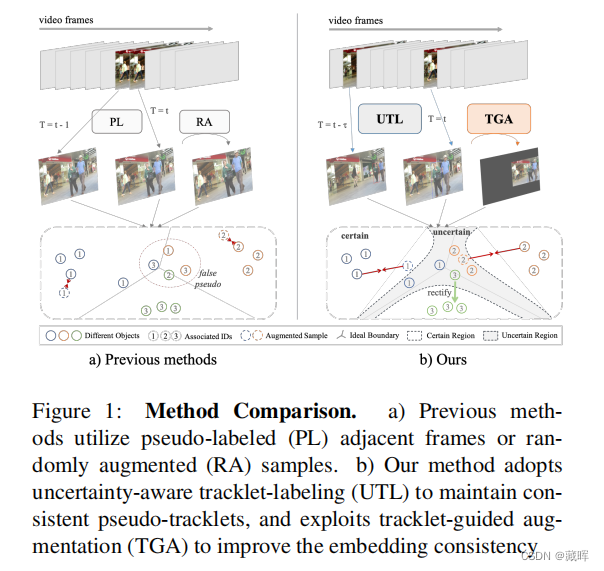
2、方法
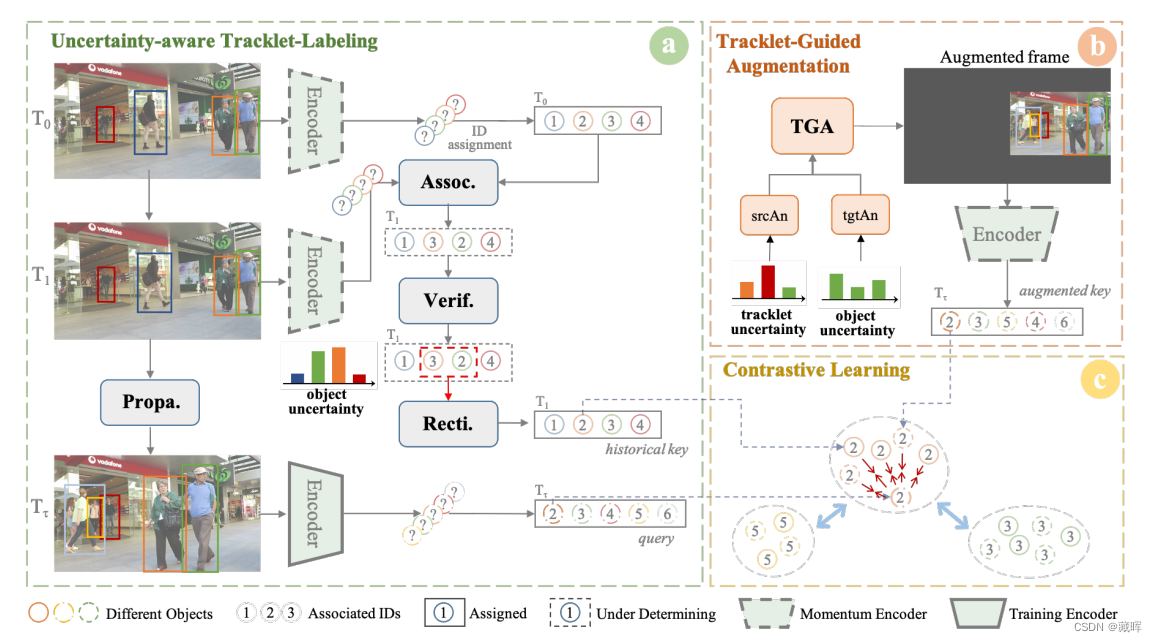
a) 我们提出了一个不确定度度量来验证和修正关联过程。精确的伪轨迹被逐帧传播。
b) 然后根据轨迹级和目标级的不确定性选择一个锚定对。轨迹的运动信息被用来指导增强(文中所指的纠正方式)。
c) 采用对比学习方法对跟踪器进行训练,将轨迹内的物体拉在一起,将不同的轨迹分开。
二十四、Adaptive and Background-Aware Vision Transformer for Real-Time UAV Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Li_Adaptive_and_Background-Aware_Vision_Transformer_for_Real-Time_UAV_Tracking_ICCV_2023_paper.pdf
github: https://github.com/xyyang317/Aba-ViTrack
1、摘要
基于判别相关滤波器(DCF)的跟踪器以其良好的效率在无人机跟踪中占优势,而基于滤波器剪枝的轻量级卷积神经网络(CNN)的跟踪器也表现出了显著的效率和精度。然而,使用纯视觉transformer(ViTs)进行无人机跟踪仍未被探索,这是一个令人惊讶的发现,因为ViTs已被证明比cnn产生更好的性能和更高的效率。在本文中,我们提出了一种有效的基于vit的跟踪框架,Aba-ViTrack,用于无人机跟踪。在我们的框架中,特征学习和模板-搜索耦合被集成到一个有效的单流ViT中,以避免一个额外的沉重的关系建模模块。所提出的Aba-ViT利用一种自适应和背景感知的Token计算方法来减少推理时间。该方法基于学习到的停止概率自适应地丢弃Token,而背景Token的停止概率先天高于目标停止概率。
2、方法
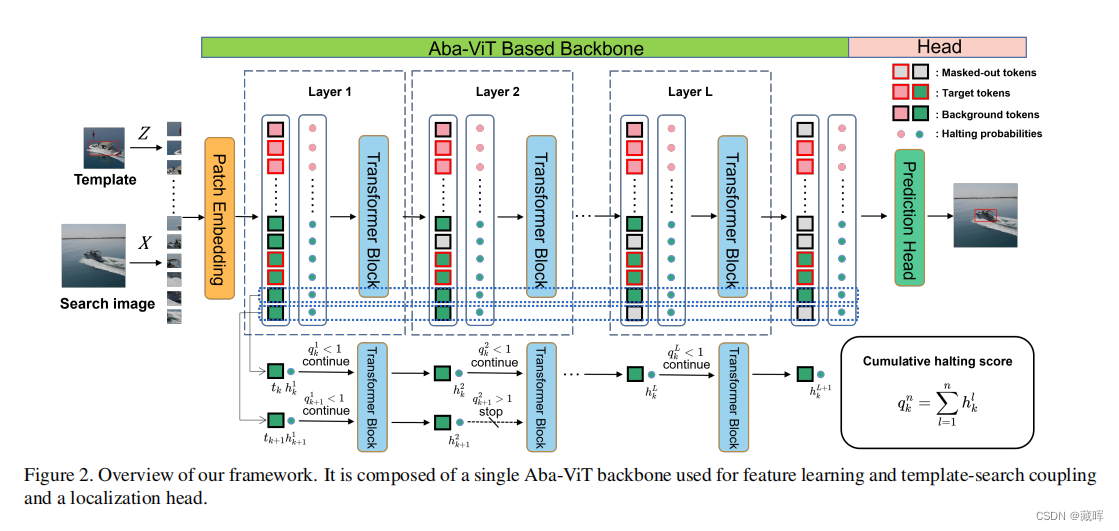
方法比较简单,差异点主要在token优化策略上。
二十五、Exploring Lightweight Hierarchical Vision Transformers for Efficient Visual Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Kang_Exploring_Lightweight_Hierarchical_Vision_Transformers_for_Efficient_Visual_Tracking_ICCV_2023_paper.pdf
github: https://github.com/kangben258/HiT
1、摘要
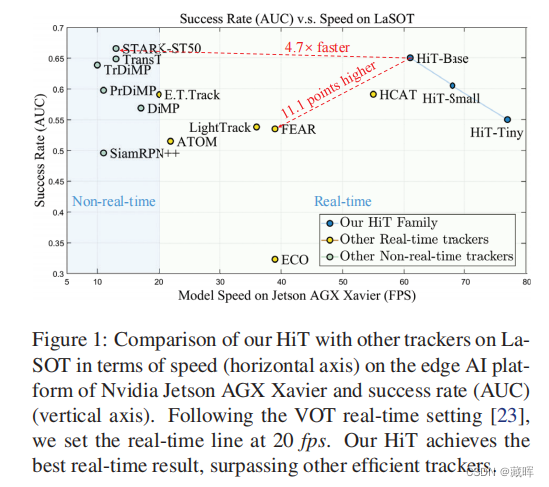
基于transformer的视觉跟踪器由于其优越的建模能力而取得了显著的进展。然而,现有的跟踪器受到低速的阻碍,限制了它们在计算能力有限的设备上的适用性。为了缓解这一问题,我们提出了HiT,一种新的高效跟踪模型家族,可以在不同的设备上高速运行,同时保持高性能。HiT的核心思想是桥接模块,它搭建了现代轻量化Transformer网络和跟踪框架之间的桥梁。桥接模块将深度特征的高级信息整合到浅层大分辨率特征中。这样,它就为跟踪头产生了更好的功能。我们还提出了一种新的双图像位置编码技术,它可以同时编码搜索区域和模板图像的位置信息。HiT模型取得了良好的速度和竞争的性能。例如,它在Nvidia Jetson AGX边缘设备上以每秒61帧(fps)的速度运行。
此外,HiT在LaSOT基准测试上达到了64.6%的AUC,超过了之前所有的高效跟踪器。
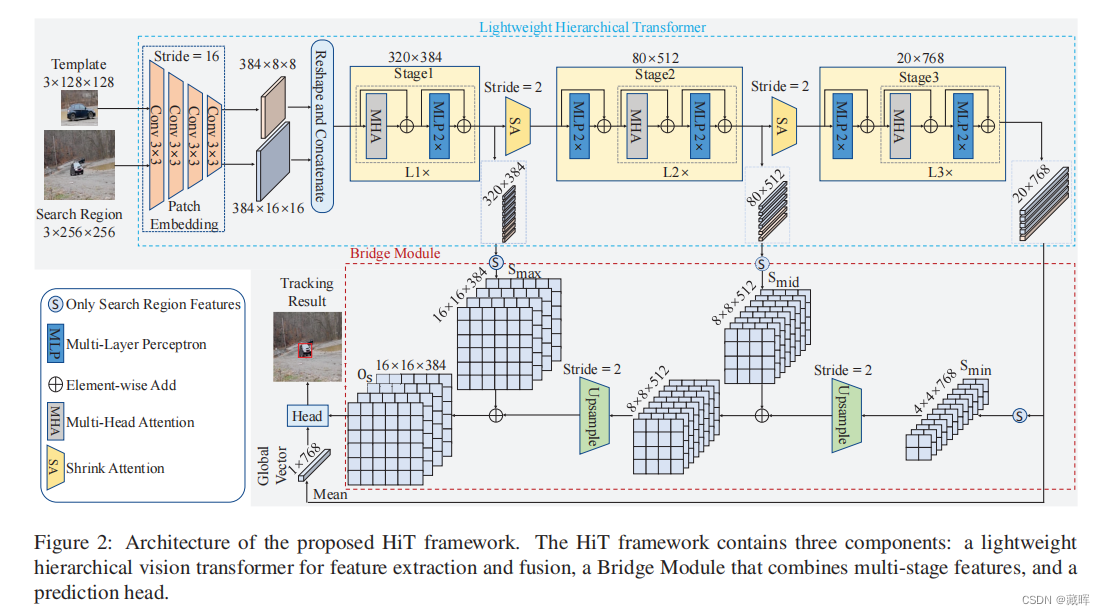
2、方法
二十六、DARTH: Holistic Test-time Adaptation for Multiple Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Segu_DARTH_Holistic_Test-time_Adaptation_for_Multiple_Object_Tracking_ICCV_2023_paper.pdf
github: https://www.vis.xyz/pub/darth
1、摘要
多目标跟踪(MOT)是自动驾驶感知系统的基本组成部分,其对不可见条件的鲁棒性是避免生命关键故障的必要条件。尽管驾驶系统需要安全,但还没有提出过解决MOT适应问题的方案。然而,MOT系统的本质是多方面的——需要对象检测和实例关联——并且调整它的所有组件都不是很简单。在本文中,我们分析了域转移对基于外观的跟踪器的影响,并介绍了MOT的整体测试时间自适应框架DARTH。我们提出了一种检测一致性公式,以自监督的方式来适应目标检测,同时通过我们的新补丁对比损失来适应实例外观表示。我们在各种领域的转移上评估了我们的方法——包括模拟模型、室外到室内、室内到室外——并在所有指标上大大提高了源模型的性能。
🔺MOT的外观特征跨域研究。
2、方法
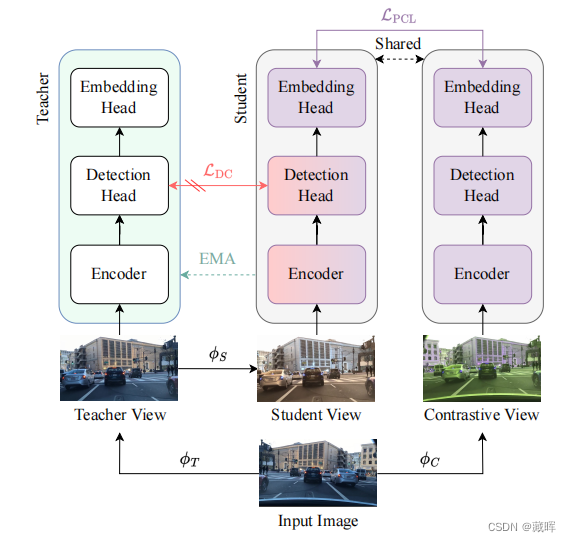
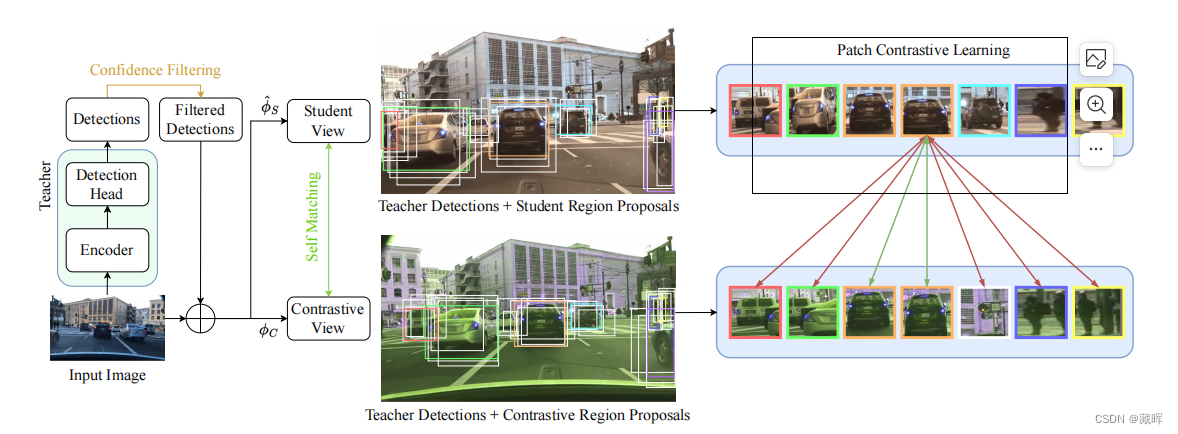
首先,通过teacher deteciton来进行检测识别,并选择高分框。
然后我们应用于输入图像和检测边界框转换ˆϕSϕC生成学生和对比视图,获得关联伪标签通过考虑匹配作为积极时提出区域(白色)在不同视图匹配相同的老师检测(识别相同的颜色在两个视图)。
最后,我们对通过student embedding head得到的所提区域的投影应用了多正斑块对比损失。我们在这里展示了一个正(绿色)和负(红色)匹配的区域。
二十七、Multiple Planar Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Zhang_Multiple_Planar_Object_Tracking_ICCV_2023_paper.pdf
github: https://zzcheng.top/MPOT
1、摘要
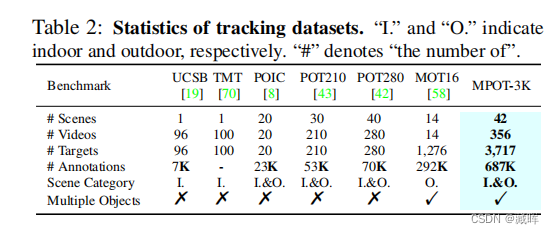
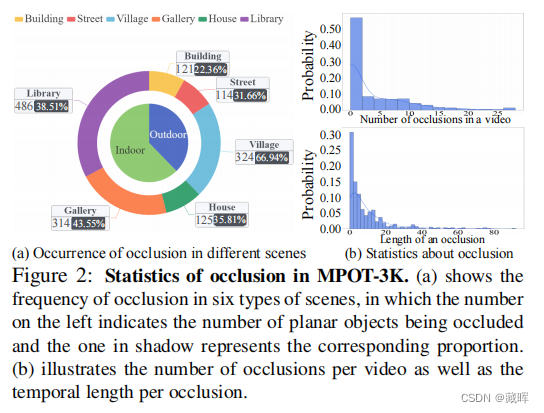
跟踪多个平面物体(MPOT)的位置和姿态对许多现实世界的应用具有重要意义。与普通物体相比,平面物体的自由度更大,这使得MPOT比研究充分的物体跟踪更具挑战性,特别是当遮挡发生时。为了解决这一具有挑战性的任务,我们受到了模态感知的启发,即人类共同跟踪目标的可见和不可见部分,并提出了一个统一外观感知和遮挡推理的跟踪框架。具体地说,我们提出了一个双分支网络来跟踪平面物体的可见部分,包括顶点和掩模。然后,我们开发了一种遮挡区域定位策略来推断不可见部分,即被遮挡区域,然后通过一个双流注意网络来最终细化预测。为了缓解该领域数据的缺乏,我们构建了第一个大规模的基准数据集,即MPOT-3K。它由356个视频中的3,717个平面物体组成,包含148,896帧和687,417个注释。收集到的平面物体有9种运动模式,视频在6种室内和室外场景中拍摄。大量的实验证明,我们提出的方法优于新开发的MPOT-3K以及其他两个流行的单平面目标跟踪数据集。
🔺平面跟随的数据集和相关tracking方法
2、方法
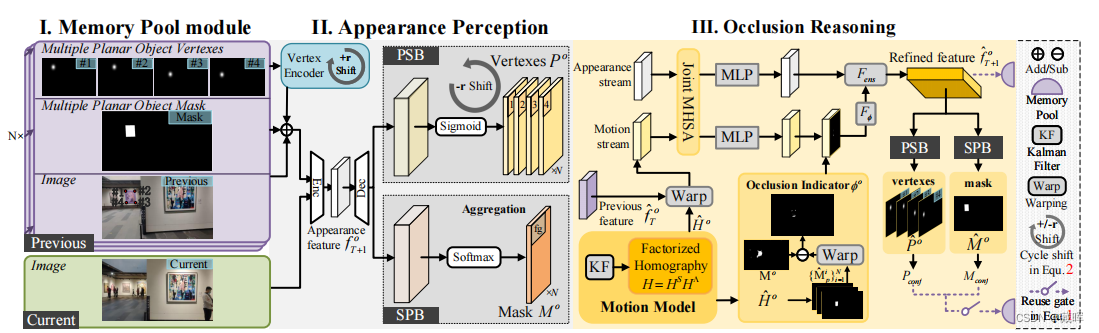
提出的方法如上图:
首先,在外观感知中,我们通过双分支网络跟踪多个平面物体的可见部分(图、mask、points),作为粗输出。
对于下一阶段的遮挡推理,将遮挡区域进行定位,然后输入一个双流自注意网络,以细化预测的目标(mask、points)。
最后,内存池模块恢复了高度自信的跟踪目标(将多种观测做融合,以预测准确的结果)。
二十八、End-to-end 3D Tracking with Decoupled Queries
paper:
https://openaccess.thecvf.com/content/ICCV2023/papers/Li_End-to-end_3D_Tracking_with_Decoupled_Queries_ICCV_2023_paper.pdf
github: https://sites.google.com/view/dqtrack
1、摘要
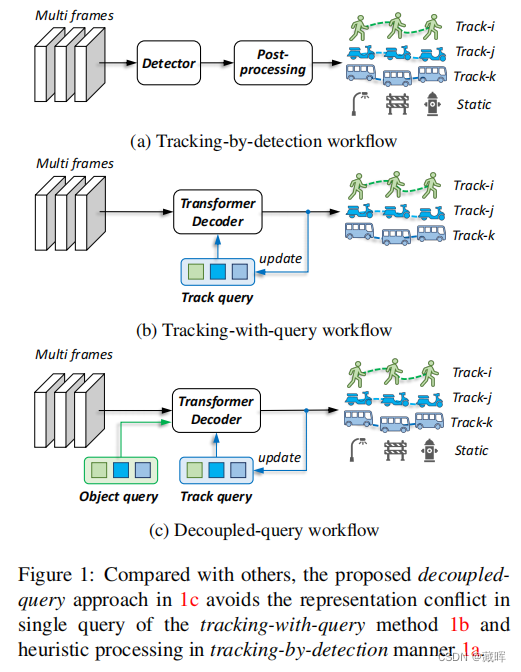
在这项工作中,我们提出了一个基于相机的三维多目标跟踪的端到端框架,称为DQTrack。为了避免基于检测的跟踪器中的启发式设计,最近的基于查询的方法处理了单一嵌入中的身份不可知的检测和身份感知跟踪。然而,由于其固有的表现冲突,它带来了较差的表现。为了解决这个问题,我们将单个嵌入解耦到单独的查询中,即对象查询和跟踪查询。与以前的基于检测和基于查询的方法不同,解耦-查询范式利用了特定于任务的查询,并且仍然维护了紧凑框架,而不需要进行复杂的后处理。此外,可学习关联和时间更新分别提供可区分的轨迹关联和帧帧查询更新。所提出的DQTrack在各种基准测试中实现了一致的收益,优于以前在nuScenes数据集上的基于检测跟踪和基于学习的方法。
2、方法
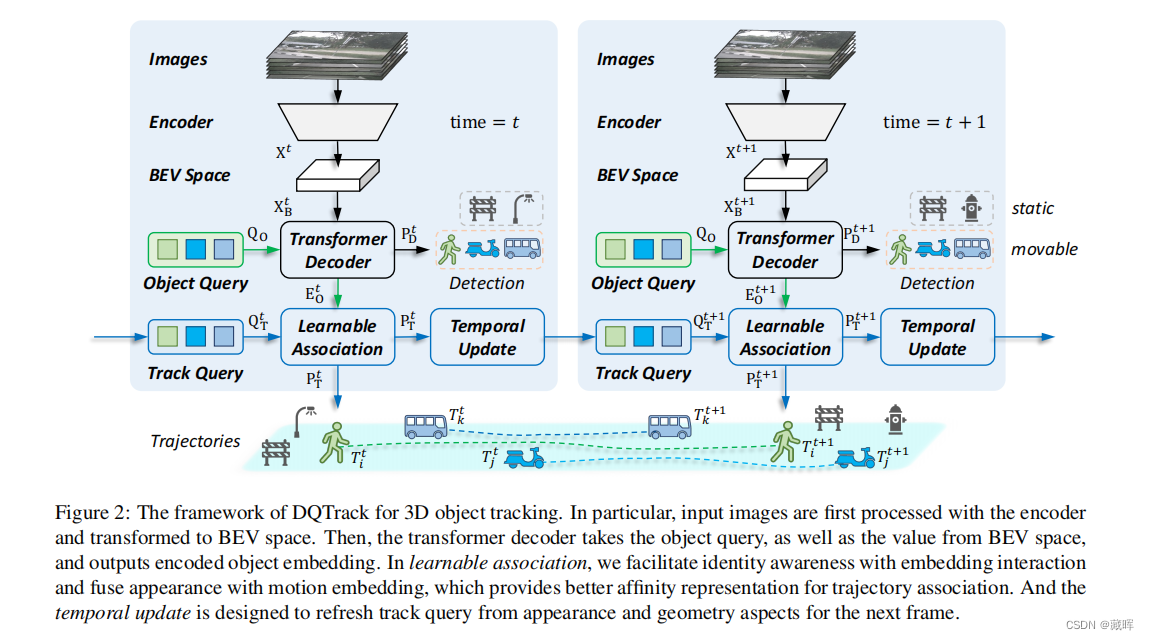
思路与MOTR类似,延展到了BEV类场景。
二十九、360VOT: A New Benchmark Dataset for Omnidirectional Visual Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Huang_360VOT_A_New_Benchmark_Dataset_for_Omnidirectional_Visual_Object_Tracking_ICCV_2023_paper.pdf
github: https://360vot.hkustvgd.com
1、摘要
360◦图像可以提供一个全方位的视野,这对稳定和长期的场景感知非常重要。在本文中,我们探索了360◦图像的视觉目标跟踪,并感知了360◦图像的大失真、拼接伪影等独特属性所带来的新挑战。为了缓解这些问题,我们利用了新的目标定位表示,即边界视场,然后引入了一个通用的360跟踪框架,可以采用典型的跟踪器进行全向跟踪。更重要的是,我们提出了一个新的大规模全向跟踪基准数据集,360VOT,以促进未来的研究。360VOT包含120个序列,在等矩形投影中具有高达113K的高分辨率帧。跟踪目标涵盖32个类别。跟踪目标涵盖了不同场景下的32个类别。此外,我们提供了4种类型的无偏真值,包括(旋转)边界框和(旋转)边界视场,以及为360◦图像定制的新度量,允许准确评估全向跟踪性能。最后,我们广泛地评估了20个最先进的视觉跟踪器,并为未来的比较提供了一个新的基线。
🔺针对于全景输入图的tracking方法 dateset以及详细的评测标注。
2、方法
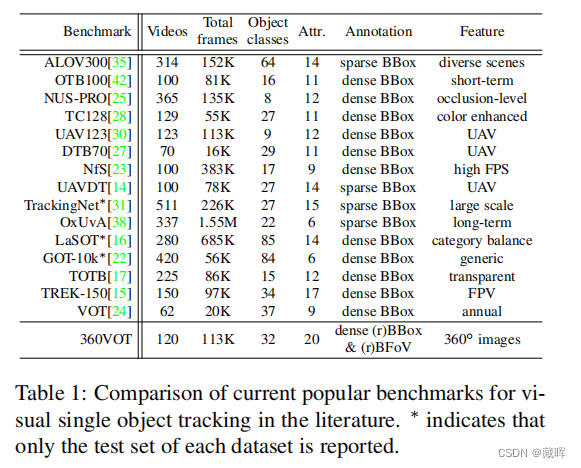

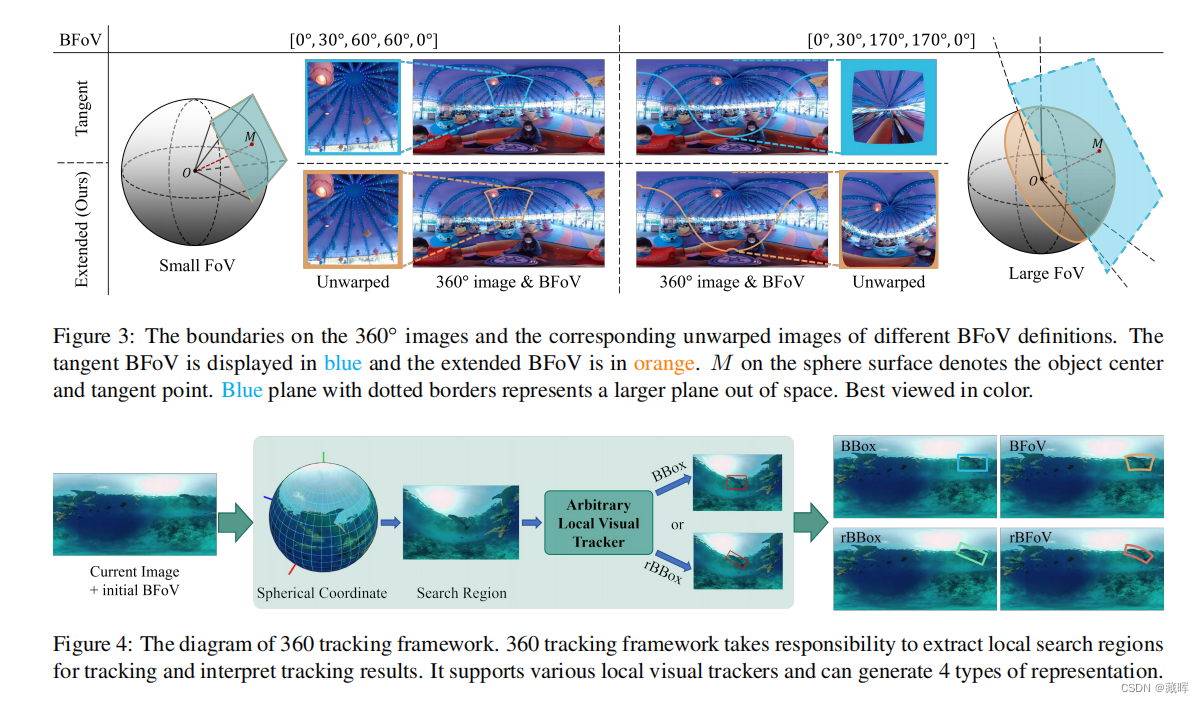
三十、Tracking without Label: Unsupervised Multiple Object Tracking via Contrastive Similarity Learning
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Meng_Tracking_without_Label_Unsupervised_Multiple_Object_Tracking_via_Contrastive_Similarity_ICCV_2023_paper.pdf
github: https://deepmind-tapir.github.io
1、摘要
由于缺乏标签,无监督学习是一项具有挑战性的任务。多目标跟踪(MOT),不可避免地存在目标相互干扰、遮挡等问题,在没有标签的监督的情况下跟随会变得更加困难。在本文中,我们探讨了视频帧间样本特征的潜在一致性,并提出了一种无监督对比相似度学习方法,名为UCSL,包括三个对比模块:自我对比,交叉对比,和歧义对比。具体来说,i)自对比使用帧内直接对比和帧间间接对比,通过最大化自相似性来获得判别表示。ii)交叉对比度对齐交叉帧和连续帧匹配的结果,减轻了物体遮挡造成的持续负面影响。iii)模糊对比将模糊对象相互匹配,通过隐式方式进一步增加后续对象关联的确定性。在现有的基准测试中,我们的方法比现有的无监督方法的性能更好,甚至提供了比许多完全监督的方法更高的精度。
🔺用了一种比较巧妙的外观监督方式,可以无监督的促进自身的一致性并拉开与其他目标的差异。
2、方法
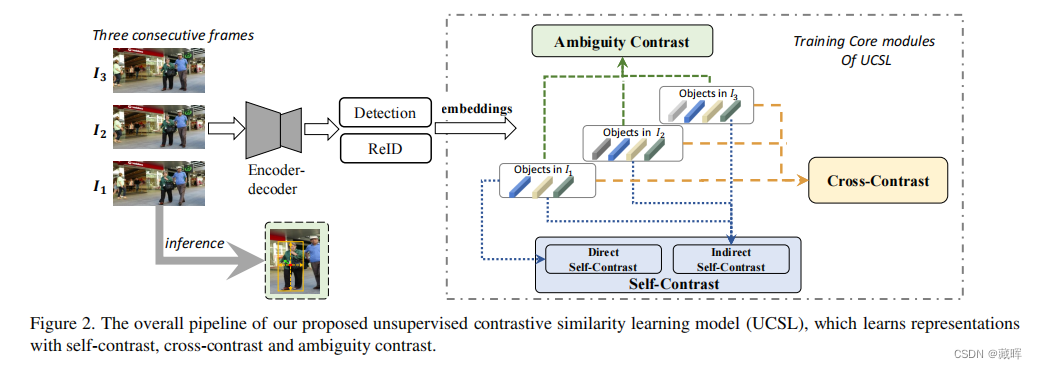
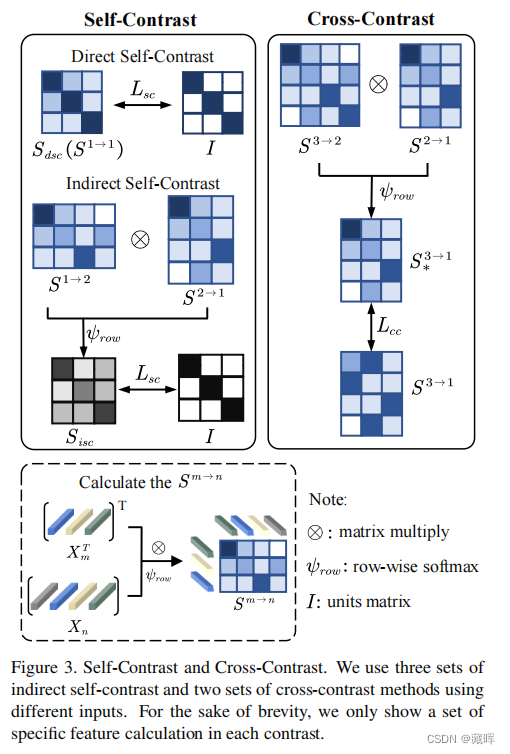
1、self-contrast的作法比较好理解,通过算第一帧和第二帧之间的embedding dist构成匹配矩阵,再计算匹配矩阵与其转置的乘积,获得一个当前帧自己和自己的匹配结果,做监督。变相的监督了自己的特征,同时拉开了其他目标外观特征的距离。
2、cross-contrast的作法是把1-2,2-3的矩阵相乘,然后和1-3的矩阵做loss。作者的目的是为了让embedding的连续帧匹配更稳定,鲁棒性更强。
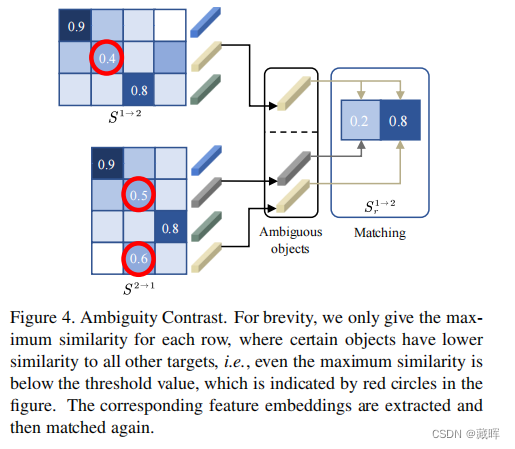
3、Ambiguity contrast是对某些没有匹配结果的对象做再处理。即即使最大相似度也低于阈值,在图中用红色圆圈表示。提取相应的特征嵌入,然后再次进行匹配。
三十一、TEMPO: Efficient Multi-View Pose Estimation, Tracking, and Forecasting
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Choudhury_TEMPO_Efficient_Multi-View_Pose_Estimation_Tracking_and_Forecasting_ICCV_2023_paper.pdf
github: https://rccchoudhury.github.io/tempo2023/
1、摘要
现有的预测三维人体姿态估计的体积方法是准确的,但计算成本昂贵,且需要对单个时间步长预测进行了优化。我们提出了一种有效的多视点姿态估计模型,学习一个鲁棒的时空表示,提高姿态精度,同时也跟踪和预测人的姿态。通过递归计算个人二维姿态特征,将空间和时间信息融合成单一表示,与最先进的技术相比,我们显著减少了计算量。在此过程中,我们的模型能够使用时空上下文来预测更准确的人体姿态,而不牺牲效率。我们进一步使用这种表示来跟踪人类随时间推移的姿势,以及预测未来的姿势。最后,我们证明了我们的模型能够在数据集之间泛化,而无需特定于场景的微调。

🔺可以同时tracking和出多目标pose。
2、方法
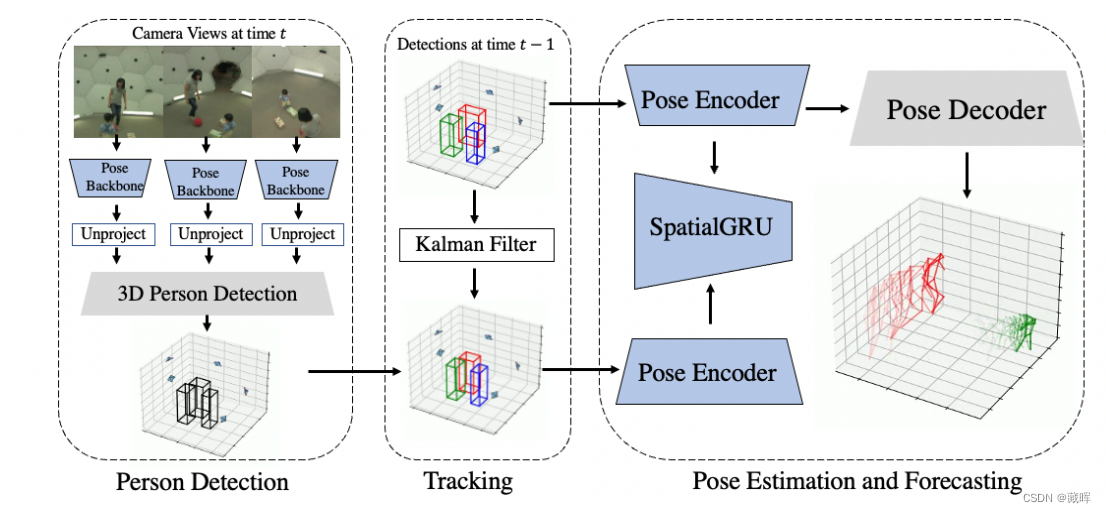
整体模型体系结构。
(1)从具有主干网络的每幅图像中提取特征,并将这些特征不投影到一个三维体中。
(2)我们使用体积来检测场景中的每个人。
(3)做时序上的关联(卡尔曼+iou)。
(4)将每个人的特征与我们的时间模型相融合,并产生一个最终的姿态估计。
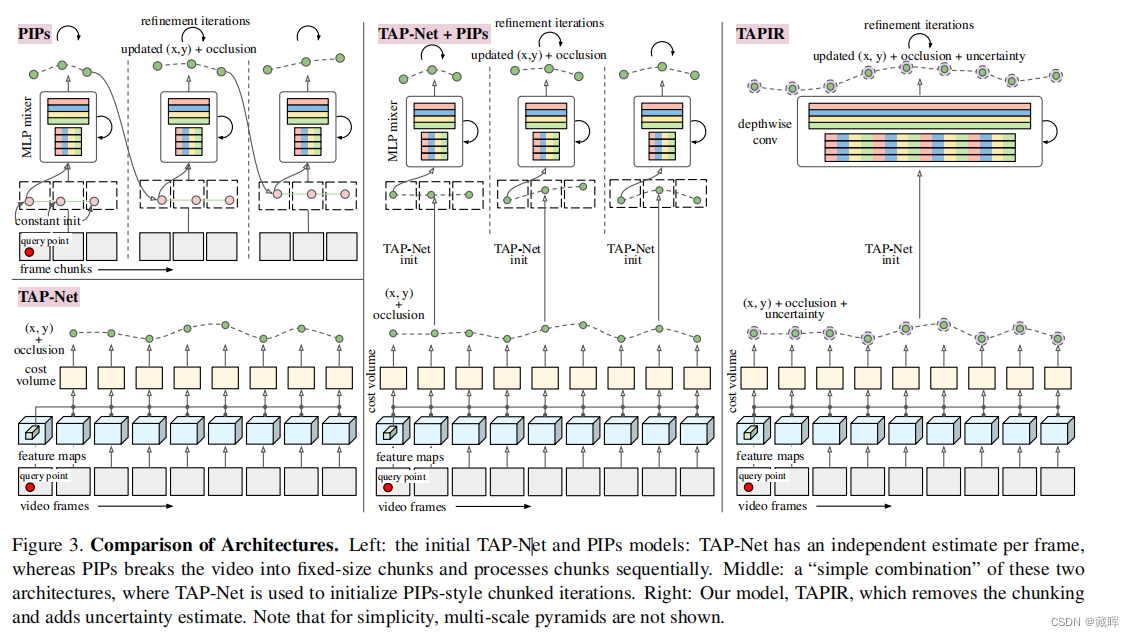
三十二、TAPIR: Tracking Any Point with Per-Frame Initialization and Temporal Refinement
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Doersch_TAPIR_Tracking_Any_Point_with_Per-Frame_Initialization_and_Temporal_Refinement_ICCV_2023_paper.pdf
1、摘要
我们提出了一种新的模型来跟踪任何点(TAP),它可以有效地跟踪整个视频序列中任何物理表面上的任何查询点。我们的方法包括两个阶段:(1) 一个匹配阶段,它在每一帧上为查询点定位合适的候选点匹配; (2) 一个细化阶段,它基于局部相关性同时更新轨迹和查询特征。在TAP-Vid基准上,结果模型显著超过了所有基线方法。我们的模型便于对长时间和高分辨率的视频序列的快速推断。在现代GPU上,我们的实现能够比实时更快地跟踪点。鉴于从一个大数据集中提取的高质量轨迹,我们演示了一个概念验证扩散模型,该模型从静态图像中生成轨迹,使合理的动画成为可能。
2、方法
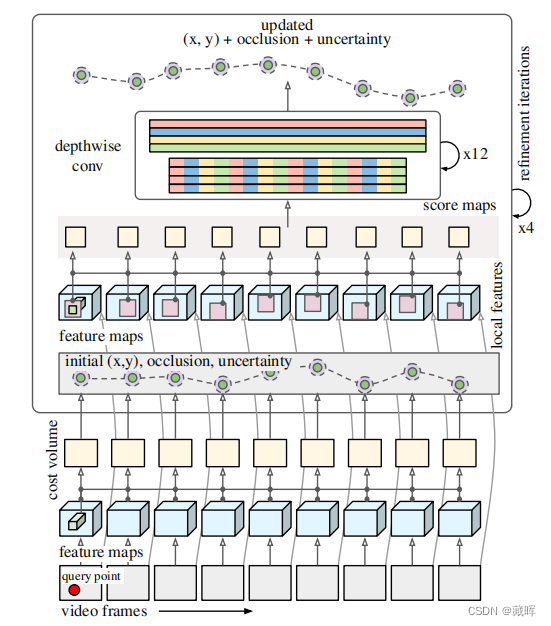
我们的模型首先对查询点特征和其他每一帧的特征进行全局比较,以计算初始轨迹估计,包括不确定性估计。
然后,我们从初始估计附近的局部邻域(粉红色)中提取特征,并将这些特征与更高分辨率的查询特征进行比较,用时间深度卷积网络对相似性进行后处理,得到更新的位置估计。
这个更新的位置被反馈到下一次细化迭代中,重复固定的迭代次数,以得到最终的结果。和先前方法的差异见下图。
三十三、Tracking by Natural Language Specification with Long Short-term Context Decoupling
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Ma_Tracking_by_Natural_Language_Specification_with_Long_Short-term_Context_Decoupling_ICCV_2023_paper.pdf
1、摘要
自然语言规范(TNL)跟踪的主要挑战是通过提供两个异构信息来预测目标对象的移动,例如,一个是对文本查询中包含的视频的主要特征的静态描述,即长期上下文;另一个是包含从当前帧中裁剪到的对象及其周围环境的图像补丁,即搜索区域。目前,大多数方法仍然在努力争取使用这两种信息和简单地融合两者的合理性。但是,文本查询中所包含的语言信息和存储在搜索区域中的视觉表示有时可能不一致,在这种情况下,两者的直接融合可能会导致冲突。为了解决这个问题,我们提出了DecoupleTNL,将一个包含短期上下文信息的视频剪辑引入TNL的框架,并探索一种减少视觉表示与语言信息不一致时影响的适当方法。具体来说,我们设计了两个联合优化的任务,即短期情境匹配和长期情境感知。上下文匹配任务的目的是在一个时期内收集动态的短期上下文信息,而上下文感知任务则倾向于提取静态的长期上下文信息。之后,我们设计了一个长期的短期调制模块来集成这两种上下文信息,以实现精确的跟踪。
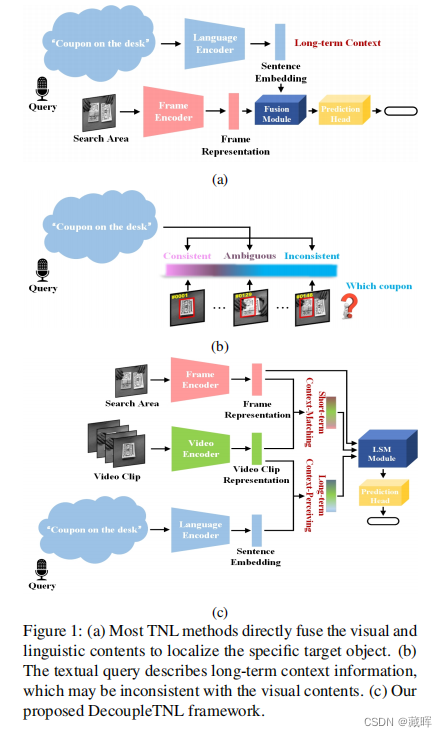
2、方法
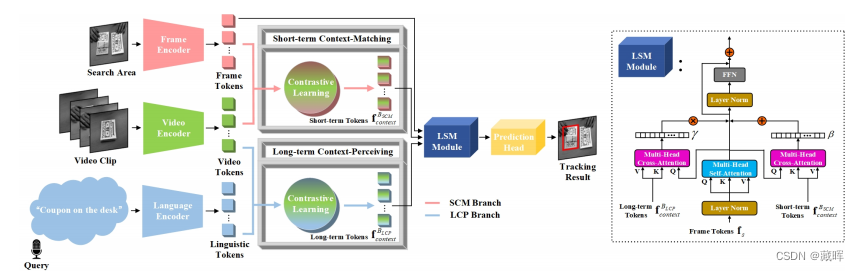
该跟踪框架中有三个特征编码器分别用于提取帧、视频和语言标记。然后,我们设计了短期上下文匹配(SCM)分支和长期上下文感知(LCP)分支,通过短期上下文匹配任务和长期上下文感知任务收集有意义的长期短期上下文信息。之后,我们通过一个长期短期调制(LSM)模块将帧标记和学习到的长期短期标记表示关联起来。最后,预测head输出目标定位结果。
三十四、Synchronize Feature Extracting and Matching: A Single Branch Framework for 3D Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Ma_Synchronize_Feature_Extracting_and_Matching_A_Single_Branch_Framework_for_ICCV_2023_paper.pdf
1、摘要
暹罗网络实际上是三维激光雷达目标跟踪的基准框架,通过共享参数编码器分别从模板和搜索区域提取特征。这个范式在很大程度上依赖于一个额外的匹配网络来建模模板和搜索区域的互相关/相似性。在本文中,我们放弃了传统的暹罗范式,提出了一种新的单分支框架SyncTrack,同步特征提取和匹配,以避免对模板和搜索区域两次转发编码器,并引入额外的匹配网络参数。该同步机制是基于Transformer的动态亲和性,并对其相关性进行了深入的理论分析。此外,在同步化的基础上,我们在Transformer层(APST)中引入了一种新的注意点采样策略,在模板和搜索区域之间的注意关系的监督下,用采样代替随机/最远点采样(FPS)方法。它意味着将点采样与特征学习联系起来,有利于聚集更独特的几何特征,用稀疏点进行跟踪。
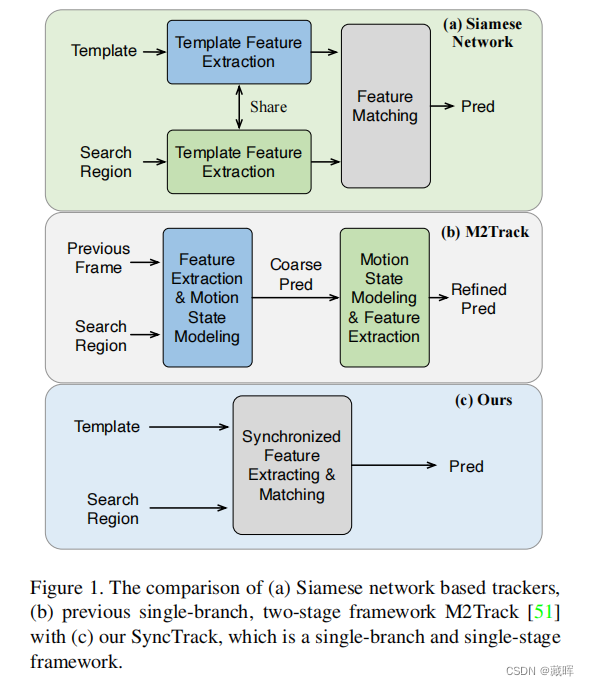
2、方法
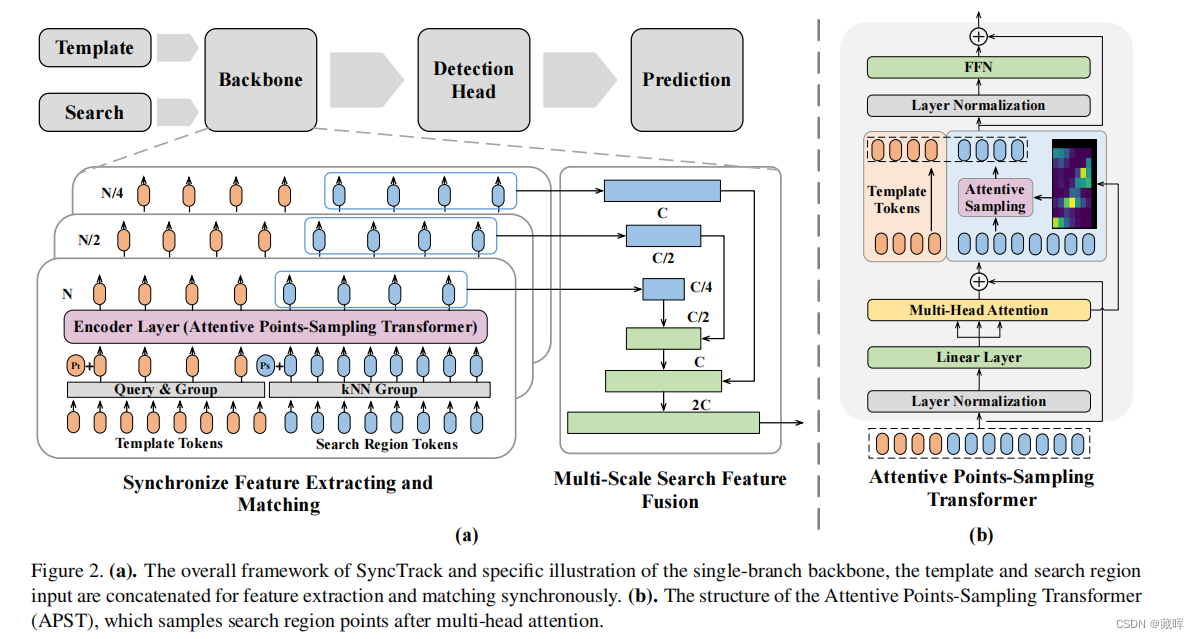
直接用了transformer网络做了点云的SOT。
三十五、PlanarTrack: A Large-scale Challenging Benchmark for Planar Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Liu_PlanarTrack_A_Large-scale_Challenging_Benchmark_for_Planar_Object_Tracking_ICCV_2023_paper.pdf
github: https://hengfan2010.github.io/projects/PlanarTrack/
1、摘要
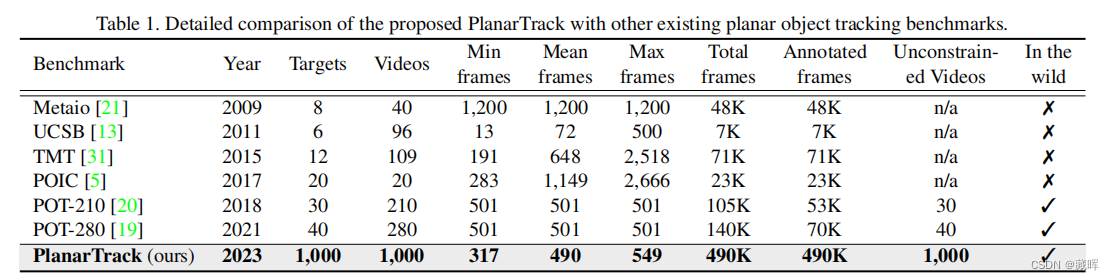
平面物体跟踪是一个关键的计算机视觉问题,由于其在机器人、增强现实等领域的关键作用而引起人们的关注。尽管进展迅速,但由于缺乏大规模的具有挑战性的基准测试,它的进一步发展,特别是在深度学习时代,在很大程度上受到了阻碍。为了解决这个问题,我们引入了平面跟踪,一个具有挑战性的大规模平面跟踪基准。具体来说,planar轨道由1000个视频和超过49万张图像组成。所有这些序列都是在复杂的无约束场景中收集的,这使得与现有的基准测试相比,PlanarTrack更具有挑战性,但对于现实应用来说更现实。为了保证高质量的标注,平面轨迹中的每一帧都采用四个角手工标注,并进行了多轮的仔细检查和细化。据我们所知,迄今为止PlanarTrack是专门致力于平面物体跟踪的最大和最具挑战性的数据集。为了分析所提出的平面轨迹,我们对10个平面跟踪器进行了评估,并进行了综合比较和深入分析。我们的结果,并不奇怪,表明目前表现最好的平面跟踪器在具有挑战性的平面跟踪上显著退化,未来需要更多的努力来改进平面跟踪。此外,我们进一步从我们的平面跟踪中推导了一个名为PlanarTrackBB的变体,用于跟踪的通用对象。我们对PlanarTrackBB上的10个优秀的通用跟踪器的评估表明,令人惊讶的是,PlanarTrackBB甚至比几个流行的通用跟踪基准更具有挑战性,应该更加注意处理这样的平面对象,尽管它们是刚性的。
🔺也是一篇平面跟随dataset的paper。
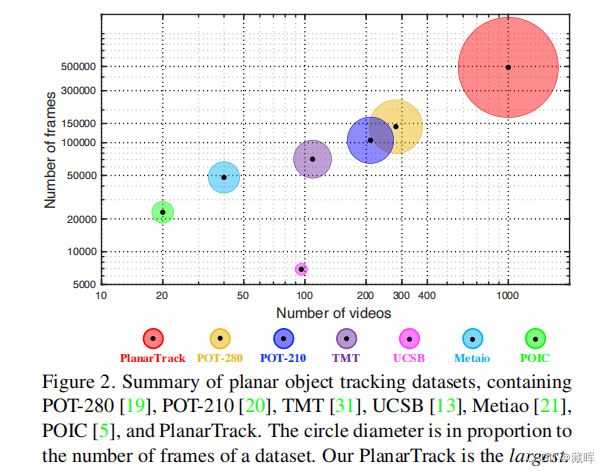
2、方法

三十六、Collaborative Tracking Learning for Frame-Rate-Insensitive Multi-Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Liu_Collaborative_Tracking_Learning_for_Frame-Rate-Insensitive_Multi-Object_Tracking_ICCV_2023_paper.pdf
github: https://github.com/yolomax/ColTrack
1、摘要
低帧率下的多目标跟踪(MOT)可以减少计算、存储和功率开销,以更好地满足边缘设备的约束。由于许多现有的MOT方法在低帧率视频之间的显著位置和外观变化,存在显著的性能下降。为此,我们提出以基于查询的端到端方式探索帧率不敏感MOT的协作跟踪学习(ColTrack)。同一目标的多个历史查询使用更丰富的时间描述共同跟踪它。同时,我们在每两个时间阻塞解码器之间插入一个信息细化模块,以更好地融合时间线索和细化特征。此外,还提出了一种跟踪对象一致性损失的方法来指导历史查询之间的交互。大量的实验结果表明,在高帧率视频中,ColTrack在大规模数据集和BDD100K上获得比先进方法获得更高的性能,并且在MOT17上优于现有的端到端方法。更重要的是,ColTrack在低帧率视频中比最先进的方法具有显著的优势,这允许它通过降低帧率要求的同时保持更高的性能,从而获得更快的处理速度。
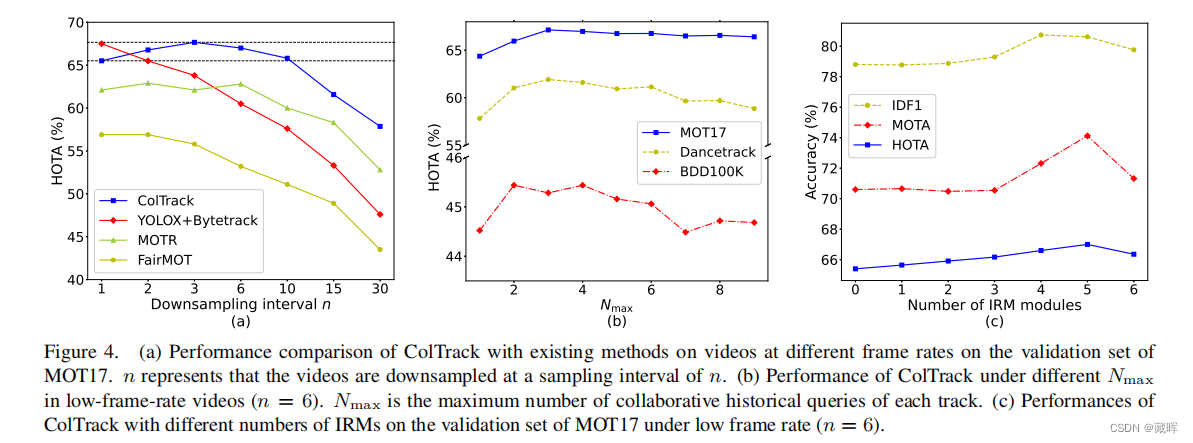
🔺该方法低帧率下tracking效果依然很好。
2、方法
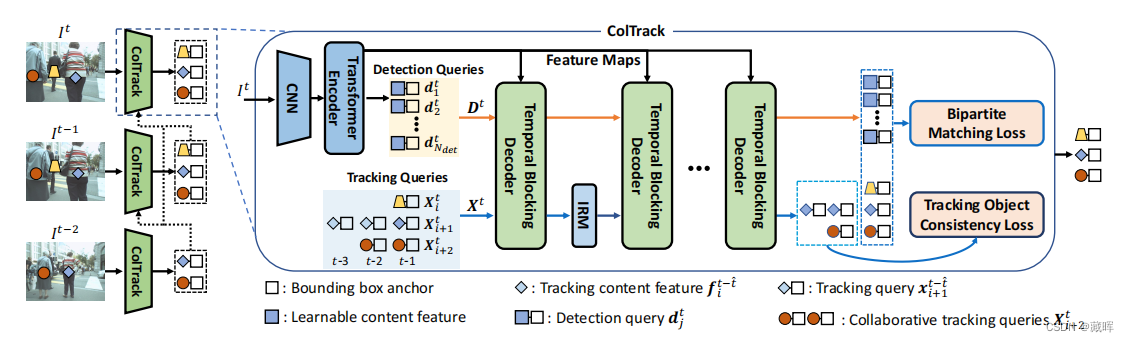
转换器编码器提供图像特征映射和新兴对象的检测查询。每个被跟踪对象的多个历史查询构成了其对其进行联合跟踪的协同跟踪查询。组合后的查询被输入多个时间阻塞解码器,迭代以细化预测。在每两个解码器之间插入一个信息细化模块(IRM),用于属于同一目标的协同跟踪查询,以集成时间线索并细化其自身。跟踪对象一致性损失指导对历史查询到相应目标的一致跟踪(类似MOTRv3/co-mot的思路,此外,Tracking Object Consistency Loss考虑了多帧到当前帧的传播并做监督,实现对帧率不敏感)。
三十七、Deep Active Contours for Real-time 6-DoF Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Wang_Deep_Active_Contours_for_Real-time_6-DoF_Object_Tracking_ICCV_2023_paper.pdf
github: https://zju3dv.github.io/deep_ac/
1、摘要
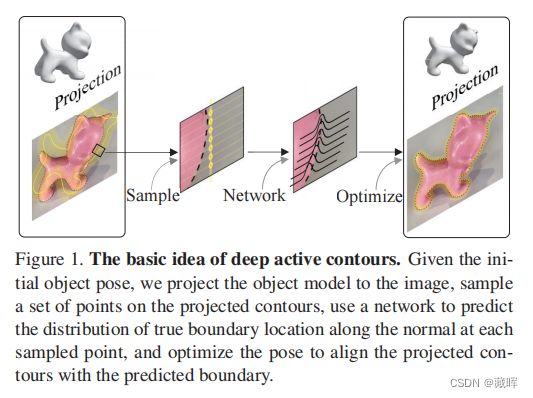
本文解决了RGB视频中实时6自由度目标跟踪的问题。先前的基于优化的方法通过基于手工特征将投影模型与图像对齐来优化对象姿态,这容易出现次优解。最近的基于学习的方法使用神经网络来预测姿态,其通用性或计算效率有限。我们提出了一个基于学习的主动轮廓模型,以充分利用这两个世界。具体来说,给定一个初始姿态,我们将目标模型投影到图像平面上,以获得初始轮廓,并使用一个轻量级网络来预测轮廓应该如何移动,以匹配真实的物体边界,从而提供了优化物体姿态的梯度。我们还设计了一个有效的优化算法来训练我们的模型端到端与姿态监督。在半合成和真实世界的6自由度目标跟踪数据集上的实验结果表明,我们的模型在姿态精度上大大优于最先进的方法,同时在移动设备上实现了实时性能。
2、方法
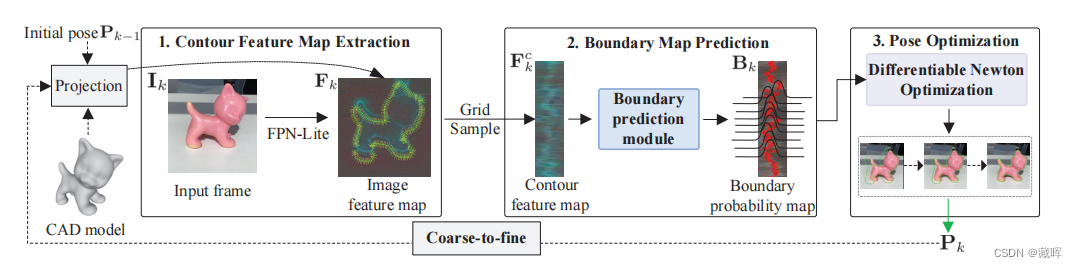
1.该方法利用FPN-Lite CNN提取当前裁剪帧Ik的多层特征Fk,并通过对应线模型表示轮廓的局部区域。(第3.2节)。
2.通过在图像特征图上采样一个循环的对应线,然后使用预测边界位置概率Bk的边界预测模块(第3.3节),构建等高线特征图Fc k。
3.使用可微分优化层,以从粗到细的方式估计姿态Pk(第3.4节)。
三十八、CiteTracker: Correlating Image and Text for Visual Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Li_CiteTracker_Correlating_Image_and_Text_for_Visual_Tracking_ICCV_2023_paper.pdf
github: https: //github.com/NorahGreen/CiteTracker
1、摘要
现有的视觉跟踪方法通常以一个图像补丁作为目标的参考来进行跟踪。然而,一个单一的图像补丁不能提供一个完整和精确的目标对象的概念,因为图像的抽象能力有限,而且可能很模糊,这使得很难跟踪具有剧烈变化的目标。在本文中,我们提出了 CiteTracker,通过连接图像和文本来增强视觉跟踪中的目标建模和推理。具体来说,我们开发了一个文本生成模块,将目标图像补丁转换为包含其类和属性信息的描述性文本,为目标提供了一个全面的参考点。此外,还设计了一个动态描述模块来适应目标的变化,以实现更有效的目标表示。然后,我们使用一个基于注意力的相关模块将目标描述和搜索图像关联起来,以生成可供目标状态参考的相关特征。在5个不同的数据集上进行了广泛的实验,以评估所提出的算法,其良好的性能证明了所提出的跟踪方法的有效性。
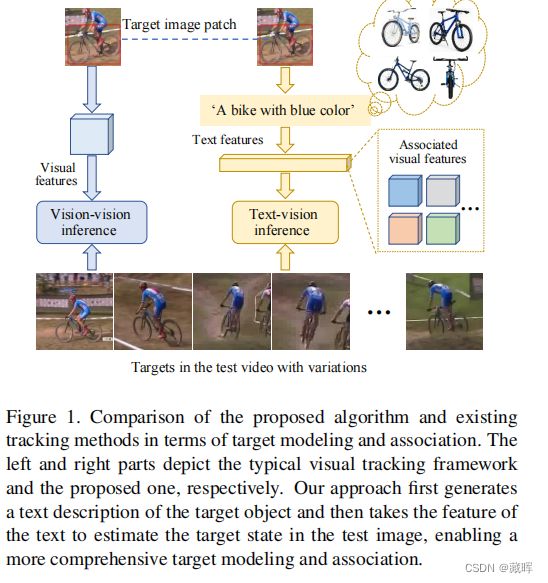
🔺抽象成文字的高阶语义tracking。
2、方法
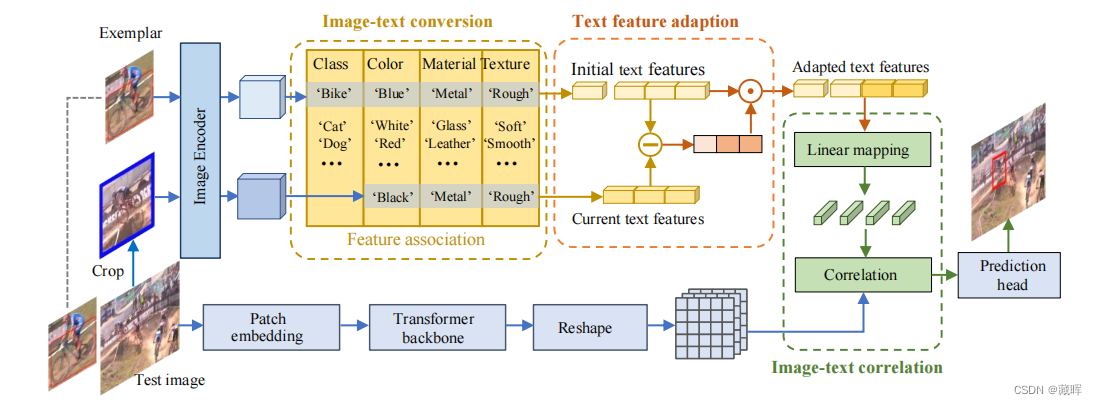
CiteTracker包含三个模块:
- 图像-文本转换模块,基于图像范例生成目标对象的文本特征;
- 文本特征自适应模块,根据当前目标状态调整属性描述的权重;
- 图像-文本相关模块,将目标描述的特征与测试图像进行关联起来,生成相关特征用于目标状态估计。
三十九、Human from Blur: Human Pose Tracking from Blurry Images
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Zhao_Human_from_Blur_Human_Pose_Tracking_from_Blurry_Images_ICCV_2023_paper.pdf
1、摘要
我们提出了一种方法来估计三维人体姿态的图像。其关键思想是通过用三维人体模型、纹理映射和一系列描述人体运动的姿态来建模正向问题来解决图像去模糊的反问题。模糊过程然后通过一个时间图像聚合步骤进行建模。使用可微渲染器,我们可以通过反向传播像素级重投影误差来解决反问题,以恢复解释单个或多个输入图像的最佳人体运动表示。由于图像重建损失本身是不够的,我们提出了额外的正则化项。据我们所知,我们提出了解决这个问题的第一种方法。我们的方法在显著模糊的输入上始终优于其他方法,因为它们缺乏我们的方法统一的一个或多个关键功能,即具有子帧精度的图像去模糊和非刚性人体运动的显式三维建模。

2、方法
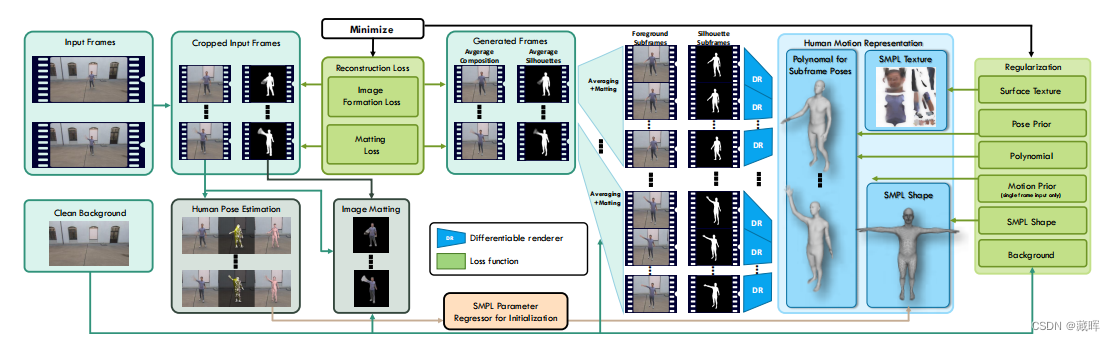
我们的方法的输入是一个人的单个或多个模糊帧(左),输出是一个人及其子帧随时间运动的三维表示(右)。从右到左:从人类的运动表征出发,我们的模型可以看作是生成模型。对于所需的一组帧和子帧,我们可以渲染子帧的外观和相应的轮廓。然后,对子帧进行平均,生成模糊帧和模糊轮廓(alpha通道),由已知背景组成,根据(2)生成输入图像。我们的方法的中心部分是图像重建损失,它将生成的图像与实际输入的图像进行比较。为了求解人体运动估计,重构损失通过整个可微pipeline进行反向传播。人体姿态估计采用传统的方法[27]进行优化初始化,图像匹配是预先计算的[28]来确定匹配损失。





![NSS [NCTF 2018]小绿草之最强大脑](https://img-blog.csdnimg.cn/img_convert/beb5d6bd3f8321588a77a31d869b3c83.png)