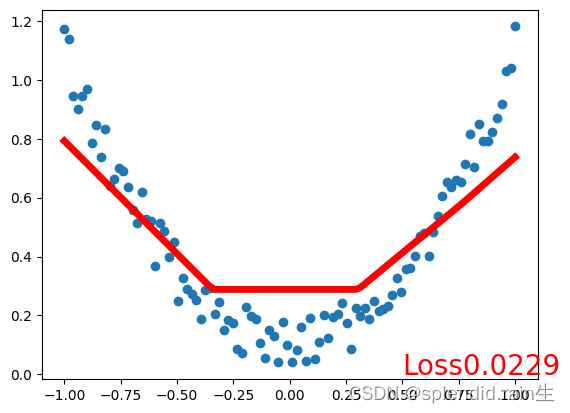
C语言之qsort()函数的模拟实现
文章目录
- C语言之qsort()函数的模拟实现
- 1. 简介
- 2. 冒泡排序
- 3. 对冒泡排序进行改造
- 4. 改造部分
- 4.1 保留部分的冒泡排序
- 4.2 比较部分
- 4.3 交换部分
- 5. bubble_sort2完整代码
- 6. 使用bubble_sort2来排序整型数组
- 7. 使用bubble_sort2来排序结构体数组
- 7.1 按名字来排序结构体数组
- 7.2 按年龄来排序结构体数组
1. 简介
qsort()函数全称为Quicksort,因为底层使用的是快速排序,对初学者来说只学过冒泡排序,使用我们使用冒泡排序来实现下qsort()函数,qsort()函数(冒泡排序版)
不知道qsort函数怎么使用的可以看看这篇qsort函数
2. 冒泡排序
既然要使用冒泡排序改模拟实现qsort,那得知道什么是冒泡排序
代码如下:
#include <stdio.h>
void bubble_sort(int arr[], int sz)
{
int i = 0;
//趟数
for (i = 0; i < sz - 1; i++)
{
//一趟冒泡排序
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[] = { 1,4,7,2,5,8,3,10,6,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
return 0;
}
3. 对冒泡排序进行改造
void bubble_sort(int arr[], int sz);
void qsort (void* base,
size_t num,
size_t size,
int (*compar)(const void*,const void*));
先来看看冒泡排序和qsort函数的函数声明
要想用冒泡排序模拟实现qsort函数,首先函数的形参要一致
void bubble_sort2(void* base,
size_t sz,
size_t width,
int (*cmp)(const void* p1,const void* p2));
仿照着qsort的形参来写
- void*:由于我们不知道要排序什么数组,所以我们使用void*来接收
- sz:为数组中元素的个数
- width:为数组中一个元素的大小(单位为字节)
- int (cmp)(const void p1,const void* p2):是函数指针
这个函数指针指向的函数是用来比较两个元素的大小
p1指向一个元素,p2也指向一个元素
函数的声明部分写好了,就得改造函数内部了
先来看看冒泡排序中的代码

- 首先函数的形参得更改吧 改为上边的函数声明
- 趟数取决于数组中元素个数使用不需要修改
- 冒泡排序只能排序整型,所以一趟冒泡排序中的比较部分需要修改
- 交换两个元素的位置也需要修改
4. 改造部分
4.1 保留部分的冒泡排序
先将冒泡排序还能使用的部分保留下来
void bubble_sort2(void* base, size_t sz, size_t width, int (*cmp)(const void* p1, const void* p2))
{
int i = 0;
//趟数
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟冒泡排序
for (j = 0; j < sz - 1 - i; j++)
{
//比较两个元素的大小
if ()
{
//Swap用于交换两个元素的位置
Swap();
}
}
}
}
int main()
{
int arr[] = { 1,4,7,2,5,8,3,10,6,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
其中的比较部分和交换部分需要我们自己来实现
4.2 比较部分
cmp((char*)base + j * width, (char*)base + (j + 1) * width)
-
由于我们得到的数组名,也就是首元素的地址,不知道第二个元素的地址
我们可以通过指针偏移来找到第二个元素 -
我们得到的是void类型的数据,我们需要将其强制转换成char类型的数据,以便于我们进行指针偏移
-
不知道数组的类型,我们只知道一个元素的大小,我们可以通过(char*)base + j + width的方式来找到一个元素的地址,(char*)base + (j+1) + width的方式来找到后一个元素的地址
用来模拟arr[j] 和 arr[j+1]

-
为什么其他类型的指针不行呢,我来举个例子:
假设用来排序double类型的数据,也就是每个元素是8字节 width = 8
(char*)base + j * width 和 (char*)base + (j+1) * width
当j等于0时,char类型的指针会偏移8个字节,找到第二个元素
如果换成其他类型的指针 int* 在这个情况下就不能使用了,只有char*类型的指针偏移是1个字节,适用于任意类型的排序
4.3 交换部分
void Swap(char* p1, char* p2,size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *p1;
*p1 = *p2;
*p2 = tmp;
p1++;
p2++;
}
}
- 由于在比较部分已经将数据强制转换成char类型,所以Swap函数的形参就可以使用char来接收
- 由于不知道接收的是什么类型的数据,但是我们知道每个元素的大小,我们可以通过一个字节一个字节进行交换,和冒泡排序一样定义一个临时变量来交换两个元素,交换完一个字节的内容之后,p1++ p2++来找到第二个字节的内容,直到交换完成
5. bubble_sort2完整代码
void Swap(char* p1, char* p2,size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *p1;
*p1 = *p2;
*p2 = tmp;
p1++;
p2++;
}
}
void bubble_sort2(void* base, size_t sz, size_t width, int (*cmp)(const void* p1, const void* p2))
{
int i = 0;
//趟数
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟冒泡排序
for (j = 0; j < sz - 1 - i; j++)
{
//比较两个元素的大小
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
//Swap用于交换两个元素的位置
Swap((char*)base + j * width, (char*)base + (j + 1) * width,width);
}
}
}
}
6. 使用bubble_sort2来排序整型数组
和使用qsort函数一样,第四个形象需要根据需要排序的数据类型来编写函数,然后将其传给qsort函数,整型数据的比较只需要两个元素作差就好了
代码如下:
int cmp_int(const void* p1, const void* p2)
{
return *(int*)p1 - *(int*)p2;
}
排序整型数组的完整代码:
#include <stdio.h>
void Swap(char* p1, char* p2,size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *p1;
*p1 = *p2;
*p2 = tmp;
p1++;
p2++;
}
}
void bubble_sort2(void* base, size_t sz, size_t width, int (*cmp)(const void* p1, const void* p2))
{
int i = 0;
//趟数
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟冒泡排序
for (j = 0; j < sz - 1 - i; j++)
{
//比较两个元素的大小
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
//Swap用于交换两个元素的位置
Swap((char*)base + j * width, (char*)base + (j + 1) * width,width);
}
}
}
}
int cmp_int(const void* p1, const void* p2)
{
return *(int*)p1 - *(int*)p2;
}
int main()
{
int arr[] = { 1,4,7,2,5,8,3,10,6,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
代码运行结果如下:

7. 使用bubble_sort2来排序结构体数组
由于结构体中的数据类型较多,可以选择一种来排序,然后根据不同的数据类型来排序
按以下两种数据来举例子
struct Stu
{
char name[20];
int age;
};
```c
int main()
{
struct Stu arr[] = { {"zhangsan",25},{"lisi",18} ,{"wangwu",30} };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort2(arr, sz, sizeof(arr[0]), cmp_struct_by_name);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);
}
return 0;
}
7.1 按名字来排序结构体数组
字符串的比较是比较ASCII,不是比较字符串的长度
int cmp_struct_by_name(const void* p1, const void* p2)
{
return strcmp(((struct Stu*)p1)->name, ((struct Stu*)p2)->name);
//return strcmp((*(struct Stu*)p1).name, (*(struct Stu*)p2).name);
//两段代码等价
}
完整代码如下:
#include <stdio.h>
#include <string.h>
void Swap(char* p1, char* p2,size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *p1;
*p1 = *p2;
*p2 = tmp;
p1++;
p2++;
}
}
void bubble_sort2(void* base, size_t sz, size_t width, int (*cmp)(const void* p1, const void* p2))
{
int i = 0;
//趟数
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟冒泡排序
for (j = 0; j < sz - 1 - i; j++)
{
//比较两个元素的大小
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
//Swap用于交换两个元素的位置
Swap((char*)base + j * width, (char*)base + (j + 1) * width,width);
}
}
}
}
struct Stu
{
char name[20];
int age;
};
int cmp_struct_by_name(const void* p1, const void* p2)
{
return strcmp(((struct Stu*)p1)->name, ((struct Stu*)p2)->name);
//return strcmp((*(struct Stu*)p1).name, (*(struct Stu*)p2).name);
//两段代码等价
}
int main()
{
struct Stu arr[] = { {"zhangsan",25},{"lisi",18} ,{"wangwu",30} };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort2(arr, sz, sizeof(arr[0]), cmp_struct_by_name);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);
}
return 0;
}
代码运行结果如下:

7.2 按年龄来排序结构体数组
int cmp_struct_by_age(const void* p1, const void* p2)
{
return ((struct Stu*)p1)->age - ((struct Stu*)p2)->age;
//return (*(struct Stu*)p1).age - (*(struct Stu*)p2).age;
//两段代码等价
}
完整代码如下:
#include <stdio.h>
void Swap(char* p1, char* p2,size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *p1;
*p1 = *p2;
*p2 = tmp;
p1++;
p2++;
}
}
void bubble_sort2(void* base, size_t sz, size_t width, int (*cmp)(const void* p1, const void* p2))
{
int i = 0;
//趟数
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟冒泡排序
for (j = 0; j < sz - 1 - i; j++)
{
//比较两个元素的大小
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
//Swap用于交换两个元素的位置
Swap((char*)base + j * width, (char*)base + (j + 1) * width,width);
}
}
}
}
struct Stu
{
char name[20];
int age;
};
int cmp_struct_by_age(const void* p1, const void* p2)
{
return ((struct Stu*)p1)->age - ((struct Stu*)p2)->age;
//return (*(struct Stu*)p1).age - (*(struct Stu*)p2).age;
//两段代码等价
}
int main()
{
struct Stu arr[] = { {"zhangsan",25},{"lisi",18} ,{"wangwu",30} };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort2(arr, sz, sizeof(arr[0]), cmp_struct_by_age);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);
}
return 0;
}
代码运行结果如下:




![NSS [NCTF 2018]小绿草之最强大脑](https://img-blog.csdnimg.cn/img_convert/beb5d6bd3f8321588a77a31d869b3c83.png)