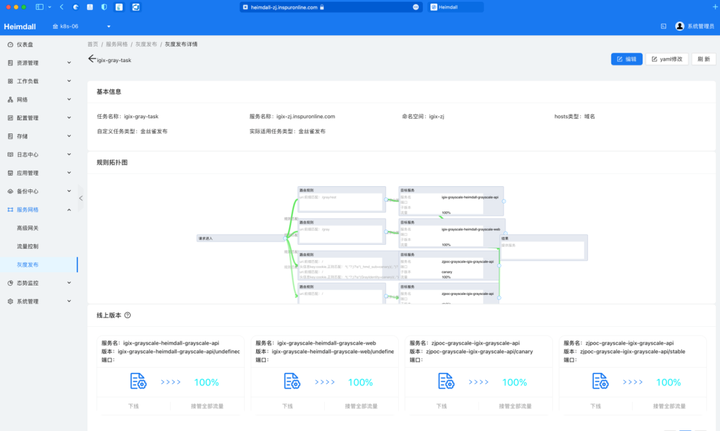
接着前面的Langchain,继续实现读取YouTube的视频脚本来问答Indexes for information retrieve
- LangChain 实现给动物取名字,
- LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字
- LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄

1. 安装youtube-transcript-api
pip install youtube-transcript-api
pip install faiss-cpu
pip install tiktoken
引用向量数据库Faiss
2. 编写读取视频字幕并存入向量数据库Faiss,文件langchain_helper.py
# 从langchain包和其他库中导入必要的模块
from langchain.document_loaders import YoutubeLoader # 导入YoutubeLoader,用于加载YouTube视频数据
from langchain.text_splitter import RecursiveCharacterTextSplitter # 导入文本分割器,用于处理文档
from langchain.embeddings.openai import OpenAIEmbeddings # 导入OpenAIEmbeddings,用于生成嵌入向量
from langchain.vectorstores import FAISS # 导入FAISS,用于大数据集中高效的相似性搜索
from langchain.llms import OpenAI # 导入OpenAI,用于语言模型功能
from langchain import PromptTemplate # 导入PromptTemplate,用于模板化提示
from langchain.chains import LLMChain # 导入LLMChain,用于创建语言模型链
from dotenv import load_dotenv # 导入load_dotenv,用于管理环境变量
load_dotenv() # 从.env文件加载环境变量
embedding = OpenAIEmbeddings() # 初始化OpenAI嵌入向量,用于生成文档嵌入向量
# YouTube视频的URL
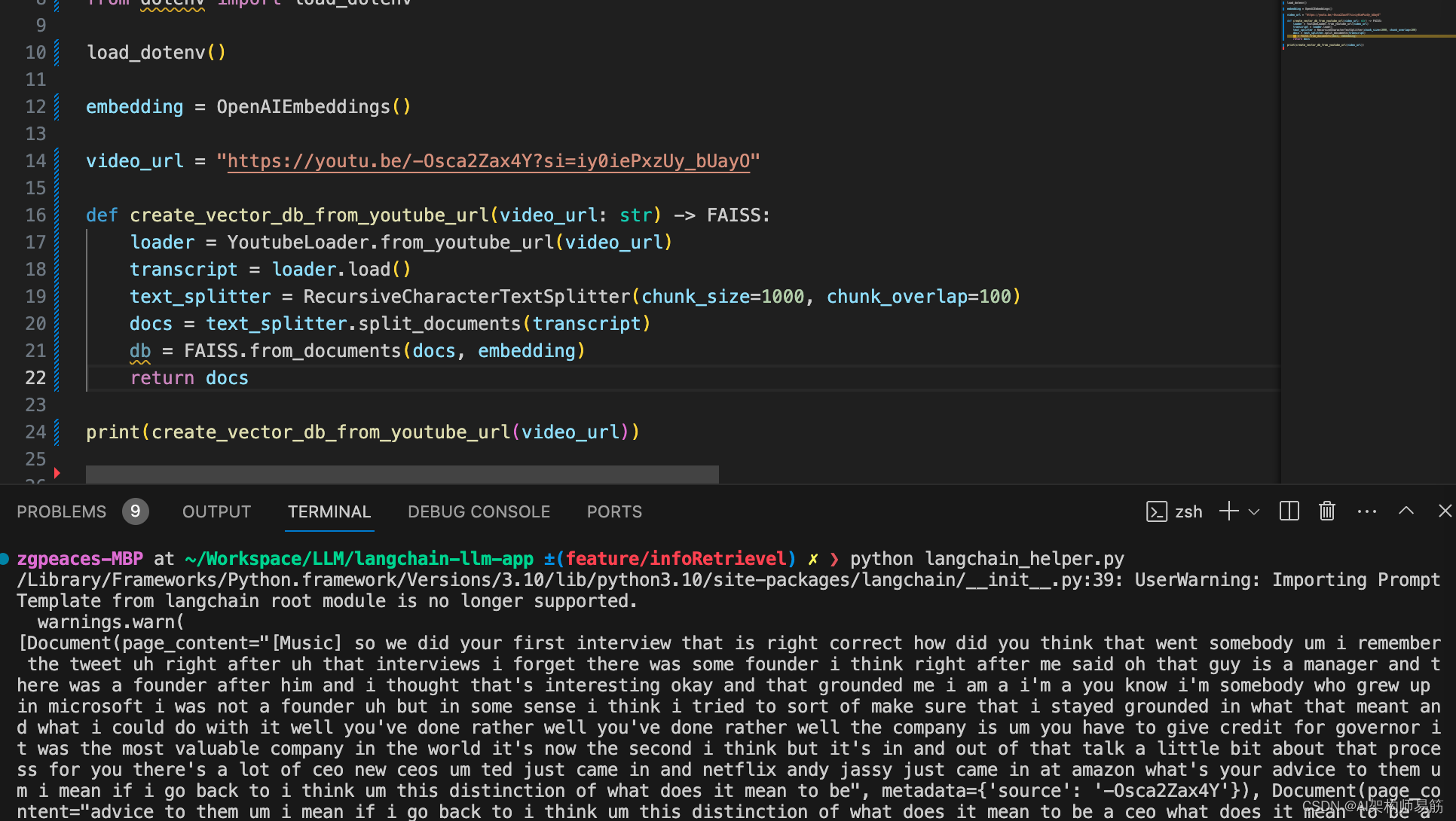
video_url = "https://youtu.be/-Osca2Zax4Y?si=iy0iePxzUy_bUayO"
def create_vector_db_from_youtube_url(video_url: str) -> FAISS:
# 加载YouTube视频字幕
loader = YoutubeLoader.from_youtube_url(video_url)
transcript = loader.load()
# 将字幕分割成较小的片段
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(transcript)
# 从文档片段创建FAISS数据库
db = FAISS.from_documents(docs, embedding)
return db
# 示例:从给定YouTube URL创建向量数据库
print(create_vector_db_from_youtube_url(video_url))
zgpeaces-MBP at ~/Workspace/LLM/langchain-llm-app ±(feature/infoRetrievel) ✗ ❯ python langchain_helper.py
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/langchain/__init__.py:39: UserWarning: Importing PromptTemplate from langchain root module is no longer supported.
warnings.warn(
<langchain.vectorstores.faiss.FAISS object at 0x11b1e96f0>
3. 根据向量数据库的信息查询
查看OpenAI model
3.1 添加查询方法
# 从langchain包和其他库中导入必要的模块
from langchain.document_loaders import YoutubeLoader # 导入YoutubeLoader,用于从YouTube视频加载数据
from langchain.text_splitter import RecursiveCharacterTextSplitter # 导入用于处理长文档的文本分割器
from langchain.embeddings.openai import OpenAIEmbeddings # 导入OpenAIEmbeddings,用于生成文档嵌入向量
from langchain.vectorstores import FAISS # 导入FAISS,用于大数据集中高效的相似性搜索
from langchain.llms import OpenAI # 导入OpenAI,用于访问语言模型功能
from langchain import PromptTemplate # 导入PromptTemplate,用于创建结构化的语言模型提示
from langchain.chains import LLMChain # 导入LLMChain,用于构建使用语言模型的操作链
from dotenv import load_dotenv # 导入load_dotenv,用于从.env文件加载环境变量
load_dotenv() # 从.env文件加载环境变量
embedding = OpenAIEmbeddings() # 初始化OpenAI嵌入向量的实例,用于生成文档嵌入向量
# YouTube视频的URL
video_url = "https://youtu.be/-Osca2Zax4Y?si=iy0iePxzUy_bUayO"
def create_vector_db_from_youtube_url(video_url: str) -> FAISS:
# 加载YouTube视频字幕
loader = YoutubeLoader.from_youtube_url(video_url)
transcript = loader.load()
# 将字幕分割成较小的片段
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(transcript)
# 从文档片段创建FAISS数据库
db = FAISS.from_documents(docs, embedding)
return db
def get_response_from_query(db, query, k=4):
# 对给定查询执行数据库的相似性搜索
docs = db.similarity_search(query, k=k)
# 连接前几个文档的内容
docs_page_content = " ".join([d.page_content for d in docs])
# 初始化一个OpenAI语言模型
llm = OpenAI(model="text-davinci-003")
# 定义语言模型的提示模板
prompt = PromptTemplate(
input_variables=["question", "docs"],
template = """
You are a helpful assistant that that can answer questions about youtube videos
based on the video's transcript.
Answer the following question: {question}
By searching the following video transcript: {docs}
Only use the factual information from the transcript to answer the question.
If you feel like you don't have enough information to answer the question, say "I don't know".
Your answers should be verbose and detailed.
""",
)
# 使用定义的提示创建一个语言模型链
chain = LLMChain(llm=llm, prompt=prompt)
# 使用查询和连接的文档运行链
response = chain.run(question=query, docs=docs_page_content)
# 通过替换换行符来格式化响应
response = response.replace("\n", " ")
return response, docs
# 示例用法:从YouTube视频URL创建向量数据库
# print(create_vector_db_from_youtube_url(video_url))
3.2 Streamlit 实现入参视频地址和查询内容
main.py
import streamlit as st # 导入Streamlit库,用于创建Web应用程序
import langchain_helper as lch # 导入自定义模块'langchain_helper',用于处理langchain操作
import textwrap # 导入textwrap模块,用于格式化文本
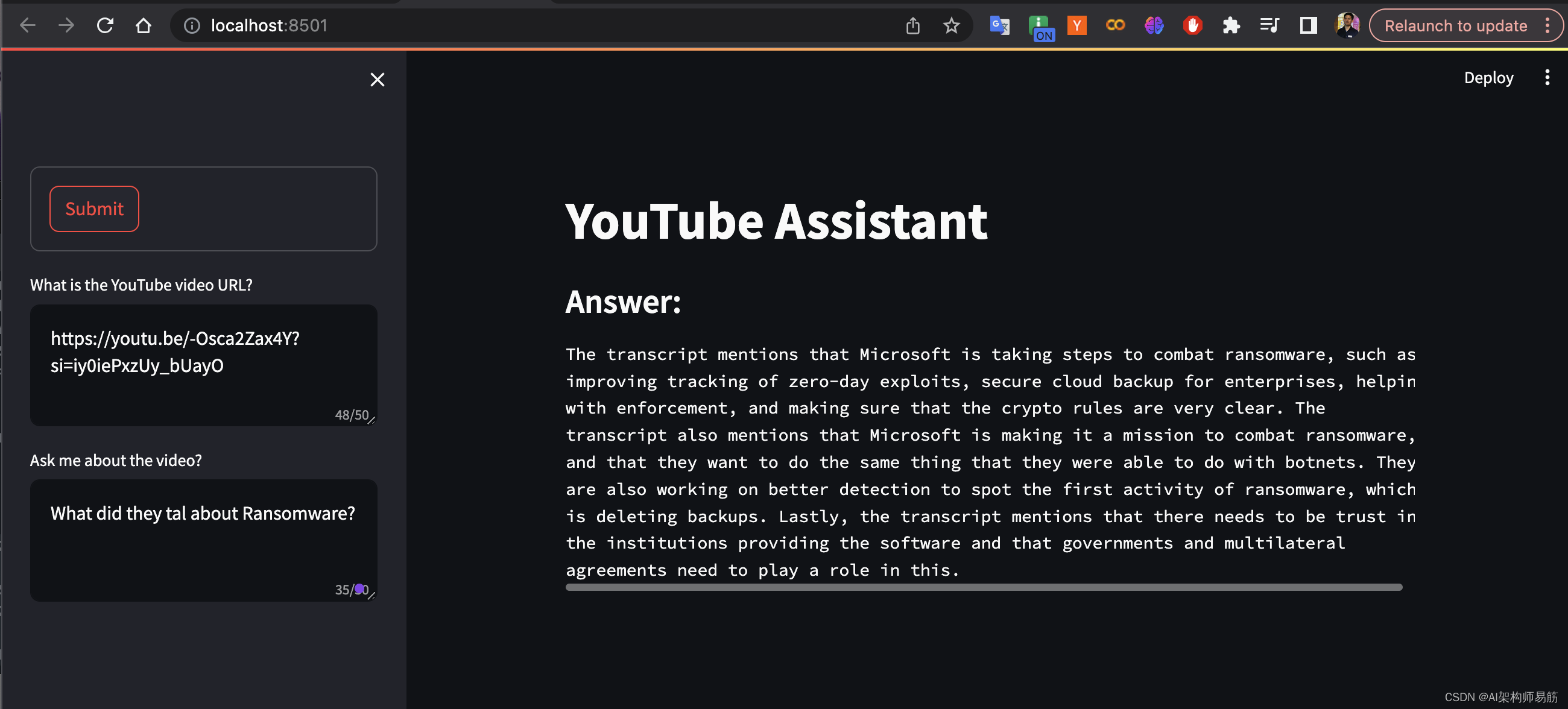
st.title("YouTube Assistant") # 设置Streamlit网页应用的标题
# 使用Streamlit的侧边栏功能来创建输入表单
with st.sidebar:
# 在侧边栏中创建一个表单
with st.form(key='my_form'):
# 创建一个文本区域用于输入YouTube视频URL
youtube_url = st.sidebar.text_area(
label="What is the YouTube video URL?",
max_chars=50
)
# 创建一个文本区域用于输入关于YouTube视频的查询
query = st.sidebar.text_area(
label="Ask me about the video?",
max_chars=50,
key="query"
)
# 创建一个提交表单的按钮
submit_button = st.form_submit_button(label='Submit')
# 检查是否同时提供了查询和YouTube URL
if query and youtube_url:
# 从YouTube视频URL创建向量数据库
db = lch.create_vector_db_from_youtube_url(youtube_url)
# 根据向量数据库获取查询的响应
response, docs = lch.get_response_from_query(db, query)
# 在应用程序中显示一个副标题“回答:”
st.subheader("Answer:")
# 显示响应,格式化为每行85个字符
st.text(textwrap.fill(response, width=85))
运行
$ streamlit run main.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.50.10:8501
For better performance, install the Watchdog module:
What is the YouTube video URL?
https://youtu.be/-Osca2Zax4Y?si=iy0iePxzUy_bUayO
Ask me about the video?
What did they tal about Ransomware?
参考
- https://github.com/zgpeace/pets-name-langchain/tree/feature/infoRetrievel
- https://python.langchain.com/docs/integrations/document_loaders/youtube_transcript
- https://youtu.be/lG7Uxts9SXs?si=H1CISGkoYiKRSF5V
- https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/
- https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo



![NSS [NCTF 2018]小绿草之最强大脑](https://img-blog.csdnimg.cn/img_convert/beb5d6bd3f8321588a77a31d869b3c83.png)