轻量级数据存储功能通常用于保存应用的一些常用配置信息,并不适合需要存储大量数据和频繁改变数据的场景。应用的数据保存在文件中,这些文件可以持久化地存储在设备上。需要注意的是,应用访问的实例包含文件所有数据,这些数据会一直加载在设备的内存中,直到应用主动从内存中将其移除前,应用可以通过Preferences的API进行数据操作。
目前安卓中常用的轻量级存储方案有:SharedPreferences、MMKV、DataStore。
SharedPreferences是安卓中最初自带的轻量级数据存储方案,可以满足基本配置存储需求。目前语玩安卓项目也使用的SharedPreferences。但是在某些场景下,无法满足,比如频繁写入,多进程等;SharedPreferences也存在严重的ANR异常问题。
一、SharedPreferences、MMKV、DataStore对比
-
SharedPreferences 劣势:
1、卡顿、ANR 2、不支持多进程
3、同步比较耗时
4、全量更新
-
MMKV的优势:
1、它的同步保存数据速度快 2、它支持多进程保存数据 3、增量更新
劣势:
1、mmkv有丢失数据的几率(意外情况不会自动备份)
-
DataStore优势
1、性能好,读写文件都在后台完成。 2、容易异步回调,采用协程实现的,容易切换线程。
劣势:
1、不支持多进程。 2、全量更新。
二、SharedPreferences
存在问题
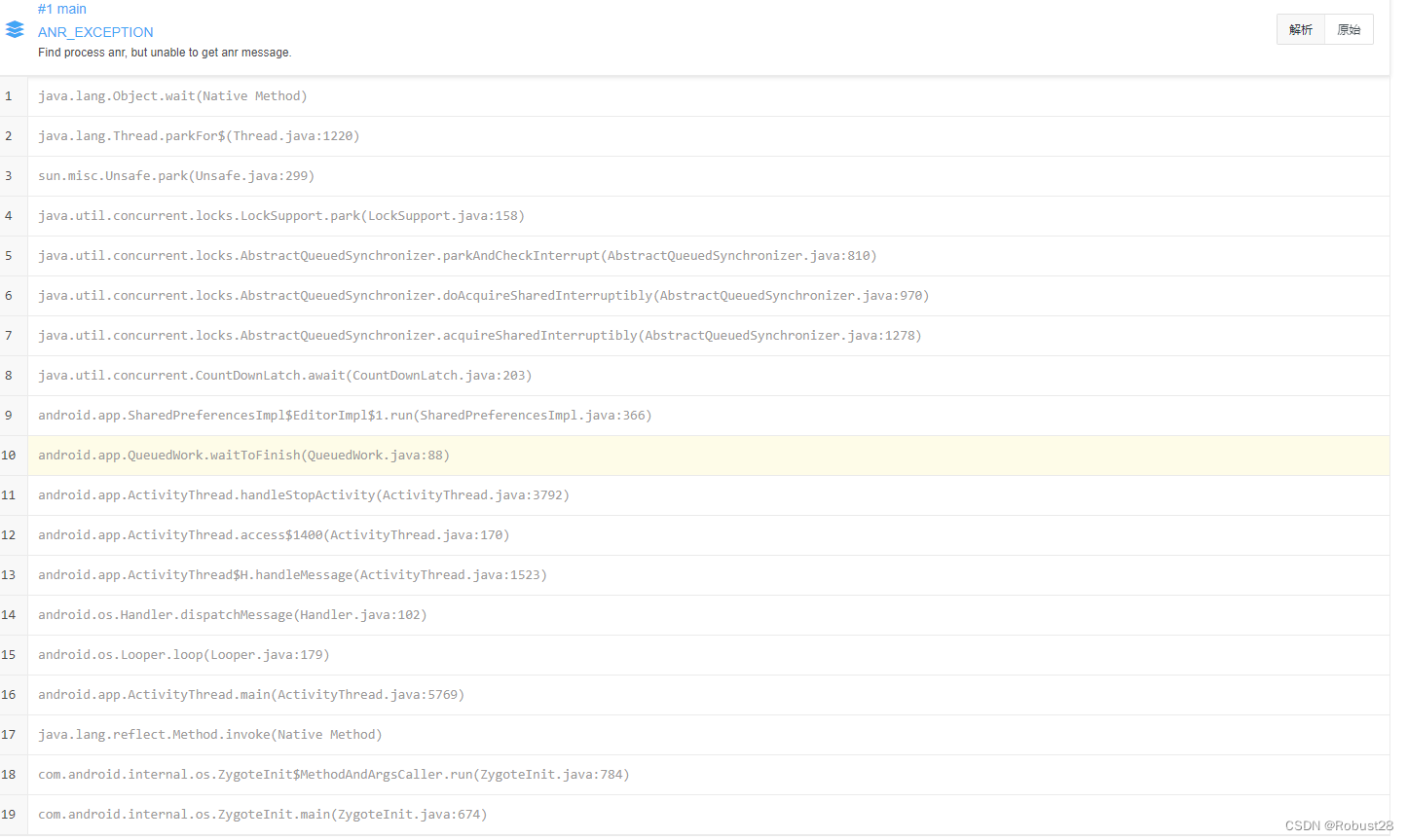
1、ANR异常:是目前SP存在的主要问题。下图是,语玩中七日内因为Sp中出现ANR情况,大概三千多。ANR主要原因是QueuedWork.waitToFinish();
SP ANR七日内崩溃率

2、不支持跨进程通信:如果想跨进程可以通过ContentProvider实现
3、SP全量更新 :每次把全量的数据写入到文件中。
SharedPreferences存储过程
-
sp简单使用
val edit = context.getSharedPreferences("sp", Context.MODE_PRIVATE).edit()
edit.putString(key,value)
if (sync) {
edit.commit()
} else {
edit.apply()
}-
SP数据存储过程

-
SP异步正常情况存储

这个过程看起来没什么问题,写文件是在子线程完成的。但是存储过程中先提交到内存,然后把写入文件加入到任务队列。这个过程会出现内存数据和文件数据的不一致的情况。
-
SP异步异常情况存储
为了保证内存数据和文件数据一致性,SharePreferences在Activity的Pause/Stop方法和Service 的start/Stop方法中调用QueuedWork.wailToFinish方法,保证数据一致性。这也是造成ANR的主要原因。主线程等待写文件,如果写入文件比较多,等待时间较长,造成用户点击事件无响应,出现ANR。

三、MMKV
MMKV介绍
MMKV 是基于 mmap 内存映射的 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强。从 2015 年中至今在微信上使用,其性能和稳定性经过了时间的验证。近期也已移植到 Android / macOS / Win32 / POSIX 平台,一并开源。
MMKV起源
在微信客户端的日常运营中,时不时就会爆发特殊文字引起系统的 crash,参考文章,文章里面设计的技术方案是在关键代码前后进行计数器的加减,通过检查计数器的异常,来发现引起闪退的异常文字。在会话列表、会话界面等有大量 cell 的地方,希望新加的计时器不会影响滑动性能;另外这些计数器还要永久存储下来——因为闪退随时可能发生。这就需要一个性能非常高的通用 key-value 存储组件,考察了 SharedPreferences、NSUserDefaults、SQLite 等常见组件,发现都没能满足如此苛刻的性能要求。考虑到这个防 crash 方案最主要的诉求还是实时写入,而 mmap 内存映射文件刚好满足这种需求,尝试通过它来实现一套 key-value 组件。
MMKV使用
MMKV 的使用非常简单,所有变更立马生效,无需调用 sync、apply。
在 App 启动时初始化 MMKV,设定 MMKV 的根目录(files/mmkv/),例如在 Application 里:
// Android
public void onCreate() {
super.onCreate();
String rootDir = MMKV.initialize(this);
System.out.println("mmkv root: " + rootDir);
//……
}// IOS
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
// init MMKV in the main thread
[MMKV initializeMMKV:nil];
//...
return YES;
}MMKV有一个全局实例,可以直接使用
// Android
import com.tencent.mmkv.MMKV;
MMKV kv = MMKV.defaultMMKV();
kv.encode("bool", true);
boolean bValue = kv.decodeBool("bool");
kv.encode("int", Integer.MIN_VALUE);
int iValue = kv.decodeInt("int");
kv.encode("string", "Hello from mmkv");
String str = kv.decodeString("string");// IOS
MMKV *mmkv = [MMKV defaultMMKV];
[mmkv setBool:YES forKey:@"bool"];
BOOL bValue = [mmkv getBoolForKey:@"bool"];
[mmkv setInt32:-1024 forKey:@"int32"];
int32_t iValue = [mmkv getInt32ForKey:@"int32"];
[mmkv setString:@"hello, mmkv" forKey:@"string"];
NSString *str = [mmkv getStringForKey:@"string"];写入流程

读取流程

MMKV原理
内存准备
通过 mmap 内存映射文件,提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失。
数据组织
数据序列化方面选用 protobuf 协议,pb 在性能和空间占用上都有不错的表现。
考虑到我们要提供的是通用 kv 组件,key 可以限定是 string 字符串类型,value 则多种多样(int/bool/double 等)。要做到通用的话,考虑将 value 通过 protobuf 协议序列化成统一的内存块(buffer),然后就可以将这些 KV 对象序列化到内存中。
protobuf数据组织
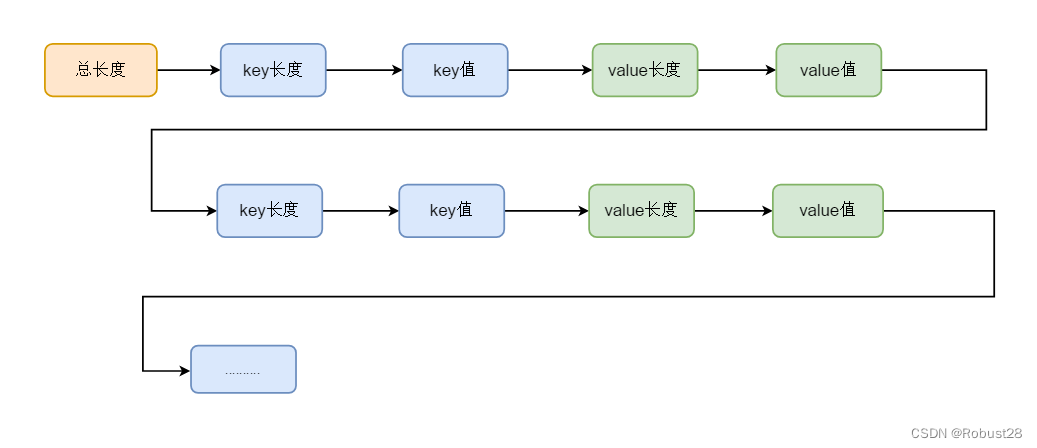
MMKV使用Protobuf存储数据,冗余数据更少,更省空间,同时可以方便地在末尾追加数据。
写入优化
标准 protobuf 不提供增量更新的能力,每次写入都必须全量写入。考虑到主要使用场景是频繁地进行写入更新,我们需要有增量更新的能力:将增量 kv 对象序列化后,直接 append 到内存末尾;这样同一个 key 会有新旧若干份数据,最新的数据在最后;那么只需在程序启动第一次打开 mmkv 时,不断用后读入的 value 替换之前的值,就可以保证数据是最新有效的。

空间增长
使用 append 实现增量更新带来了一个新的问题,就是不断 append 的话,文件大小会增长得不可控。例如同一个 key 不断更新的话,是可能耗尽几百 M 甚至上 G 空间,而事实上整个 kv 文件就这一个 key,不到 1k 空间就存得下。这明显是不可取的。我们需要在性能和空间上做个折中:以内存 pagesize 为单位申请空间,在空间用尽之前都是 append 模式;当 append 到文件末尾时,进行文件重整、key 排重,尝试序列化保存排重结果;排重后空间还是不够用的话,将文件扩大一倍,直到空间足够。
-(BOOL)append:(NSData*)data {
if (space >= data.length) {
append(fd, data);
} else {
newData = unique(m_allKV);
if (total_space >= newData.length) {
write(fd, newData);
} else {
while (total_space < newData.length) {
total_space *= 2;
}
ftruncate(fd, total_space);
write(fd, newData);
}
}
}数据有效性
考虑到文件系统、操作系统都有一定的不稳定性(断电关机之类的操作系统级别的崩溃),另外增加了 crc 校验,对无效数据进行甄别。
在 crc 校验失败,或者文件长度不对的时候,MMKV 默认会丢弃所有数据。你可以让 MMKV 恢复数据。要注意的是修复率无法保证,而且可能修复出奇怪的 key-value。同样地也是实现MMKVHandler接口
@Override
public MMKVRecoverStrategic onMMKVCRCCheckFail(String mmapID) {
return MMKVRecoverStrategic.OnErrorRecover;
}
@Override
public MMKVRecoverStrategic onMMKVFileLengthError(String mmapID) {
return MMKVRecoverStrategic.OnErrorRecover;
}Android 多进程访问
首先我们简单回顾一下 MMKV 原来的逻辑。MMKV 本质上是将文件 mmap 到内存块中,将新增的 key-value 统统 append 到内存中;到达边界后,进行重整回写以腾出空间,空间还是不够的话,就 double 内存空间;对于内存文件中可能存在的重复键值,MMKV 只选用最后写入的作为有效键值。那么其他进程为了保持数据一致,就需要处理这三种情况:写指针增长、内存重整、内存增长。但首先还得解决一个问题:怎么让其他进程感知这三种情况?
状态同步
-
写指针的同步 我们可以在每个进程内部缓存自己的写指针,然后在写入键值的同时,还要把最新的写指针位置也写到 mmap 内存中;这样每个进程只需要对比一下缓存的指针与 mmap 内存的写指针,如果不一样,就说明其他进程进行了写操作。事实上 MMKV 原本就在文件头部保存了有效内存的大小,这个数值刚好就是写指针的内存偏移量,我们可以重用这个数值来校对写指针。
-
内存重整的感知 考虑使用一个单调递增的序列号,每次发生内存重整,就将序列号递增。将这个序列号也放到 mmap 内存中,每个进程内部也缓存一份,只需要对比序列号是否一致,就能够知道其他进程是否触发了内存重整。
-
内存增长的感知 事实上 MMKV 在内存增长之前,会先尝试通过内存重整来腾出空间,重整后还不够空间才申请新的内存。所以内存增长可以跟内存重整一样处理。至于新的内存大小,可以通过查询文件大小来获得,无需在 mmap 内存另外存放。
状态同步逻辑用伪码表达大概是这个样子:
void checkLoadData() {
if (m_sequence != mmapSequence()) {
m_sequence = mmapSequence();
if (m_size != fileSize()) {
m_size = fileSize();
// 处理内存增长
} else {
// 处理内存重整
}
} else if (m_actualSize != mmapActualSize()) {
auto lastPosition = m_actualSize;
m_actualSize = mmapActualSize();
// 处理写指针增长
} else {
// 什么也没发生
return;
}
}写指针增长
当一个进程发现 mmap 写指针增长,就意味着其他进程写入了新键值。这些新的键值都 append 在原有写指针后面,可能跟前面的 key 重复,也可能是全新的 key,而原写指针前面的键值都是有效的。那么我们就要把这些新键值都读出来,插入或替换原有键值,并将写指针同步到最新位置。
auto lastPosition = m_actualSize;
m_actualSize = mmapActualSize();
// 处理写指针增长
auto bufferSize = m_actualSize - lastPosition;
auto buffer = Buffer(lastPosition, bufferSize);
map<string, Buffer> dictionary = decodeMap(buffer);
for (auto& itr : dictionary) {
// m_cache 还是有效的
m_cache[itr.first] = itr.second;
}内存重整
当一个进程发现内存被重整了,就意味着原写指针前面的键值全部失效,那么最简单的做法是全部抛弃掉,从头开始重新加载一遍。
// 处理内存重整
m_actualSize = mmapActualSize();
auto buffer = Buffer(0, m_actualSize);
m_cache = decodeMap(buffer);内存增长
正如前文所述,发生内存增长的时候,必然已经先发生了内存重整,那么原写指针前面的键值也是统统失效,处理逻辑跟内存重整一样。
文件锁
-
递归锁 意思是如果一个进程/线程已经拥有了锁,那么后续的加锁操作不会导致卡死,并且解锁也不会导致外层的锁被解掉。对于文件锁来说,前者是满足的,后者则不然。因为文件锁是状态锁,没有计数器,无论加了多少次锁,一个解锁操作就全解掉。只要用到子函数,就非常需要递归锁。
-
锁升级/降级 锁升级是指将已经持有的共享锁,升级为互斥锁,亦即将读锁升级为写锁;锁降级则是反过来。文件锁支持锁升级,但是容易死锁:假如 A、B 进程都持有了读锁,现在都想升级到写锁,就会陷入相互等待的困境,发生死锁。另外,由于文件锁不支持递归锁,也导致了锁降级无法进行,一降就降到没有锁。
为了解决这两个难题,需要对文件锁进行封装,增加读锁、写锁计数器。处理逻辑如下表:
| 读锁计数器 | 写锁计数器 | 加读锁 | 加写锁 | 解读锁 | 解写锁 |
|---|---|---|---|---|---|
| 0 | 0 | 加读锁 | 加写锁 | - | - |
| 0 | 1 | +1 | +1 | - | 解写锁 |
| 0 | N | +1 | +1 | - | -1 |
| 1 | 0 | +1 | 解读锁再加写锁 | 解读锁 | - |
| 1 | 1 | +1 | +1 | -1 | 加读锁 |
| 1 | N | +1 | +1 | -1 | -1 |
| N | 0 | +1 | 解读锁再加写锁 | -1 | - |
| N | 1 | +1 | +1 | -1 | 加读锁 |
| N | N | +1 | +1 | -1 | -1 |
需要注意的地方有两点:
-
加写锁时,如果当前已经持有读锁,那么先尝试加写锁,try_lock 失败说明其他进程持有了读锁,我们需要先将自己的读锁释放掉,再进行加写锁操作,以避免死锁的发生。
-
解写锁时,假如之前曾经持有读锁,那么我们不能直接释放掉写锁,这样会导致读锁也解了。我们应该加一个读锁,将锁降级。
四、DataStore
Jetpack DataStore 是一种数据存储解决方案,允许您使用协议缓冲区存储键值对或类型化对象。DataStore 使用 Kotlin 协程和 Flow 以异步、一致的事务方式存储数据。
如果您当前在使用SharedPreferences 存储数据,请考虑迁移到 DataStore。
Preferences DataStore 和 Proto DataStore
DataStore 提供两种不同的实现:Preferences DataStore 和 Proto DataStore。
-
Preferences DataStore 使用键存储和访问数据。此实现不需要预定义的架构,也不确保类型安全。
-
Proto DataStore 将数据作为自定义数据类型的实例进行存储。此实现要求您使用协议缓冲区来定义架构,但可以确保类型安全。
Preferences DataStore
-
使用 Preferences DataStore 存储键值对
Preferences DataStore 实现使用 DataStore 和 Preferences 类将简单的键值对保留在磁盘上。
-
创建 Preferences DataStore
使用由 preferencesDataStore 创建的属性委托来创建 Datastore<Preferences> 实例。在您的 Kotlin 文件顶层调用该实例一次,便可在应用的所有其余部分通过此属性访问该实例。这样可以更轻松地将 DataStore 保留为单例。
此外,如果您使用的是 RxJava,请使用 RxPreferenceDataStoreBuilder。必需的 name 参数是 Preferences DataStore 的名称。
// At the top level of your kotlin file:
val Context.dataStore: DataStore<Preferences> by preferencesDataStore(name = "settings")
**避免为同一文件创建多个DataStore实例**
如果创建多个会抛出异常
java.lang.IllegalStateException: There are multiple DataStores active for the same file:
/data/user/0/com.share/files/datastore/simpleASync.preferences_pb.
You should either maintain your DataStore as a singleton or confirm that there is no two DataStore's active on the same file (by confirming that the scope is cancelled). SingleProcessDataStore 最终实现所有方法
-
从 Preferences DataStore 读取内容
由于 Preferences DataStore 不使用预定义的架构,因此您必须使用相应的键类型函数为需要存储在 DataStore<Preferences> 实例中的每个值定义一个键。例如,如需为 int 值定义一个键,请使用 intPreferencesKey()。然后,使用 DataStore.data 属性,通过 Flow 提供适当的存储值。
val EXAMPLE_COUNTER = intPreferencesKey("example_counter")
val exampleCounterFlow: Flow<Int> = context.dataStore.data
.map { preferences ->
// No type safety.
preferences[EXAMPLE_COUNTER] ?: 0
}
-
将内容写入 Preferences DataStore
Preferences DataStore 提供了一个 edit() 函数,用于以事务方式更新 DataStore 中的数据。该函数的 transform 参数接受代码块,您可以在其中根据需要更新值。转换块中的所有代码均被视为单个事务。
suspend fun incrementCounter() {
context.dataStore.edit { settings ->
val currentCounterValue = settings[EXAMPLE_COUNTER] ?: 0
settings[EXAMPLE_COUNTER] = currentCounterValue + 1
}
}
和SharePreference区别,先写入文件,写入成功,更新缓存数据。无需考虑缓存数据和文件数据不一致情况。
// downstreamFlow.value must be successfully set to data before calling this
private suspend fun transformAndWrite(
transform: suspend (t: T) -> T,
callerContext: CoroutineContext
): T {
// value is not null or an exception because we must have the value set by now so this cast
// is safe.
val curDataAndHash = downstreamFlow.value as Data<T>
curDataAndHash.checkHashCode()
val curData = curDataAndHash.value
val newData = withContext(callerContext) { transform(curData) }
// Check that curData has not changed...
curDataAndHash.checkHashCode()
return if (curData == newData) {
curData
} else {
writeData(newData)
downstreamFlow.value = Data(newData, newData.hashCode())
newData
}
}/**
* Internal only to prevent creation of synthetic accessor function. Do not call this from
* outside this class.
*/
internal suspend fun writeData(newData: T) {
file.createParentDirectories()
val scratchFile = File(file.absolutePath + SCRATCH_SUFFIX)
try {
FileOutputStream(scratchFile).use { stream ->
serializer.writeTo(newData, UncloseableOutputStream(stream))
stream.fd.sync()
// TODO(b/151635324): fsync the directory, otherwise a badly timed crash could
// result in reverting to a previous state.
}
if (!scratchFile.renameTo(file)) {
throw IOException(
"Unable to rename $scratchFile." +
"This likely means that there are multiple instances of DataStore " +
"for this file. Ensure that you are only creating a single instance of " +
"datastore for this file."
)
}
} catch (ex: IOException) {
if (scratchFile.exists()) {
scratchFile.delete() // Swallow failure to delete
}
throw ex
}
}Proto DataStore
-
使用 Proto DataStore 存储类型化的对象
Proto DataStore 实现使用 DataStore 和Proto Buffers将类型化的对象保留在磁盘上。
-
定义架构
Proto DataStore 要求在 app/src/main/proto/ 目录的 proto 文件中保存预定义的架构。此架构用于定义您在 Proto DataStore 中保存的对象的类型。如需详细了解如何定义 proto 架构,请参阅 protobuf 语言指南。
syntax = "proto3";
option java_package = "com.example.application";
option java_multiple_files = true;
message Settings {
// wire type = 1 , field_number =1
int32 example_counter = 1; // (位置1/标识符)
}
注意:您的存储对象的类在编译时由 proto 文件中定义的
message生成。请务必重新构建您的项目。
-
创建 Proto DataStore
创建 Proto DataStore 来存储类型化对象涉及两个步骤:
-
定义一个实现
Serializer<T>的类,其中T是 proto 文件中定义的类型。此序列化器类会告知 DataStore 如何读取和写入您的数据类型。请务必为该序列化器添加默认值,以便在尚未创建任何文件时使用。 -
使用由
dataStore创建的属性委托来创建DataStore<T>的实例,其中T是在 proto 文件中定义的类型。在您的 Kotlin 文件顶层调用该实例一次,便可在应用的所有其余部分通过此属性委托访问该实例。
filename参数会告知 DataStore 使用哪个文件存储数据,而serializer参数会告知 DataStore 第 1 步中定义的序列化器类的名称。
object SettingsSerializer : Serializer<Settings> {
override val defaultValue: Settings = Settings.getDefaultInstance()
override suspend fun readFrom(input: InputStream): Settings {
try {
return Settings.parseFrom(input)
} catch (exception: InvalidProtocolBufferException) {
throw CorruptionException("Cannot read proto.", exception)
}
}
override suspend fun writeTo(
t: Settings,
output: OutputStream) = t.writeTo(output)
}
val Context.settingsDataStore: DataStore<Settings> by dataStore(
fileName = "settings.pb",
serializer = SettingsSerializer
)
-
从 Proto DataStore 读取内容
使用 DataStore.data 显示所有存储对象中相应属性的 Flow。
val exampleCounterFlow: Flow<Int> = context.settingsDataStore.data
.map { settings ->
// The exampleCounter property is generated from the proto schema.
settings.exampleCounter
}
-
将内容写入 Proto DataStore
Proto DataStore 提供了一个 updateData() 函数,用于以事务方式更新存储的对象。updateData() 为您提供数据的当前状态,作为数据类型的一个实例,并在原子读-写-修改操作中以事务方式更新数据。
suspend fun incrementCounter() {
context.settingsDataStore.updateData { currentSettings ->
currentSettings.toBuilder()
.setExampleCounter(currentSettings.exampleCounter + 1)
.build()
}
}在同步代码中使用 DataStore
【注意】:请尽可能避免在 DataStore 数据读取时阻塞线程。阻塞UI线程可能会导致 ANR 或界面卡顿,而阻塞其他线程可能会导致死锁。
DataStore 的主要优势之一是异步 API,但可能不一定始终能将所有的代码都更改为异步代码。如果您使用的现有代码库采用同步磁盘 I/O,或者您的依赖项不提供异步 API,就可能出现这种情况。
Kotlin 协程提供 runBlocking() 协程构建器,以帮助消除同步与异步代码之间的差异。
在Kotlin中,您可以使用 runBlocking() 从 DataStore 同步读取数据。
在Java中可以使用RxJava 在 Flowable 上提供阻塞方法。
以下代码会阻塞发起调用的线程,直到 DataStore 返回数据:
kotlin
val exampleData = runBlocking { context.dataStore.data.first() }
java
Settings settings = dataStore.data().blockingFirst();对UI线程执行同步 I/O 操作可能会导致 ANR 或界面卡顿。您可以通过从 DataStore 异步预加载数据来减少这些问题:
lifecycleScope.launch {
context.dataStore.data.first()
// You should also handle IOExceptions here.
}这样,DataStore 可以异步读取数据并将其缓存在内存中。以后使用 runBlocking() 进行同步读取的速度可能会更快,或者如果初始读取已经完成,可能也可以完全避免磁盘 I/O 操作。
五、补充文档
MMAP映射
1、IO在系统中操作流程
虚拟内存被操作系统划分成两块:用户空间和内核空间,用户空间是用户程序代码运行的地方,内核空间是内核代码运行的地方。为了安全,它们是隔离的,即使用户的程序崩溃了,内核也不受影响。
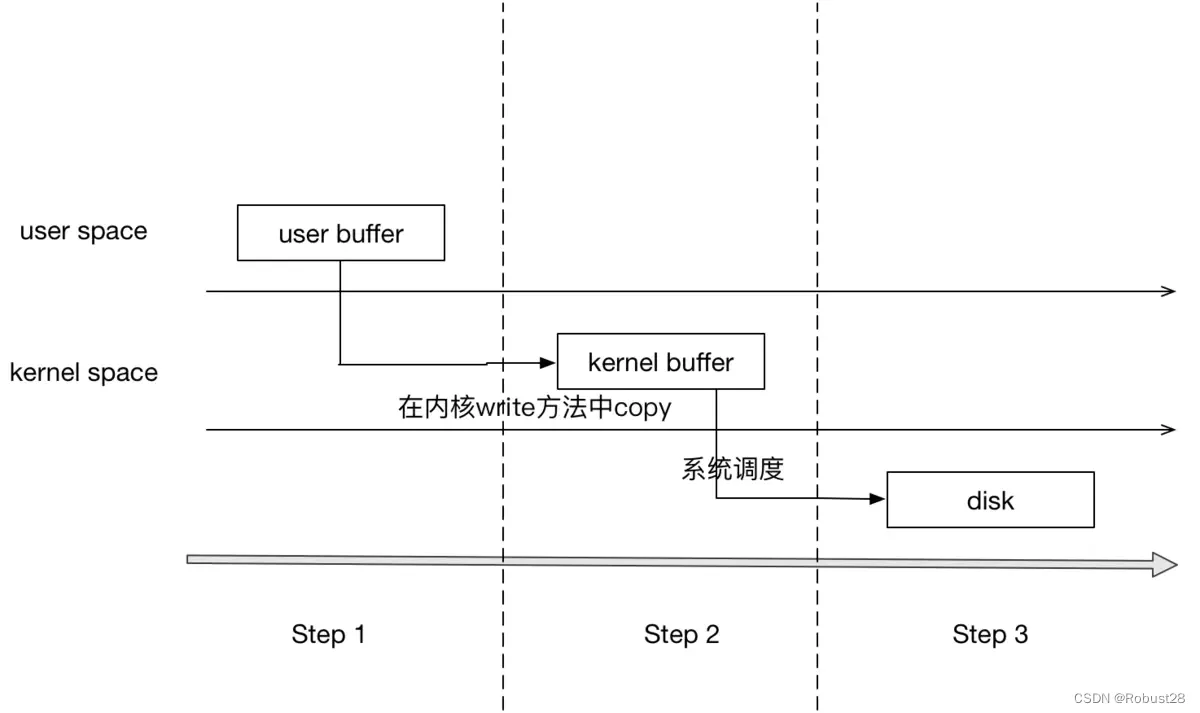
写文件流程:
-
调用write,告诉内核需要写入数据的开始地址和长度
-
内核将数据拷贝到内核缓存
-
由操作系统调用,将数据拷贝到磁盘,完成写入
2、MMAP内存映射
Linux通过将一个虚拟内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping)。

对文件进行mmap,会在进程的虚拟内存分配地址空间,创建映射关系
实现这样的映射关系后,就可以采用指针的方式读写操作这一段内存,而系统会自动回写到对应的文件磁盘上
3、MMAP优点
-
MMAP对文件的读写操作只需要从磁盘到用户主存的一次数据拷贝过程,减少了数据的拷贝次数,提高了文件读写效率。
-
MMAP使用逻辑内存对磁盘文件进行映射,操作内存就相当于操作文件,不需要开启线程,操作MMAP的速度和操作内存的速度一样快;
-
MMAP提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统如内存不足、进程退出等时候负责将内存回写到文件,不必担心 crash 导致数据丢失。
ProtoBuf
-
介绍
协议缓冲区提供了一种语言无关、平台无关、可扩展的机制,用于以向前兼容和向后兼容的方式序列化结构化数据。它类似于json、xml,只是它更小、更快,并且生成本地语言绑定。
协议缓冲区是定义语言(在.proto文件中创建)、proto编译器生成的用于与数据交互的代码、特定于语言的运行时库以及写入文件(或通过网络连接发送)的数据的序列化格式的组合。
-
Encoding(编码)
protobuf数据类型
| type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | groups (deprecated) |
| 4 | End group | groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
要理解简单的 protocol buffer编码,首先需要理解varints。varints是一种使用一个或多个字节序列化整数的方法。较小的数字占用较小的字节数。
varints中的每个字节,除了最后一个字节,都设置了最高有效位(MSB)-这表明还有更多的字节。每个字节的低7位,用于以7位为一组存储数字的二进制的补码,最低有效组优先。
例如,这里是数字1 -它是一个单字节,所以没有设置MSB:
0000 0001
这是300,16进制 AC 02 ,这有点复杂:
1010 1100 0000 0010
怎么算出这是300?首先你从每个字节中删除MSB,因为这只是告诉我们是否已经到达了数字的末尾(正如你所看到的,它被设置在第一个字节中,因为在varint中有多个字节):
1010 1100 0000 0010 → 010 1100 000 0010
您可以将两组7位颠倒过来,因为varint首先存储的是最低有效组的数字。然后将它们连接起来,得到最终值:
000 0010 010 1100 → 000 0010 ++ 010 1100 → 100101100 → 256 + 32 + 8 + 4 = 300
-
总结
比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于32位整型数据经过Varint编码后需要1~5个字节,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。64位整型数据编码后占用1~10个字节。在实际场景中小数字的使用率远远多于大数字,因此通过Varint编码对于大部分场景都可以起到很好的压缩效果。
这种编码方式,主要是去掉无用的前导0,来提高存储效率,降低存储空间。对于负数的编码使用zigzag压缩来降低无效的前导0,此处不在深入讨论,感兴趣的可以了解一下。
六、总结
1、存储占用空间对比

存储1000个int类型的数据所占空间:
SharePreference:39.9KB
mmkv:16KB
datastore:17.4KB
存储1000个String类型的数据所占空间:
SharePreference:46.8KB
mmkv:32KB
datastore:25.2KB
2、存储消耗时间对比
1000 Int类型 各种情况耗时
2022-09-19 09:29:52.594 4476-4476/com.share E/TAG: sp-commit-1645 ms 2022-09-19 09:30:19.315 4476-4476/com.share E/TAG: sp-Apply-175 ms
2022-09-19 09:30:30.146 4476-4476/com.share E/TAG: mmkv-13 ms
2022-09-19 09:30:51.976 4476-4476/com.share E/TAG: datastore-sync-7684 ms 2022-09-19 09:31:02.648 4476-4476/com.share E/TAG: datastore-async-4 ms
1000 String类型 各种情况耗时
2022-09-19 09:23:56.458 3668-3668/com.share E/TAG: sp-commit-1453 ms 2022-09-19 09:24:19.033 3668-3668/com.share E/TAG: sp-Apply-188 ms
2022-09-19 09:24:40.979 3668-3668/com.share E/TAG: mmkv-14 ms
2022-09-19 09:25:04.736 3668-3668/com.share E/TAG: datastore-sync-10010 ms 2022-09-19 09:25:18.600 3668-3668/com.share E/TAG: datastore-async-10 ms
存储耗时由于不同手机性能,会有一些差异。
datastore-async 看着时间很短,因为统计的是在主线程耗时,所有的操作在协程中完成,不阻塞主线程。
3、总结
-
如果你有多进程支持的需求,MMKV是唯一的选择。
-
如果你有高频写入的需求,优先考虑MMKV,但是它有很小的概率丢失数据,是否采取备份方案。
-
如果没有多进程和高频写入的需求,DateStore作为最完美的方案,优先被考虑。
-
如果没有使用kotlin和协程是没有办法使用DateStore的,但是官方提供RxDataStore来在java中使用。
-
在使用三种轻量级存储方式时候,建议按照模块或者功能区分,存储数据,来降低文件大小,提高文件读写效率。防止一个文件存储过多数据。
七、疑问补充
1、zigzag编码解码
压缩:如果是sint32、sint64先采用ZigZag编码后,进行varint方式压缩。
解码:对于有符号的sint32、sint64类型,解码先通过Varint解码,在通过zigzag解码。
对于正数通过zigzag编码后不变,对于负数通过zigzag编码后增加前导0。再通过varint方式,去掉前导0。
2、可能引起SharePreference的ANR的原因
目前安卓SharePreference引起ANR主要在8.0以下的低端手机上。
(1)8.0以上系统,如果同一Sp多次提交,只会执行最后一次写入文件操作。
8.0以下系统,如果同一Sp多次提交,会执行多次写入文件操作。
(2)android8.0之前,是将runnable任务加入到单线程的线程池中,
在多个生命周期方法中,在主线程等待任务队列去执行完毕,而由于cpu调度的关系任务队列所在的线程并不一定是处于执行状态的,而且当apply提交的任务比较多时,等待全部任务执行完成,会消耗不少时间,这就有可能出现ANR。
参考文档
MMKV--github
SharedPreferences
Datastore
自动生成proto文件