1,排序处理
1.1cluster by排序
,在Hive中使用order by排序时是全表扫描,且仅使用一个Reduce完成。
在海量数据待排序查询处理时,可以采用【先分桶再排序】的策略提升效率。此时,
就可以使用cluster by语法。
cluster by语句可以指定根据某字段将数据进行分桶,在桶内再根据这个字段进行正序排序
通俗地说,就是根据一个字段来排序,先分桶再排序。[分桶虚拟,自动处理]
cluster by语句的语法:
select * from 表名 cluster by 字段名; # 正序排序
– 程序中动态设定reduce值
set mapreduce.job.reduces = 桶数;
– 查看reduce值
set mapreduce.job.reduces;
当然了,若数据量较小(比如小于TB),Hive处理不占优势。
-- 查看reduce值
set mapreduce.job.reduces; -- 默认值是-1
set mapreduce.job.reduces = -1;
-- order by
select *
from tb_student
order by score; -- 数据量小: 效率高, 没有分桶操作
-- cluster by
select
*
from tb_student
cluster by score; -- 海量数据查询: 排序效率高
-- 看运行时间
-- 1.先直接测试order by与cluster by操作: 排序效果一样; 2.设定桶数,
看运行时间
当要先分桶再排序处理时,可以使用hive的cluster by
一般地,cluster by仅对字段做正序排序,即升序。
1.2distribute by+sort by排序
先分组,再排序的使用
select * from 表名 distribute by 字段名 sort by 字段名;
说明:
(1)distribute by表示先按字段名执行分组;
(2)sort by用于在分组内负责对某字段进行排序;
(3)当且仅当distribute by与sort by字段名一致时,等同于cluster by效果。
创建分桶表设定排序字段
create [external] table 表名(
字段名 字段类型 [comment '注释'],
字段名 字段类型 [comment '注释'],
...
)
[clustered by (字段名) sorted by (字段名) into 分桶数 buckets]
[row format delimited
fields terminated by '指定分隔符'];
2.排序操作:
①order by 普通排序
②over(order by ^) 窗口函数
③cluster by 先分桶在排序
④distribute by+ sort by 先分表后排序
⑤clustered by + sorted by 创建分桶表+自动排序
-- 1
select
*
from tb_student
distribute by gender
sort by score;
-- 3
create table tb_bucket_student(
id int,
name string,
gender string,
score double
)
clustered by (gender) sorted by (score) into 3 buckets
row format delimited
fields terminated by ",";
show tables ;
-- 4
-- 5
load data inpath "/itheima/student_data.txt" into table
tb_bucket_student;
-- 导入数据: hdfs
select * from tb_bucket_student;
(1)distribute by+sort by语句配合一起使用时,就是先分后排序的思想观
念;
(2)注意:当要提升对海量数据的访问效率时,一般可以对表进行分区或分
桶。
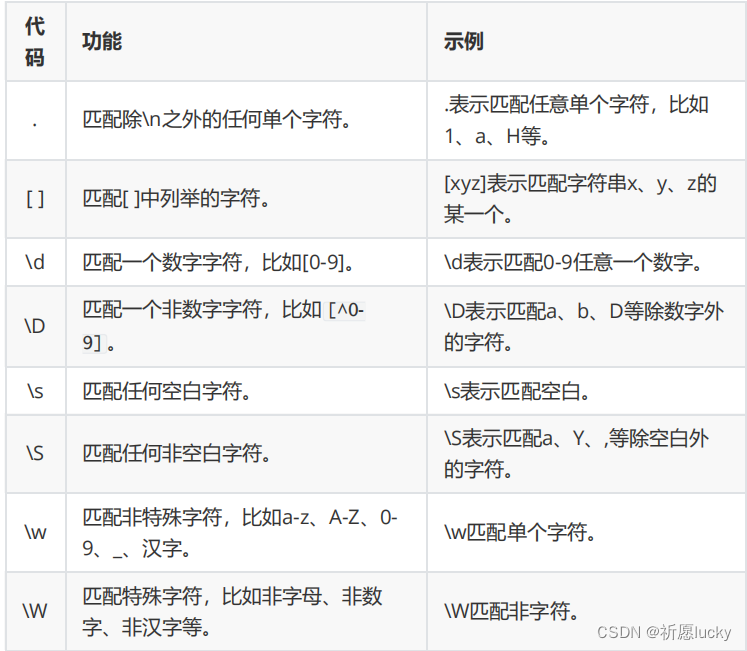
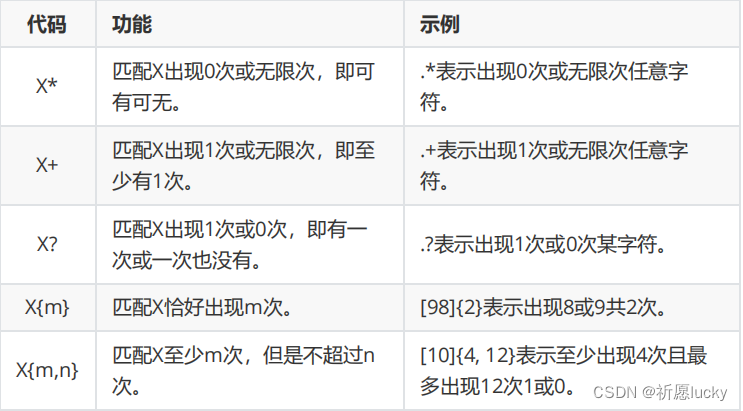
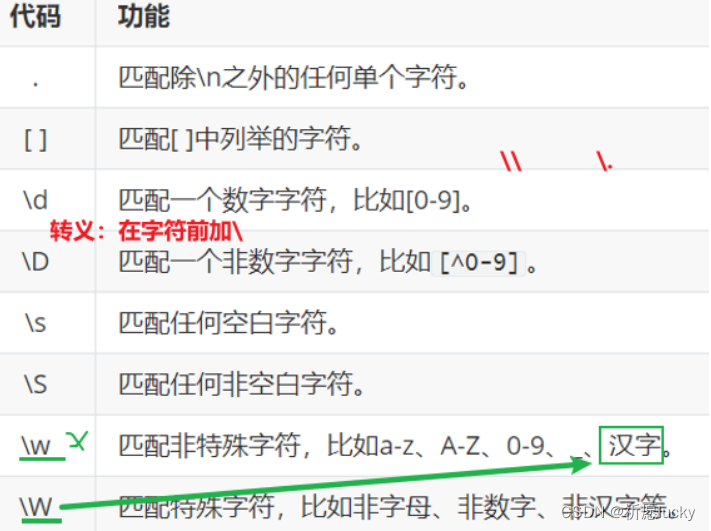
2.正则表达式
使用场景:在网站注册新用户时,对用户名、手机号等的验证就使用了正则表达式。
在Hive中,可以使用RLIKE进行正则匹配
select *|字段名1,字段名2,... from 表名 where 字段名 rlike "正则内容";

select
*
from tb_orders
where
userAddress rlike ".*广东省.*"
and
totalMoney > 5000;
-- 5
select
*
from tb_orders
where userAddress rlike ".*省 .*市 .*区.*";
正则就是一段特殊的字符串,而正则语法规范,需要多实践、多思考,才能更加熟练化。
3,union与CTE语法
3.1union联合
连接查询的特点是多个表进行【横向】合并在一起!
也可以完成纵向合并或追加数据操作。
union联合可用于将多个SELECT语句的结果集,组合形成单个完全结果集。
一起看看union联合,语法:
select 语句1
union [ all | distinct ]
select 语句2
[ union select 语句 ...];
说明:
(1)union all不对数据内容进行去重,默认使用union all;
(2)union distinct可实现数据去重,但必须添加distinct关键字;
(3)每个select语句返回的列数量、名称必须一致,否则,将引发字段架构错误。
-- 显示所有
select * from tb_course1
union all
select * from tb_course2;
select * from tb_course1 union select * from tb_course2; --
默认去重
-- 去掉重复
select * from tb_course1
union distinct
select * from tb_course2;
-- 先联合, 再根据条件筛选数据
select
*
from
(select * from tb_course1
union all
select * from tb_course2) temp_course
where name in ("周杰轮", "王力鸿");
-- where name="周杰轮" or name="王力鸿";
(1)union可以用于将多个SELECT结果集合并,但要注意结果集的字段名、类型等架构要一致;
当使用union语句完成自动去除数据重复值时,记得设定为union distinct
3.2CTE语法
CTE(Common Table Expressions的缩写)公用表表达式,表示临时结果集。
CTE是一个在查询中,定义的临时命名结果集,并可在from子句中使用它。语法:
with 别名 as
(select查询语句)
[别名 as (select查询语句), ...]
select查询语句;
说明:
(1)每个CTE仅被定义一次,可被引用任意次,但是一旦此查询语句结束,cte
就失效;
(2)注意,CTE表达式仅在单个语句的执行范围内定义,并取别名。[from前置]
with stu as (
select * from tb_student
)
select * from stu;
-- 3
-- 先取别名, 引用, 再过滤
with stu as (
select * from tb_student
)
select * from stu where stu.gender="男"; // 好理解
with stu as (
select * from tb_student
)
select * from stu where gender="男";
with语句可以配合union一起使用
为了便于掌握union关键字,我们会发现:当union联合多表时,可以当成是一张完整数据表
4. 抽样、虚拟列
4.1抽样tablesample
解决的问题:
当数据量特别大时,对全体数据进行处理存在困难时,就可以抽取部分数据来进行处理,则显得尤为重要。
我们已知晓,在大数据体系且是真实的企业环境中,很容易出现超大数据容量的表,比如体积达到TB/PB级别。
对这种表一个简单的SELECT * 都会非常的慢,
哪怕LIMIT 10想要看10条数据,
我们发现,有可能也会走MapReduce计算流程。
这种时间等待是漫长且不合适的......
Hive支持抽样,需要使用tablesample语法:
select * from 表名 tablesample (bucket x out of y [on colname字段名|rand()]);
说明:(1)y表示桶的数量,比如设定为值5,则表示5桶;
(2)x是要抽样的桶编号,桶编号从1开始计算,colname字段名表示抽样的列(也就是按照那个字段分桶);
(3)使用rand()表明在整个行中抽取样本而不是单个列;
(4)翻译为:按照colname字段名分成y桶,抽取其中的第x桶。
select
*
from tb_orders
-- tablesample ( bucket 1 out of 6 on userName); -- 数据倾斜
tablesample ( bucket 2 out of 6 on userName); -- 数据倾斜
-- 3
select
*
from tb_orders
tablesample ( bucket 4 out of 5 on orderNo);
-- 4
select
*
from tb_orders
tablesample ( bucket 2 out of 10 on rand());
当要快速从海量数据表中采样部分数据量,可以使用tablesample();函数;
(2)使用部分数据采样形式,能提升获取局部数据量的效率,便于在调试海量数据的程序时使用。
4.2虚拟列
虚拟列表示未在表中真正存在的字段,在创建分区表中,分区列就是虚拟列的一个体现!
为了将Hive中的表进行分区(partition),这对每日增长的海量数据存储而言,是非常有用的。
为了保证HiveQL的高效运行,强烈推荐在where语句后,使用虚拟列(分区列)作为限定。[拿Web日志举例说明。]
2,Hive中有3个可用的虚拟列:
(1)INPUT__FILE__NAME
显示数据行所在的具体文件
(2)BLOCK__OFFSET__INSIDE__FILE
显示数据行所在文件的偏移量
(3)ROW__OFFSET__INSIDE__BLOCK # 没提示, 且默认不开启-需设置参数
[单独说明]
显示数据所在HDFS块的偏移量
# 偏移量指的是获取数据时,指针所在位置
对于 ROW__OFFSET__INSIDE__BLOCK 虚拟列,要设置参数:
-- 查看数据在HDFS块的偏移量设置是否开启
set hive.exec.rowoffset;
-- 设置开启
set hive.exec.rowoffset=true;
-- 若要关闭, 则需要重新设置为false
-- 若要关闭, 则需要重新设置为false
set hive.exec.rowoffset=false;
-- 5
use sz41db_bucket;
show tables ;
select
*,
INPUT__FILE__NAME,
BLOCK__OFFSET__INSIDE__FILE
from bucket_id_course;
(1)简单地说,虚拟列就是Hive内置在查询语句中的几个特殊标记,可直接取用
(2)当要在查询结果中显示数据文件名信息,可以使用 INPUT__FILE__NAME虚拟列。
5,Hive基础函数
了解Hive函数有哪些分类?
在Hive中,有一些能直接被调用使用,比如类似于current_database()调用方式:
Hive的函数,可分为两大类:
(1)内置函数(Built-in Functions)
数学函数
日期函数
字符串函数
条件函数
类型转换函数
数据脱敏函数
(2)用户定义函数(User-Defined Functions)
UDF(User Defined Functions)用户定义功能函数
UDAF(User Defined Aggregate Functions)用户定义聚合函数
UDTF(User Defined Table-generating Functions)用户定义表生成函数
内置函数属于Hive基础函数、用户定义函数属于Hive进阶函数。
-- 查看可用的所有函数
show functions;
-- 查看函数的使用方式
desc function extended 函数名;
当要查看某函数如何使用时,可以使用desc function extended 函数名语句查看帮助信息
在Hive中,当要使用函数时, 语法为[select 函数名(xx);]。
5.1]数学函数
rand() 获取一个完全随机数,取值范围0-1。 double
round(x [, y]) 取整/设置小数精度(四舍五入)。 double
select round(3.141592654,2);
select round(3.141592654);
-- 3
select rand()*100;
select round(rand()*100);
当要保留浮点数后几位小数时,推荐使用round()函数
一般地,数学函数主要是用于处理各类数值型内容项
5.2日期函数
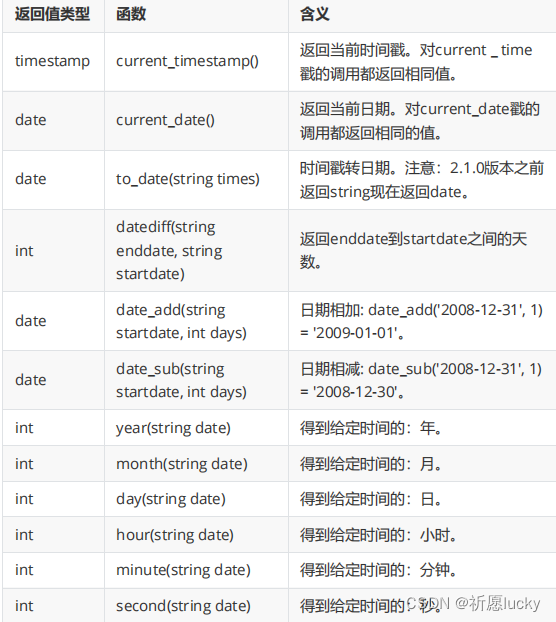
select current_date();
desc function extended year; -- 有用
select year(`current_date`());
select year(`current_timestamp`());
select year("2023-11-14");
-- desc function extended month;
select month(current_date());
select day(current_date());
desc function extended hour;
select hour(current_timestamp());
select minute(current_timestamp());
select second(current_timestamp());
(2)通常情况下,当要处理时间日期时,要想到Hive中常用的日期函数。
5.3字符串函数
在Hive中,常用的字符串函数有:

-- 1
select concat("hello","WORLD");
select concat_ws("=","hello","WORLD");
-- 1-10-100-20
select split("1-10-100-20","-");
select split("1-10-100-20","-")[0];
-- 2
-- Hello Heima
select length("Hello Heima");
select lower("Hello Heima");
select upper("Hello Heima");
-- 3
-- 2022-08-22 17:28:01
-- 通过日期函数year()
select year("2022-08-22 17:28:01");
-- 截取
select substr("2022-08-22 17:28:01",0,3); // 无法截取到结束位end
select substr("2022-08-22 17:28:01",0,4);
-- select substring()
-- 分割, 提取
select split("2022-08-22 17:28:01","-")[0];
字符串函数通常用于处理string、varchar等字符串类型的数据结果。
5.4条件函数、转换类型
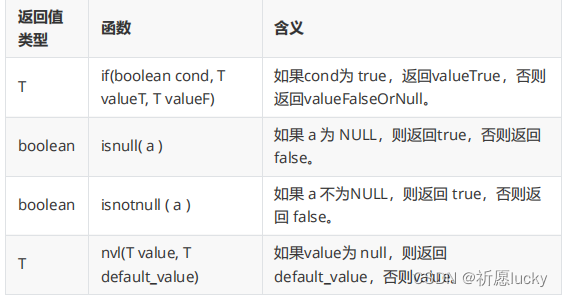
1,类型转换函数有:
cast(expras) 将expr值强制转换为给定类型type。例如,cast(‘1’ as int会将字符串 ‘1’ 转换为整数。
select current_database();
-- if
select if(1=1,"男","女");
select if(1=0,"男","女"); -- 等号 =; 后期编程语言中, 等号==
-- isnull
select isnull(null);
select isnull("hello"); -- 没约束, 判断
-- isnotnull
select isnotnull(null);
select isnotnull("hello");
select nvl(null,18); -- 没有年龄值, 则默认为18岁
select nvl(20,18);
-- cast
select cast("100" as int);
select cast(12.14 as string); -- double
select cast("hello" as int);
-- 1700096276154
select cast(1700096276154/1000 as int); -- 1700096276 秒[10位数]-格式
强制类型转换在Hive中不一定成功,若不成功,则会返回null值。
5.5 数据脱敏函数
我们知道,当把元数据存储在MySQL中,需要将元数据中敏感部分(如身份证、电话号码等)进行脱敏处理,再供用户使用
通俗地说,就是进行掩码处理,或者加密处理。

select mask_hash("123ABC");
select mask("123ABC");
select mask("AB12aa"); -- XXnnxx
-- 2
select mask_first_n("AA11nn8989AAAAAAA",4);
select mask_last_n("AA11nn8989AAAAAAA",4);
select mask_show_first_n("it66ABCDE",3);
select mask_show_last_n("it66ABCDE",3);
,要做数据脱敏操作,可以根据mask单词看DataGrip的快捷提示,并选择使用某个。
5.6其他函数
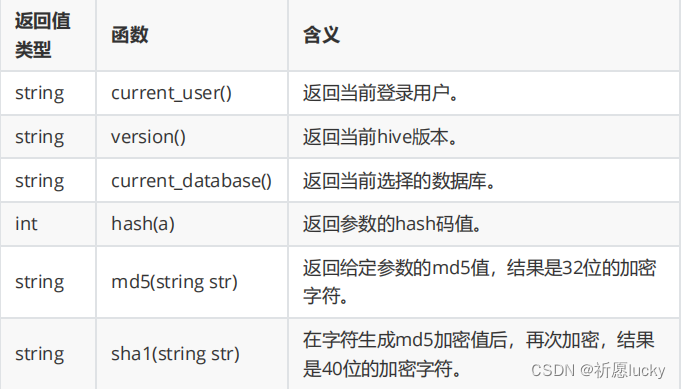
select hash("123456"); -- hash 哈希算法(散列算法) = 哈希码
select md5("123456"); -- e10adc3949ba59abbe56e057f20f883e
32位/不可逆的 动态值绑定了结果?
select sha1("123456"); --
7c4a8d09ca3762af61e59520943dc26494f8941b
-- 3
select length("e10adc3949ba59abbe56e057f20f883e");
select length("7c4a8d09ca3762af61e59520943dc26494f8941b");
-- 4 转换日期格式 转换为年月日 1700096276154
desc function date_format;
desc function from_unixtime;
-- a.把毫秒转换为秒, int
select cast(1700096276154/1000 as int);
-- b.使用函数即可
select from_unixtime(cast(1700096276154/1000 as int),"yyyyMM-dd");
select year(from_unixtime(cast(1700096276154/1000 as int),"yyyy-MM-dd"));
对于Hive函数的使用,若在应用中,还发现有新需求,可以通过查阅Hive函数资料来解决。
6.Hive高阶函数
用户自定义函数有:
用户定义函数(User-Defined Functions)
(1)UDF(User Defined Functions)用户定义功能函数
(2)UDTF(User Defined Table-generating Functions)用户定义表生成函数
(3)UDAF(User Defined Aggregate Functions)用户定义聚合函数
说明:
(1)最初,UDF、UDAF、UDTF这3个标准,是针对用户自定义函数分类的;
(2)目前,可以将这个分类标准直接扩大到Hive中的所有函数,包括内置函数和自定义函数
(1)UDF(User Defined Functions)用户定义功能函数
UDF函数可以理解为:普通函数。用于一进一出,即当输入一行数据时,则输出一行数据。比较常见的有split()分割函数。
select split("10-20-30-40","-");
-- 结果: ["10","20","30","40"]
(2)UDTF(User Defined Table-generating Functions)用户定义表生成函数
UDTF用于表生成函数。用于一进多出,即当输入一行时,则输出多行数据。比较常见的有:explode()。
(3)UDAF(User Defined Aggregate Functions)用户定义聚合函数
UDAF可表示为:聚合函数。用于多进一出,即当输入多行时,则输出一行数据。
6.1窗口函数
select
字段名, …
窗口函数() over([partition by xx order by xx [asc | desc]])
from 表名;
说明:
(1)窗口函数名可以是聚合函数,例如sum()、count()、avg()等,也可以是分
析函数;
(2)聚合函数有count()、sum()、avg()、min()、max();
(3)分析函数有row_number、rank、dense_rank等;
(4)partition by用于分组、order by用于排序。
当要把某数据列添加到数据表时,可以使用窗口函数over()关键字
6.2json数据处理
JSON的全称是:JavaScript Object Notation,即JS对象标记法。在很多开发场景里,JSON数据传输很常见!
(1)数组(Array)用中括号[ ]表示;
(2)对象(0bject)用大括号{ }表示。
说明:在Hive中,没有json类的存在,一般使用string类型来修饰,叫做json字符串。
get_json_object(json_txt, path) 用于解析json字符串
说明:path参数通常可用于获取json中的数据内容,语法:“$.key”。
select
get_json_object(data,"$.device")
from json_device;
select
get_json_object(data,"$.device") device,
get_json_object(data,"$.deviceType") divece_type,
get_json_object(data,"$.signal") signal,
get_json_object(data,"$.time") int_time
from json_device;
split(from_unixtime(cast(get_json_object(data,"$.time")/1000
as int),"yyyy/MM/dd"),"/")[0] year,
6.3 炸裂函数
explode()可用于表生成函数,一进多出,即当输入一行时,则输出多行数据。
通俗地说,就是可以使用explode()炸开数据。
explode(array | mapdata)
用于炸裂数据内容,并分开数据结果。
通常情况下,炸裂函数会与侧视图配合一起使用。
侧视图(lateral view)原理是:
(1)将UDTF的结果构建成一个类似于视图的表;
(2)然后,将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。
ateral view侧视图语法:
select ... from 表A 别名
lateral view
UDTF(xxx) 别名 as 列名1, 列名2, 列名3, ...;
create table table_nba(
team_name string,
champion_year array<string>
) row format delimited
fields terminated by ','
collection items terminated by '|';
select * from tb_nba;
-- a.单独获取到冠军年份
select
explode(champion_year)
from tb_nba;
-- b.显示出来??
select
*,
explode(champion_year) //报错了
from tb_nba;
-- 对year进行一个升序排序处理
select
*
from
(select
a.team_name,
b.year
from tb_nba a
lateral view
explode(champion_year) b as year) temp_nba
order by temp_nba.year;
select
*
from
(select
a.team_name,
b.year
from tb_nba a
lateral view
explode(champion_year) b as year) temp_nba
order by cast(temp_nba.year as int);
炸裂函数把数据炸开后,若在处理时遇到一些问题,可以考虑引入侧视图配合使用