1.安装地址
(1) Flume官网地址:http://flume.apache.org/
(2)文档查看地址:http://flume.apache.org/FlumeUserGuide.html
(3)下载地址:http://archive.apache.org/dist/flume/
2.安装部署
注意:前提是配置好java环境
(1)将apache-flume-1.10.1-bin.tar.gz上传到linux的/opt/package/目录下
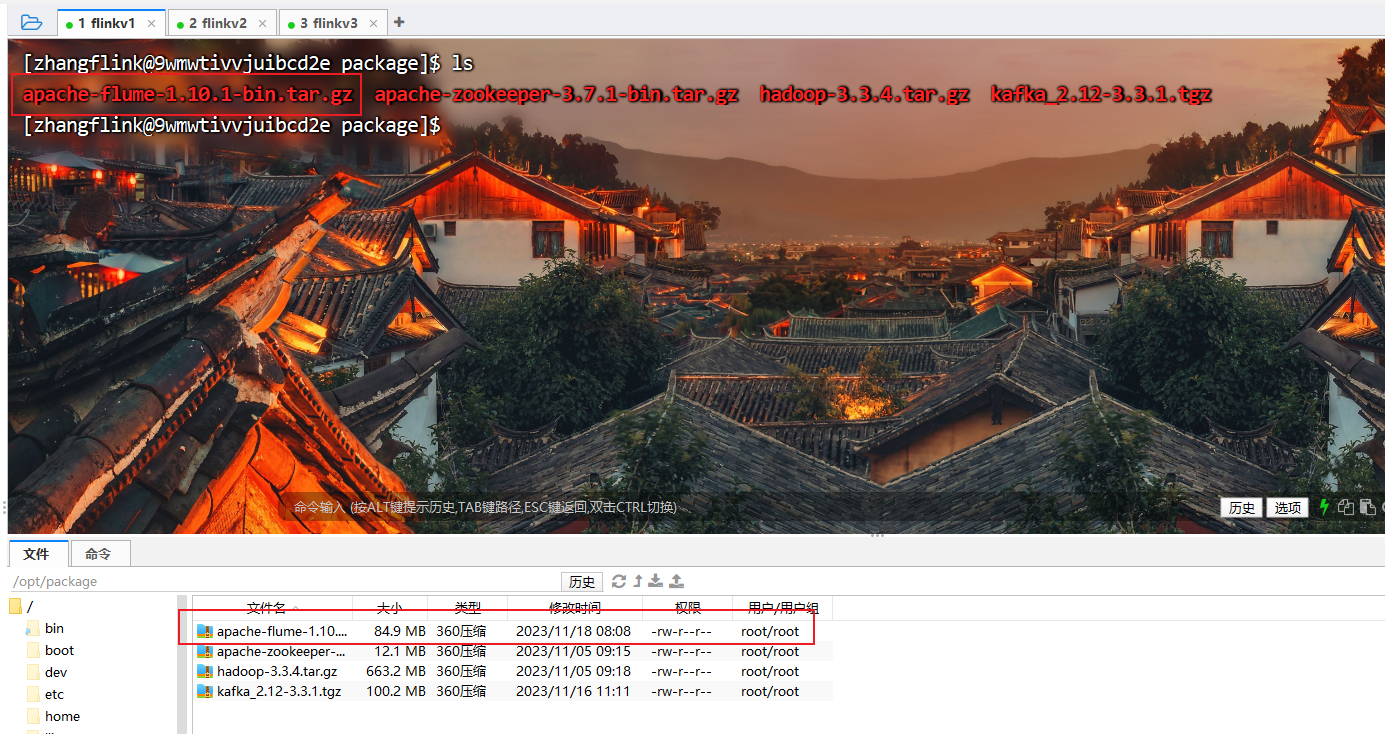
(2)解压apache-flume-1.10.1-bin.tar.gz到/opt/software/目录下
[zhangflink@9wmwtivvjuibcd2e package]$ tar -zxvf apache-flume-1.10.1-bin.tar.gz -C /opt/software/
(3)修改apache-flume-1.10.1-bin的名称为flume
[zhangflink@9wmwtivvjuibcd2e software]$ mv apache-flume-1.10.1-bin/ flume
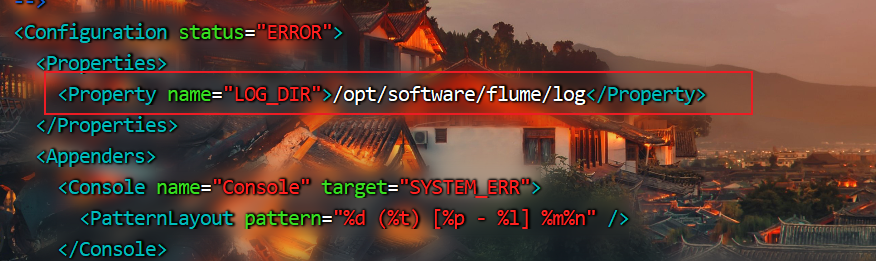
(4)修改conf目录下的log4j2.xml配置文件,配置日志文件路径
修改日志路径
<Property name="LOG_DIR">/opt/module/flume/log</Property>
<AppenderRef ref="Console" />
编写配置文件
官网翻译成中文的网站,可以参考这个网站进行编写配置文件:https://flume.liyifeng.org/
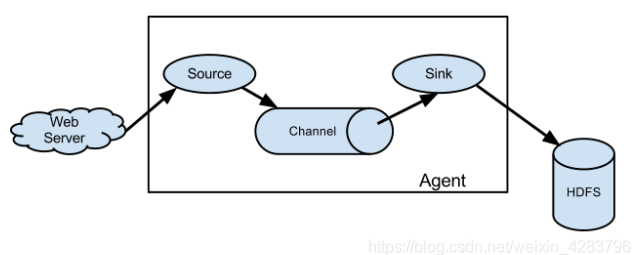
(1).Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有三个组成部分,Source、Channel、Sink。
(2).第一步:配置各个组件,根据你采集数据的需求进行选择对应的source,channels,sinks组件(直接去参考官网对应的组件功能选择即可)。
(3).第二步:连接各个组件,把采集端(Flume Sources),中间缓存(Flume Channels)和写入端(Flume Sinks)连接到一起。
(4).第三步:启动Agent。
bin目录下的flume-ng是Flume的启动脚本,启动时需要指定Agent的名字、配置文件的目录和配置文件的名称。
bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
-n后面就是agent的主节点,-f 后面就是配置文件的位置,其它不变。
常用案例
监听端口配置:
# example.conf: 一个单节点的 Flume 实例配置
# 配置Agent a1各个组件的名称
#Agent a1 的source有一个,叫做r1
a1.sources = r1
#Agent a1 的sink也有一个,叫做k1
a1.sinks = k1
#Agent a1 的channel有一个,叫做c1
a1.channels = c1
# 配置Agent a1的source r1的属性
#使用的是NetCat TCP Source,这里配的是别名,Flume内置的一些组件都是有别名的,没有别名填全限定类名
a1.sources.r1.type = netcat
#NetCat TCP Source监听的hostname,这个是本机
a1.sources.r1.bind = localhost
#监听的端口
a1.sources.r1.port = 44444
# 配置Agent a1的sink k1的属性
# sink使用的是Logger Sink,这个配的也是别名
a1.sinks.k1.type = logger
# 配置Agent a1的channel c1的属性,channel是用来缓冲Event数据的
#channel的类型是内存channel,顾名思义这个channel是使用内存来缓冲数据
a1.channels.c1.type = memory
#内存channel的容量大小是1000,注意这个容量不是越大越好,配置越大一旦Flume挂掉丢失的event也就越多
a1.channels.c1.capacity = 1000
#source和sink从内存channel每次事务传输的event数量
a1.channels.c1.transactionCapacity = 100
# 把source和sink绑定到channel上
#与source r1绑定的channel有一个,叫做c1
a1.sources.r1.channels = c1
#与sink k1绑定的channel有一个,叫做c1
a1.sinks.k1.channel = c1
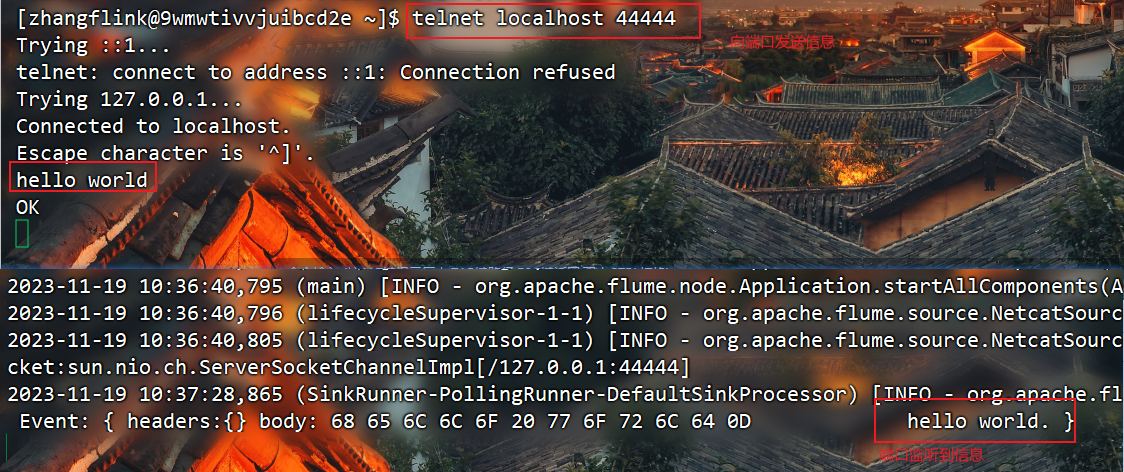
启动agent
bin/flume-ng agent -n a1 -c conf -f conf/example.conf
监听文件写入HDFS里面
# file_chanel_hdfs.conf: 一个监听文件数据写入hdfs的实例配置
# 配置Agent a1各个组件的名称
#Agent a1 的source有一个,叫做r1
a1.sources = r1
#Agent a1 的sink也有一个,叫做k1
a1.sinks = k1
#Agent a1 的channel有一个,叫做c1
a1.channels = c1
#监听文件的source,这个source支持断点续传可靠性更高
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/software/flume/text_log/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /opt/software/flume/text_log/example.log
a1.sources.r1.headers.f1.headerKey1 = value1
a1.sources.r1.filegroups.f2 = /opt/software/flume/text_log/.*log.*
a1.sources.r1.headers.f2.headerKey1 = value2
a1.sources.r1.headers.f2.headerKey2 = value2-2
a1.sources.r1.fileHeader = true
a1.sources.ri.maxBatchCount = 1000
# 配置Agent a1的sink k1的属性
#写入HDFS的sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://10.0.3.141:8020/flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.timeZone = Asia/Shanghai
# 配置Agent a1的channel c1的属性,channel是用来缓冲Event数据的
#channel的类型是内存channel,顾名思义这个channel是使用内存来缓冲数据
a1.channels.c1.type = memory
#内存channel的容量大小是1000,注意这个容量不是越大越好,配置越大一旦Flume挂掉丢失的event也就越多
a1.channels.c1.capacity = 1000
#source和sink从内存channel每次事务传输的event数量
a1.channels.c1.transactionCapacity = 100
# 把source和sink绑定到channel上
#与source r1绑定的channel有一个,叫做c1
a1.sources.r1.channels = c1
#与sink k1绑定的channel有一个,叫做c1
a1.sinks.k1.channel = c1
启动后可能遇到的问题及解决方法

原因是普通用户没有创建文件的权限,使用root权限启动即可
sudo bin/flume-ng agent -c conf -n a1 -f conf/file_chanel_hdfs.conf

原因是因为写入到hfds时使用到了时间戳来区分目录结构,flume的消息组件event在接受到之后在header中没有发现时间戳参数,导致该错误发生,有三种方法可以解决这个错误;
1、agent1.sources.source1.interceptors = t1
agent1.sources.source1.interceptors.t1.type = timestamp
为source添加拦截,每条event头中加入时间戳;(效率会慢一些)
2、agent1.sinks.sink1.hdfs.useLocalTimeStamp = true 为sink指定该参数为true
(如果客户端和flume集群时间不一致数据时间会不准确)
3、在向source发送event时,将时间戳参数添加到event的header中即可,header是一个map,添加时mapkey为timestamp(推荐使用)
我使用了第二种方法(如果实时链路中,一般数据中都会带有时间戳,要使用第一种方法,保证时间语义的准确性)。


遇到这个错误是sink配置语句中创建hdfs的路径报错
要和hadoop里面的core-site.xml 文件保持一致
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://flinkv1:8020</value>
</property>

此问题是由于操作hdfs的文件权限不足,修改hdfs文件权限即可。
[zhangflink@9wmwtivvjuibcd2e flume]$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - zhangflink supergroup 0 2023-11-19 11:04 /flume
[zhangflink@9wmwtivvjuibcd2e flume]$ hdfs dfs -chmod 777 /flume
[zhangflink@9wmwtivvjuibcd2e flume]$ hdfs dfs -ls /
Found 1 items
drwxrwxrwx - zhangflink supergroup 0 2023-11-19 11:04 /flume
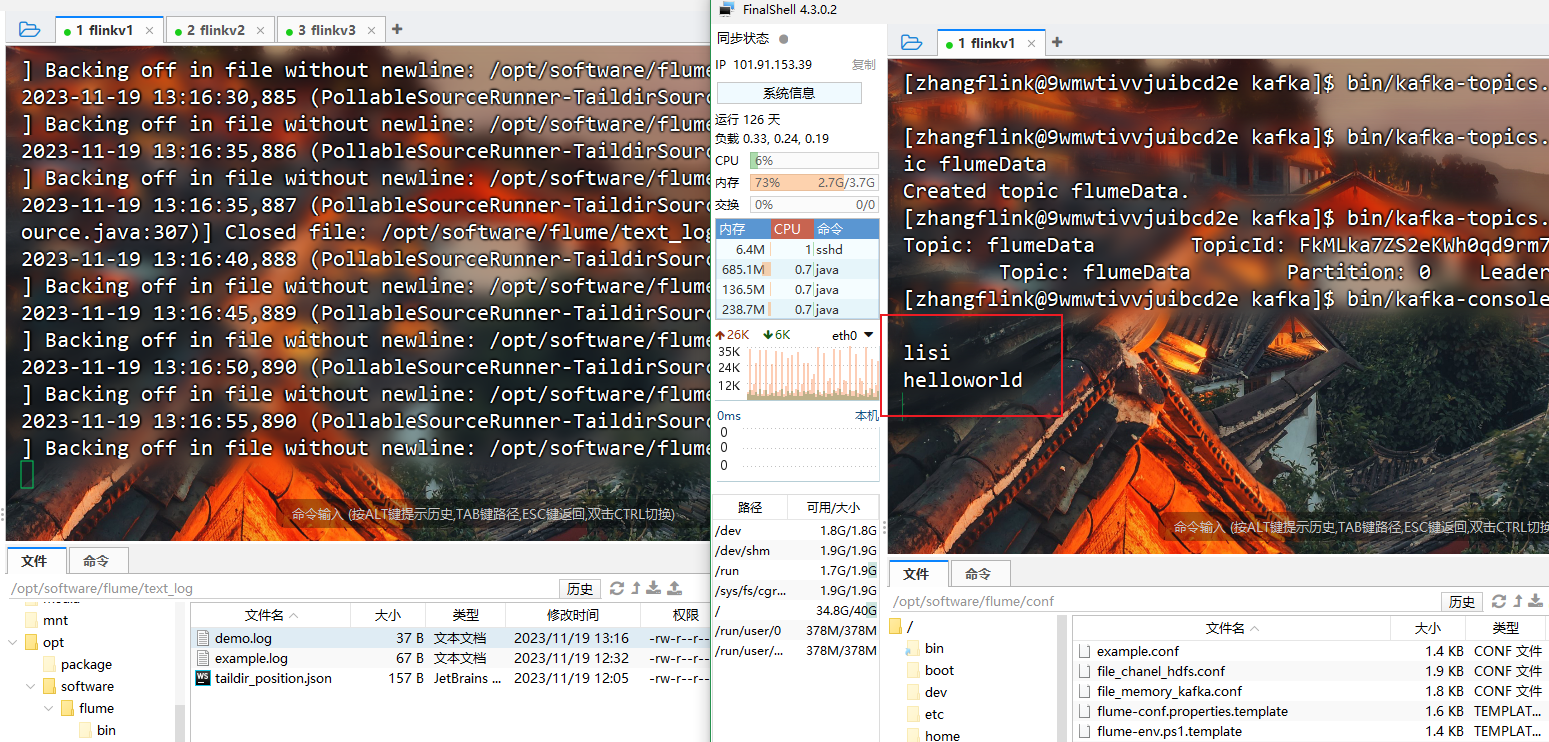
启动成功数据写入


监听文件写入kafka里面
首先创建kafka的topic
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-topics.sh --bootstrap-server flinkv1:9092 --create --partitions 1 --replication-factor 3 --topic flumeData
编写配置文件:
# file_memory_kafka.conf: 一个监听文件数据写入hdfs的实例配置
# 配置Agent a1各个组件的名称
#Agent a1 的source有一个,叫做r1
a1.sources = r1
#Agent a1 的sink也有一个,叫做k1
a1.sinks = k1
#Agent a1 的channel有一个,叫做c1
a1.channels = c1
#监听文件的source,这个source支持断点续传可靠性更高
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/software/flume/text_log/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /opt/software/flume/text_log/example.log
a1.sources.r1.headers.f1.headerKey1 = value1
a1.sources.r1.filegroups.f2 = /opt/software/flume/text_log/.*log.*
a1.sources.r1.headers.f2.headerKey1 = value2
a1.sources.r1.headers.f2.headerKey2 = value2-2
a1.sources.r1.fileHeader = true
a1.sources.ri.maxBatchCount = 1000
# 配置Agent a1的sink k1的属性
#写入kafka的sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = flumeData
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
# 配置Agent a1的channel c1的属性,channel是用来缓冲Event数据的
#channel的类型是内存channel,顾名思义这个channel是使用内存来缓冲数据
a1.channels.c1.type = memory
#内存channel的容量大小是1000,注意这个容量不是越大越好,配置越大一旦Flume挂掉丢失的event也就越多
a1.channels.c1.capacity = 1000
#source和sink从内存channel每次事务传输的event数量
a1.channels.c1.transactionCapacity = 100
# 把source和sink绑定到channel上
#与source r1绑定的channel有一个,叫做c1
a1.sources.r1.channels = c1
#与sink k1绑定的channel有一个,叫做c1
a1.sinks.k1.channel = c1
消费对应topic测试数据是否写入
[zhangflink@9wmwtivvjuibcd2e kafka]$ bin/kafka-console-consumer.sh --bootstrap-server flinkv1:9092 --from-beginning --topic flumeData
监听成功
![[qemu逃逸] DefconQuals2018-EC3](https://img-blog.csdnimg.cn/5aa463d551814949afbae96903a3eee8.png)