1 文章信息
文章题为“Learning Geo-Contextual Embeddings for Commuting Flow Prediction”,是一篇发表于The Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI-20)的一篇论文。该论文主要针对交通中OD流预测任务,从地理上下文信息中捕获空间相关性,同时设置多任务学习,确保嵌入表示的有效性,提升模型性能。
2 摘要
基于基础设施和土地利用信息预测起讫点(Origin-Destination, OD)流量对城市规划和公共政策制定至关重要。然而,由于OD流的时空规律较为复杂,因此实现OD流的准确预测是一项具有挑战性的任务。大多数现有的基于机器学习的方法忽略了空间相关性,无法对附近区域的影响进行建模。为解决这些问题,文章提出了地理上下文多任务嵌入学习(GMEL)模型,该模型从地理上下文信息中捕获空间相关性,用于通勤流量预测。具体来说,我们首先构建了一个包含地理上下文信息的地理邻接网络。在此基础上,提出了一种基于图注意网络(GAT)框架的注意机制,用于捕获空间相关性,并将地理上下文信息编码到嵌入空间中。两个单独的服务贸易总协定被用来模拟供给和需求特征。为提高嵌入表示的有效性,文章使用了一个多任务学习框架来引入更强的限制,获得有效的嵌入表示,从而进行流量预测。最后,基于模型所学习的嵌入训练一个梯度增强机(gradient boosting machine),实现OD流预测。文章使用来自纽约市的真实数据集评估我们的模型,实验结果证明了文章提出的方法的有效性。本文的主要贡献如下:
1、文章提出了一个从地理上下文信息中捕获空间相关性的模型(GMEL),并基于图注意力网络将信息编码到嵌入空间中。
2、文章使用来自纽约市的真实世界数据集进行广泛的实验。结果表明GMEL的有效性。
3 基本概念
地理单元:文章将城市划分为N个地理单元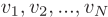 ,例如街道等。
,例如街道等。
城市指标:城市指标是一个向量,表示地理单元的城市指标特征,描述了地理单元的基础设施和土地利用的汇总信息。
通勤旅行记录(OD)及问题定义:文章用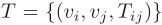 表示通勤旅行记录,其中表示地理单元i和地理单元j之间的通勤流量,即所谓的OD流量。文章旨在利用历史通勤流量(或OD流量)预测未来的通勤流量(或OD流量)。
表示通勤旅行记录,其中表示地理单元i和地理单元j之间的通勤流量,即所谓的OD流量。文章旨在利用历史通勤流量(或OD流量)预测未来的通勤流量(或OD流量)。
4 模型结构
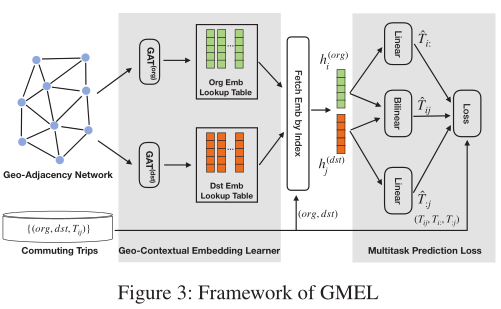
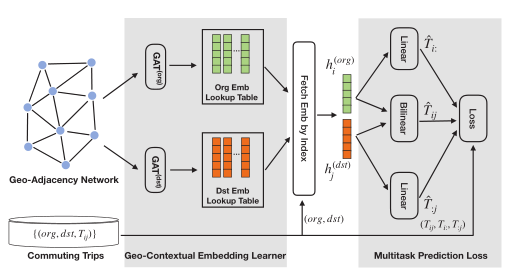
地理语境多任务嵌入学习器(Geo-contextual Multitask Embedding Learner, GMEL):
GMEL旨在从地理环境中捕获空间相关性。GMEL利用图注意网络将地理上下文信息编码到嵌入空间中。为提取蕴含在基础设施和土地使用中的供需特征,GMEL采用两个单独的GAT将地理上下文信息编码到两个不同的嵌入空间中。为了确保嵌入表示的有效性,GMEL采用了多任务学习框架,该框架施加了更强的限制,迫使嵌入封装有效表示,从而实现OD预测。
预测器:结合GMEL学习到的嵌入表示,文章使用GBM(gradient boosting machine)作为回归模型实现OD流域测。
GMEL旨在学习对城市地理单元进行有效嵌入,并对地理上下文信息进行编码。为了分别学习每个地理单元的供给和需求特征,该模型使用两个单独的GAT来编码这些信息。然后将生成的嵌入应用于双线性函数来预测流量。同时,这些嵌入也将应用于两个线性函数来预测地理单元的流入/流出。整体预测损失是三个任务损失的加权和,文章使用反向传播以端到端方式训练GMEL。模型的整体结构如下图所示。
图注意力网络(GAT):假设第l层中,节点i的状态为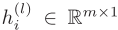 ,同时地理单元i和地理单元j之间的边特征为
,同时地理单元i和地理单元j之间的边特征为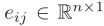 ,GAT首先对所有向量进行线性变化,如下式所示。
,GAT首先对所有向量进行线性变化,如下式所示。
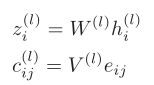
其中,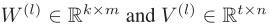 是可学习参数。进一步计算每个边的注意力得分,
是可学习参数。进一步计算每个边的注意力得分,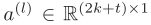 是可学习参数。
是可学习参数。
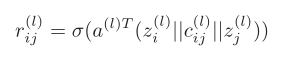
进一步,将上述注意力得分通过softmax归一化,并进行汇总求得第l+1层,节点i的状态表示。其中,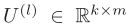 是可学习参数。
是可学习参数。
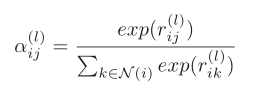
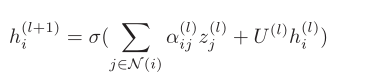
供需特征建模:通勤流量(OD流量)可以被视为供给和需求之间的一种空间互动,文章假设流动是由起源地理单元的供给特征和目的地地理单元的需求特征决定的。文章使用两个单独的GAT网络分别对起点和终点的特征进行提取,并将不同结果进行汇总。
多任务学习:模型包括一个主任务和两个子任务,其中,主任务为预测通勤流量(OD流量),依据两个单独的GAT网络的输出,通过下式计算未来OD流。
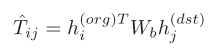
对应的损失函数如下。
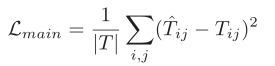
子任务为进站流和出站流的预测,文章将进出预测作为两个子任务,即预测每个地理单元的进出站总数。直觉上,通勤流量和进出流量是高度相关的,因此,这两个子任务将对GMEL的训练过程施加更强的限制。同样,分别依据两个GAT模型的输出,分别计算进站流和出站流,如下所示。
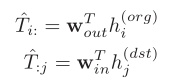
对应损失函数如下。
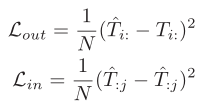
总损失函数为上述三个任务对应损失的加权求和,如下式所示。其中,不同任务的权重为超参数。
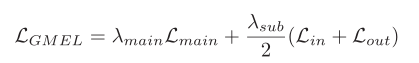
模型的训练算法如下所示。

5 实验
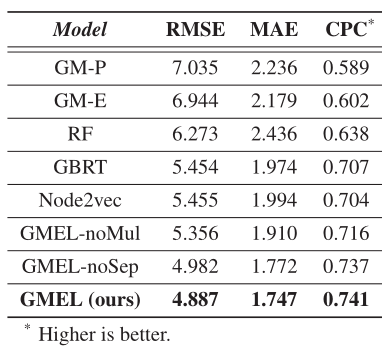
文章在纽约市的真实数据集上验证了所提出的模型,同时文章使用2010年纽约市人口普查区作为地理单位(总共2168个单位)。对于通勤行程和城市指标,文章使用了以下数据集和方法:(1)OD数据集:LODES,该数据集记录了工人的住所和工作地点,代表了稳定的通勤流量。这些流量被聚合成地理单元级流。在纽约市收集了3031641名通勤者和905837对始发目的地旅行。文章以6:2:2的比例将通勤数据随机分为训练、验证和测试数据集;(2)土地利用数据:PLUTO,该数据集记录了2015年纽约市的土地利用和基础设施信息;(3)OSRM,该方法用于测量人口普查区质心之间的旅行距离。实验结果如下所示。
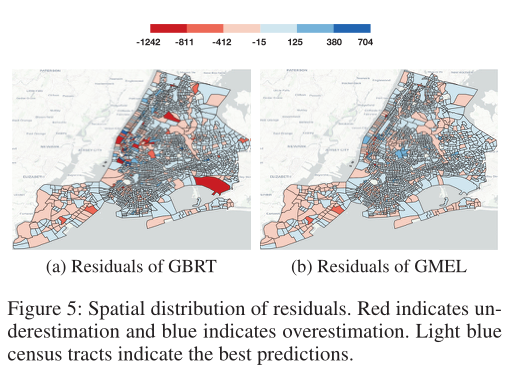
进一步,文章为说明利用空间相关性的有效性,绘制了残差图,如下图所示。这些残差图显示了预测和实际流入流量之间的差异,其中红色表示预测值低于真实值,蓝色表示预测值高于真实值,浅蓝色表示预测值和真实值基本一致。GMEL利用地理背景信息捕捉空间相关性,能够考虑到感兴趣区域的特征和附近区域的影响。
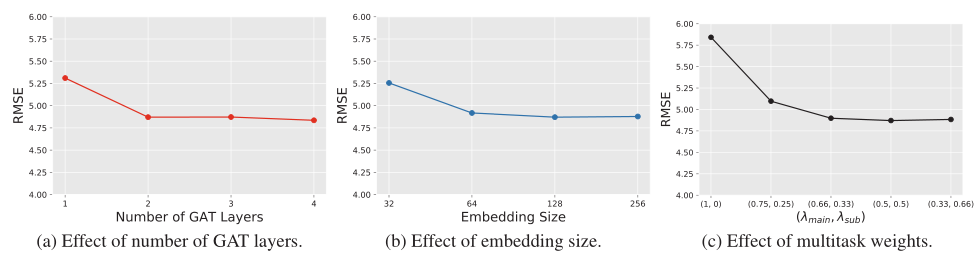
此外,文章还对模型的参数进行分析,如下图所示。包括GAT的层数,嵌入的大小以及多任务学习的权重,如下图所示。值得一提的是,多任务学习权重的最优取值为(0.5,0.5)。
6 总结
本文研究了仅利用基础设施和土地利用信息预测通勤流量的问题,这是城市规划和公共政策制定中的一个基本问题。与传统的重力模型和最近提出的机器学习方法不同,文章提出使用地理上下文信息进行通勤流量预测。为此,文章提出了一种基于图注意网络的端到端嵌入学习框架,用于学习地理单元的地理上下文嵌入。然后将学习到的嵌入输入到梯度增强机器中进行预测。文章利用纽约市的真实数据集进行了广泛的实验。结果表明,引入地理环境信息可以大大提高预测的准确性,并且文章所提出的模型优于所有基线方法。