当我们试图提高神经网络的准确性时,经常会遇到过拟合训练数据的情况。当我们运行测试数据的模型时,这会导致一个糟糕的预测。因此,我采取了一个数据集,并应用这些技术,不仅提高准确性,而且还处理过拟合的问题。
在本文中,我们将使用以下技术在不到5分钟的时间内训练一个最先进的模型,以达到从 Fruit 360数据集中分类图像的95% 以上的准确率:
数据增强
数据分析中的数据增强是通过对现有数据或从现有数据中新创建的合成数据进行稍加修改的“副本”来增加数据量的技术。在训练机器学习模型时,它起到调节器的作用,有助于减少过拟合。
批量归一化
批量归一化是一种训练非常深入的神经网络的技术,它标准化每个小批量的输入到一个层。这有助于稳定学习过程,大大减少训练深层网络所需的训练时期。
学习率策略
学习率策略用于寻求调整学习率在训练期间通过降低学习率根据预先确定的调度器。常见的学习率策略包括基于时间的衰减,阶跃衰减和指数衰减。
权重衰减
我们使用权重衰减来保持较小的权重值,避免梯度爆炸。因为权重值将会经过L2标准化后加入到损失中,你的网络的每次迭代除了损失之外都会试图优化/最小化模型权重。这将有助于保持尽可能小的权重值,防止权重增长失控,从而避免梯度爆炸。
梯度裁剪
使用梯度裁剪可以防止梯度在神经网络中爆炸。梯度裁剪限制梯度的大小。计算梯度裁剪的方法有很多种,但一种常见的方法是重新调整梯度。
Adam 优化器
这一系列的优化器被引入来解决梯度下降法的算法问题。它们最重要的特点是不需要调整学习率值。实际上,有些库ーー例如 Keras ーー仍然可以让您手动调整它,以便进行更高级的试验。
关于数据集
水果在当今世界非常普遍ーー尽管有大量的快餐和精制食品,但水果仍然是人们广泛食用的食物。举个例子,在水果的生产过程中,可能需要对它们进行分类。传统上被机械地执行,今天,基于深度学习的技术可以增强甚至接管这个过程。
目录
-
引言
-
数据预处理
-
探索数据集
-
应用数据增强
-
访问少量样本图片
-
访问 GPU
-
配置模型
-
模型训练及成果
-
预测
-
摘要
1. 引言
图片总数:90483。
训练集大小:67692图像(每图像一个水果或蔬菜)。
测试集大小:22688图像(每张图像一个水果或蔬菜)。
类别数目:131(水果和蔬菜)。
图像大小:100x100像素。
同一种水果的不同品种(例如苹果)属于不同的类别。
2. 数据预处理
导入所需的库
因为我们使用 PyTorch 来构建神经网络,所以我一次性导入所有相关的库。
import os
import torch
import torchvision
import tarfile
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
from torchvision.datasets.utils import download_url
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
import torchvision.transforms as tt
from torch.utils.data import random_split
from torchvision.utils import make_grid
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")下载数据集
# Upload kaggle.jason
# please follow this link incase not aware: https://www.kaggle.com/general/74235
from google.colab import files
files.upload()
! pip install opendatasets --upgrade
import opendatasets as od
dataset_url = 'https://www.kaggle.com/moltean/fruits'
od.download(dataset_url)在运行任何探索之前,数据集必须加载到 DataLoader。我们使用 PyTorch 的 ImageFolder 将图像加载到 DataLoader。
3. 探索数据集
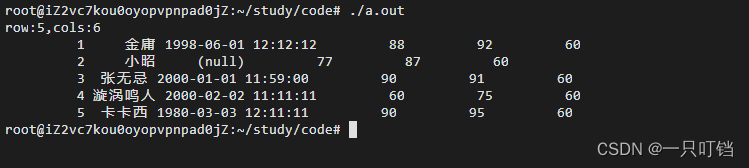
问: 训练和测试数据集包含多少图像?
dataset_size = len(train_dataset)
test_dataset_size = len(test_dataset)
print(train_dataset)
print(test_dataset)输出:
Dataset ImageFolder
Number of datapoints: 67692
Root location: /content/fruits/fruits-360/Training
StandardTransform
Transform: ToTensor()
Dataset ImageFolder
Number of datapoints: 22688
Root location: /content/fruits/fruits-360/Test
StandardTransform
Transform: ToTensor()问:数据集包含多少个输出类?
# Accesssing the classes
data_dir = '/content/fruits/fruits-360/'
# print(os.listdir(data_dir))
classes = os.listdir(data_dir + "Training")
print(f'Total Number of Classe {len(classes)}')
print(f'Classes Names: {classes}')输出:
Total Number of Classe 131
Classes Names: ['Apple Braeburn', 'Cherry Wax Red', 'Melon Piel de Sapo', 'Rambutan', 'Tamarillo', 'Pepino', 'Lemon', 'Tomato Cherry Red', 'Apple Golden 1', 'Peach Flat', 'Apple Red Delicious', 'Lemon Meyer', 'Banana Red', 'Orange', 'Peach 2', 'Pepper Red', 'Grape White', 'Kaki', 'Pepper Yellow', 'Salak', 'Potato White', 'Cucumber Ripe 2', 'Apple Golden 2', 'Pitahaya Red', 'Mulberry', 'Carambula', 'Pear Abate', 'Banana', 'Tomato Maroon', 'Pear Red', 'Pear Forelle', 'Pineapple', 'Ginger Root', 'Potato Red', 'Apple Pink Lady', 'Pear Kaiser', 'Mandarine', 'Strawberry', 'Apple Golden 3', 'Nectarine', 'Plum 3', 'Avocado ripe', 'Cantaloupe 2', 'Fig', 'Tomato 1', 'Tomato Heart', 'Passion Fruit', 'Grape Blue', 'Cantaloupe 1', 'Apple Granny Smith', 'Banana Lady Finger', 'Mango Red', 'Cherry Rainier', 'Corn Husk', 'Hazelnut', 'Pear', 'Cauliflower', 'Pear Williams', 'Tangelo', 'Avocado', 'Physalis', 'Chestnut', 'Onion White', 'Granadilla', 'Strawberry Wedge', 'Plum 2', 'Plum', 'Pepper Green', 'Tomato 3', 'Grape White 4', 'Quince', 'Maracuja', 'Apple Red 1', 'Grapefruit White', 'Cherry 1', 'Walnut', 'Grape White 2', 'Cactus fruit', 'Grape Pink', 'Potato Red Washed', 'Apple Red Yellow 1', 'Cherry 2', 'Pear 2', 'Huckleberry', 'Guava', 'Apple Red 2', 'Beetroot', 'Limes', 'Kiwi', 'Tomato 2', 'Pear Stone', 'Grapefruit Pink', 'Peach', 'Mango', 'Nut Forest', 'Cherry Wax Yellow', 'Eggplant', 'Clementine', 'Pear Monster', 'Nectarine Flat', 'Pepper Orange', 'Onion Red Peeled', 'Cocos', 'Grape White 3', 'Redcurrant', 'Dates', 'Tomato Yellow', 'Pomegranate', 'Pineapple Mini', 'Pomelo Sweetie', 'Papaya', 'Corn', 'Cucumber Ripe', 'Onion Red', 'Nut Pecan', 'Potato Sweet', 'Cherry Wax Black', 'Physalis with Husk', 'Mangostan', 'Tomato not Ripened', 'Tomato 4', 'Apricot', 'Kumquats', 'Apple Red Yellow 2', 'Kohlrabi', 'Lychee', 'Apple Crimson Snow', 'Blueberry', 'Raspberry', 'Watermelon', 'Apple Red 3']问: 数据集中的图像张量的形状是什么?
img, label = train_dataset[0]
img_shape = img.shape
img_shape输出:
torch.Size([3, 100, 100])让我们打印一个示例图像及其类和标签。
img, label = train_dataset[0]
plt.imshow(img.permute((1, 2, 0)))
print('Label (numeric):', label)
print('Label (textual):', classes[label])输出:
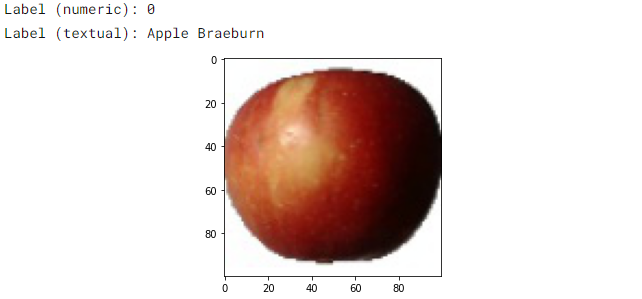
问: 你能确定属于每个类别的图像数量吗?
dataset_size = len(train_dataset)
classes = train_dataset.classes
num_classes = len(train_dataset.classes)
img_dict = {}
for i in range(num_classes):
img_dict[classes[i]] = 0
for i in range(dataset_size):
img, label = train_dataset[i]
img_dict[classes[label]] += 1
## Plotting classes along with images info
from matplotlib import pyplot as plt
fig, ax = plt.subplots(figsize =(16, 32))
ax.barh(list(img_dict.keys()), list(img_dict.values()))
# Add Plot Title
ax.set_title('Each Class along with their values',
loc ='left', )
# Add annotation to bars
for i in ax.patches:
plt.text(i.get_width()+0.2, i.get_y()+0.5,
str(round((i.get_width()), 2)),
fontsize = 10, fontweight ='bold',
color ='grey')
# Add Text watermark
fig.text(0.9, 0.15, 'gurjeet333', fontsize = 12,
color ='grey', ha ='right', va ='bottom',
alpha = 0.7)
plt.show()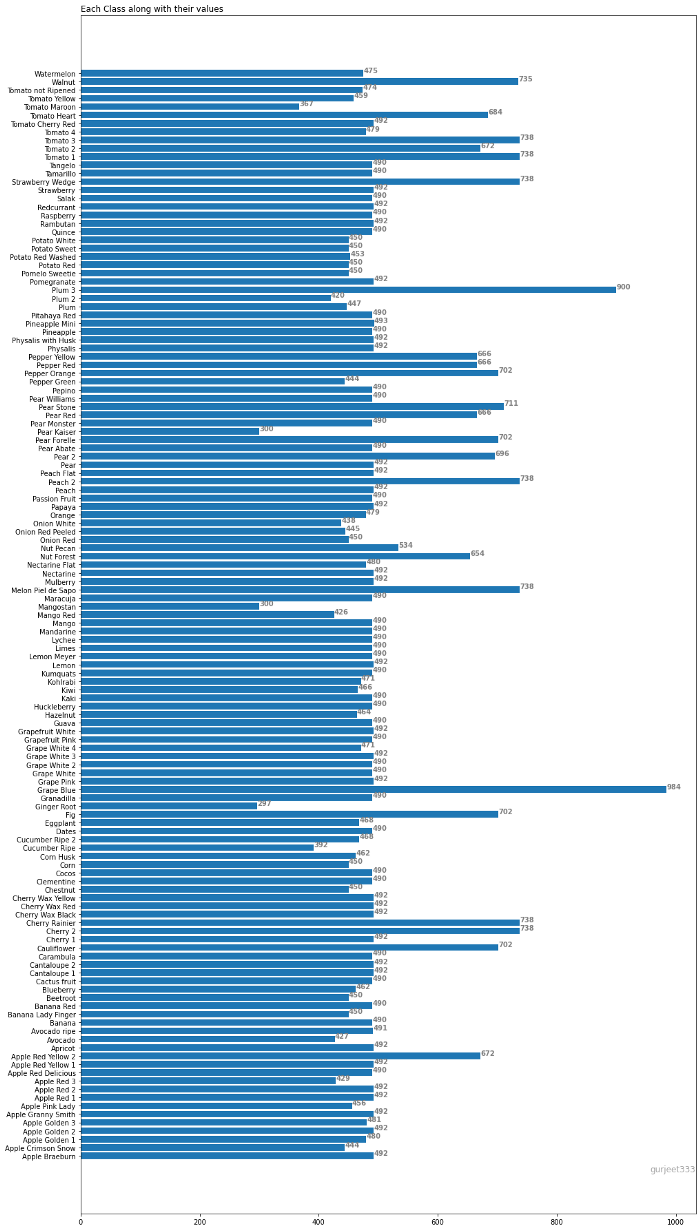
4. 应用数据增强
构建数据转换
我们将首先编写转换函数,以便实现数据增强。
# Data transforms (data augmentation)
train_tfms = tt.Compose([
tt.RandomCrop(100, padding=4, padding_mode='reflect'),
tt.Resize((100,100)),
tt.RandomHorizontalFlip(),
# tt.RandomRotate
# tt.RandomResizedCrop(256, scale=(0.5,0.9), ratio=(1, 1)),
# tt.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
tt.ToTensor(),
])
valid_tfms = tt.Compose([tt.ToTensor(), tt.Resize((100,100)),
])请随时尝试其他参数,如 tt.RandomResized,tt.ColorJitter(我在代码中添加了它们)
将转换应用于数据集
我们构建的转换需要应用于训练和测试数据集。注意:我们不在测试数据集中应用数据增强。
dataset = ImageFolder(data_dir + "/Training", transform=train_tfms)
Testing = ImageFolder(data_dir + "/Test", transform=valid_tfms)分割数据集
我们将使用来自训练集的20%作为验证集。为了确保每次获得相同的验证集,我们将 PyTorch 的随机数生成器设置种子值为43。
torch.manual_seed(43)
val_size = round(len(dataset) * 0.2)
train_size = round(len(dataset) - val_size)
train_ds, val_ds = random_split(dataset, [train_size, val_size])
len(train_ds), len(val_ds)
batch_size=400
train_loader = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_ds, batch_size*2, num_workers=4, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size*2, num_workers=4, pin_memory=True)5. 访问样本
让我们使用来自 Torchvision 的 make_grid 函数来可视化一批数据。
def show_batch(dl):
for images, labels in dl:
fig, ax = plt.subplots(figsize=(12, 12))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(images, nrow=16).permute(1, 2, 0))
break
show_batch(train_loader)
你能通过观察标记所有的图像吗?尝试手动标记一个随机的数据样本是一个很好的方式来估计问题的难度,并识别标记错误
6. 使用GPU
如果你的电脑有连接到 NVIDIA 生产的 GPU 上,你可以使用一个图形处理器图形处理器(GPU)来更快地训练你的模型。按照以下说明在你选择的平台上使用 GPU:
-
Google Colab:使用菜单选项“ Runtime > Change Runtime Type”,从“ Hardware Accelerator”下拉菜单中选择“ GPU”
-
Kaggle:在侧边栏的“设置”部分,从“ Accelerator”下拉菜单中选择“ GPU”,使用右上角的按钮打开侧边栏
-
Binder:运行在Binder上的代码不能使用 GPU
-
Linux:如果您的笔记本/台式机有 NVIDIA GPU (显卡) ,请确保您已经安装了 NVIDIA CUDA 驱动程序
-
Windows:如果你的笔记本/台式机有 NVIDIA GPU (显卡) ,请确保你已经安装了 NVIDIA CUDA 驱动程序。
-
macOS:macOS 与 NVIDIA GPU 不兼容
-
如果你不能访问 GPU 或者不确定它是什么,不要担心,你可以在没有 GPU 的情况下很好地执行本教程中的所有代码
让我们从安装和导入所需的库开始。
def get_default_device():
"""Pick GPU if available, else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)现在我使用 DeviceDataLoader 函数将训练和验证集加载到 GPU 中。
device = get_default_device()
device
train_dl = DeviceDataLoader(train_loader, device)
valid_dl = DeviceDataLoader(val_loader, device)7. 配置模型
设置精度函数和图像基类
两者都是通用函数,不需要对任何数据集进行任何更改。这些是计算精度的辅助函数,并实现损失函数来计算模型的训练和验证损失。
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
class ImageClassificationBase(nn.Module):
def training_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
return loss
def validation_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
acc = accuracy(out, labels) # Calculate accuracy
return {'val_loss': loss.detach(), 'val_acc': acc}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['train_loss'], result['val_loss'], result['val_acc']))class ImageClassificationBase(nn.Module):
def training_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
return loss
def validation_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
acc = accuracy(out, labels) # Calculate accuracy
return {'val_loss': loss.detach(), 'val_acc': acc}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['train_loss'], result['val_loss'], result['val_acc']))实现批量标准化和Dropout
我们用 nn.Squential 将多层神经网络链接在一起。我在代码中添加了注释,以便简单地理解。注意——在这里我使用 nn.BatchNorm2d 在每一层的末尾实现批量归一化。
class Fruit360CnnModel(ImageClassificationBase):
def __init__(self):
super().__init__()
self.network = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=2, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2, 2), # 16 X 50 X 50
nn.Conv2d(16, 32, kernel_size=2, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2), # 32 X 25 X 25
nn.Conv2d(32, 64, kernel_size=2, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(5, 5), # 64 X 5 X 5
nn.Flatten(),
nn.Dropout(0.3),
nn.ReLU(),
nn.Linear(64*5*5, 131))
def forward(self, xb):
return self.network(xb)
model = Fruit360CnnModel()
model输出:
Fruit360CnnModel(
(network): Sequential(
(0): Conv2d(3, 16, kernel_size=(2, 2), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(16, 32, kernel_size=(2, 2), stride=(1, 1), padding=(1, 1))
(5): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU()
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): Conv2d(32, 64, kernel_size=(2, 2), stride=(1, 1), padding=(1, 1))
(9): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): ReLU()
(11): MaxPool2d(kernel_size=5, stride=5, padding=0, dilation=1, ceil_mode=False)
(12): Flatten(start_dim=1, end_dim=-1)
(13): Dropout(p=0.3, inplace=False)
(14): ReLU()
(15): Linear(in_features=1600, out_features=131, bias=True)
)
)实现权重衰减,梯度裁剪,Adam 优化
@torch.no_grad()
def evaluate(model, val_loader):
model.eval()
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def fit_one_cycle(epochs, max_lr, model, train_loader, val_loader,
weight_decay=0, grad_clip=None, opt_func=torch.optim.SGD):
torch.cuda.empty_cache()
history = []
# Set up cutom optimizer with weight decay
optimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)
# Set up one-cycle learning rate scheduler
sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs,
steps_per_epoch=len(train_loader))
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
lrs = []
for batch in train_loader:
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
# Gradient clipping
if grad_clip:
nn.utils.clip_grad_value_(model.parameters(), grad_clip)
optimizer.step()
optimizer.zero_grad()
# Record & update learning rate
lrs.append(get_lr(optimizer))
sched.step()
# Validation phase
result = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
result['lrs'] = lrs
model.epoch_end(epoch, result)
history.append(result)
return history
# Moving the model to GPU
model = to_device(model, device)
model输出:
Fruit360CnnModel(
(network): Sequential(
(0): Conv2d(3, 16, kernel_size=(2, 2), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(16, 32, kernel_size=(2, 2), stride=(1, 1), padding=(1, 1))
(5): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU()
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): Conv2d(32, 64, kernel_size=(2, 2), stride=(1, 1), padding=(1, 1))
(9): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): ReLU()
(11): MaxPool2d(kernel_size=5, stride=5, padding=0, dilation=1, ceil_mode=False)
(12): Flatten(start_dim=1, end_dim=-1)
(13): Dropout(p=0.3, inplace=False)
(14): ReLU()
(15): Linear(in_features=1600, out_features=131, bias=True)
)
)模型在训练前的表现似乎很差。正如下面观察到的,模型的准确度低于1% ,因为模型试图随机猜测输出。
os.environ['WANDB_CONSOLE'] = 'off'
history = [evaluate(model, valid_dl)]
history输出:
[{'val_acc': 0.005484417546540499, 'val_loss': 4.877397537231445}]8. 模型训练和结果分析
在训练前设置参数
epochs = 4
max_lr = 0.01
grad_clip = 0.1
weight_decay = 1e-4
opt_func = torch.optim.Adam运行4个epochs
%%time
os.environ['WANDB_CONSOLE'] = 'off'
history += fit_one_cycle(epochs, max_lr, model, train_dl, valid_dl,
grad_clip=grad_clip,
weight_decay=weight_decay,
opt_func=opt_func)输出:
Epoch [0], train_loss: 1.2414, val_loss: 0.8754, val_acc: 0.7948
Epoch [1], train_loss: 0.1211, val_loss: 0.0212, val_acc: 0.9931
Epoch [2], train_loss: 0.0101, val_loss: 0.0025, val_acc: 0.9996
Epoch [3], train_loss: 0.0049, val_loss: 0.0011, val_acc: 0.9999
CPU times: user 11.8 s, sys: 7.95 s, total: 19.8 s
Wall time: 3min 7在4个epoch4分钟以内,我们取得了很好的精度。
Accuracy vs No
def plot_accuracies(history):
accuracies = [x['val_acc'] for x in history]
plt.plot(accuracies, '-x')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Accuracy vs. No. of epochs');
plot_accuracies(history)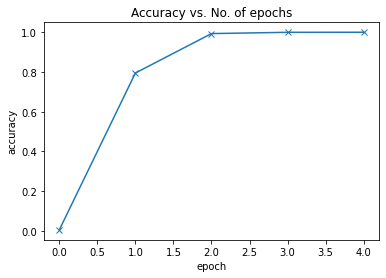
Loss vs epochs
def plot_losses(history):
train_losses = [x.get('train_loss') for x in history]
val_losses = [x['val_loss'] for x in history]
plt.plot(train_losses, '-bx')
plt.plot(val_losses, '-rx')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['Training', 'Validation'])
plt.title('Loss vs. No. of epochs');
plot_losses(history)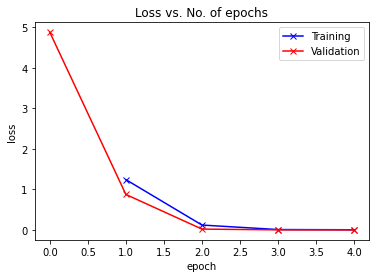
由于训练和验证的损失不是发散的,而是逐渐收敛的,这表明我们没有过度拟合我们的模型。
学习率
def plot_lrs(history):
lrs = np.concatenate([x.get('lrs', []) for x in history])
plt.plot(lrs)
plt.xlabel('Batch no.')
plt.ylabel('Learning rate')
plt.title('Learning Rate vs. Batch no.')
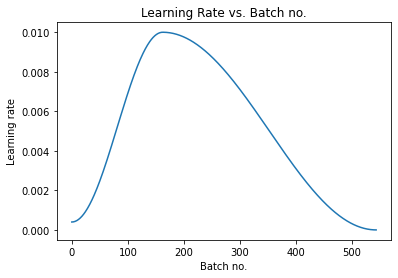
正如预期的那样,学习率开始于一个较低的值,并且在30% 的迭代中逐渐增加到最大值0.01,然后逐渐降低到一个非常小的值。
9. 预测
让我们在测试数据集上进行模型预测
test_tfms = tt.Compose([tt.Resize((100, 100)),
tt.ToTensor()])
test_dataset = ImageFolder(data_dir + "Test", transform=test_tfms)
test_loader = DeviceDataLoader(DataLoader(test_dataset, batch_size), device)
result = evaluate(model, test_loader)
result输出:
{'val_acc': 0.9883334040641785, 'val_loss': 0.08684124052524567}验证准确率超过98% ,我们编写了一个辅助函数,获取一个图像并将其应用到模型中
def predict_image(img, model):
# Convert to a batch of 1
xb = to_device(img.unsqueeze(0), device)
# Get predictions from model
yb = model(xb)
# Pick index with highest probability
_, preds = torch.max(yb, dim=1)
# Retrieve the class label
return dataset.classes[preds[0].item()]我们现在在样本图像上测试预测
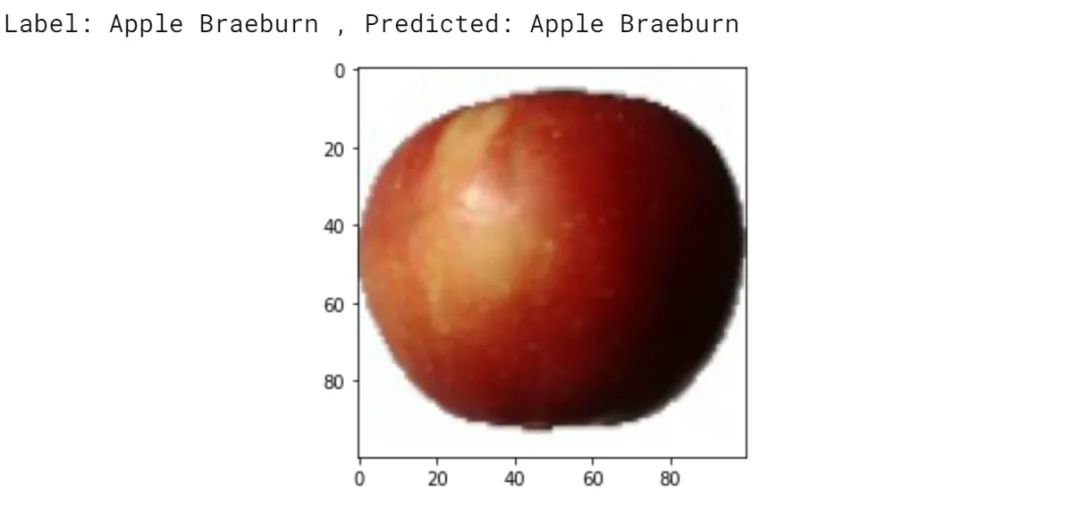
img, label = test_dataset[0]
plt.imshow(img.permute(1, 2, 0))
print('Label:', dataset.classes[label], 'Predicted:', predict_image(img, model))输出:
10. 总结
下面是本教程中用于提高模型性能和减少训练时间的不同技术的总结:
-
数据增强:我们应用随机变换加载图像时,从训练数据集。具体来说,我们将每张图片填充4个像素,然后随机裁剪100 × 100个像素,然后以50% 的概率水平翻转图片
-
批量归一化:在每个卷积层之后,我们增加了一个批量归一化层,对前一层的输出进行归一化处理。这有点类似于数据规范化,只不过它应用于一个层的输出,而平均值和标准差是学习参数
-
学习率策略:不再使用固定的学习率,而是使用学习率调度器,每次训练后调整学习率。在训练过程中,有很多策略可以改变学习率,我们采用了“One Cycle Learning Rate Policy”
-
权重衰减:我们给优化器增加了权重衰减,这是另一种正则化技术,它通过在损失函数中增加一个附加项来防止权重值变得过大
-
梯度裁剪:我们还增加了梯度裁剪,这有助于限制梯度值在一个小的范围,以防止不良变化的模型参数
-
Adam 优化器:我们使用 Adam 优化器代替 SGD (随机梯度下降) ,该优化器使用momentum 和 自适应学习率等技术进行更快的训练。还有许多其他的优化器可以选择并进行实验





![[H5动画制作系列]键盘及鼠标事件基础测试](https://img-blog.csdnimg.cn/9da9a3f7df59474d9764fe0bf0b0fd9c.png)