REORDER LIBRARY
重排序库提供了根据其序列号对mbuf进行重排序的机制。
16.1 操作
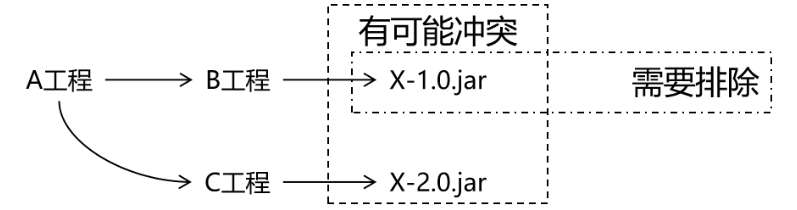
重排序库本质上是一个对mbuf进行重新排序的缓冲区。用户将乱序的mbuf插入重排序缓冲区,并从中提取顺序正确的mbuf。
在任何给定时刻,重排序缓冲区包含其序列号位于序列窗口内的mbuf。序列窗口由最小序列号和缓冲区配置为保存的条目数确定。例如,给定一个具有200个条目和最小序列号为350的重排序缓冲区,序列窗口的低限和高限分别为350和550。
在插入mbuf时,重排序库根据插入mbuf的序列号区分有效、晚到和早到的mbuf:
- 有效:序列号在窗口内。
- 晚到:序列号超出窗口且小于低限。
- 早到:序列号超出窗口且大于高限。
重排序缓冲区直接返回晚到的mbuf,并尝试容纳早到的mbuf。
16.2 实现细节
重排序库实现为一对缓冲区,分别称为Order缓冲区和Ready缓冲区。
在插入调用时,有效的mbuf直接插入Order缓冲区,而晚到的mbuf则以错误的形式返回给用户。
对于早到的mbuf,重排序缓冲区将尝试移动窗口(递增最小序列号),使mbuf变为有效。为此,将Order缓冲区中的mbuf移动到Ready缓冲区。尚未到达的mbuf将被忽略,因此将成为晚到的mbuf。这意味着只要Ready缓冲区有空间,窗口就会移动以容纳本应在重排序窗口外的早到mbuf。
例如,假设我们有一个包含200个条目、最小序列号为350的缓冲区,并且我们需要插入序列号为565的早到mbuf。这意味着我们需要至少移动窗口15个位置来容纳该mbuf。重排序缓冲区会尝试从Order缓冲区的至少接下来的15个插槽中移动mbuf到Ready缓冲区,只要Ready缓冲区有空间。在此时,Order缓冲区中的任何间隙都将被跳过,并且这些数据包在到达时将被报告为晚到的数据包。将数据包移动到Ready缓冲区的过程会持续超过最小要求,直到在Order缓冲区中遇到间隙(即丢失的mbuf)为止。
在排空mbuf时,重排序缓冲区首先从Ready缓冲区返回mbuf,然后从Order缓冲区返回,直到找到间隙(尚未到达的mbuf)为止。
16.3 Use Case: Packet Distributor
使用DPDK数据包分发器的应用程序可以利用重排序库以按接收顺序传输数据包。
一个基本的数据包分发器用例包括具有多个工作核心的分发器。工作核心对数据包的处理不能保证顺序,因此可以使用重排序缓冲区对尽可能多的数据包进行排序。
在这种情况下,分发器在将数据包传递给工作核心之前为mbuf分配序列号。随着工作核心完成处理数据包,分发器将这些mbuf插入重排序缓冲区,最后传输排空的mbuf。
注意:当前的重排序缓冲区不是线程安全的,因此同一个线程负责插入和排空mbuf。
IP FRAGMENTATION AND REASSEMBLY LIBRARY
IP Fragmentation and Reassembly Library实现了IPv4和IPv6数据包的分片和重组。
17.1 数据包分片
数据包分片例程将输入数据包分成多个片段。rte_ipv4_fragment_packet()和rte_ipv6_fragment_packet()函数假设输入的mbuf数据指向数据包的IP头的起始位置(即L2头已经被剥离)。为避免对实际数据包数据进行复制,使用了零拷贝技术(rte_pktmbuf_attach)。
对于每个片段,创建了两个新的mbuf:
- 直接mbuf:将包含新片段的L3头。
- 间接mbuf:附加到具有原始数据包的mbuf上。它的数据字段指向原始数据包数据的起始位置加上片段偏移量。
然后,将原始mbuf中的L3头复制到“直接”mbuf中,并更新以反映新的分片状态。注意,对于IPv4,不会重新计算头部校验和,而是设置为零。
最后,通过mbuf的next字段将每个片段的“直接”和“间接”mbuf链接在一起,以组成新片段的数据包。
调用者可以显式指定应从中分配“直接”和“间接”mbuf的内存池。
有关直接和间接mbuf的更多信息,请参阅DPDK程序员指南7.7 Direct and Indirect Buffers。
17.2 数据包重组
17.2.1 IP分片表
分片表维护关于已接收到数据包片段的信息。
每个IP数据包由三元组 <源IP地址>、<目标IP地址>、 唯一标识。
需要注意的是,对分片表的所有更新/查找操作都不是线程安全的。因此,如果不同的执行上下文(线程/进程)同时访问相同的表,则必须提供某种外部同步机制。
每个表条目可以包含最多 RTE_LIBRTE_IP_FRAG_MAX(默认值为4)个片段的信息。
示例代码演示了如何创建一个新的分片表:
frag_cycles = (rte_get_tsc_hz() + MS_PER_S - 1) / MS_PER_S * max_flow_ttl;
bucket_num = max_flow_num + max_flow_num / 4;
frag_tbl = rte_ip_frag_table_create(max_flow_num, bucket_entries,
max_flow_num, frag_cycles, socket_id);
内部分片表是一个简单的哈希表。基本思想是使用两个哈希函数和 <bucket_entries> * 关联性。这为每个键提供了 2 * <bucket_entries> 个可能的位置。当发生冲突并且所有 2 * <bucket_entries> 位置都被占用时,ip_frag_tbl_add() 不会重新插入现有键到备用位置,而只是返回失败。
此外,驻留在表中时间超过 <max_cycles> 的条目被视为无效,并且可以被新条目删除/替换。
需要注意的是,重组需要大量的mbuf进行分配。在任何给定时间内,最多可以在分片表中存储 (2 * bucket_entries * RTE_LIBRTE_IP_FRAG_MAX * <每个数据包的最大mbuf数>) 个片段等待其余片段的到来。
17.2.2 数据包重组
分片数据包的处理和重组由rte_ipv4_frag_reassemble_packet() / rte_ipv6_frag_reassemble_packet()函数完成。这些函数要么返回包含重组数据包的有效mbuf指针,要么返回NULL(如果由于某种原因无法重组数据包)。
这些函数负责:
- 在分片表中查找具有数据包的<IPv4源地址,IPv4目标地址,数据包ID>的条目。
- 如果找到条目,则检查该条目是否已超时。如果是,则释放所有先前接收到的片段,并从条目中删除与它们相关的信息。
- 如果没有找到具有此键的条目,则尝试通过以下两种方式之一创建新条目:
(a) 使用空条目。
(b) 删除超时条目,释放与其关联的mbuf,并在其中存储具有指定键的新条目。 - 更新条目以包含新的片段信息,并检查是否可以重新组装数据包(数据包的条目包含所有片段)。
(a) 如果可以,那么重新组装数据包,将表的条目标记为空,并将重组的mbuf返回给调用者。
(b) 如果不能,则向调用者返回NULL。
如果在数据包处理的任何阶段遇到错误(例如:无法将新条目插入分片表,或者无效/超时的片段),则函数将释放与数据包关联的所有片段,将表条目标记为无效,并向调用者返回NULL。
17.2.3 调试日志记录和统计收集
RTE_LIBRTE_IP_FRAG_TBL_STAT配置宏控制分片表的统计收集。默认情况下,此宏未启用。
RTE_LIBRTE_IP_FRAG_DEBUG控制IP片段处理和重组的调试日志记录。默认情况下,此宏已禁用。需要注意的是,尽管日志包含大量详细信息,但它会减慢数据包处理速度,并可能导致大量数据包丢失。
MULTI-PROCESS SUPPORT
在DPDK中,多进程支持旨在允许一组DPDK进程在Intel®架构硬件上以简单透明的方式共同执行数据包处理或其他工作负载。为支持此功能,对核心DPDK环境抽象层(EAL)进行了一些增加。
EAL已被修改以允许生成不同类型的DPDK进程,每个进程对应用程序使用的hugepage内存具有不同的权限。目前有两种指定的进程类型:
- 主进程:可以初始化并具有对共享内存的全部权限。
- 次要进程:无法初始化共享内存,但可以附加到预先初始化的共享内存并在其中创建对象。
独立的DPDK进程是主进程,而次要进程只能在主进程旁边运行或在主进程已为其配置了hugepage共享内存后运行。
为支持这两种进程类型和后续描述的其他多进程设置,EAL提供了两个额外的命令行参数:
- –proc-type:用于指定给定进程实例为主要或次要DPDK实例。
- –file-prefix:允许不想合作的进程具有不同的内存区域。
提供了许多示例应用程序,演示了如何一起使用多个DPDK进程。这些在“DPDK示例应用程序用户指南”的“多进程示例应用程序”章节中有更详细的文档记录。
18.1 内存共享
使用DPDK创建多进程应用程序的关键要素是确保内存资源在构成多进程应用程序的各个进程之间得到正确共享。一旦有多个进程可以访问的共享内存块,那么诸如进程间通信(IPC)之类的问题就变得简单得多。
在主要或独立进程的应用程序启动时,DPDK将内存配置的详细信息记录到内存映射文件中 - 使用的hugepages,它们映射的虚拟地址,存在的内存通道数等。当启动次要进程时,会读取这些文件,EAL会在次要进程中重新创建相同的内存配置,以便所有内存区域在进程之间共享,并且所有对该内存的指针在两个进程中都是有效的,并且指向相同的对象。
注意:有关Linux内核地址空间布局随机化(ASLR)如何影响内存共享的详细信息,请参阅多进程限制部分。
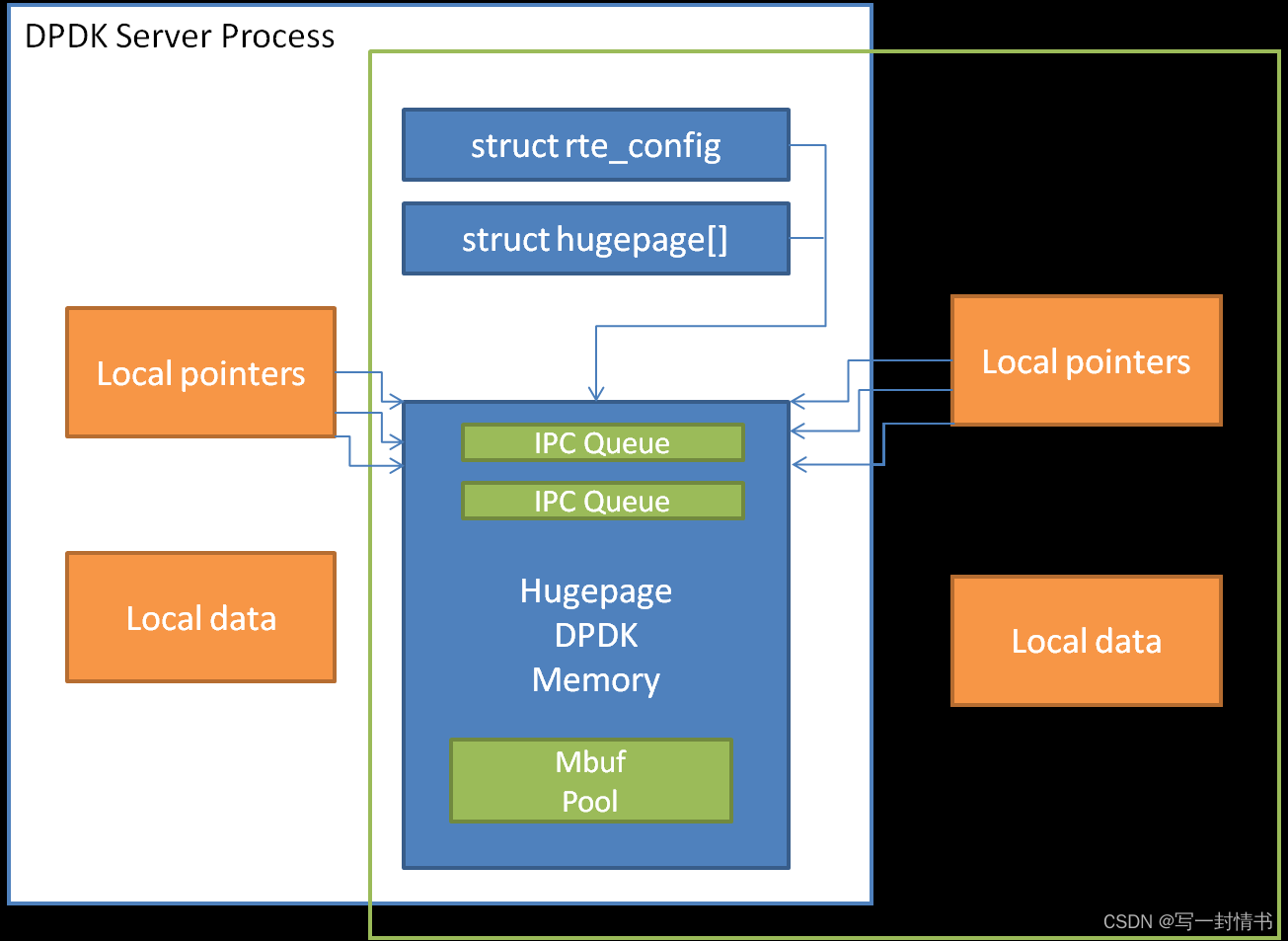
Figure 18.1: Memory Sharing in the DPDK Multi-process Sample Application
EAL还支持自动检测模式(通过EAL的 --proc-type=auto 标志设置),如果已经运行了主要实例,则会启动一个DPDK进程作为次要实例。
18.2 部署模型
18.2.1 对称/对等进程
DPDK多进程支持可用于创建一组对等进程,其中每个进程执行相同的工作负载。该模型相当于具有多个线程,每个线程都运行相同的主循环功能,这是大多数提供的DPDK示例应用程序所做的。在此模型中,首个生成的进程应使用 --proc-type=primary EAL标志生成,而所有后续实例应使用 --proc-type=secondary 标志生成。
simple_mp 和 symmetric_mp 示例应用程序展示了这种用法模型。它们在“DPDK示例应用程序用户指南”的“多进程示例应用程序”章节中有描述。
18.2.2 非对称/非对等进程
多进程应用程序的另一种可用部署模型是拥有一个充当负载均衡器或服务器的单个主进程实例,将接收到的数据包分发给作为次要进程运行的工作线程或客户端线程。在这种情况下,广泛使用了位于共享hugepage内存中的rte_ring对象。
client_server_mp 示例应用程序展示了这种用法模型。它在“DPDK示例应用程序用户指南”的“多进程示例应用程序”章节中有描述。
18.2.3 运行多个独立的DPDK应用程序
除了涉及多个DPDK进程共同工作的上述情景之外,还可以在旁边运行多个独立的DPDK进程,这些进程都在独立工作。支持此使用场景的方法是使用EAL的 --file-prefix 参数。
默认情况下,EAL在每个hugetlbfs文件系统上创建hugepage文件,文件名为rtemap_X,其中X的范围是从0到最大hugepages - 1。类似地,当以root用户运行时(或以非root用户运行时,如果文件系统和设备权限设置允许的话),它会创建共享配置文件,每个进程中都有内存映射,文件名为/var/run/.rte_config,文件名中的rte部分可以使用file-prefix参数进行配置。
除了指定file-prefix参数之外,任何要并行运行的DPDK应用程序都必须明确限制其内存使用。这通过向每个进程传递 -m 标志来实现,以指定每个进程可以使用多少兆字节的hugepage内存(或传递 --socket-mem 以指定每个进程在每个插槽上可以使用多少hugepage内存)。
注意:在单个机器上并行运行的独立DPDK实例不能共享任何网络端口。任何一个进程使用的网络端口应在其他每个进程中列入黑名单。
18.2.4 运行多个独立DPDK应用程序组
与在单个系统上并行运行独立的DPDK应用程序类似,这可以轻松地扩展到并行运行多个DPDK应用程序组。在这种情况下,次要进程必须使用与其连接到的主要进程相同的 --file-prefix 参数。
注意:在此使用场景中,所有与并行运行的多个独立DPDK进程相关的限制和问题也适用。
18.3 多进程的限制
在运行DPDK多进程应用程序时存在一些限制。以下是其中一些已记录的限制:
-
多进程功能要求所有应用程序中都存在完全相同的hugepage内存映射。Linux安全功能 - 地址空间布局随机化(ASLR)可能会干扰此映射,因此可能需要禁用此功能才能可靠地运行多进程应用程序。
警告:禁用地址空间布局随机化(ASLR)可能会带来安全问题,因此建议仅在绝对必要时和在理解了此更改的影响后才禁用。 -
所有作为单个应用程序运行并使用共享内存的DPDK进程必须具有不同的coremask参数。不可能有一个主要实例和次要实例,或者两个次要实例,使用相同的逻辑核心。试图这样做可能会导致内存池缓存的损坏,等其他问题。
-
在次要进程中,例如以太网设备链接状态中断等中断的传递不起作用。所有中断仅在主进程内触发。
任何需要在多个进程中进行中断通知的应用程序都应提供自己的机制,将中断信息从主进程传输到需要该信息的任何次要进程。 -
在基于不同编译的二进制文件的多个进程之间使用函数指针是不受支持的,因为给定函数在一个进程中的位置可能与其在第二个进程中的位置不同。这会阻止librte_hash库的正常行为,因为它在内部使用指向哈希函数的指针,类似于多线程实例。
为解决此问题,建议多进程应用程序通过直接从代码中调用哈希函数进行哈希计算,然后使用rte_hash_add_with_hash()/rte_hash_lookup_with_hash()函数,而不是使用内部执行哈希计算的函数,如rte_hash_add()/rte_hash_lookup()。 -
根据正在使用的硬件和使用的DPDK进程数量,可能无法在每个DPDK实例中使用HPET定时器。Linux*用户空间可用的最小HPET比较器数量可能只有一个比较器,这意味着只有第一个主要DPDK进程实例可以打开并mmap /dev/hpet。如果所需的DPDK进程数量超过可用HPET比较器的数量,则必须在所有进程中使用TSC(在此版本中是默认定时器)作为时间源,而不是使用HPET。
DPDK内核NIC接口
DPDK(Data Plane Development Kit)内核NIC接口(KNI)允许用户空间应用程序访问Linux*控制平面。
使用DPDK KNI的好处有:
- 比现有的Linux TUN/TAP接口更快(通过消除系统调用和copy_to_user()/copy_from_user()操作)。
- 允许使用标准的Linux网络工具(如ethtool、ifconfig和tcpdump)管理DPDK端口。
- 允许与内核网络堆栈进行接口。
使用DPDK内核NIC接口的应用程序组件如图19.1所示。
19.1 DPDK KNI内核模块
KNI内核可加载模块支持两种类型的设备:
杂项设备(/dev/kni):- 通过ioctl调用创建网络设备。
- 维护所有KNI实例共享的内核线程上下文(模拟网络驱动程序的RX端)。
- 对于单个内核线程模式,维护所有KNI实例共享的内核线程上下文(模拟网络驱动程序的RX端)。
- 对于多个内核线程模式,为每个KNI实例维护内核线程上下文(模拟新驱动程序的RX端)。
网络设备:- 通过实现多个操作(如netdev_ops、header_ops、ethtool_ops),提供网络功能,这些操作由struct net_device定义,包括对DPDK mbufs和FIFOs的支持。
- 接口名称由用户空间提供。
- MAC地址可以是真实的NIC MAC地址或随机生成的。
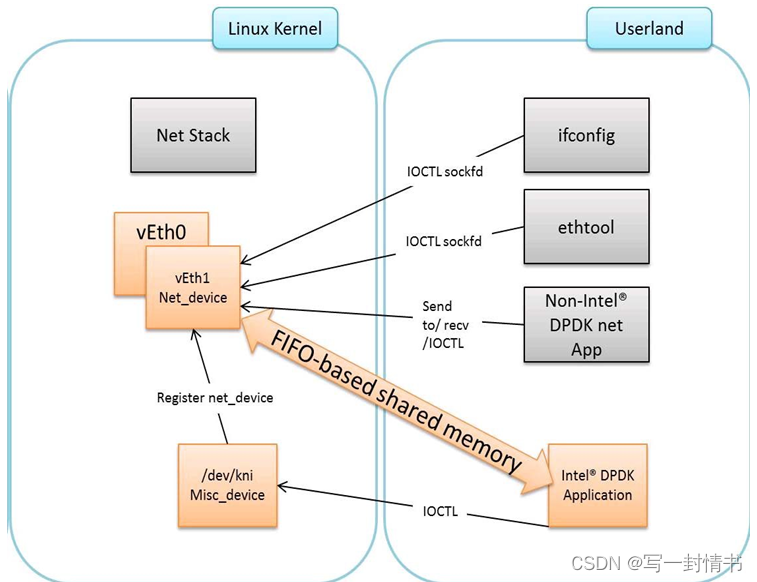
Figure 19.1: Components of a DPDK KNI Application
19.2 KNI创建和删除
KNI接口由DPDK应用程序动态创建。接口名称和FIFO详细信息由应用程序通过使用rte_kni_device_info结构的ioctl调用提供,其中包含:
- 接口名称。
- 相关FIFO的对应memzones的物理地址。
- Mbuf内存池的详细信息,包括物理和虚拟地址(用于计算mbuf指针的偏移量)。
- PCI信息。
- 核心亲和性。
请参阅DPDK源代码中的rte_kni_common.h以获取更多详细信息。
这些物理地址将重新映射到内核地址空间,并存储在单独的KNI上下文中。
一旦创建了KNI接口,可以通过调用rte_kni_info_get()函数查询KNI上下文信息。
KNI接口可以在创建后由DPDK应用程序动态删除。
此外,所有未被删除的KNI接口将在杂项设备的释放操作中被删除(当关闭DPDK应用程序时)。
19.3 DPDK mbuf流程
为了最小化在内核空间运行的DPDK代码量,mbuf内存池仅由用户空间管理。内核模块将了解mbuf,但所有的mbuf分配和释放操作将仅由DPDK应用程序处理。图19.2显示了一个典型的双向发送数据包的场景。
19.4 使用案例:入口
在DPDK的RX端,mbuf由PMD在RX线程上下文中分配。此线程将mbuf排入rx_q FIFO。KNI线程将轮询所有KNI活动设备以获取rx_q。如果出列一个mbuf,它将被转换为sk_buff,并通过netif_rx()发送到网络堆栈。出列的mbuf必须被释放,因此相同的指针将通过free_q FIFO发送回去。在同一主循环中,RX线程轮询此FIFO并在出列后释放mbuf。
19.5 使用案例:出口
对于数据包出口,DPDK应用程序必须首先排入多个mbuf以在内核端创建mbuf缓存。
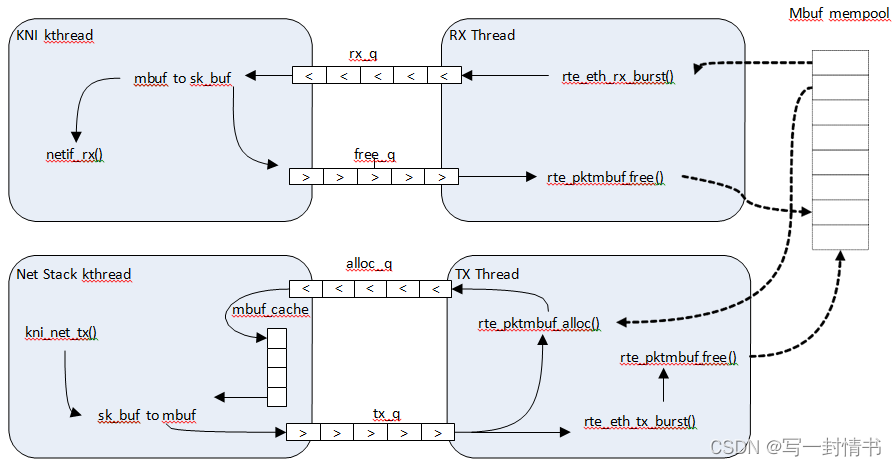
Figure 19.2: Packet Flow via mbufs in the DPDK KNI
数据包通过调用kni_net_tx()回调从Linux网络堆栈接收。mbuf被出列(由于缓存而无需等待),并用sk_buff中的数据填充。然后释放sk_buff并将mbuf发送到tx_q FIFO。DPDK的TX线程出列mbuf并将其发送到PMD(通过rte_eth_tx_burst())。然后将mbuf放回缓存中。
19.6 Ethtool
Ethtool是一个特定于Linux的工具,在内核中具有相应的支持,每个网络设备必须为支持的操作注册自己的回调函数。当前的实现使用了修改后的igb/ixgbe Linux驱动程序以支持ethtool。在i40e和VM(VF或EM设备)中不支持Ethtool。
19.7 链路状态和MTU更改
链路状态和MTU更改是特定于网络接口的操作,通常通过ifconfig完成。请求是从内核端(在ifconfig进程的上下文中)发起的,并由用户空间的DPDK应用程序处理。应用程序轮询请求,调用应用程序处理程序,并将响应返回到内核空间。应用程序处理程序可以在接口创建时注册,也可以在运行时显式注册/注销。这在多进程场景中提供了灵活性(其中KNI在主进程中创建,但回调在辅助进程中处理)。约束是单个进程可以注册和处理请求。
19.8 KNI作为内核vHost后端
vHost是一个内核模块,通常作为virtio(一种para-虚拟化驱动框架)的后端,加速从客户机到主机的流量。DPDK内核NIC接口提供了将vHost流量连接到用户空间DPDK应用程序的功能。与DPDK PMD virtio一起使用,它显著改善了客户机和主机之间的吞吐量。在DPDK作为主机中的快速路径运行的情况下,kni-vhost是流量的高效路径。
19.8.1 概述
vHost-net有三种真实后端实现。它们是:1)tap,2)macvtap和3)RAW socket。kni-vhost背后的主要思想是使KNI作为RAW socket工作,将其附加为vHost-net的后端实例。它使用与vHost-net的现有接口,因此不需要任何内核修改,并且与内核vhost模块完全兼容。由于vHost仍然负责与前端virtio通信,因此它自然支持传统的virtio-net和DPDK PMD virtio。来自vhost非轮询模式的一点惩罚。但是,在使用多线程模式的KNI时,它能够很好地扩展吞吐量。
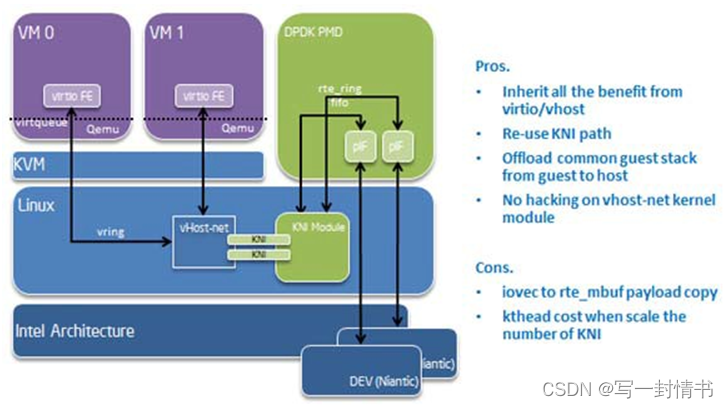
Figure 19.3: vHost-net Architecture Overview
19.8.2 数据包流动
与原始KNI流量流程相比,只有一个轻微的区别。在传输端,vhost kthread调用RAW socket的ops sendmsg,并将数据包放入KNI传输FIFO中。在接收端,kni kthread从KNI接收FIFO获取数据包,将它们放入原始套接字的队列中,并唤醒vhost kthread中的任务开始接收。无论是在传输端还是接收端,所有的数据包复制都发生在vhost kthread的上下文中。每个vhost-net设备都暴露给客户机中的一个前端virtio设备。
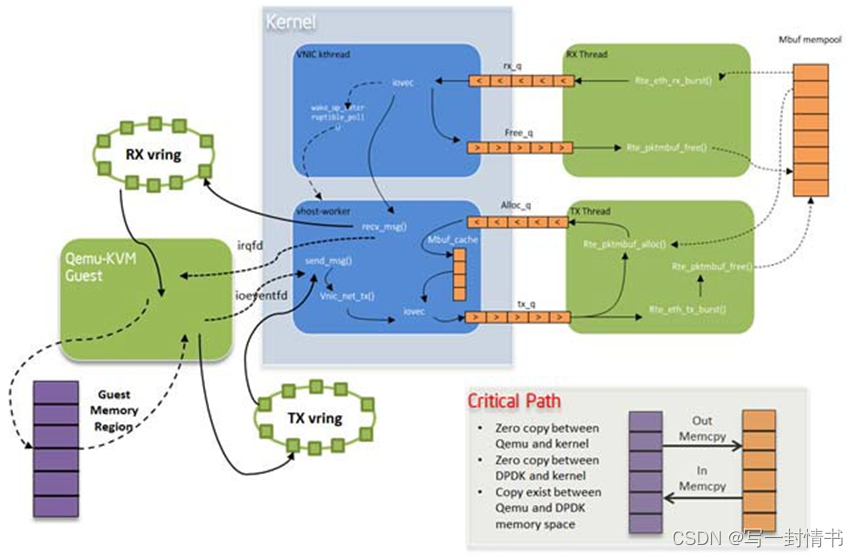
Figure 19.4: KNI Traffic Flow
9.8.3 示例用法
在开始使用KNI作为vhost的后端之前,必须打开CONFIG_RTE_KNI_VHOST配置选项。否则,默认情况下,KNI将不会启用其后端支持功能。
当然,作为先决条件,在编译内核之前应选择vhost/vhost-net内核CONFIG。
1.编译DPDK并像平常一样插入uio_pci_generic/igb_uio内核模块。
2.插入KNI内核模块:
insmod ./rte_kni.ko
如果在多线程模式下使用KNI,使用以下命令行:
insmod ./rte_kni.ko kthread_mode=multiple
3.运行KNI示例应用程序:
./kni -c -0xf0 -n 4 -- -p 0x3 -P -config="(0,4,6),(1,5,7)"
此命令在两个物理端口上运行kni示例应用程序。每个端口将在用户空间中钉住两个转发核心(入口/出口)。
4.在qemu-kvm启动时将原始套接字分配给vhost-net。由于DPDK没有提供执行此操作的脚本,因为用户可以轻松自定义。以下显示了启动带有kni-vhost的qemu-kvm的关键步骤:
#!/bin/bash
echo 1 > /sys/class/net/vEth0/sock_en
fd=$(cat /sys/class/net/vEth0/sock_fd)
qemu-kvm \
-name vm1 -cpu host -m 2048 -smp 1 -hda /opt/vm-fc16.img \
-netdev tap,fd=$fd,id=hostnet1,vhost=on \
-device virti-net-pci,netdev=hostnet1,id=net1,bus=pci.0,addr=0x4
使用sysfs的sock_en简单启用原始套接字,并在KNI设备节点下使用sock_fd获取原始套接字fd。
然后,使用带有-netdev选项的qemu-kvm命令将此类原始套接字fd分配为vhost的后端。
注意:关键字tap必须存在,因为qemu-kvm现在仅支持带有tap后端的vhost,所以我们通过现有的fd来欺骗qemu-kvm。
19.8.4 兼容性配置选项
在DPDK配置文件中有一个CONFIG_RTE_KNI_VHOST_VNET_HDR_EN配置选项。默认情况下,它设置为n,这意味着不启用virtio net头部,该头部用于支持附加功能(例如,csum offload、vlan offload、generic-segmentation等),因为kni-vhost目前不支持这些功能。
即使选项被打开,kni-vhost也将忽略头部包含的信息。在与客户机上的传统virtio一起工作时,最好使用ethtool -K关闭不支持的offload功能。否则,可能会出现诸如不正确的L4校验和错误等问题。
20. 线程安全性的DPDK函数
DPDK由几个库组成。这些库中的一些函数可以安全地同时从多个线程调用,而其他函数则不行。本节允许开发人员在构建自己的应用程序时考虑这些问题。
20.1 快速路径 API
在数据平面操作的应用程序对性能敏感,但这些库中的某些函数可能不适合同时从多个线程调用。哈希、LPM和内存池库以及PMD中的RX/TX就是这种情况的例子。
哈希和LPM库在设计上是线程不安全的,以保持性能。但是,如果需要,开发人员可以在这些库之上添加层以提供线程安全性。并非在所有情况下都需要锁定,在哈希和LPM库中,可以在多个线程中并行执行值的查找。但是,无法在多个线程中添加、删除或修改值,除非在访问单个哈希或LPM表时使用锁定。另一个替代锁定的方法是创建这些表的多个实例,允许每个线程拥有自己的副本。
PMD的RX和TX是DPDK应用程序最关键的部分,建议不要使用锁定,因为它会影响性能。但是,请注意,当每个线程在不同的NIC队列上执行I/O时,这些函数可以安全地从多个线程中使用。如果多个线程要在同一个NIC端口上使用相同的硬件队列,则需要锁定或其他形式的互斥。
环形缓冲区库基于无锁环形缓冲区算法,保持其原始设计以实现线程安全性。此外,它为多个或单个消费者/生产者的入队/出队操作提供高性能。内存池库基于DPDK无锁环形缓冲区库,因此也是多线程安全的。
20.2 不敏感于性能的API
在前一节中描述的性能敏感区域之外,DPDK为大多数其他库提供了线程安全的API。例如,malloc(librte_malloc)和memzone函数在多线程和多进程环境中是安全的。
PMD的设置和配置既不敏感于性能,也不是线程安全的。在PMD设置和配置期间的多次读/写可能在多线程环境中会导致破坏。由于这不是性能敏感的,开发人员可以选择添加自己的层来提供线程安全的设置和配置。在大多数应用程序中,预计网络端口的初始配置将由单个线程在启动时完成。
20.3 库的初始化
建议在应用程序启动的主线程中初始化DPDK库,而不是在之后的转发线程中初始化。然而,DPDK执行检查以确保库只初始化一次。如果尝试多次初始化,则会返回错误。
在多进程的情况下,共享内存的配置信息只会被主进程初始化。之后,主进程和次要进程都可以分配/释放依赖于rte_malloc或memzones的任何内存对象。
20.4 中断线程
DPDK几乎完全在Linux用户空间中以轮询模式运行。对于某些不频繁的操作,例如接收PMD链路状态更改通知,回调可能会在主DPDK处理线程之外的额外线程中调用。这些函数回调应避免操纵也由常规DPDK线程管理的DPDK对象。如果它们需要这样做,就由应用程序提供适当的锁定或互斥约束来围绕这些对象。