作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
对于60%的程序员而言,Java的三层架构Controller、Service、Dao可以说是“越往后走天越黑”,特别是到了Dao层,提着灯笼也只能看到脚边一米开外的河边小石子,只闻对岸风啸马嘶却不知到底是人是鬼,只能借着MyBatis或JPA这些ORM框架隔着宽宽的河举行一场又一场的刺刀战,你砍我一刀,我刺你一剑。

诚然,很多人对MySQL数据库的印象就是一个模糊的大铁柜,闭上眼睛深吸一口气仿佛还能嗅到一股铁锈味。只知柜子里藏着很多张表,表里面存着很多行数据,再详细一点的呢?不知道。
本文旨在帮大家以全新的视角重新认识MySQL的数据组织方式以及SQL优化的底层原理,看完后再去学习其他机构的视频就简单多了。
以下是正文。
柏青哥
大家小时候在游戏厅看过下面这种机器吗:

日本人管它叫柏青哥(パチンコ),玩法是:
从机器最上方的唯一入口投入一颗钢珠,由于重力的作用,钢珠会往下落。机器是直立的,面板上有很多突出的圆柱,它们的作用是随机改变钢珠的落点。最终,钢珠掉落在下方的某个槽中。

这里提柏青哥,是为后面的B+树及分析B+树搜索过程(下篇再讨论)做铺垫。到时你会发现,沿着索引树搜索的过程和柏青哥小钢珠的下落过程是多么相似!
很多人都听过数据库索引,但是很少人会去思考下面几个问题:
- 索引是什么
- 为什么需要索引
- 索引怎么起作用
在历史的长河中,索引的出现几乎是必然的。不信?那就跟我重走一遍历史吧。
请大家先忘了MySQL、Oracle等乱七八糟的玩意儿,就假设你是上世纪第一批程序员,由你来开天辟地。目前摆在你面前的最大难题是:如何存取数据?
线性结构
最直观的想法就是存“格子”里,也就是将数据存在线性结构的容器中,比如数组或链表。
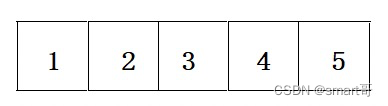
而由于数据库存储数据量往往比较大,很难从一开始就分配整块的空间,所以最终可能是采用链表组织数据:
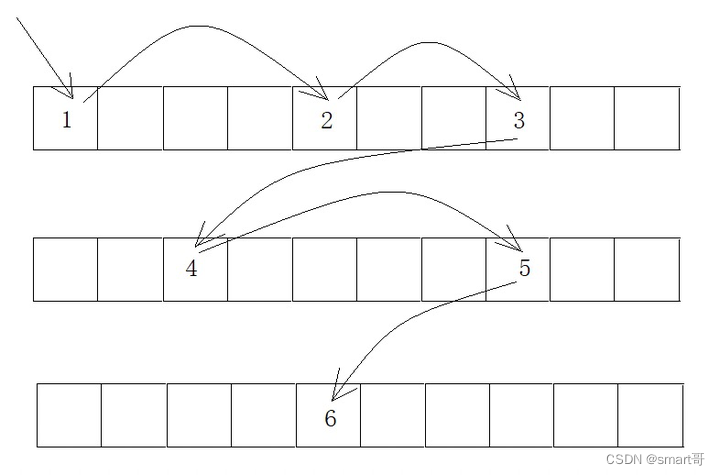
用线性结构存储数据短期看是没问题的,但是一家名为SUN的公司发现,随着公司的业务增长,平台要经手的用户数据越来越多,特别是今年,他们收到了很多客户的信件投诉,说网页的数据加载越来越慢了!
SUN的工程师做了个实验,一个线性表如果存了42亿条数据,想要找到id=100的数据,游标只需爬99格即可返回,但如果id=10000000,就要爬将近1000w个格子才能返回。对于这42亿条数据,平均查询次数是21亿次。
二叉查找树
作为改进,有人提出用树结构来存储数据。比如,如果要找id=6的数据,那么只要比较3次,小于爬格子次数(5次)

如果要找id=9的数据,只要比较4次,小于爬格子次数(8次)。
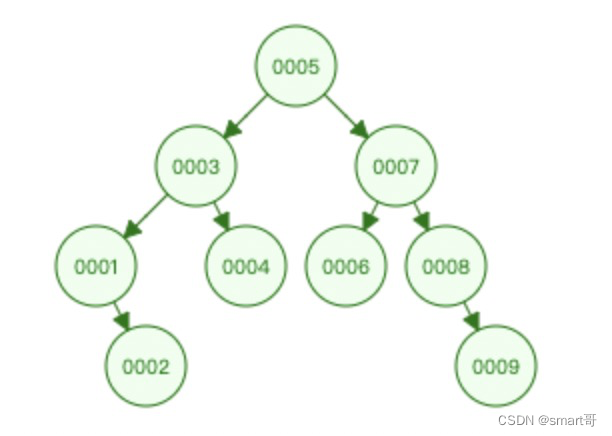
结合两次实验,SUN的工程师发现:
在一棵树中找到目标数据所需的比较次数 = 目标数据所在的层级
如果用一棵树来存储42亿条数据,即232=42亿,树的层级是32,最差的情况也只要查32次(需要是二叉平衡树),远远小于线性结构的平均21亿次,这是非常夸张的。
有人可能会钻牛角尖,说我没有对线性结构中42亿条数据采用二分查找法...真是冤枉,这完全是两个概念。
眼前就是一棵存了42亿数据的树 和 一条存了42亿数据的长条格子,“焊死”在那了,而且指针都是从第一个位置开始的,每移动一次就比较一次,直到找到匹配的数据。所以,我们是无法直接把42亿数据读取到内存中进行二分查找的。
只不过二叉树结构刚好天然就可以进行二分查找,所以效率非常高。
然而,树结构也分好几种:
- Binary Search Tree(二叉查找树)
- AVL Tree(二叉平衡树)
- B Tree(平衡树)
- B+ Tree(大名鼎鼎的B+树,对B Tree的改进)
- ...
大家可以访问Data Structure Visualizations这个网站动手玩一下,特别注意上面的4种树:

如果你听我的建议,打开上面的网站选择Binary Search Tree并按1,2,3,4...的顺序插入数据时,它其实是就变成了线性结构:

显然,这不是我们想要的结果,因为事实证明线性结构不适合存储大数据,因为后期数据量大了以后要爬很多“格子”。
二叉平衡树
相比来说,AVL Tree更符合SUN工程师的需求:

二叉平衡树会在数据插入完毕后自动调整节点,好让“树的层级”不至于太深。(赶紧去动手玩一下)
按理来说,如果我们按二叉平衡树组织表数据的话,应该是非常完美的。你想啊,42亿数据中找一条记录最多只需比较32次,尤其是对于CPU来说,别说32次比较,哪怕32w次简单数据的比较都不会超过0.1秒。但是!问题在于这里所谓的“32w次简单数据的比较不会超过0.1秒”有个前提条件:数据必须全部在内存中。
而我们的表数据因为数据量很大,而且需要持久化,所以一般来说是存在磁盘中。即使采用树结构组织数据,查询时还是需要把数据加载到内存中,这里就涉及到磁盘-内存的IO操作。通常情况下,没有人会直接把500w行数据一次性加载到内存中进行二分查找,内存极有可能顶不住(同时访问多张表,全部加载)。所以,最终我们组织数据库的方式只能是:
- 把数据存在磁盘中
- 数据按树结构组织
- 查询时分块读取数据并比较,持续进行磁盘IO读取节点,直到找到目标数据
二叉平衡树与磁盘IO
数据存在磁盘中,没问题。
数据桉树结构组织,没问题。
查询时分块读取数据,有一点点问题。

磁盘IO是非常耗时的操作,耗时到什么程度呢?大家可能都听过各个语言的执行效率:
C > C++ > Java >> Python
但这些都是在内存层面谈论语言自身的执行效率,而实际上开发一个Web应用,无论用上述哪个语言,网站响应速度都是可以满足用户需求的,真正的瓶颈是IO(网络IO和磁盘IO)。就好比F1赛车、奥迪A4和拖拉机一起跑在北京4环的路上,限制它们的不是引擎,而是堵车
所以,二叉平衡树虽然查找42亿数据最多只需32次,但是32次磁盘IO还是不能接受的。
B树
基于上面的分析,如果考虑磁盘IO,那么原本优秀的二叉平衡树将显得不再那么优秀。错的不是二叉平衡树,而是我们没有那么大的内存,也不方便把数据都放内存。
但现在不是考虑谁对谁错的时候,要想优化当前数据库,关键是减少磁盘IO次数,而影响IO次数的关键因素就是树的层级(深度)!举个例子,如果目标数据在第二层,那么只要比较到第二层,就找到目标数据直接返回,不用再继续磁盘IO读取下一个节点。而如果数据在32层,那么就需要进行32次磁盘IO,比较到最后一层的节点。
那么,如何减少树的层级呢(让树变矮)?
请大家思考一下232中的“2”指的是什么?
其实就是“二叉平衡树”的“二”,而指数32代表树的层级。也就是说,如果以二叉平衡树的结构组织42亿行数据,那么树的深度是32。如果是“三叉平衡树”呢?
3?? = 232
3的指数大概为21。也就是说,如果用“三叉树”组织数据,那么层级将会减少到21,也就意味着磁盘IO次数最多为21次。

所以,到这里我们已经有答案了:要想减少二叉平衡树的磁盘IO次数,需要增加它的“叉”,变成“N叉平衡树”,从而减少树的深度。
此时有位长者说了一句:你们心里没点B树吗。
听到这,SUN的工程师颇受启发:对哦,直接用B树就好了。
B树有个“阶”的概念,比如“三叉平衡”的B树其实叫“3阶B树”。
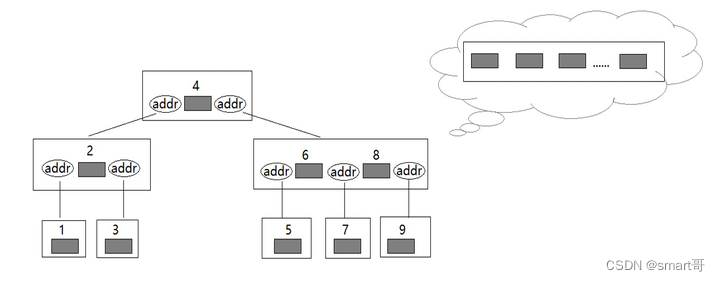
通过上面的图,我们会发现B树每个节点可以存多行数据(二叉平衡树每个节点只存一行数据),且每个节点可以连接至少2个节点,但最多连接数不超过M(M是当前B树的阶数)。
这样组织的好处是,每次加载一个节点时都可以从磁盘带出更多条数据,从而减少磁盘IO的次数。比如原先比完id=3,接下来要和id=5比较,需要再从磁盘中把id=5的数据读出来。而现在当前节点已经有id=3,id=5的数据了,直接比较即可,无需做磁盘IO。
这是典型的“空间换时间”。
但B树最难的地方不是结构本身,而是如何实现这种结构,尤其是如何通过B树组织数据库的表数据?

举个例子,当我要找id=7的数据时,需要先找到根节点,和id=4的节点比较,由于5>4,所以选择右侧那一支,接着因为6<7<8,所以这个节点中三个addr选择中间的addr,顺着这个地址找到7的节点,然后取出数据。
至于如何根据id范围确定addr,以及节点内部addr和表数据是如何组织的,可以不用深究。但有一点要知道:节点内的数据比较是很快的,因为它本身是在内存中,且据说也是二分查找。
上面只是演示了3阶B树,实际上1个节点可以存更多数据,做成N阶B树:
分析到这里,历史的话剧就告一个段落,让我们看看MySQL索引的真正实现方式吧。
B+树与索引
上面分析了B树如何实现索引,但B树仍存在一点瑕疵。实际上MySQL的索引也不是采用B树结构,而是B+树。
为什么不用B树呢?
在操作系统中有个叫“页”的概念,是用来存储数据的一种单位,大小为4k。MySQL中也有“页”的概念,但大小为16k,你可以理解为MySQL中的“页”就是上面B树的一个个节点。
那么问题来了:你知道日常开发中,表中的一行数据大概占多少字节吗?
让我们来计算一下:
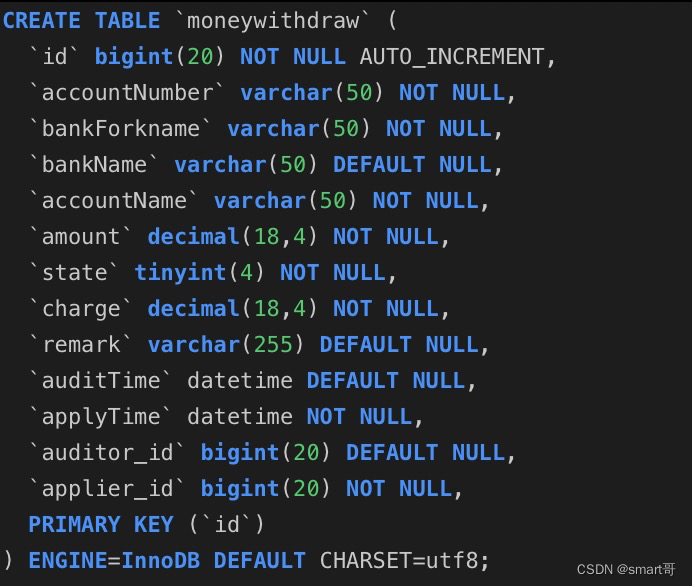
在上面这张表中,按每列数据类型推算,一行数据大概 8+150+150+150+150+9+2+9+750+5+5+8+8=1404字节,就算1k好了,因为节点最大size是16k,所以每个节点最多只能存16行数据。
我们之前之所以从二叉平衡树转为B树,是因为B树的每个节点可以存更多数据。但上面的计算告诉我们,其实也就是比二叉平衡树多了15条数据而已。
但原则是对的,为了尽可能使树“变矮”从而减少磁盘IO,最好的做法是让一个节点尽可能地塞入更多的数据。
不过把整行数据塞到节点中,有点太浪费了,我们其实可以把每一行数据的主键存进去。即使用bigint类型做主键,一个主键也就8个字节。假设每个主键对应一个addr(指针),MySQL中一个指针为6个字节,那么节点内每个主键-地址这样形式的数据能存16*1024/14=1170个。

这其实就是B+树对B树的改造。
所谓的B+树,就是把原先B树中分散在各个节点的数据都“赶到”最底层的叶子节点,非叶子节点只存储主键-addr形式的数据:

最终,一棵3层的B+树,最底下的叶子节点总共能存2000w条数据。
有部分同学可能还是不明白B+树为什么比B树能存储更多数据,这里再举个最极端的例子,假设一行表数据8k,如果是B Tree,由于最上面的节点存了整行数据,所以只能存两行,最终有3个addr,只能指向3个其他节点:

但如果是B+ Tree只存主键:

那么最上面的节点可以存更多的主键,指向更多的下级节点,就有更多的“16k数据”。上面还只是分析单个节点的情况,如果放眼整棵索引树,最终叶子节点会多很多很多的“16k数据”。
从MySQL学习者的角度而言,我们只需要知道B+树2个很重要的特征:
- 非叶子节点不存数据
- 叶子节点数据用链表相连
所以更详细的版本是:

叶子节点是有序链表,可以帮助做范围查询。
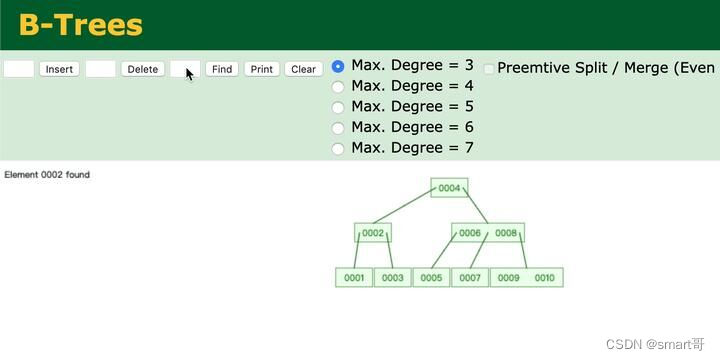
最后,还有个问题,如果我不提估计很少有人会考虑:B+树如何查找数据。
比如,B树的每个节点是有整行数据的,比如我想找id=4的数据,因为id=4的节点有完整的数据,可以直接返回:

但是,B+树怎么办?非叶子节点只有主键,如果我要找id=7的数据,到了007节点是不能直接返回的:

B+树是怎么解决这个问题的呢?去上面提到的那个网站动手试验一下即可:

讨论到这,我们来对比一下B树和B+树:
- B树的所有节点都会存储行数据,一个节点容量有限,而B+树非叶子节点只存储主键,能容纳更多数据
- 由于非叶子节点能容纳更多数据,那么同一个节点能指向更多下级节点,所以相同数据量时,B+树更加“矮”,IO更少
- B树的查询效率是不稳定的,最好情况是根节点,最差情况是叶子节点,而B+树是稳定的
- B+树的叶子节点是有序列表,非常便于范围查询
光看上面的图,大家可能觉得B树反而更“矮”,这是因为我们给B树和B+树都选择了3阶,实际上B+树可以存更多,让树变得“更矮”。
另外,很多人可能觉得B+树每次都是稳定的查询叶子节点,还不如B树不稳定的查询(最好情况根节点就返回了)。但是上面分析了,B+树每个节点能存储的数据是B树的1170/16≈73倍,意味着B+树每个节点可以连接的分支更多,相同数据量的情况下,B+树远远矮于B树。比如B树的查询IO次数是1~100,而B+树恒定为5,你觉得哪个效率高?
回头看看柏青哥,像不像一棵B+树呢~

学到这里,相信Dao层的对岸到底是什么,大家心里已经有B+树了:

数据库里一张张表,其实都可以看做一颗颗B+树。索引即数据,数据即索引(对于主键索引而言)。
对于MyISAM和InnoDB可以简单总结如下:
- MyISAM:非聚簇索引
- InnoDB:
- 聚簇索引:主键索引,叶子节点是表数据
- 非聚簇索引:辅助索引(唯一索引、普通索引),叶子节点是主键,必要时需要根据主键回表查询
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬



![23111702[含文档+PPT+源码等]计算机毕业设计javaweb高校宿舍管理系统寝室管理](https://img-blog.csdnimg.cn/img_convert/41b5adbc95dfdf8ec2f762c343eae7c5.png)