作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
上一篇,我们重走了一遍数据库索引的历史,认识了B+树结构,这一篇我们回归现实中的MySQL数据库,学习具体的SQL优化原则,并从索引底层原理出发,分析为什么会有这些优化原则。
提到索引,很多人就会说:哦,索引能提高查询速度。一般这么说的人,可能学得还不错,但绝对还没有完全掌握索引的底层原理。
索引的类型
打开Navicat,尝试创建索引时会发现有4种索引类型可以选择:
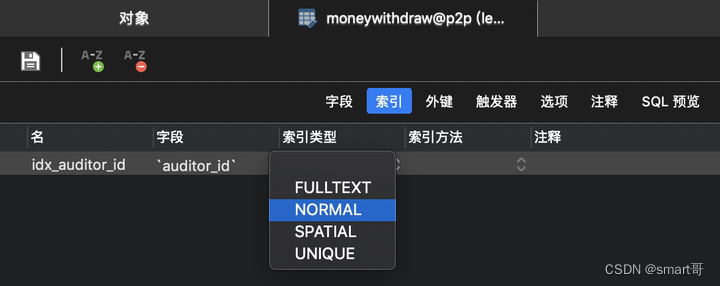
- 全文索引
- 普通索引
- 空间索引
- 唯一索引
普通索引就可以组织树结构了,而唯一索引在普通索引的基础上还要求索引列不能重复。比如,假设我们给student表的name列加了唯一索引,如果表中已经存在"张三",那么再次插入"张三"将会报错。
MySQL这种关系型数据库并不适合进行全文检索(考虑Elastic Search),所以全文索引一般很少使用。
至于空间索引,我也不知道是什么。
实际开发常用的索引只有普通索引和唯一索引,其他的可以不用理会。
索引的实现方法
索引的实现方式一般有两种,通过B+树结构或hash算法实现。
特别注意,这里虽然写的是"BTREE",但MySQL确实使用的是B+Tree。
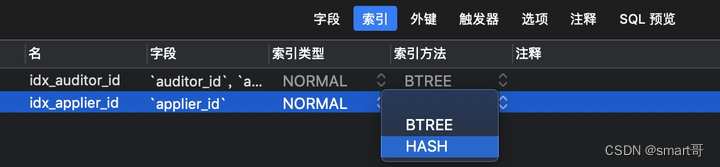
这个概念,其实和上面“索引的类型”并不冲突。
比如,对于普通索引,我们可以使用B+树的结构组织索引,也可以使用hash算法实现。经过上一篇的学习,我们对B+树结构已经比较了解,所以这里单独聊一下hash索引。
所谓hash索引,其实就是利用哈希算法为索引列计算得到唯一的存储地址,一般来说这个地址是不会重复的(重复的情况被称为哈希冲突)。
举个燕十八老师说的例子:
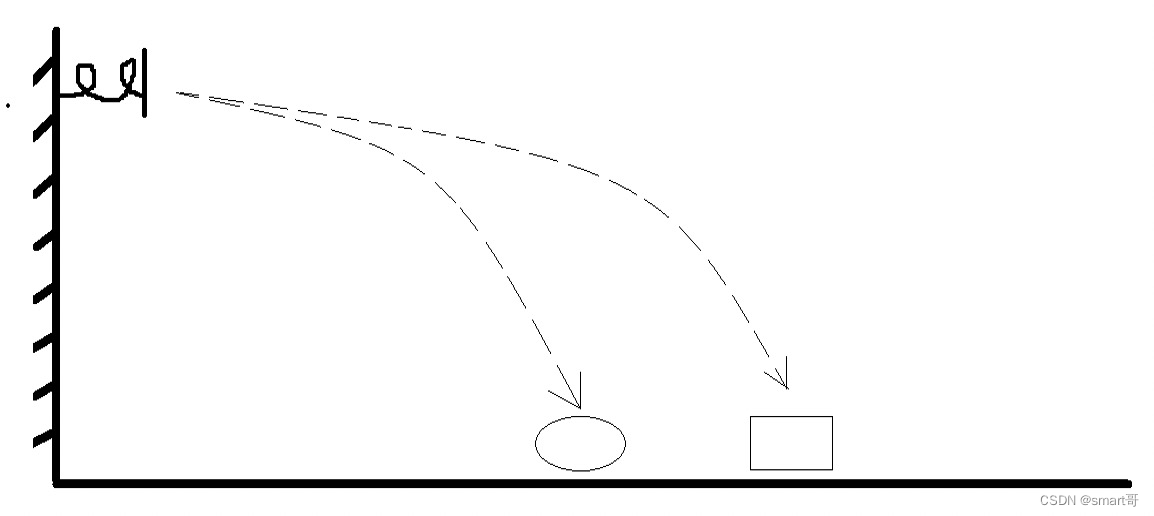
在墙上装一根弹性永不衰变的弹簧,每次拿不同的物件把弹簧压到极限后放开,不同的物件最终落点会不同。比如你上回存了一本书,那么下次想要找到这本书时,只需要拿一本 一模一样的书重新弹一下,即可在本次落点处找到上次那本书。
对应到实际的数据库索引设计上,就好比你存入id=10086的数据时,根据id弹一下得到了一个落点并存储数据,下次拿着id=10086查询时,只要把id再弹一下,就能马上找到对应的行数据,是不是很快呢~
而所谓的哈希冲突,指的是某次你换成一个书包测试时,结果因为空气阻力或重量等综合因素作用,落点竟然和某本书是一样的,也就是落点发生了冲突。
但上面的比喻其实不准确,会让人误以为越重的物品落点越近,越轻的物品落点越远,误以为hash索引可以进行范围查找。我们先来了解下hash索引的优劣,再来解释为什么hash索引不适合做范围查询。
hash索引的优劣势
- 优势:速度非常快,只需一次计算即可得到地址,时间复杂度O(1),而B+树是O(logn)
- 劣势:对于范围查找无能为力,只能逐次计算得到所有数据,而B+树叶子节点是有序链表,范围查询非常方便。另外,哈希算法本身代表着精确定位,依赖于计算的入参得出唯一的值,所以无法进行模糊匹配。你给我"bravo",我可以计算唯一的hash值,你给我"bra%",我会以为这人就叫"bra%",也计算一个值,但这个值代表着"bra%"计算得到的落点,而不是"所有以bra开头的数据"的落点,显然是不对的
hash索引为什么不适合做范围查询呢?通常做范围查询时,我们只需要计算两个边界值,处于边界值之间的数据都是符合要求的。但对于hash索引,这是不成立的,因为hash本身就是散列的,它的落点其实是没有规律的。
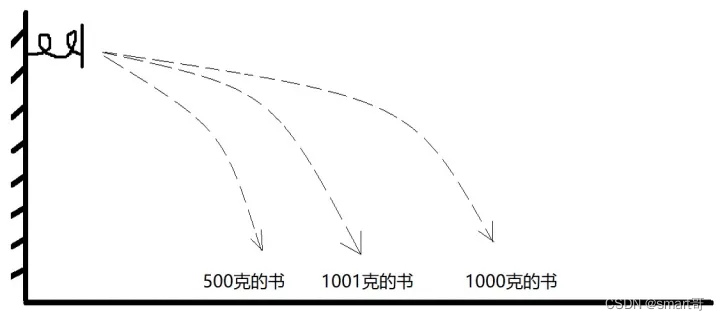
比如你想要重量在500克~1000克的全部书籍,但这个区间内的数据不一定就是500~1000克的书(对于真正的hash算法,重量与距离并不是正相关,所以我说上面的弹簧例子不是很恰当)。比如在JavaSE阶段接触HashMap时,大家也发现了,put的顺序和遍历的顺序并不一定相同。比如第一次put存了1001克的书,第二次put存了500克的书,你以为取出的顺序是1001克、500克,其实是500克,1001克(顺序)。
说到hash索引,还有人记得《实用小算法》中List转HashMap的操作吗?其实就是借鉴hash索引!
索引的创建
索引的创建时机有两处:
- 起初,建表时顺便建立索引
- 后期,修改表结构创建索引
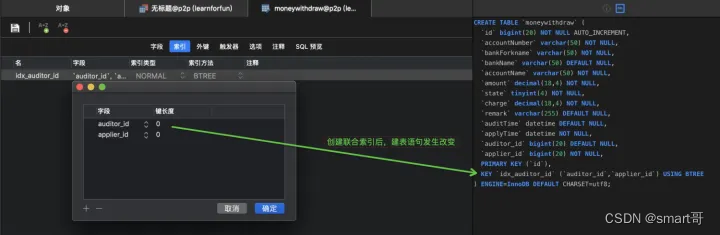
比如,一开始就创建索引:
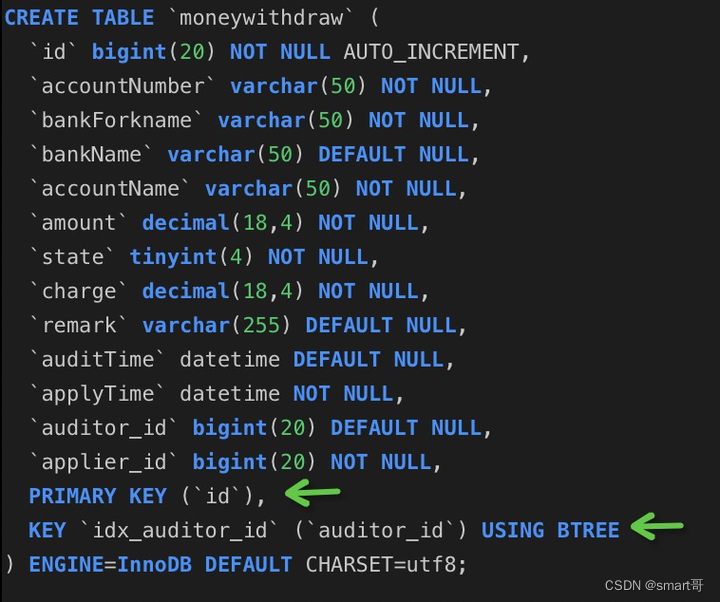
这张表有两个索引:主键索引、auditor_id普通索引。
主键索引并不属于上面介绍的4种索引类型之一,但所谓的Primary Key可以看做 唯一索引 + NOT NULL约束。
后期如果需要添加索引,可以通过两种方式:SQL语句、Navicat图形界面。
-- 1.添加PRIMARY KEY(主键索引)
ALTER TABLE `table_name` ADD PRIMARY KEY (`column`) ;
-- 2.添加UNIQUE(唯一索引)
ALTER TABLE `table_name` ADD UNIQUE (`column`);
-- 3.添加INDEX(普通索引)
ALTER TABLE `table_name` ADD INDEX index_name (`column`);
-- 4.添加FULLTEXT(全文索引)
ALTER TABLE `table_name` ADD FULLTEXT (`column`);
-- 5.添加联合索引
ALTER TABLE `table_name` ADD INDEX index_name (`column1`, `column2`, `column3`);在本案例中,可以写:
ALTER TABLE `moneywithdraw` ADD INDEX idx_auditor_id (`auditor_id`);利用Navicat图形界面创建单列索引:
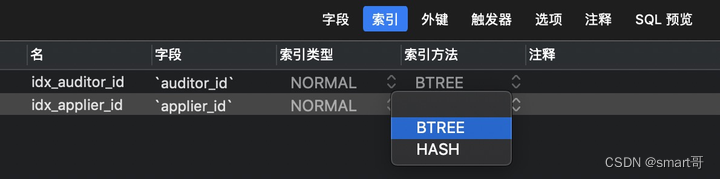
利用Navicat图形界面创建联合索引:
索引的好与坏
文章开头有一句话:
提到索引,很多人就会说:哦,索引能提高查询速度。一般这么说的人,可能学得还不错,但绝对还没有完全掌握索引的底层原理。
如果你认为索引的优势只是加快查询,那就太小看索引了。
索引的优势是:
- 加快查询速度(包括关联查询)
- 加快排序速度(ORDER BY)
- 加快分组速度(GROUP BY)
虽然加快排序、加快分组最终还是体现在加快查询速度上,但能主动意识到这一点算是一种突破,只有你意识到索引能加快排序和分组,你才会在写ORDER BY和GROUP BY时有意识地利用索引(最左匹配原则),从而写出更优的SQL。
索引的劣势:
- 对索引列的增删改需要额外维护索引,也就是说索引能提高查询速度,但往往会降低增删改的速度
- 日常开发通常是建联合索引,而联合索引需要考虑索引失效问题
- 太多的索引会增加查询优化器的选择时间
建索引的原则
很多人觉得SQL优化才是重中之重,创建索引只需要一行代码即可,没什么大不了的。但现在你已经知道了索引的优势与劣势,你会明白“在合适的字段建立索引”是多么空泛的口号。创建索引的判断依据究竟是什么呢?
创建索引有4个大原则:
- 联合索引应该优于多个单列索引
- 索引应该建立在区分度高的字段上
- 尽量给查询频繁的字段创建索引,避免为修改频繁的字段创建索引
- 避免重复索引
第一个原则背后的原因是,实际上数据库一次查询只会选择一个索引(不包括回表),更专业的说法是每次查询只会选择一个执行计划。所以即使你给所有列都加了索引,SELECT xx, xxx FROM table WHERE ...时,数据库也只会择优选择一个执行计划进行查询。既然其他索引帮不上忙,又会增加维护负担,为何我们还要执意创建多个单列索引呢?
看到这,你可能会反问:我靠,那MySQL也太笨了吧,为什么这么死心眼一次只利用一个索引?
我个人的理解是,索引本身的出发点是“走完一遍索引后,数据库应该返回精确的结果或很小的结果集”,此时再走一遍索引还不如直接遍历结果集来得快。当然,这个假设是建立在“你建立的索引区分度很高”的基础上。
什么是区分度很高?这就是第二个原则。比如,表中有100w学生数据,你如果在sex列加索引,那么根据sex大概只能筛选出50w,这是一个很大的结果集,此时这个索引就很差,因为区分度太低了。
第三个原则就是字面意思,总之要意识到索引在加快查询的同时几乎必然会对修改产生负担,所以创建索引并没有那么简单,它绝对是一门“平衡的艺术”。
第四个原则是,比如已经建立a索引,又建立index(a,b,c)联合索引,此时单列索引a就是冗余的,因为联合索引已经可以保证符合条件时会利用a索引。在物理存储上,a单列索引和index(a, b, c)是两个独立的B+树。此时如果留着a单列索引,会增加维护成本。
以上四个原则,后面的内容还会重新提到。
MySQL常用引擎
MySQL的引擎有很多种,但最常听到的就MyISAM和InnoDB,而实际开发几乎99%选择使用InnoDB,而且MySQL5.6还是哪个版本以后默认引擎就从MyISAM变成了InnoDB,所以这里着重介绍InnoDB,简略介绍MyISAM。
对于两种引擎的介绍,可以看下面
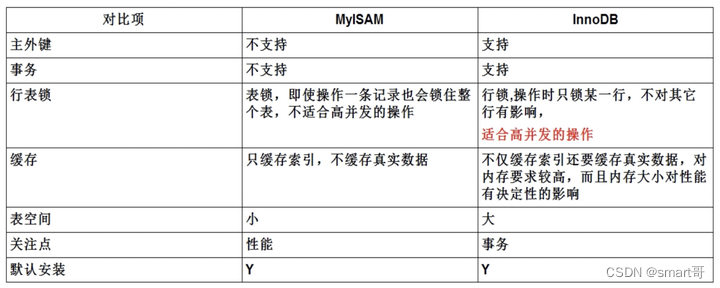
这里主要想和大家讨论MyISAM和InnoDB在索引组织上的区别。大家应该都已经知道,MyISAM和InnoDB存储数据的方式是不同的。
MyISAM的每张表在存储时会分为3个文件:
- 表结构
- 表数据
- 索引
也就是说,表数据和索引是分别独立存储的。
而InnoDB的表数据在存储时只分为2个文件:
- 表结构
- 表数据+索引
需要注意的是,InnoDB所有表的数据和索引都在同一个文件里(见下一个小节)。
聚簇索引与非聚簇索引
对于BTREE索引而言,从数据的组织形式来看,索引又可以分为两大类:
- 聚簇索引
- 非聚簇索引
所谓聚簇索引,可以简单理解为索引和数据是“聚合”在一起的,而非聚簇索引的数据和索引是分开的。
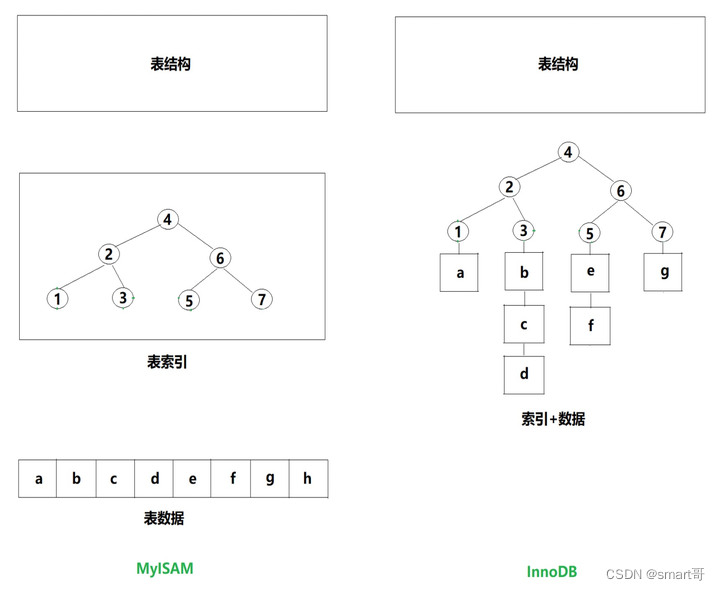
对于MyISAM和InnoDB,可以简单总结如下:
- 非聚簇索引(MyISAM)
- 聚簇索引(InnoDB)
- 主键索引:叶子节点是表数据
- 辅助索引(唯一索引、普通索引):叶子节点是主键,必要时需要根据主键回表查询
对于MyISAM而言,根据索引快速查询到目标结果后,往往都需要“回表”。所谓“回表”,一般指的是根据索引确定数据行以后,由于缺少其他列的字段,需要回到数据表中取得其余数据。在这句话描述中,索引和数据表是独立的,这也确实是MyISAM的文件结构。
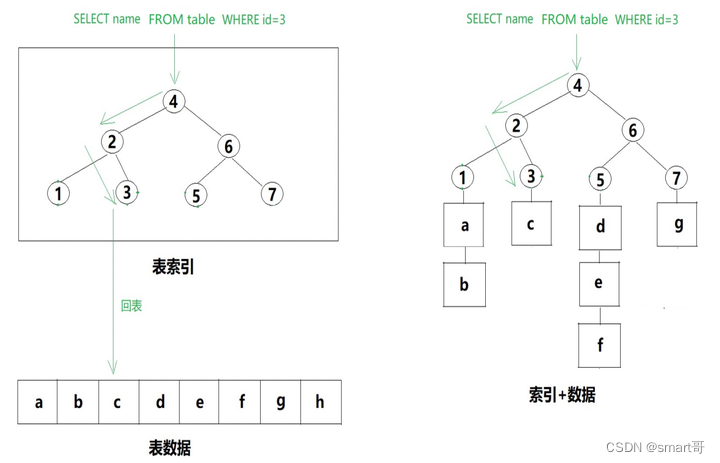
而InnoDB引擎的主键索引无需回表,每一行完整的数据都直接挂在叶子节点下,可以直接返回。对于InnoDB的主键索引而言,数据即索引,索引即数据。
InnoDB的主键索引与辅助索引
InnoDB的索引属于聚簇索引,但并不是说InnoDB下的所有索引下面都会挂着数据。假设一个场景:
用户新建表后,自然会有主键索引。但后期发现name字段查询很频繁,于是加了name索引。
如果name索引(辅助索引)也和主键索引一样挂着数据,那么两个索引数据就会重复。相当于一张student表,存了两份数据。且不说数据冗余,更新时还可能产生数据不一致。
所以InnoDB的做法是,辅助索引只存储索引列+主键,必要时需要“回表”:
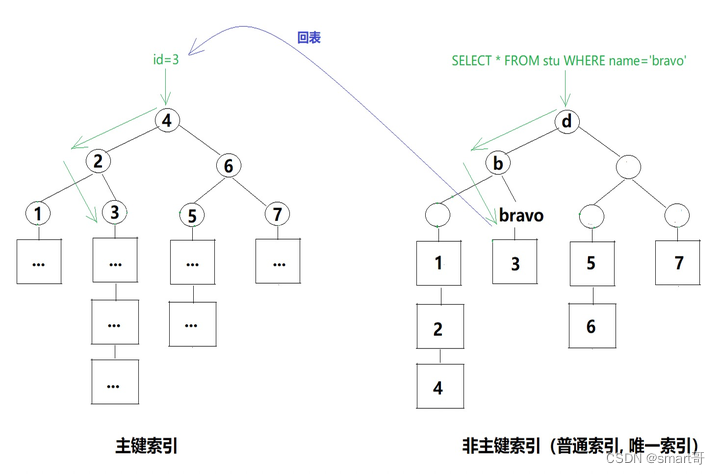
由于SELECT * FROM stu WHERE name='bravo'中,查询的数据是*,也就是整行数据。而上面的辅助索引只存了主键+name,所以必须回表,拿着主键再去跑一遍主键索引,最终返回数据。
总的来说,MyISAM由于是非聚簇索引,决定了它必须回表,而InnoDB是聚簇索引,主键索引一般是不用回表的,而利用辅助索引时可能需要回表。
再聊聊回表
介绍MyISAM时,我们第一次接触“回表”的概念,因为MyISAM的索引和表数据是分开的,从索引回到表数据中查询数据的操作称为“回表”,大家很容易接受。
而在InnoDB的辅助索引上查询完毕后回到主键索引的操作也叫“回表”,这是对于InnoDB的主键索引而言,数据即索引,索引即数据,回到主键索引查询当然也算是回表查询啦。
SQL优化的本质其实就是减少/减小磁盘IO,而回表必然会增加磁盘IO次数(还是要把主键索引的一个个节点加载到内存)。
如果仔细观察MyISAM和InnoDB的回表,你会发现MyISAM的查询速度会优于InnoDB。原因在于:
MyISAM索引和数据是分离的,索引很小,必要时可以全部一次性加载进内存,磁盘IO降到最低,只需在最后执行一次回表。
而InnoDB由于是聚簇索引,索引和数据不分离,导致无法直接一次性加载索引,转而采用磁盘IO的方式分多次读取节点。最差的情况下,根据普通索引找到目标数据的id后,还需要回表查询,重走一次主键索引!
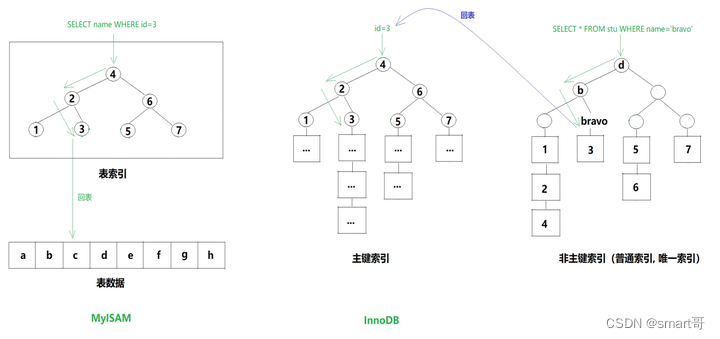
所以,一般在介绍MySQL引擎时,MyISAM的特点都是查询快,但不支持事务,而InnoDB查询稍逊,但支持事务。
InnoDB的回表与索引失效

InnoDB这种先查辅助索引,再根据辅助索引上查到的id回到主键索引查询全部行数据的行为称为“回表”。假设一种情况:一个student表,id为主键索引,name是辅助索引(普通索引或唯一索引)。对于
SELECT * FROM t_student WHERE name like 'bravo____'
假设t_student表共有10000行数据,其中name字段命名方式为"bravo1988"、"bravo1989"...,那么极有可能会发生以下情况:
MySQL沿着辅助索引(name)跑了整棵树,最终得到9999个符合条件的id,然后还要遍历9999个id,逐个再跑一次主键索引。
这种情况效率极低,所以MySQL往往选择壮士断腕,放弃辅助索引,直接全表扫描。所谓全表扫描,个人认为是走主键索引底部的链表。在上面的案例中,因为WHERE条件是name,而主键索引是id组织的,索引无法利用B+树。
对于MySQL的InnoDB索引,当利用辅助索引查询的结果集超过某个阈值(比如占总数据的80%,泛指,未求证),MySQL便会放弃走索引,直接全表扫描。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬