简介
Scrapy是一个强大的Python爬虫框架,可用于从网站上抓取数据。本教程将指导你创建自己的Scrapy爬虫。其中,中间件是其重要特性之一,允许开发者在爬取过程中拦截和处理请求与响应,实现个性化的爬虫行为。
本篇博客将深入探讨Scrapy中间件的关键作用,并以一个实例详细介绍了自定义的Selenium中间件。我们将从Scrapy的基本设置开始,逐步讲解各项常用设置的作用与配置方法。随后,重点关注中间件的重要性,介绍了下载器中间件和Spider中间件的作用,并通过一个自定义Selenium中间件的示例,演示了如何利用Selenium实现页面渲染,并在Scrapy中应用该中间件。
如果对您对scrapy不了解,建议先了解一下:
初识Scrapy:Python中的网页抓取神器 - 掘金 (juejin.cn)
编写settings.py
本文件为scrapy的配置文件.
以下是有关Scrapy设置的详细介绍:
- BOT_NAME: 设置爬虫的名称。
- SPIDER_MODULES 和 NEWSPIDER_MODULE: 定义了包含爬虫代码的模块路径。
- ROBOTSTXT_OBEY: 设置为True时,遵守Robots协议,爬虫将会尊重网站的robots.txt文件。
- USER_AGENT: 设置用户代理(User-Agent),模拟浏览器访问。
- DOWNLOAD_DELAY 和 CONCURRENT_REQUESTS_PER_IP: 控制下载延迟和每个IP的并发请求数,用于避免过度访问网站。
- COOKIES_ENABLED: 设置为True时,启用Cookies。
- DEFAULT_REQUEST_HEADERS: 设置默认的HTTP请求头。
- ITEM_PIPELINES: 定义项目管道,用于处理爬取的数据。
- DOWNLOADER_MIDDLEWARES 和 SPIDER_MIDDLEWARES: 分别定义下载器中间件和Spider中间件,用于在请求和响应过程中执行特定操作。
- AUTOTHROTTLE_ENABLED 和 AUTOTHROTTLE_TARGET_CONCURRENCY: 自动限速功能,帮助动态调整请求速率,以防止被封IP。
这些设置可以在Scrapy项目中的settings.py文件中进行配置。例如:
BOT_NAME = 'mybot'
SPIDER_MODULES = ['mybot.spiders']
NEWSPIDER_MODULE = 'mybot.spiders'
ROBOTSTXT_OBEY = True
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
DOWNLOAD_DELAY = 2
CONCURRENT_REQUESTS_PER_IP = 4
COOKIES_ENABLED = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
ITEM_PIPELINES = {
'mybot.pipelines.MyPipeline': 300,
}
DOWNLOADER_MIDDLEWARES = {
'mybot.middlewares.MyDownloaderMiddleware': 543,
}
SPIDER_MIDDLEWARES = {
'mybot.middlewares.MySpiderMiddleware': 543,
}
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
以上是一些常用的Scrapy设置,可以根据需要进行调整和扩展,以满足特定爬虫的要求。
其中DEFAULT_REQUEST_HEADERS中设置默认的请求头只是整个scrapy的默认爬虫,可以具体的spider里覆盖,仅作用于该spider。
例如:
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'Cookie':"*****************************************************"
}
for i in range(1, 2):
key = scenic_namelist[i]
newurl = 'https:/www.***********.com/ticket/list.htm?keyword=' + key + '®ion=&from=mpl_search_suggest'
print(newurl)
yield Request(url=newurl,headers=header)
该操作可用于一个scrapy项目里有多个网站的爬虫的情况下,需要设置不同的请求头。
可以在生成request时去添加header,将覆盖setting里配置的默认header。
而文章中PIP管道和各个中间件之中的配置后边的数字是指优先度。数字越小优先度越高,若同时启动多个中间件,请求将从优先度高的中间件->优先度低的中间件的顺序全部处理一遍。
自定义中间件
Scrapy中间件是在Scrapy引擎处理请求和响应的过程中,允许你在特定的点上自定义处理逻辑的组件。它们在整个爬取过程中能够拦截并处理Scrapy引擎发送和接收的请求和响应。中间件可以用于以下几个方面:
- 全局性处理请求和响应: 中间件可以截取所有请求和响应,允许你对它们进行全局性的修改,例如添加自定义的请求头、代理设置或处理响应数据等。
- 自定义爬取过程: 通过中间件,你可以自定义爬取的逻辑。例如,在请求被发送之前,可以通过中间件对请求进行处理,或者在收到响应后对响应进行预处理,以适应特定需求或网站的要求。
- 处理下载器(Downloader)和Spider之间的通信: 中间件允许你在下载器和Spider之间进行通信,并在其中植入处理逻辑。这可以用于在请求下载之前或响应到达Spider之后执行额外的操作。
- 实现和管理代理、用户认证等: 中间件也常用于处理代理设置、用户认证等功能。这些功能可能是整个爬取过程中必不可少的一部分。
- 处理异常和错误: 中间件可以用于捕获请求过程中可能出现的异常或错误,以执行相应的错误处理逻辑,比如重试请求或记录错误日志等。
在Scrapy中,有两种类型的中间件:
- Downloader Middleware:用于处理引擎发送给下载器的请求和下载器返回的响应。
- Spider Middleware:处理引擎发送给Spider的响应和Spider返回的请求。
通过编写和配置这些中间件,我们可以高度定制Scrapy爬虫的行为,从而更有效地处理网站数据并应对不同的场景和需求。
下面我们以一个自定义的Selenium中间件为例子来让大家更加深入的了解中间件。
from selenium import webdriver
from scrapy.http import HtmlResponse
from selenium.common.exceptions import TimeoutException
from scrapy import signals
class SeleniumMiddleware(object):
def __init__(self):
self.driver = webdriver.Chrome(executable_path='path_to_chromedriver')
@classmethod
def from_crawler(cls, crawler):
middleware = cls()
crawler.signals.connect(middleware.spider_closed, signals.spider_closed)
return middleware
def process_request(self, request, spider):
if request.meta.get('selenium'):
try:
self.driver.get(request.url)
body = self.driver.page_source.encode('utf-8')
return HtmlResponse(self.driver.current_url, body=body, encoding='utf-8', request=request)
except TimeoutException:
return HtmlResponse(self.driver.current_url, status=504, request=request)
return None
def spider_closed(self, spider):
self.driver.quit()
这个中间件示例使用了Selenium库,它会在处理Scrapy请求时,检查请求的元数据中是否包含selenium字段。如果包含,它将使用Selenium打开浏览器并加载页面,然后返回页面的HTML内容给Spider。request.meta.get也是我们判断某个中间件是否启动常用操作。
要使用这个中间件,需要在settings.py中进行相应的配置:
DOWNLOADER_MIDDLEWARES = {
'your_project_name.middlewares.SeleniumMiddleware': 543,
}
SELENIUM_BROWSER = 'Chrome' # 设置浏览器类型,可以是Chrome/Firefox等
在使用selenium中间件时有一些需要注意的地方。
如果使用场景是某个搜索框,若我们使用显示等待的方式等待结果元素的动态加载时要考虑到,若搜索结果为空的情况,此时显示等待就会报时间超限的异常。我们要提前想好处理逻辑。
下面是一个此种场景下的真实样例:
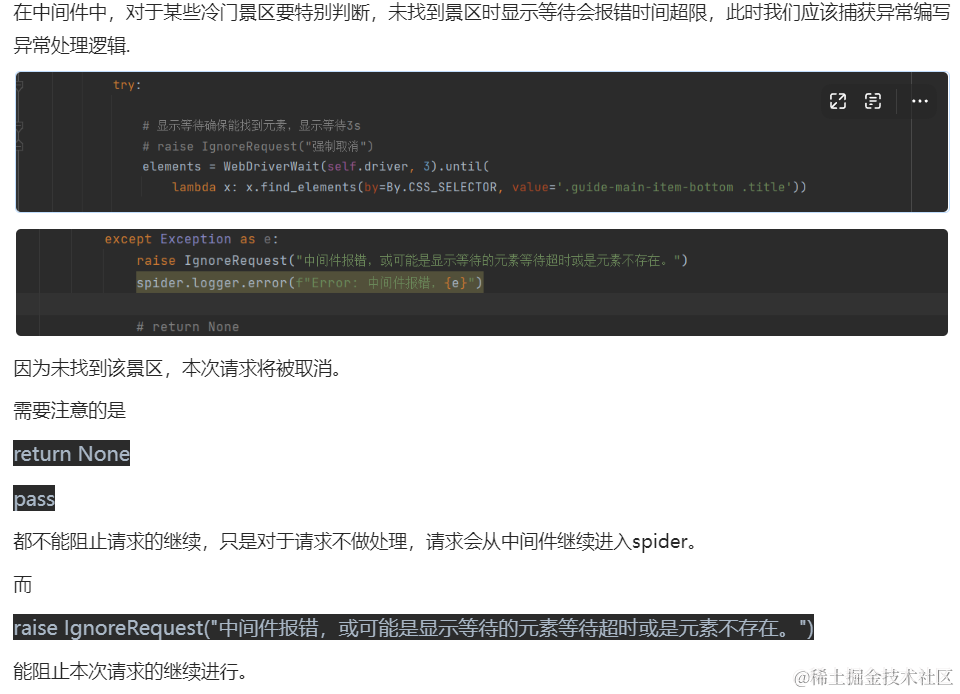
当然我们的生成URL列表的逻辑也可以放在中间件中,在def init(self):中执行。








![23111707[含文档+PPT+源码等]计算机毕业设计基于javawebmysql的旅游网址前后台-全新项目](https://img-blog.csdnimg.cn/img_convert/e1a49b4802b87123878d034ab4d10f0f.png)