开放领域对话系统是指针对非特定领域或行业的对话系统,它可以与用户进行自由的对话,不受特定领域或行业的知识和规则的限制。开放领域对话系统需要具备更广泛的语言理解和生成能力,以便与用户进行自然、流畅的对话。
与垂直领域对话系统相比,开放领域对话系统的构建更具挑战性,因为它需要处理更广泛的语言现象和用户行为,同时还需要进行更复杂的自然语言理解和生成任务。
目前,开放领域对话系统还处于研究和开发阶段,尚未有成熟的商业应用。但是,随着技术的不断进步和应用的不断深化,开放领域对话系统有望在未来成为人工智能领域的重要发展方向,为人们提供更加智能、自然、便捷的交互体验。
1.系统组成
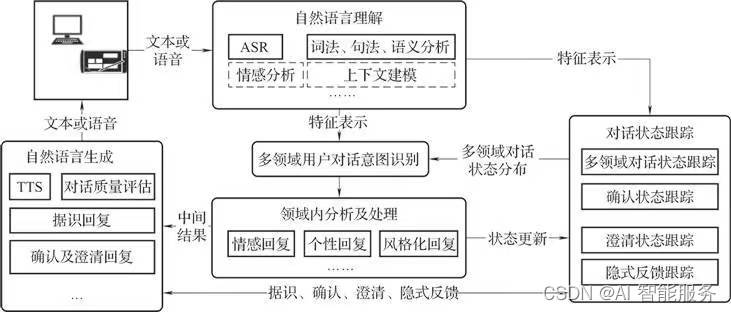
开放领域对话系统的架构通常包括以下模块:
- 自然语言理解模块:负责对用户输入进行理解,包括句子的语义、情感、语言风格等信息。该模块将用户输入转化为计算机可理解的语言表示,为后续的处理提供基础。
- 对话管理模块:负责管理和维护对话状态,包括对话的上下文、历史记录、用户意图等信息。该模块通过不断更新对话状态,来维持与用户的对话,并保证对话的连贯性和流畅性。
- 自然语言生成模块:负责生成回复用户的信息,包括文本、语音、图像等形式。该模块将计算机理解的信息转化为用户易于理解的文本或语音,提高用户满意度和服务质量。
- 知识库和规则库模块:负责存储和管理领域知识和规则信息,包括事实、概念、关系等信息。该模块为对话系统提供基础的知识和规则支持,帮助系统更好地理解和回答用户问题。
- 机器学习模块:负责对系统进行训练和优化,包括模型训练、参数调整、性能评估等功能。该模块通过不断的学习和优化,来提高系统的性能和准确性。
在开放领域对话系统的架构中,各个模块之间相互协作,共同实现与用户的自由对话。同时,系统还需要具备高度的可扩展性和灵活性,以便能够适应不同领域和行业的需求。


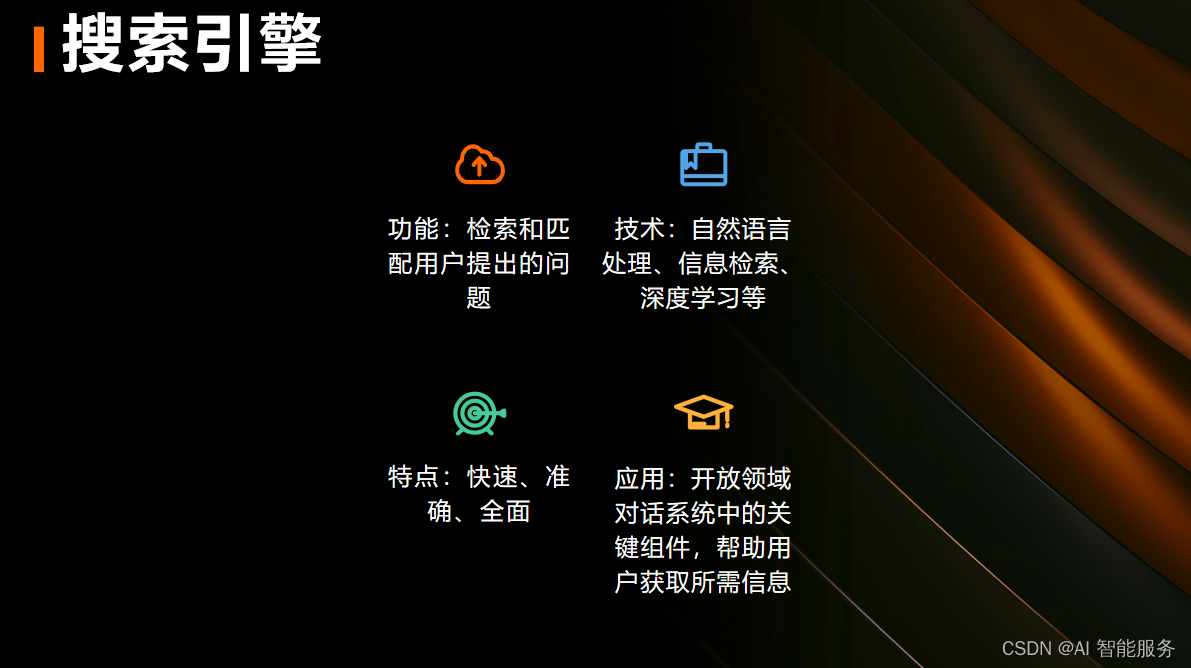
2.系统功能


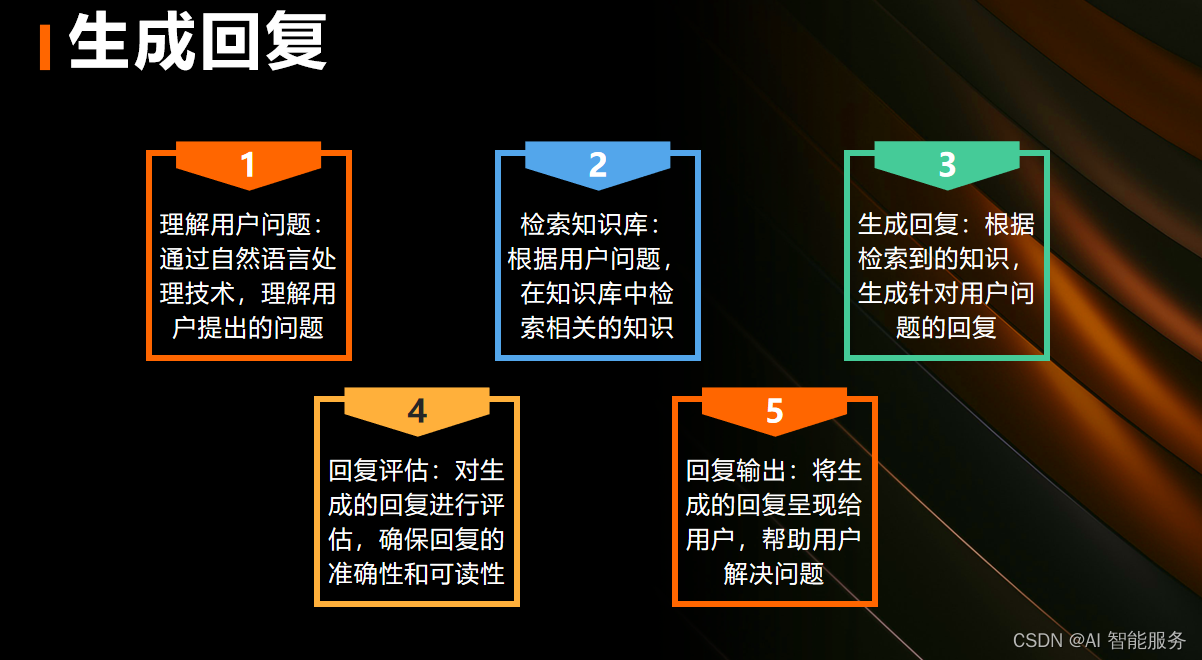
3.系统特点
开放领域对话系统具有以下特点:
- 自由对话:开放领域对话系统与用户之间可以进行任何话题的自由对话,不受特定主题或目标的限制。
- 丰富的知识库:开放领域对话系统需要具备丰富的知识库,以便能够回答用户提出的不同类型的问题。
- 多任务处理:开放领域对话系统可以完成多项任务,例如回答问题、提供建议、执行指令等。
- 社会性:开放领域对话系统需要具备一定的社会性,包括友好度、自觉性、幽默感等,以便能够与用户进行更为自然的交互。
- 上下文管理:开放领域对话系统需要对对话的上下文进行管理,以便能够理解用户的意图和维持对话的连贯性。
- 对话流程控制:开放领域对话系统需要对对话流程进行控制,包括引导对话、避免重复、确保信息准确等。
- 自然语言生成:开放领域对话系统需要具备自然语言生成的能力,以便能够生成自然、流畅的文本或语音回复用户。
- 高度可扩展性:开放领域对话系统需要具备高度可扩展性,以便能够适应不同领域和行业的需求。
开放领域对话系统是一种高度智能化、自然化、多功能的人工智能系统,能够与用户进行自由、自然的交互,并提供高质量的服务体验。

3.1优点
开放领域对话系统的优点主要包括:
- 广泛的适用性:开放领域对话系统可以应用于多个领域和行业,例如客户服务、虚拟助手、教育、智能家居等。这使得它可以满足不同用户的需求,并提高用户满意度。
- 自然语言交互:开放领域对话系统能够理解和生成自然语言,这使得用户可以以更自然、更直观的方式与系统进行交互,提高交互的效率和舒适度。
- 丰富的知识库:开放领域对话系统具备丰富的知识库,可以回答用户提出的不同类型的问题。这使得用户可以获得更全面、更准确的信息,并更好地了解相关领域的知识。
- 多任务处理能力:开放领域对话系统可以完成多项任务,例如回答问题、提供建议、执行指令等。这使得用户可以获得更全面、更个性化的服务体验。
- 社会性:开放领域对话系统具备一定的社会性,可以与用户进行更为自然的交互。这使得用户可以更好地感受到系统的友好度和亲切感,从而提高交互的舒适度。
- 高度可扩展性:开放领域对话系统需要具备高度可扩展性,以便能够适应不同领域和行业的需求。这使得系统可以随着技术的不断进步和应用的不断深化,不断进行优化和改进。
开放领域对话系统的优点在于它具有广泛的适用性、自然语言交互、丰富的知识库、多任务处理能力、社会性和高度可扩展性。这些优点使得开放领域对话系统成为一种高效、便捷、个性化的智能交互方式,可以满足不同用户的需求,提高用户满意度。
3.2缺点与困难

开放领域对话系统存在以下缺点和困难:
- 上下文理解和对话管理困难:开放领域对话系统需要理解和跟踪对话的上下文,以确保对话的连贯性和准确性。然而,由于开放领域对话系统的自由度和不确定性,理解和跟踪对话的上下文变得更加困难。此外,开放领域对话系统还需要进行多轮对话管理,以确保对话的流畅性和完整性。这需要系统具备较高的对话管理能力,包括对对话流程的掌控、对话内容的理解、用户意图的判断等。
- 语言处理和理解的复杂性:开放领域对话系统需要处理自然语言,这需要解决很多语言处理和理解的问题。例如,歧义性、一词多义、语法错误、语义理解等。这些问题的解决需要大量的数据和复杂的算法支持,增加了开放领域对话系统的复杂性和开发难度。
- 信息筛选和过滤困难:由于开放领域对话系统的自由度和不确定性,用户可能会输入大量不相关的信息,甚至是一些无意义的内容。因此,开放领域对话系统需要具备信息筛选和过滤的能力,以识别和筛选出有用的信息。这需要系统具备较高的自然语言处理和信息检索能力,增加了系统的复杂性和开发难度。
- 隐私和安全问题:开放领域对话系统需要处理用户的输入和输出信息,这涉及到用户的隐私和安全问题。因此,开放领域对话系统需要采取有效的隐私保护和安全措施,以确保用户数据的安全性和保密性。这需要系统具备较高的安全性能和隐私保护能力,增加了系统的开发难度和成本。
- 训练数据获取和标注困难:开放领域对话系统需要大量的训练数据来支持模型的训练和学习。然而,获取和标注大量高质量的训练数据是一项既耗时又耗力的任务,增加了系统的开发难度和成本。此外,由于语言的多样性和复杂性,训练数据的获取和标注也面临着很多挑战和困难。
开放领域对话系统存在上下文理解、语言处理和理解、信息筛选和过滤、隐私和安全问题以及训练数据获取和标注等方面的缺点和困难。这些问题的解决需要大量的技术投入和研发工作,增加了系统的开发难度和成本。
3.3用python搭建一个开放域智能客服
要使用Python搭建一个开放域智能客服,需要以下几个步骤:
1.数据收集和预处理
首先需要收集大量的文本数据,包括问题和答案。可以使用爬虫技术从互联网上抓取数据,或者从公开的数据集下载。收集到数据后,需要进行预处理,例如去除噪音、标准化文本等。
2.模型选择
在数据预处理之后,需要选择一个合适的模型来进行训练。可以选择的模型有很多种,例如基于规则的模型、基于统计的模型、深度学习模型等。在这里我们选择深度学习模型,因为它们可以自动从数据中学习规则和模式,并且具有很好的泛化性能。
3.模型训练
选择模型后,需要使用大量的数据来进行训练。可以使用Python中的机器学习库来进行训练,例如TensorFlow或PyTorch。在训练模型时,需要调整模型的参数,例如学习率、批次大小、隐藏层大小等,以便得到最好的性能。
4.模型评估和调整
训练模型后,需要评估模型的性能,以便了解模型是否能够正确地回答问题。可以使用测试集来进行评估,比较模型预测的答案和真实答案的匹配度。如果模型的性能不够好,需要对模型进行调整和优化,例如改变隐藏层大小、增加数据量等。
5.部署上线
完成模型训练和评估后,可以将模型部署到线上,以便用户访问。可以使用Python中的Web框架来进行部署,例如Flask或Django。在部署时,需要考虑如何处理用户输入和输出,以便得到最好的用户体验。
以上是搭建开放域智能客服的基本步骤。当然在实际操作中还需要考虑很多细节问题,例如如何保证数据的安全性和隐私性、如何处理用户反馈和投诉等。
代码展示
当然,下面是一个简单的示例代码,演示如何使用Python和TensorFlow搭建一个简单的开放域智能客服:
python
import tensorflow as tf
import numpy as np
import re
# 数据预处理
def preprocess_data(text):
text = re.sub(r'\W+', ' ', text) # 将非字母数字字符替换为空格
text = text.lower() # 将文本转换为小写
text = text.split() # 将文本拆分为单词
return text
# 构建词汇表
def build_vocab(text):
word2idx = {}
idx2word = {}
words = set(text)
for i, word in enumerate(words):
word2idx[word] = i
idx2word[i] = word
return word2idx, idx2word
# 构建模型
def build_model(vocab_size, embedding_dim, hidden_dim, output_dim):
input_layer = tf.keras.Input(shape=(None,), dtype='int32')
embedding_layer = tf.keras.layers.Embedding(vocab_size, embedding_dim)(input_layer)
lstm_layer = tf.keras.layers.LSTM(hidden_dim)(embedding_layer)
output_layer = tf.keras.layers.Dense(output_dim, activation='softmax')(lstm_layer)
model = tf.keras.Model(inputs=input_layer, outputs=output_layer)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# 训练模型
def train_model(model, data, labels, epochs):
model.fit(data, labels, epochs=epochs, batch_size=32)
# 评估模型
def evaluate_model(model, data, labels):
loss, accuracy = model.evaluate(data, labels)
return loss, accuracy
4.大模型涌现
2022年以来,大模型在开放域对话上表现出色。
ChatGPT是一种由OpenAI开发的大型语言模型,采用无监督学习方法,以Transformer为基础架构,能够通过使用大量的语料库进行训练来模拟人类的语言行为。它可以用来生成各种类型的文本,例如文章、新闻报道、产品描述、对话等。ChatGPT的目标是回答用户提出的问题或执行用户提供的指令,同时尽可能地使对话流畅自然。ChatGPT拥有大量的语料库和训练数据,这使得它能够生成高质量的文本内容,并且可以处理各种语言和主题。
ChatGPT的应用非常广泛,例如在聊天机器人、智能客服、自动翻译、自然语言处理等领域中都有应用。它也可以用于辅助写作和编辑,帮助人们快速生成高质量的文本内容。此外,ChatGPT还可以用于生成个性化的回复和答案,例如在社交媒体平台上自动回复用户的问题和评论。
【基础课5——垂直领域对话系统架构 - CSDN App】http://t.csdnimg.cn/5BUpt