title: 《网络协议》08. 概念补充
date: 2022-10-06 18:33:04
updated: 2023-11-17 10:35:52
categories: 学习记录:网络协议
excerpt: 代理、VPN、CDN、网络爬虫、无线网络、缓存、Cookie & Session、RESTful。
comments: false
tags:
top_image: /images/backimg/SunsetClimbing.png
网络协议
- 1:代理
- 1.1:正向代理
- 1.2:反向代理
- 1.3:相关头部字段
- 2:VPN
- 2.1:作用
- 2.2:VPN 与代理的区别
- 2.3:实现原理
- 3:CDN
- 4:网络爬虫
- 4.1:简易实例
- 4.2:robots.txt
- 5:无线网络
- 6:缓存
- 6.1:响应头
- 6.2:请求头
- 6.3:缓存的使用流程
- 7:Cookie & Session
- 8:RESTful
- 8.1:实践建议
网络协议从入门到底层原理。
1:代理
代理服务器(Proxy Server)。
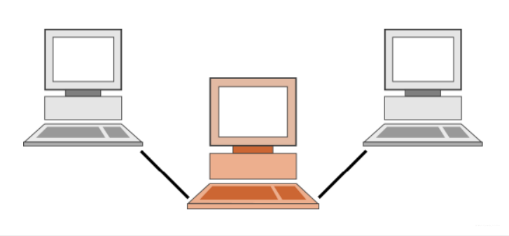
特点:
- 本身不生产内容
- 处于中间位置转发上下游的请求和响应
- 面向下游的客户端:它是服务器
- 面向上游的服务器:它是客户端
正向代理 / 反向代理:
- 正向代理:代理的对象是客户端
- 反向代理:代理的对象是服务器
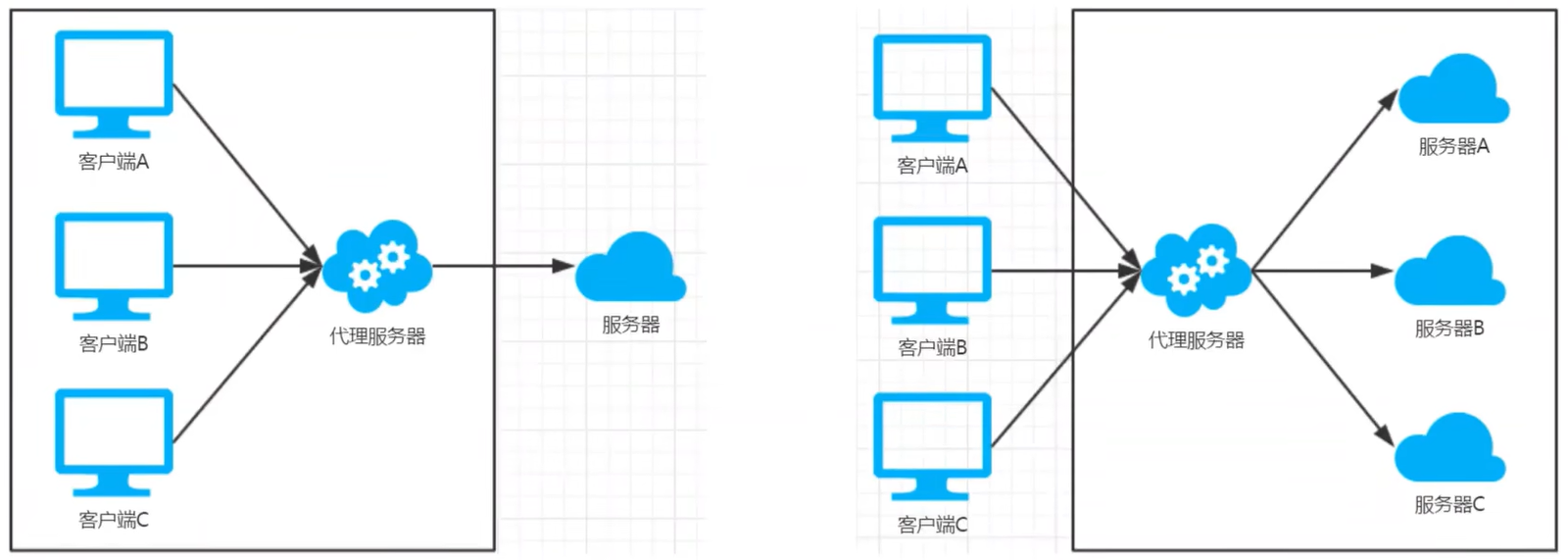
1.1:正向代理
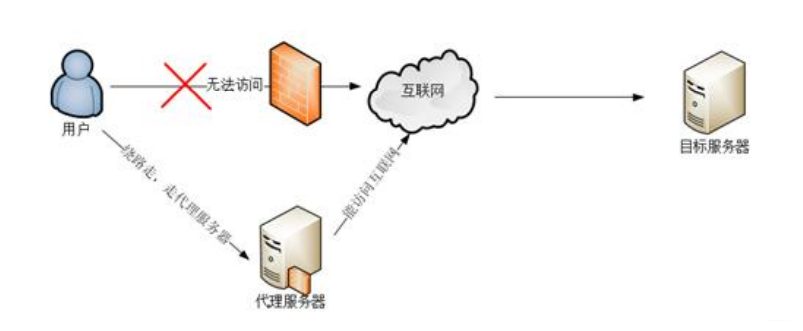
作用:
- 隐藏客户端身份
- 绕过防火墙(突破访问限制)
- Internet 访问控制
- 数据过滤
- …
1.2:反向代理
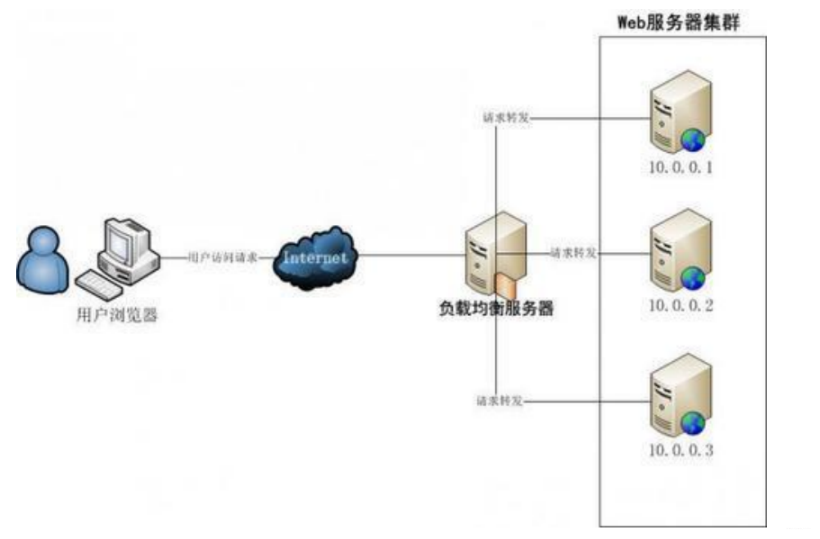
作用:
- 隐藏服务器身份
- 安全防护
- 负载均衡
- …
抓包工具的原理:
Fiddler、Charles 等抓包工具的原理:在客户端启动了正向代理服务。
Wireshark、tcpdump 的原理:通过底层驱动,拦截网卡上流过的数据。
tcpdump:
tcpdump 是 Linux 平台的抓包分析工具,Windows 版本是 WinDump。
使用手册:
https://www.tcpdump.org/manpages/tcpdump.1.html不错的教程:
https://danielmiessler.com/study/tcpdump/
1.3:相关头部字段
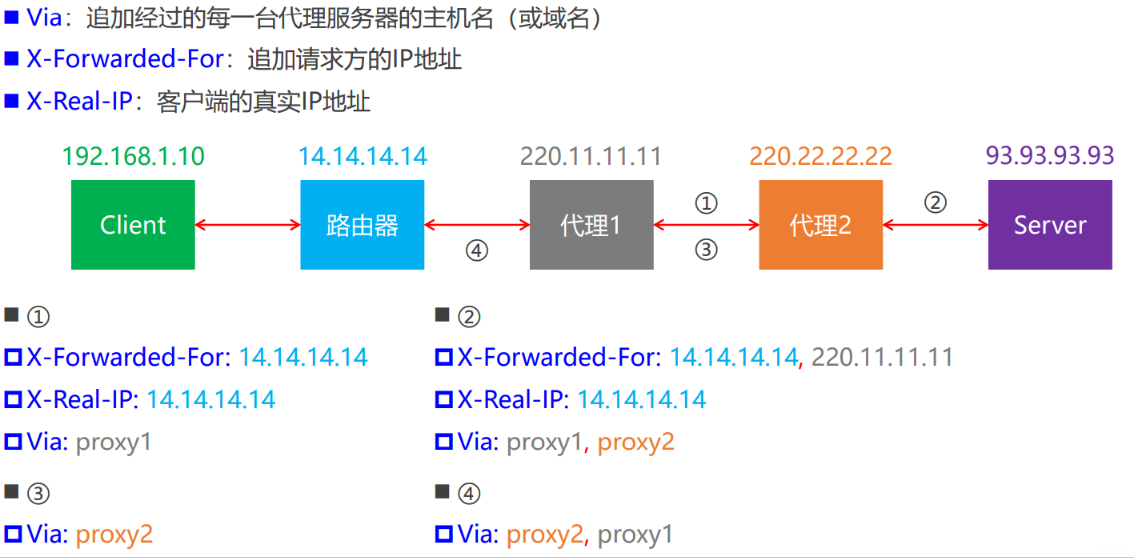
2:VPN
VPN(Virtual Private Network),虚拟私人网络。它可以在公共网络上建立专用网络,进行加密通讯。
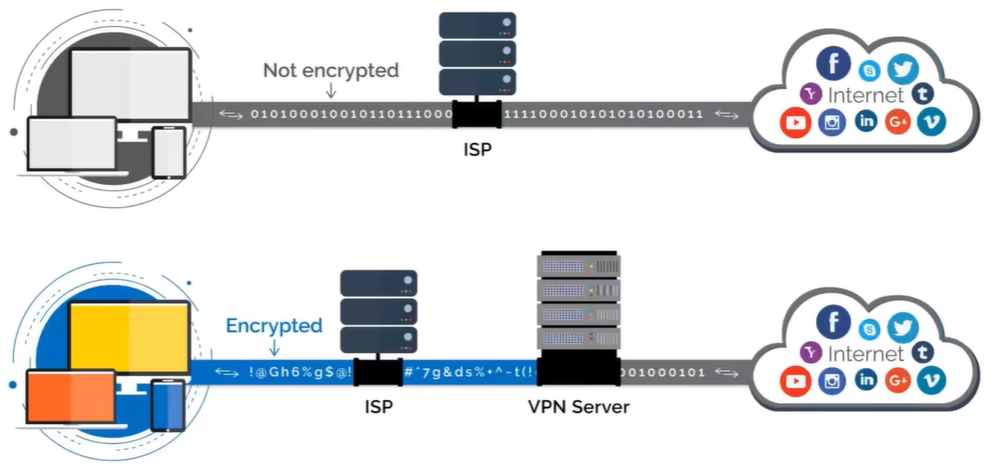
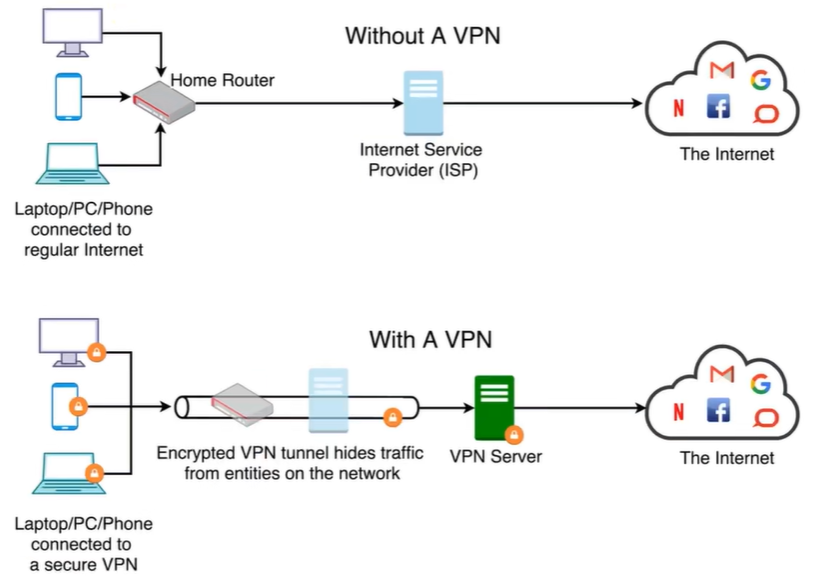
2.1:作用
- 提高上网的安全性
- 保护公司内部资料
- 隐藏上网者的身份
- 突破网站的地域限制(有些网站针对不同地区的用户展示不同的内容)
- 突破网络封锁
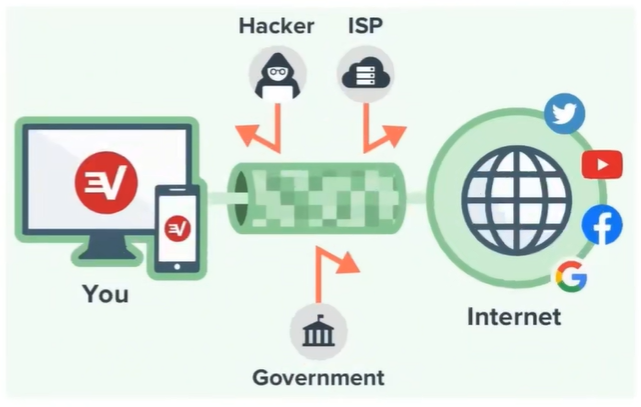
2.2:VPN 与代理的区别
- 软件
- VPN 一般需要安装 VPN 客户端软件
- 代理不需要安装额外的软件
- 安全性
- VPN 默认会对数据进行加密
- 代理默认不会对数据进行加密(数据最终是否加密取决于使用的协议本身)
- 费用
- 一般情况下,VPN 比代理贵
2.3:实现原理
VPN 的实现原理:使用了隧道协议(Tunneling Protocol)
常见的 VPN 隧道协议有:
- PPTP(Point to Point Tunneling Protocol):点对点隧道协议
- L2TP(Layer Two Tunneling Protocol):第二层隧道协议
- IPsec(Internet Protocol Security):互联网安全协议
- SSL VPN(如 OpenVPN)
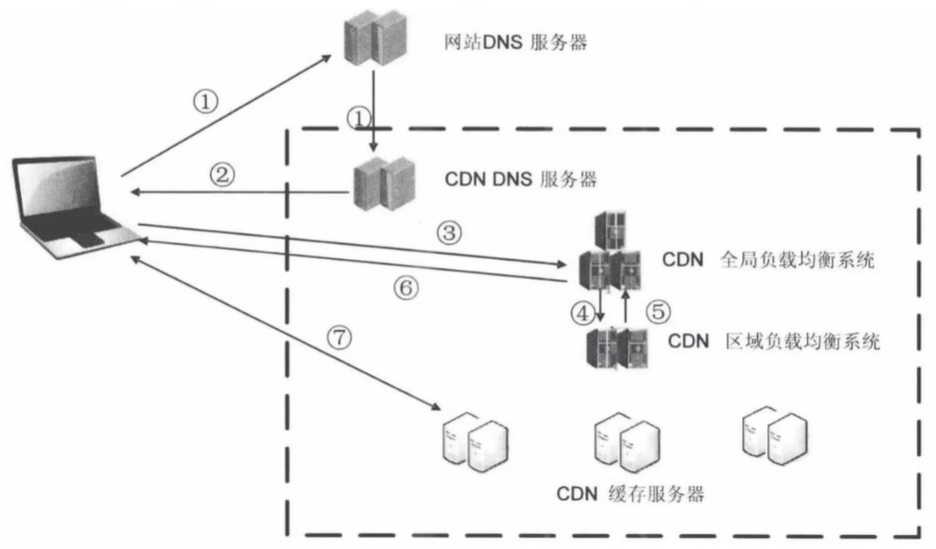
3:CDN
CDN(Content Delivery Network 或 Content Distribution Network),内容分发网络。
- 利用最靠近每位用户的服务器
- 更快更可靠地将音乐、图片、视频等资源文件(一般是静态资源)传递给用户
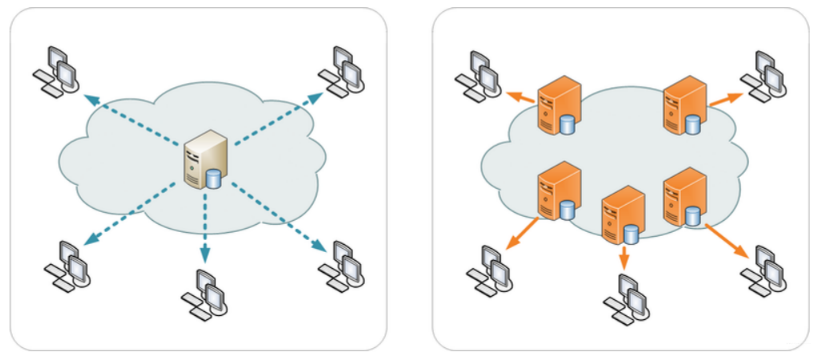
CDN 运营商在全国、乃至全球的各个大枢纽城市都建立了机房,部署了大量拥有高存储高带宽的节点,构建了一个跨运营商、跨地域的专用网络。
内容所有者向 CDN 运营商支付费用,CDN 将其内容交付给最终用户。
使用 CDN 前后对比:
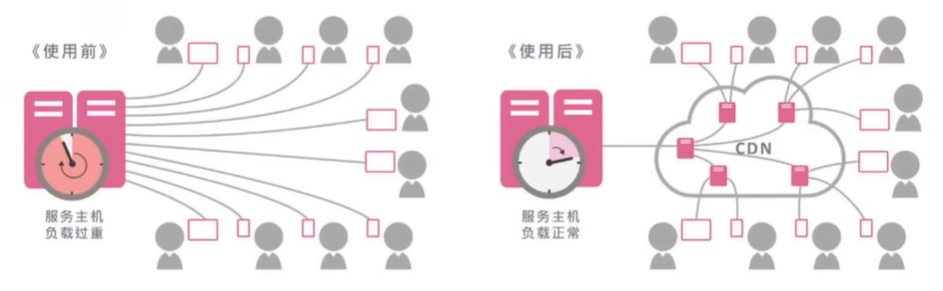
使用 CDN 前:
使用 CDN 后:
4:网络爬虫
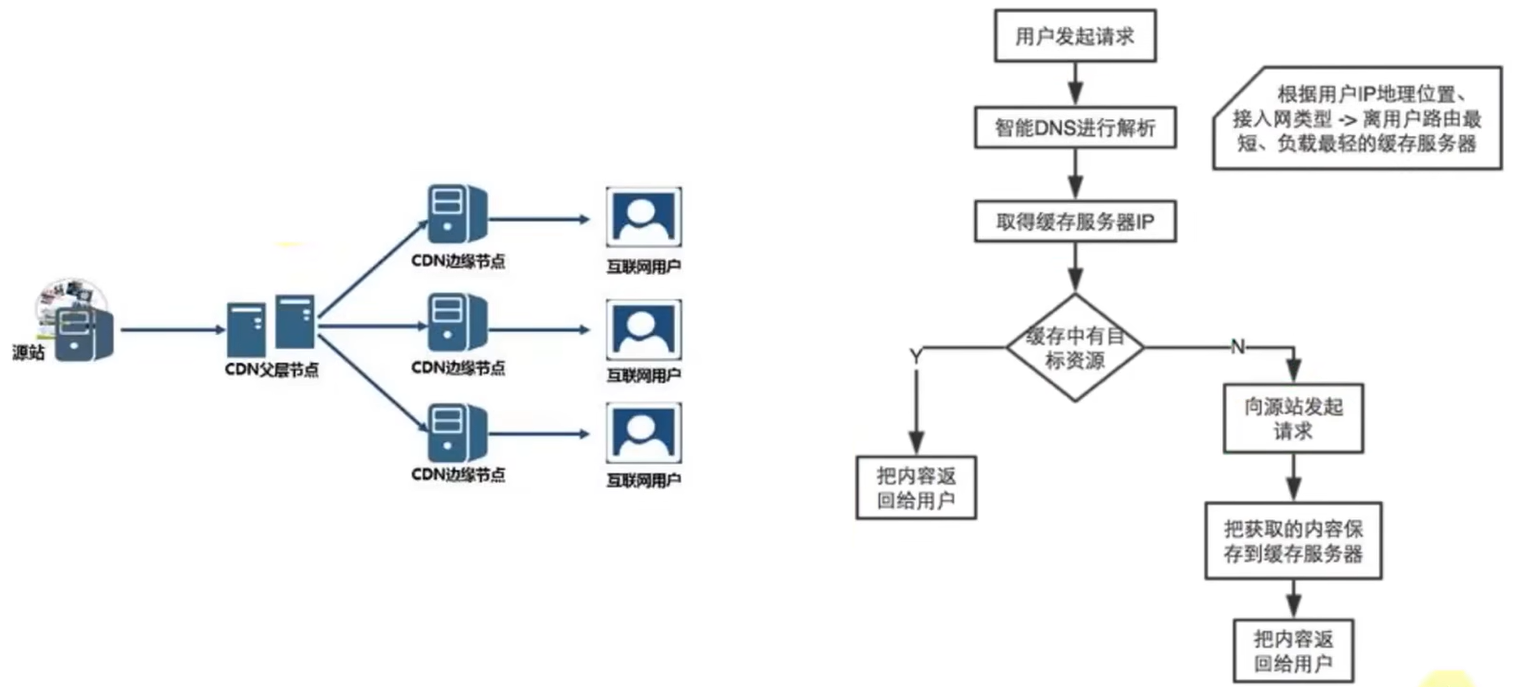
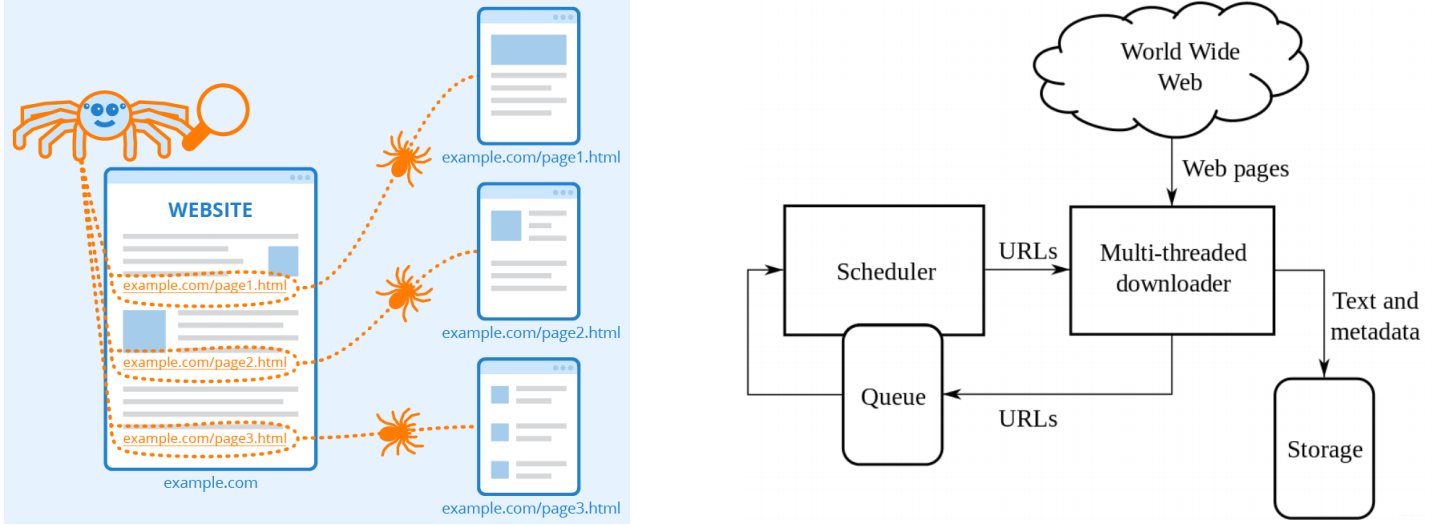
网络爬虫(Web Crawler),也叫做网络蜘蛛(Web Spider)。模拟人类使用浏览器操作页面的行为,对页面进行相关的操作。
常用爬虫工具:Python 的 Scrapy 框架。
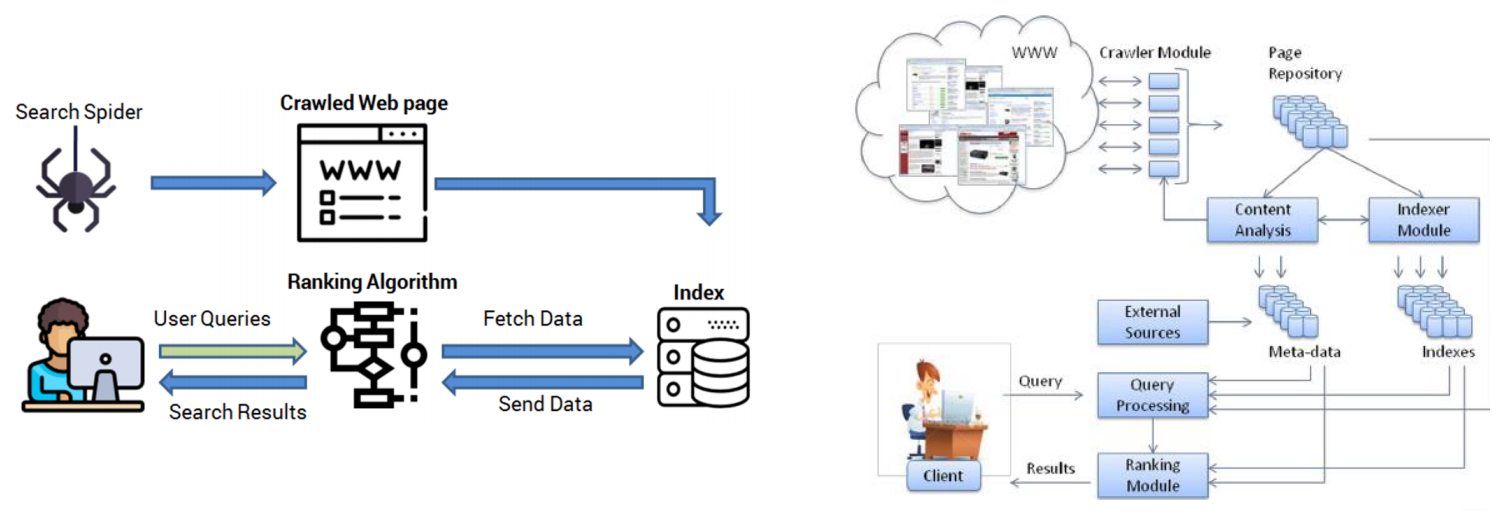
搜索引擎 :
4.1:简易实例
可以使用 Java 的一个小框架 Jsoup 爬一些简单的数据。
- jar 包(jsoup、commons-io):
https://jsoup.org/packages/jsoup-1.13.1.jar
https://mirror.bit.edu.cn/apache//commons/io/binaries/commons-io-2.8.0-bin.zip
爬取目标:https://ext.se.360.cn/webstore/categor
import org.apache.commons.io.FileUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.net.URL;
public class Main {
public static void main(String[] args) throws Exception {
// 请求网站:https://ext.se.360.cn/webstore/category
// Jsoup使用CSS选择器来查找元素
String dir = "F:/T/"; // 爬取后的存放路径
String url = "https://ext.se.360.cn/webstore/category";
Document doc = Jsoup.connect(url).get();
Elements eles = doc.select(".applist .appwrap");
for (Element ele : eles) {
String img = ele.selectFirst("img").attr("src");
String title = ele.selectFirst("h3").text();
String intro = ele.selectFirst(".intro").text();
// 下载图片
String filepath = dir + (title + ".png");
FileUtils.copyURLToFile(new URL(img), new File(filepath));
}
}
}
4.2:robots.txt
robots.txt 是存放于网站根目录下的文本文件,用来告诉爬虫,哪些内容是不应被爬取的,哪些是可以被爬取的。
比如:https://www.baidu.com/robots.txt
因为一些系统中的 URL 是大小写敏感的,所以 robots.txt 的文件名应统一为小写。
robots.txt 并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
只能防君子,不能防小人。
无法阻止 “不讲武德” 的爬虫爬取隐私信息。
一般格式:

5:无线网络
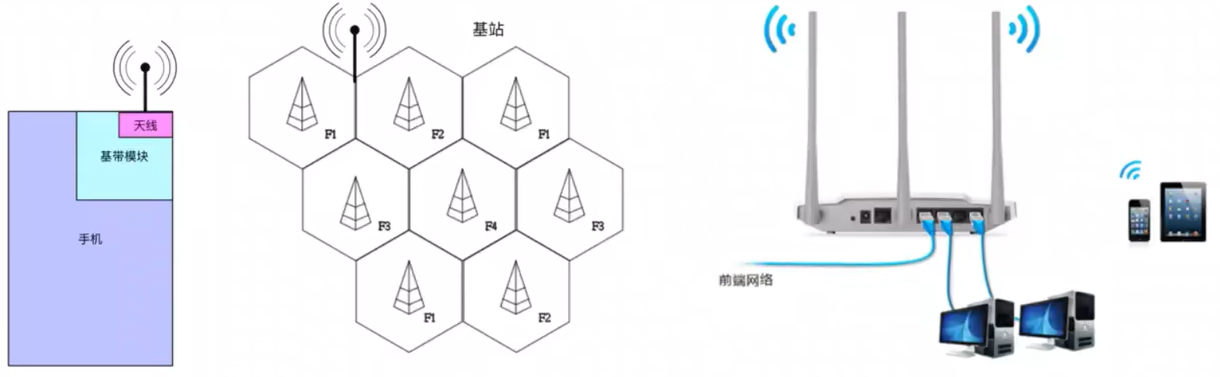
无线 AP(Access Point):无线接入点。
6:缓存
缓存(Cache)。
通常会缓存的情况是:GET 请求 + 静态资源(比如 HTML、CSS、JS、图片等)。
Ctrl + F5:强制刷新缓存。
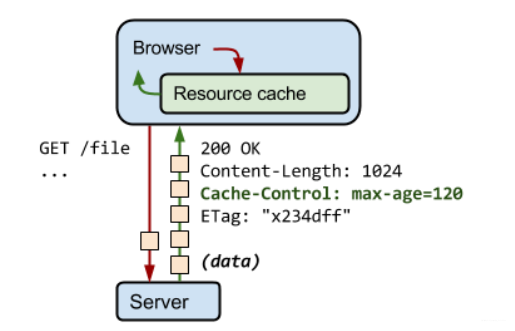
实际上,HTTP 的缓存机制远比上图的流程要复杂。
6.1:响应头
-
Pragma:作用类似于 Cache-Control,HTTP/1.0 的产物
-
Expires:缓存的过期时间(GMT 格式时间),HTTP/1.0 的产物
GMT 时间:例如
date: Sat, 19 May 2018 17:17:24 GMT
- Cache-Control:设置缓存策略
- no-storage:不缓存数据到本地
- public:允许用户、代理服务器缓存数据到本地
- private:只允许用户缓存数据到本地
- max-age:缓存的有效时间(多长时间不过期),单位秒
- no-cache:每次需要发请求给服务器询问缓存是否有变化,再来决定如何使用缓存
优先级:Pragma > Cache-Control > Expires。
-
Last-Modified:资源的最后一次修改时间
-
ETag:资源的唯一标识(根据文件内容计算出来的摘要值)
优先级:ETag > Last-Modifie
Last-Modified vs ETag
Last-Modified 的缺陷
- 只能精确到秒级别,如果资源在 1 秒内被修改了,客户端将无法获取最新的资源数据
- 如果某些资源被修改了(最后一次修改时间发生了变化),但是内容并没有任何变化,则会导致相同数据重复传输,没有使用到缓存
ETag
- 只要资源的内容没有变化,就不会重复传输资源数据
- 只要资源的内容发生了变化,就会返回最新的资源数据给客户端
6.2:请求头
- If-None-Match
- 如果上一次的响应头中有 ETag,就会将 ETag 的值作为请求头的值
- 服务器发现资源的最新摘要值跟 If-None-Match 不匹配,就会返回新的资源(200 OK)
- 否则,就不会返回资源的具体数据(304 Not Modified)
- If-Modified-Since
- 如果上一次的响应头中没有 ETag,有 Last-Modified,就会将 Last-Modified 的值作为请求头的值
- 如果服务器发现资源的最后一次修改时间晚于 If-Modified-Since,就会返回新的资源(200 OK)
- 否则,就不会返回资源的具体数据(304 Not Modified)
6.3:缓存的使用流程
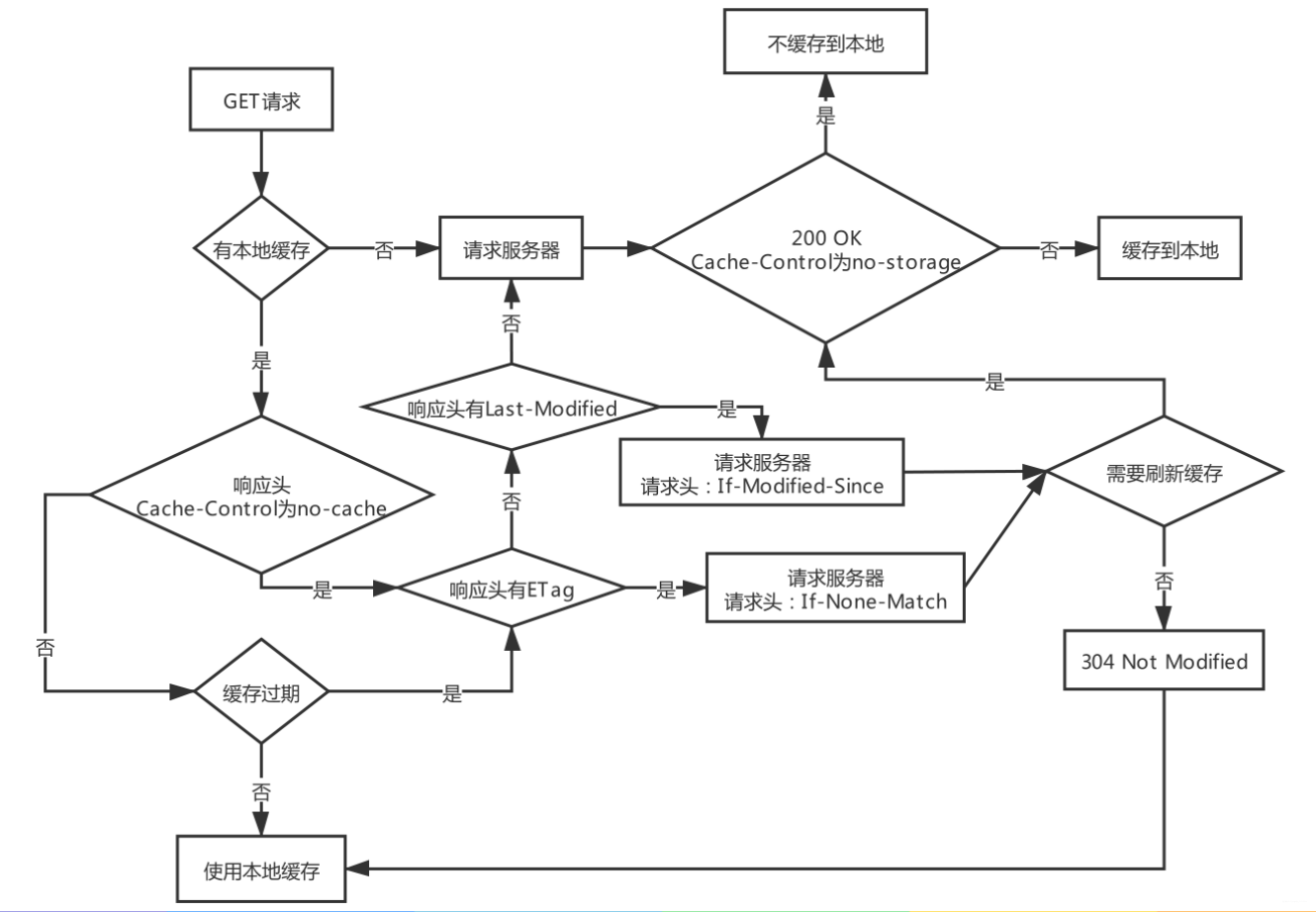
7:Cookie & Session
会话(Session)跟踪是 Web 程序中常用的技术,用来跟踪用户的整个会话。
常用的会话跟踪技术有 Cookie、Session。
- Cookie 通过在客户端记录信息确定用户身份
- Session 通过在服务器端记录信息确定用户身份
除此以外类似的概念还有 Token、JWT 等。
Cookie:
- 数据存储在浏览器客户端
- 数据有大小和数量的限制
- 适合存储一些小型、不敏感的数据
- 默认情况下,关闭浏览器后就会销毁
Session:
- 数据存储在服务器端
- 数据没有大小和数量的限制
- 可以存储大型、敏感的数据(比如用户信息)
- 默认情况下,未使用 30 分钟后就会销毁
8:RESTful
REST 的全称是:REpresentational State Transfer,表现层状态转移。
REST 是一种互联网软件架构的设计风格:
- 定义了一组用于创建 Web 服务的约束
- 符合 REST 架构的 Web 服务,称为 RESTful Web 服务
8.1:实践建议
-
URL 中使用名词(建议用复数形式),不使用动词。
推荐:/users、/users/6
不推荐:listsers,/getser?id=6,/uer/list,/user/get?id=6 -
使用 HTTP 的请求方法表达动作。

-
一个资源连接到其他资源,使用子资源的形式。
GET /users/6/cars/8
POST /users/8/cars -
API 版本化。
mj.com/v1/users
mj.com/v2/users/66 -
返回 JSON 格式的数据。
-
发生错误时,不要返回 200 状态码。
-
…
今人不见古时月,今月曾经照古人。
——《把酒问月 · 故人贾淳令予问之》(唐)李白