| 40.文献阅读笔记(m-RNN) | ||
| 简介 | 题目 | Explain Images with Multimodal Recurrent Neural Networks |
| 作者 | Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, Alan L. Yuille, arXiv:1410.1090 | |
| 原文链接 | http://arxiv.org/pdf/1410.1090.pdf | |
| 关键词 | m-RNN、multimodal | |
| 研究问题 | 研究问题:解释图像内容;图像和句子检索。 以前的方法思路:看做句子和图像之间的检索问题。给定句子(图像)查询相应的图像(句子)。 具体实施方法:对句子和图像都提取特征,并且将其映射到相同的语义 嵌入空间。 缺点:这样的方法对新图像的描述能力弱。(不在数据库中的句子、图像无法查询,或者查询结果不准确) 针对这一任务,通常有两类方法。第一类假定有特定的语言语法规则。它们解析句子并将其分为几个部分。然后将每个部分与图像中的对象或属性关联起来(例如,使用条件随机场模型,使用马尔可夫随机场模型)。这类方法生成的句子在语法上是正确的。另一类方法与我们的方法更为相关,它们利用深度玻尔兹曼机和主题模型等,学习多模态输入(即句子和图像)空间的概率密度。与第一种方法相比,它们能生成结构更丰富、更灵活的句子。给定相应图像生成句子的概率可作为检索的亲和度指标。 | |
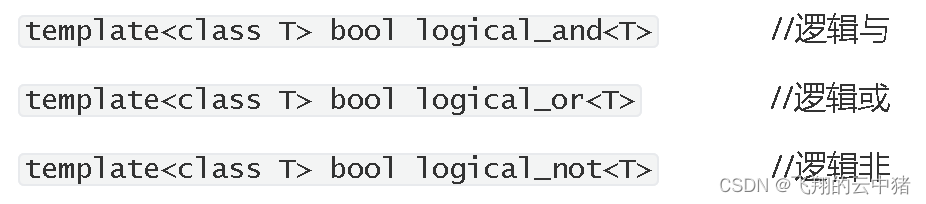
| 研究方法 | 多模态循环神经网络(m-RNN):该模型直接模拟了在给定先前单词和图像的情况下生成单词的概率分布。图像描述就是从这个分布中采样生成的。该模型由两个子网络组成:用于句子的深度递归神经网络和用于图像的深度卷积网络。这两个子网络在多模态层中相互作用,形成整个 m-RNN 模型。 The whole m-RNN architecture contains a language model part, an image part and a multimodal part. The language model part learns the dense feature embedding for each word in the dictionary and stores the semantic temporal context in recurrent layers. The image part contains a deep Convulutional Neural Network (CNN) [17] which extracts image features. The multimodal part connects the language model and the deep CNN together by a one-layer representation. 语言模型学习字典中每个词的稠密特征嵌入,并在recurrent layers中存储语义时间上下文(semantic temporal context)。 图像部分包含提取图像特征的深度卷积神经网络( CNN )。 多模态部分通过单层表示将语言模型和深度CNN连接在一起。 损失函数:using a perplexity based cost function
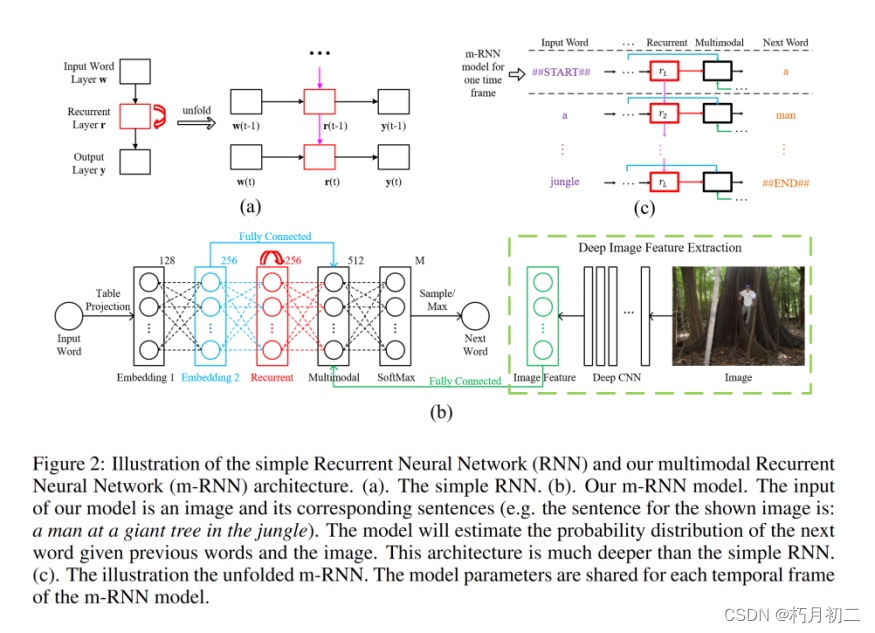 | |
| 研究结论 | 模型优于最先进的生成方法。此外,m-RNN 模型还可应用于检索图像或句子的任务,与直接优化检索排序目标函数的先进方法相比,其性能有了显著提高。模型是可扩展的,并且有潜力通过为图像和句子整合更强大的深度网络来进一步改进。 | |
| 创新不足 | ||
| 额外知识 | 递归神经网络:【神经网络】递归神经网络 - 知乎 (zhihu.com) 模型必须能够按照树结构去处理信息,而不是序列(循环神经网络),这就是递归神经网络的作用。 | |
| 41.文献阅读笔记 | ||
| 简介 | 题目 | Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models |
| 作者 | Ryan Kiros, Ruslan Salakhutdinov, Richard S. Zemel, arXiv:1411.2539. | |
| 原文链接 | http://arxiv.org/pdf/1411.2539.pdf | |
| 关键词 | Visual-Semantic | |
| 研究问题 | 图像描述 | |
| 研究方法 |  编码器:深度卷积网络( CNN )和长短期记忆循环网络( LSTM ),用于学习图像-句子的联合嵌入。解码器:一种新的神经语言模型,它将结构向量和内容向量结合起来,用于每次依次生成单词。 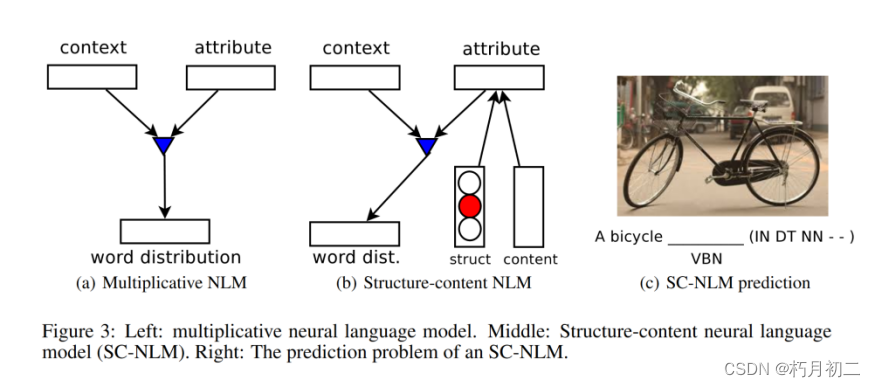 解码器补充:引入了一种新的神经语言模型,称为结构-内容神经语言模型(SC-NLM)。SC-NLM 与现有模型的不同之处在于,它以编码器产生的分布式表征为条件,将句子的结构与内容割裂开来。 结构变量有助于引导模型生成短语,可以看作是一个软模板,有助于避免模型生成语法废话。 SC-NLM 可以仅根据文本进行训练。这样,我们就可以利用大量的单语文本(如非图像标题)来提高语言模型的质量。 编码器为我们提供了一种对图像和标题进行排序并开发良好评分函数的方法,而解码器则可以使用所学到的表征来优化评分函数,从而生成新的描述并对其进行评分。 | |
| 研究结论 | 最先进的性能 | |
| 创新不足 | ||
| 额外知识 | Lstm:包含一个内置的记忆单元,用于存储信息和利用远距离上下文。LSTM 存储单元周围有门控单元,用于读写和重置信息。 | |
| 42.文献阅读笔记(LRCN) | ||
| 简介 | 题目 | Long-term Recurrent Convolutional Networks for Visual Recognition and Description |
| 作者 | Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, Trevor Darrel l, arXiv:1411.4389. | |
| 原文链接 | http://arxiv.org/pdf/1411.4389.pdf | |
| 关键词 | recurrent convolutional | |
| 研究问题 | 描述了一类可端到端训练且适用于大规模视觉理解任务的递归卷积架构,并展示了这些模型在活动识别、图像标题和视频描述方面的价值。 递归卷积模型则是 "双重深度 "的,因为它们学习空间和时间的组合表征。当非线性因素被纳入网络状态更新时,学习长期依赖关系就成为可能。可微分递归模型的吸引力在于,它们可以将可变长度的输入(如视频)直接映射到可变长度的输出(如自然语言文本),并能模拟复杂的时间动态;同时,它们还能通过反向传播进行优化。 有关用于视频处理的 CNN 模型的研究已经考虑了在原始序列数据上学习三维时空滤波器,以及在固定窗口或视频镜头片段上学习帧到帧表示,其中包含了瞬时光流或基于轨迹的聚合模型 。这些模型探索了感知时间序列表征学习的两个极端:要么学习完全通用的时变加权,要么应用简单的时间池。 | |
| 研究方法 | 主张视频识别和描述模型也应在时间维度上进行深度学习,即潜在变量具有时间递归性。

LSTM 单元的隐藏状态使用非线性机制进行增强,允许状态在不修改的情况下传播、更新或重置,使用的是简单的学习门控函数。 应用于时变输入和输出的愿望不断增长的架构 | |
| 研究结论 | 证明 LSTM 类型的模型可以提高传统视频活动挑战的识别率,并实现从图像像素到句子级自然语言描述的新颖端到端优化映射。我们还表明,这些模型改进了从传统视觉模型衍生的中间视觉表征中生成描述的能力。 | |
| 创新不足 | ||
| 额外知识 | CRF:条件随机场 | |


| 43.文献阅读笔记 | ||
| 简介 | 题目 | Show and Tell: A Neural Image Caption Generator |
| 作者 | Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan | |
| 原文链接 | http://arxiv.org/pdf/1411.4555.pdf | |
| 关键词 | ||
| 研究问题 | 图像描述 想回答诸如"数据集大小如何影响泛化"、"它将能够实现什么样的迁移学习"、"它将如何处理弱标记样本"等问题。 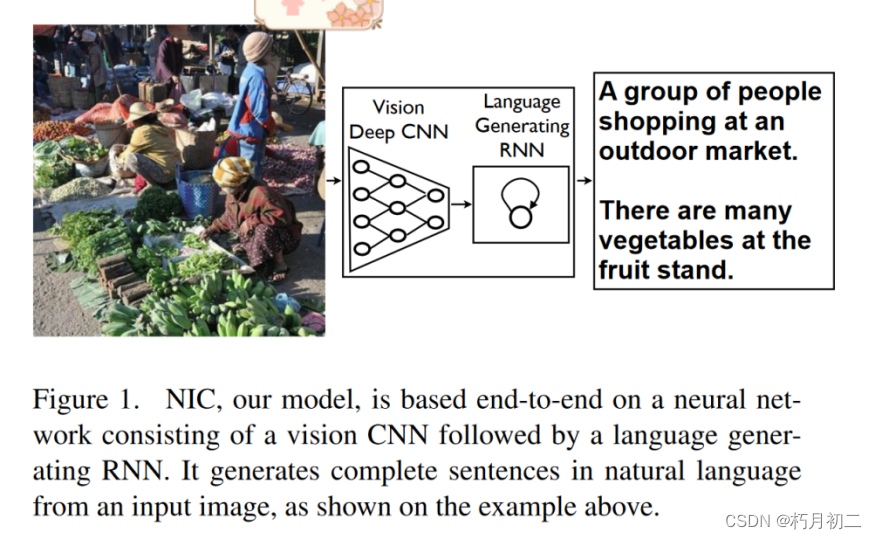 | |
| 研究方法 | CNN(图像的表示)+LSTM(联系前后输入) 介绍了 NIC,这是一个端到端神经网络系统,可以自动查看图像并生成通俗易懂的合理描述。NIC 以卷积神经网络为基础,将图像编码为紧凑的表示形式,然后由递归神经网络生成相应的句子。对模型的训练是为了最大限度地提高给定图像的句子的可能性。 利用一个循环神经网络将可变长度的输入编码为固定维度的向量,并使用这种表示将其"解码"到期望的输出句子。 | |
| 研究结论 | 随着图像描述可用数据集规模的扩大,NIC 等方法的性能也将随之提高。此外,如何利用来自图像和文本的无监督数据来改进图像描述方法也将是一个有趣的课题。 | |
| 创新不足 | ||
| 额外知识 | None | |
| 44.文献阅读笔记 | ||
| 简介 | 题目 | Deep Visual-Semantic Alignments for Generating Image Description |
| 作者 | Andrej Karpathy, Li Fei-Fei, CVPR, 2015. | |
| 原文链接 | http://cs.stanford.edu/people/karpathy/cvpr2015.pdf | |
| 关键词 | 对图像内容进行密集注释。 | |
| 研究问题 | 提出了一种生成图像及其区域的自然语言描述的模型。以往视觉识别领域的大部分工作都集中在用一组固定的视觉类别标记图像上,这些工作已经取得了很大的进展。然而,尽管封闭的视觉概念词汇表构成了一种方便的建模假设,但与人类所能编写的大量丰富描述相比,它们具有极大的局限性。针对生成图像描述的挑战,已经开发出了一些开创性的方法。然而,这些模型通常依赖于硬编码的视觉概念和句子模板,这就限制了它们的多样性。此外,这些工作的重点是将复杂的视觉场景还原成一个句子,而我们认为这是不必要的限制。 | |
| 研究方法 | 利用图像及其句子描述的数据集来学习语言和视觉数据之间的模态间对应关系。基于图像区域上的卷积神经网络,句子上的双向循环神经网络和通过多模态嵌入对齐两个模态的结构化目标的新颖组合。  描述了一种多模态循环神经网络架构,该架构使用推断的对齐来学习生成新的图像区域描述。 输入->推断->输出 | |
| 研究结论 |  | |
| 创新不足 | ||
| 额外知识 | 双向递归神经网络(Bidirectional Recurrent Neural Network,BRNN):来计算单词表示。双向递归神经网络采用 N 个单词序列(以 1-k 表示法编码),并将每个单词转换为 h 维向量。不过,每个单词的表征都会被该单词周围大小不一的上下文所丰富。 | |
| 45.文献阅读笔记 | ||
| 简介 | 题目 | Translating Videos to Natural Language Using Deep Recurrent Neural Networks |
| 作者 | Subhashini Venugopalan, Huijuan Xu, Jeff Donahue, Marcus Rohrbach, Raymond Mooney, Kate Saenko, NAACL-HLT, 2015. | |
| 原文链接 | http://arxiv.org/pdf/1412.4729.pdf | |
| 关键词 | 视频翻译 | |
| 研究问题 | 将视频直接翻译成句子.描述的视频数据集稀缺,现有的大多数方法已被应用于可能词汇量较小的玩具领域。人们已经提出了针对具有一小部分已知动作和对象的狭窄领域的解决方案. | |
| 研究方法 | 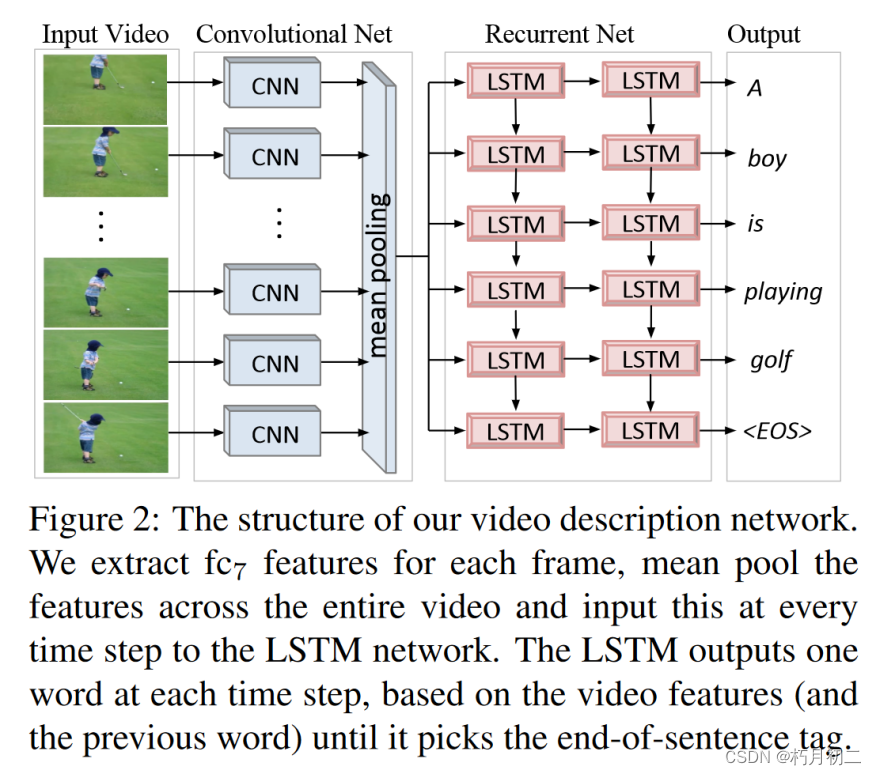 同时具有卷积和循环结构的统一深度神经网络将视频直接翻译成句子。 该网络在 120 多万张带有类别标签的图像上进行了预先训练. 他们将其模型的一个版本应用于视频到文本的生成,但没有提出端到端的单一网络,而是使用了中间角色表示。 利用长短期记忆(LSTM)递归神经网络来建立序列动态模型,但将其直接连接到深度卷积神经网络来处理传入的视频帧,从而完全避免了监督中间表征。 | |
| 研究结论 | 提出了一种用于视频描述的模型,该模型使用神经网络从像素到句子的整个流水线,并且可以潜在地允许整个网络的训练和调整。在一个广泛的实验评估中,我们表明我们的方法比相关的方法生成更好的句子。我们还表明,与仅依赖视频描述数据相比,利用图像描述数据可以提高性能。然而,我们的方法在更好地利用视频中的时间信息方面存在不足 | |
| 创新不足 | 每帧都进行卷积处理,运算量太大. | |
| 额外知识 | ||