1.副本
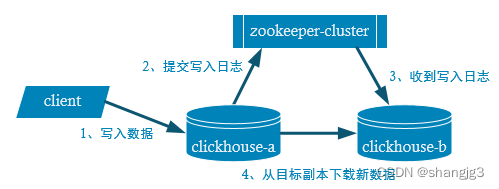
副本的目的主要是保障数据的高可用性,即使一台ClickHouse节点宕机,那么也可以从其他服务器获得相同的数据。
Data Replication | ClickHouse Docs
1.1 副本写入流程
1.2 配置步骤
(1)启动zookeeper集群
(2)在hadoop102的/etc/clickhouse-server/config.d目录下创建一个名为metrika.xml的配置文件,内容如下:
注:也可以不创建外部文件,直接在config.xml中指定<zookeeper>
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
(3)同步到hadoop103和hadoop104上
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.d/metrika.xml
(4)在 hadoop102的/etc/clickhouse-server/config.xml中增加
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>

(5)同步到hadoop103和hadoop104上
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.xml
分别在hadoop102和hadoop103上启动ClickHouse服务
注意:因为修改了配置文件,如果以前启动了服务需要重启
[atguigu@hadoop102|3 ~]$ sudo clickhouse restart
注意:我们演示副本操作只需要在hadoop102和hadoop103两台服务器即可,上面的操作,我们hadoop104可以你不用同步,我们这里为了保证集群中资源的一致性,做了同步。
(6)在hadoop102和hadoop103上分别建表
副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表
①hadoop102
create table t_order_rep2 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_102')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
②hadoop103
create table t_order_rep2 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_103')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
③参数解释
ReplicatedMergeTree 中,
第一个参数是分片的zk_path一般按照: /clickhouse/table/{shard}/{table_name} 的格式写,如果只有一个分片就写01即可。
第二个参数是副本名称,相同的分片副本名称不能相同。
(7)在hadoop102上执行insert语句
insert into t_order_rep2 values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00');

(8)在hadoop103上执行select,可以查询出结果,说明副本配置正确

2.分片集群
副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。
要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过Distributed表引擎把数据拼接起来一同使用。
Distributed表引擎本身不存储数据,有点类似于MyCat之于MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
注意:ClickHouse的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
2.1 集群写入流程(3分片2副本共6个节点)

2.2 集群读取流程(3分片2副本共6个节点)

2.3 3分片2副本共6个节点集群配置(供参考)
配置的位置还是在之前的/etc/clickhouse-server/config.d/metrika.xml,内容如下
注:也可以不创建外部文件,直接在config.xml的<remote_servers>中指定
<yandex>
<remote_servers>
<gmall_cluster> <!-- 集群名称-->
<shard> <!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<!--该分片的第一个副本-->
<replica>
<host>hadoop101</host>
<port>9000</port>
</replica>
<!--该分片的第二个副本-->
<replica>
<host>hadoop102</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop103</host>
<port>9000</port>
</replica>
<replica> <!--该分片的第二个副本-->
<host>hadoop104</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--集群的第三个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop105</host>
<port>9000</port>
</replica>
<replica> <!--该分片的第二个副本-->
<host>hadoop106</host>
<port>9000</port>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
</yandex>
2.4 配置三节点版本集群及副本
2.4.1 集群及副本规划(2个分片,只有第一个分片有副本)

| hadoop102 | hadoop103 | hadoop104 |
| <macros> <shard>01</shard> <replica>rep_1_1</replica> </macros> | <macros> <shard>01</shard> <replica>rep_1_2</replica> </macros> | <macros> <shard>02</shard> <replica>rep_2_1</replica> </macros> |
2.4.2 配置步骤
1)在hadoop102的/etc/clickhouse-server/config.d目录下创建metrika-shard.xml文件
注:也可以不创建外部文件,直接在config.xml的<remote_servers>中指定
<?xml version="1.0"?>
<yandex>
<remote_servers>
<gmall_cluster> <!-- 集群名称-->
<shard> <!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop102</host>
<port>9000</port>
</replica>
<replica> <!--该分片的第二个副本-->
<host>hadoop103</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop104</host>
<port>9000</port>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>01</shard> <!--不同机器放的分片数不一样-->
<replica>rep_1_1</replica> <!--不同机器放的副本数不一样-->
</macros>
</yandex>
2)将hadoop102的metrika-shard.xml同步到103和104
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.d/metrika-shard.xml

3)修改103和104中metrika-shard.xml宏的配置
(1)103
[atguigu@hadoop103 ~]$ sudo vim /etc/clickhouse-server/config.d/metrika-shard.xml

(2)104
[atguigu@hadoop104 ~]$ sudo vim /etc/clickhouse-server/config.d/metrika-shard.xml

4)在hadoop102上修改/etc/clickhouse-server/config.xml

5)同步/etc/clickhouse-server/config.xml到103和104
[atguigu@hadoop102 ~]$ sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.xml
6)重启三台服务器上的ClickHouse服务
[atguigu@hadoop102 clickhouse-server]$ sudo clickhouse restart
[atguigu@hadoop102 clickhouse-server]$ ps -ef |grep click

7)在hadoop102上执行建表语句
- 会自动同步到hadoop103和hadoop104上
- 集群名字要和配置文件中的一致
- 分片和副本名称从配置文件的宏定义中获取
create table st_order_mt on cluster gmall_cluster (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);

可以到hadoop103和hadoop104上查看表是否创建成功


8)在hadoop102上创建Distribute 分布式表
create table st_order_mt_all2 on cluster gmall_cluster
(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(gmall_cluster,default, st_order_mt,hiveHash(sku_id));
参数含义:
Distributed(集群名称,库名,本地表名,分片键)
分片键必须是整型数字,所以用hiveHash函数转换,也可以rand()

9)在hadoop102上插入测试数据
insert into st_order_mt_all2 values
(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00'),
(205,'sku_003',600.00,'2020-06-02 12:00:00');
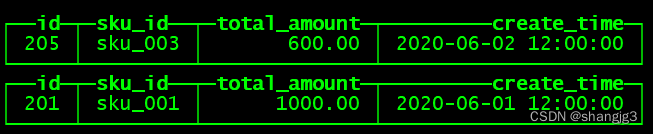
10)通过查询分布式表和本地表观察输出结果
(1)分布式表
SELECT * FROM st_order_mt_all;
(2)本地表
select * from st_order_mt;
(3)观察数据的分布
| st_order_mt_all |
|
| hadoop102: st_order_mt |
|
| hadoop103: st_order_mt |
|
| hadoop104: st_order_mt |
|



2.5 项目为了节省资源,就使用单节点,不用集群
不需要求改文件引用,因为已经使用集群建表了,如果改为引用metrika-shard.xml的话,启动会报错。我们以后用的时候只启动102即可。