爬取全国高校数据
网站:
运行下面代码得到网站.
import base64
# 解码
website = base64.b64decode('IGh0dHA6Ly9jb2xsZWdlLmdhb2thby5jb20vc2NobGlzdC8='.encode('utf-8'))
print(website)
分析:
我们需要爬取的字段,高校名称,高校所在地,高校类型,高校性质,高校特色,高校隶属,学校网站。

该网页静态网页,内容就在网页里面,一共107页数据,向每一页发送请求,直接使用Xpath解析的页面数据即可拿到我们想要的数据。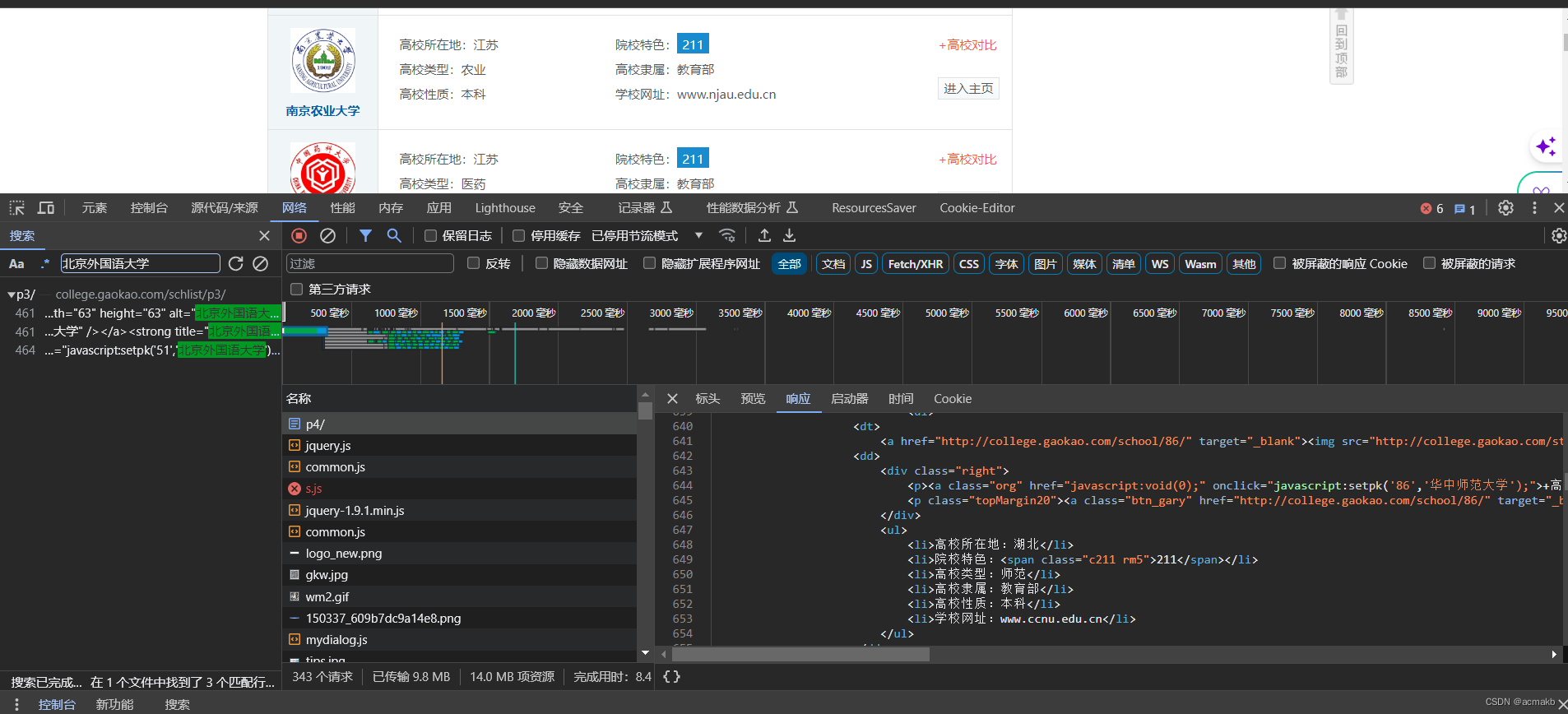
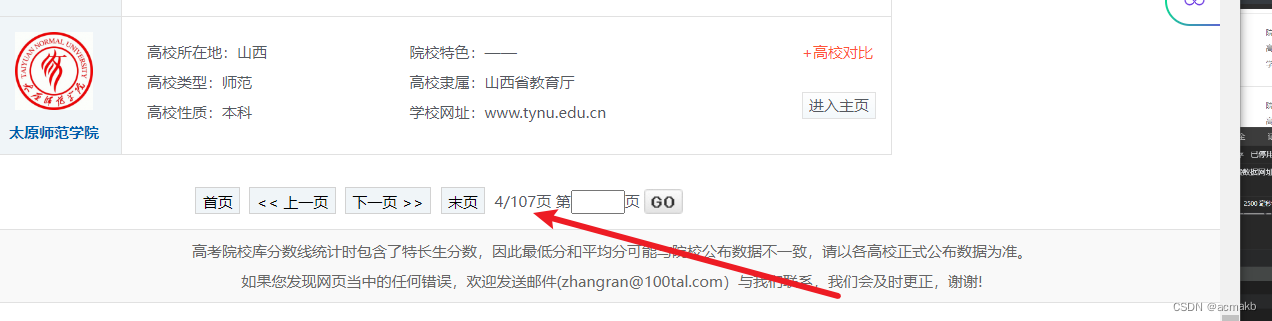
Xpath提取字段:
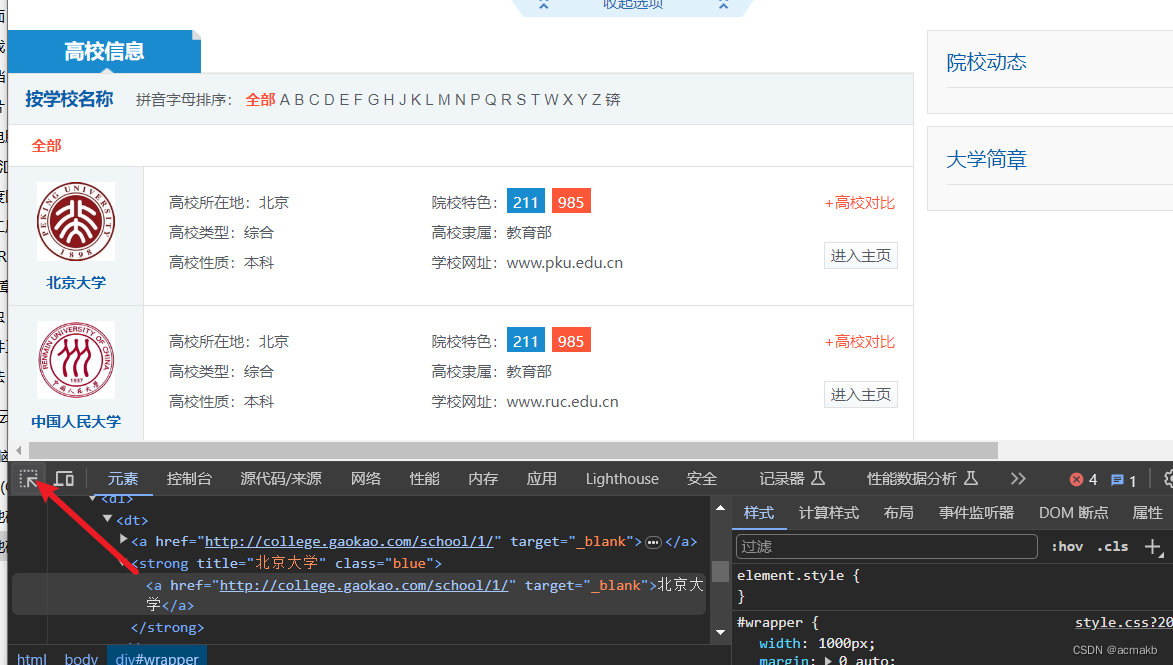
然后点击我们需要提取的字段。
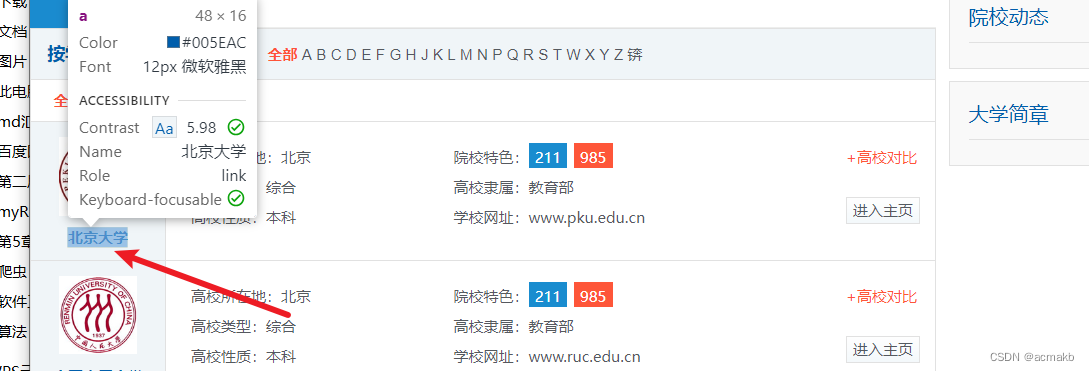
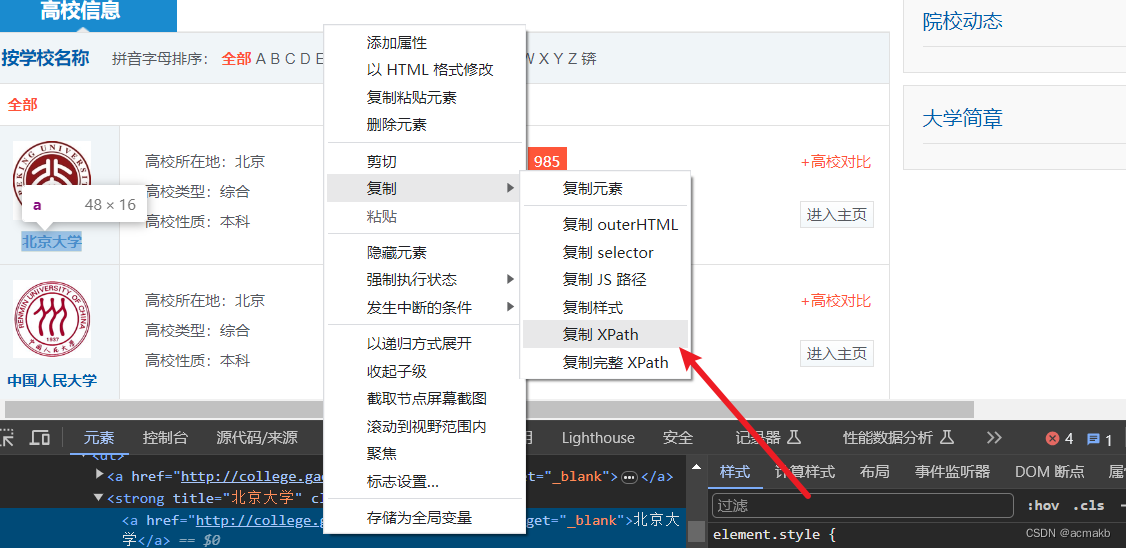
//*[@id=“wrapper”]/div[4]/div[1]/dl[1]/dt/strong/a , 然后我们看一下页面结构 ,对Xpath进行修改即可。
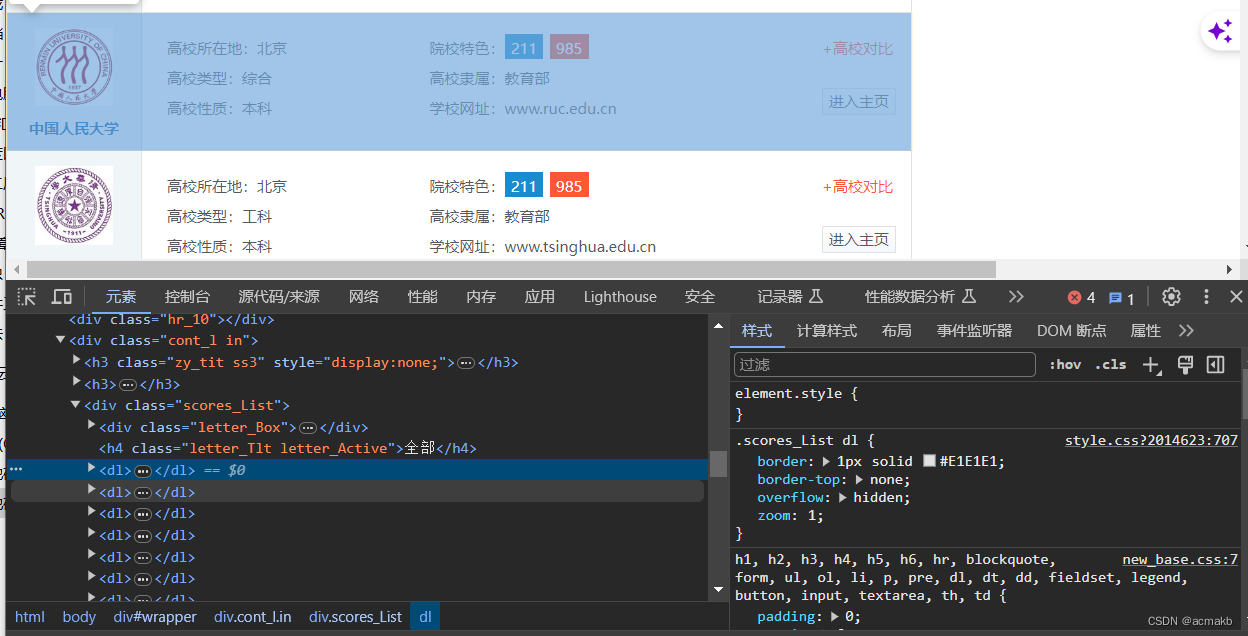
我们不难发现每一个dl标签就是一个学校的所有信息,这个学校的信息的Xpath:
//div[@class="cont_l in"]//div[@class="scores_List"]/dl
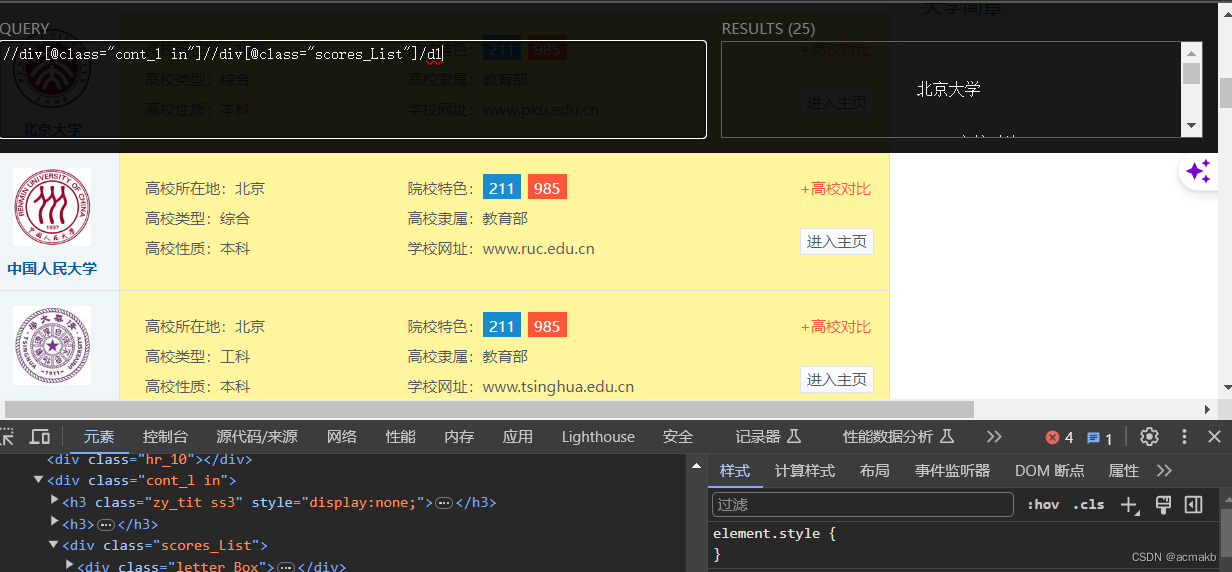
学校名称:
//div[@class="cont_l in"]//div[@class="scores_List"]/dl//strong/@title
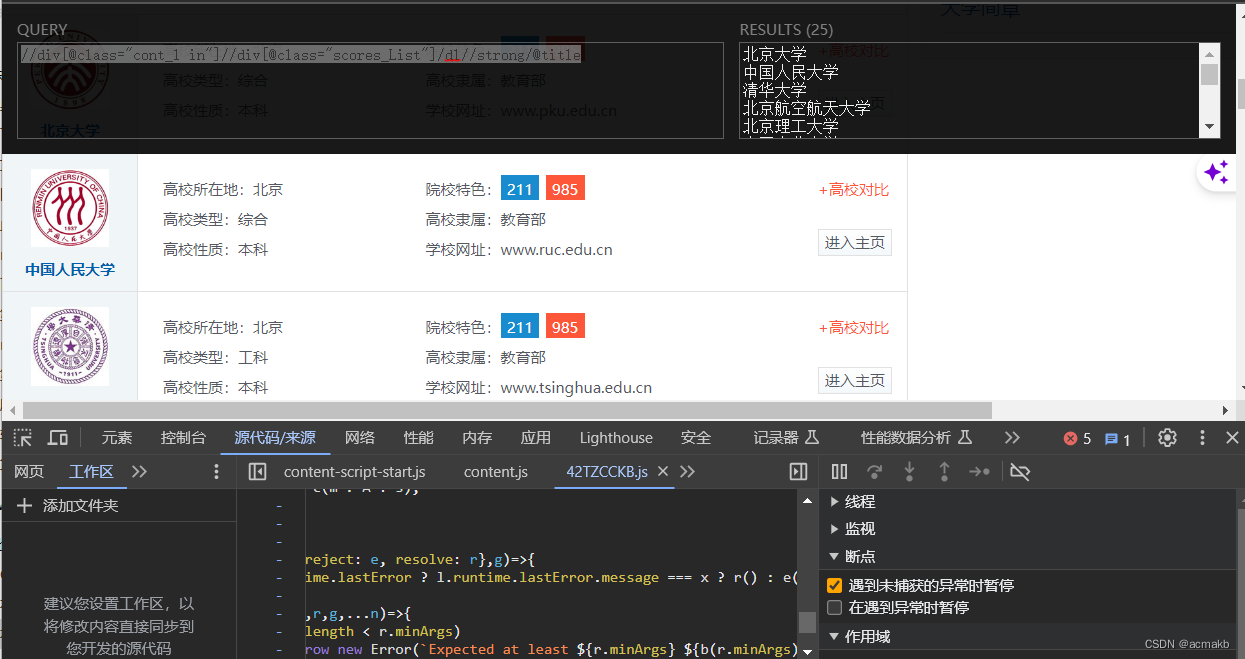
然后我们就可以得到所有的信息,xpath如下:
高校所在地:
//div[@class="cont_l in"]//div[@class="scores_List"]/dl//ul/li[1]/text()
高校类型:
//div[@class="cont_l in"]//div[@class="scores_List"]/dl//ul/li[3]/text()
高校性质:
//div[@class="cont_l in"]//div[@class="scores_List"]/dl//ul/li[5]/text()
高校隶属:
//div[@class="cont_l in"]//div[@class="scores_List"]/dl//ul/li[4]/text()
高校网站:
//div[@class="cont_l in"]//div[@class="scores_List"]/dl//ul/li[6]/text()
是否211:
//div[@class="cont_l in"]//div[@class="scores_List"]/dl//ul/li[2]/span[1]/text()
是否985:
//div[@class="cont_l in"]//div[@class="scores_List"]/dl//ul/li[2]/span[2]/text()
但是有一个问题:如果某个学校是985不是211,则对应的211标签提取就会报错,我们需要异常处理,如果有这个标签怎么样,没有怎么样。
爬虫代码:
import requests
from lxml import etree
import time
import random
import pandas as pd
from fake_useragent import UserAgent
import os
def crawl(pages, filename, start_page=1, end_page=None):
# 设置请求头信息
ua = UserAgent()
headers = {'User-Agent': ua.random}
# 获取网页内容
url_template = 'http://college.gaokao.com/schlist/p{}/'
data = []
for page in range(start_page, min(end_page or pages, pages) + 1):
url_page = url_template.format(page)
response = requests.get(url_page, headers=headers).text
# 设置请求时间间隔,防止被反爬虫
time.sleep(random.uniform(1, 3))
# 解析网页内容,提取需要的信息
html = etree.HTML(response)
rows = html.xpath('//div[@class="cont_l in"]//div[@class="scores_List"]/dl')
for row in rows:
name = row.xpath('.//strong/@title')[0] # 获取的每一个都是列表 只有一个元素
location = row.xpath('.//ul/li[1]/text()')[0]
location = location.split(':')[1] # 将字符串按照冒号分割成两部分,获取第二部分
school_type = row.xpath('.//ul/li[3]/text()')[0]
school_type = school_type.split(':')[1]
school_property = row.xpath('.//ul/li[5]/text()')[0]
school_property = school_property.split(':')[1]
school_affiliation = row.xpath('.//ul/li[4]/text()')[0]
school_affiliation = school_affiliation.split(':')[1]
website = row.xpath('.//ul/li[6]/text()')[0]
website = website.split(':')[1]
# feature_211= row.xpath('.//ul/li[2]/span[1]/text()')[0]
try:
feature_211 = row.xpath('.//ul/li[2]/span[1]/text()')[0]
except IndexError:
feature_211 = "0"
try:
feature_985 = row.xpath('.//ul/li[2]/span[2]/text()')[0]
except IndexError:
feature_985 = "0"
data.append(
[name, location, school_type, school_property, school_affiliation, website, feature_211, feature_985])
# ['北京大学', '北京', '综合', '本科', '教育部', 'www.pku.edu.cn', '211', '985']
# ['中国矿业大学(徐州)', '江苏', '工科', '本科', '教育部', 'http://www.cumt.edu.cn/', '211', '0']
# 将提取的数据存储到pandas的DataFrame中
df = pd.DataFrame(data,
columns=['学校名称', '高校所在地', '高校类型', '高校性质', '高校隶属', '学校网站', '是否211',
'是否985'])
# 将DataFrame中的数据保存到CSV文件中
df.to_csv(filename, mode='a', index=False, header=not os.path.exists(filename))
# 追加写入数据,如果文件不存在则写入表头
if __name__ == '__main__':
# 第一次爬取前20页,保存到university.csv文件中
crawl(pages=20, filename='demo.csv')
# 第二次爬取21到40页,追加到university.csv文件中
crawl(pages=40, filename='demo.csv', start_page=21, end_page=40)
# 第三次爬取41到60页,追加到demo.csv文件中
crawl(pages=60, filename='demo.csv', start_page=41, end_page=60)
# # 第四次爬取61到80页,追加到university.csv文件中
crawl(pages=80, filename='demo.csv', start_page=61, end_page=80)
# # 第五次爬取81到100页,追加到university.csv文件中
crawl(pages=100, filename='demo.csv', start_page=81, end_page=100)
# # 第六次爬取101到107页,追加到university.csv文件中
crawl(pages=107, filename='demo.csv', start_page=101, end_page=107)
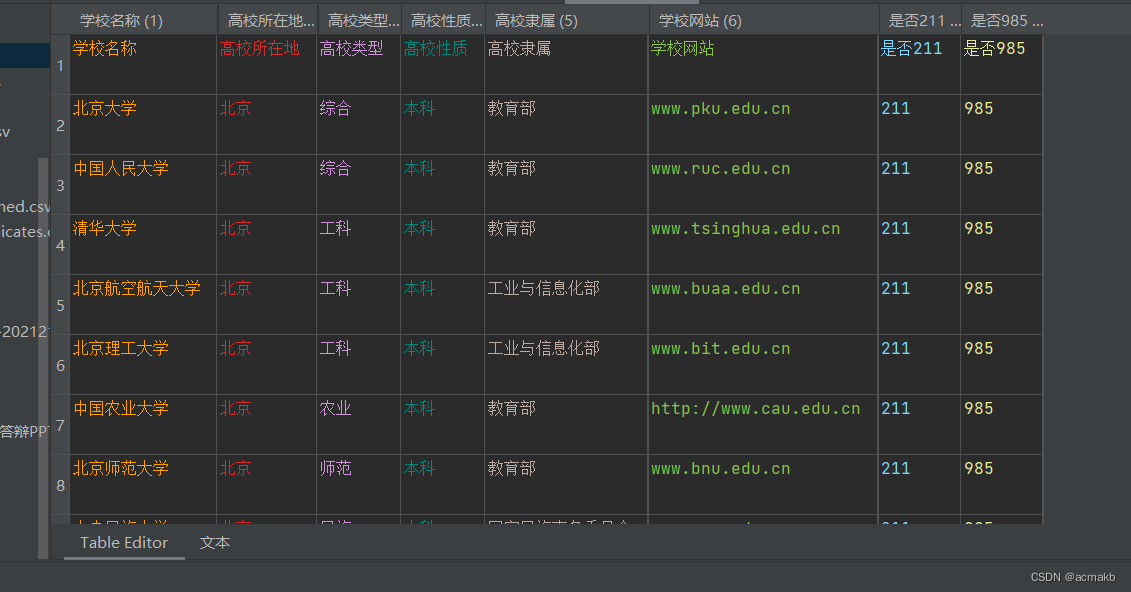
ok!结束!