2.1 数据清洗
以titanic数据为例。
df = pd.read_csv('titanic.csv')
2.1.1 缺失值
(1)缺失判断
df.isnull()
(2)缺失统计
# 列缺失统计
df.isnull().sum(axis=0)
# 行缺失统计
df.isnull().sum(axis=1)
# 统计缺失率
df.isnull().mean(axis=0)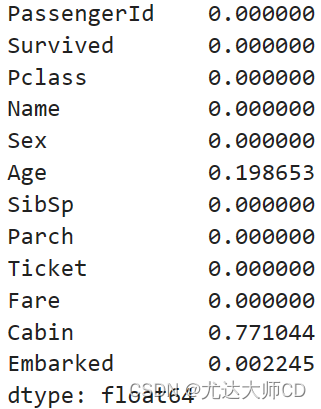
(3)缺失删除
# 删除有缺失值的行
df.dropna(axis=0)
# 删除有缺失值的列
df.dropna(axis=1)
# 删除至少有两个缺失值的行
df.dropna(thresh=2)
# 指定判断缺失值的列范围
df.dropna(subset=['Survived','Pclass'])
# 指定某列的缺失值删除
df['Sex'].dropna()(4)缺失筛选
# 筛选有缺失值的行
df.loc[df.isna().any(1)]
# 筛选有缺失值的列
df.loc[:,df.isna().any()]
# 查询没有缺失值的行
df.loc[~(df.isna().any(1))]
# 查询没有缺失值的列
df.loc[:,~(df.isna().any())]
### 筛选缺失率大于0.7的列
# 设置缺失率阈值
cutoff = 0.7
cond = df.isnull().mean(axis=0) > 0.7
# 缺失率>0.7的变量
drop_list = [k for k,v in cond.to_dict().items() if v==True]
# 缺失率<=0.7的变量
keep_list = [k for k,v in cond.to_dict().items() if v==False]
# 缺失率大于0.7的列
df[drop_list]
# 缺失率小于0.7的列
df[keep_list](5)缺失填充
### fillna()函数填充
# 将所有缺失值填充为0
df.fillna(0)
# 将缺失值填充为指定字符
df.fillna('x')
# 指定字段填充,此处用均值
df.Age.fillna(df['Age'].mean())
# 只替换一个 df.fillna(0, limit=1)
### replace()函数填充
# 将指定列的空值替换成指定值
df.replace({'Age':{np.nan:df['Age'].mean()}})
### mask()函数替换
tc = df['Age'].mean()
cond = df['Age'].isnull()==True
df['Age'] = df['Age'].mask(cond, tc)
### interpolate()插值填充
df.Age.interpolate() #默认线性插值2.1.2 重复值
(1)重复查询
df.duplicated(subset=['name', 'birthday'], keep='first') # 按姓名和生日查询,除第一个重复值以外的其余重复值都被筛选出来(2)重复统计
# 对user列查重并统计重复数量
df.duplicated(subset=['user'], keep=False).sum(axis=0) # keep=False所有重复值都被筛选出来
# 对user列查重并统计重复率
df.duplicated(subset=['user'], keep=False).mean(axis=0)(3)重复删除
# 对全部列去重,在原数据frame上生效
df.drop_duplicates(inplace=True)
# 对user列去重,在原数据frame上生效
df.drop_duplicated(subset=['user'], inplace=True)
# 对user、hobby列去重,保留最后一个重复行
df.drop_duplicated(subset=['user','hobby'],keep='last',inplace=True)(4)索引重置
# 索引重置
df.drop_duplicates(subset=['user'],keep='first').reset_index(drop=True)(5)先排序再去重
当重复数据有排序行时,一定要对数据排序后在进行去重处理。
# 排序
df = df.sort_values(by=['user','price'],ascending=True).reset_index(drop=True)
# 去重
df = df.drop_duplicated(subset=['user'],keep='first').reset_index(drop=True)2.1.3 数据替换
(1)loc/iloc赋值
# 第1行第3列的数据替换为4
df.iloc[0:1,2:3] = 4
# 将Age均值替换空值
df.loc[(df['Age'].isnull()==True), 'Age'] = df['Age'].mean()
# 将Pclass3以上替换为'3+'
df['Pclass'] = df['Pclass'].astype(str) df.loc[(df['Pclass']>=3), 'Pclass'] = '3+'(2)replace替换
### 指定值替换
# 数值替换
s.replace(to_replace=0, value=5)
# 字符替换
df.replace(to_replace='S', value='C')
# 空值替换
df.replace(to_replace='.', value=np.nan)
# 列表一一替换
df.replace(to_replace=[0,1,2,3,4], value=[4,3,2,1,0])
# to_replace为字典时
s.replace(to_replace={0:10, 1:100}) # 此时按字典映射进行替换,value不再指定替换值 df.replace(to_replace={'Age':0.42,'Pclass':2}, value=18) # 此时字典键为列名,值为被替换值,value为替换值
df = df.replace(to_replace={'Age':{0.42,18, 0.67:18}}) # 作为嵌套字典,指定将某列中的具体数据按字典映射替换,value不再指定替换值
### method替换
# 将1,2 替换为它们前一个值
s.replace([1,2], method='ffill')
# 将1,2替换为它们后一个值
s.replace([1,2], method='bfill')
### 正则表达式替换
# 将Futrelle开头的值替换为FAA
df.replace(to_replace=r'^Futrelle.*',value='FAA',regex=True)
# 多个规则均替换为同样的值
df.replace(regex=[r'^Futrelle.*', r'Braund.*'], value='FAA').head()
# 多个正则级对应的替换内容
df.replace(regex={r'^Futrelle.*':'FAA', r'^Braund.*':'BAA'})2.2 文本处理
主要是针对series.str.func的应用。
2.2.1 文本格式
(1)大小写变换
# 字符全部变成小写
s.str.lower()
# 字符全部大写
s.str.upper()
# 每个单词首字母大写
s.str.title()
# 字符串第一个字母大写
s.str.capitalize()
# 大小写字母转换
s.str.swapcase()(2)格式判断
s.str.isalpha # 是否为字母
s.str.isnumeric # 是否为数字0-9
s.str.isalnum # 是否由字母和数字组成
s.str.isupper # 是否为大写
s.str.islower # 是否为小写
s.str.isdigit # 是否为数字(3)文本对齐
# 居中对齐,宽度为8,其余用*填充
s.str.center(8, fillchar='*')
# 左对齐,宽度为8,其余用*填充
s.str.ljust(8, fillchar='*')
# 右对齐,宽度为8,其余用*填充
s.str.rjust(8, fillchar='*')
# 自定义对齐方式,参数可调整宽度,对齐方向,填充字符
s.str.pad(width=8, side='both', fillchar='*')(4)计数编码
s.str.count('b') # 字符串中包括指定字母的数量
s.str.len() # 字符串长度
s.str.encode('utf-8') # 字符编码
s.str.decode('utf-8') # 字符解码2.2.2 文本拆分
# 使用方法
s.str.split('x', n=1)
# 举例
df.Email.str.split('@')
# expand=True 可以让拆分的内容扩展成单独一列
df.Email.str.split('@', expand=True)
# 同时通过@和.进行拆分成三部分
df.Email.str.split('@|\.', expand=True)2.2.3 文本替换
(1)replace替换
# 将email种的com都替换为cn
df.Email.str.replace('com', 'cn')
# 将@之前的名字都替换为xxx
df.Email.str.replace('(.*?)@', 'xxx@')
# 将替换内容传递给lambda隐函数实现字符大写功能
df.Email.str.replace('(.*?)@', lambda x:x.group().upper())(2)切片替换
df.Email.str.slice_replace(start=1, stop=2, repl='XX')(3)重复替换
df.name.str.repeat(repeats=2)2.2.4 文本拼接
(1)单Series序列拼接
# name列series直接拼接
df.name.str.cat()
# 设置sep分隔符为'-'
df.name.str.cat(sep='-')
# 将缺失值设置为*
df.name.str.cat(sep='-', na_rep='*')(2)多series序列拼接
# 设置others后,cat会将series和others定义的序列进行拼接
df.name.str.cat(others=['*']*6)
# 多列拼接
df.name.str.cat([df.Email, df.level], sep='-', na_rep='*')2.2.5 文本提取
# extrac
df.Email.extract(pat='(,*?)@(.*).com')
# extractall多返回一列match
df.Email.extractall(pat='(,*?)@(.*).com')2.2.6 文本查询
### find:返回原字符串的位置,没有返回-1
df.Email.str.find('@')
### findall:支持正则表达式
df.Email.str.findall('(,*?)@(.*).com')2.2.7 文本包含
配合loc用于查询。
df.loc[df.Email.str.contains('com|Mike', na=False)]2.2.8 文本哑变量
df.name.str.get_dummies()2.3 时间处理
2.3.1 时间类型
| Timestamp | 最基础的时间类,表示某个确切的时间点。在绝大多数的场景中的时间数据都是Timestamp形式的事件类型 |
| Period | 表示单个时间跨度,或者某个时间段,例如某一天,某一小时等。 |
| Timedelta | Timedelta表示不同单位的时间,例如1天、1.5小时、3分钟、4秒等,并非具体的某个时间段。 |
| DatetimeIndex | 一组Timestamp构成的index |
| PeriodtimeIndex | 一组Period构成的index |
| TimedeltaIndex | 一组Timedelta构成的index |
### 创建方式
# 时间戳创建
pd.Timestamp(1990,1,1)
# 时间差创建
pd.Timedelta('1days 1minute')
# 时间周期创建
pd.Period(2023, freq='M')2.3.2 时间类型转换
(1)to_datetime
df = pd.to_datetime(df)
df['a'] = pd.to_datetime(df['a'], format='%Y.%m.%d')(2)to_timedelta
pd.to_timedelta(['1days 1minute', '2days 2minute'])2.3.2 时间类型属性
(1)Timestamp
可以实现时间信息的提取、判断、格式变换。
# 属性
s.dt.date # 转换为object类型的日期
s.dt.year
s.dt.quarter # 季节
s.dt.month
s.dt.hour
s.dt.minute
s.dt.second
s.dt.nanosecond # 纳秒
s.dt.weekday # 工作日第几天
s.dt.day # 一个月当中的第几日
s.dt.day_of_week # 一周中第几天
s.dt.day_of_year # 一年中第几天
s.dt.dayofweek
s.dt.dayofyear
s.dt.days_in_month # 时间所在月份总天数
s.dt.daysinmonth
s.dt.is_month_start # 是否为月初
s.dt.is_month_end # 是否为月末
s.dt.is_quarter_start # 是否为季度第一天
s.dt.is_quarter_end # 是否为季度最后一天
s.dt.is_year_start
s.dt.is_year_end
s.dt.is_leap_year # 是否为闰年
s.dt.time # 获取时分秒的具体时间
s.dt.timetz # 获取时分秒的具体时间+时区
s.dt.freq # 频率
s.dt.unit # 时间最小单位# 函数
s.dt.as_unit('s') # 转换最小单位精度
s.dt.ceil(freq='d') # 按指定频率向上取整
s.dt.floor(freq='d') # 按指定频率向下取整
s.dt.round(freq='d') # 按指定频率四舍五入
s.dt.day_name() # 时间对应的星期数,英文字符串
s.dt.month_name() # 时间对应的月份,英文字符串
s.dt.normalize() # 时间转换到midnight半夜
s.dt.strftime(date_format='%Y-%M-%D') # 转换时间格式,转换后对象为object
s.dt.isocalendar() # 日历函数,返回三个字段:年、一年中第几周、一周中第几天
s.dt.to_period() # 转换为period类型
s.dt.to_pydatetime() # 以numpy array形式返回Python中定义的时间差类型对象(2)TimeDelta
# 函数
s.dt.as_unit('s') # 转换最小单位精度
s.dt.ceil(freq='d') # 按指定频率向上取整
s.dt.floor(freq='d') # 按指定频率向下取整
s.dt.round(freq='d') # 按指定频率四舍五入
s.dt.day_name() # 时间对应的星期数,英文字符串
s.dt.month_name() # 时间对应的月份,英文字符串
s.dt.normalize() # 时间转换到midnight半夜
s.dt.strftime(date_format='%Y-%M-%D') # 转换时间格式,转换后对象为object
s.dt.isocalendar() # 日历函数,返回三个字段:年、一年中第几周、一周中第几天
s.dt.to_period() # 转换为period类型
s.dt.to_pydatetime() # 以numpy array形式返回Python中定义的时间差类型对象# 函数
s.dt.as_unit('s') # 转换最小单位精度
s.dt.ceil(freq='d') # 按指定频率向上取整
s.dt.floor(freq='d') # 按指定频率向下取整
s.dt.round(freq='d') # 按指定频率四舍五入
s.dt.to_pytimedelta() # 以numpy array形式返回Python中定义的时间差类型对象
# 将时间差的成分进行分解,并转化为具体的数值
s.dt.components
# 转换为以秒单位的数值
s.dt.total_seconds()(3)Period
# 属性
df.dt.day # 每个周期的天数
df.dt.day_of_week # 一周中的第几天
df.dt.day_of_year # 一年中的第几天
df.dt.dayofweek
df.dt.dayofyear
df.dt.days_in_month # 一月中的第几天
df.dt.daysinmonth
df.dt.start_time # 一个周期的开始时间
df.dt.end_time # 一个周期的结束时间
df.dt.is_leap_year # 所在年是否为闰年
df.dt.freq # 频率
df.dt.year # 时间所在年
df.dt.quarter # 时间所在季节
df.dt.month
df.dt.week
df.dt.hour
df.dt.weekday # 时间所在一周中的第几天
df.dt.weekofyear # 时间在一年中的第几周
# 函数
df.dt.to_timestamp() # 转换为时间戳类型
df.dt.asfreq(freq='Q') # 改变周期频率为季度
df.dt.striftime(date_format='%Y-%m-%d') # 改变时间格式