作为一个淘系出来的人,参加过声势浩大的S11、S2大促;也和阿里云数据库团队、内核团队等并肩作战过;更是手握过六七百万的预算支持阿里云的服务,更是他们的至尊群用户,得知此次重大故障后,也甚是惊讶。
从阿里云的角度看,这次故障很“不阿里云”,毕竟阿里云一向以安全稳定高可用自居,如此范围之大、持续时间之久、影响面如此广的故障,对阿里云的品牌形象绝对是致命的打击。
目录
- 回顾
- 时间
- 影响
- 阿里系产品集体崩溃
- 受影响云产品
- 受影响地区
- 生活的方方面面
- 处理过程
- 原因
- 启迪
- 稳定性
- 代码需要稳定性
- 设计上需要稳定性
- 迭代变更需要稳定性
- 最重要的是人员需要稳定性
- 书籍推荐
- 书籍名称:《收割Offer互联网大厂面经》
- 内容介绍
- 适合人群
- 如何领书
回顾
时间
2023年11月12日17:39~19.20,故障时间为 1 小时 41 分。
影响
阿里系产品集体崩溃
双11当晚,淘宝曾有短暂宕机,但很快就过去了。但到了12日傍晚,阿里云突然出现事故,导致淘宝、闲鱼、钉钉、阿里云盘、饿了么、天猫精灵、菜鸟、夸克、语雀等,多个阿里系App出现无法访问或服务异常的情况。
阿里云崩了、淘宝崩了、闲鱼崩了、钉钉崩了等话题相继登上热搜。
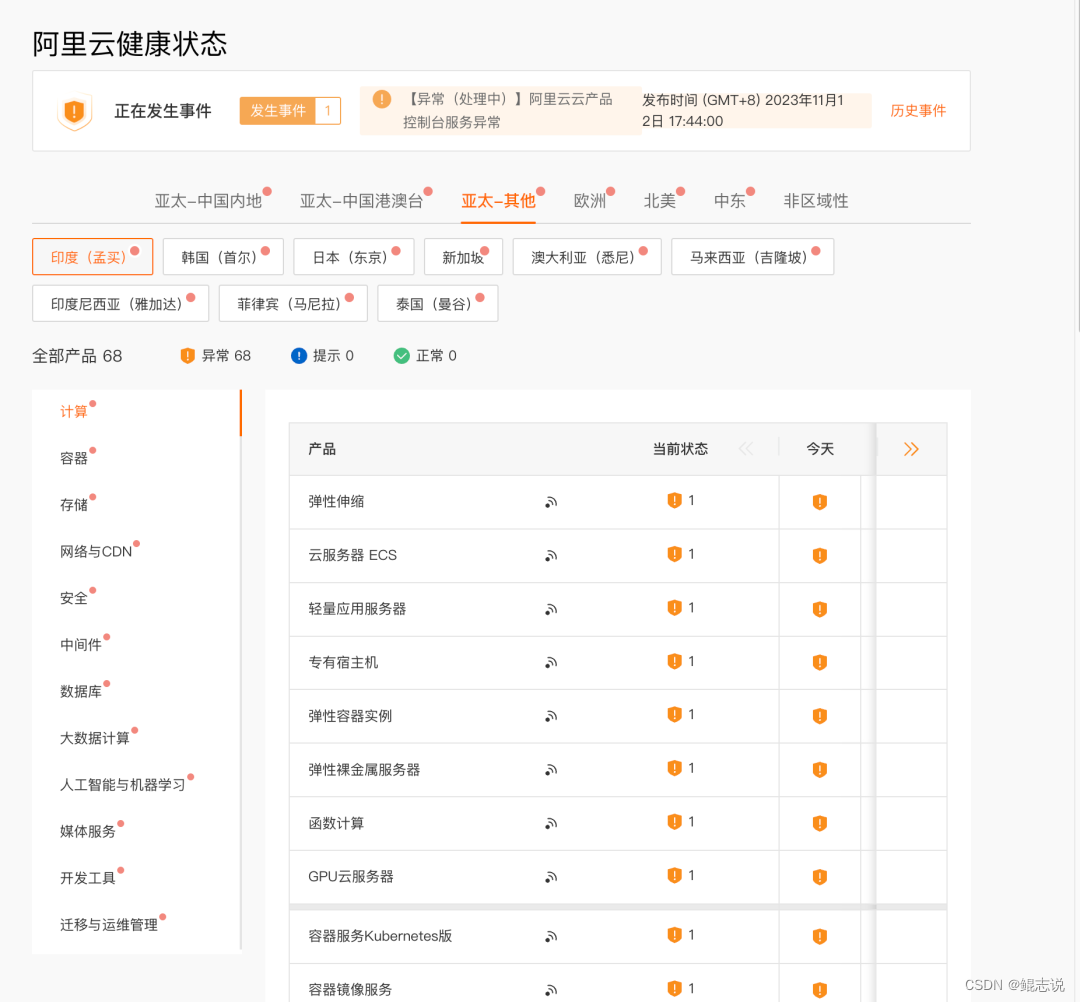
受影响云产品
企业级分布式应用服务、 消息队列MQ、微服务引擎、链路追踪、应用高可用服务、应用实时监控服务、Prometheus监控服务、消息服务、消息队列Kafka版、机器学习、图像搜索、智能推荐AlRec、智能开放搜索OpenSearch、云行情、数据总线DataHub、检索分析服务Elasticsearch版、 图计算服务Graph Compute、实时计算Flink版、智能数据建设与治理Dataphin、开源大数据平台E-MapReduce、云原生大数据计算服务MaxCompute、实时数仓Hologres.大数据开发治理平台DataWorks、智能媒体服务、媒体处理、视频点播、对象存储、文件存储NAS、表格存储、日志服务、云存储网关、文件存储HDFS版、块存储、混合云备份服务、密钥管理服务、云防火墙、数据库审计、加密服 务、运维安全中心(堡垒机)、 容器镜像服务、容器服务Ku bernetes版、API 网关、资源编排、云原生数据仓库Analyti cDB PostgreSQL版、图数据库、云原生内存数据库Tair、云 数据库Redis 版、云原生关系型数据库PolarDB、云数据库专属集群、云数据库MySQL版、云原生数据仓库AnalyticD B MySQL版、云原生分布式数据库PolarDB-X、云数据库 ClickHouse、云原生多模数据库L indorm、云数据库Postgr eSQL版、云数据库SQL Server 版、云数据库MongoDB版、云数据库HBase版、数据传输、数据库自治服务、数据库备份、物联网平台、NAT网关、负载均衡、云解析PrivateZone、弹性公网IP、共享带宽、转发路由器、私网连接、高速通道、IPv6网关、专有网络VPC、云企业网、VPN网关、FPGA云服务器、超级计算集群、批量计算、无影云桌面、弹性伸缩、弹性容器实例、弹性裸金属服务器、云服务器EC S、轻量应用服务器、函数计算、Serverless 应用引擎、云托付、专有宿主机、GPU云服务器、弹性高性能计算、操作审计、服务器迁移中心、运维编排、智能计算灵骏、云呼叫中心、交通云控平台、客服工作台、视觉智能开放平台、智能外呼机器人、智能语音交互、智能对话机器人、智能用户增长、运维事件中心、新零售智能助理。
受影响地区

生活的方方面面
比如,很多学校的学生不能使用宿舍里的洗衣机了,因为大部分学校里共享洗衣机的服务商的业务就跑在阿里云上。此外,还有很多很多人因此遭遇了无法使用直饮水机、无法给电瓶车充电、停车场停车杆抬不起来等问题。
处理过程
- 17:39:阿里云云产品控制台访问及管控 API 调用出现异常,阿里云工程师正在紧急介入排查。
- 17:50:工程师确认故障是 AK 服务异常导致,影响云产品控制台、管控 API 调用异常,以及依赖 AK 服务的云产品服务运行异常,工程师正在紧急处理中。
- 18:01:工程师定位到根因。
- 18:07:开始执行恢复措施,包括修订白名单版本、重启 AK 服务。
- 18:54 经过工程师处理,杭州、北京等地域控制台及API服务已恢复,其他地域控制台服务逐步恢复中。
- 19:20:工程师通过分批重启组件服务,绝大部分地域控制台及API服务已恢复。
- 19:43 异常管控服务组件均已完成重启,除个别云产品(如消息队列MQ、消息服务MNS)仍需处理,其余云产品控制台及API服务已恢复。
- 20:12 北京、杭州等地域消息队列MQ已完成重启,其余地域逐步恢复中。
原因
访问密钥服务 (AK)在读取白名单数据时出现读取异常,因处理读取异常的代码存在逻辑缺陷,生成了一份不完整白名单,导致不在此白名单中的有效请求失败,影响云产品控制台及管控 API 服务出现异常,同时部分依赖 AK 服务的产品因不完整的白名单出现部分服务运行异常。
启迪
网上对于此次阿里云事件议论纷纷,我也通过内部渠道了解了部分原因,可能这次冥冥之中是逃不掉故障的,因为听说稳定性已经很久没人提了。然而此次事故最大的原因,就是稳定性。
稳定性
记得之前每每大促,稳定性保障一词总是被提起,还有稳定性保障团队及负责人。但现在也被人遗忘了,在降本增效的今天深刻的证明了:杀头的生意有人做,亏本的买卖无人干。
稳定性难得真的不是技术,当业务研发上千,日迭代频繁,基础设施不计其数的各项对象及参数,牵一发而动全身,稳定性需要有团队,组织,文化,技术,管理等各类综合工具与人员来统一护航管理,对业务,对组织负责,不是简单的降本增效、人员迭代、工作交接,就可以搞定的!
代码需要稳定性
优秀的程序员的最大差别其实就是在代码的鲁棒性上
-
对边界的控制,确保输入是符合自己的预期的,而不只是设计文档上空洞的三言两语,例如最典型的故障是批量操作型的接口,由于批量操作的量超过了预期,直接内存溢出等;
-
对使用到的接口或工具充分了解(包括实现原理、代码细节),只有这样,才能知道各种情况下的状况,从而在真正出故障的情况下能快速处理;
设计上需要稳定性
设计上要尽量做到高内聚低耦合
- 强弱依赖识别,对弱依赖的地方,确保有各种降级策略;
- 自身能力保护,一定要对自己系统的能力有清晰的认识;
- 容灾能力,这个从集群化、到同城多活、再到异地多活,其实都有各种成熟的案例和相应的方案。
迭代变更需要稳定性
众所周知,出故障的时候,往往是做了一些改动,但又没考虑周全
- 一定要灰度,可以灰度测试,就能提前发现问题,解决问题,同时减少影响半径;
- 可监控,可回滚。可监控是为了及时发现问题;可回滚是变更一旦出问题,最好用的招;
- 有尽快恢复的兜底方案。在故障出现时尽快恢复,而不是解决故障,在保留一定的现场的基础上,尽快的恢复问题比查问题重要的多。
最重要的是人员需要稳定性
稳定性难在没有银弹,只能靠大量的细节来落地做好稳定性这个系统工程的事情,这意味着需要大量的投入,毕竟就算有指导思想、解决方案、能力,但没有相应的投入,那自然只能有一定的取舍,最终呢,总是要还的。
就像我们毕业群里校友调侃的
- 降本增效就是一个伪命题,总想着既让马儿跑又不让马儿吃草,这不是扯吗,都不懂鱼和熊掌不可兼得不出事才怪
- 阿里云高管的调整、业务团队的变动、一线员工的离开,以及精力的转移增加了不确定性,业务稳定性亦在降低。
- 维护一个复杂的中台需要大量专业的开发和运营人员,而阿里云今年的裁员对此或多或少产生了影响,另外,管理亦是因素之一。
书籍推荐
我们可能决定不了一直留在哪家公司,但我们可以选择去哪家公司,下面给大家推荐一本 《收割Offer互联网大厂面经》 ,来帮助大家找到更好的东家去做好稳定性保障!
书籍名称:《收割Offer互联网大厂面经》
对于后端程序员来说,这是一本让你获得大厂Offer的秘诀和宝典。

内容介绍
《收割Offer:互联网大厂面经》根据编者工作和面试经验,全面介绍了后端工程师求职面试需要掌握的知识和技能。主要内容分为五个部分:八股文、算法、场景设计题、项目和HR面试技巧。 八股文章节涵盖了后端面试必备的重要知识点,包括综合知识、数据库、Redis、RocketMQ、操作系统、计算机网络、Spring、ZooKeeper、Dubbo等。
HR面试技巧章节以与头部大厂HR访谈记录的形式向读者展示了HR面试内幕。本书的内容安排完全与面试要求匹配,根据历史经验,任何一场后端面试80%的问题都可以在本书中找到。阅读本书可以快速找到学习方向,树立求职信心,提高面试通过率。
适合人群
《收割Offer:互联网大厂面经》适合希望从事互联网后端开发的读者,包括参加校园招聘和社会招聘的求职者。此外,后端开发与测试开发的技能要求有很多共同点,因此,本书对于从事测试工作的读者也有较大参考价值。

如何领书
————————————————
本次本篇文章送书 🔥2-3本 评论区抽2-3位小伙伴送书
活动时间:截止到 2023-11-25 20:00:00
抽奖方式:利用网络公开的在线抽奖工具进行抽奖
参与方式:关注、点赞、收藏,评论“人生苦短,给我offer"
根据文章阅读量的多少来安排送书的本数。
————————————————
🔥 注:活动结束后,会私信中奖粉丝的,各位注意查看私信哦!
小伙伴也可以访问链接进行自主购买哦~
直达京东购买链接:《收割Offer:互联网大厂面经》