0,视频地址
https://www.bilibili.com/video/BV16j411E7FX/?vd_source=4b290247452adda4e56d84b659b0c8a2
【chatglm3】(4):如何设计一个知识库问答系统,参考智谱AI的知识库系统,学习设计理念,开源组件
1,知识库项目地址
https://open.bigmodel.cn/knowledge
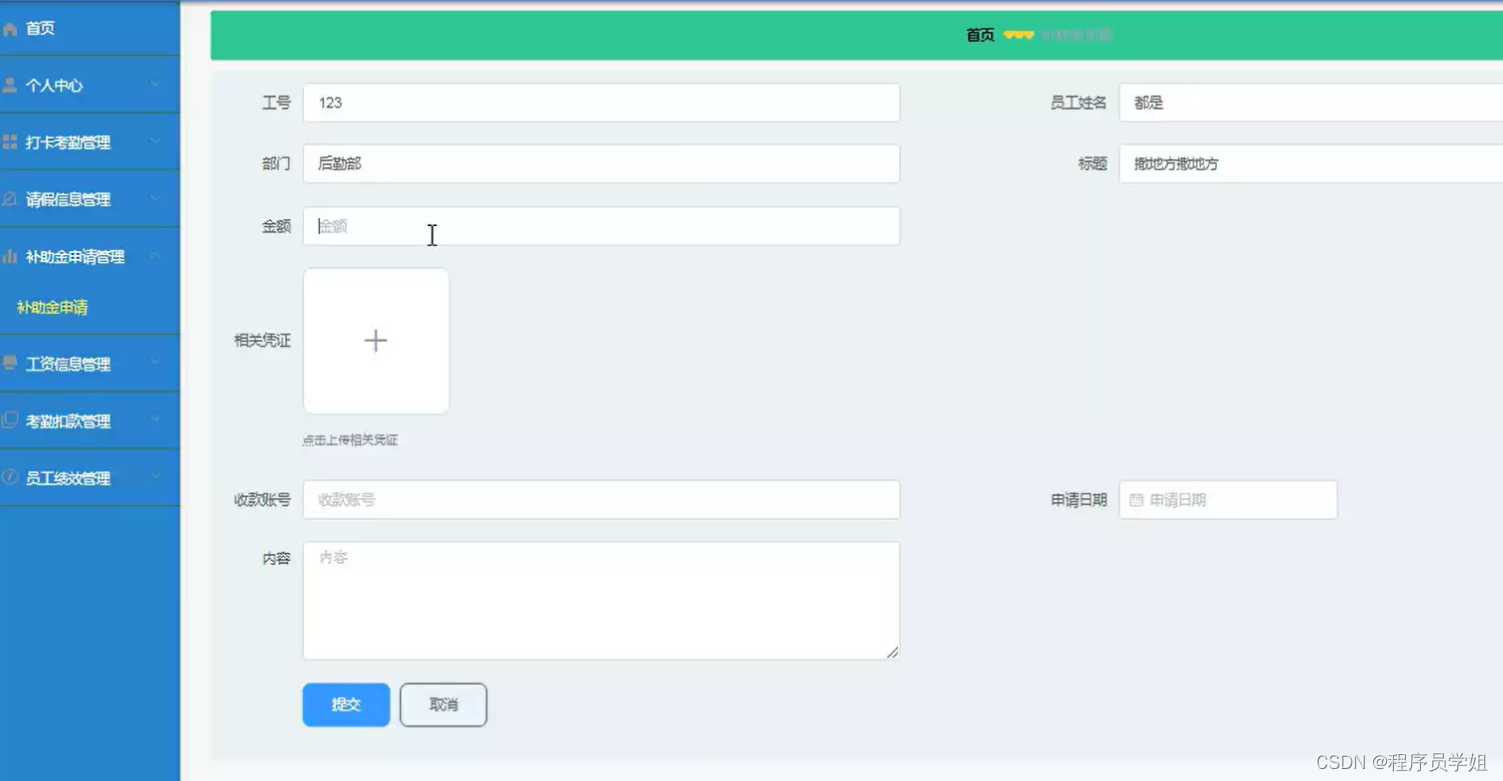
知识配置:
演示效果:

2,系统原理参考
项目地址是:
https://github.com/chatchat-space/Langchain-Chatchat
gitee搬运的项目:
https://gitee.com/yang_hong_quan/Langchain-Chatchat
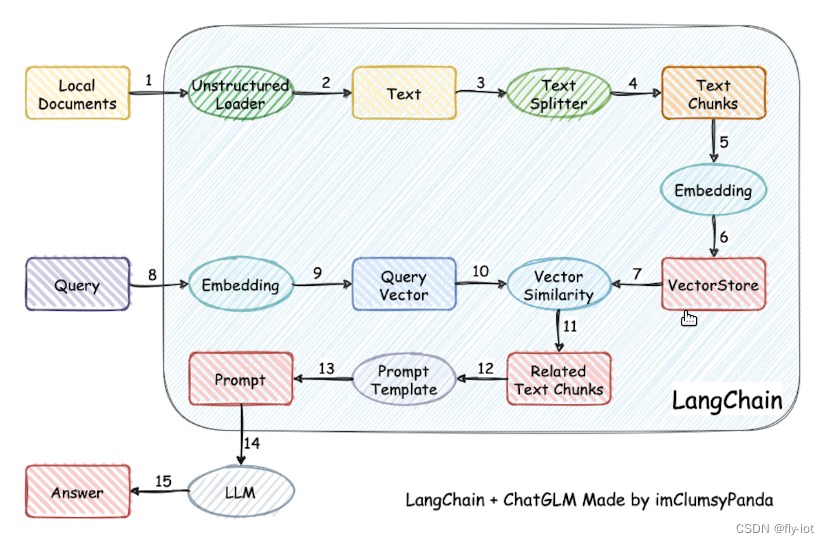
文档流程:
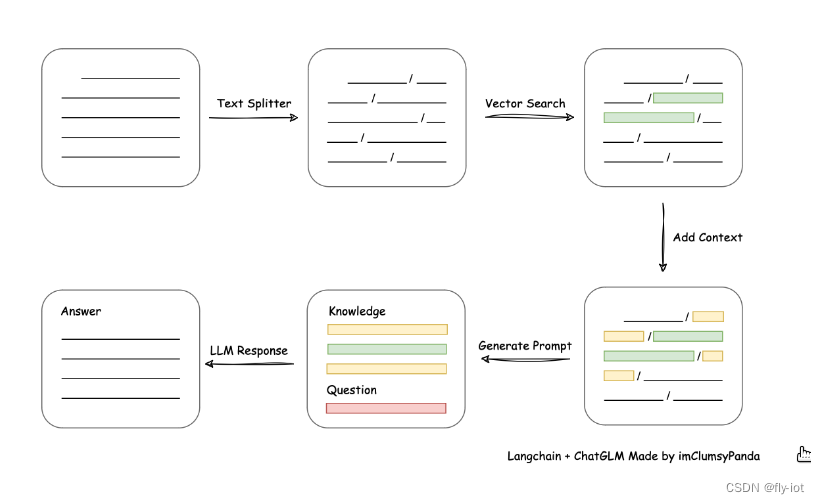
3,涉及系统开发
智谱AI大模型接口:
https://open.bigmodel.cn/dev/api#text_embedding
https://open.bigmodel.cn/dev/api#http
4,向量数据库
| 名称 | 开源 | 社区星 | 语言 | 说明 |
|---|---|---|---|---|
| weaviate | 是 | 5.3k star | Go | 同时支持向量与对象的存储、支持向量检索与结构化过滤、具备主流模式成熟的使用案例。高速、灵活,不仅仅具备向量检索,还会支持推荐、总结等能力 |
| qdrant | 是 | 6.3k star | Rust | 向量存储与检索、云原生、分布式、支持过滤、丰富的数据类型、WAL日志写入 |
| milvus | 是 | 17.7k star | Go | 极高的检索性能: 万亿矢量数据集的毫秒级搜索非结构化数据的极简管理丰富的API跨平台实时搜索和分析可靠:具有很高的容灾与故障转移能力高度可拓展与弹性支持混合检索统一的Lambda架构社区支持、行业认可。 |
milvus 向量数据库可以研究下:
https://milvus.io/
可以使用docker 进行项目部署
https://milvus.io/docs/install_standalone-docker.md
5,开源模型 Embeddings
Text2vec文本表征及相似度计算:包括text2vec-large-chinese(LERT,升级版)、base(CoSENT方法训练,MacBERT)两个模型。这个模型也使用了word2vec(基于腾讯的800万中文词训练)、SBERT(Sentence-BERT)、CoSENT(Cosine Sentence)三种表示方法训练
https://modelscope.cn/models/thomas/text2vec-large-chinese/summary
百度的 ernie-3.0-base-zh:https://github.com/PaddlePaddle/PaddleNLP
SimCSE:https://github.com/princeton-nlp/SimCSE
M3E:Moka Massive Mixed Embedding的缩写,由MokaAI训练,训练脚本使用 uniem,评测BenchMark使用MTEB-zh,通过千万级 (2200w+) 的中文句对数据集进行训练。
https://www.modelscope.cn/models/xrunda/m3e-base/summary
6,总结
通过大语言模型快速搭建本地知识库系统。
将本地数据知识结合业务场景应用。非常不错的事情。
最重要的是转换格式,做 embedding ,然后存储到向量数据库中。