前言
文件系统
我们先来看两个例子:

这个程序输出:

此时的输出也满足的我们预期。
我们也可以把 程序执行结果,输出重定向到 一个文件当中:
当我们在代码的结尾处,创建了子进程,那么输出应该还是和上述是一样的:
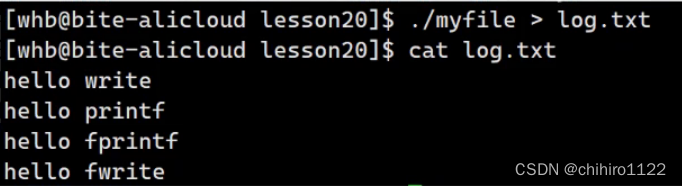
此时,我们把 这个程序的输出结果 ">" 重定向到 一个文件当中,为了验证,所以,我们把之前在文件当中保存的 数据先删除:
![]()
然后,在进行重定向操作(其实 ">" 这个重定向本来就可以做到 清空文件的作用,这里只不过是 为了 分步骤来看,更加可观):

发现,此时的结果,在文件当中输出和之前不一样了。
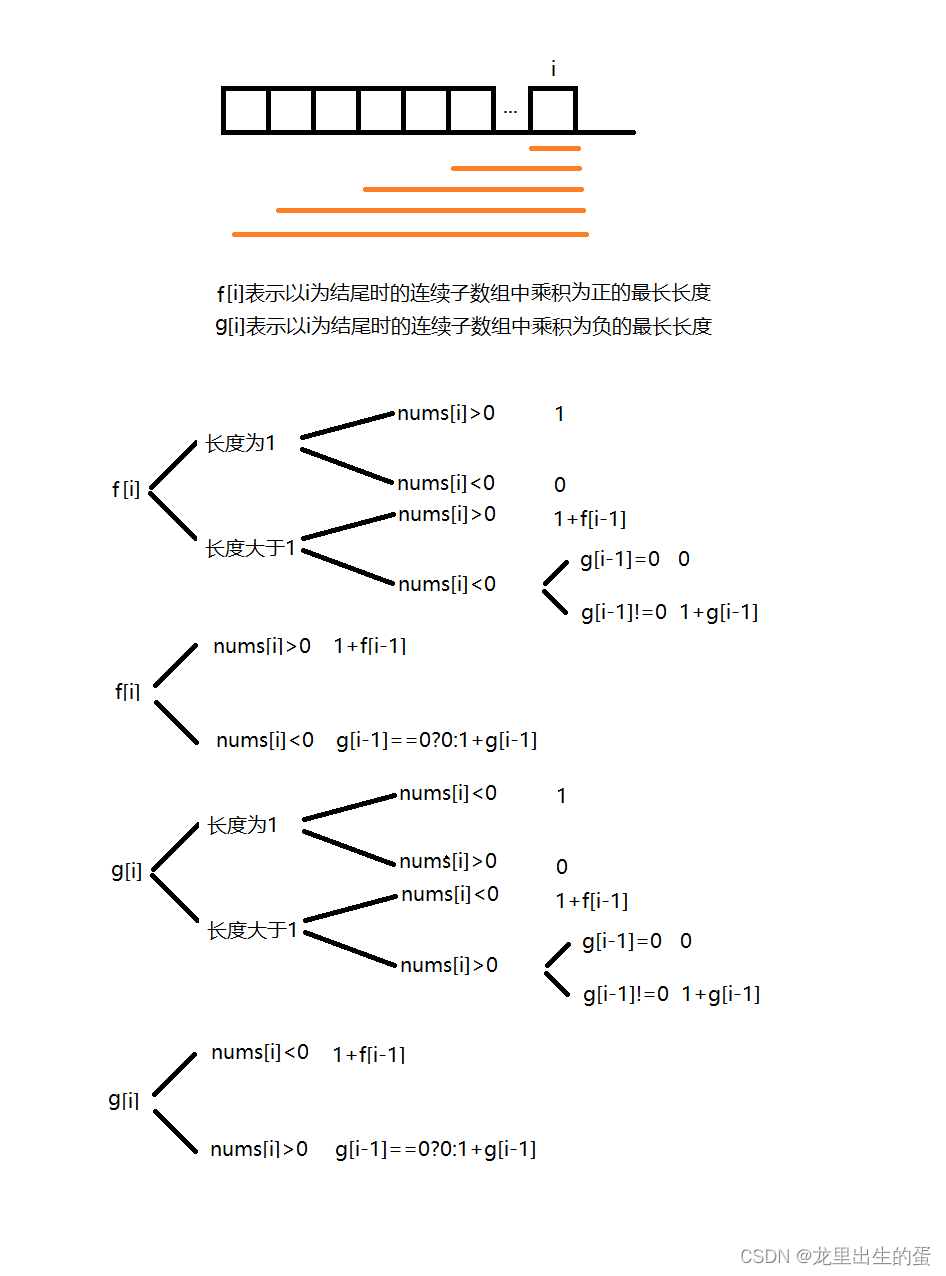
上述的输出结果,看上去和之前的输出结果没什么关系,也不是单纯的输出了两遍,因为只输出了 7 行 而不是 8 行。
我们发现,除了 write()系统调用接口函数之外,C 库当中都是按照我们调用的顺序 调用了两遍。而且,wirte()函数的打印顺序,和之前相比也是不一样的。
说明,系统调用接口,没有受到我们 fork()函数影响。
出现上述的原因,就和 缓冲区脱不了干系了。
缓冲区
先看下述 例子 :
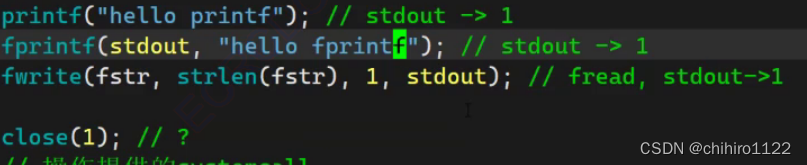
上述的 三个函数 都是 在 stdout 这个文件当中输出数据,当他们输出完毕之后,我再去 把 1 号文件也就对应着 stdout 这个文件关闭了,然后程序执行结束,你再猜猜 此时的输出结果是什么?

发现,此时是什么结果都没有输出的,同样,重定向到 log.txt 文件当中也是没有输出的。
上述的是 3 个 C库函数,如果是 系统调用接口呢?此时我们把 write()系统调用接口调用:
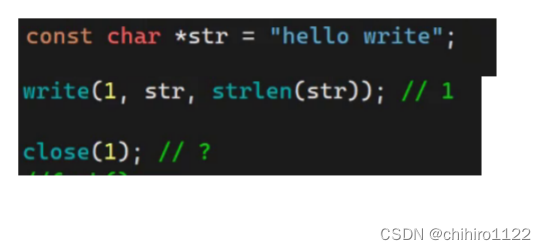
输出:
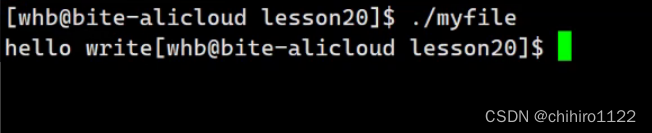
发现居然 成功输出 了。
在 C 当中封装的要调用到 硬件的 函数,底层都是要调用 系统调用接口的,比如上述的函数,都是要调用 write()函数的。
都是把对应的数据,传入到 write()系统调用接口,然后通过系统调用接口 来 输入到缓冲区当中。
其实,上述使用的 3 个C库函数,其实是已经在缓冲区当中输入数据了的。
一个文件,肯定是提供了 自己 操作系统级别的缓冲区。这个缓冲器就是这个文件的 文件缓冲区。
但是,3 个C库函数 写入的缓冲区肯定不是 系统级别的缓冲区,如果是系统级别的缓冲区的话,程序执行结束之时,就会刷新缓冲区,我们就会看到对应的输出结果。
这就是为什么 write()系统调用接口可以看到 输出结果。write()函数,是直接向 传入的文件的 对应 文件缓冲区当中 写入数据。到最后刷新文件缓冲区之时,就会把数据刷新到文件当中。
而且,像 printf / fprintf / fwrite / fputs ····· 这些函数,不是直接向文件缓冲区当中去刷新数据,因为 文件缓冲区是属于内核的,在语言级别 封装的 函数是不能直接访问到的,中间还有层级。(反证:如果 printf / fprintf / fwrite / fputs ····· 这些函数 已经把数据拷贝到 文件缓冲区当中了,当我们调用 close()函数之时,比如 close(1),就会把 1 号文件 对应的 文件缓冲区当中的数据 刷新 到磁盘当中。 但是,我们并没有看到 输出结果。)

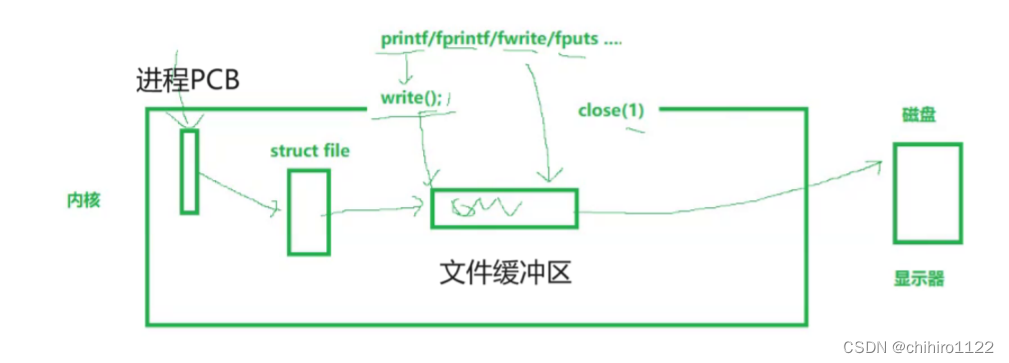
那么 ,语言层级的 函数,不直接向 系统级别的 缓冲区当中写入数据,那么数据究竟被写入到那里了呢?
其实,像 C/C++ 语言,是有自己的 语言层级的 缓冲区 的。这个缓冲区是 用户级别的 缓冲区。
所以,像 printf / fprintf / fwrite / fputs ····· 这些函数 在向文件当中写入数据之时,并不是直接把数据写到 系统级别的缓冲区当中,而是先写入到 语言层级的 缓冲区 当中。
只有当在 合适时机,比如 遇到了强制刷新缓冲区,fclose()函数,或者是在字符串当中有 '\n' ····· 等等时机,此时 才会调用 write()函数把 语言层级的 缓冲区 当中的数据,写入到 系统缓冲区当中。
所以,在 开始 close(1)关闭1号文件 C 库函数没有输出的原因是:
- 在 C语言当中的缓冲区刷新之前,1 号 文件 也就是 stdout 文件 已经被关闭了,当程序解释之时, C语言当中的缓冲区 想要刷新 其中的数据到 1 号文件的 文件缓冲区之时,在这个进程当中就找不到这 1 号文件了。
所以,此时如果我们把 三个 C库函数当中要输出的字符串都 ,就可以输出数据了。

输出:

为什么 在字符串当中 带上 '\n' 的话 就 可以 刷新呢?
因为 显示器文件的刷新方案是 行刷新。所以在 类似 printf()函数执行之时,识别到 字符串当中有 '\n' ,遇到 '\n' 就会立即把 C语言 缓冲区当中的数据 刷新出去。
所以,刷新的本质就是 通过 1 号文件 + write()系统接口的方式,写入到内核当中的 系统级别的 缓冲区当中。
所以,例如 exit() 和 _exit()两个函数是有区别的!!
exit()是C当中通过 _exit()函数封装的一个函数,而 _exit()此时 真正实现 进程退出的 系统调用接口;exit()底层当中 一定 有_exit()的调用。
在理解上述 用户级别 缓冲区 和 操作系统级别的缓冲区的 区别之后,你应该就会明白这两个函数有什么不同。
之所以 exit() 函数能刷新 C语言缓冲区,是因为 exit()函数是 在 C语言当中通过 _exit()函数封装的一个 函数( fflush(strout); _exit() ),他能看到 这个层次 C语言缓冲区。而 _exit() 不能刷新 C语言缓冲区是因为 _exit()是底层系统调用接口,它的层级是在底层,它看不到 在用户层级的 C语言缓冲区。
所以,到现在,你可以简单 理解的为:只要是 数据被刷新到 系统缓冲区当中了,也就是 数据被刷新到了内核当中,数据就可以到达硬件了。
缓冲区的刷新问题
主要分为三种方式进行刷新:
- 无缓冲 --- 直接进行刷新,也就是收到数据就马上把这个数据给刷新出去。比如调用 prinf()函数,调用 printf()函数结束 就 立即把 缓冲区当中的数据刷新 到内核当中。
- 行缓冲 --- 就像上述的 显示器文件一样,一行一行的进行输出。不管当前缓冲区当中有多少个数据,只要没有 '\n' 类似的换行符,就会一直在 缓冲区当中等待,只要 缓冲区当中读到了第一个 '\n' 类似的换行符,才会把 缓冲区当中的 数据刷到 内核当中。 、
- 全缓冲 --- 什么都不认,无论输入什么数据到 缓冲区当中,都要进行等待,直到 把 缓冲区当中的数据写满了,才会把 缓冲区当中的数据 刷新到 内核当中。

在文件缓冲区当中使用的刷新方式是 全缓冲,也就是,把缓冲区当中写满才会 把数据写到 文件缓冲区当中。
为什么文件要使用 全缓冲呢?(因为,除了 显示器文件,其他在磁盘当中存储的文件,不是直接拿给 用户 或者是 操作系统来直接查看的。没有 显示器文件那种需求。)
当然,当进程退出之时,也就刷新 C 语言缓冲区。像我们在 调用 printf("hello Linux!"); 在这个语句当中是没有 '\n' 的,但是,在最后还是会给我们刷新到 strout 文件当中让我们看到。
就是因为 当进程退出的之时,也会刷新缓冲区。
所以,缓冲区当中的刷新不一样必须按照上述的 三种方式来刷新。
为什么在 语言 层面会多出一个 语言层面的缓冲区呢?
其实,在语言层面的缓冲区就跟 快递公司一样,当我们先寄出一个包裹的时候,只需要到快递公司,把信息填好,快递公司就可以帮我们把东西送到目的地。
如果没有快递公司,那么我们可能就要自己亲自去送到 目的地,那么在此期间,就会非常的耗费时间。
有了快递公司,我们可以很方便的 把 "送东西"这个操作,交给快递公司来做,而我们就可以去干自己的事情。
快递公司在此处就相当于是 语言缓冲区,它解决的事 程序运行的效率问题。注意解决的不是 操作系统当中的效率,而是程序自己在运行之时的效率问题,这个数据要 放到那个 文件当中,该怎么放入,走什么流程,还是上述所说的流程,只不过,把这个流程不用程序自己做了,交给 语言缓冲区来做就可以了。所以提高的是程序的运行效率。
所以我们调用 printf()/ fprintf()···· 这些需要向文件当做写入 数据的 函数,才能很快的就调用个完。
要不是,在用户层面,要想访问到 底层当中硬件设备,中间必须要 一层一层往下去调用接口来实现,如果都交给 这个函数来完成的话,程序的效率就会下降。
所以,直接把要输入到 文件当中的数据,直接放到 语言缓冲区当中,交给他自己来判断当前的输入的数据当中是否 又要刷新的提示字符,在合适时机,来进行刷新。
同样,语言层面的缓冲区 和 快递公司也是一样的,如果你发一个快递,就把 这个人的快递,利用 货车,或者是 飞机之类的方式,直接送到目的地,那不得亏死。
所以,肯定是把 很多人的快递一块发送,这样才省力。
在 缓冲区当中就有这么 多种刷新的方式,但是都不是 来一个 数据比如来一个 char 类型的数据就把这个数据直接发送出去,而是都是多个数据一起发送。
我们在使用 printf()类似的函数之时:

在C语言当中我们把这些函数称之为 -- 格式化输入输出函数。
因为 strout 本质上其实是一个文件,在文件当中只能存储字符串,所以,我们在 显示器上看到的 输出的数据了,其实就是字符串。
而,上述函数在输出之时,像 int a = 100 ; printf("hello %d Linux!" , a); 当中的 "hello %d Linux!" 这个字符串是我们在 函数当中使用的 格式化输出的字符串的格式,要求在 这个字符串当中的 "%d" 这个位置,替换为 a 变量的值。
而 a 变量是 int 类型,其实就是在 "%d" 这个位置 把 a 变量的值,以字符串的形式 替换到 "%d" 这个位置。
所以,其实在 语言缓冲区当中,收到的就是 这个经过格式化的 字符串,
所以,语言缓冲区 还有一个作用就是 : 配合格式化输出。
像底层的 操作系统级别的缓冲区,不需要给各种不同的语言来 给这个缓冲区来指定不同的 格式化 输出的方法。
自己 语言的 格式化 为 字符串的方法,由自己的语言的缓冲区来提供和实现,操作系统级别的缓冲区只用做的是 把 上层缓冲区传入的 字符串 数据,保存到自己的缓冲区当中,然后刷新到对应文件当中。
所以,各种数据,结果各个接口,来到各个缓冲区当中之时,来的时候可能是多少多少字节的方式刷新到缓冲区当中的;而又是以 多少多少字节的方式刷新到 文件当中的。
这种方式不就像是 流水一般,有近就有出;所以,我们把这个称之为 --- 文件流。
语言缓冲区在哪?
上述我们多次 提到了 语言缓冲区,那么这个缓冲区到底在哪呢?
在 C 当中,我们要像访问 文件,对文件内容进行修改的话,离不开 C 当中的封装的一个结构体 -- FILE。
这个 FILE 本质其实就是一个结构体,在这个结构体当中封装了 fd 文件描述符。因为 不管哪种语言,只要是想访问 文件,就必须要按照 操作系统 当中访问文件的方式来访问 -- 就是使用 fd 文件描述符 ,通过 文件描述符表 当中的映射关系来找到这个文件对象,从而对 文件进行访问。
实际上,FILE 当中封装的不只是 上述的 fd文件描述符,还有 上述所说的 语言缓冲区字段 和 维护这个缓冲区的信息。
所以,其实这个缓冲区就是在 FILE 这个结构体当中 创建 和维护的。
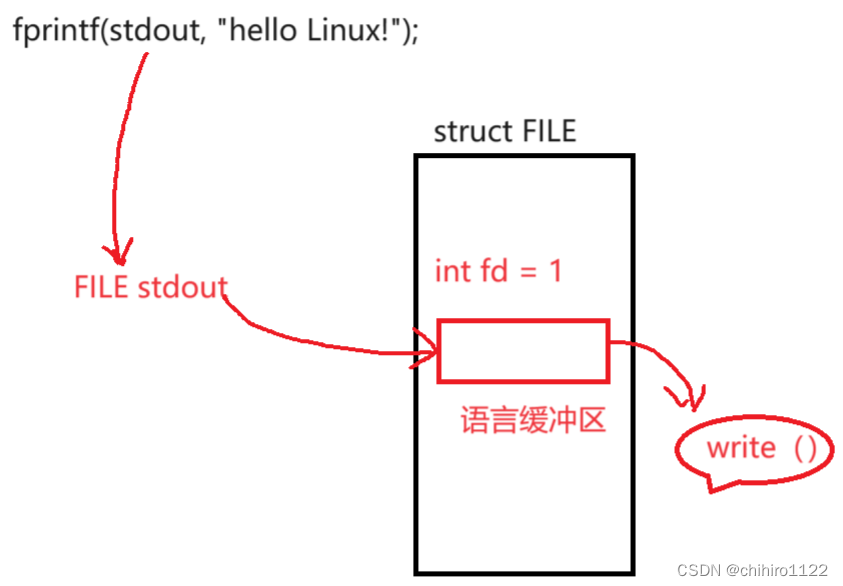
所以,在打开这个文件之后,如果我们先要 利用某些函数来访问到这个文件的话,就需要找到这个 FILE,所以我们才要传入这个 FILE 的指针。
所以,如果我们现在打开的 10 个文件,那么就 创建了 FILE 文件。
每一个 像不同文件写入数据的操作,实际上就是 ,通过对应文件的 FILE 结构体当中的缓冲区当中的数据,把这个数据刷新到 对应文件当中。
如下就是 FILE 结构体的定义(部分):
Linux 当中是 在/usr/include/stdio.h 默认是在 这个路径下:
typedef struct _IO_FILE FILE; // 在/usr/include/stdio.h//在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char* _IO_save_base; /* Pointer to start of non-current get area. */
char* _IO_backup_base; /* Pointer to first valid character of backup area */
char* _IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker* _markers;
struct _IO_FILE* _chain;
int _fileno; //封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t* _lock;
#ifdef _IO_USE_OLD_IO_FILE
};
通过上述的说明,你就会知道,为什么open()函数返回的是 FILE* , 在 open()函数当中肯定是要 类似 FILE* file = (FILE*)malloc(sizeof(xxx) * xxx); 这样创建一个 FILE 结构体对象的操作。
C 当中的 FILE 对象是属于用户?还是操作系统?
答案是属于 用户的,所有的语言层面的,都是属于用户的。 所以,我们 把 FILE 当中的缓冲区,称之为 用户级别的缓冲区。
理解开头 例子 (理解子进程当中继承的父进程当中的 FILE)
所以你就可以了理解上述的例子为什么会输出上述的 结果了:

因为我们上述在进行输出的时候,使用了 ">" 这个重定向符号,我们知道,在上述例子当中的这个 ">" 其实实现就是 把 输出文件从 stdout 文件改为了 log.txt 文件。
那么,缓冲区的刷新方式 也从 显示文件的 行刷新 转变到了 文件的全刷新。
也就是说此时,遇到 '\n' 不会再进行刷新。 只有当缓冲区当中的数据已经被写满了,才会去刷新。在不满的情况下,只有在 进程结束才会刷新。
现在,我们再把下述程序的输出过程来证明一下:

上述程序输出:

为什么是 wirte()先打印?
我们写一个 简单的 脚本来查看 这个程序的运行过程,查看 写入顺序:

脚本 输出:

- 而在上述代码当中,是先把三个 C库函数调用完毕,然后再调用 write()系统调用接口;
- 那么,程序只要是输出了 write()函数输出的内容,说明上述的 三个 C库函数 已经 调用完毕。 那么为什么不输出 三个 C库函数 的输出结果呢?为什么是在后面 输出呢?就是因为 这个 三个 C库函数 是往 语言缓冲区当中输出的;而 write()是直接往 系统缓冲区当中输出的。
- 而且,在上述代码当中,三个 C库函数 输出的字符串当中都带上了 '/n' 的,按照 显示器文件,那么应该是 一个C 库函数的输出,但是为什么上述是一起输出的呢? 其实就是因为,当我们, 重定向之后,输出文件变成了 log.txt 这个文件,这是普通文件,所以 刷新方式是 全刷新方式。
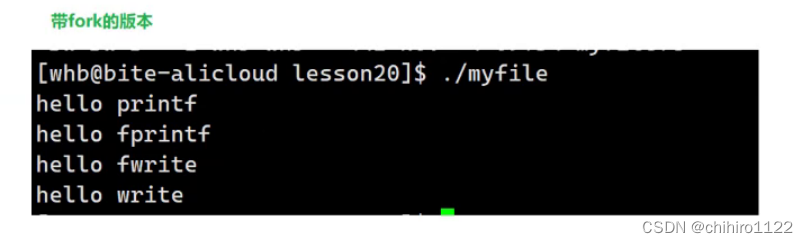
所以,在上述例子的基础之上,我们创建了子进程,输出如下所示:
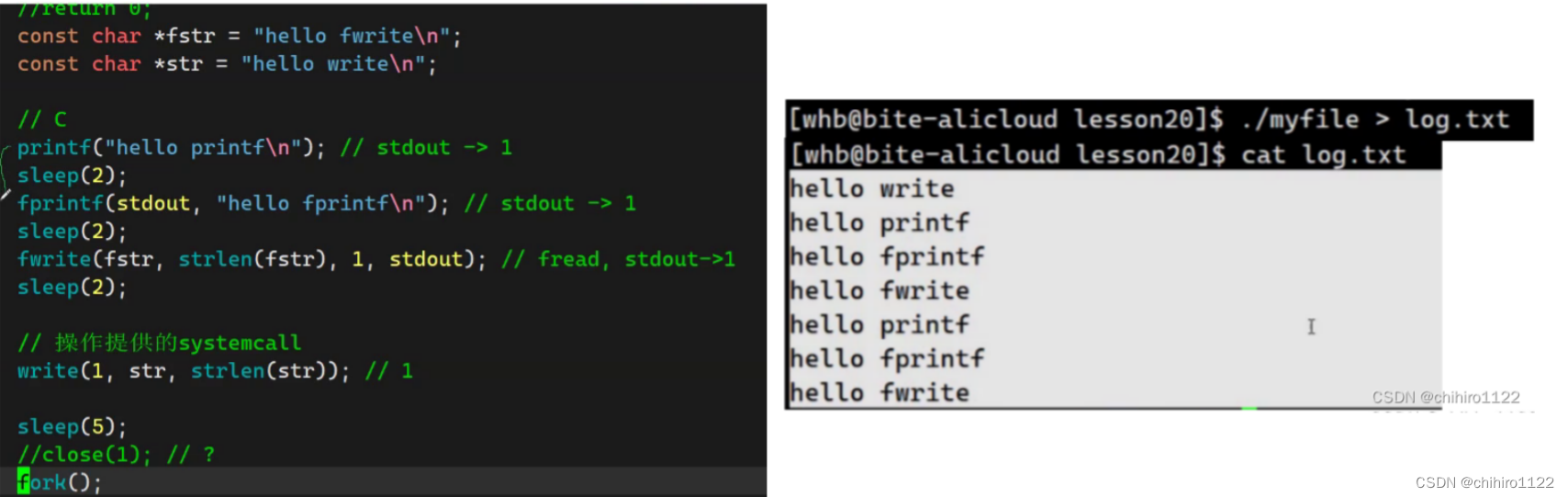
其实就是因为:
缓冲区的刷新方式变成了全缓冲(在不满的情况下,只有在 进程结束才会刷新),因为 write()函数是直接往 系统缓冲区当中刷新数据,所以,可以直接刷新到文件。
在 父进程当中,write()函数调用之前 调用的 三个 C库函数,已经被刷新到 语言缓冲区当中的,但是因为是 全刷新方式,所以,遇到 '\n',没有刷新到 系统缓冲区当中。
当子进程当中,虽然没有调用 三个 C库函数,此时,对于 父子进程来说,他们共有一个 代码和数据,也就是此时,父子进程共有 一个 FILE 结构体对象,那么其中的缓冲区也是共有的。
但是,因为最后,当程序执行结束时,就要把缓冲区当中的数据刷新到 系统缓冲区当中;对于 父进程来说,把缓冲区当中内容刷新到 系统缓冲区当中这个操作,不就相当于是把 FILE 当中的缓冲区字段清空了,这不就是修改操作吗?
所以,在父子进程当中,不管是谁修改了某一个数据,操作系统就会为这个 进程 进行写时拷贝。所以,此时,父子进程当中就有了 两个 FILE 结构体对象,也就有了 父子进程 各自独有的缓冲区了。
也就是说,在最后 把 父子进程共有的 缓冲区当中的数据刷新到 系统缓冲区当中之时,对于父进程,缓冲区其实就是我们在堆上开辟出的空间,刷新到 系统缓冲区这个操作,就是把 这个堆上开辟空间存储的数据全部删除了,也就相当于是 父进程 对这个空间当中的数据进行了修改,所以要发生写时拷贝。
写时拷贝之后,父子进程就拥有 各自的 两个独立的 FILE 对象了,也就有两个 独立的 缓冲区了。
而,子进程当中缓冲区的数据 还是之前 三个 C库函数 写入的数据,父进程也还是,所以,我们发现,在C 库函数当中输出的内容,在创建子进程之后,打印了两遍了。
而 上述是因为 fork()创建了子进程,而且,还使用了 ">" 把程序输出内容输出到 文件当中,改变了刷新方式;
而,如果我们直接运行程序,不重定向到 其他普通文件,就算我们 创建了子进程,因为 显示器文件是行刷新的,在上述例子当中每一个 C库函数 当中的输出字符串 当中就有 '\n' 字符,用于 很刷新的判断。
所以,每调用完 函数,就会检测到 '\n' 字符,直接就进行刷新了。