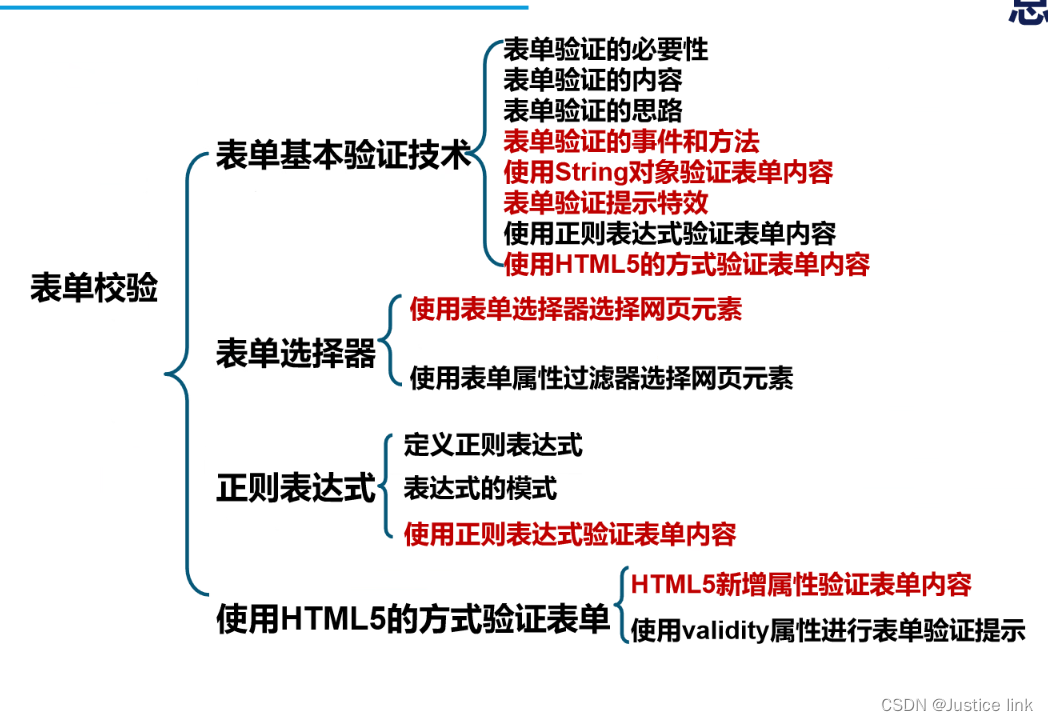
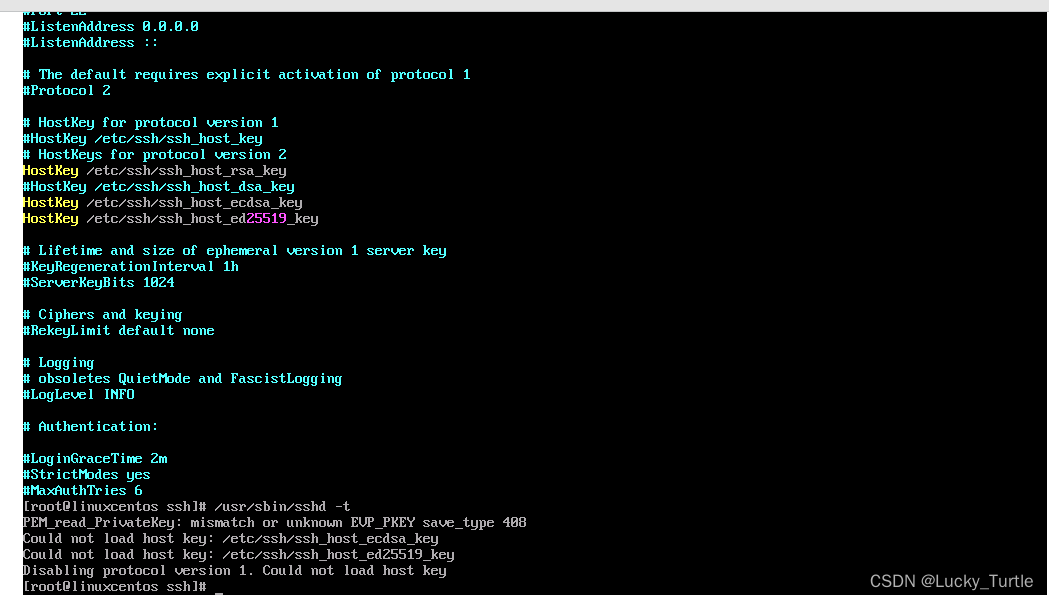
上链接:
P3370 【模板】字符串哈希 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)![]() https://www.luogu.com.cn/problem/P3370#submit上题干:
https://www.luogu.com.cn/problem/P3370#submit上题干:
就是说,给你N个字符串,然后让你判断,这N个字符串里面有多少不同的字符串(用hash做)
将这个问题简化,比如,给你10^6个数字,然后让你计算一下有多少不同的数字。
由于数据不大,所以我们可以直接用数组模拟。开一个10^6的数组,然后出现哪个数字,标记哪个数字就行了。最后再计算有多少个数字被标记了。
那如果给10^9个数字,显然我们无法开一个10^9的数组。
那我们应该怎么做呢?
我们可以对这些数字进行取模运算。
例如mod=1007,然后将每个数字取模,存入vector中,即 vector[ x%mod ][ i ],
然后每次查询,是否vector里面是否有该数字,如果没有,就push_back(),然后将答案++
但是显然,如果取模1007的话,显然是可能会有很多重复的情况,我们叫做”哈希碰撞“
如果有很多重复的话,我们就要花费额外的次数去查询,这样时间复杂度会比较高。
所以,我们尽量让每个数值的哈希值不相同。
所以我们可以设置一个base值。
拿这道题为例子
假如这个数据类型是字符串,我们就可以用字符串里面的每个字符的ascii码来求哈希值,
最笨的做法就是求每个字符串的ascii码之和作为哈希值,
这样的话,如果所有的字符串的ascii码之和都是相同的,那么时间复杂度将爆炸,很容易被hack
所以我们希望对它进行改进:
假如一个字符串为 abcdefgh。
其哈希值可以是: a+(a*base+b)+(a*base^2+b*base+c)........
这样可以使得每个字符串的哈希值都是不同的。
这样我们每次查询的次数就是1,甚至可以不需要查询。
所以,这也就是用空间换时间的典型例子。
上代码:
typedef long long int LL; const int mod = 1007; const int base = 117; vector<string> linker[mod + 2]; string s; int ans; void insert1(string s) { int hash = 0; for (int i = 0; i < s.size(); i++) { hash = (hash*1ll*base + (LL)s[i]) % mod; } for (int i = 0; i < linker[hash].size(); i++) if (linker[hash][i] == s)return; linker[hash].push_back(s); ans++; } int main() { int n; cin >> n; while (n--) { cin >> s; insert1(s); } cout << ans; }