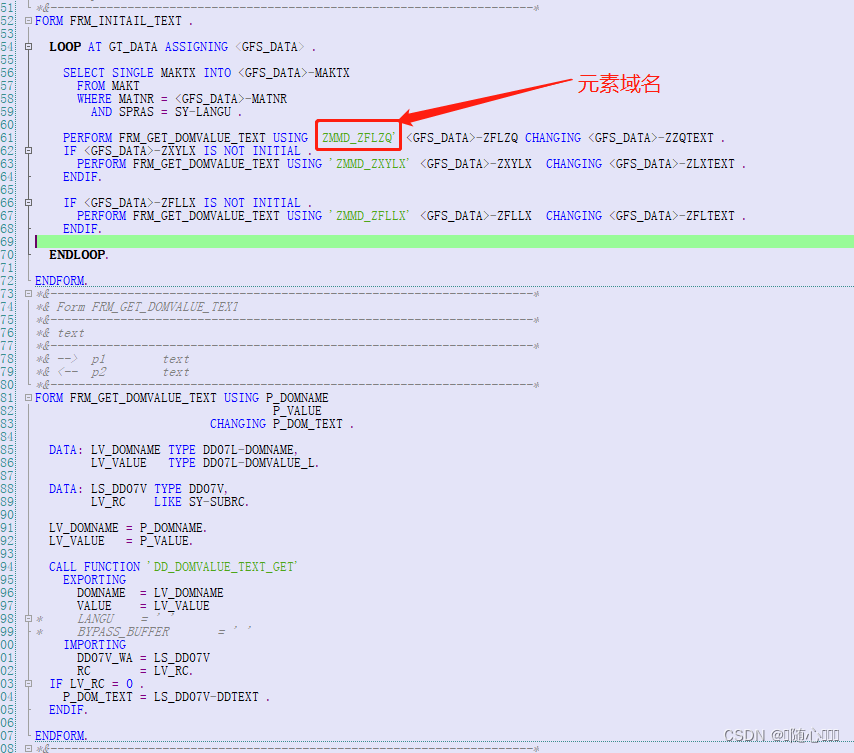
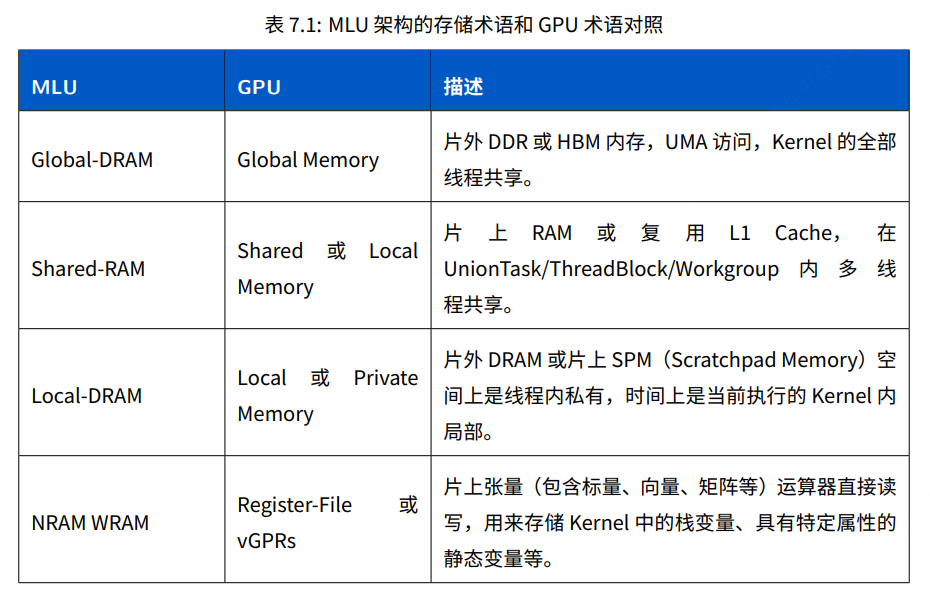
本文将探讨 issue 80 中提出的技术问题及其解决方案。该问题主要涉及如何在模型的 _encode_params 方法中处理列表作为字典值的情况。

问题背景
在处理用户提交的数据时,有时需要将字典序列化为 URL 编码字符串。在 requests 库中,这个过程通常通过 parse_qs 和 urlencode 方法实现。然而,当列表作为字典值时,现有的解决方案会遇到问题。
例如,给定字典 {'oauth': ['sig'], 'status': ['hanzi ok']},现有的解决方案可能会将其编码为 "oauth=sig&status=hanzi%20ok",而不是期望的 "oauth=sig&status=hanzi%20ok"。这是因为在 URL 编码中,列表值 [](空括号)会被视为字符串,并被编码为 "%5B%5D"。
解决方案
为了解决这个问题,我们需要在 URL 编码之前对字典值进行处理。一种可能的解决方案是使用 doseq 参数。在 Python 的 urllib.parse 中,urlencode 方法有一个 doseq 参数,如果设置为 True,则会对字典的值进行序列化,而不是将其作为一个整体编码。
以下是修改后的解决方案:
import urllib.parse
def _encode_params(params):
使用 doseq 参数序列化字典值
encoded_params = urllib.parse.urlencode(params, doseq=True)
返回序列化后的参数
return encoded_params
在上述解决方案中,我们首先导入了 urllib.parse 库,然后定义了一个名为 _encode_params 的函数。在该函数中,我们使用 urllib.parse.urlencode 方法对参数进行编码,同时设置 doseq 参数为 True。
通过这种方式,我们可以在 URL 编码中正确处理列表作为字典值的情况。
结论
本文讨论了 issue 80 中提出的技术问题,即如何在模型的 _encode_params 方法中处理列表作为字典值的情况。我们提出了一种解决方案,使用 doseq 参数对字典进行序列化,从而正确处理列表作为字典值的情况。通过这种方式,我们可以更好地处理用户提交的数据,并提供更好的用户体验。










![[Mac软件]Adobe XD(Experience Design) v57.1.12.2一个功能强大的原型设计软件](https://img-blog.csdnimg.cn/90aa798e3f794ba2a93e298844537ba1.png)