⼀个MLU 设备由 Memory ⼦系统、MTP(Multi Tensor Processor)⼦系统、Media ⼦系统等构成。MTP⼦系统是寒武纪MLU 架构的核⼼。
文章目录
- TP1 架构
- TP2 架构
- TP3
- 1⾯向不同 MLU 架构的 Cambricon BANG 编程最佳实践
- 1.1 Device 级异构调优指南
- 1.2 Cluster 级并⾏调优指南
- 1.3 Core 级并⾏调优指南
- 2 MTP 编程调优
- 2.1 并发性
- 2.1.1 TP Core 内多指令流⽔线并发
- 2.1.2 MTP Cluster 的多 Task 并发
- 2.1.3 Host 和 Device 的并发
- 2.2 同步
- 2.2.1 TP Core 内多指令流⽔线同步
- 2.2.2 MTP Cluster 的同步
- 2.2.3 Host 和 Device 的同步
- 3访问存系统
- 3.1 MLU 架构的存储层级和 Cambricon BANG 的地址空间
- 3.1.1 Global 地址空间
- 3.1.2 Shared 地址空间
- 3.1.3 Local 地址空间
- 3.1.4 Stack 地址空间
- 3.1.5 NRAM 地址空间
- 3.1.6 WRAM 地址空间
- 3.2 存储系统的吞吐和延迟
- 参考
MLU 架构具有端云⼀体可扩展性,可扩展的最⼩单位分为两种架构TP (Tensor Processor)和 MTP(Multi Tensor Processor)。TP 架构⽤来代称⼀个IPU Core 的架构,对应编程模型中只可以执⾏⼀个Block Task。MTP 架构代称多个 IPU Core 组成的 Cluster 架构,对应编程模型中执⾏⼀个 Union Block Task,简称 Union Task。
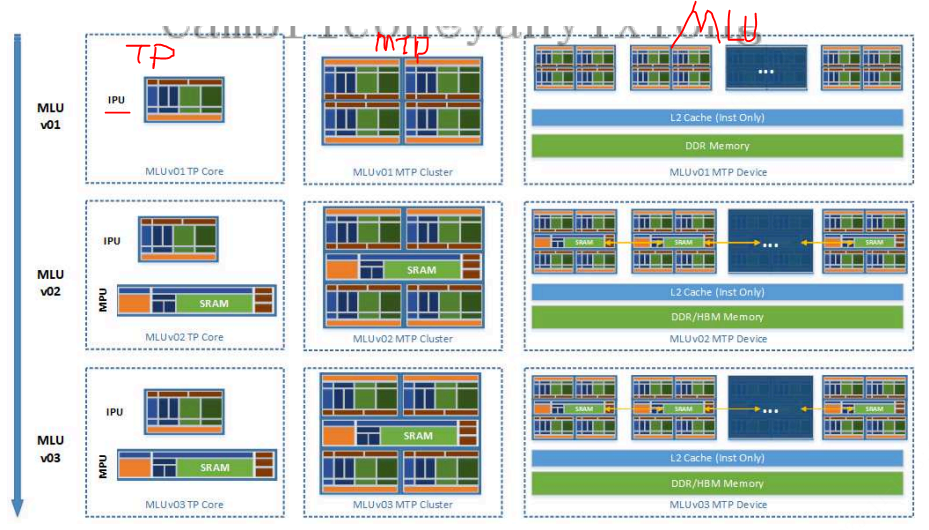
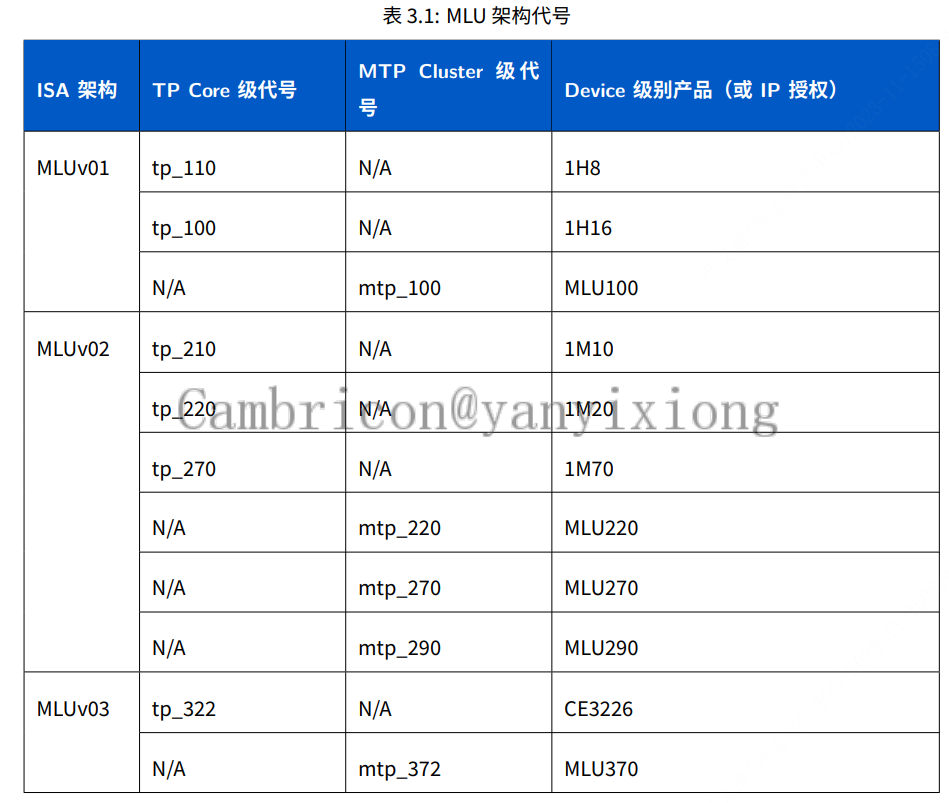
Device 级架构⼀款 MLU 加速卡芯⽚中,包含⼀个或多个 MTP Cluster,还包含 PCIE、内存控制器、L2Cache、Media处理单元、MLU-Link 等。MLU 对应的编程模型称为Cambricon BANG ,寓意寒武纪⼤爆炸,是⼀种Host-Device 的异构并⾏编程模型。
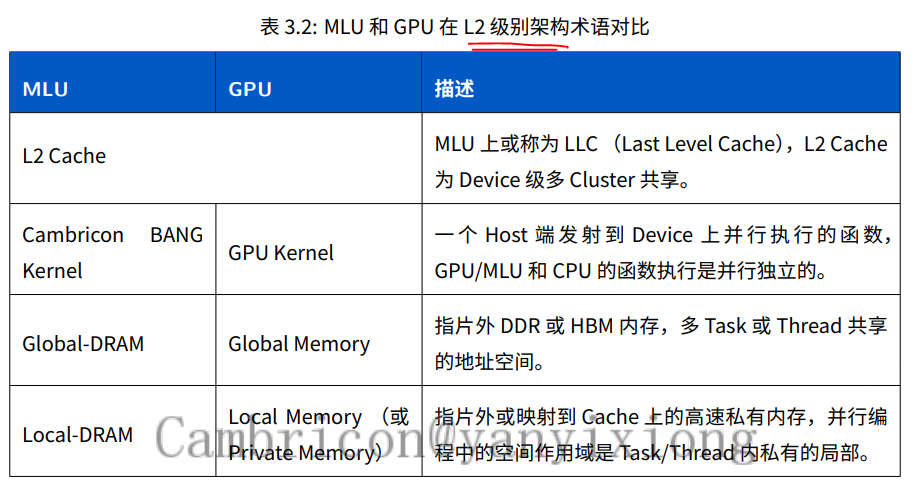
下表对⽐了 Device 级别 MLU 和 GPU 的术语,可以帮助⽤⼾理解认识MLU 和Cambricon BANG 的编程。
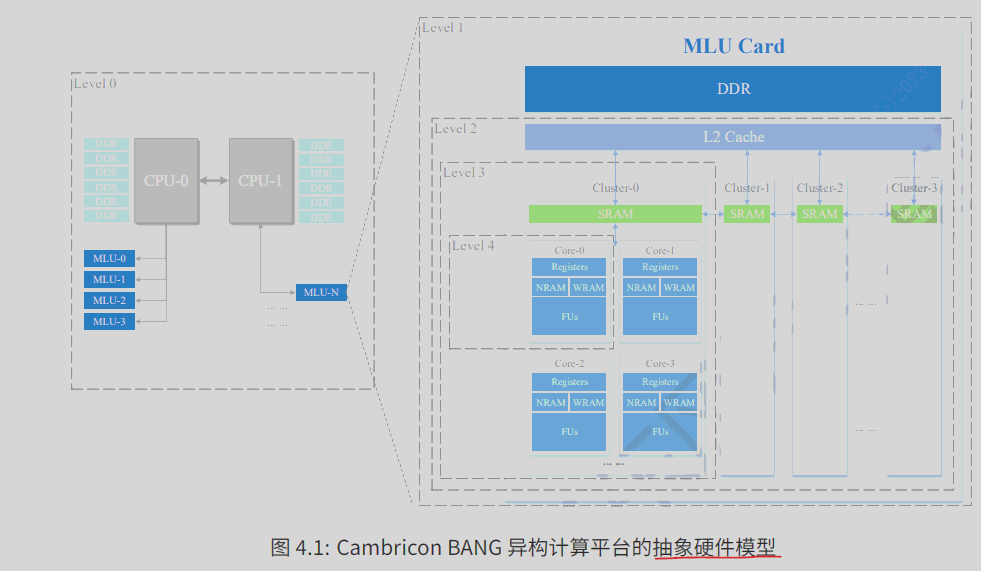
抽象硬件模型分为5层次,
- 服务器级别level0(多cpu+ddr+多mlu板卡)
- mlu 板卡 level1(mlu+ddr)
- 芯片 level2(多cluster+L2 cache)
- cluster 级level3 (多Core+SRAM),也可以说是MTP,MTP 架构代称多个 IPU Core 组成的 Cluster 架构,对应编程模型中执⾏⼀个 Union Block Task,简称 Union Task。
- core级 level4(),也可以说是TP,TP 架构⽤来代称⼀个IPU Core 的架构,对应编程模型中只可以执⾏⼀个Block Task。⼀个 TP 核⼼由负责标量运算的ALU 、负责 AI 运算的VFU/TFU 功能部件、多种负责数据搬移的DMA 单元组成。
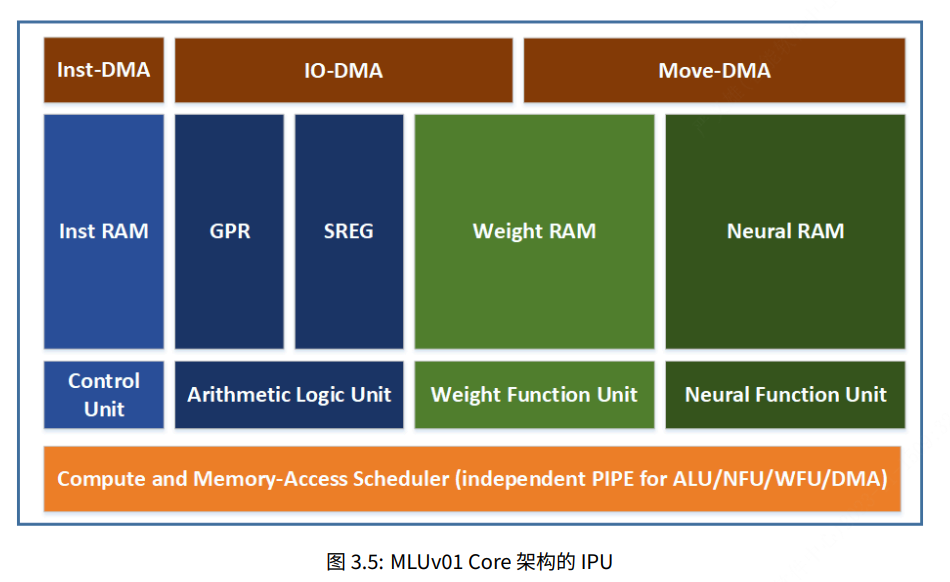
TP1 架构

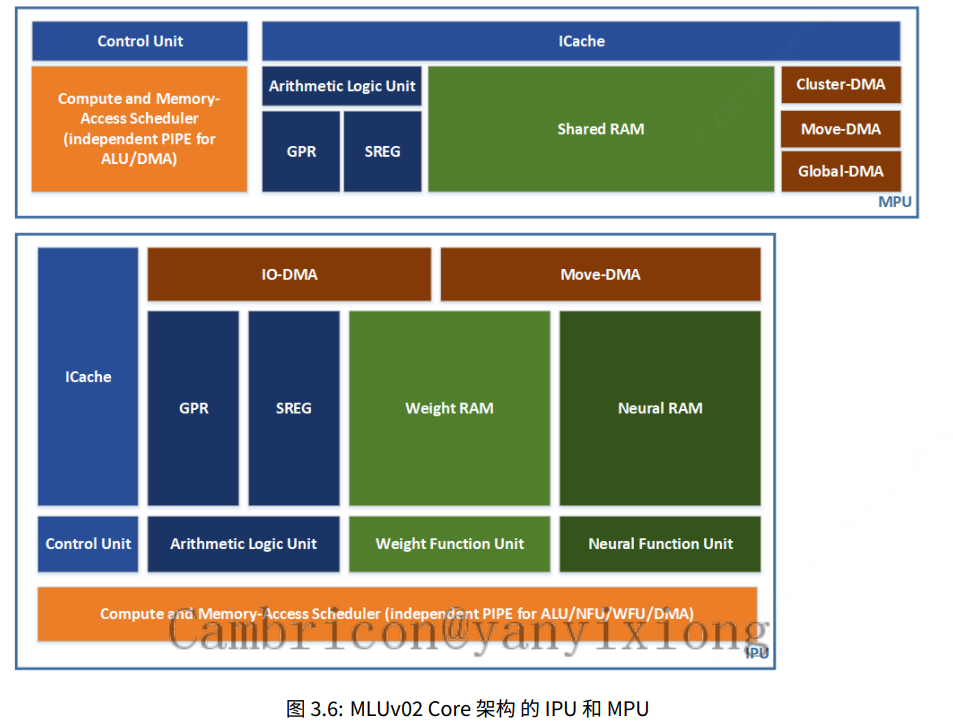
TP2 架构

TP3
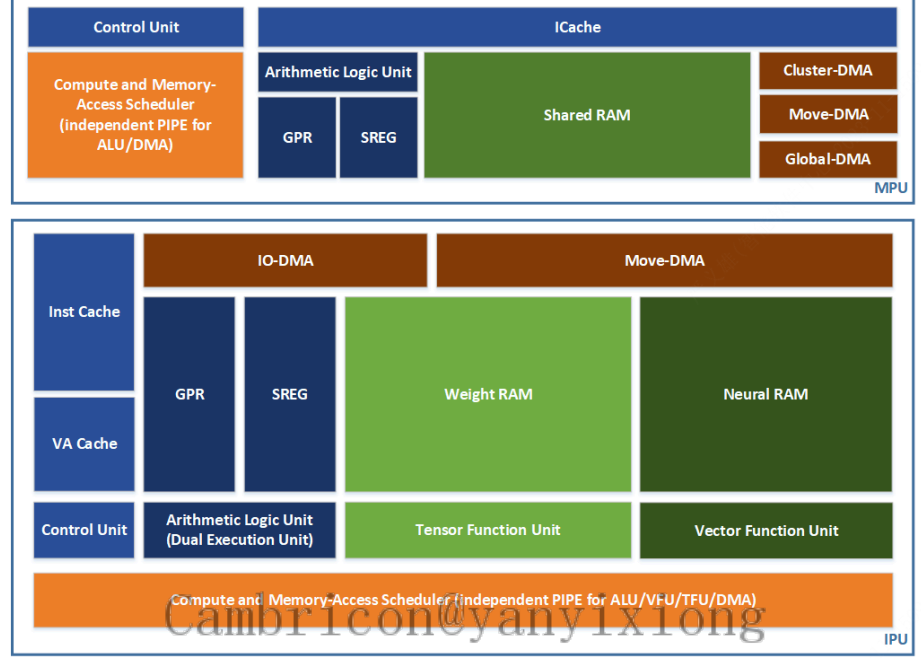

1⾯向不同 MLU 架构的 Cambricon BANG 编程最佳实践
1.1 Device 级异构调优指南
• 减少 Host 端和 Device 端直接的内存数据拷⻉。
• Device 端内存的 Malloc 有较⼤开销,建议提前申请,避免频繁申请释放。
• Kernel 函数的执⾏、异构内存的 HD/DD/DH 拷⻉是异步的,可以将有数据依赖的计算和拷⻉切⽚在 Host 和 Device 端之间做流⽔并⾏,使⽤CNPerf ⼯具的 timechart 可视化功能进⾏调优。
• 动态库或可执⾏程序在加载时,⼆进制 Module 的加载会需要较⼤峰值 Host 内存⽤来解压缩,并且在Module 卸载前会⼀直占⽤ Device 内存,所以请注意 Host、Device 端内存的分配和预留。
1.2 Cluster 级并⾏调优指南
• ⾯向⼀个较⼤的并⾏任务,⾸先按 Block (Block 包含若⼲可以并⾏的⼦任务)切分,即每个TP 负责处理⼀个任务 Block,这样的基础拆分对端侧和云侧共⽤⼀份代码最友好,因为MTP 架构⽀持运⾏ TP架构的 Block 任务。
• 如果发现多个 Block 任务可以通过共享 SRAM 或 L Cache 来提升性能(例如数据归约可以使⽤ SRAM替代 DRAM、指令相同可以命中共享 L Cache、卷积核张量数据暂存 SRAM 共⽤、离散 IO 读写可以通过 SRAM 合并等等),可以将多个 Block 任务合并为 Union 任务,Union 任务被映射到⼀个 MTP的 Cluster 上执⾏,MTP 和 Cluster 概念介绍参考Cluster 级架构 。
• Cambricon BANG 编程除了⽀持 Union 任务映射到⼀个 MTP Cluster 上并⾏执⾏,还⽀持 Union、Union 等等 的幂次⽅任务类型,使⽤多 MTP Cluster 联合执⾏,除了可以利⽤ SRAM 通讯减少DRAM 读写,还可以让更多的 TP Core 在同⼀时段内使⽤ Atomic 原⼦指令。
1.3 Core 级并⾏调优指南
• 当每个 Block 任务被切分映射到⼀个 TP Core 上执⾏后,就需要充分利⽤ IPU 的 SIMD 向量化来加速Block 任务内的并⾏计算。
• 将 Cambricon BANG 的向量化编程简单抽象为⾯向NRAM 的 Load、Compute、Store 的话,⾯向单TP Core 内的优化思路就类似 Host-Device 的切⽚异步流⽔优化,优化思路可以概括为:⾯向可编程变⻓的寄存器⽂件,使⽤异步可变⻓的访存和计算指令,合理的切分和循环让每⼀个功能部件都并⾏起来,从⽽发挥出硬件极限性能。
2 MTP 编程调优
MLUv03 架构的 MTP 为例概要介绍编程时的调优。
2.1 并发性
MLU 设备加速 AI 运算,可以归结为并⾏执⾏的并发加速和异构的异步加速两个⽅⾯,其中并发性可以从单 Core TP 内的并发、单 Cluster MTP 内的并发、多 Cluster MTP 的并发、Host 和多 Device 的并发⼏个⽅⾯来解释。
2.1.1 TP Core 内多指令流⽔线并发
TP 核⼼内具有多条独⽴执⾏的指令流⽔线(这⾥⽤ PIPE 代称),分别为负责标量运算的ALU 、负责向量运算的VFU 、矩阵/卷积或称为张量运算的TFU 、负责⽚上和⽚外数据搬移的 IO-DMA、负责⽚上数据搬移的 Move-DMA。
如下图⽰,Inst-Cache 中的⼀段指令序列顺序开始执⾏后,经过分发和调度被分配进多个 PIPE 队列,进⼊ PIPE 前指令是顺序执⾏被译码的,进⼊不同计算或访存队列后由硬件解决寄存器重命名或读写依赖。MLUv03 的 PIPE 深度为16,并且IO-DMA 和 Move-DMA 互相独⽴,所以 MLUv03⽤⼾的⽚上的访存操作和⽚外访存操作可以⽆依赖独⽴执⾏。
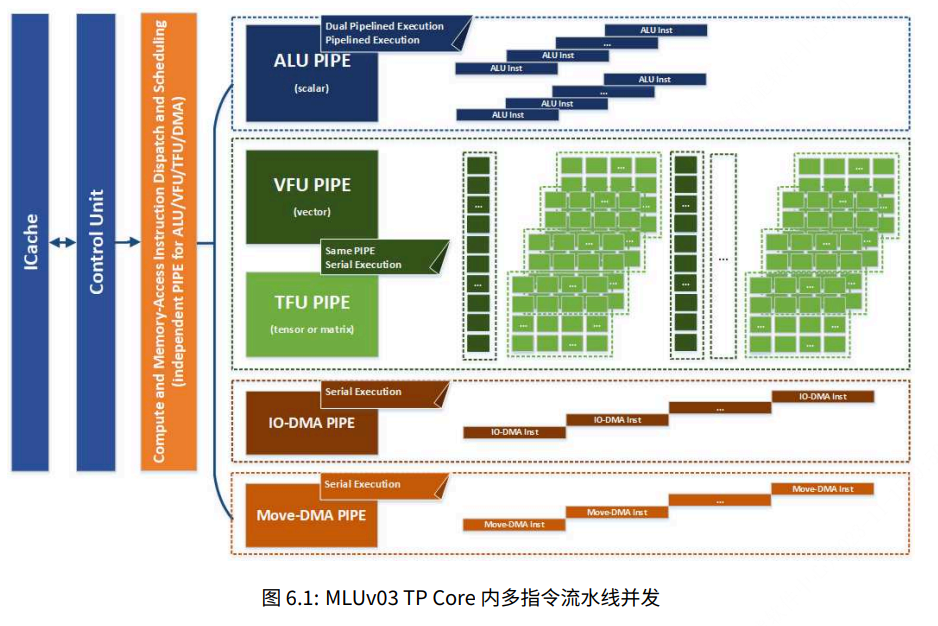
虽然 MLU 硬件和 Cambricon BANG 编程提供给⽤⼾可变⻓的计算和访存接⼝,但是在⽤⼾编程或编译器⾃由优化中,必须使⽤多级软流⽔、合理的数据块拆分循环,才可以将⽆数据依赖关系的不同流指令并⾏执⾏达到最优性能。
2.1.2 MTP Cluster 的多 Task 并发
⼀个 MTP Cluster 内由多个 IPU Core 和 ⼀个 MPU Core 组成,⽤⼾如果要启动⼀个MTP Cluster 进⾏并⾏运算,如下⽰例代码:
__mlu_global_ void foo() {}
int main() {
cnrtDev_t dev;
CNRT_CHECK(cnrtGetDeviceHandle(&dev, 0));
cnrtQueue_t queue;
CNRT_CHECK(cnrtCreateQueue(&queue));
// Value of dimX should be divisible by max IPU core count per MTP cluster.
int dimX = 0;
cnDeviceGetAttribute(&dimX, CN_DEVICE_ATTRIBUTE_MAX_CORE_COUNT_PER_CLUSTER, dev);
cnrtDim3_t dim3 = {dimX, 1, 1};
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
foo<<<dim3, ktype, queue>>>();
CHRT_CHECK(cnrtSyncQueue(queue));
CNRT_CHECK(cnrtDestroyQueue(queue));
return 0;
}
当配置 Kernel 函数以 Union1 类型展开时,这个 Union1 并⾏任务会被映射或调度到⼀个 MTP Cluster上执⾏,所以我们约束⽤⼾ X 维度必须为⼀个 MTP Cluster 内最⼤的 IPU Core 数量的整数倍。
下图给出两个多维 Kernel 函数并⾏展开映射到硬件 MTP Cluster 执⾏的⽰意,如果使⽤整个 MTP Device 时都使⽤相同任务类型例如都是 Union1 类型的任务,那么整个设备的利⽤率会较⾼,因为硬件调度器看到的并⾏粒度统⼀,不会出现 Union2 等待 2 个 MTP Cluster 的情况。
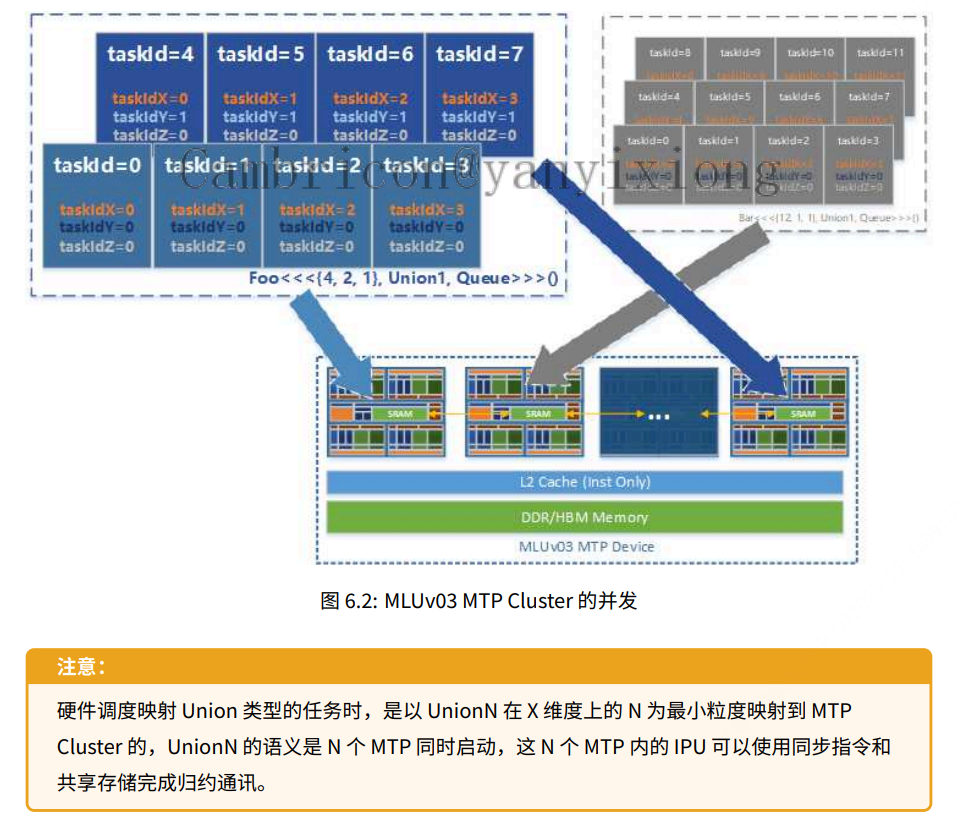
举例说明,如果是 foo<<<{16, 2, 1}, Union2, Queue>>>() 的任务:
当有 8 个 MTP Cluster 空闲,这个 Kernel 函数就可以同时执⾏在 8个 MTP Cluster 上,每 2 个 MTP Cluster 处理⼀个 Union2 的任务。
• 当只有 2 个 MTP Cluster 空闲时,会时分复⽤执⾏ 4 轮 Union2的任务。
• 当只有 1 个 MTP Cluster 空闲时,持续等待有 2 个 MTP Cluster。
• 当硬件型号只有 1 个 MTP Cluster 时,运⾏报错不⽀持。
2.1.3 Host 和 Device 的并发
从 Cambricon BANG 2 开始,⽤⼾可以使⽤ foo<<<…>>>() 完成异步的 Kernel 计算,还可以使⽤ CNRT 或 CNDrv 的异步 Memcpy 实现 HD/DD/DH 的传输.
如上⼀⼩结所述,MLU Device 会根据下发的任务类型调度执⾏⼀个 Block 或 UnionN,那么在 Host 和 Device 之间就有⼀个任务队列,不同硬件⽀持的队列最⼤深度是不⼀样的,⽤⼾可以使⽤ cnDeviceGetAttribute() 接⼝和CN_DEVICE_ATTRIBUTE_MAX_QUEUE_COUNT 来获取。
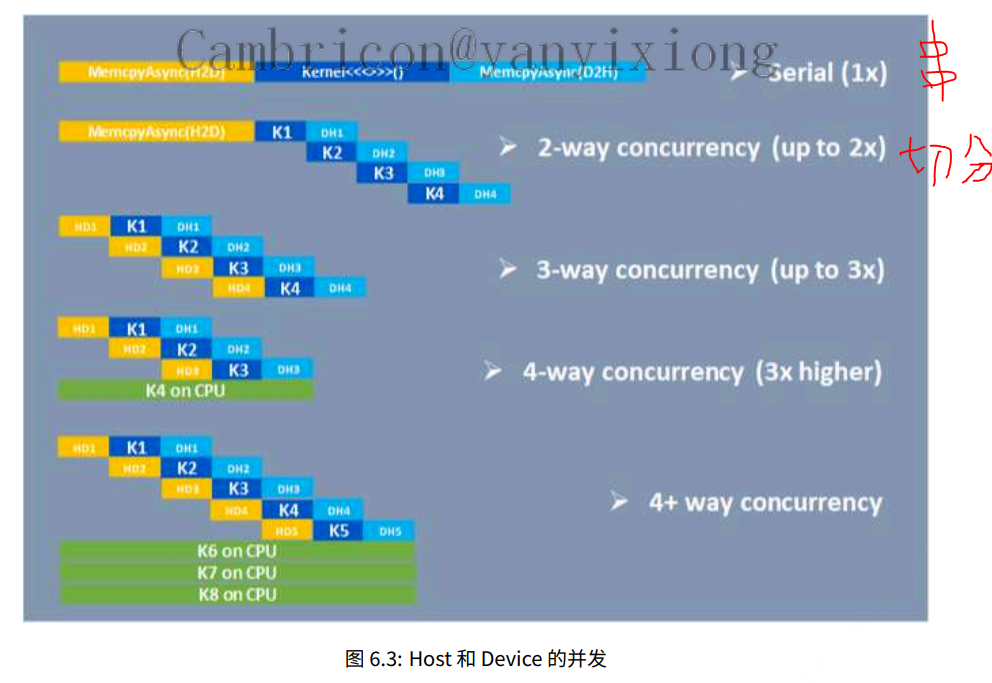
基于 MLU 硬件的编程模型特点可以概括为异构和并⾏,除了前⾯所讲的 TP Core 内部的流⽔线并⾏,MTP Cluster 的并⾏,对系统级性能影响较⼤的还有异构的并⾏,可以类⽐为 Host 和 Device 都为计算节点,之间存在⼀个异步的同步机制,⽤⼾若要发挥整体系统最⼤性能,就需要按下图所⽰,对较⼤的任务进⾏切分流⽔。
2.2 同步
MLU 架构的并⾏或并发如前⾯所述可以分为 TP Core 、MTP Cluster、Host + Device 这三个级别,并发对应的同步我们也从这三个级别描述。
2.2.1 TP Core 内多指令流⽔线同步
如TP Core 内多指令流⽔线并发 章节所述,TP Core 内的多个 PIPE 可以异步并⾏执⾏,我们将不同 PIPE 的运算或者访存抽象为读和写的话,即可建⽴依赖关系,如下图蓝⾊连线 A/B/C/D/E/F:
 (A) 是 ALU-PIPE 内对 GPR 的读写依赖,⽤⼾⽆需管理同步,编译器⽆需管理同步,硬件基于寄存器重命名解决依赖。
(A) 是 ALU-PIPE 内对 GPR 的读写依赖,⽤⼾⽆需管理同步,编译器⽆需管理同步,硬件基于寄存器重命名解决依赖。
• (B) 是 IO-PIPE 访存指令 ld.async 需要读取 GPR 作为地址操作数,GPR 中的值来源于 ALU-PIPE 的写,这种依赖由硬件解决。
• © 是 IO-PIPE 的两条 ld.async 指令为 VFU/TFU-PIPE 的 conv 指令准备运算的卷积输⼊张量和卷积核张量数据,此时是基于 NRAM 和 WRAM 的读写依赖,需要⽤⼾使⽤ sync 指令保证依赖,或使⽤⽆async 修饰的 ld 指令。
• (D) 是 VFU/TFU-PIPE 的 conv 运算结果需要⽤ IO-PIPE 的 st.async 写出到⽚外内存,需要⽤⼾使⽤sync 指令保证依赖,或使⽤不带 async 修饰的 st 指令。
• (E) 是 Move-PIPE 可以和 VFU/TFU-PIPE 并发执⾏时的访存操作,即在 conv 运算的同时 ld.async 为下⼀条 conv 运算准备卷积输⼊张量数据,下⼀条 conv 执⾏前需要有 sync 保证依赖。
• (F) 是 IO-PIPE 需要将 VFU/TFU-PIPE 的 conv 结果写出⽚外存储,也需要⽤⼾使⽤ sync 来保证依赖。
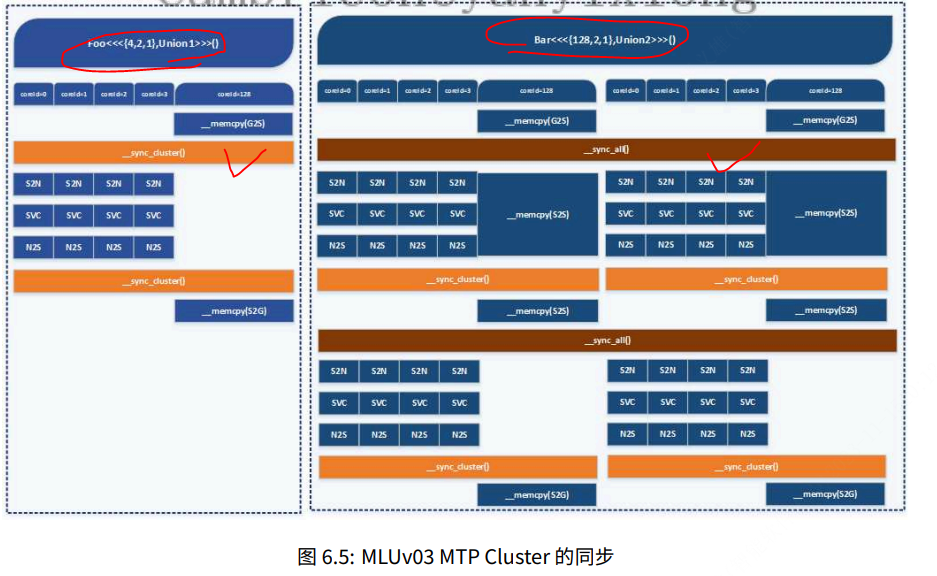
2.2.2 MTP Cluster 的同步
⼀个 TP Core 内的多流⽔线同步更多地由硬件和编译器来保证,但多核或多线程的同步必须由⽤⼾来控制,Cambricon BANG C 的 Builtin 函数提供了两种粒度的同步⽅法,
• __sync_cluster() 负责同步⼀个物理概念的 Cluster,⽆论⽤⼾启动 Kernel 函数时配置的是 Union1还是 Union2等类型,__sync_cluster() 的作⽤域仅限制在 MTP Cluster 内部的 4 个 IPU 和 1 个 MPU,对应的指令伪代码是 barrier.sync.local ID, (%coreDim + 1)
• __sync_all() 负责同步⼀个软件概念的 Union Block Task 的全部 Block Task,⽆论⽤⼾启动的是Union1、Union2、Union3、UnionX 等联合任务,此函数会同步 UnionX 映射到的全部 X 个 Cluster,对应的指令伪代码是 barrier.sync.global ID, (%coreDim + 1) * %clusterDi
2.2.3 Host 和 Device 的同步
CNToolkit 中的 CNDrv 提供了异步和同步的 Memcpy/Memset 访存接⼝,异步的 InvokeKernel 计算接⼝,还提供了⾯向 Queue/Context 级别的同步接⼝。
同步 Memcpy 类接⼝的语义为:
• Memcpy 类接⼝与 Context 的 Default Queue ⽆关,执⾏⼀个 Memcpy 操作,不会在 Default Queue 上下发拷⻉任务,在拷⻉完成后,也不会隐式的对 Default Queue 调⽤ QueueSync 类接⼝。简⾔之就是,同步的内存拷⻉,不会对 Default Queue 有任何影响。
• 同步拷⻉接⼝,在接⼝返回时,就已经完成了拷⻉操作,不论该内存是如何申请的或来⾃于 Host 还是Device,但 P2P 除外。
异步 MemcpyAsync 类接⼝的语义为:
• 异步拷⻉接⼝⽬前不⽀持进⾏ Host 内存到 Host 内存的拷⻉。不论这个内存是 C 库的 malloc 还是CNDrv 库的 cnMallocHost 申请的。
• 异步拷⻉接⼝⽬前都是完全异步的,当接⼝返回时,拷⻉还未开始或完成,⽤⼾需要调⽤ Sync 接⼝确认拷⻉完成。
• 异步拷⻉操作的内存提前释放都是⻛险极⾼的,⽆法保证在异步拷动作正常完成,即使正常完成也⽆法保证数据的正确性。
• 异步拷⻉操作的内存在调⽤ Sync 类接⼝之前,如果 Host 对其进⾏写操作,也⽆法保证最终拷⻉数据的正确性。
• 不论是如何申请的 Host 内存,不论是进⾏异步的 H2D 或 D2H 拷⻉时,在拷⻉完成前,⽤⼾不能提前释放该内存,否则有可能导致拷⻉失败或结果不正确。
• 通过 cnMallocHost 申请的内存,当⽤⼾调⽤ cnFreeHost 时,如果该内存还有未完成的异步拷⻉任务,CNDrv 不会阻塞⽤⼾调⽤的返回。
异步 MemsetAsync 类接⼝的语义为:
• 异步内存写接⼝⽬前都是完全异步的,当接⼝返回时,写还未开始或完成,⽤⼾需要调⽤ Sync 接⼝确认写内存完成。异步 cnInvokeKernel() 接⼝或 foo<<<>>>() 语法糖函数调⽤的语义为:
• 对于 Host 端,启动⼀个 Kernel 函数是完全异步的,当接⼝或函数返回时,Kernel 函数的执⾏还未开始或完成,⽤⼾需要调⽤ Sync 接⼝确认完成。
3访问存系统
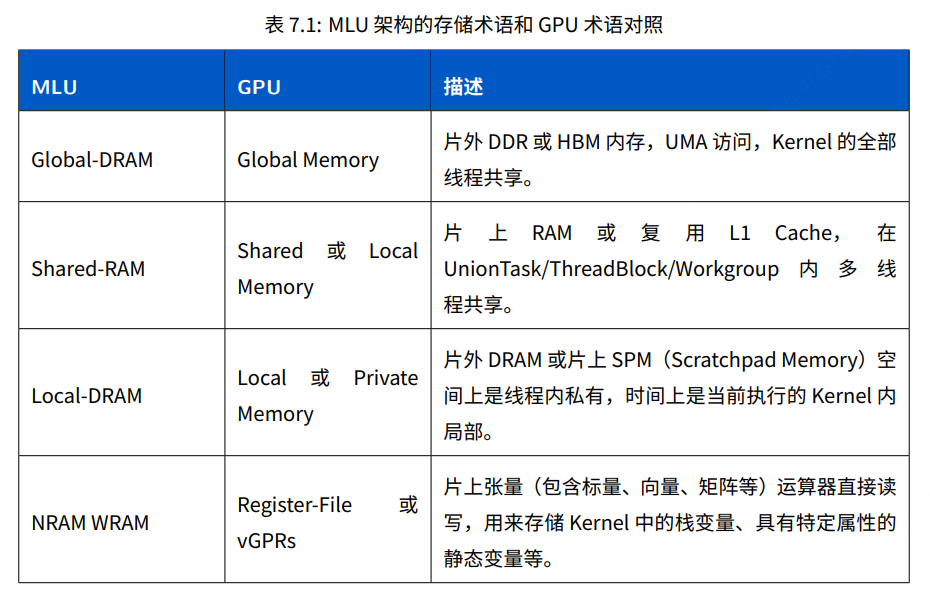
3.1 MLU 架构的存储层级和 Cambricon BANG 的地址空间
冯.诺伊曼结构,也称普林斯顿结构,是一种将程序指令存储器和数据存储器合并在一起的电脑设计概念结构。
MLU 架构的存储架构属于冯诺依曼架构,存储层次的特点是具有较⼤的⽚上SPM (Scratchpad Memory)空间,我们称为 NRAM 和 WRAM,它们直接和负责 AI 运算的VFU 和TFU 相连,可以最⼤化得利⽤空间和时间局部性,在NRAM 和WRAM 上完成更多的 AI 运算,减少和 DDR/HBM 内存之间的数据搬移,从⽽极⼤的提升性能并降低功耗。
3.1.1 Global 地址空间
全局地址空间的空间作⽤域在虚拟化后或⾮虚拟化后的⼀个 Device 内,即⼀个 Device 的所有 MTP 运算单元和其他 Media 编解码单元全局共享可⻅,从时间作⽤域上讲,任何 Kernel 函数或 Media API 都可以任意时刻读写相同的 Global-DRAM 的指针。
在 Cambricon BANG C 中 mlu_global 修饰的变量或数据结构即属于 Global-DRAM,语义具有以下
⼏个特点:
• 静态全局,不⽀持动态数组动态申请等形式,由编译器确定⼤⼩。
• 空间作⽤域,在⼀个 Context 中所有 Queue 可以共享,即⼀个 Module 被装载后,其中的全局变量在Context 中唯⼀,多个 Queue 中的 Kernel/Memcpy/Memset 都可以共享读写。
• 时间作⽤域,可以跨 Kernel 函数作为全局变量传递数据,这些 Kernel 函数可以是被映射到不同 MTPCluster 上并发执⾏的也可以是按时间顺序执⾏的。
在 Cambricon BANG C 中 mlu_const 修饰的变量或数据结构也属于 Global-DRAM,语义和__mlu_global__ 的不同之处在于是只读属性,这⾥的只读是 Device 端的 Kernel 只读,但 Host 端发起的 Memcpy/Memset 依然是可读可写的。
3.1.2 Shared 地址空间
在 Cambricon BANG C 中 mlu_shared 修饰的变量或数据结构属于 Shared-DRAM,这⾥相⽐ GPU的 shared 容易混淆的是空间上的共享作⽤域,Cambricon BANG 编程中⾸先要区分 TP 架构的单核编程和 MTP 架构的多核编程,在 TP 架构编程中是不可以使⽤ mlu_shared 属性的。在 MTP 架构编程中,容易混淆的是 UnionX 任务的 Kernel 执⾏中,由于 X 不同,所以 __mlu_shared__的空间共享作⽤域是什么?当前 Cambricon BANG 3 中,⽆论⽤⼾启动的是 Union1、Union2、Union4、Union8 等任意 UnionX,mlu_shared 修饰的变量只能在 MTP Cluster 内部的多个 Core共享。举例当⽤⼾启动 Union 的 Kernel 函数时,mlu_shared 修饰的变量在 Union4 映射执⾏的 个 MTP Cluster 上会有 4 份独⽴的实体,如果⽤⼾期望⼀个 Union Block Task 中不同 Cluster 上的Shared-RAM 上的读写逻辑有区分,就需要在 Union Kernel 内部使⽤ clusterId 变量来做控制流区分。
3.1.3 Local 地址空间
MLUv1 和 MLUv2 硬件架构是 NUMA 访存模型,Cambricon BANG 为⽤⼾抽象了 Local-DRAM 的地址空间,即在 MLUv1/MLUv2 硬件上 Local-DRAM 的虚拟地址空间是映射到距离 MTP Cluster 最近的DDR 通道上,性能相⽐ Global-DRAM 具有 0-20% 的提升。在 MLUv3 硬件架构上,硬件访存模型是UMA 的,即 Local-DRAM 和 Global-DRAM 的性能基本⼀致。
Local-DRAM 在 Cambricon BANG 的编程模型中应⽤场景较少,在 MLUv1 架构的 CNML、CNPlugin编程中较为有⽤,因为 MLUv1 架构和 CNML 都是 NUMA 访存模型。
3.1.4 Stack 地址空间
每个 Task (GPU 称为 Thread)的私有栈空间会⽤到 Local-DRAM,但在 Cambricon BANG 编程中 CNCC 默认将栈空间映射到了 NRAM 上从⽽⼤⼤降低了访存延迟,如需关闭可以使⽤ cncc–bang-stack-on-ldram 编译选项。
Cambricon BANG 编程中⽤⼾的 Kernel 函数输⼊输出地址空间必须为 Global-DRAM,所以 Kernel 内的运算主逻辑是 Load G2N Compute NRAM Store N2G ,利⽤ Thread-Local 属性的 ldram 的场景就相对较少,如果需要 Thread-Local 属性临时变量时更推荐⽤⼾直接使⽤栈变量,因为如上⼀条所说 CNCC默认将栈映射到了 NRAM 地址空间性能远优于 Local-DRAM。
3.1.5 NRAM 地址空间
NRAM 是每个 TP Core 中独⽴的寄存器⽂件,在 Cambricon BANG 编程模型中是静态全局属性,虽然栈变量也默认映射到 NRAM 上,但 NRAM 是⽤⼾显式管理和编程的,⽽栈变量是由编译器管理的。
// file name foo.mlu
#include <bang.h>
__nram__ int ArrayC[128];
__mlu_global__ void KernelA(int *ptrA) {
__nram__ int ArrayA[128];
__memcpy(ptrA, ArrayA, 128, NRAM2GDRAM);
#if 0
__memcpy(ptrA, ArrayB, 128, NRAM2GDRAM); // error: use of undeclared identifier 'ArrayB'
#endif
__memcpy(ptrA, ArrayC, 128, NRAM2GDRAM);
}
__mlu_global__ void KernelB(int *ptrB) {
__nram__ int ArrayB[128];
__memcpy(ptrB, ArrayB, 128, NRAM2GDRAM);
#if 0
__memcpy(ptrB, ArrayA, 128, NRAM2GDRAM); // error: use of undeclared identifier 'ArrayA'
#endif
__memcpy(ptrB, ArrayC, 128, NRAM2GDRAM);
}
NRAM 的静态全局属性含义有如下需要注意的特点,我们以上⾯这份源码作为⽰例:
• 在如下⼀份源码⽂件中,Kernel 内部声明的 ArrayA 和 ArraryB 仅 Kernel 内可⻅,即 KernelA 不可以使⽤ ArrayB。
• 如上⾯代码所⽰,在 Kernel 函数外部声明的 ArrayC,可以被 KernelA 和 KernelB 使⽤,但不能共享,是 C 语⾔中的 static 静态全局属性的。
• 需要查看源码编译后各种存储的占⽤空间时,使⽤如下命令⾏
$ cncc --bang-mlu-arch=mtp_372 foo.mlu -c --bang-device-only -S -O1
$ cnas -i foo-bang-mlisa-cambricon-bang-mtp_372.s --verbose
*************************************************************
region name: _Z7KernelAPi
SpillInfo Total CachedRegister Stack
GPR 0 0 0
*************************************************************
*************************************************************
region name: _Z7KernelBPi
SpillInfo Total CachedRegister Stack
GPR 0 0 0
*************************************************************
Memory Space Used(bytes) Avail(bytes) Total(bytes) Used details(bytes)
NRAM 3712 782720 786432 User:1536, Stack:192,␣
֒→Padding:0, Reserved:1984
WRAM 0 1048576 1048576 User:0
SRAM 448 4193856 4194304 User:0, Stack:192,␣
֒→Reserved:256
LDRAM 0 268435456 268435456 User:0, Stack:0
GDRAM 0 - - User:0
3.1.6 WRAM 地址空间
WRAM 对应的 Cambricon BANG C 属性 wram 在语法作⽤域和使⽤约束上和 nram 基本相同,
需要特别关注的是对⻬约束,在不同 MLU v/v/v 版本上,Cambricon BANG ././. 对应的
对⻬约束检查有所不同,总体上对⻬约束是在变弱,⽤⼾可以按更⼩的对⻬粒度使⽤ WRAM。
3.2 存储系统的吞吐和延迟
MLU v1/v2/v3 不同架构芯⽚的内存控制器和带宽规格都持续提升,详细的硬件规格参数⽐如MLUv3 架构的请参考《寒武纪 MLUv3 架构⽩⽪书》。不同芯⽚架构的延迟和带宽规格略有不同,⼀般芯⽚越⼤(可以理解为 MTP Cluster 数量越多),UMA 访存模型中延迟越⾼,但芯⽚设计时是遵循阿姆达尔定律,提供合理的算⼒和带宽配⽐的。
Cambricon BANG 编程⽤⼾调优时可以简化理解为合理的异步流⽔切⽚,既可以让带宽掩盖访存延迟,从⽽实现最⼤吞吐。对于⽤⼾直接使⽤的 Cambricon BANG 异构并⾏编程模型,需要从异构和并⾏(可以理解为 Device/Cluster/Core 各个级别的并发)两个⻆度关注吞吐的性能:
异构并发的吞吐:
• 提升吞吐⾸先要提⾼ Device 的利⽤率,Host 端作为异构计算的发起者,需要充分利⽤ Host-Device直接的访存和 Kernel 执⾏的异步性,尽量多的异步下发异步任务到 Queue 中,才可以保证 Device 处于忙碌状态,例如 Host 端单线程⽆法将 Queue 填满,就需要启⽤多线程将更多的异构计算任务下发到⼀个 Queue 中。
• Host-Device 之间的 Queue 分为两个层次,⽤⼾通过 cnCreateQueue 感知的是软件 Queue,最⼤深度通过 CN_DEVICE_ATTRIBUTE_MAX_QUEUE_COUNT 属性获取,如果异步下发的访存或计算任务单个耗时较⼩,就需要在单位时间内下发较多的任务才能将 Device 的所有 MTP Cluster 利⽤率打满;⽤⼾感知不明显的是硬件 Queue,即硬件 Job Scheduler 单元⾃动处理调度的队列最⼤深度,硬件 Queue中可以同时容纳不同软件 Queue 内的任务,如果⼀个软件 Queue ⽆法将硬件 Queue 打满,可以尝试多个软件 Queue 同时下发任务。
• Host-Device 之 间 的 访 存 最 ⼤ 吞 吐 由 硬 件 的 PCIE 带 宽 决 定, 通过 CN_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH 属性获取,当某款芯⽚或板卡型号的带宽较⼩时,我们可以将 H2D/D2H 的数据块切的更⼩充分利⽤异步拷⻉特点来提升吞吐,这个原理如Host和 Device 的并发 中图所⽰,带宽瓶颈时异步流⽔切的数据块越⼩越能减少计算等待访存的时间,从⽽提升吞吐。
MTP Cluster 并发的吞吐:
• MTP Cluster 内的所有 IPU/MPU 只能访问 Device 端内存,Device-Only 视⻆讨论访存吞吐和延迟的主体除了 Kernel 外,还有 cnMemcpyDtoD 类的CNDrv 接⼝。
• 逻辑上 Kernel 可以配置多维 Block Task 或 Union Block Task 并⾏执⾏,只有启动 Union 类型的Kernel 时,才能保证同⼀时段内所有 IPU/MPU 同时执⾏相同 IO-DMA 指令访问 Global-DRAM,Block类型的 Kernel 之间⽆法同步所以 IO-DMA 访问是互相独⽴的。
• 同⼀时刻物理上可以并发的 CN_DEVICE_ATTRIBUTE_MAX_CLUSTER_COUNT 个 Cluster 如果同时访问Global-DRAM,是会相互竞争 DDR/HBM 的带宽的,如果我们启动的是 Union 类型的 Kernel,我们就可以在 IO-DMA 操作前后插⼊ __bang_lock() 和 __bang_unlock() Builtin 函数,从⽽减少不同 IPU发起的 IO-DMA 在 DDR/HBM 的总出⼝处的竞争,提升⼀定的访存性能。
• 当启动 Union 类型的 Kernel 时,由于所有 IPU/MPU 在同⼀时间段在 L2 Cache 上共享同⼀份指令,所以相⽐ Block 类型的 Kernel 在取指性能上有⼀定优势,由于 MLU 架构属于CISC 架构单条指令体积较⼤,⽽且当 L2 Cache 发⽣ Inst-Miss 时流⽔线会等待,某些极端情况对性能的影响是很可观的,所以建议⽤⼾按 SIMT ⽽不是 MIMP 的并⾏编程模型开发 Kernel,即让所有 Task 执⾏相同的控制流逻辑。
TP Core 并发的吞吐:
• 当启动 Union Block Task 的 Kernel 时,Cluster 内的多个 TP Core 才可以使⽤ Shared-RAM,此时可以利⽤⽚上共享存储 Shared-RAM 进⾏通讯或归约。
• Union Block Task 内建议使⽤ MPU 负责 Global-DRAM 和 Shared-RAM 之间的通讯,然后多个 TPCore 的 NRAM/WRAM 和 Shared-RAM 通讯,⼀⽅⾯可以减少多个 TP Core 并发访问 Global-DRAM 竞争带宽,另⼀⽅⾯可以充分利⽤⽚上更⼤的带宽和更低的延迟。
• MLU 架构的各级存储直接的访问都是 DMA 的,⽽且负责⽚上和⽚外的 IO-DMA、⽚上和⽚上的Move-DMA 可以并⾏⼯作,所以 Cambricon BANG C 程序中可以使⽤ __memcpy_async() 接⼝让更多的 DMA 单元并⾏起来提升吞吐。
TP 内 PIPE 并发的吞吐:
• 单个 TP Core 内提升吞吐的⽅法就是对数据进⾏合理切⽚,并通过循环内计算和访存的异步,将各种PIPE 打满,从⽽提升吞吐。
• 每个 TP Core 内的 NRAM 和 WRAM 都较⼤,可以充分利⽤数据局部性,将卷积核张量尽量驻留在WRAM 上,或充分利⽤时间局部性将中间结果驻留在 NRAM 上,充分利⽤⽚上 Move-DMA 的带宽和低延迟来提升吞吐。
参考
Cambricon-MLU-Architecture-Tuning-Guide-CN-v0.4.1-2.pdf

![[C/C++]数据结构 链表OJ题:随机链表的复制](https://img-blog.csdnimg.cn/65a0d7676f2c4c86ad0991077ddd5e68.png)