目录
一、JDK的安装
1、安装jdk
2、配置Java环境变量
3、加载环境变量
4、进行校验
二、hadoop的集群搭建
1、hadoop的下载安装
2、配置文件设置
2.1. 配置 hadoop-env.sh
2.2. 配置 core-site.xml
2.3. 配置hdfs-site.xml
2.4. 配置 yarn-site.xml
2.5. 配置 mapred-site.xml
2.6. 配置 workers(伪分布式不配置)
2.7 配置sbin下启停命令
3、复制hadoop到其他节点(伪分布式不执行此步)
4、Hdfs格式化
5、启动hdfs分布式文件系统
三、msyql安装
1、卸载旧MySQL文件
2、下载mysql安装包
3、配置环境变量
4、删除用户组
5、创建用户和组
6、创建文件夹
7、更改权限
8、初始化
9、记住初始密码
10、配置文件
11 将mysql加入到服务中
12、设置开机启动并查看进程
13、 创建软连接
14、授权修改密码
四、HIve安装
1、下载安装
2、配置环境变量
3、配置文件
4、拷贝jar包
5、初始化
6、启动hive
一、JDK的安装
1、安装jdk
sudo yum search openjdk
yum install java-1.8.0-openjdk.x86_64
yum install java-1.8.0-openjdk-devel.x86_64
2、配置Java环境变量
vi ~/.bash_profile
export JAVA_HOME=/usr/local/jdk1.8.0_11
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
3、加载环境变量
source ~/.bash_profile
验证环境变量是否生效:
env | grep HOME
env | grep PATH
4、进行校验

二、hadoop的集群搭建
1、hadoop的下载安装
1.1. 下载
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/
下载 hadoop-3.3.4.tar.gz 安装包1.2 上传
使用xshell上传到指定安装路径此处是安装路径是 /usr/local
1.3 解压重命名
tar -xzvf hadoop-3.3.4.tar.gz
mv hadoop-3.3.4 hadoop
1.4 配置环境变量
vi ~/.bash_profile
export JAVA_HOME=/usr/local/jdk1.8.0_11
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
1.5 加载环境变量
source ~/.bash_profile
验证环境变量是否生效:
env | grep HOME
env | grep PATH
1.6检验安装
hadoop version
出现下图说明安装成功




2、配置文件设置
2.1. 配置 hadoop-env.sh
hadoop伪分布式配置
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export JAVA_HOME=/usr/local/jdk1.8.0_11hadoop集群配置(root指的是用户名)
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export JAVA_HOME=/usr/local/jdk1.8.0_11export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
2.2. 配置 core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 默认 9000端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
<description>配置NameNode的URL</description>
</property><!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data</value>
</property>分布式集群配置下面内容,伪分布式只需配置上面内容
<!--配置所有节点的root用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property><!--配置root用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property><!--配置root用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>
2.3. 配置hdfs-site.xml
以下配置集群和伪分布式均可用
<configuration>
<!-- 数据的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value> <!-- 伪分布式此时为1->
</property>
<!-- nn web端访问地址 默认也是9870-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop001:9870</value>
</property><!--设置权限为false-->
<property>
<name>dfs.permissions.enabled </name>
<value>false</value>
</property><!--设置元数据存储目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoopdata/dfs/data</value>
</property>集群配置使用
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop003:9868</value>
</property>
<!-- 2nn web端访问地址 可以不配置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property></configuration>
2.4. 配置 yarn-site.xml
<configuration>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>伪分布式以下无需配置
<!-- Site specific YARN configuration properties -->
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop002</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<!-- 关闭yarn内存检查 flink on hadoop 配置-->
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property><!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
2.5. 配置 mapred-site.xml
<configuration>
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>以下配置为集群配置使用
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property><!-- 历史服务器端地址伪分布式和集群分布式都可以不配置 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop003:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop003:19888</value>
</property>
</configuration>
2.6. 配置 workers(伪分布式不配置)
配置三台主机名,在集群中使用。如果不是集群可以不用配置
hadoop102
hadoop103
hadoop104
2.7 配置sbin下启停命令
在 sbin下的start-dfs.sh和stop-dfs.sh中顶部配置
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在 sbin下的start-yarn.sh和stop-yarn.sh中顶部配置
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3、复制hadoop到其他节点(伪分布式不执行此步)
scp /usr/local/hadoop root@hadoop002:/usr/local/
4、Hdfs格式化
cd /usr/local/hadoop/
bin/hdfs namenode -format
find /usr/local/data/hadoop/
5、启动hdfs分布式文件系统
cd /usr/local/hadoop
./sbin/start-dfs.sh
使用 jps 查看启动进程
访问hadoop分布式文件系统


6、启动yarn
cd /usr/local/hadoop
./sbin/start-yarn.sh
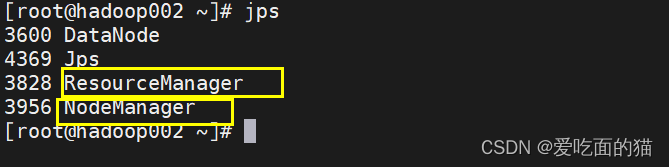
使用 jps 查看启动进程
访问hadoop分布式yarn页面

三、msyql安装
1、卸载旧MySQL文件
执行命令
# yum remove mysql mysql-server mysql-lib mysql-server
•再查看当前安装mysql的情况看卸载情况:
# rpm -qa|grep -i mysql
可以看到之前安装的包,然后执行删除命令,全部删除
# rpm -ev MySQL-devel--5.1.52-1.el6.i686 --nodeps
•查找之前老版本MySQL的目录,并删除老版本的MySQL的文件和库
# find / -name mysql
删除查找到的所有目录
#例如:rm -rf /run/lock/subsys/mysql
#例如: rm -rf /etc/selinux/targeted/active/modules/100/mysql # rm -rf /var/lib/mysql
•手动删除/etc/my.cnf
# rm -rf /etc/my.cnf
•再次查询如果无,则删除干净
# rpm -qa|grep -i mysql删除 mariadb
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs
rpm -e --nodeps mysql-libs-5.1.52-1.el6_0.1.x86_64
2、Mysql下载安装
1.1 下载
官网网址:MySQL :: Download MySQL Community Server
在这里下载的是如下版本的mysql
https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz1.2 上传
使用xshell上传到到linux服务器指定安装路径
此处是安装路径是 /usr/local
1.3 解压重命名
cd /usr/local/
tar -xzvf mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz -C
# 如果是xz结尾压缩包用 tar -xvJf,如 tar -xvJf mysql-8.0.30-linux-glibc2.12-x86_64.tar.xz
重命令
mv mysql-5.7.26-linux-glibc2.12-x86_64 mysql
3、配置环境变量
vim /etc/profile
export MYSQL_HOME=/usr/local/mysql
export PATH=$PATH:$MYSQL_HOME/bin使环境生效
source /etc/profile
4、删除用户组
删除用户组
cat /etc/group|grep mysql
groupdel mysql
userdel mysql
5、创建用户和组
groupadd mysql
useradd -r -g mysql mysql
6、创建文件夹
mkdir /usr/local/mysql/data
7、更改权限
更改mysql目录下所有的目录及文件夹所属的用户组和用户,以及赋予可执行权限
chown -R mysql:mysql /usr/local/mysql/data/
chown -R mysql:mysql /usr/local/mysql/
chmod -R 755 /usr/local/mysql/
8、初始化
安装依赖包
yum install libaio 或者下面的
yum install -y mariadb-server 安装mariadb-server 5.X版本使用
执行初始化
/usr/local/mysql/bin/mysqld --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/ --initialize
9、记住初始密码

10、配置文件
5.x版本
[mysqld]
port=3306
user=mysql
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/tmp/mysql.sock
#character config
character_set_server=utf8mb4
explicit_defaults_for_timestamp=true
8.0版
[mysql]
socket=/usr/local/mysql/tmp/mysql.sock
port=3306
user=mysql
default-character-set=utf8[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/tmp/mysql.sock
port=3306
user=mysql
log_timestamps=SYSTEM
collation-server = utf8_unicode_ci
character-set-server = utf8
default_authentication_plugin= mysql_native_password[mysqld_safe]
log-error=/usr/local/mysql/log/mysqld_safe.err
pid-file=/usr/local/mysql/tmp/mysqld.pid
socket=/usr/local/mysql/tmp/mysql.sock[mysql.server]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/tmp/mysql.sock
port=3306
user=mysql
11 将mysql加入到服务中
复制
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql#赋予可执行权限
chmod +x /etc/init.d/mysql
#添加服务
chkconfig --add mysql
#显示服务列表
chkconfig --list mysql

12、设置开机启动并查看进程
设置开机启动:chkconfig mysql on
启动mysql :service mysql start;
查看进程:ps -ef|grep mysql;
查看状态:service mysql status;
13、 创建软连接
ln -s /usr/local/mysql/bin/mysql /usr/bin
14、授权修改密码
mysql -uroot -p
输入密码(初始化时候的密码)
8.0以下修改密码:
use mysql;
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('newpassword');
flush privileges;
8.0以上修改密码
use mysql;
UPDATE user SET authentication_string="" WHERE user="root";
FLUSH PRIVILEGES;
update user set Host="%" where User="root";
flush privileges;
alter user "root"@"%" identified by "root";
flush privileges;8.0以下授权
grant all privileges on *.* to 'root'@'%' identified by '密码123456' with grant option;
flush privileges;8.0以上授权
use mysql;
#还原密码验证插件,将MySQL8的密码认证插件由caching_sha2_password更换成mysql_native_password
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'root';
#刷新权限
flush privileges;
四、HIve安装
1、下载安装
1.1下载
下载地址:http://archive.apache.org/dist/hive/
我们选择apache-hive-3.1.3-bin.tar.gz版本学习
1.2 上传
1.3 解压重命名
2、配置环境变量
vi ~/.bash_profile
export HIVE_HOME=/usr/local/hiveexport PATH=$PATH:$HIVE_HOME/bin
刷新配置
source ~/.bash_profile
3、配置文件
配置hive-env.sh
export HADOOP_HOME=/usr/local/hadoop
export HIVE_CONF_DIR=/usr/local/hive/conf
配置hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
4、拷贝jar包
4.1 拷贝mysql驱动
需要提前现在对应的驱动包,并解压
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar /usr/local/hive/lib/
4.2 拷贝guava包
#hadoop和hive里面的guava包版本可能不一致,那么用hadoop里面的覆盖掉hive里面的
cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib/#删除hive的旧依赖包
rm /opt/hive/lib/guava-19.0.jar
5、初始化
5.1 启动msyql
# 先查看mysql是否启动
service mysql status;
#未启动则进行启动
service mysql start
5.2 启动hadoop
#进入hadoop安装目录
cd /usr/local/hadoop/
#启动hadoop
sbin/start-all.sh
5.3 初始化hive
#进入hive安装目录
cd /usr/local/hive
#执行初始化命令,#初始化Hive
bin/schematool -dbType mysql -initSchema
6、启动hive
#进入hive安装目录
cd /usr/local/hive
#使用命令验证hive是否安装成功
bin/hive
#进入hive shell,使用show databases; 查看数据,说明安装成功!