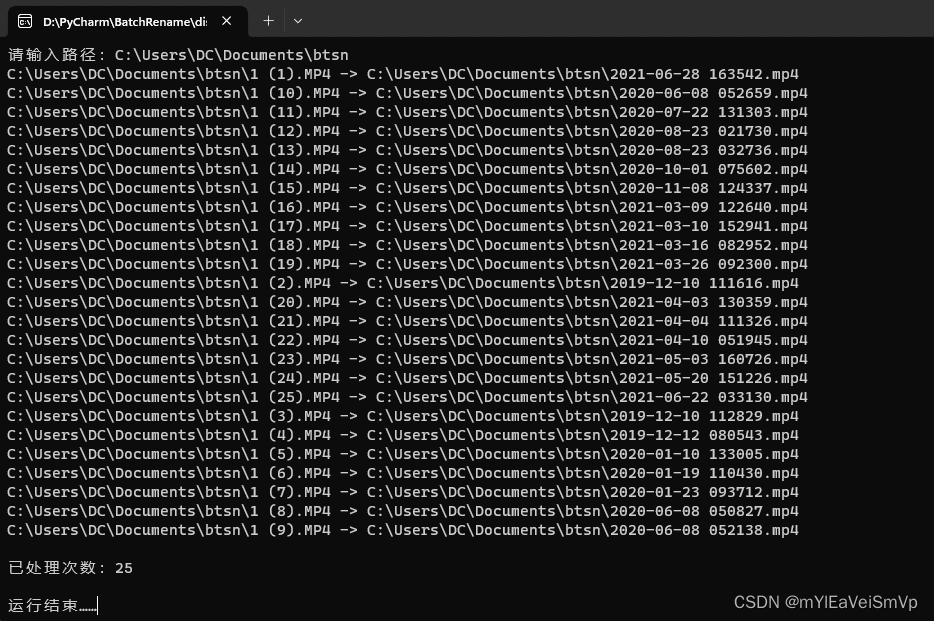
图解

堆排序是一种常见的排序算法,它借助了堆这种数据结构。堆是一种完全二叉树,它可以分为两种类型:最大堆和最小堆。在最大堆中,每个结点的值都大于等于它的子结点的值,而在最小堆中,每个结点的值都小于等于它的子结点的值。
堆排序的基本思想是:先将待排序的序列构建成一个最大堆(或者最小堆),然后将堆顶元素(最大值或最小值)与序列的最后一个元素交换位置,然后再将剩余的元素重新构建成一个最大堆(或最小堆),继续进行交换和重构堆的操作,直到所有元素都排列好为止。
堆排序的时间复杂度为O(nlogn),它不仅具有稳定性,而且还适合处理大规模数据的排序问题。
堆排序是一种基于二叉堆的排序算法,它的时间复杂度为 O(n log n)。
以下是 Java 实现堆排序的代码:
public class HeapSort {
public static void sort(int[] arr) {
int n = arr.length;
// 建立最大堆
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
// 逐步取出堆顶元素,放置到数组末尾
for (int i = n - 1; i > 0; i--) {
swap(arr, 0, i);
heapify(arr, i, 0);
}
}
private static void heapify(int[] arr, int n, int i) {
int largest = i; // 初始化最大节点为当前节点 i
int left = 2 * i + 1; // 左子节点
int right = 2 * i + 2; // 右子节点
// 如果左子节点大于当前节点,则更新最大节点为左子节点
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
// 如果右子节点大于当前节点和左子节点,则更新最大节点为右子节点
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
// 如果最大节点不是当前节点,则交换它们,再以最大节点为根继续向下堆化
if (largest != i) {
swap(arr, i, largest);
heapify(arr, n, largest);
}
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
在上述代码中,sort 方法代表堆排序的入口,它首先建立最大堆,再逐步取出堆顶元素,放置到数组末尾。
heapify 方法用于维护最大堆的性质,它接受三个参数:数组、数组长度和当前节点的索引。该方法首先找到当前节点的左子节点和右子节点,然后找出它们中的最大值。如果最大值不是当前节点,则交换它们,并以最大节点为根继续向下堆化,直到完成维护最大堆的过程。
swap 方法用于交换数组中的两个元素。