目录
一、什么是C++
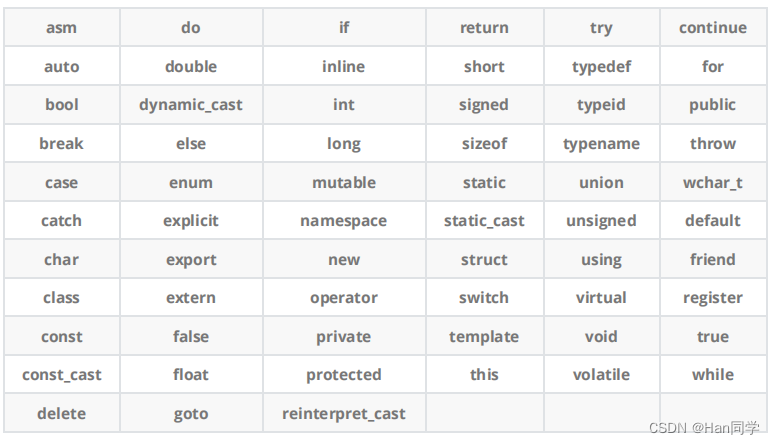
1、C++关键字(C++98)
2、C++兼容C
二、C++程序预处理指令
三、命名空间
1、命名冲突
第一种:
第二种:
2、域作用限定符
3、实现命名空间
4、命名空间冲突
5、访问命名空间
6、命名空间“std”
四、输入输出
1、定义
2、自动识别类型
3、格式化输出
五、缺省参数
1、全缺省
2、半缺省
一、什么是C++
- C++是一种高级程序设计语言,它是在C语言的基础上发展而来的。C++支持面向对象编程OOP(object oriented programming:面向对象)思想,这种编程方式可以更好地处理复杂问题和大规模程序的开发。
- C++既可以进行C语言的过程化程序设计,也可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。
- 1982年,C++的设计者Bjarne Stroustrup博士在C语言的基础上引入并扩充了面向对象的概念,使得C++成为一种功能强大、灵活性高、可扩展性好的编程语言。
- C++的出现是为了解决软件危机,支持高度抽象和建模,适用于处理复杂问题和大规模程序的开发。C++还支持泛型编程和模板元编程,这使得C++成为一种非常灵活和强大的编程语言。
1、C++关键字(C++98)
2、C++兼容C
使用C语言的语法在 .cpp 文件中依然可以运行。

二、C++程序预处理指令
#include <iostream>C和C++一样,使用一个预处理器 在进行主编译之前对源文件进行处理,上述的编译指令使预处理器将 iostream 文件的内容添加到程序中。
那么什么要将 iostream 文件的内容添加到程序中呢?
- 答案涉及程序与外部世界之间的通信。iostream 中的 io 指的是输入(进入程序的信息)和输出(从程序中发送出去的信息)。
- C++的输入输出方案涉及 iostream文件中的多个定义。为了使用cout来显示消息,第一个程序需要这些定义。#include编译指令导致 iostream 文件的内容随源代码文件的内容一起被发送给编译器。
- 实际上,iostream 文件的内容将取代程序中的代码行#include <iostream>。原始文件没有被修改,而是将源代码文件和 iostream 组合成一个复合文件,编译的下一阶段将使用该文件。
- 注意:使用 cin(=scanf) 和 cout(=printf) 进行输入和输出的程序必须包含文件iostrcam。
#include <iostream>
using namespace std;//后续讲解
int main()
{
int a = 0;
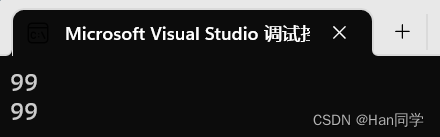
cin >> a;
cout << a << endl;
return 0;
} 
三、命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
1、命名冲突
我们先来看一下命名冲突:
大体命名冲突有两种:
- 我们自己定义和库里面的名字冲突
- 项目组,多个人之间定义的名字冲突
下面我们举例来解释两种情况的产生 。
第一种:
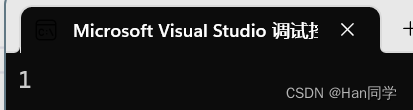
我们定义一个全局变量rand,此时程序正常输出。
#include <stdio.h>
int rand = 1;
int main()
{
printf("%d\n", rand);
return 0;
} 
如果我们包含头文件<stdlib.h>再次运行
#include <stdio.h>
#include <stdlib.h>
int rand = 1;
int main()
{
printf("%d\n", rand);
return 0;
}此时程序无法正常运行,显示错误如下:
![]()
这是因为<stdlib>头文件中定义了rand函数,当我们自己声明全局变量rand时,再包含头文件<stdlib.h> 就造成了 rand 的重定义。
第二种:
我们在两个头文件中同时定义了Node结构体。
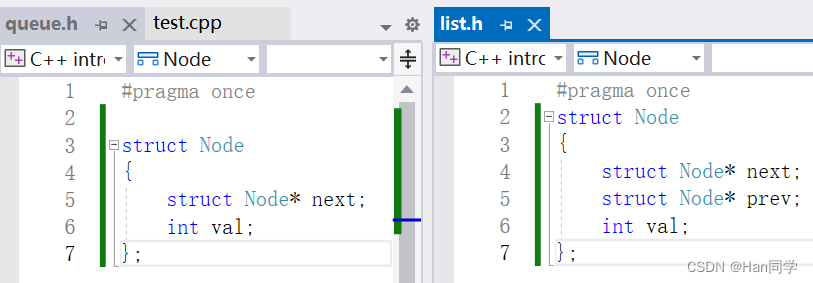
然后主函数包含两个新创建的头文件,
#include <stdio.h>
#include "list.h"
#include "queue.h"
int main()
{
return 0;
}编译一下,结果程序报错如下:

由此可知,两个头文件包含相同的命名时,同时调用程序会报错。
为了解决这个问题,我们的大佬推出了命名空间的概念,对标识符的名称进行本地化,以避免命名冲突或名字污染。
2、域作用限定符
我们先来回顾“域”的概念:
在C/C++中,域(Scope)是指程序中变量、函数、类等实体的可见范围和生命周期。根据实体的定义位置和作用范围,可以将域分为以下几种类型:
-
全局域(Global Scope):全局域中定义的变量、函数、类等实体在整个程序中都是可见的,它们的生命周期与程序的运行时间相同。在C/C++中,全局变量和全局函数默认情况下都属于全局域。
-
局部域(Local Scope):局部域中定义的变量、函数、类等实体只在其定义的代码块中可见,它们的生命周期与代码块的执行时间相同。在C/C++中,函数中定义的变量和函数参数都属于局部域。
这段代码中函数 f1 和函数 f2 中变量a都是域,int a = 2;是全局域。
#include<stdio.h>
int a = 2;
void f1()
{
int a = 0;
}
void f2()
{
int a = 1;
}
int main()
{
printf("%d\n", a);
return 0;
}此时如何在函数 f1的局部域中打印全局域的变量 a 呢?
我们可以借助域作用限定符 :: (两个冒号) 实现,:: 左边为指定的域,不指定默认全局域。
int a = 2;
void f1()
{
int a = 0;
printf("%d\n",::a); // ::域作用限定符
}
运行后,成功输出全局域的全局变量 2 。
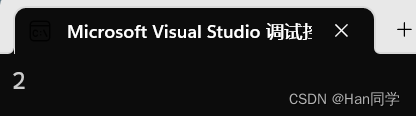
3、实现命名空间
定义命名空间需要关键字 namespace,分别为两个Node结构体定义名为 Q
和名为 L 的命名空间 .
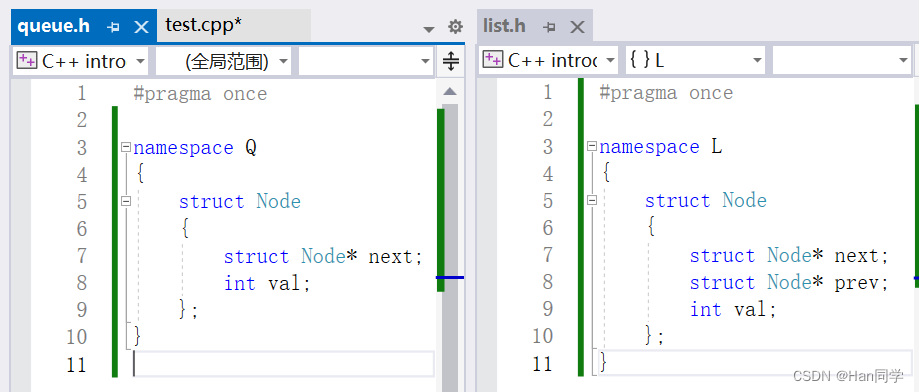
然后在主函数中使用通过命名空间使用他们。
#include <stdio.h>
#include "list.h"
#include "queue.h"
int main()
{
struct Q::Node node1;
struct L::Node node2;
return 0;
}我们声明了一个名为node1的 struct Q::Node 类型的变量,然后声明了一个名为node2的 struct L::Node 结构体类型的变量。由于这两个结构体都定义在不同的命名空间中,因此我们需要使用作用域解析运算符::来指定命名空间的名称。
我们对于重名的变量也可以放入不同的命名空间中,在两个命名空间中分别加入变量 x。
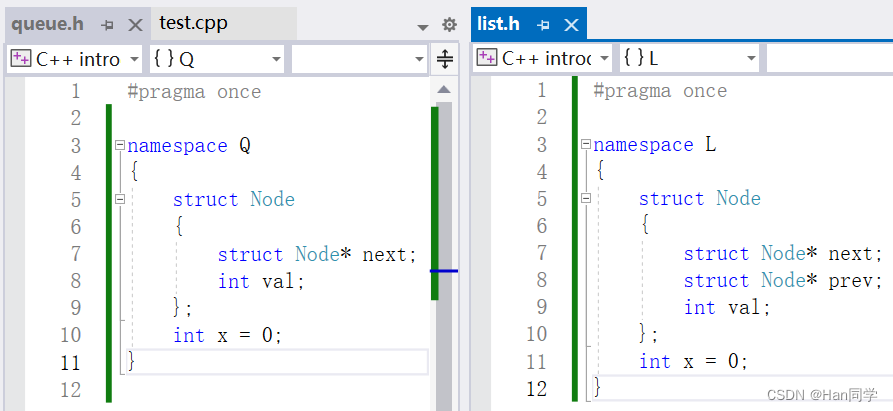
我也可以通过作用域解析运算符,访问不同命名空间中相同命名的变量。
int main()
{
struct Q::Node node1;
struct L::Node node2;
Q::x++;
L::x++;
return 0;
}4、命名空间冲突
比如这种情况:
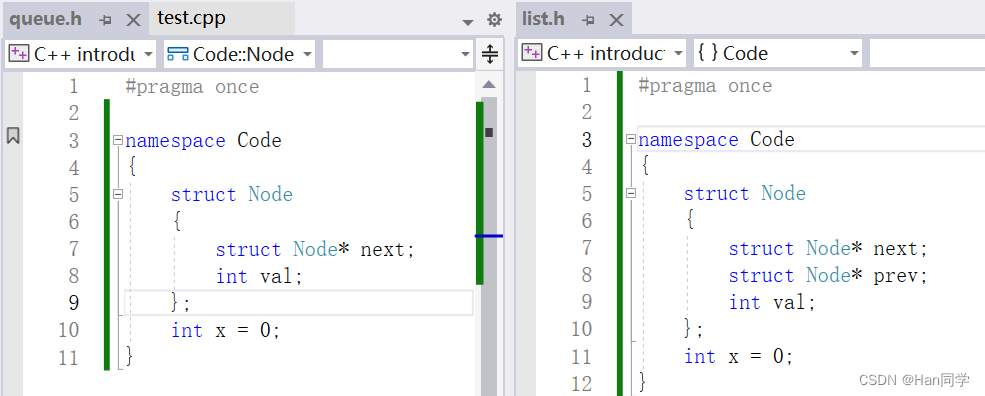
我们可以进行命名空间的嵌套。

我们对命名空间Code分别嵌套一层命名空间Q和L,这样就可解决命名空间冲突的问题,使用命名空间的内容时,只需多加一层域解析运算符。代码如下:
#include <stdio.h>
#include "list.h"
#include "queue.h"
int main()
{
struct Code::Q::Node node1;
struct Code::L::Node node2;
Code::Q::x++;
Code::L::x++;
return 0;
}这种嵌套没有限制,可以进行多层嵌套。
5、访问命名空间
- 指定命名空间访问
struct Code::Q::Node node1; struct Code::L::Node node2;- 全局展开. 一般情况,不建议全局展开的。
但是一般情况下不建议全局展开,项目中禁止,平时练习可以。#include "list.h" using namespace Code; int main() { struct L i; return 0; }- 部分展开
using std::cout; using std::endl; int main() { cout << "1111" << endl; return 0; }
6、命名空间“std”
#include <iostream>
using namespace std;
int main()
{
int a = 0;
cin >> a;
cout << a << endl;
return 0;
}
std是一个命名空间,它包含了许多标准库函数和对象,例如cout和cin。命名空间的作用是为了避免不同库中的函数或对象名称冲突,因此在使用标准库中的函数和对象时,
- 如果不使用
using namespace std;语句,需要在前面加上std::前缀,以指明它们属于std命名空间。 - 如果使用
using namespace std;语句可以让我们直接使用这些函数和对象,而不需要加上std::前缀。
四、输入输出
1、定义
- 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件 以及按命名空间使用方法使用std。
- cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含<
- iostream >头文件中。
- <<是流插入运算符,>>是流提取运算符。
#include <iostream>
using namespace std;
int main()
{
int a;
cin >> a;
cout << a << endl;
return 0;
}
2、自动识别类型
- 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。
- C++的输入输出可以自动识别变量类型。
#include <iostream>
using namespace std;
int main()
{
int n = 0;
cin >> n;
double* a = (double*)malloc(sizeof(int) * n);
for (int i = 0; i < n; i++)
{
cin >> a[i];
}
for (int i = 0; i < n; i++)
{
cout << a[i] << endl;
}
return 0;
}
3、格式化输出
这种情况用cout输出就显得有些麻烦,此时用C语言的printf进行格式化输出就方便许多。
int main()
{
char name[100] = "Kelly";
int age = 20;
cout << "name:" << name << endl;
cout << "age:" << age << endl;
printf("name:%s\nage:%d\n", name, age);
return 0;
}五、缺省参数
C++ 可以在函数定义时对参数赋初始值,调用时可以不对函数传值,输出则为参数的初始值。
void func(int a = 0)
{
cout << a << endl;
}
int main()
{
func();
return 0;
}
如果对函数传值,则函数使用传入值。
func(666);
1、全缺省
使用缺省值,必须从右往左连续使用。
void Func(int a = 1, int b = 2, int c = 3)
{
cout << a << " " << b << " " << c << endl;
}
int main()
{
Func(4, 5, 6);
Func(4, 5);
Func(4);
Func();
return 0;
}输出结果如下:

2、半缺省
必须从右往左连续缺省。
void Func(int a , int b = 2, int c = 3)
{
cout << a << " " << b << " " << c << endl;
}
int main()
{
Func(4, 5, 6);
Func(4, 5);
Func(4);
//Func(); 至少传一个值给a
return 0;
}
这种就不可以 ,不符合从右往左连续缺省。
void Func(int a = 0, int b , int c = 3)注意!
缺省参数不能在函数声明和定义中同时出现
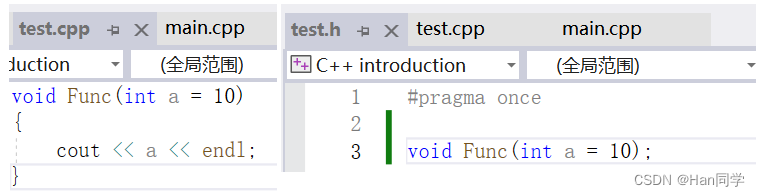
Visual Studio可能没有报错,是因为它的编译器对这种情况进行了特殊处理,将函数声明和定义中的缺省参数合并起来,但是,这种行为并不是所有编译器都支持,因此在编写跨平台的代码时,最好避免在函数声明和定义中同时指定缺省参数,以函数声明中指定的缺省参数为准。