昇科能源、清华大学欧阳明高院士团队等的最新研究成果《动态深度学习实现锂离子电池异常检测》,用已经处理的整车充电段数据,分析车辆当前或近期是否存在故障。
思想步骤:
- 用正常电池的充电片段数据构造训练集,用如下的方式构造损失函数训练模型。
损失函数构造:
(1)计算mean_pred(由encoder输出)和里程之间的mse损失;
(2)计算log_p(由decoder输出)和(“min_temp”, “max_single_volt”, “max_temp”, “min_single_volt”, “volt”)之间的SmoothL1Loss损失;
(3)计算log_v和mean的kl损失。
(4)最终的损失由(1)(2)(3)加权得出。 - 用1中的模型计算训练集和部分故障车充电数据(result)的误差(这里的误差指的是如上(2)所示)。
- 获得误差阈值,误差阈值的选取方式为:误差排序后((2)所示)的第千分之n的result数据所对应的误差值,n是使得result数据中故障车的比例最高时的取值。
- 按照真实故障标签和同一辆车前百分比误差均值计算auroc,按照误差阈值计算混淆矩阵、召回率等。
- 用剩余正常电池的充电片段数据和剩余故障电池的充电片段数据构建测试集
- 用3中所述误差阈值计算5中测试集的故障标签,计算混淆矩阵、召回率等,按照真实故障标签和同一辆车前百分比误差均值计算auroc
数据介绍
- 文章发布了从清华大学EV数据平台收集的三个大规模数据集,这些数据集包括来自347辆电动汽车的69万多个LiB充电片段,包括55辆异常车辆(LiB故障车辆)和292辆正常车辆(LiB无故障车辆),为相同品牌的车辆。
- 车级故障标签由驾驶员报告生成,工程师根据镀锂、续航里程过低、温度过高或电压异常变化(过低、电池间不一致等)的识别进行确认。这些标签是逐案创建的,不能用基于规则的数据表达式来描述。
- 电池故障时或故障附近的异常数据被删除。
- 发布的数据已经被清洗过,数值的大小不能再反映电池本身的特性,但数据变化的趋势仍然符合电池的规律,每个样本数据(对应于作者给的每个pkl文件)具有(128, 8)的时序数据。
- 字段名称:包含两部分,第一部分的列名为:volt, current, soc, max_single_volt, min_single_volt, max_temp, min_temp, timestamp;第二部分的列名为:fault label, car number, charge segment number and mileage
timestamp:时间戳
fault label:故障标签,多种故障类型在数据中统一标注为1
样本数据案例:
(array([[ -1.54891411, -107.14166667, 46.97083333, ..., 29. ,
26. , 0. ],
[ -1.54891411, -107.1625 , 47.16875 , ..., 29. ,
26. , 10. ],
[ -1.54891411, -107.18333333, 47.36666667, ..., 29. ,
26. , 20. ],
...,
[ 1.59613311, -90.29166667, 72.91666667, ..., 34. ,
31. , 1250. ],
[ 1.62806252, -90.02083333, 73.08333333, ..., 34. ,
31. , 1260. ],
[ 1.65999193, -89.6875 , 73.25 , ..., 34. ,
31. , 1270. ]]), OrderedDict([('label', '00'), ('car', 168), ('charge_segment', '122'), ('mileage', 1728.670740234375)]))
样本案例中取出第一条数据:
[ -1.54891411 -107.14166667 46.97083333 3.76328125 3.74908854
29. 26. 0. ]
模型
model DynamicVAE(
(encoder_rnn): GRU(7, 128, num_layers=2, batch_first=True, bidirectional=True)
(decoder_rnn): GRU(2, 128, num_layers=2, batch_first=True, bidirectional=True)
(hidden2mean): Linear(in_features=512, out_features=8, bias=True)
(hidden2log_v): Linear(in_features=512, out_features=8, bias=True)
(latent2hidden): Linear(in_features=8, out_features=512, bias=True)
(outputs2embedding): Linear(in_features=256, out_features=5, bias=True)
(mean2latent): Sequential(
(0): Linear(in_features=8, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=1, bias=True)
)
结果
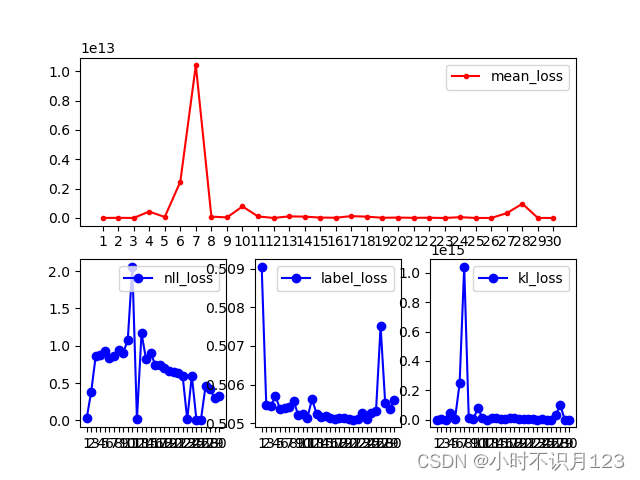
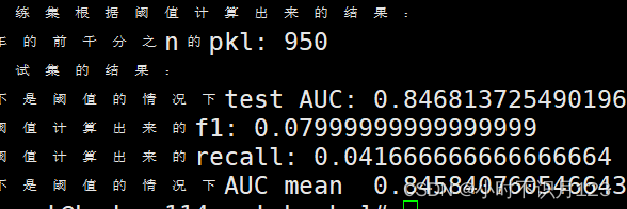
battery_brand1五折交叉验证后的结果,感觉召回率不理想啊,忧愁。
论文的疑问
- 最大的疑问就是召回率咋那么低,该咋调
- 训练集是由正常车数据组成的?给的源码我理解是这样的。
- 代码和文章不同之处-里程损失定义和模型定义:代码中里程损失是encoder输出结果和真实里程之间计算mse,文章中写的是decoder结果和真实里程之间计算mse;代码中隐藏层是128维,num_layers是2,文章中是32维3层。

- 正常充电片段数据定义规则,故障片段数据定义规则
如距故障发生时间点算起,向前推多久的数据算作故障数据?
数据集中的每辆车只有一个确定的故障标签,在样本数据构造过程中,同一辆车不能同时取故障和正常两个时期的数据吗(文章未明确,数据分析得出)
epochs超过3,loss就不行了?