导语
Apache Pulsar 是一个多租户、高性能的服务间消息传输解决方案,支持多租户、低延时、读写分离、跨地域复制、快速扩容、灵活容错等特性。本文是 Pulsar 技术系列中的一篇,主要介绍 Pulsar 在海量DB Binlog 增量数据采集、分拣场景下的应用。
前言
Pulsar 作为下一代消息中间件的典型代表,在大数据领域、广告、计费等场景已经得到了广泛的应用。本文主要分享 Pulsar 在大数据领域, DB Binlog 增量数据采集、分拣案例中的应用,以及在使用过程中对 Pulsar Java SDK 的使用调优,供大家参考。
一、背景介绍
本文分享的对 MySQL Binlog 做增量数据采集和分拣的场景,是 [Apache InLong] (https://inlong.apache.org/) 系统的一个子能力。需要使用到 Apache InLong 中的 DBAgent( 采集Binlog 的组件)、Sort(分拣入库的组件) 及US(调度系统) 等组件。
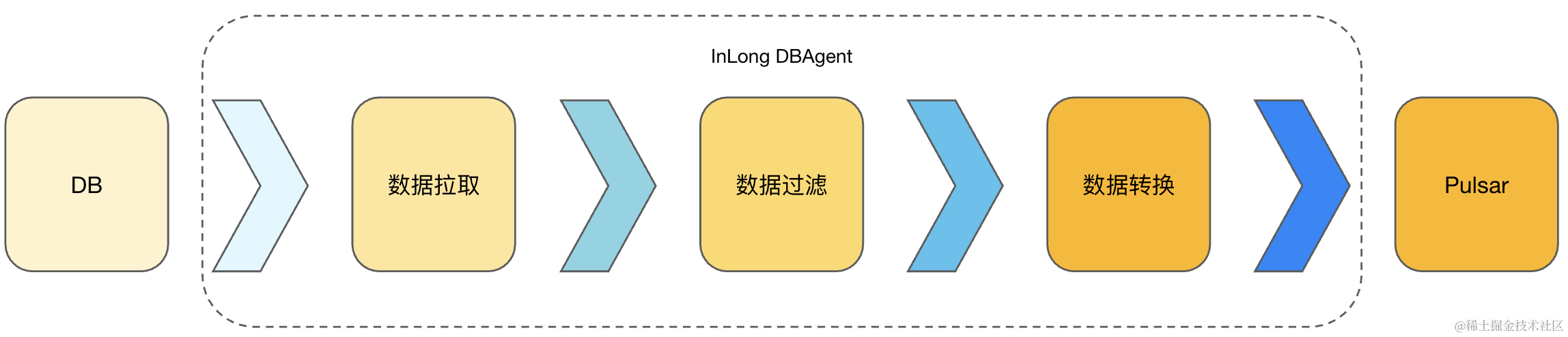
如图1所示,InLong DBAgent (采集 Binlog )组件使用 Java 语言实现,完成 Binlog 同步、Binlog 数据解析、Binlog 数据过滤、Binlog 数据转换及将符合过滤条件的数据及指标发送到 Pulsar 集群的功能。
InLong Sort(分拣入库) 采用 Java 语言实现,完成数据从 Pulsar 集群的订阅、数据的解析-转换及最终数据的入库操作(Thive)。
US Runner (调度任务)采用 Java 语言实现,这里依赖 US 调度平台,是通过 Pulsar 消息方式触发,在拉起业务方挂载的任务 Runner 之前,完成保障数据完整性的校验,即对前置依赖的数据采集状态进行校验、完成指标数据对账、完成端到端对账及端到端补数据等。
1.1、功能架构
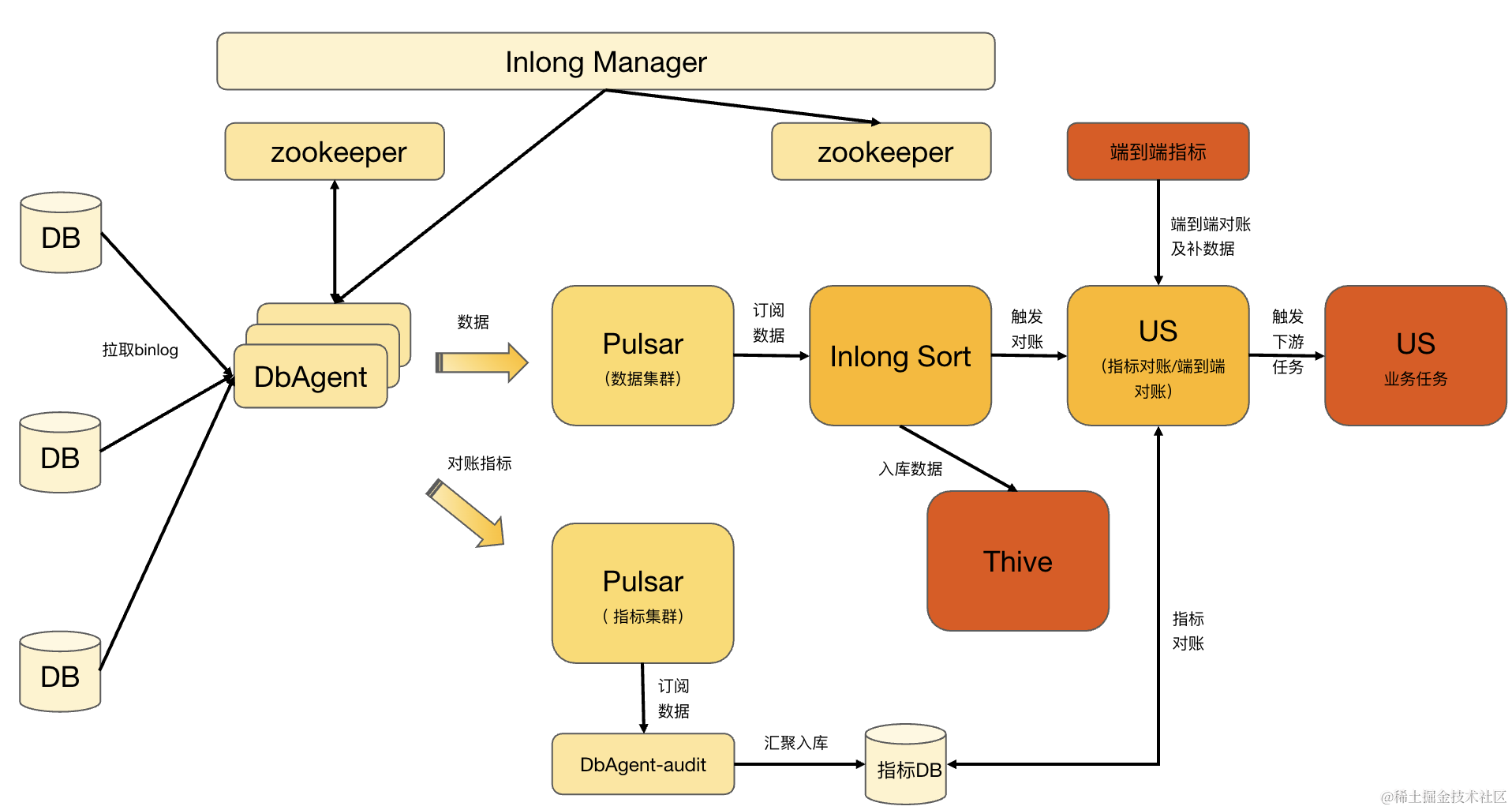
如图2所示,Apache InLong 系统内,基于MySQL Binlog 做的增量数据采集、分拣流程主要有如下几个部分组成:
-
InLong Manger:负责 DB 采集、分拣配置的接入和下发。
-
InLong DBAgent:负责具体 DB 采集任务的执行,节点无状态,高可用,支持异构机型部署,支持 DB 采集任务在多个 InLong DBAgent 之间做 HA 调度,发送数据和指标分别到对应的 Pulsar 集群。
-
Pulsar: 分为数据集群和指标集群,使用时可以配置为相同集群地址。
-
InLong Sort : 负责订阅分拣数据,处理数据的转换和入库逻辑。支持 Exactly Once 语意,支持多种入库 Sink,如 Thive/Hive、Iceberg、Hbase、Clickhouse 等。
-
US Runner:US 是调度平台,这里的 Runner 是指在其上运行的任务,当前支持指标对账和端到端对账,只有对账通过时,下游任务才会运行,确保数据在一定质量保障的前提下被用户使用。
1.2、基于 Pulsar 的采集端
1.2.1 采集端架构设计
InLong DBAgent 作为数据的采集端,将采集的数据发送到Pulsar集群。
InLong DBAgent 为无状态节点,具备断点续采、单机多 DB 任务采集、DB 采集任务 HA 调度等能力,同时支持单机多部署、异构机型部署等能力。
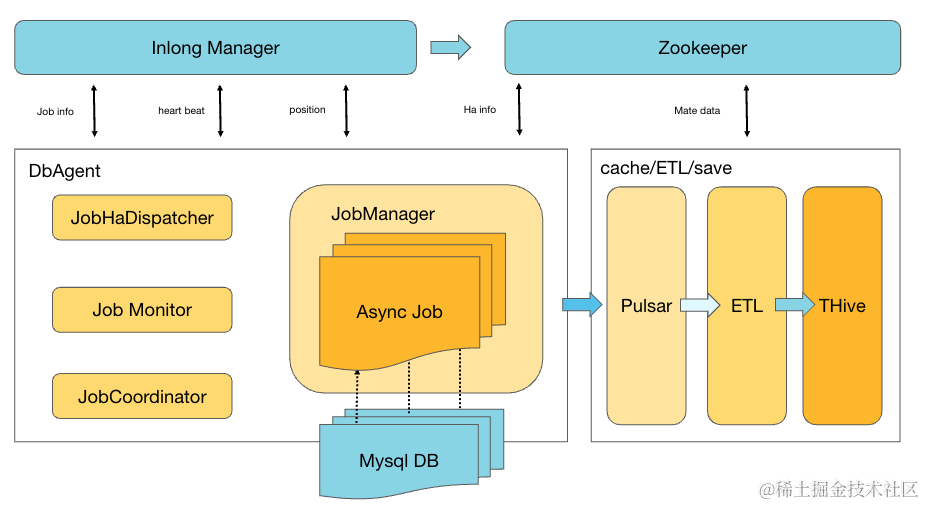
如图3所示,InLong DBAgent 同步的 Job 元数据信息通过 InLong Manager 进行管理,用户通过 InLong Manager 进行 Job 的元数据的配置。多个 InLong DBAgent 执行节点组成一个 InLong DBAgent 集群。
每个 InLong DBAgent 集群, 会通过 Zookeeper 选主,产生一个 Coordinator 角色的节点,负责这个集群下 DB 采集 Job 的分配。
1.2.2 生产数据与指标
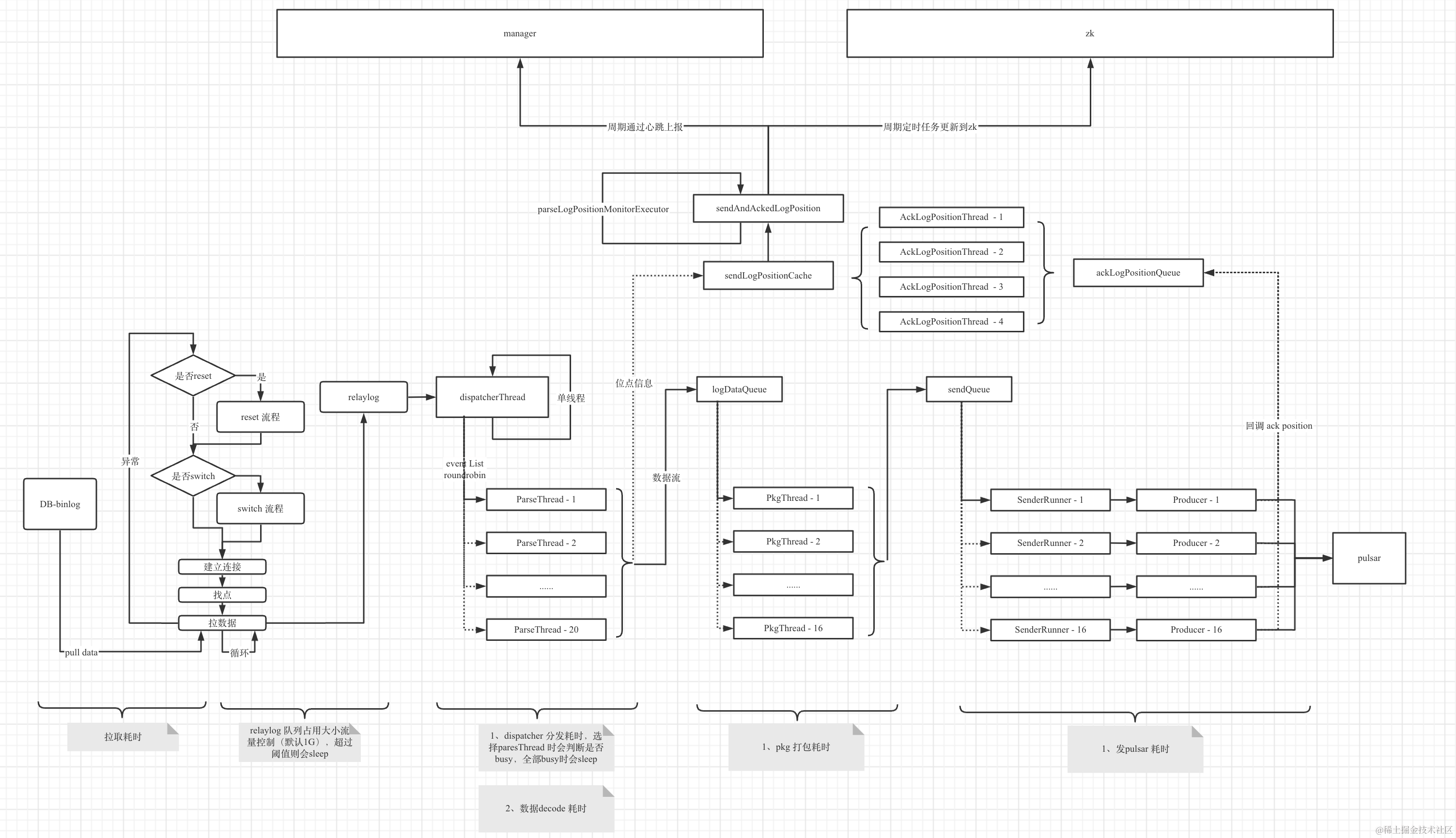
InLong DBAgent 同时处理多个 Job 的采集,如图4 所示,为 Inlong DBAgent 内部单个 Job 的处理流程,而不同 Job 之间,是逻辑隔离的(历史版本很长时间没有做到完全的隔离,后面章节会介绍这里存在的一些问题),即不同 Job 使用完全独立的逻辑资源,如 DB 连接、数据 Pulsar Client、数据 Pulsar Producer、指标 Pulsar Client 、指标 Pulsar Producer 及中间数据扭转过程中用于汇聚的Cache 、分发的线程和 Queue 等,避免 Job 之间相互影响,同时也方便 Job 在不同 InLong DBAgent 节点间做HA 调度。
当然,这种设计方式也存在一定的风险,需要在部署和运营过程中做合理的规划,后面章节会有详细的说明。
为了保证数据的完成性,整个采集、分拣流程支持指标对账流程,这里的指标对账保证的是每个时间分区内,InLong DBAgent 采集发送到 Pulsar 成功的数据条数与 InLong Sort 入库写入到 Thive 且去重复后的数据总量的比较。
InLong DBAgent 通过两点设计保障数据的完整性和指标数据的准确性。
首先,设计 Binlog 位点的确认机制。通过这个机制保证采集拉取过程的连续性,避免采集跳点问题。
InLong DBAgent 中的每个 Job 拉取到数据、解析,处理完向后分发逻辑(包括,没有实际向后分发数据的场景,如需要跳过的位点,心跳时间产生的位逻辑位点等,也需要做加入和 Ack 的操作,移除时会更新当前的最小位置信息)之后,将位置信息保存到 ConcurrentSkipListSet 类型的集合中,当数据发送到 Pulsar 成功后,会走内部的位点 Ack 流程,从 ConcurrentSkipListSet 中移除位点的同时,将当前的集合中最小的位置,通过比较逻辑,更新到采集位点缓存,这个缓存信息作为当前采集完成的位置。后台通过周期线程,将当前的采集完的缓存位置信息同步到 ZK 和上报给 InLong Manager。
当 InLong DBAgent 进程重启或 Job 被调度到新的 InLong DBAgent 节点上执行时,Job 需要首先使用 ZK 中保存的位点信息进行初始化,进而保证从上次采集完成的位置继续开始拉取数据。
需要注意的一点是,位点是通过异步方式进行更新保存的。因此,在重启或 HA 调度后,Job 的续采可能产生少量的重复数据。
其次,设计指标与数据一对一的保障机制。指标数据是在消息数据异步发送 Pulsar 消息后,回调处理的成功逻辑中生成的,通过汇聚计算,周期的发送到指标服务器。
InLong DBAgent 的进程停止和 Job 停止过程处理的相对闭环和复杂,需要保证发送给 Pulsar 的消息成功后的对账指标全部发送成功且最新的位点更新到 ZK 后再停止应用或 Job 。而在 Kill-9 这种非正常的操作情况下,会产生重复数据和导致指标丢失。这种情况下,所在分区的对账流程,需要人工介入处理。
现网的环境是复杂的,业务的使用和运维场景也是多种多样的,位点确认保证机制,不能完全的避免跳点和丢数据。比如,采集过程中,因当前连接的 DB 发生故障,采集触发了连接切换,从新的 DB 节点上面拉取数据,如果这个节点上的 Binlog 文件数据存储在断层,即新的节点上 Binlog 不全或者采集位置所在的 Binlog 已经被清理了。还比如,采集过程因数据量较大或采集机器出现了资源瓶颈,出现采集延迟,采集进度赶不上服务器端 Binlog 的清理速度等。这些都是在运营过程中出现过的场景,这种情况就需要通过监控指标,及时的发现,及时的进行人工干预处理。
1.3、基于 Pulsar 的分拣端
1.3.1 分拣端架构设计
InLong Sort 作为数据的分拣端,负责从 Pulsar 集群订阅数据,做反序列化、转换和入库。
InLong Sort 是基于 Flink 框架实现的,实现过程中涉及很多 Flink 相关的机制、概念,本文不做过多的描述,有兴趣的同学可以到 Flink 社区官网查看相关解释。
InLong Sort 的整体架构如图5所示,采集的数据目前主要被分拣入库到 Thive 中。
1.3.2 消费数据
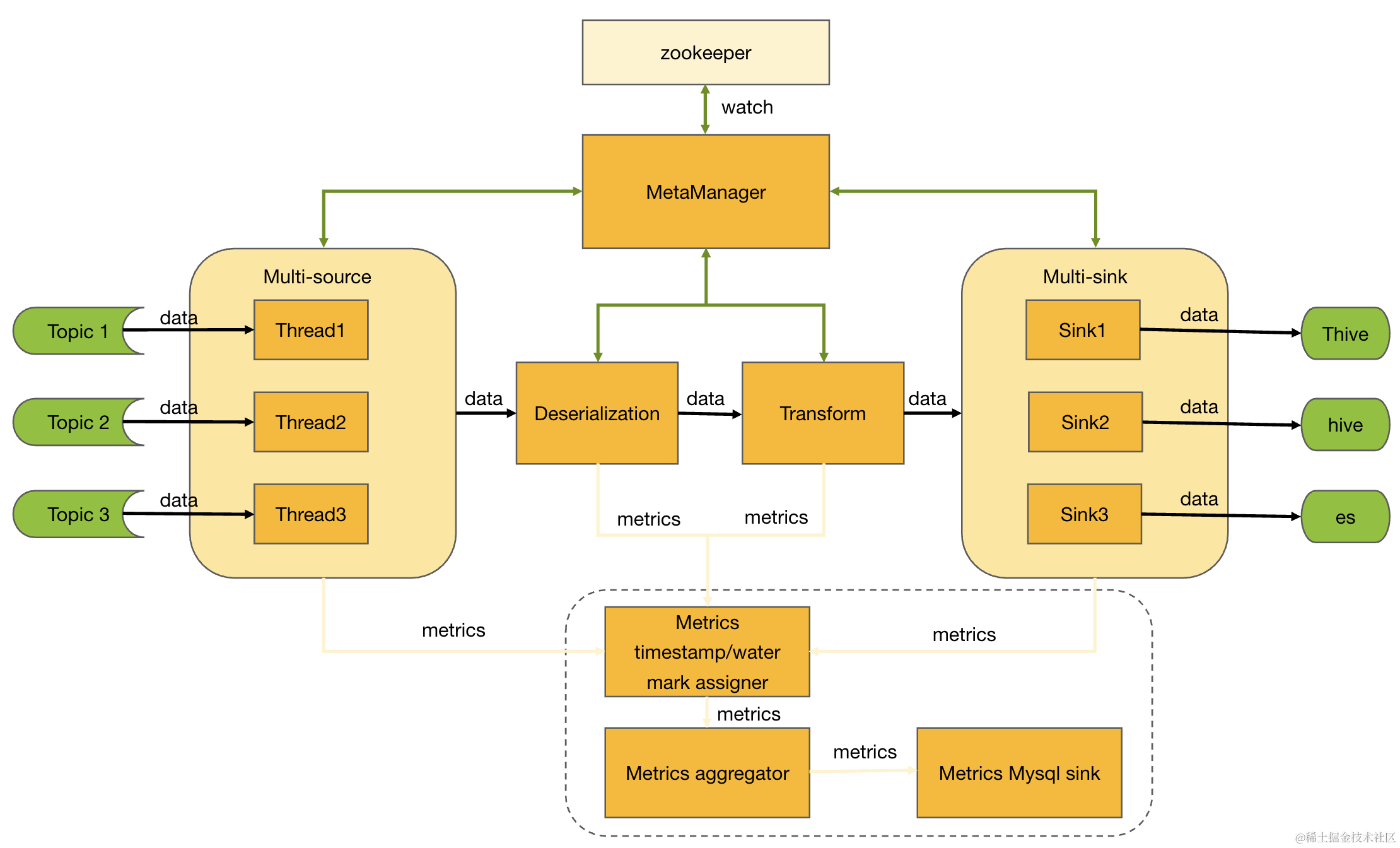
InLong Sort 订阅消费 Pulsar 集群中的数据,按照数据的处理流程,大体分为如图6 所示的 4 个部分,这里未标出指标相关的算子。当然,不同的入库类型,会存在些些许差异。

InLong Sort 是单任务(Oceanus 任务),多 Dataflow 分拣的应用。因此,每个算子都需要处理多 Dataflow 的场景,Dataflow 之间的数据流处理过程,在逻辑上是隔离的。
Source 算子,处理 Dataflow 中 Souce info 部分的解析和加载,处理 Pulsar 消息的订阅和向后分发。
Deserialization 算子,处理 MQ 消息数据的解析,按照配置拆分成不同字段内容,组织在 Record 中,向后分发。
Sink 算子,处理数据的入库逻辑。
Commiter 算子,处理入库数据的提交逻辑,以Thive 为例,Commiter 部分处理分区的创建,US Pulsar 消息的生产等。Commiter 算子并不是所有入库类型都需要的,程序中会根据接入的库类型做区分处理。
InLong Sort 的整体处理流程和设计是比较清晰的,但是实现相对比较复杂,中间算子的实现也在不断的在迭代演进,本文不做过多的描述,有兴趣的同学可以关注相关的分享或后续相关主题文章进行了解。
1.4、基于调度平台的对账
Runner 是 US 调度系统中执行的实例概念,InLong Sort 分拣数据之后,通过 Pulsar 消息触发 US 平台执行 相应的 Runner。这里主要有 ‘触发’ 和 ‘对账’ 两个相关类型的任务。其中 ‘触发’ 任务是一个空任务,US 的 Pulsar 消息的消费者收到对应的 MQ 消息后,通过 ‘触发’ 任务间接的拉起 ‘对账’ 任务。
二、Pulsar 应用
在整个的数据采集、分拣的过程中,Pulsar 作为数据和指标的中转站,分别接收 InLong DBAgent 上报的数据和发送成功的数据指标,接受 InLong Sort 任务订阅数据,接收 DBAgent-Audit 订阅指标数据。下面分两个小节,分别介绍采集生产 Pulsar 消息和分拣消费 Pulsar 数据的使用场景、存在的问题和处理的经验。
2.1 Pulsar 生产
2.1.1 生产场景
通过第一节对 InLong DBAgent 的架构设计的介绍可知,每个 InLong DBAgent 的进程中,需要跑 1-N 个采集 Job,每个 Job 负责采集一个 DB 实例上面的 Binlog 数据,每个 Job 对应一个 Pulsar 集群配置,将采集到的数据生产到这个 Pulsar 集群上,每个 Job 下包含多个 Task,而每个 Task 对应一个Pulsar Topic,这个 Topic 汇集一组符合过滤条件的库、表数据。转换到 Pulsar 部分对应关系如下图 7所示:
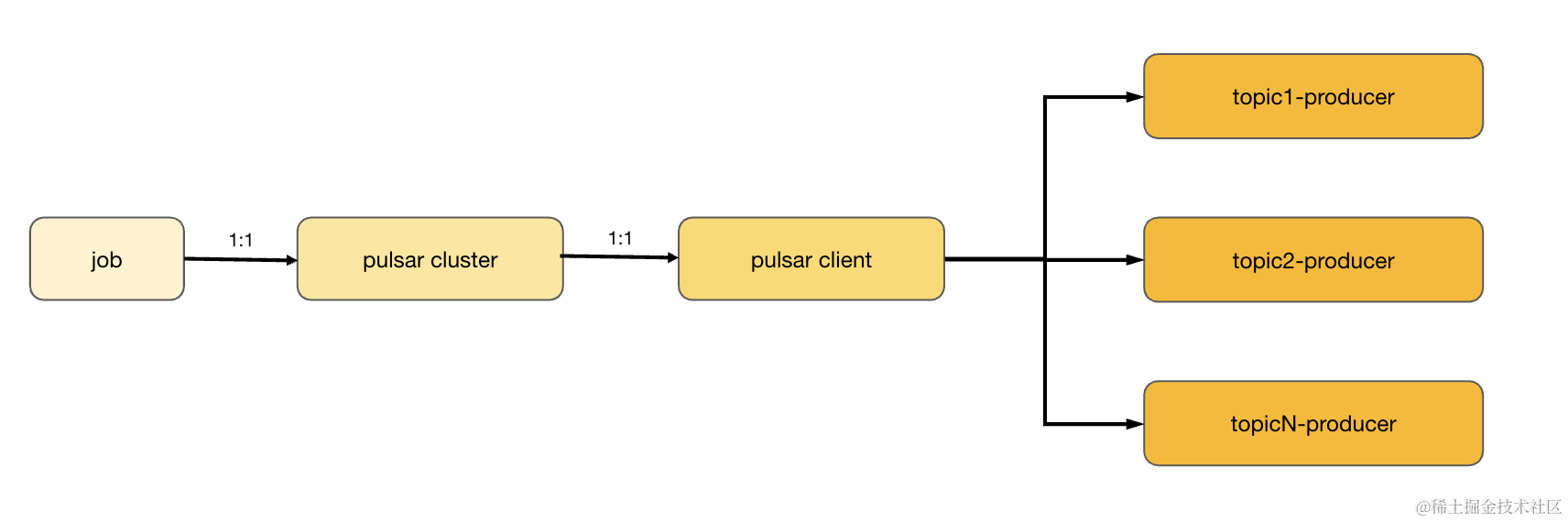
由此可见,InLong DBAgent 使用 Pulsar SDK 的场景是,我们需要在单个的 Java 进程内创建、维护 1-M 个 Pulsar Client 对象。并且,需要使用每个 Pulsar Client 对象创建、维护 1-N 个 Topic的 Producer 对象。
2.1.2 问题与调优
针对上一小节,说明的应用场景,需要考虑和处理如下几个问题:
问题1: 是否全局维护 Pulsar Client 对象,多个 Job 间如果配置相同,共用一个 Pulsar Client 对象?
我们在老版本,的确是这么实现的,这样不但能减少 Pulsar Client 对象的个数,也能减少采集节点(每个 InLong DBAgent 部署节点看作一个采集节点)与 Pulsar 集群的连接数。
但是,在实际的运营过程中我们遇到了如下两个问题。
首先,Job 之间的(Job 之内的 Task之间)数据量具有不均衡性,有的数据量可能会非常大,如流水数据表、指标数据表等,有的数据量可能非常小,如海外的部分业务订单等,有些库表具备周期性特点,如每天凌晨批量更新跑批的数据表等。这些,如果共用一个 Pulsar Client,创建 Producer 对象进行生产,Job之间采集的数据进度,存在因数量级的不同,产生的相互影响,最终导致大量的采集延迟。
其次,为了保证数据采集的高可用性,系统需要具备根据机器负载,在集群内多个 InLong DBAgent 节点之间调度 Job的能力(也就是说 Job 1上一时刻可能在 InLong DBAgent-1上面执行,后面某一个时刻可能就被调度走,在 InLong DBAgent-2上面执行了)。多个 Job 之间共用 Pulsar Client,需要根据共用信息的变化,动态的维护 Pulsar Client 及 Producer,这样不仅增加了开发、维护的难度,实现不好会导致 Client 及 Producer 的对象泄漏,为程序留下隐患。同时,在关闭 Producer Client 的时候也可能对其他的处在中间状态的 Job 产生影响甚至丢数据。
经过一段时间的论证和考量之后,版本迭代过程中,做了 Job 之间完全隔离的策略,即每个 Job 维护自己的 Pulsar Client 对象,并在此对象的基础上创建这个 Job 里需要的 1-N 个 Topic 的 Producer。这样从逻辑上完全避免了 Job 之间的相互影响。有的读者可能会问,Job 内多个 Task 之间就不存在相互影响吗?是不会的或者影响基本上是可以忽略的。这是因为,每个 Job 采集的是同一个 DB 实例内的 Binlog 数据,数据只会按照顺序进行拉取,数据天然的具备先后顺序,不同 Topic 间基本上不会引发任何问题。此外,Job 间完整的隔离,也方便 Job 在 InLong DBAgent 节点间做 HA 调度,降低了代码的开发和维护难度。
这里有另一个问题,不得不提一下—即连接数问题(占用 FD 资源)。
每个 InLong DBAgent 上面,会根据当前的机器配置(也就是所谓的异构机型),配置当前 InLong DBAgent 所能同时运行的 Job 的最大个数。当前节点与 Pulsar 集群的最大连接数,需要按如下公式进行估算(假设每个 Job 内的 1-N 个 Topic 的分区能覆盖分布到所有的 Broker 节点上):
最大连接数 =(MaxJobsNum)* (Pre BrokerConnectNum)* (PulsarBrokerNum)* Min(MaxPartitionNum,PulsarBrokerNum)
例如:
MaxJobsNum = 60 、PreBrokerConnectNum = 2、PulsarBrokerNum = 90
最大连接数 =(MaxJobsNum)* (Pre BrokerConnectNum)* (PulsarBrokerNum)* Min(MaxPartitionNum,PulsarBrokerNum)= 97200
这个数值在一般的现网机器上面,算占比,也是非常大的值了,而且会随着 Broker 节点个数的增加、单个 InLong DBAgent 节点内 Job 个数的增加而增加,在现网部署、运维过程中一定要进行相应值的估算和部署规划,避面前期没有问题,运营过程中偶发大面积进程崩溃。
问题2: 在使用 Pulsar Producer 生产消息时,为了提高效率,是否能采用多线程生产?
答案是肯定的,我们可以通过多线程分发生产消息。但是,如下实现方式(伪代码),可能会严重的降低生产效率:
public Sender extends Thread {
Producer prodcuer;
Queue msgQueue;
public Sender(Producer prodcuer,Queue msgQueue) {
this.prodcuer = prodcuer;
this.msgQueue = msgQueue;
}
public void run() {
while(true) {
Message msg = msgQueue.poll();
producer.asynSend(msg);
}
}
}
.....
PulsarProducer prodcuer = new PulsarProducer();
Queue msgQueue = new Queue();
Sender sender1 = new Sender(prodcuer, msgQueue).start();
Sender sender2 = new Sender(prodcuer, msgQueue).start();
如伪代码所示,多线程之间同时从 msgQueue 中 poll 数据,通过相同的 Producer 按照异步(或者同步,同步的效果会更明显)的方式,生产 Pulsar 消息,Pulsar SDK 在生产过程中,会在多个分区间轮训,需要做并发和锁的控制(有兴趣的同学可以看下 Pulsar SDK 中对Producer 部分的具体实现),这种共用 Producer 的方式,并不能体现到多线程并行发送的优势,反而会增加生产耗时,降低生产效率。
如果需要多线程进行并发生产,需要每个线程内使用自己的 Producer 对象进行生产。改进方式,如下图所示:
public Sender extends Thread {
Queue msgQueue;
public Sender(String topic ,Queue msgQueue) {
this.prodcuer = new Prodcuer(topic);
this.msgQueue = msgQueue;
}
public void run() {
while(true) {
Message msg = msgQueue.poll();
producer.asynSend(msg);
}
}
}
上面,是我在采集端,开发、测试、运维过程中,发现的生产 Pulsar 消息,比较具有代表性的两个问题,大家可以根据自己的业务特点进行参考借鉴。
2.2 Pulsar 消费
2.2.1 消费场景
由第一节的背景介绍可知,InLong Sort 是基于 Flink 框架实现的,采用的是单任务(这里指的是 Oceanus 任务)多数据流(多 Dataflow)的方式,即每个 Oceanus 任务下,处理 1-N 个 Dataflow 的数据分拣入库。每个 Dataflow 对应一个 Topic 的消费配置,且单个Dataflow 支持订阅多个 Pulsar 集群的数据。由此可见,InLong Sort 订阅处理过程,与 InLong DBAgent 的生产消息场景有些类似,一个进程中需要根据 1-N 个 Dataflow 配置维护多个 Pulsar Client,处理对应的1-N 个 Topic 的订阅。
2.2.2 问题与调优
InLong Sort 的消息订阅消费部分,先后演进了两个版本,下面分别说明一下第一个版本的处理方式和存在的问题,以及第二个版本的改进方式。
在开始说明消息订阅部分之前,简单的描述一下 InLong Sort 分拣 DB 数据的一些信息。 DB 数据目前主要是入 Thive 。其中 MQ 消费进度的位点、数据的分区状态、入库文件的可见性等状态信息是通过 Flink 的 State 机制进行维护,依赖 Flink 的 Checkpoint 机制周期保存到持久化存储。同时,依赖 Checkpoint 机制,完成文件的使用方可见性的控制。
MQ 消费位点的维护和分区内文件的可见性控制,这两点直接影响数据的完整性。例如,如果消费位点已经更新保存,但是这之前的消息还不能保证已经落库完毕,发生重启(预期或非预期的重启)就会导致数据丢失。与之相对应的,如果每次重启都从已经处理过且文件已经可见的消息位置开始消费,会导致数据被重复消费,数据重复入库,导致重复。因此,这两点是我们分拣处理过程中的重中之重。
下面具体说明一下,第一个版本的消费处理过程和存在的问题。
第一个版本,与 Pulsar Flink Connector 的处理方式类似,采用 Pulsar Reader 的方式实现。Pulsar Reader 设计的初衷是,每个reader 订阅一个 Topic 的一个 Partition,即初始化时需要分 Partition Topic 做配置,同时 Reader 订阅消费过程中会使用一个随机的、非持久化的消费组。
随机的订阅组,对运维过程中的监控很不友好,每次重启,不得不重新获取、配置监控的消费组信息。为了便于运维,第一个版本,利用了当时 Pulsar Broker 版本的一个漏洞(或者说是与设计相悖的能力,这点很难保证后续版本会持续存在),即为每个 Reader 指定了一个持久化的订阅组,并利用这个持久化的订阅组在 Broker 的统计数据,进行进度监控。
另外,在分拣的运维过程中,经常会根据消息量,调整 Flink 任务的内存、并行度等配置,而部分配置调整后会影响 State 的恢复,即部分配置变更后,需要选择 不从 Checkpoint 状态恢复启动。
此外,运营过程中,经常会出现因预期和非预期的原因,需要重新入库一份数据的需求。从源头补充数据,显得略有些重,需要业务方做配置。而比较便利的方式,是从 Pulsar 的历史位置再重新消费一次数据。
说明到这里,总结一下,我们需要分拣过程中具备的能力:
1. 便于运维监控消费进度;
2. 不从 Checkpoint 恢复时,不能丢数据;
3. 能够根据需求,动态的重置消费位点
通过上面的描述可知,Reader 方式的实现,显的有些鸡肋。首先,是消费组名称的问题,上面已经描述清楚,主要是不能保证后续版本的可用性。其次,不从 Checkpoint 恢复时,可能会导致丢失消息。不从 Checkpoint 恢复时,只能选择从最开始,还是最后(新)的位置开始消费,前者一定会导致数据重复,后者很大可能会导致丢数据。再次,是不能做停止后的调整位点操作,只能在运行过程中调整。
为了解决 Reader 方式的潜在风险和问题,InLong Sort 消费部分的第二个版本,改为 Puslar Consumer 实现。
首先,Consumer 方式,支持使用持久化订阅消费组,便于运维监控消费进度,这个机制符合 Pulsar 的设计预期,不涉及到兼容性问题。其次,Consumer 方式支持运行过程中及程序停止后的重置位点操作,应用场景更丰富。再次,是 Consumer 方式支持多种订阅模式,即 Shared、Exclusive、Failover 等,而分拣消费这种场景非常适合使用 Exclusive 方式。
与 Reader 方式类似,在 InLong Sort 中采用 Exclusive 模式创建 Consumer 时,也需要采用指定 Parititon Topic 的方式处理。
特别说明一下,InLong Sort 这里为什么不选用 Shared 模式创建 Consumer ?最主要的,还是为了保证数据的完整性。
对 Pulsar 的设计和实现机制有所了解的同学都会知道,Pulsar 的消费模型与 RockerMQ、Kafka 等上一代 MQ 的设计区别很大,有兴趣的同学可以参考 Pulsar 社区的相关文档。如果在 InLong Sort 这里采用 Shared 方式处理,会有哪些问题呢?
InLong Sort 是一个 Flink 任务,有算子和并行度的概念,如果 Source(订阅 Pulsar Topic 消息的消费者所在的算子)采用 Shared 方式创建消费者,针对目标 Topic 创建的消费者都会消费这个 Topic 的消息,那如何保存消费位点呢?
如果,重启时使用 Broker 端记录的位置开始消费,这样显然是有问题的,因为不能保证重启(正常或非预期)时,这个位置之前的消息已经入库成功了。
如果,重启时从 Checkpoint 恢复,采用对应的 State 信息中记录的位点,那这里的 State 信息要如何保存呢?因为,所有的 Consumer 都会消费每个 Partition Topic 的数据,也就是说,每个并行度内的 Consumer 都会有一份 Ack 的消费位点信息。那么重启后要从哪个位置开始呢?为了不丢失数据,我们不得不汇聚所有的 State 信息,针对每个 Partition Topic 选一个最小的位置重置消费,这样不可避免的会导致数据重复。不但提高了程序的复杂度,增加了 Checkpiont 的大小,而且不得不选用 Union State 类型做保存,当者类数据过大时,在重启时对任务非常的不友好,甚至可能会导致任务启动失败。
上面,是我在数据分拣的过程中,使用 Pulsar 时的分析、处理的一些经验,大家可以参考下。
三、小结
本文分享了 Apache InLong 增量 DB 数据采集案例。首先,分别对 InLong DBAgent、InLong Sort、US 对账 Runner 等部分的总体架构和部分能力进行了介绍。之后,着重分享了采集、分拣过程中使用 Pulsar 的一些经验,供大家做一定的参考。Apache InLong 各个组件的详细设计和实现细节可以围观 Apache InLong 社区或相关主题的文档、课程分享。