CAP理论
分区容忍是能容忍一个或一部分节点挂掉后,整体系统也能正常工作(就是别的节点还是活着的),所以分布式系统中P是必须要有的。比如数据库主从架构,主从两个节点之间需要数据同步,主挂了,从还能提供服务,这就是分区容错的体现
可用性是,每个请求都能得到正常的响应(不要求读到最新值)
p分区容忍,既然是分布式系统那么分区容忍是逃不掉的,剩余的一致性和可用性相互矛盾,只能二选一
- G1和G2两个集群,如果当前有线程a写G1,如果此时你允许线程b读取G2,则会出现数据不一致
- G1和G2两个集群,如果当前有线程a写G1,此时锁定G2不让读取,等G1的修改数据同步到G2,再将G2放开读取。此时,G2就出现了锁定期间,这段时间的不可用
有没有保证CA的系统,单机就是。因为单机没有分区,单机也就是只有一个节点,那么也就不需要网络通信,也就不需要节点之间的数据同步。但是没有p,也就是只有一个节点,那么也就不能算作一个分布式系统了
注册中心对比
zk作为注册中心是保证CP,因为zk有主从的概念,主挂了整个集群重新选举期间,整个服务是不可用的;
euraka作为注册中心保证的AP
所以相比起来,euraka,nacos这种AP的系统是更适合做注册中心的
为什么注册中心更适合用AP?
注册中心更适合用AP,因为注册中心如果不保证C的话,会出现两种后果
1,可能有微服务上线,有些微服务去读某个注册中心实例的时候可以读到新注册的服务,有些微服务去读还没更新好的注册中心可能读不到新注册的服务,这个不会有影响
2,如果是某个服务下线,同理,有些服务感知到了服务下线,有些感知不到,感知不到的话会导致请求失败。而请求失败我们可以用熔断+降级+重试来进行解决。
3,同时注册中心需要能扛住高并发,也就是能服务于各个服务来抓注册表,发送心跳等等,也就是说微服务越多,要接受的qps越多,所以qps还是非常高的,而如果用了CP,必然无法扛住这么高的请求。
综上,注册中心更适合用AP
rocketMQ的namesrv就是典型的AP,nameserver 和nameserver之间互相都是不通信的,没有数据同步,是独立运行的,完全不考虑它们之间的数据一致性
注:
一致性有:数据库事务的一致性、分布式的一致性。
有几种场景,会引出数据一致性的问题:
1. 出于提升性能,而使用数据复制 replicate 引出的一致性问题,比如内存数据复制到L1,L2缓存,引出的缓存与内存数据的不一致问题
2. 数据安全性角度保证高可用,比如主备集群,副本机制保证数据不丢失。多个节点,如果有数据更新,就很难保证一次性,同时变更所有数据节点
当前线上的有状态的服务,一般是怎么保证一致性的?
线上大部分系统还是选择了最终一致性,但是也有一些强一致性的场景,比如银行要做到CP
分布式系统AP和CP如何取舍?
以redis主从集群举例,
比如你更新完redis,有些客户端连的是从节点,但是该从节点还没有数据同步过来,那针对同一个key,不同的客户端在多个从节点上读到的数据就出现了不一致,但是等所有从节点都同步完了后,最终看到的数据还是一致的,这就是最终一致性
如果要采取强一致的解决方案,那就是在写请求时,先加一个分布式锁,让所有读请求都阻塞在这里,等把所有的从节点都更新完后,释放分布式锁,让所有的读请求再进来。这个时候,所有的客户端读取到的数据都是一致的。但是这时性能就无法得到保证,比如如果同步某个从节点时,因为网络问题导致同步需要耗费非常长的时候,那你这个阻塞性能是非常差的。
ZK是过半机制就行,可能小部分机器还是没有新数据同步过来,那这个时候其他客户端还是会读取到老数据,所以ZK也不是真正的强一致
小结:
分布式系统都一样。都是在不同场景下对cp和ap取舍
Eureka核心功能点
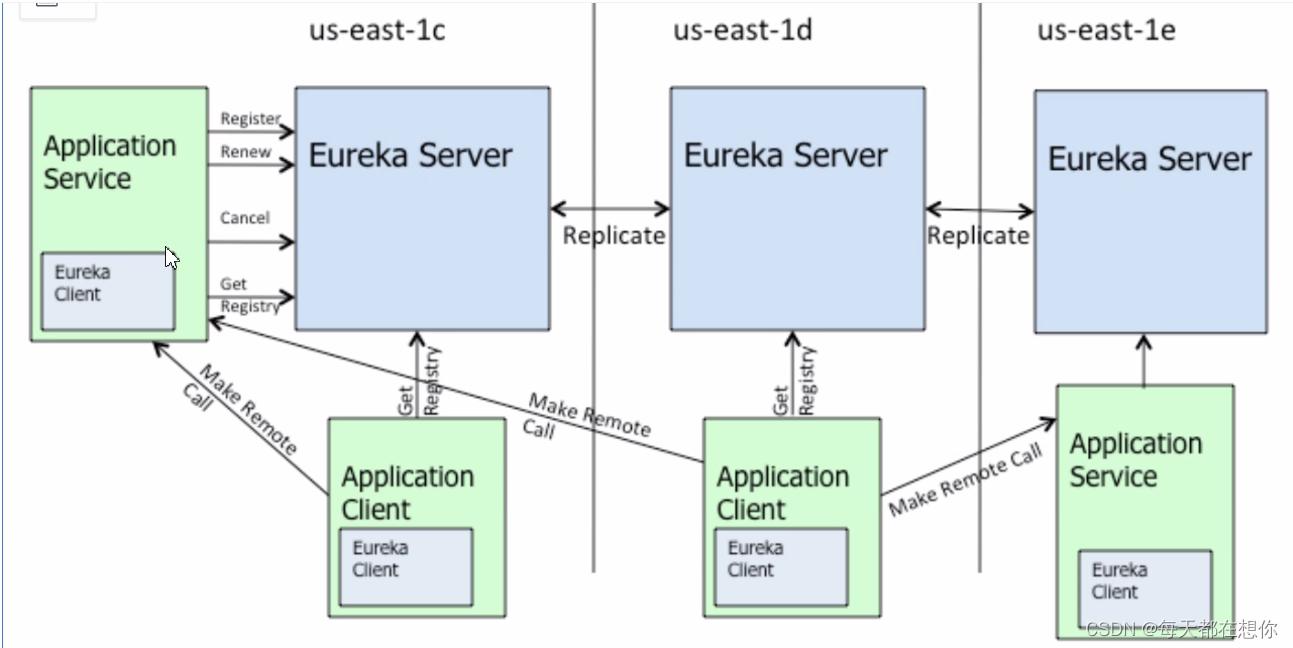
注意eureka作为注册中心,多台eureka server之间会进行信息交换,也就是服务同步

服务下线,eureka client在下线时,会有个回调函数,去回调server的服务剔除接口
只有知道了框架的核心功能点,看源码时,才能有的放矢
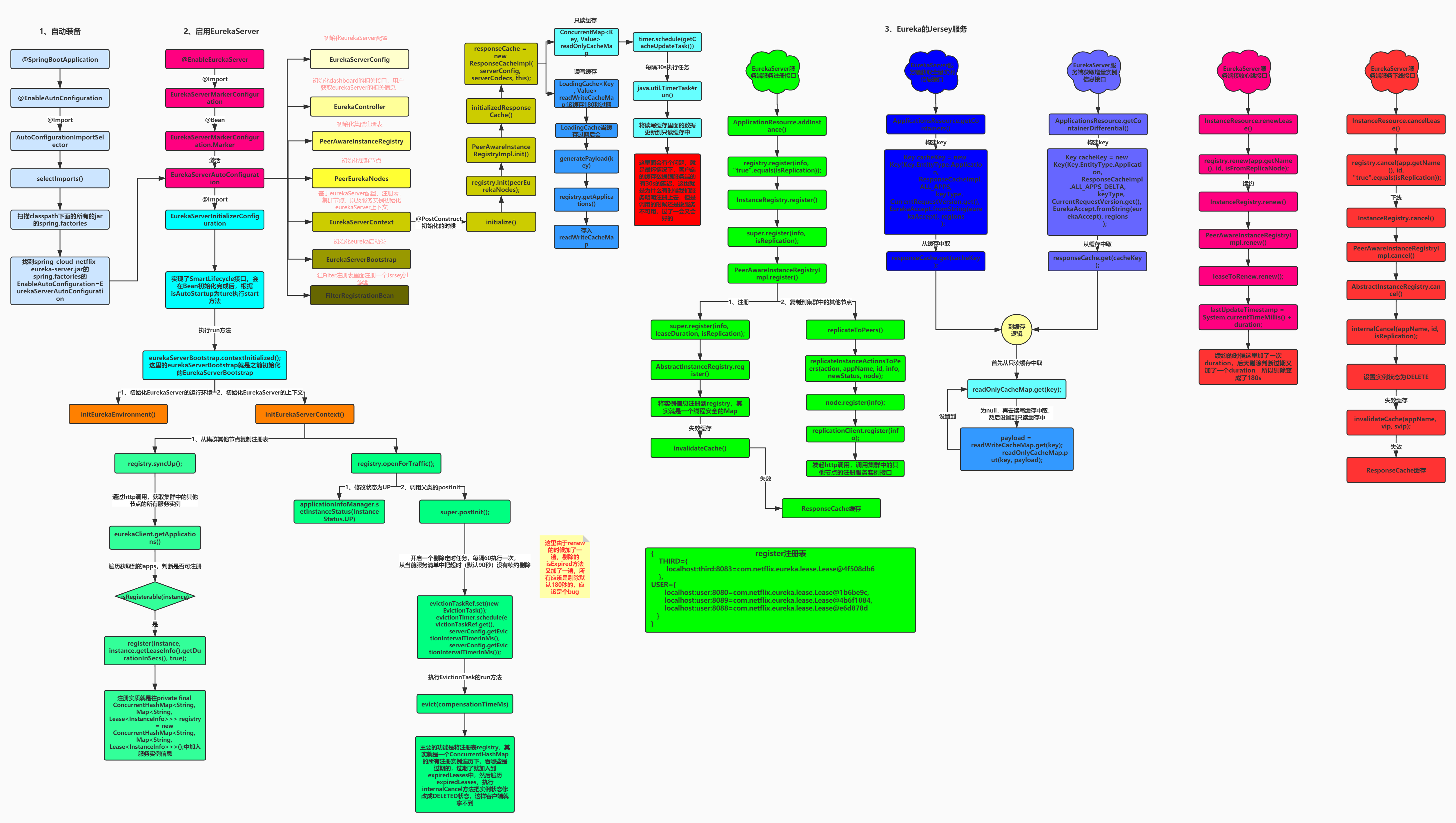
Euraka server启动的主线流程
总体流程图
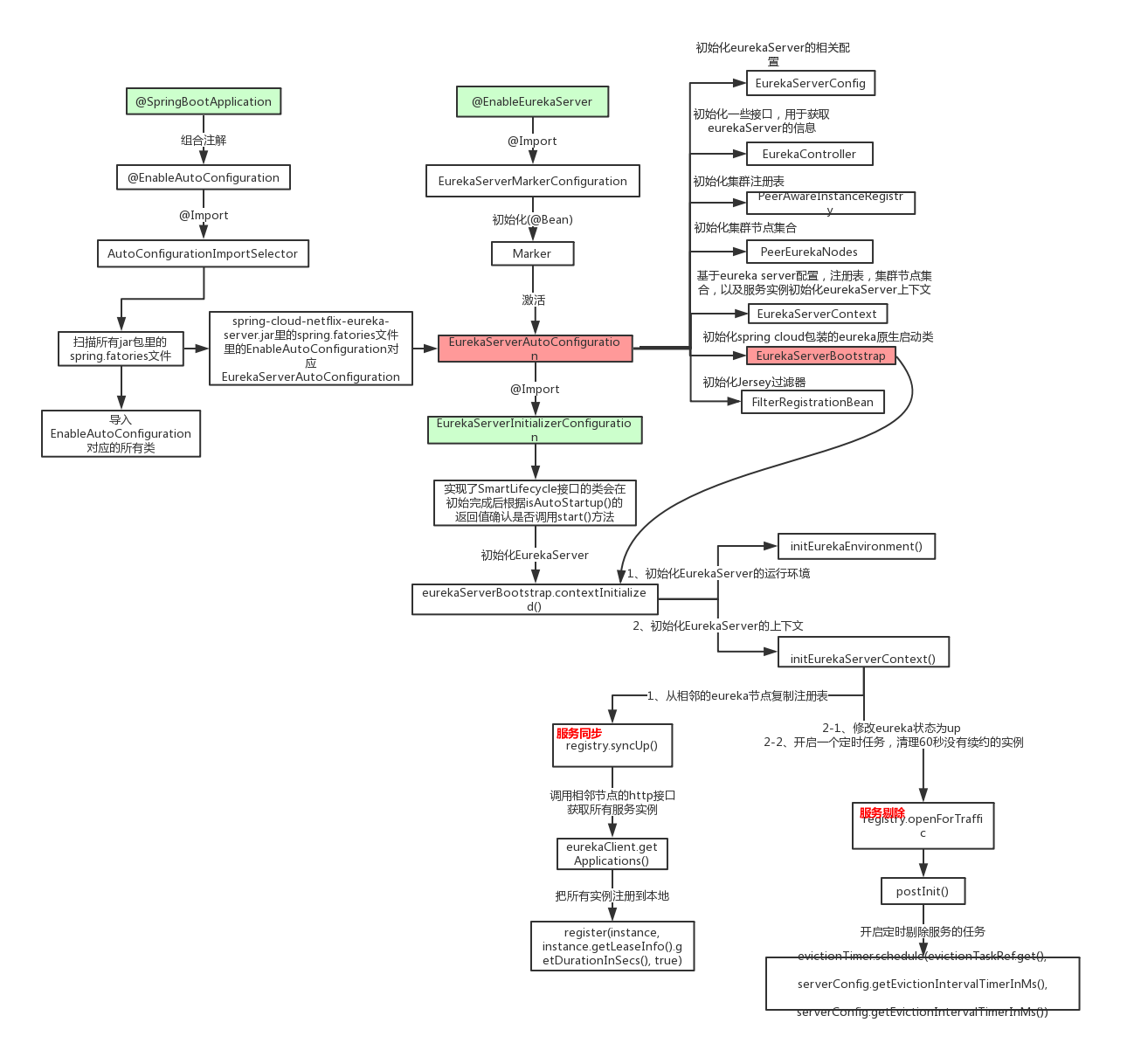
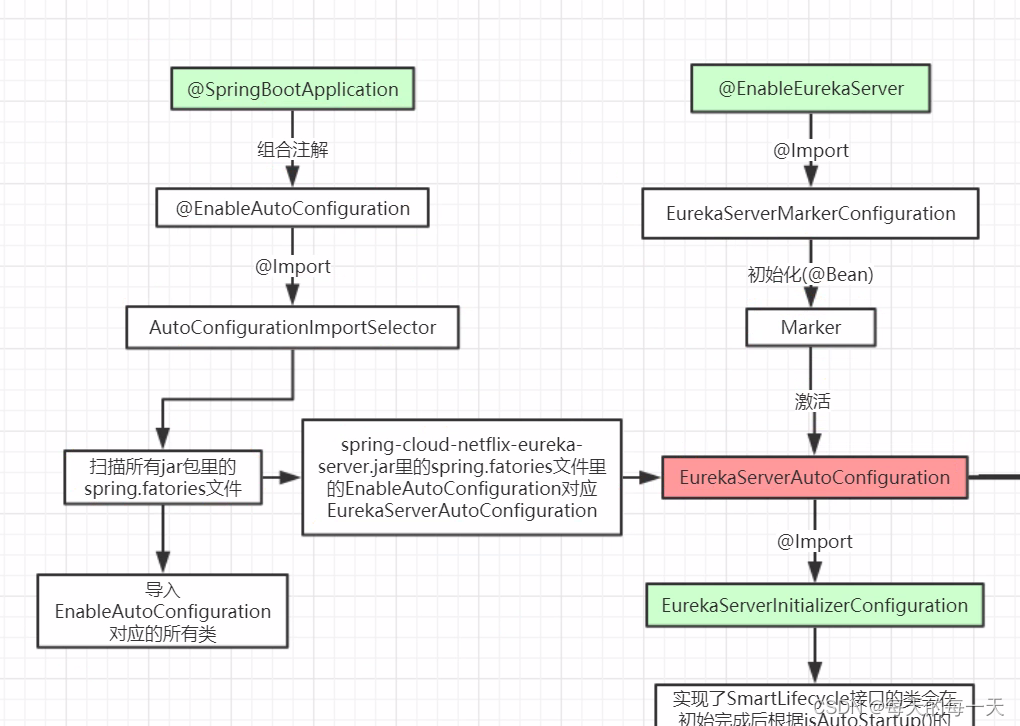
@EnableEurekaServer
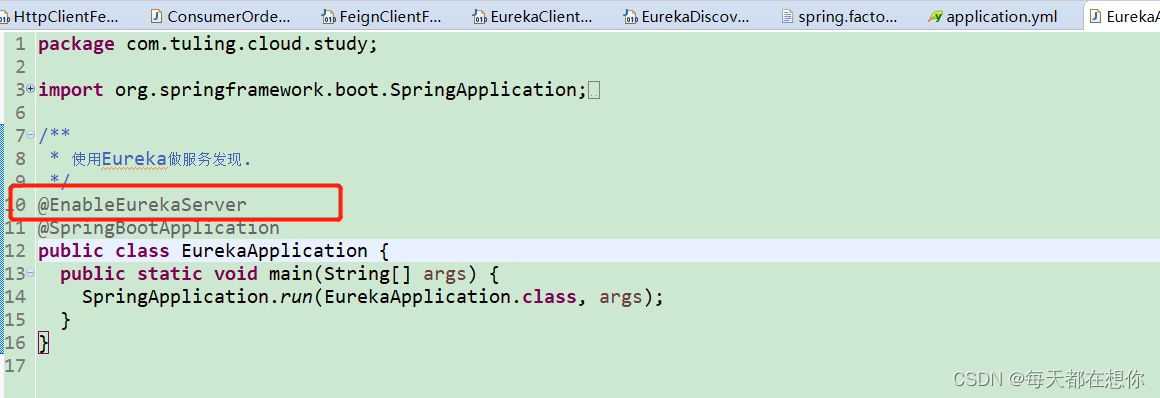
从这个注解开始,因为eureka实际上也就是一个基于springboot的项目,那既然是springboot,那么自然就会有一堆的自动装配AutoConfiguration,来为eureka的初始化,启动,运行等提供配置支持 ,所以,这个时候我们要做的,就是把这一堆的自动配置找出来
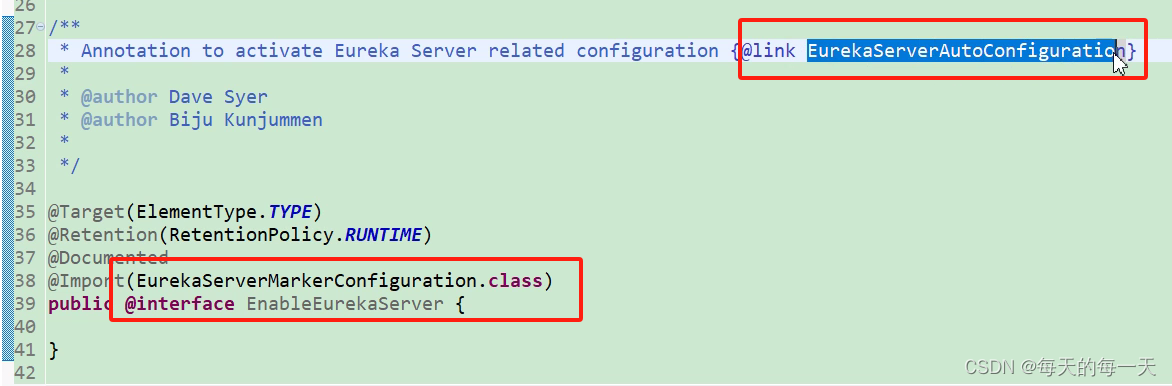
激活EurekaServerAutoConfiguration
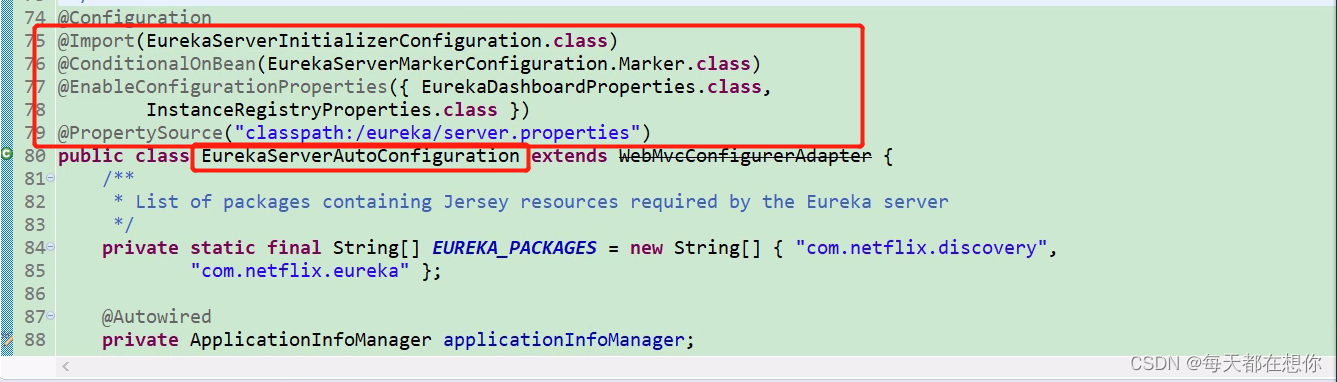
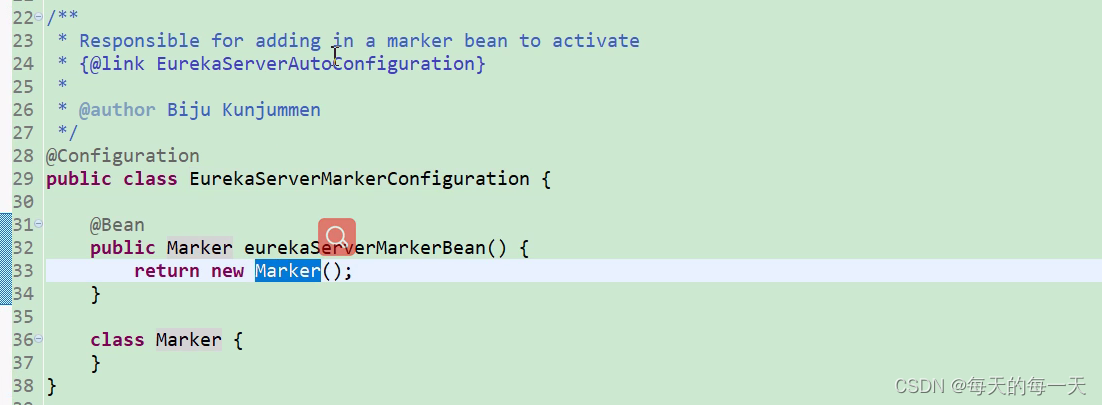
这里就是,@ConditionOnBean注解 + Marker类的组合使用的套路
Springboot先通过spi将EurekaServerAutoConfiguration扫描进来,但是EurekaServerAutoConfiguration身上有@ConditionOnBean(Marker)注解,@EnableEurekaServer就将Markr类自动装配进ioc容器中,从而激活EurekaServerAutoConfiguration
- 75行这种带有Initialize/Initializer的,就是看源码时需要重点关注的类,因为是与当前组件的初始化有关
- 一般的自动配置类上,都会有@EnableConfigurationProperties来激活当前自动配置类服务的组件所对应的属性配置类
- 一般的自动配置类上,都会有@Import来导入另外一些@Configuration配置类,有可能是单一职责原则不可能在一个XxxxAutoConfiguration中写太多内容
- 一般看自动配置类,优先看自动配置类中@Configuration修饰的内部类和@Bean修饰的服务支持bean
- 读源码,启动初始化的的过程中,这些带有Initialier,Bootstrap……,还有@Import中导入的,就是我们要重点看的
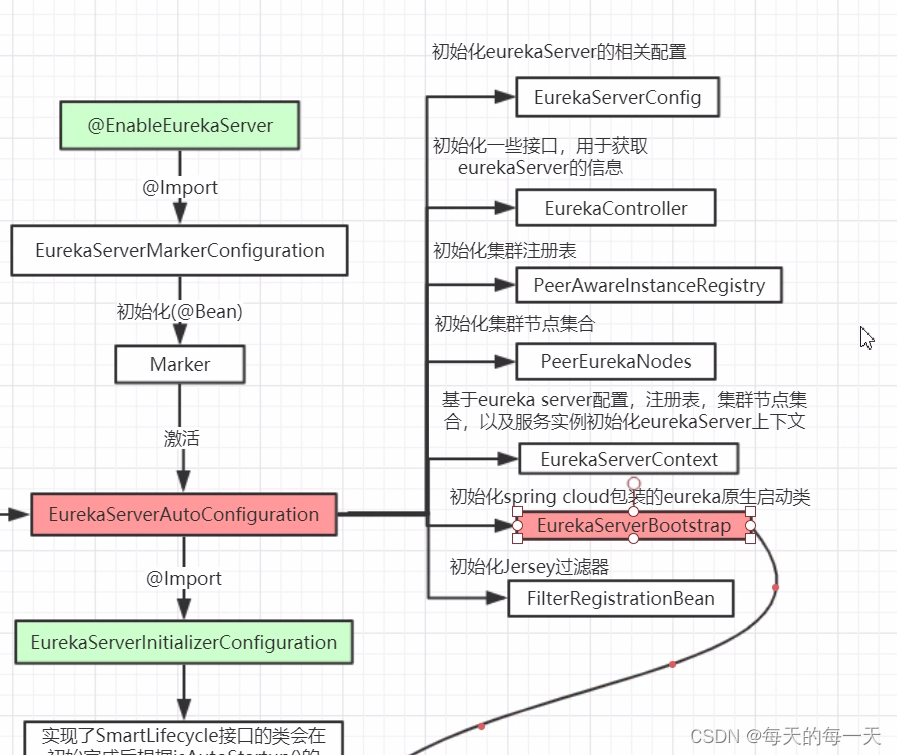
流程图
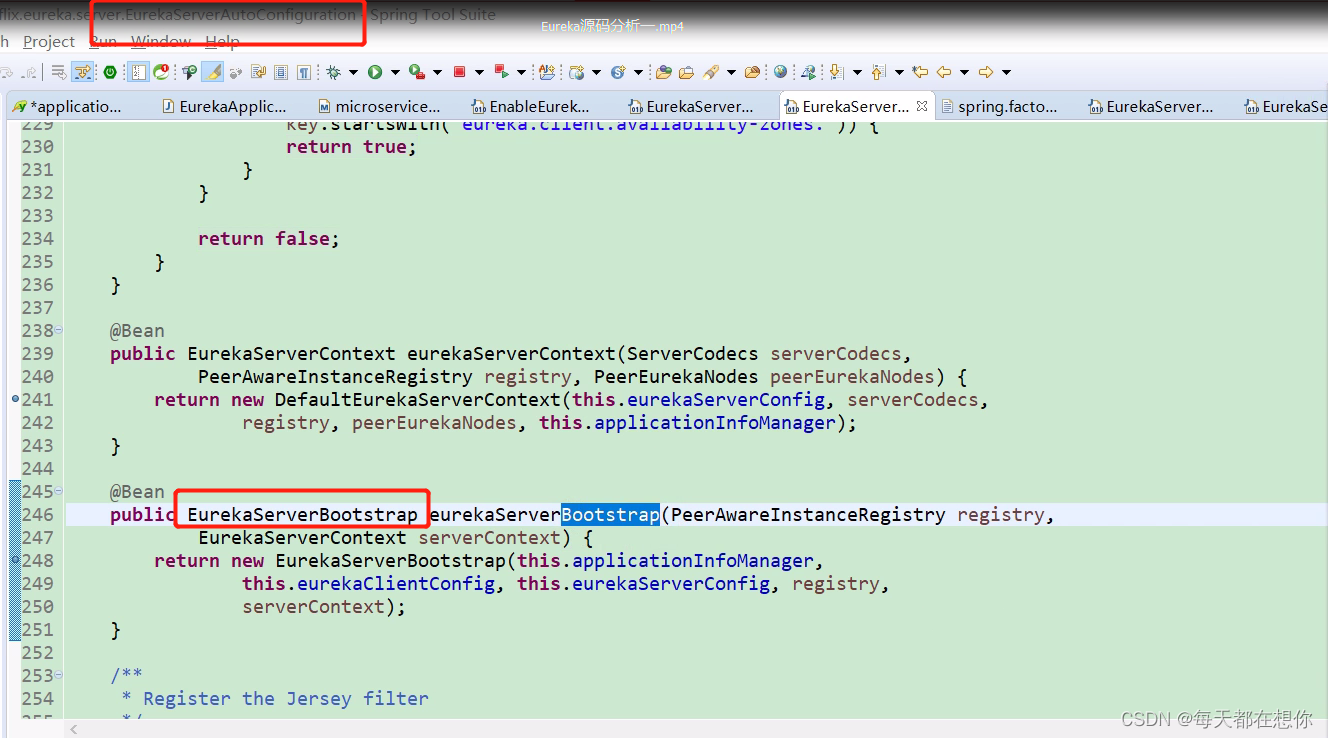
EurekaServerAutoConfiguration
内部有大量的关于eureka的自动配置,无非就是看这个自动配置类中,给我们的IOC容器中注入了哪些Bean
这里,EurekaServerAutoConfiguration这些自动配置类,一看就肯定知道是Spring cloud开发的,而不是Netflix eureka开发的。Spring cloud官方就是为了把Netflix eureka整合进spring cloud生态,所以才让自己的团队开发出EurekaServerAutoConfiguration这些自动配置类,来把EurekaServerBootstrap这样的Netflix eureka运行需要的核心API bean给注入到ioc容器中来
同理,spring cloud整合别的第三方框架时,肯定也是会为这个第三方框架写一堆的XxxxAutoConfiguration的自动配置类,比如spring cloud整合Nacos时,肯定就需要为Alibaba Nacos写一个NacosAutoConfiguration来将Nacos运行需要的核心API bean装配到IOC容器中来
EurekaServerInitializerConfiguration
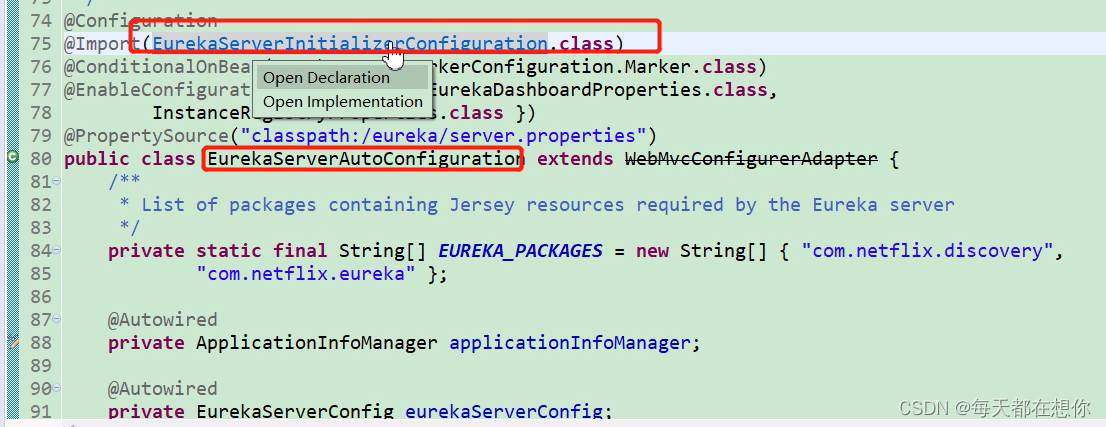
上面自动配置类通过@Bean注入的服务支持bean EurekaServerBootstrap,就在这里被@Autowired获取到了
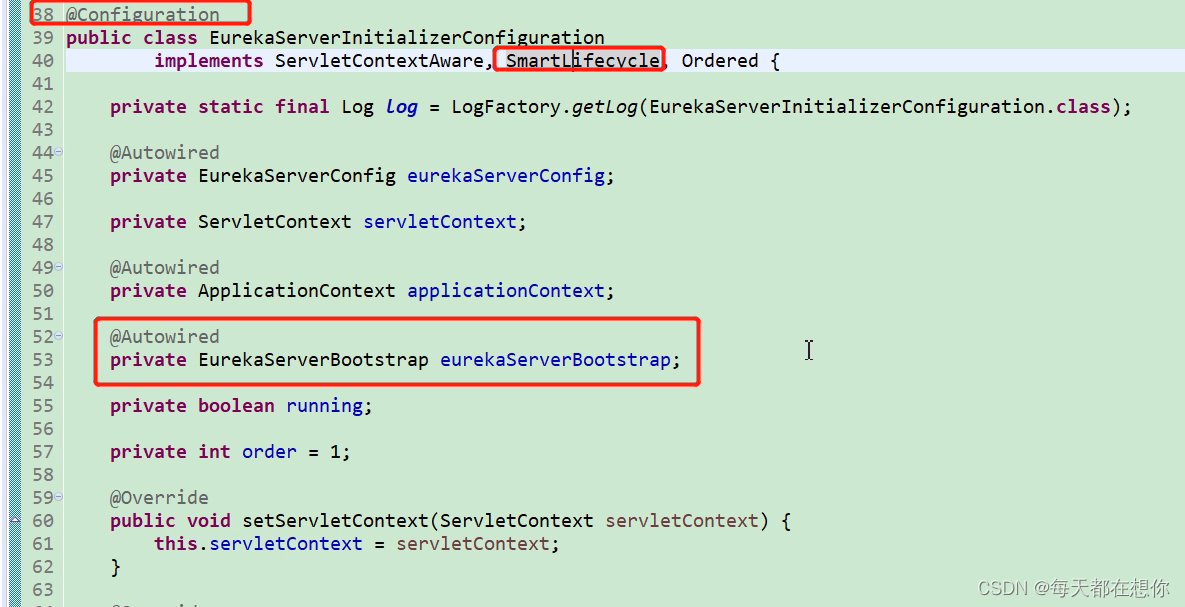
Eureka的原生启动类
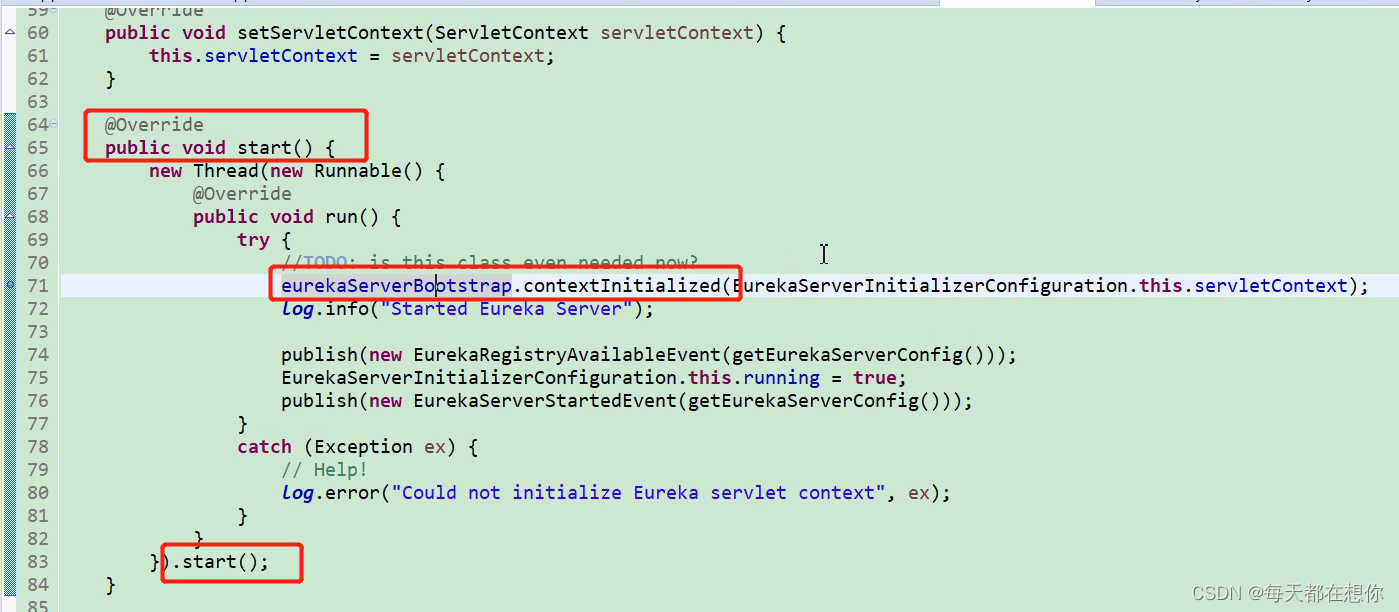
通过这里第72行的日志,就能看到Started Eureka Server,就能看到这里Eureka已经启动起来了,看主线日志也是一种学习方法。下面几行就是发布了几个事件,通过经验得知如果我们不关心这些事件,那么这几行代码也就不用关注了
这里就通过LifeCycle#start()方法,初始化出了一个eureka的服务器线程 ,这个方法在spring容器启动时,就会调用这个方法
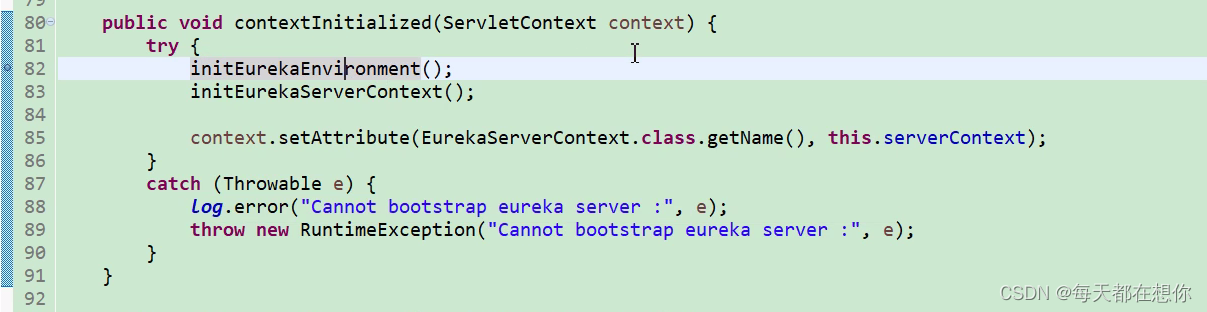
初始化Eureka运行环境、初始化Eureka服务器上下文
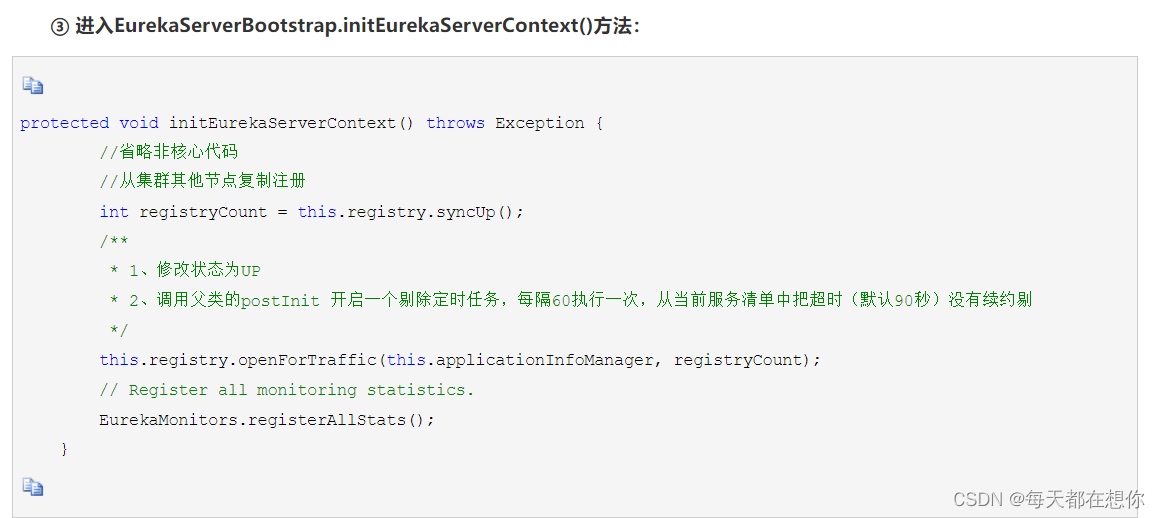
初始化eureka上下文环境
就包括开启一些后台服务定时任务,对应流程图如下:
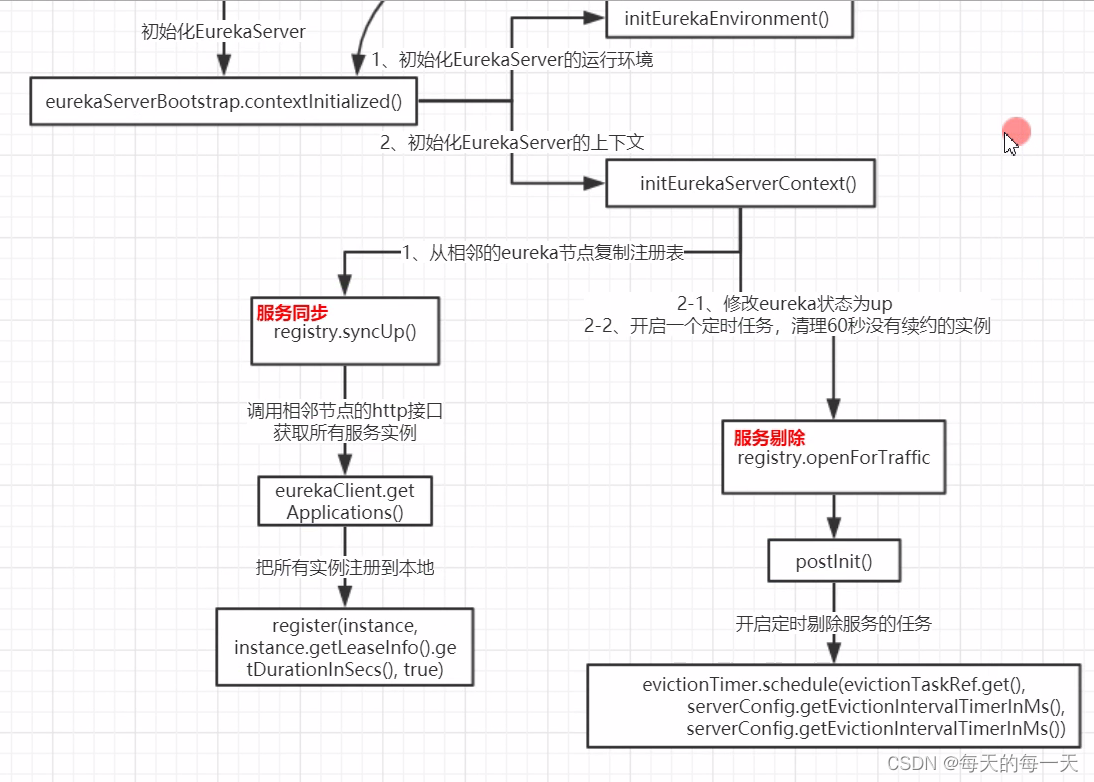
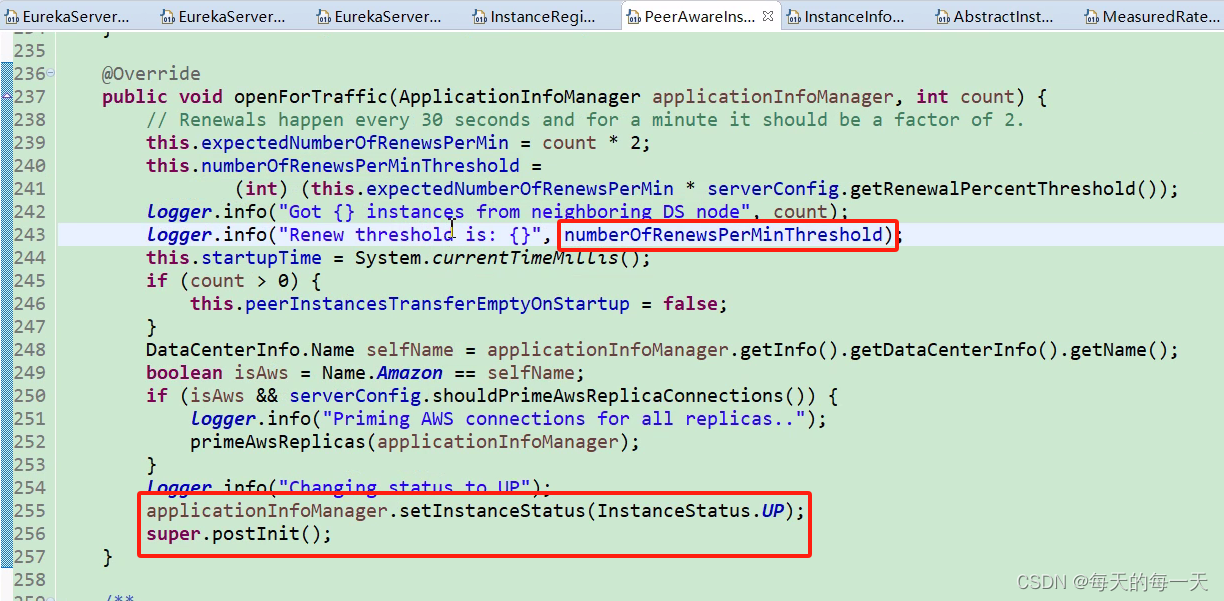

每60s,执行周期性的服务剔除Evict,把90s没有心跳续约renew的服务,给剔除掉
注:
每个中间件,都会有搞一个专门的组件参数配置类,用来存储所有与该组件运行有关的相关配置参数
一般,在该配置类中会定义多个字段,用来存储该中间件运行时需要的各个参数,并且还会为该参数设置一个默认值
如果,用户需要自定义这些参数值,就在配置文件中配置这些参数,然后组件自己负责把这些配置文件中的参数读取进来,覆盖掉这些默认值
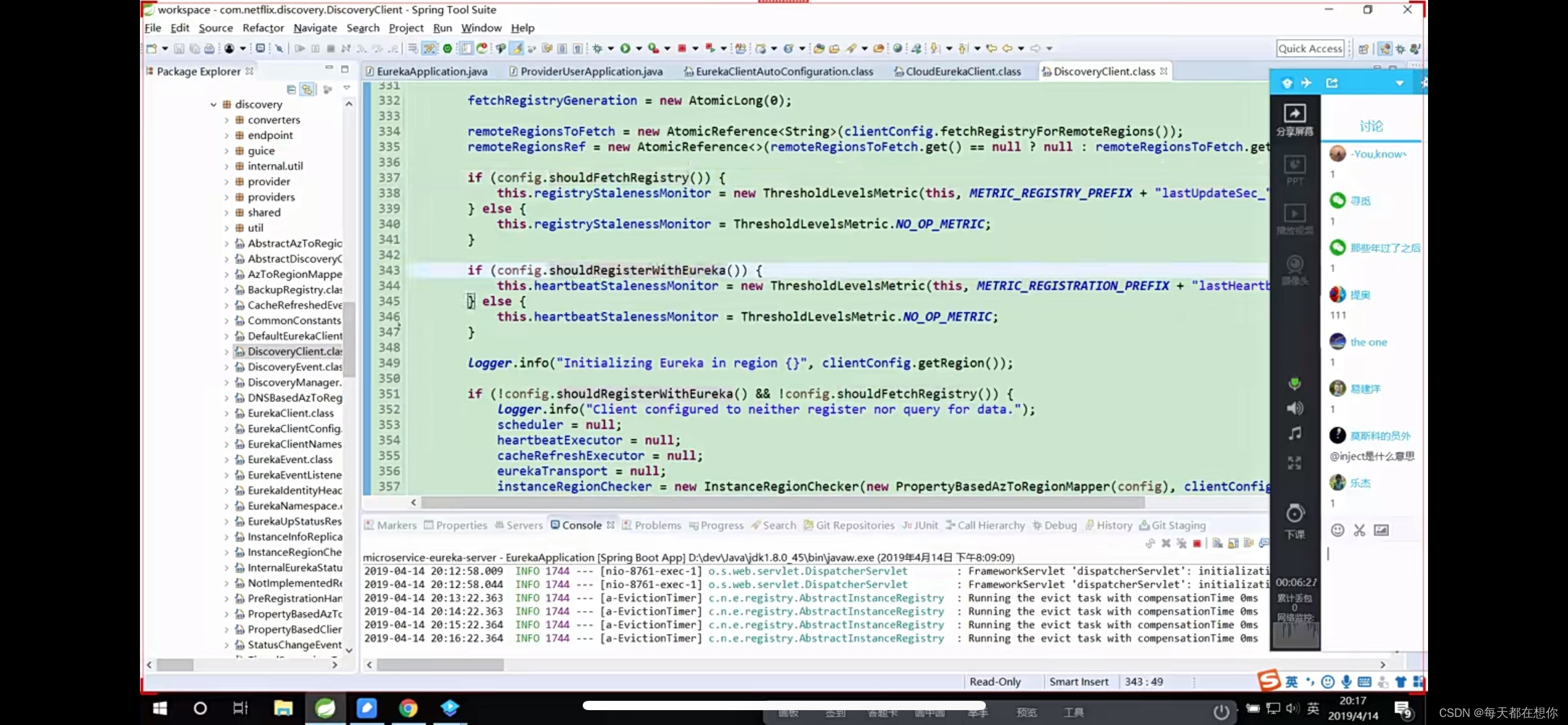
这两个if也就对应了客户端两个关于euraka的配置一个关于fetch的,一个关于registry的。可以了解到配置文件中暴露的一个个配置项,实际上在代码中也就对应着一个个的if判断
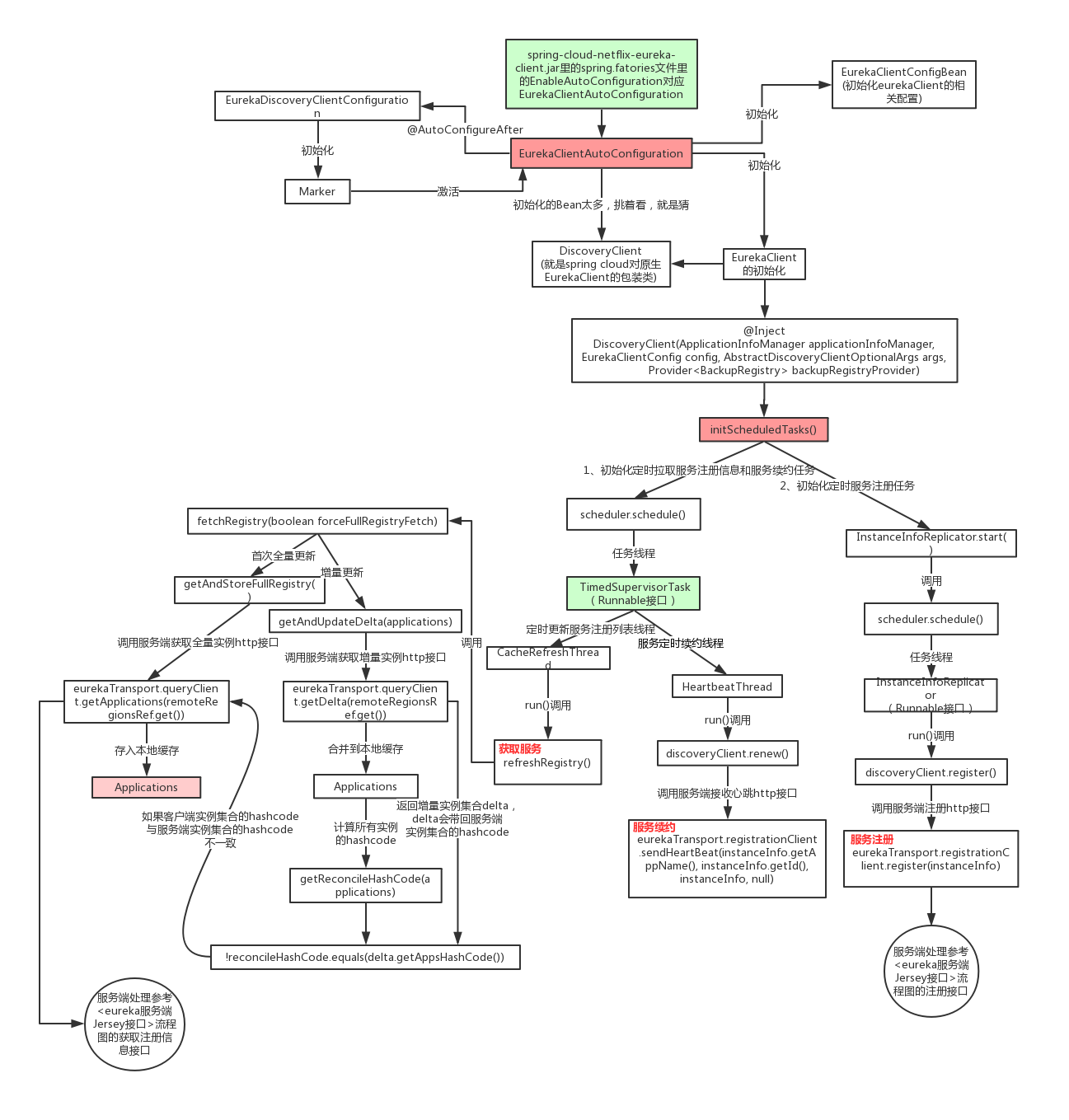
Euraka client启动的主线流程
总体流程图
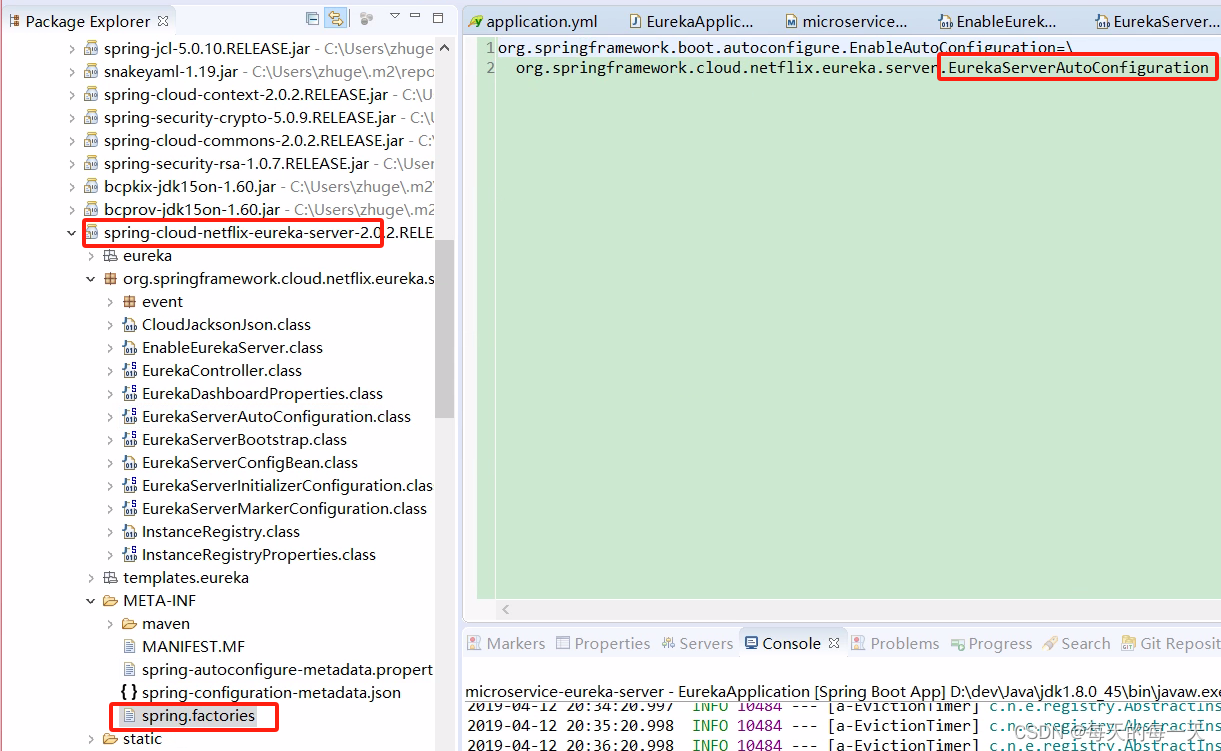
可以看到这里并没有找到入口,没有组件的@EnableXxxxx之类的注解,那么我们就需要去Springboot项目通用的找入口的地方,也就是jar包的SPI spring.factories文件中
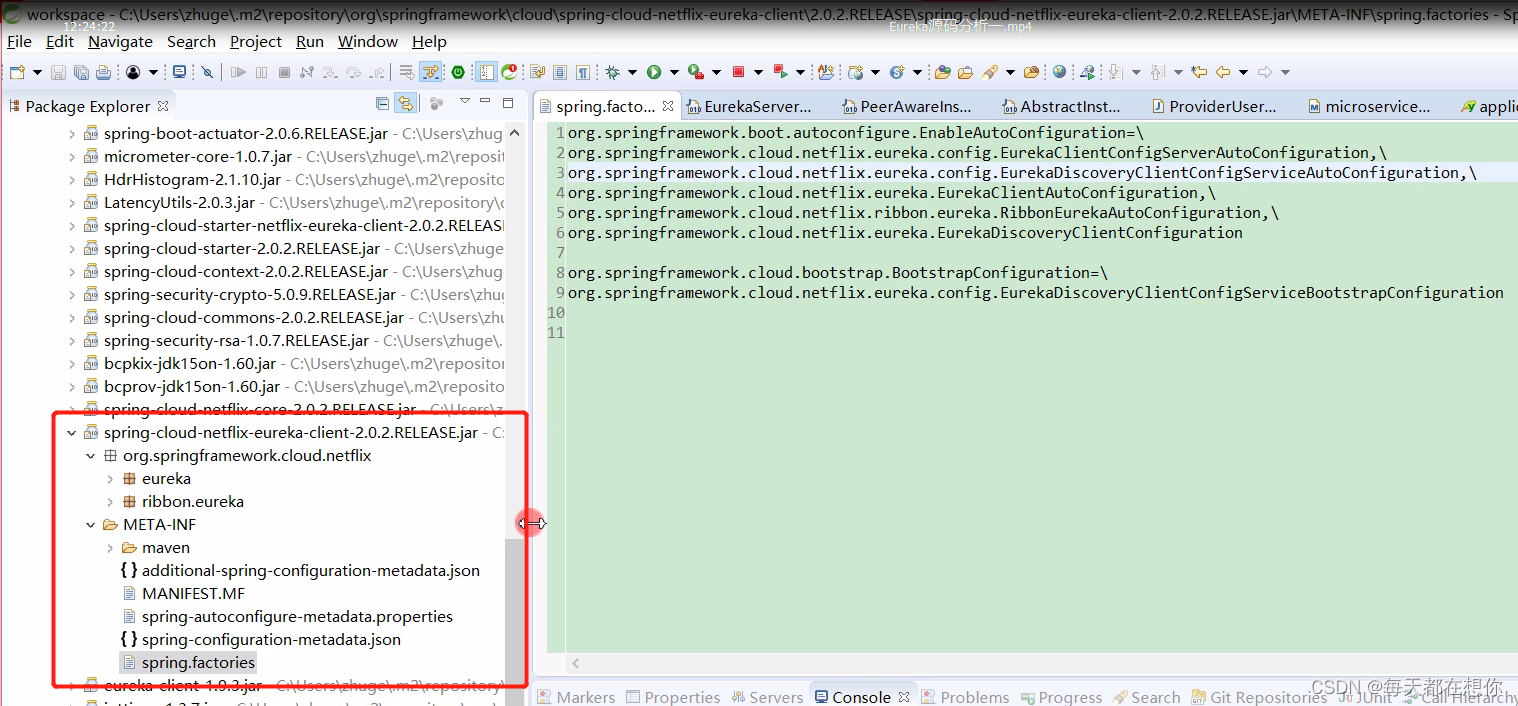
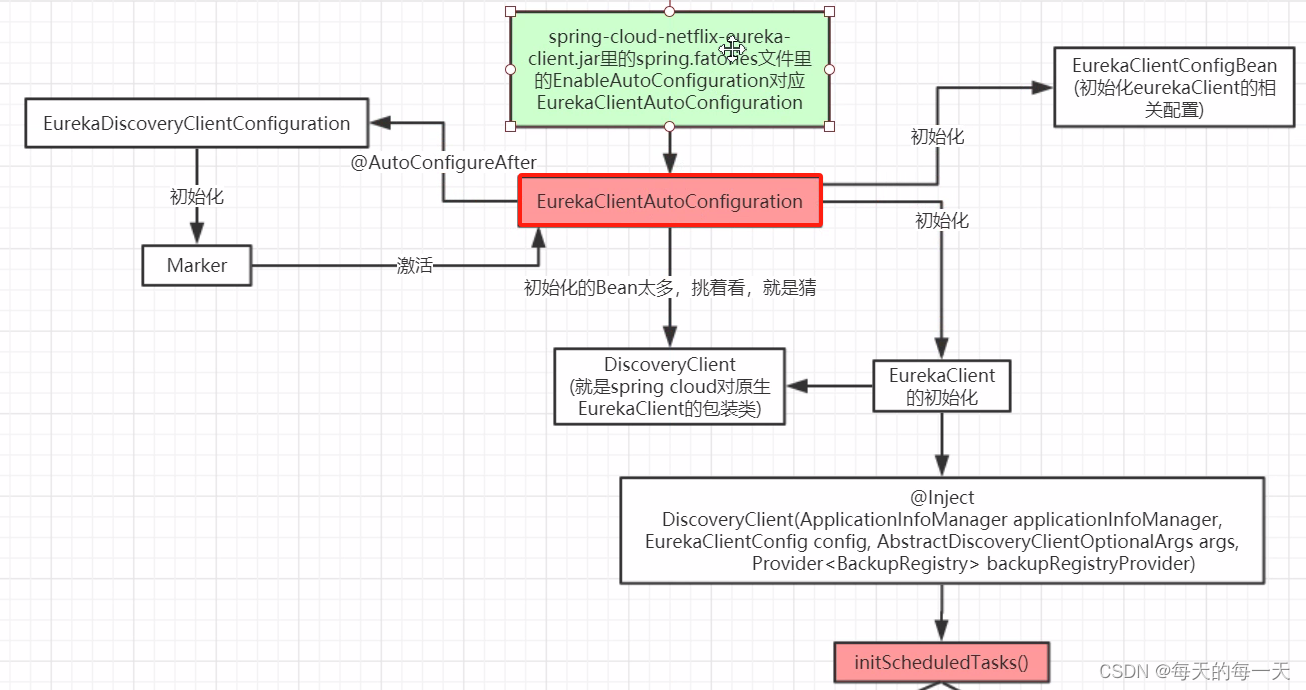
EurekaClientAutoConfiguration,客户端的启动入口类,Springboot的代码都是写的很规范的,客户端服务端都是很一致很对称的,前面服务端已经有了一个EurekaServerAutoConfiguration
EurekaClientAutoConfiguration
客户端的启动入口类
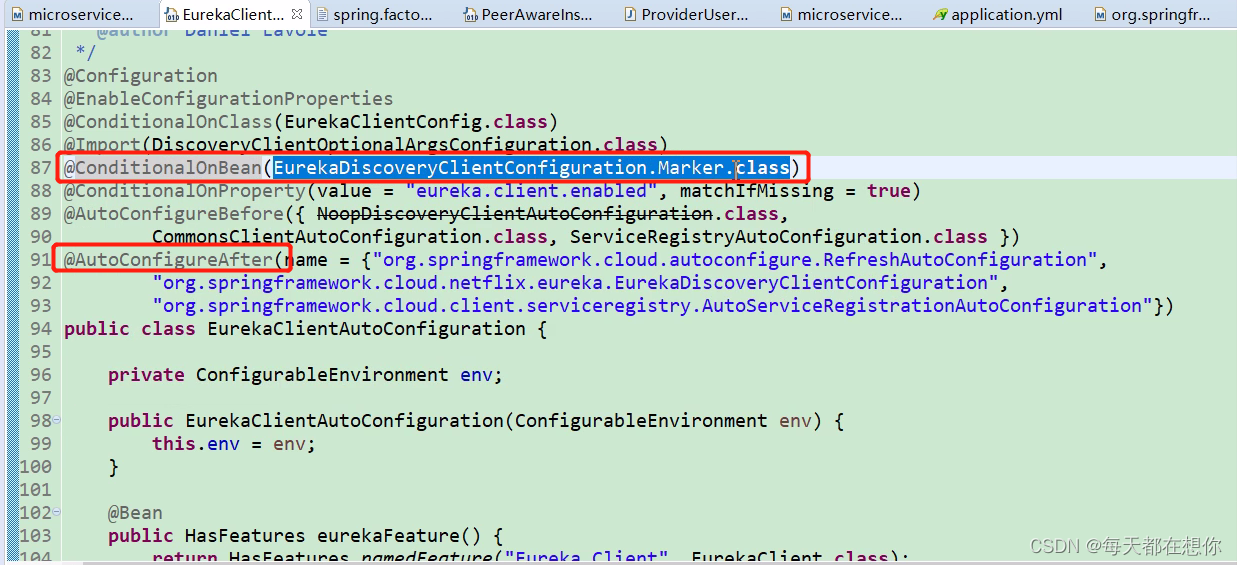
首先看当前自动配置类的前置启动条件,比如@ConditionOnBean、@AutoConfigureAfter
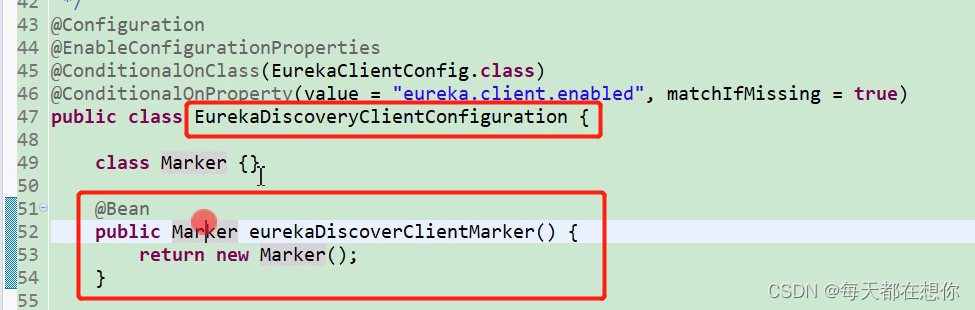
这个EurekaDiscoveryClientConfiguration也是前面jar包的META-INFO/spring.fatories文件中已经注入进来了
又是标记Marker类,激活自动配置类的写法
@AutoConfigureAfter(XXX),就是当前自动配置类EurekaDiscoveryClientConfiguration在XXX后面执行,也就是91、92、93三行是当前自动配置类的前置条件:就是springboot在启动了91、92、93三个配置类后,才会去启动加载当前自动配置类。而只有在加载当前配置类时,才会加载当前配置类上面的@Import注解
SpringCloud Eureka和Netflix Eureka的关联
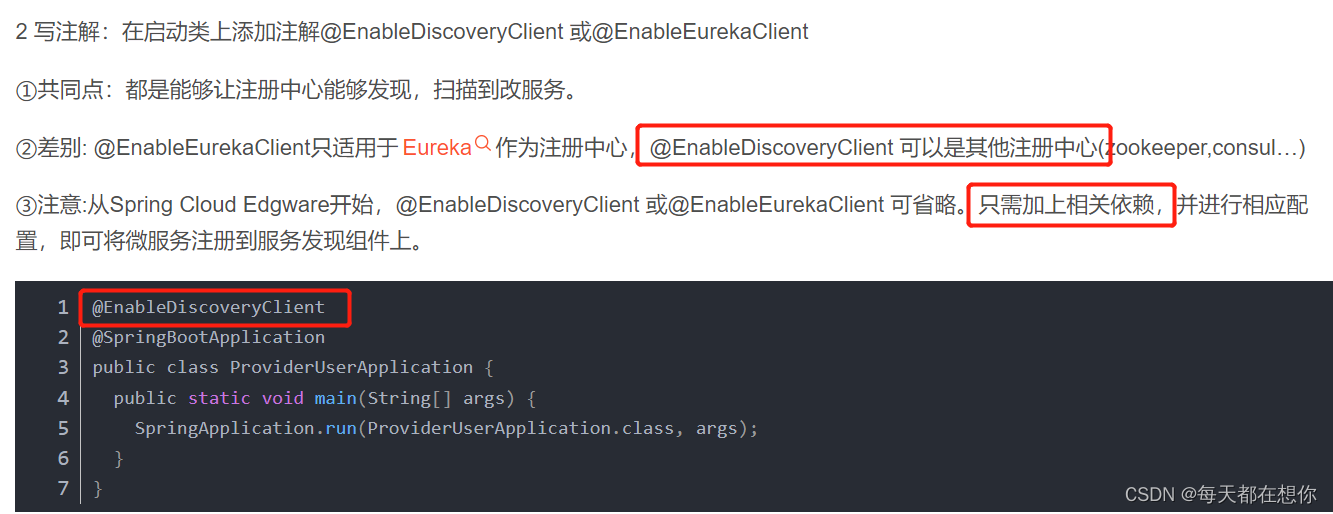
EurekaClientAutoConfiguration内部就会初始化下面的第206行的bean
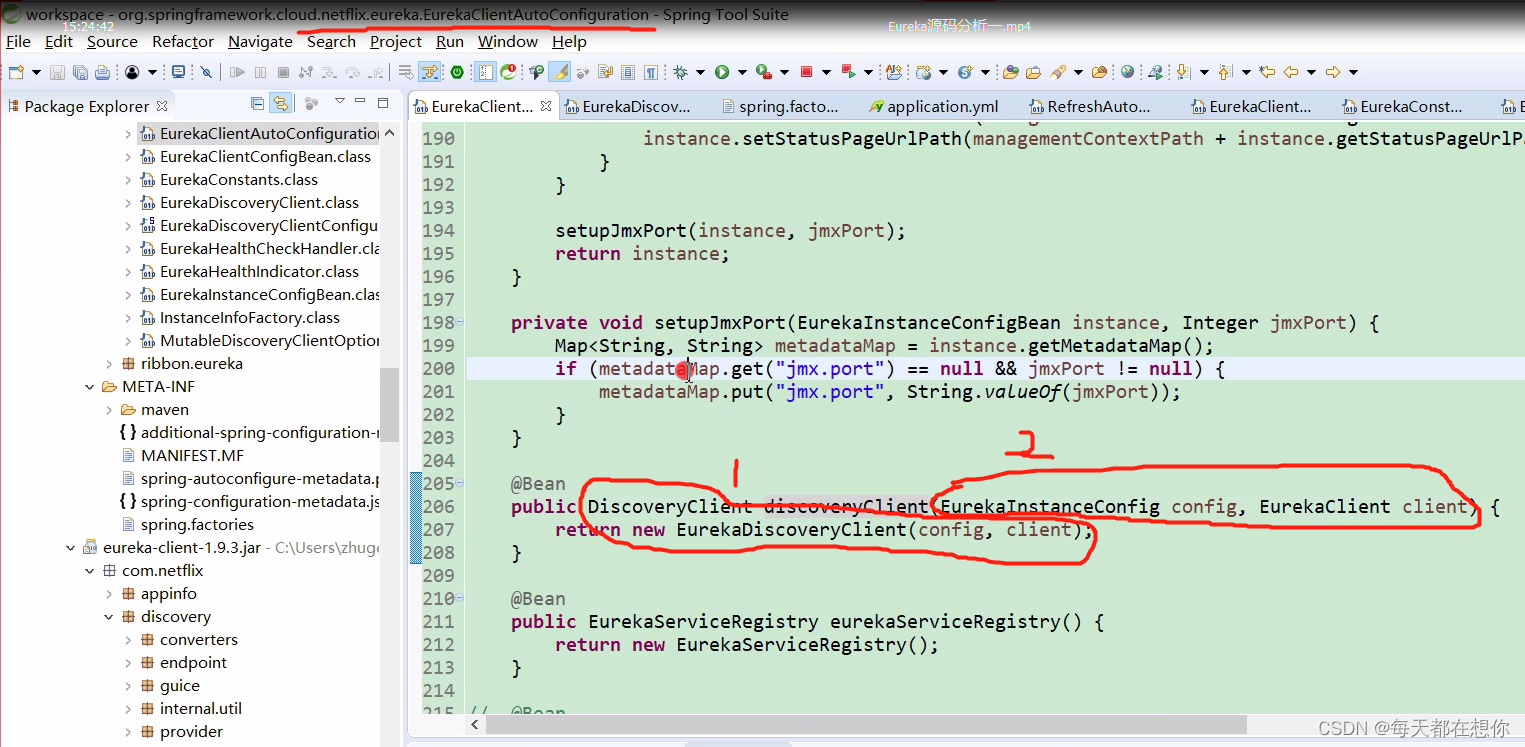
上面1就是Spring cloud包装后的类,比如DiscoveryClient接口就是Spring cloud为了统一市面上所有的注册中心的客户端访问服务端的方式而统一提供的一个规范接口,EurekaDiscoveryClient是Spring cloud为了整合Netflix eureka进来而提供的DiscoveryClient接口的一个实现类,EurekaDiscoveryClient内部实际上还是把真正做事的逻辑委托给了Netflix eureka的原生API EurekaClient
而2,EurekaClient就是Netflix eureka的原生API
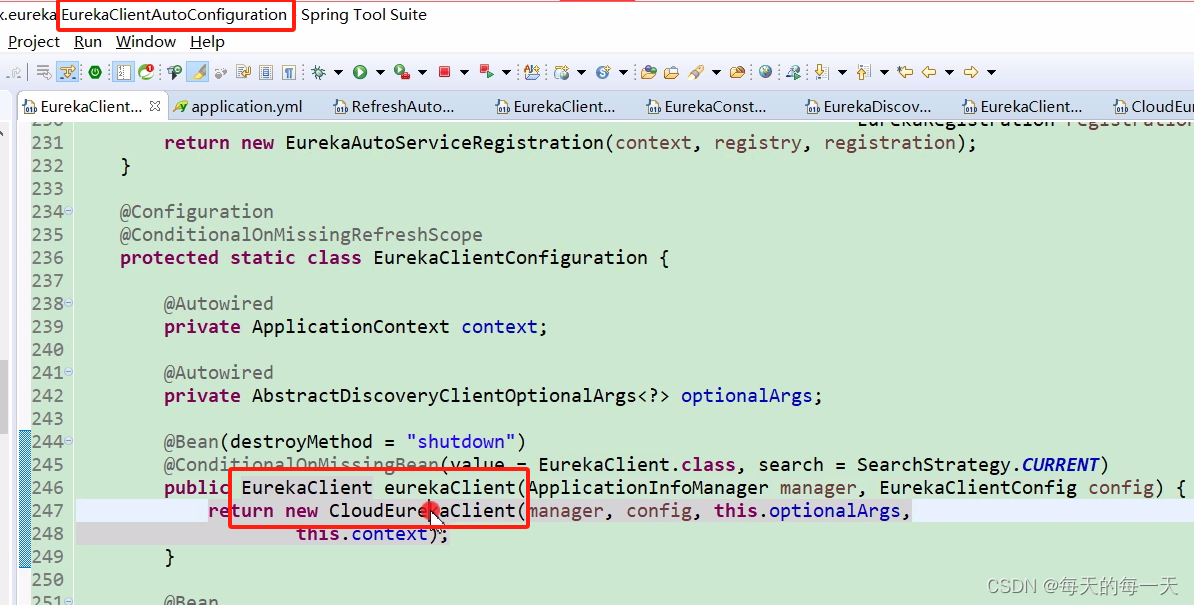
- Netflix eureka本身是和spring cloud没什么关系的,Spring Cloud Eureka是Spring Cloud官方利用springboot自动装配的技术,把Netflix eureka给集成进spring cloud生态的。集成后方便用户的使用,而避免用户再去直接接触Netflix eureka暴露出来的一些原生API
- 把Netflix eureka给集成进spring cloud生态的方式,就是Spring cloud利用spring boot的一些自动装配技术,把Netflix Euraka中启动需要的一些核心bean自动装配进ioc容器中,仅给外部用户在配置文件中暴露一些配置项
- Spring Cloud官方提供这些统一的注解,一些统一的接口类,就是想第三方组件都能实现这些接口类,然后就能无差别的使用spring cloud官方提供的统一的功能注解,而不用再修改源代码,只需要修改依赖的第三方组件jar包。比如,spring cloud官方提供的@LoadBalanced注解,无论注册中心换成eureka还是nacos,@LoadBalanced注解都能无缝使用,无需再次修改源代码
Nacos支持spring cloud的原生注解
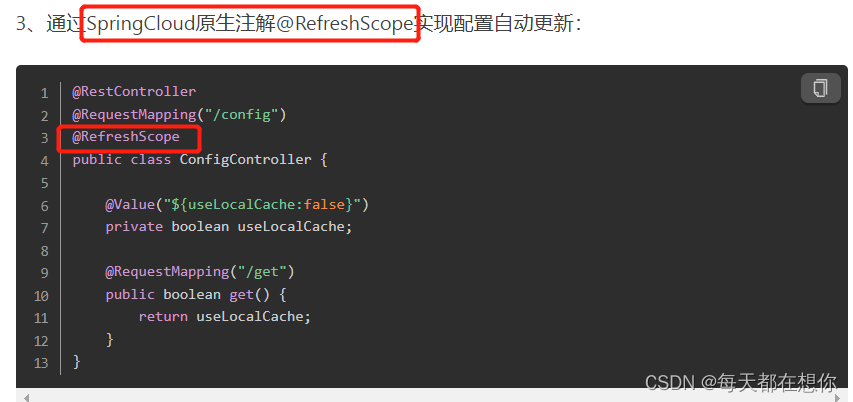
打个比方,如果Eureka没有实现Spring cloud官方提供的统一接口,那么如果用户程序想要实现配置自动刷新就无法使用上面的spring cloud原生注解@RefreshScope,而只能使用和Eureka框架绑定的特定的配置自动刷新注解。这样,也就无法实现只替换依赖jar不修改源代码就能替换掉当前注册中心的目的

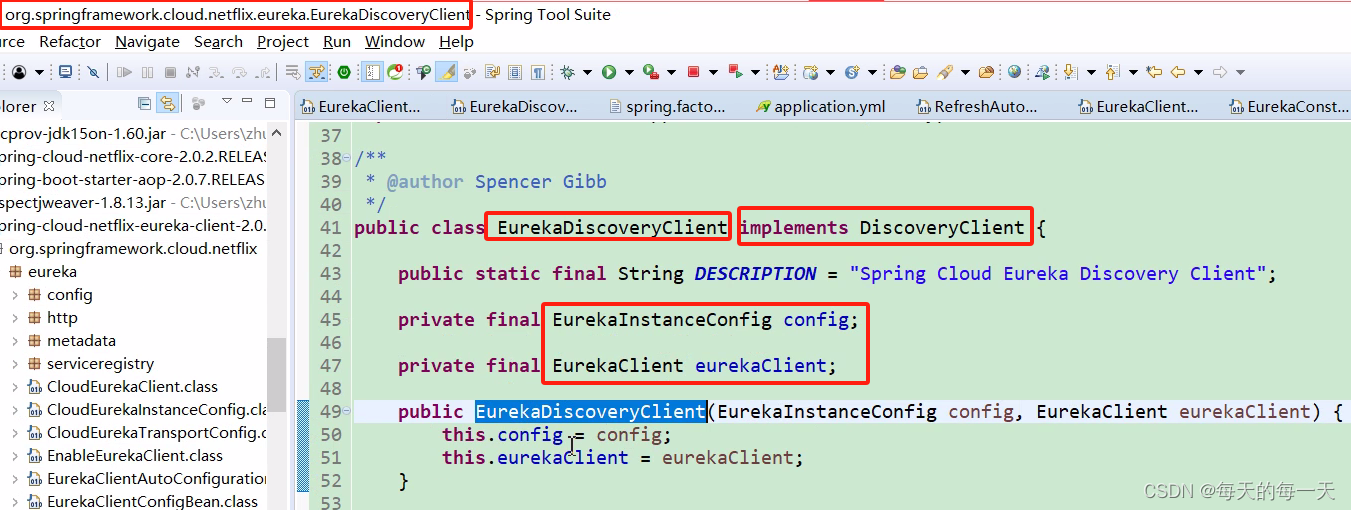
可以看到,org.springframework.cloud.client.discovery.DiscoveryClient接口是Spring Cloud官方提供的统一接口类,而这个org.springframework.cloud.netflix.eureka.EurekaDiscoveryClient是spring cloud的中间件开发团队为了把Netflix eureka集成到Spring Cloud生态体系中来而开发的适配接口实现,这实际上也有点类似于适配器设计模式
核心初始化代码
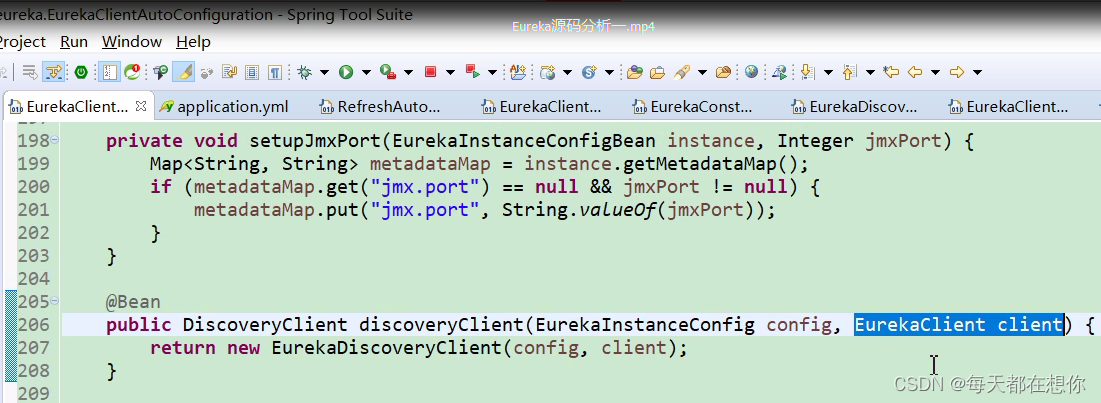
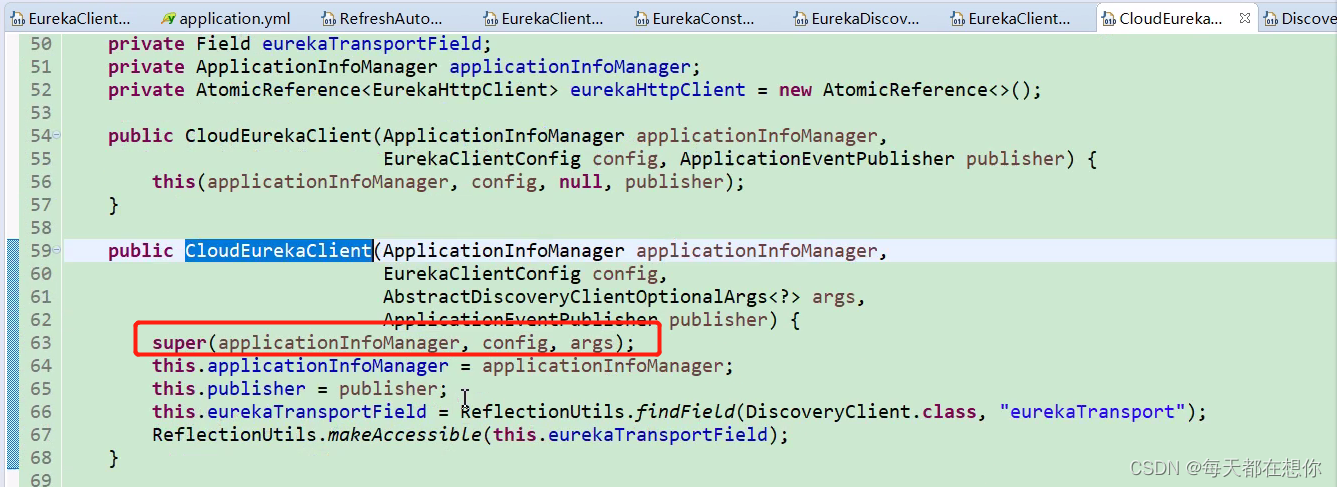
CloudEurekaClient的父类就是DiscoveryClient(注意这里的DiscoveryClient是Netflix eureka原生的实现类,不是Spring cloud 官方提供的统一服务发现DiscoveryClient接口) ,上面第63行就会调起下面的这个构造函数com.netflix.discovery.DiscoveryClient()
public com.netflix.discovery.class DiscoveryClient implements EurekaClient {
@Inject
DiscoveryClient(ApplicationInfoManager applicationInfoManager, EurekaClientConfig config, AbstractDiscoveryClientOptionalArgs args, Provider<BackupRegistry> backupRegistryProvider) {
if (config.shouldRegisterWithEureka()) {
this.heartbeatStalenessMonitor = new ThresholdLevelsMetric(this, "eurekaClient.registration.lastHeartbeatSec_", new long[]{15L, 30L, 60L, 120L, 240L, 480L});
} else {
this.heartbeatStalenessMonitor = ThresholdLevelsMetric.NO_OP_METRIC;
}
logger.info("Initializing Eureka in region {}", this.clientConfig.getRegion());
if (!config.shouldRegisterWithEureka() && !config.shouldFetchRegistry()) {
logger.info("Client configured to neither register nor query for data.");
// xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
} else {
try {
this.scheduler = Executors.newScheduledThreadPool(2, (new ThreadFactoryBuilder()).setNameFormat("DiscoveryClient-%d").setDaemon(true).build());
// 心跳服务线程池,单线程
this.heartbeatExecutor = new ThreadPoolExecutor(1, this.clientConfig.getHeartbeatExecutorThreadPoolSize(), 0L, TimeUnit.SECONDS, new SynchronousQueue(), (new ThreadFactoryBuilder()).setNameFormat("DiscoveryClient-HeartbeatExecutor-%d").setDaemon(true).build());
this.cacheRefreshExecutor = new ThreadPoolExecutor(1, this.clientConfig.getCacheRefreshExecutorThreadPoolSize(), 0L, TimeUnit.SECONDS, new SynchronousQueue(), (new ThreadFactoryBuilder()).setNameFormat("DiscoveryClient-CacheRefreshExecutor-%d").setDaemon(true).build());
this.eurekaTransport = new DiscoveryClient.EurekaTransport();
this.scheduleServerEndpointTask(this.eurekaTransport, args);
Object azToRegionMapper;
if (this.clientConfig.shouldUseDnsForFetchingServiceUrls()) {
azToRegionMapper = new DNSBasedAzToRegionMapper(this.clientConfig);
} else {
azToRegionMapper = new PropertyBasedAzToRegionMapper(this.clientConfig);
}
if (null != this.remoteRegionsToFetch.get()) {
((AzToRegionMapper)azToRegionMapper).setRegionsToFetch(((String)this.remoteRegionsToFetch.get()).split(","));
}
this.instanceRegionChecker = new InstanceRegionChecker((AzToRegionMapper)azToRegionMapper, this.clientConfig.getRegion());
} catch (Throwable var9) {
throw new RuntimeException("Failed to initialize DiscoveryClient!", var9);
}
// 读取配置文件中的配置,就在这里生效:比如在配置文件中配置,eureka server端就不需要进行注册,也不需要拉取
if (this.clientConfig.shouldFetchRegistry() && !this.fetchRegistry(false)) {
this.fetchRegistryFromBackup();
}
if (this.preRegistrationHandler != null) {
this.preRegistrationHandler.beforeRegistration();
}
if (this.clientConfig.shouldRegisterWithEureka() && this.clientConfig.shouldEnforceRegistrationAtInit()) {
try {
if (!this.register()) {
throw new IllegalStateException("Registration error at startup. Invalid server response.");
}
} catch (Throwable var8) {
logger.error("Registration error at startup: {}", var8.getMessage());
throw new IllegalStateException(var8);
}
}
/*
========================================================================
启动心跳等各种定时任务
========================================================================
*/
this.initScheduledTasks();
try {
Monitors.registerObject(this);
} catch (Throwable var7) {
logger.warn("Cannot register timers", var7);
}
DiscoveryManager.getInstance().setDiscoveryClient(this);
DiscoveryManager.getInstance().setEurekaClientConfig(config);
this.initTimestampMs = System.currentTimeMillis();
logger.info("Discovery Client initialized at timestamp {} with initial instances count: {}", this.initTimestampMs, this.getApplications().size());
}
}
}核心就是这行代码this.initScheduledTasks(); 启动心跳等各种定时任务
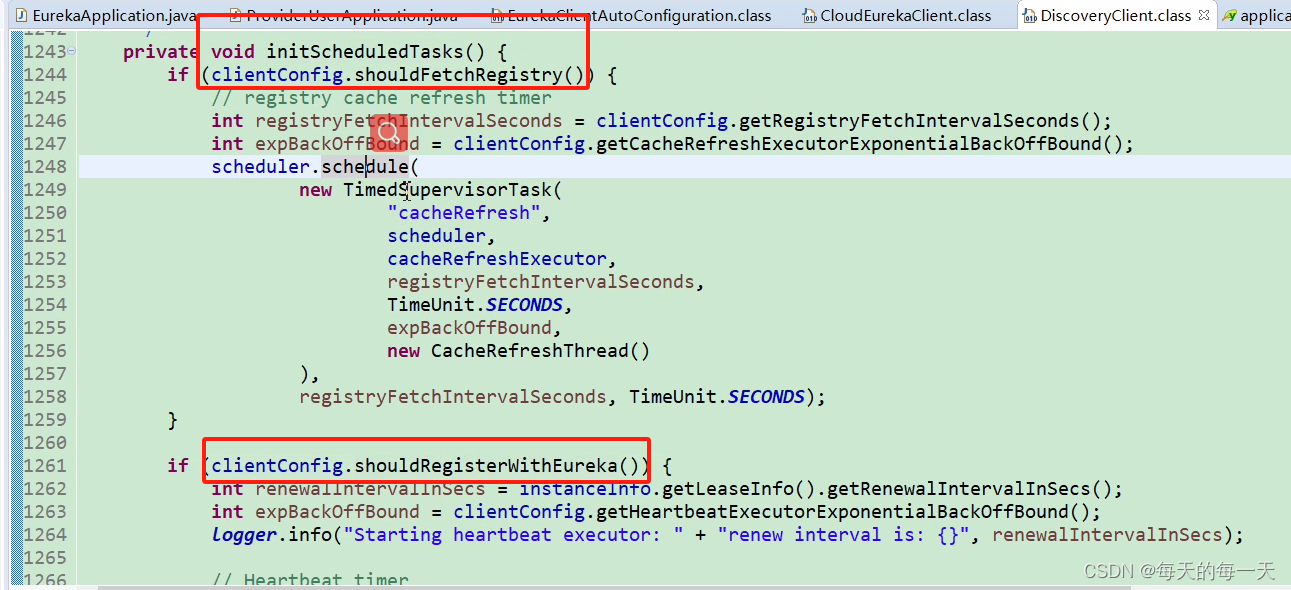
这两个参数不配置默认也是true,
服务获取
服务获取-客户端
CacheRefreshThread
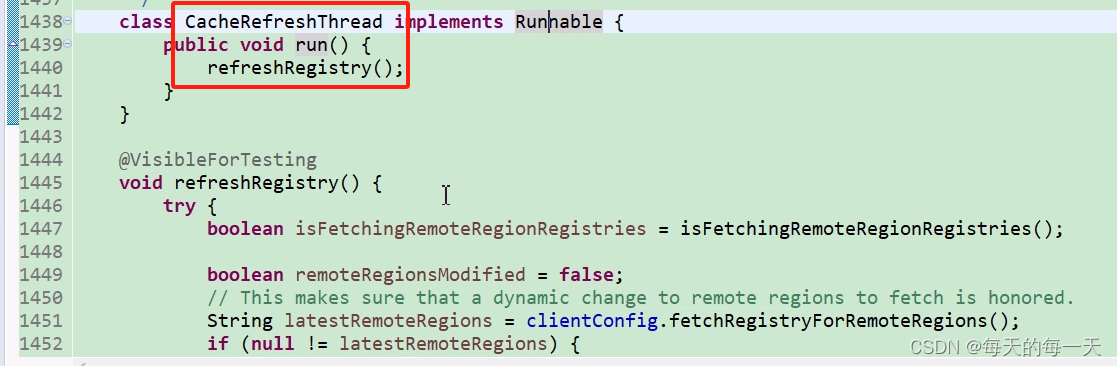

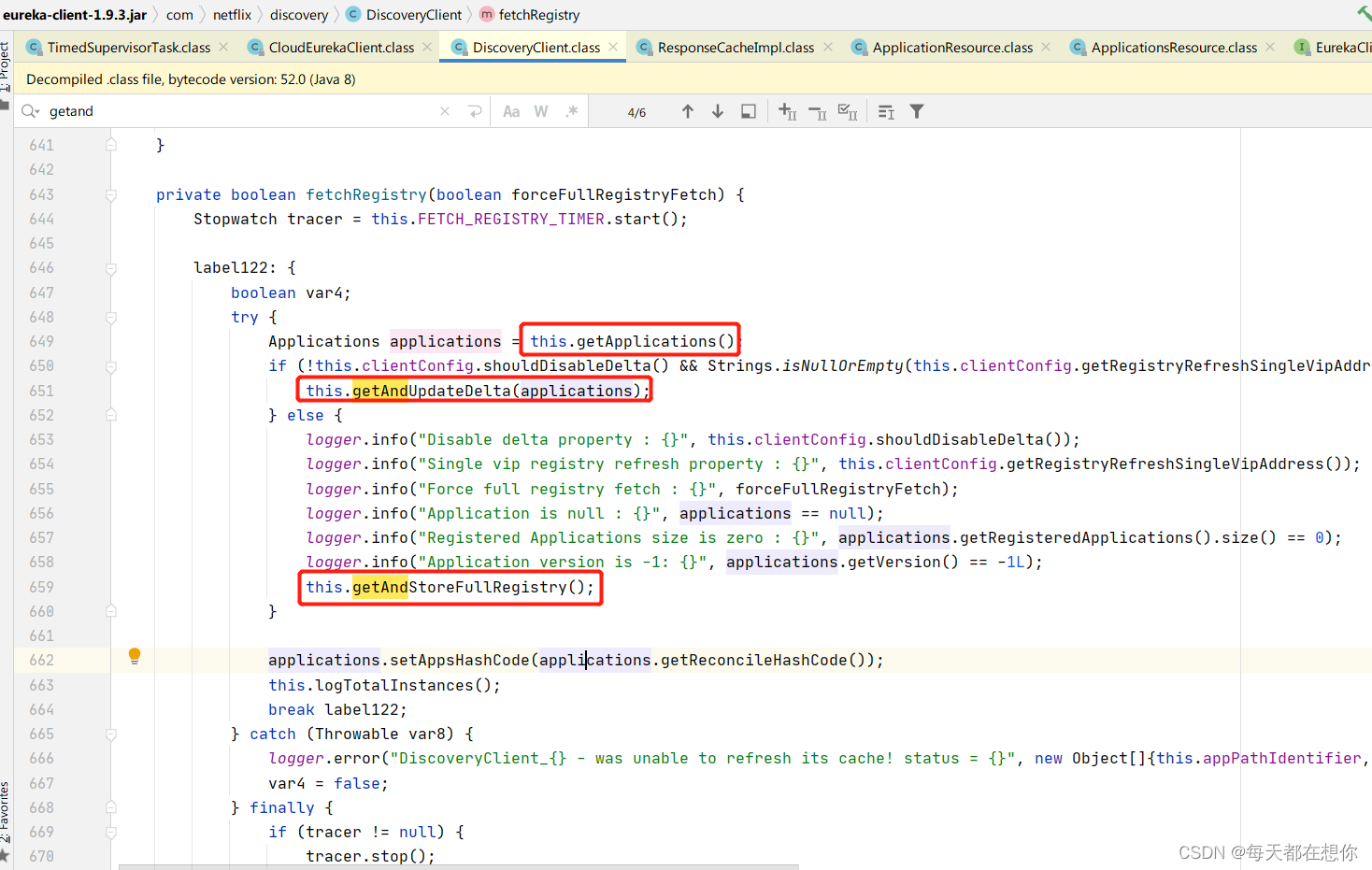
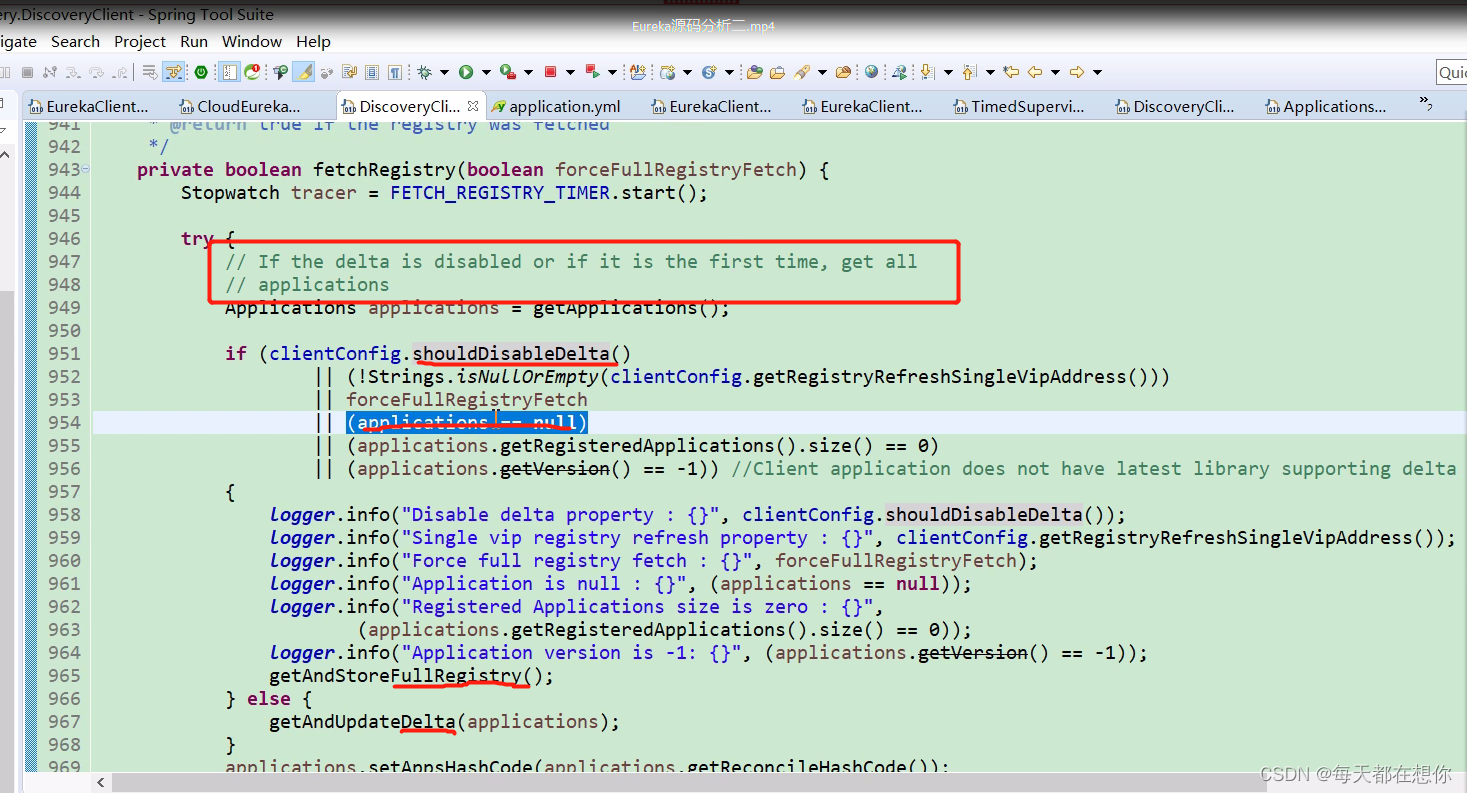
如果禁用了增量更新,则每次都调用全量更新接口getAndStoreFullRegistry(),如果本地缓存applications为null,也就是本地缓存为null,那么就代表是首次
如果是第一次拉取,则也是调用全量更新接口
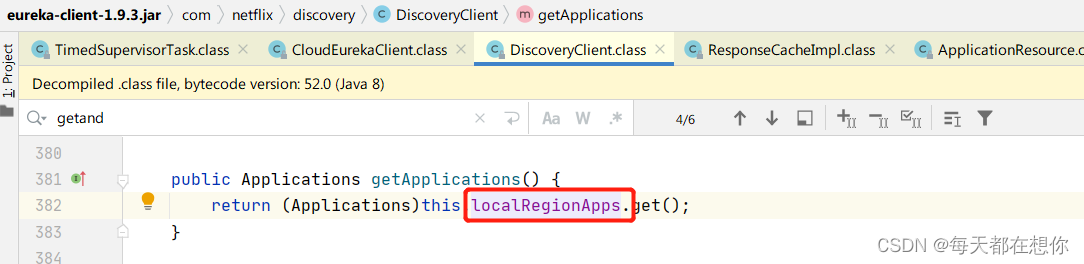
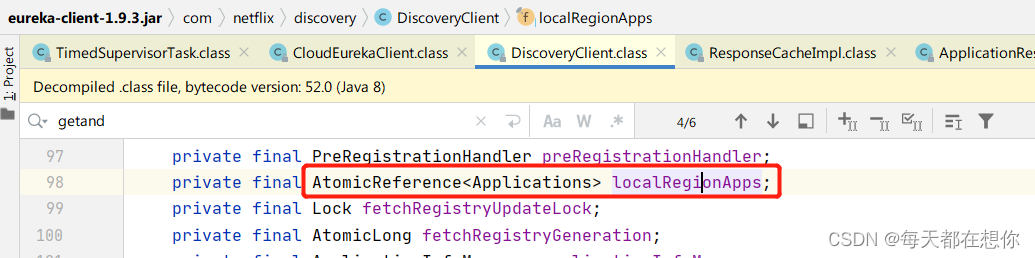
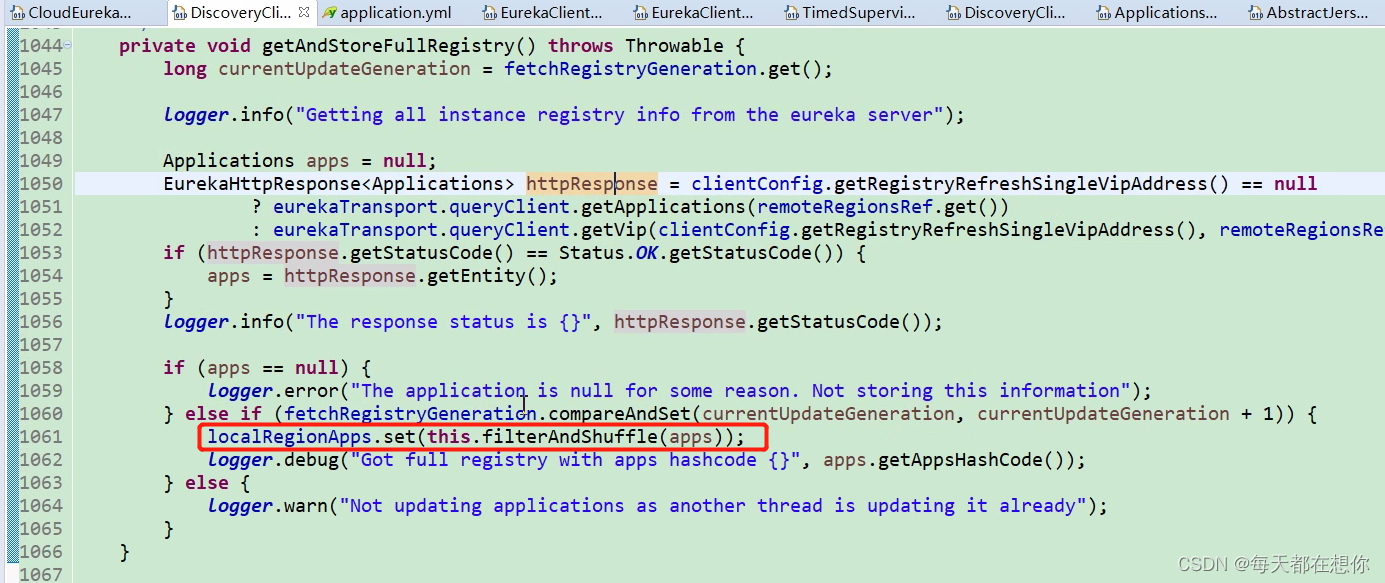
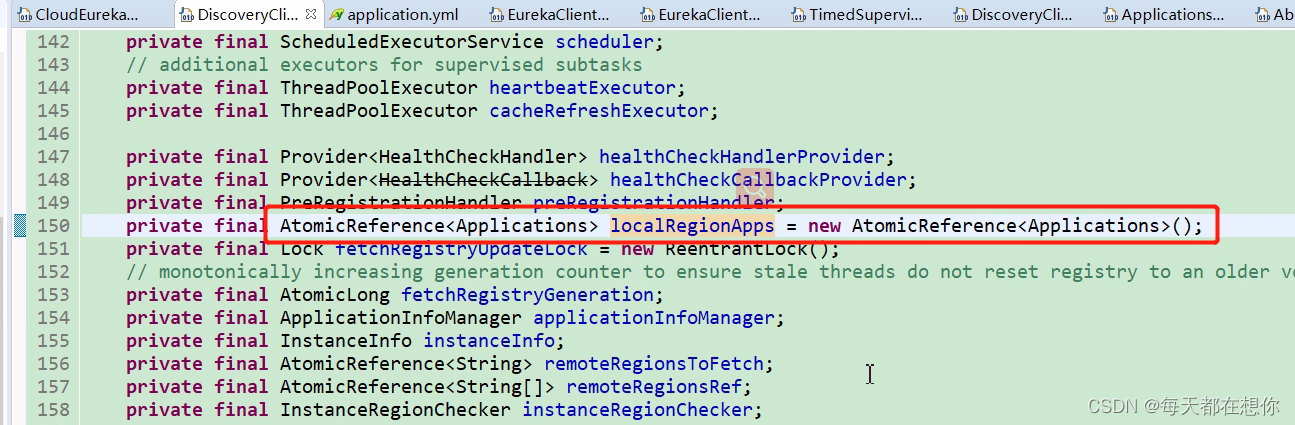
eureka客户端的本地注册表缓存localRegionApps,就是一个Applications类
全量更新接口
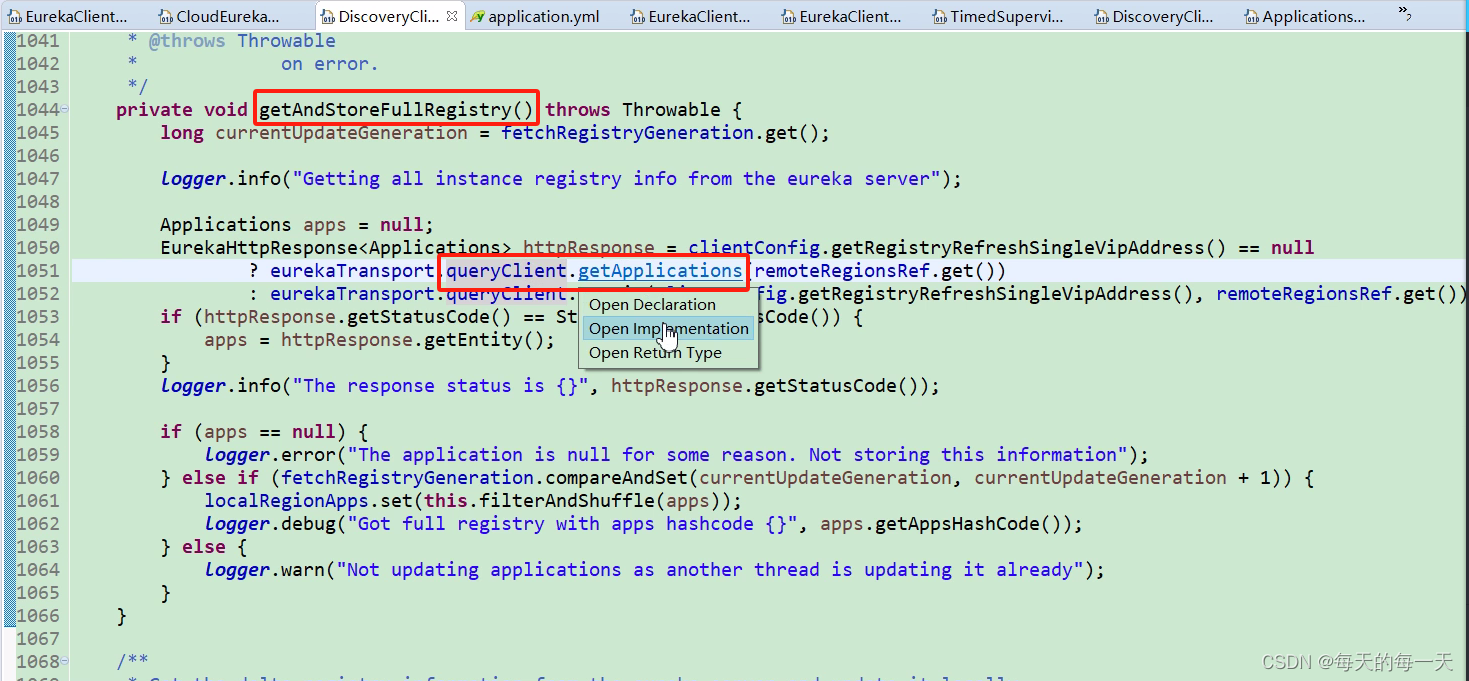
第1061行,就是把从eureka服务端的注册表信息,放入eureka客户端的本地注册表缓存localRegionApps中
增量更新接口
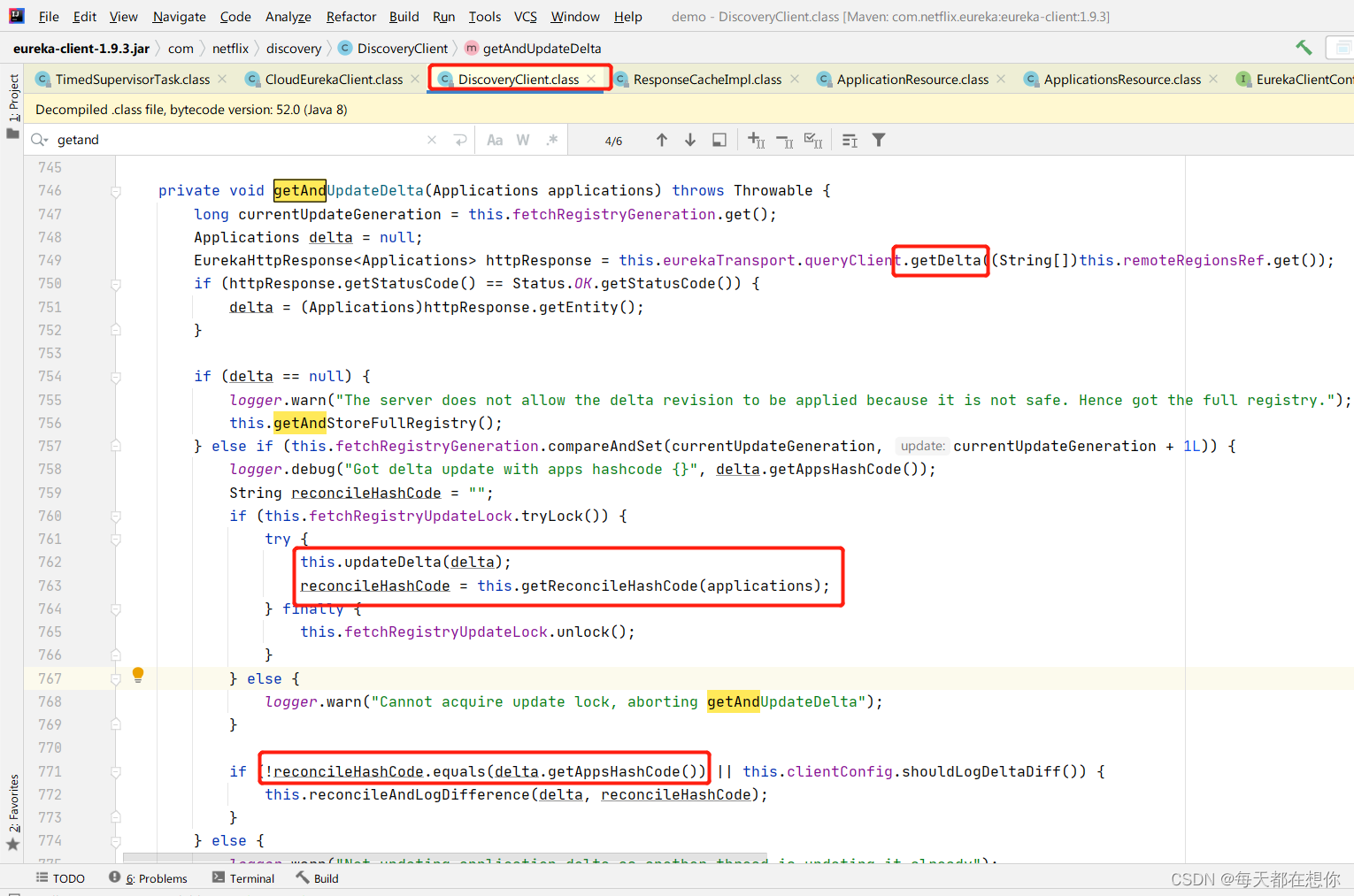
增量更新中的hash一致性比对的技巧
private void updateDelta(Applications delta) {
int deltaCount = 0;
// 对从服务端获取到的Application列表进行遍历
for (Application app : delta.getRegisteredApplications()) {
// 对每个Application对应的服务实例列表进行遍历
for (InstanceInfo instance : app.getInstances()) {
// 获取本地缓存localRegionApps存储的Applications实例
Applications applications = getApplications();
String instanceRegion = instanceRegionChecker.getInstanceRegion(instance);
if (!instanceRegionChecker.isLocalRegion(instanceRegion)) {
Applications remoteApps = remoteRegionVsApps.get(instanceRegion);
if (null == remoteApps) {
remoteApps = new Applications();
remoteRegionVsApps.put(instanceRegion, remoteApps);
}
applications = remoteApps;
}
++deltaCount;
// 如果服务实例的类型是新增
if (ActionType.ADDED.equals(instance.getActionType())) {
Application existingApp = applications.getRegisteredApplications(instance.getAppName());
if (existingApp == null) {
applications.addApplication(app);
}
logger.debug("Added instance {} to the existing apps in region {}", instance.getId(), instanceRegion);
applications.getRegisteredApplications(instance.getAppName()).addInstance(instance);
// 如果服务实例的类型是修改
} else if (ActionType.MODIFIED.equals(instance.getActionType())) {
Application existingApp = applications.getRegisteredApplications(instance.getAppName());
if (existingApp == null) {
applications.addApplication(app);
}
logger.debug("Modified instance {} to the existing apps ", instance.getId());
applications.getRegisteredApplications(instance.getAppName()).addInstance(instance);
// 如果服务实例的类型是删除
} else if (ActionType.DELETED.equals(instance.getActionType())) {
Application existingApp = applications.getRegisteredApplications(instance.getAppName());
if (existingApp != null) {
logger.debug("Deleted instance {} to the existing apps ", instance.getId());
existingApp.removeInstance(instance);
if (existingApp.getInstancesAsIsFromEureka().isEmpty()) {
applications.removeApplication(existingApp);
}
}
}
}
}
logger.debug("The total number of instances fetched by the delta processor : {}", deltaCount);
getApplications().setVersion(delta.getVersion());
getApplications().shuffleInstances(clientConfig.shouldFilterOnlyUpInstances());
for (Applications applications : remoteRegionVsApps.values()) {
applications.setVersion(delta.getVersion());
applications.shuffleInstances(clientConfig.shouldFilterOnlyUpInstances());
}
}
遍历每个应用Application中的每个Instance,看是否一致,不一致的修改,本地没有的则add添加进来
服务端注册表中有多个应用,每个应用下面又有多个实例
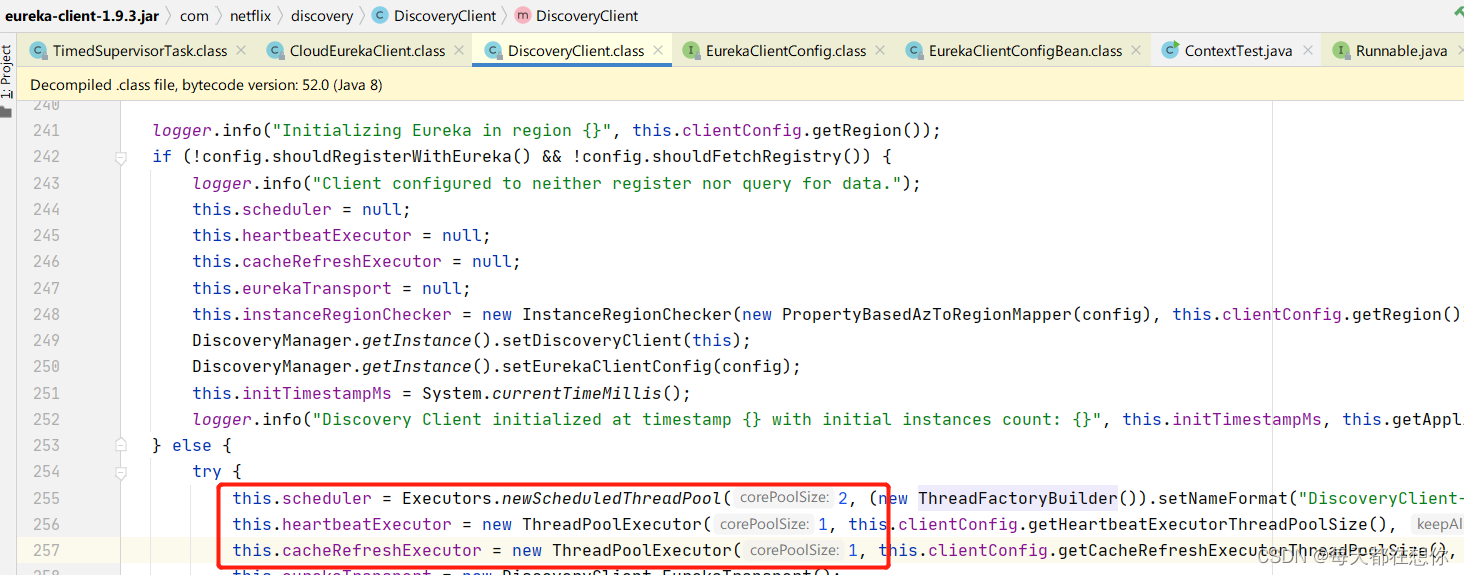
 scheduler线程池是凌驾于业务之上的延迟调度的线程池
scheduler线程池是凌驾于业务之上的延迟调度的线程池
heartBeatExecutor和cacheRefreshExecutor才是真正执行业务的线程池,可以看到这两个业务线程池的阻塞队列都使用的SynchronousQuene

这个初始化调度任务的init方法,也是被上面的DiscoveryClient的构造方法调起的,也就是说和上面的线程池的初始化是在一起被执行的
区分这里的scheduler延迟调度线程池,和executor业务线程池。 这里的executor业务线程池根据不同的业务场景,可以是heartBeatExecutor、也可以是cacheRefreshExecutor线程池
上面的this.task就是CacheRefreshThread,CacheRefreshThread主要负责服务获取逻辑,但是定时调度的逻辑没有耦合进CacheRefreshThread,而是由TimerSupervisorTask来嵌套调度的方式实现周期性的调度
CacheRefreshThread#run()
这个就是客户端的eureka本地缓存
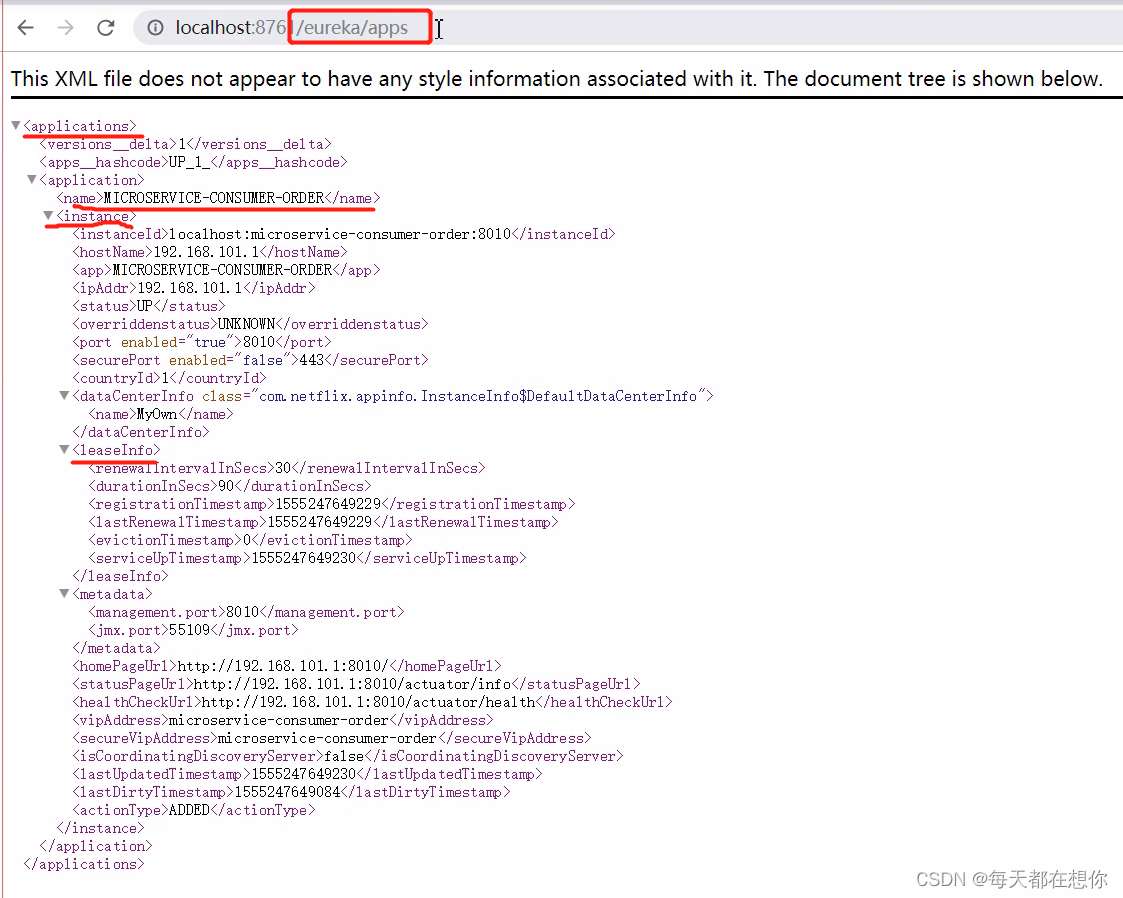
流程图
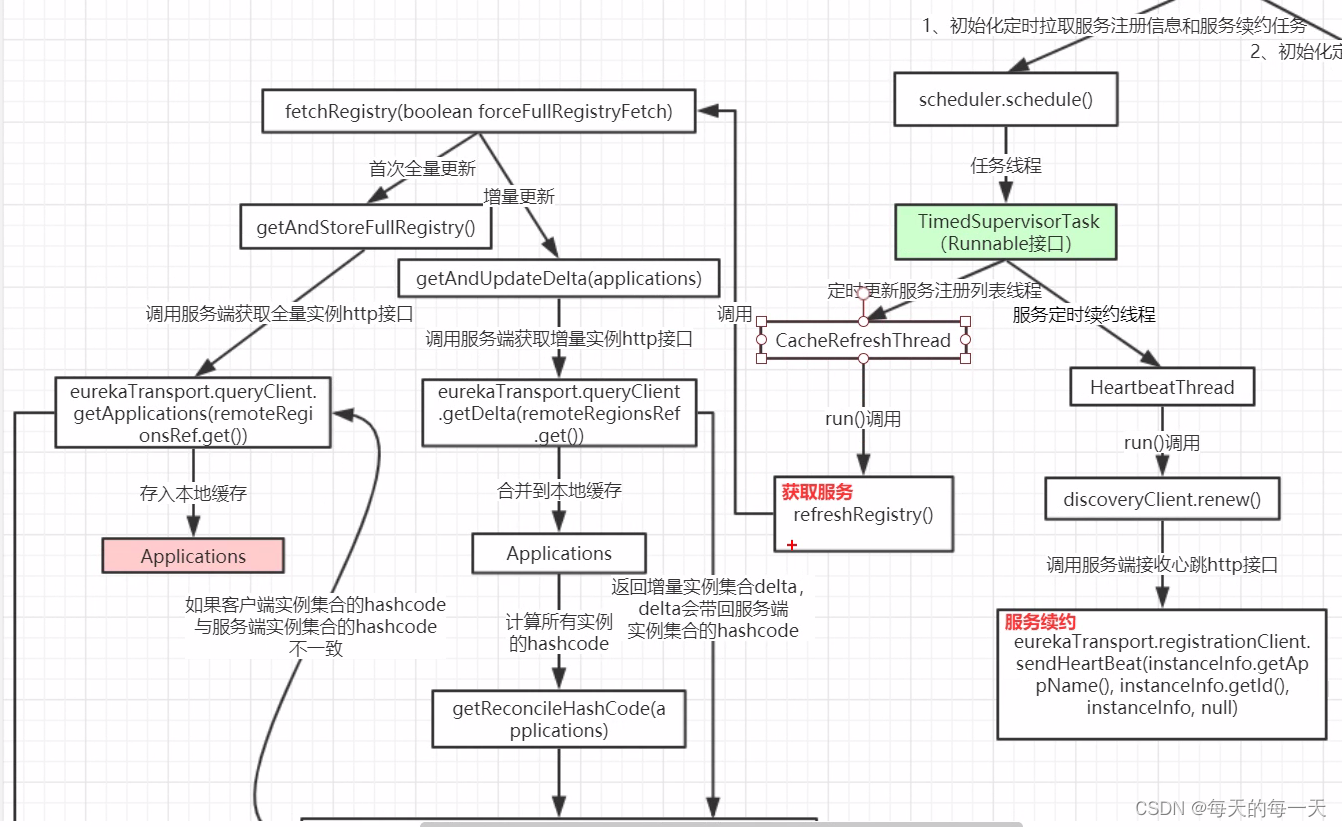

服务获取-服务端
两级缓存机制

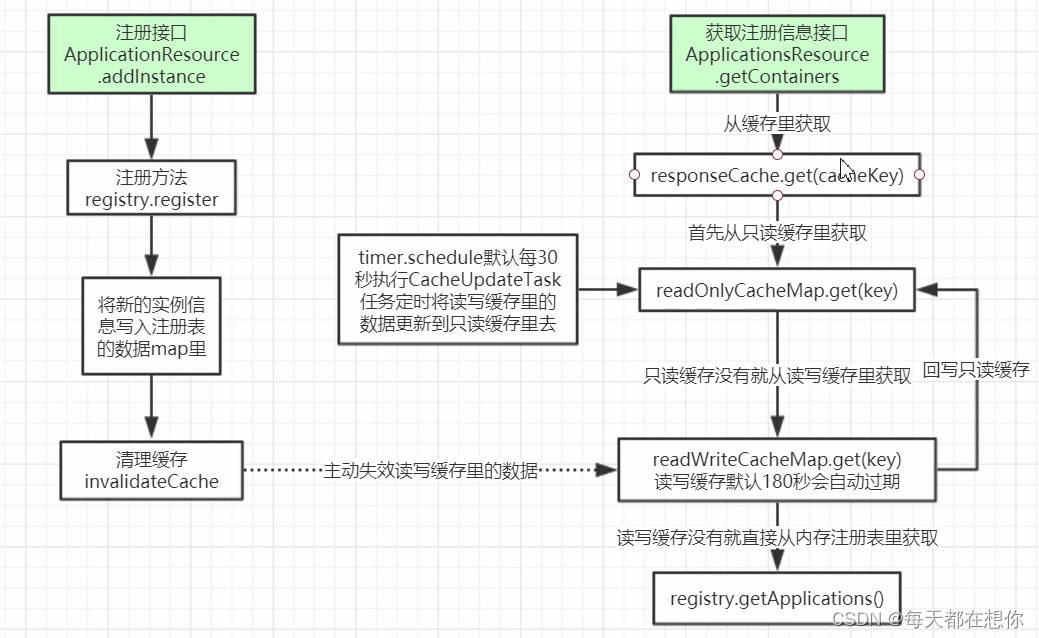
只读缓存
和支持Google的回调动作的读写缓存LoadingCache
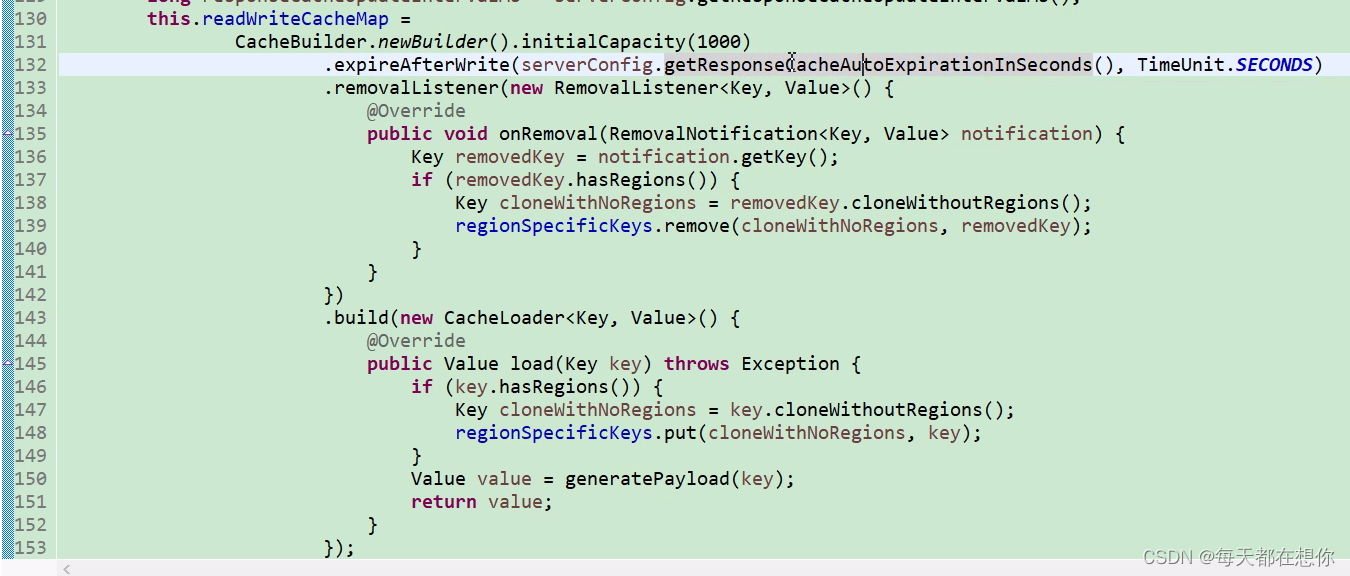
读写缓存失效时间是180s,读写缓存没有读取到后,会回调一个generatePayload(key)去实际服务注册数据registry中查,查到后会回写读写缓存

只读缓存,这里启动了一个定时任务,每30s执行一次,把读写缓存中的数据和只读缓存中的数据进行比对,如果不一致,则把读写缓存中的数据覆盖进只读缓存中
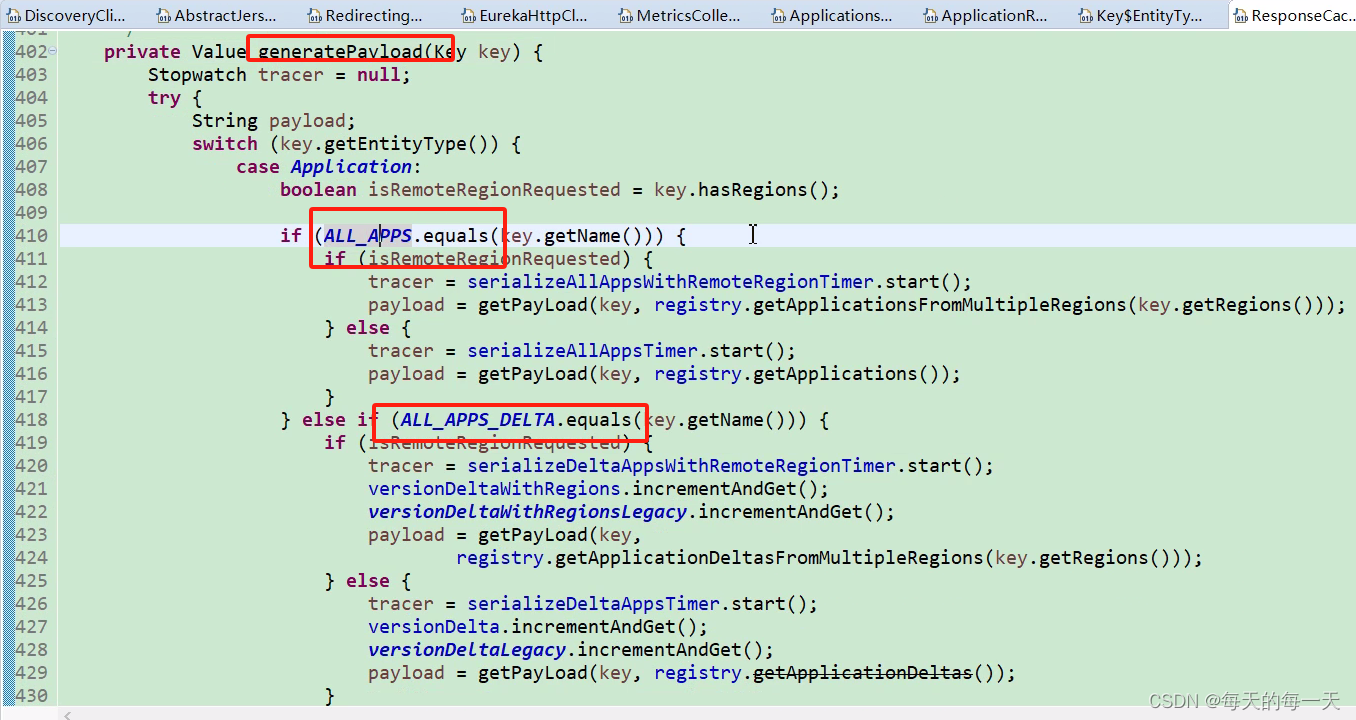
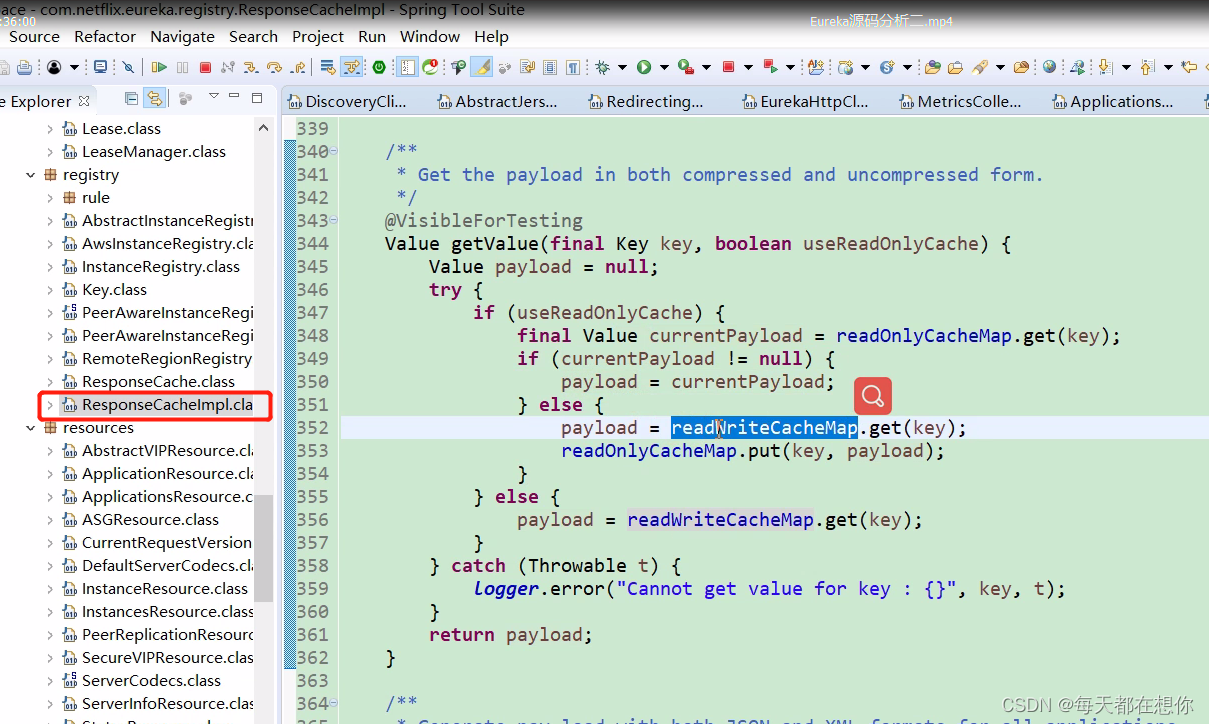
可以看到,348行如果只读缓存中有数据则直接返回,如果只读缓存中没有数据,则353行在读写缓存中读取到数据后,会回写只读缓存
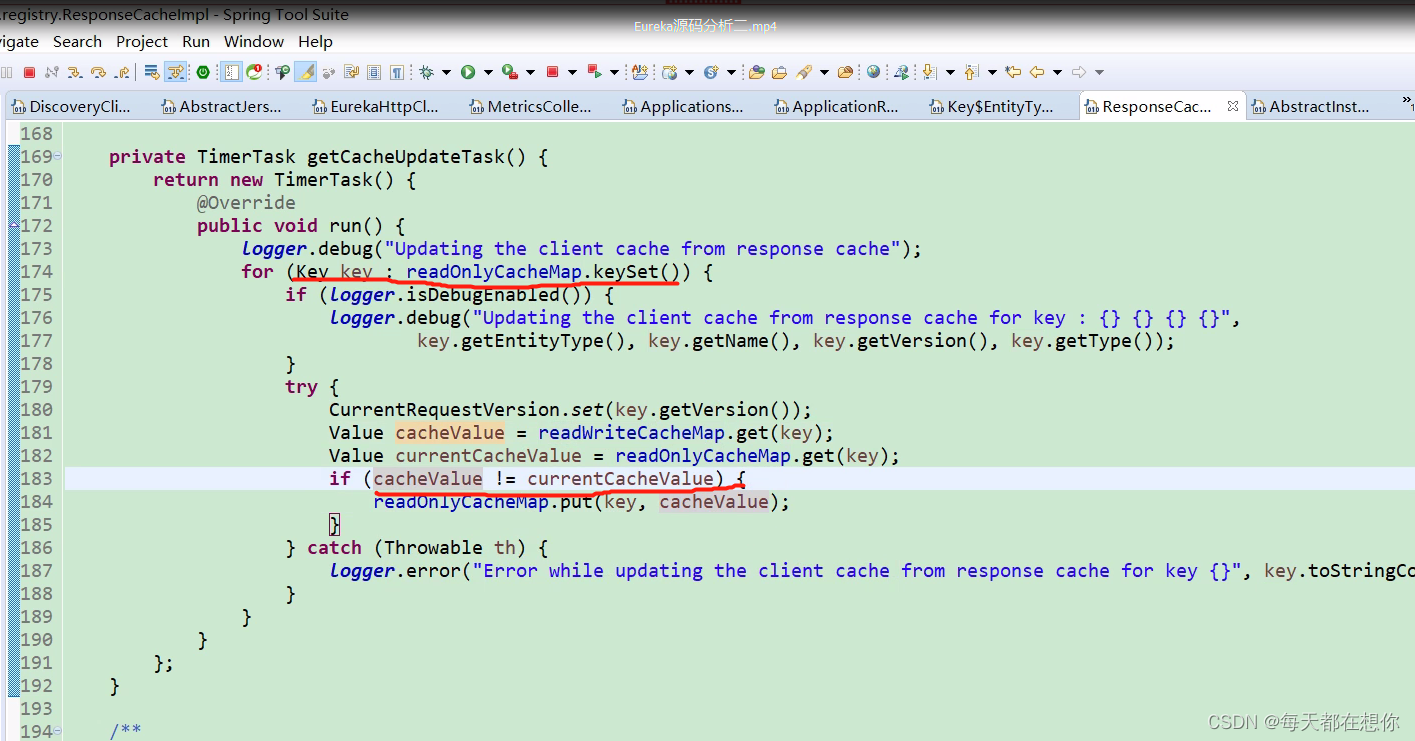
单开一个定时任务30s执行一次,遍历只读缓存中的所有key,发现和读写缓存中的值不一致的,直接覆盖
流程图
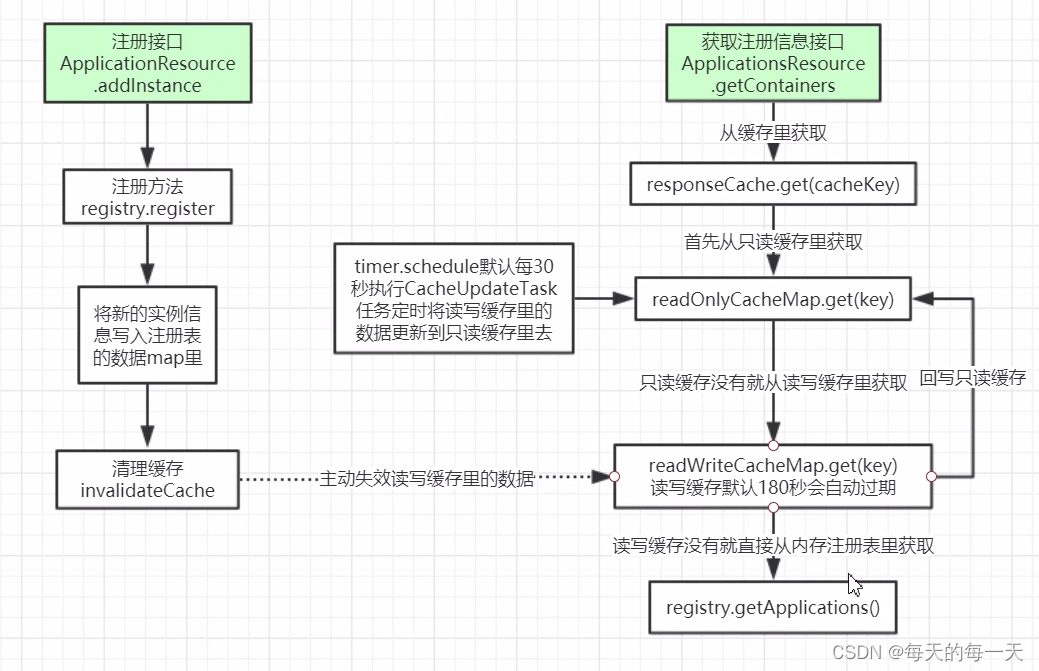
服务端获取全量数据
客户端叫getApplications(),服务端又叫getContainers(),命令不统一很垃圾
服务端获取增量数据
获取所有应用增量信息,registry.getApplicationDeltas():
public Applications getApplicationDeltas() {
Applications apps = new Applications();
apps.setVersion(responseCache.getVersionDelta().get());
Map applicationInstancesMap = new HashMap();
try {
/**
这里读取用的是写锁,
这里的写锁实际上是对“遍历”动作加的锁,让遍历的过程中不允许其他线程写
*/
write.lock();
//遍历recentlyChangedQueue,获取所有增量信息
Iterator iter = this.recentlyChangedQueue.iterator();
logger.debug("The number of elements in the delta queue is :"
+ this.recentlyChangedQueue.size());
while (iter.hasNext()) {
Lease lease = iter.next().getLeaseInfo();
InstanceInfo instanceInfo = lease.getHolder();
Object[] args = {instanceInfo.getId(),
instanceInfo.getStatus().name(),
instanceInfo.getActionType().name()};
logger.debug(
"The instance id %s is found with status %s and actiontype %s",
args);
Application app = applicationInstancesMap.get(instanceInfo
.getAppName());
if (app == null) {
app = new Application(instanceInfo.getAppName());
applicationInstancesMap.put(instanceInfo.getAppName(), app);
apps.addApplication(app);
}
app.addInstance(decorateInstanceInfo(lease));
}
//读取其他Region的Apps信息,我们目前不关心,略过这部分代码......
Applications allApps = getApplications(!disableTransparentFallback);
//设置AppsHashCode,在之后的介绍中,我们会提到,客户端读取到之后更新好自己的Apps缓存之后会对比这个AppsHashCode,如果不一样,就会进行一次全量Apps信息请求
apps.setAppsHashCode(allApps.getReconcileHashCode());
return apps;
} finally {
write.unlock();
}
}遍历recentlyChangedQueue,获取所有增量信息,可以看到这个随着时间动态往后滑动的180s的时间窗口,就是实现时间窗口式的增量信息保存的关键结构
为何这里读写锁这么用,首先我们来分析下这个锁保护的对象是谁,可以很明显的看出,是recentlyChangedQueue这个最近队列。那么谁在修改这个队列,谁又在读取呢?每个服务实例注册取消的时候,都会修改这个队列,这个队列是多线程修改的。但是读取,只有以ALL_APPS_DELTA为key读取LoadingCache时,LoadingCache的初始化线程会读取recentlyChangedQueue(客户端调用增量查询接口时,EurekaClient的查询请求实际查询也是通过LoadingCache的初始化线程先读取到读写缓存的),而且在缓存失效前LoadingCache的初始化线程都不会再读取recentlyChangedQueue
所以可以归纳为:多线程频繁修改,但是单线程不频繁读取。 如果没有锁,那么recentlyChangedQueue在遍历读取时如果遇到修改,就会抛出并发修改异常(需要加锁的根本原因)。如果用writeLock锁住多线程修改,那么同一时间只有一个线程能修改则效率不好。所以,利用读锁锁住多线程修改,利用写锁锁住单线程读取正好符合这里的场景
recentlyChangedQueue是ConcurrentLinkedQueue,对它的并发读写本身都是线程安全的,我们要加锁的原因仅仅是因为:让“并发读写”和“遍历”这两组动作能互斥,加锁并不是为了让读和写互斥
注册流程,也就是对最近变化队列加读锁的过程
public void register(InstanceInfo registrant, int leaseDuration, boolean isReplication) {
try {
/**
register()虽然看上去好像是修改recentlyChangedQueue,但是这里用的是读锁
加读锁仅为了在修改recentlyChangedQueue的过程中,没有其他线程遍历recentlyChangedQueue
*/
read.lock();
//从registry中查看这个app是否存在
Map> gMap = registry.get(registrant.getAppName());
//不存在就创建
if (gMap == null) {
final ConcurrentHashMap> gNewMap = new ConcurrentHashMap>();
gMap = registry.putIfAbsent(registrant.getAppName(), gNewMap);
if (gMap == null) {
gMap = gNewMap;
}
}
//查看这个app的这个实例是否已存在
Lease existingLease = gMap.get(registrant.getId());
if (existingLease != null && (existingLease.getHolder() != null)) {
//如果已存在,对比时间戳,保留比较新的实例信息......
} else {
// 如果不存在,证明是一个新的实例
//更新自我保护监控变量的值的代码.....
}
Lease lease = new Lease(registrant, leaseDuration);
if (existingLease != null) {
lease.setServiceUpTimestamp(existingLease.getServiceUpTimestamp());
}
//放入registry
gMap.put(registrant.getId(), lease);
//加入最近修改的记录队列
recentlyChangedQueue.add(new RecentlyChangedItem(lease));
//初始化状态,记录时间等相关代码......
//主动让Response缓存失效
invalidateCache(registrant.getAppName(), registrant.getVIPAddress(), registrant.getSecureVipAddress());
} finally {
read.unlock();
}
}服务注册
流程图

向Eureka发送注册请求EurekaServer发生了什么?
主要有两个存储,一个是之前提到过的registry整体注册信息缓存,还有一个最近变化队列,后面我们会知道这个最近变化队列里面就是客户端获取增量实例信息的内容:
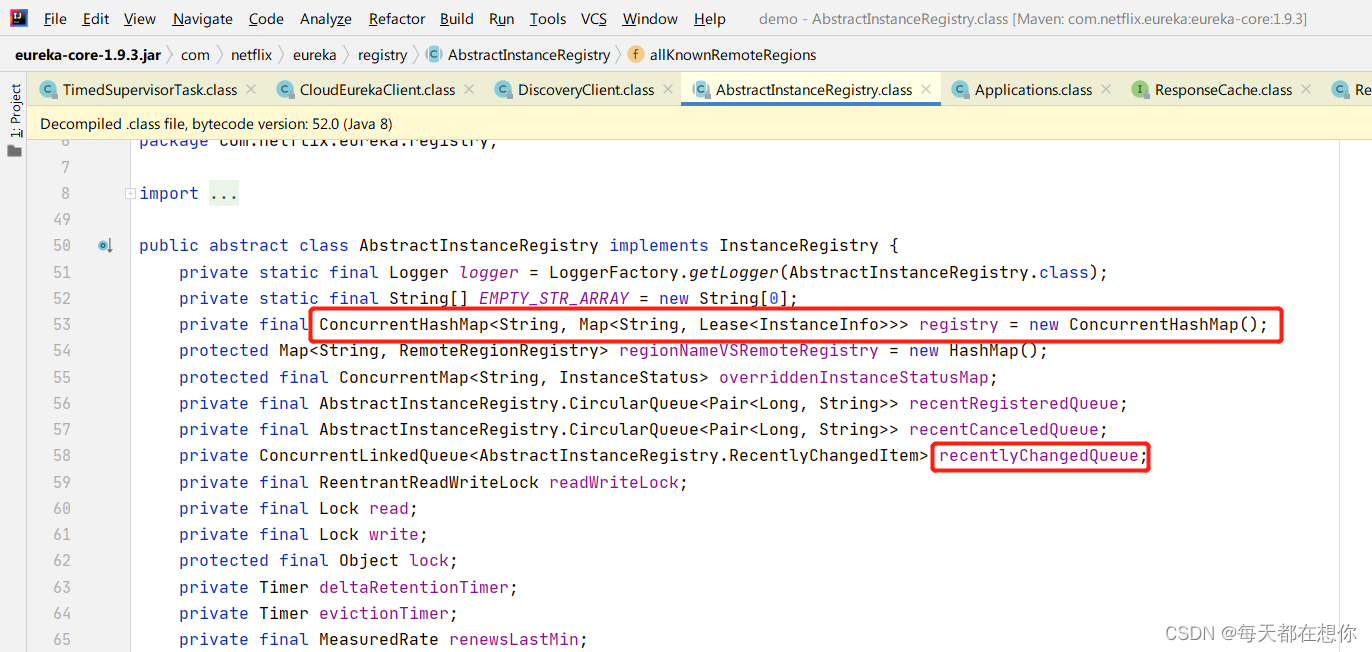
小技巧:一般可以看到容器缓存等,都是定义在Abstract类中
服务注册说白了,实际上就是客户端发送请求到Eureka服务端的注册表,给注册表中的当前微服务所属的列表中,添加上当前自身实例
public abstract class AbstractInstanceRegistry implements InstanceRegistry {
// 最近变化队列
private ConcurrentLinkedQueue<AbstractInstanceRegistry.RecentlyChangedItem> recentlyChangedQueue;
public void register(InstanceInfo registrant, int leaseDuration, boolean isReplication) {
try {
//register虽然看上去好像是修改,但是这里用的是读锁,后面会解释
read.lock();
//从registry中查看这个app是否存在
Map> gMap = registry.get(registrant.getAppName());
//不存在就创建
if (gMap == null) {
final ConcurrentHashMap> gNewMap = new ConcurrentHashMap>();
gMap = registry.putIfAbsent(registrant.getAppName(), gNewMap);
if (gMap == null) {
gMap = gNewMap;
}
}
//查看这个app的这个实例是否已存在
Lease existingLease = gMap.get(registrant.getId());
if (existingLease != null && (existingLease.getHolder() != null)) {
//如果已存在,对比时间戳,保留比较新的实例信息......
} else {
// 如果不存在,证明是一个新的实例
//更新自我保护监控变量的值的代码.....
}
Lease lease = new Lease(registrant, leaseDuration);
if (existingLease != null) {
lease.setServiceUpTimestamp(existingLease.getServiceUpTimestamp());
}
//放入registry
gMap.put(registrant.getId(), lease);
//加入最近修改的记录队列
recentlyChangedQueue.add(new RecentlyChangedItem(lease));
//初始化状态,记录时间等相关代码......
//主动让Response读写缓存失效
invalidateCache(registrant.getAppName(), registrant.getVIPAddress(), registrant.getSecureVipAddress());
} finally {
read.unlock();
}
}总结起来,就是主要三件事:
- 将实例注册信息放入或者更新registry
- 将实例注册信息加入最近修改的记录队列
- 主动让Response读写缓存失效(未让只读缓存失效)
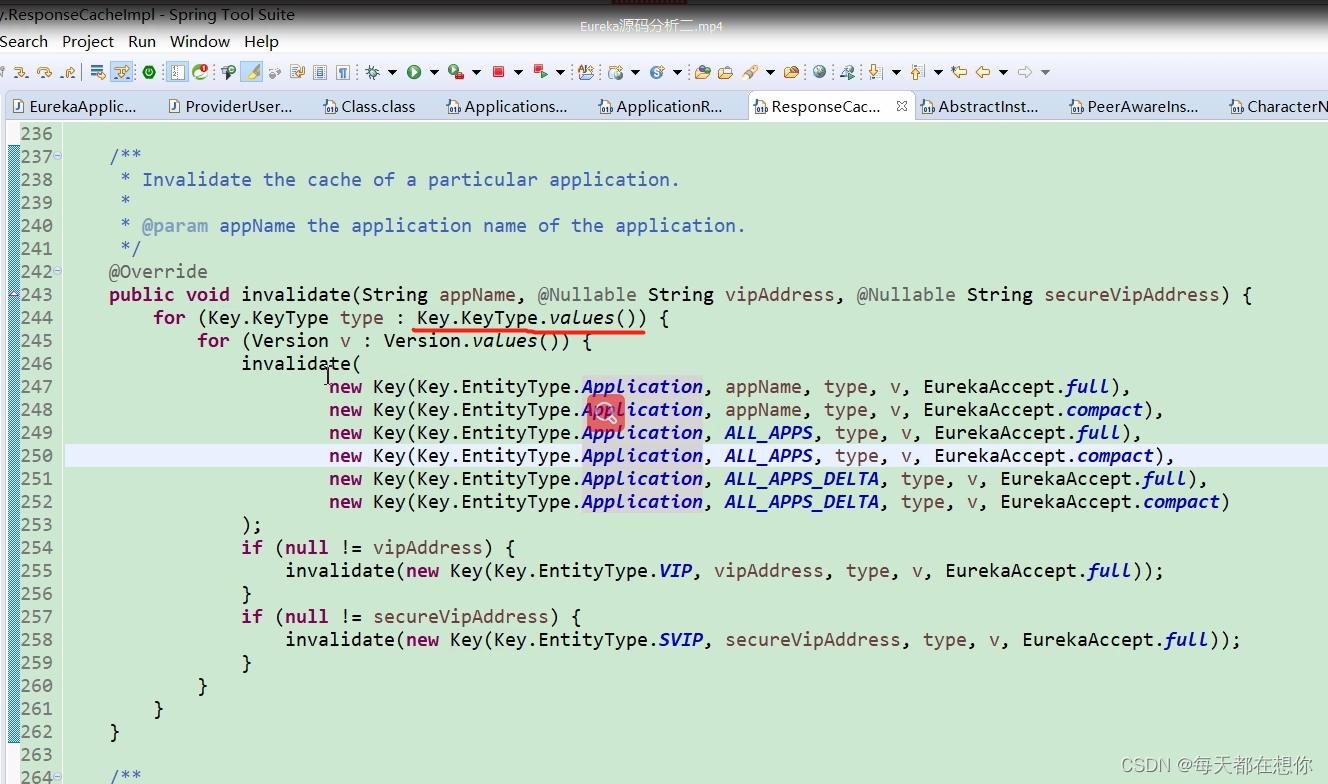
在当前实例的所有注册动作结束后,还会执行一步上面的缓存失效的动作,这里会让key为ALL_APPS的全量缓存要全部清零,key为ALL_APPS_DELTA的增量缓存也全部清空。keyType有两种类型一种是xml另一种是json
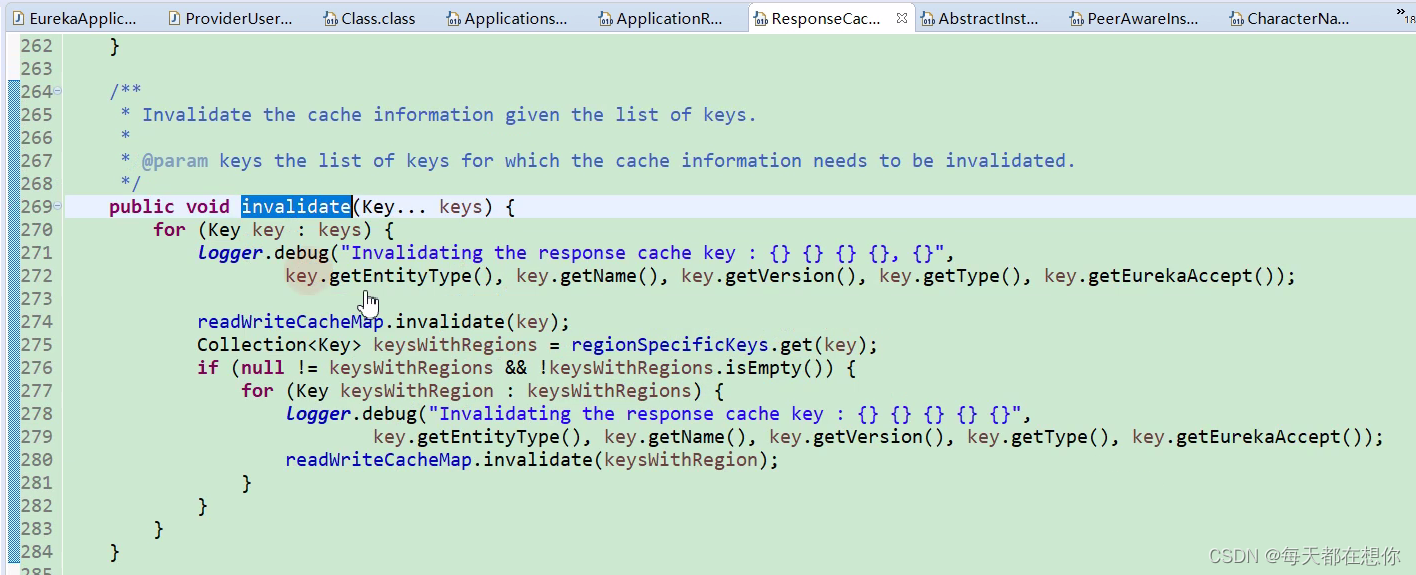
服务取消
protected boolean internalCancel(String appName, String id, boolean isReplication) {
try {
//cancel虽然看上去好像是修改,但是这里用的是读锁,后面会解释
read.lock();
//从registry中剔除这个实例
Map> gMap = registry.get(appName);
Lease leaseToCancel = null;
if (gMap != null) {
leaseToCancel = gMap.remove(id);
}
if (leaseToCancel == null) {
logger.warn("DS: Registry: cancel failed because Lease is not registered for: {}/{}", appName, id);
return false;
} else {
//改变状态,记录状态修改时间等相关代码......
if (instanceInfo != null) {
instanceInfo.setActionType(ActionType.DELETED);
//加入最近修改的记录队列
recentlyChangedQueue.add(new RecentlyChangedItem(leaseToCancel));
}
//主动让Response缓存失效
invalidateCache(appName, vip, svip);
logger.info("Cancelled instance {}/{} (replication={})", appName, id, isReplication);
return true;
}
} finally {
read.unlock();
}
}总结起来,也是主要三件事:
1.从registry中剔除这个实例
2.将实例注册信息加入最近修改的记录队列
3.主动让Response缓存失效
服务续约Renew
流程图
续约,实际上就是客户端发送请求到Eureka服务端的注册表,更新一下注册表中自身实例的超时时间
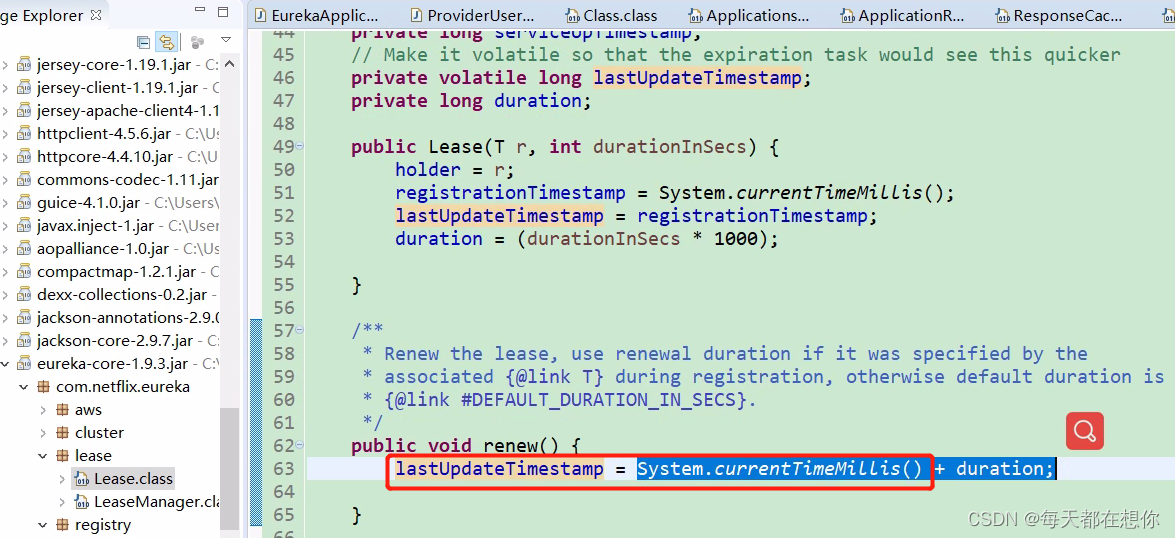
这里有个bug就是在最后加了个duration(90s)
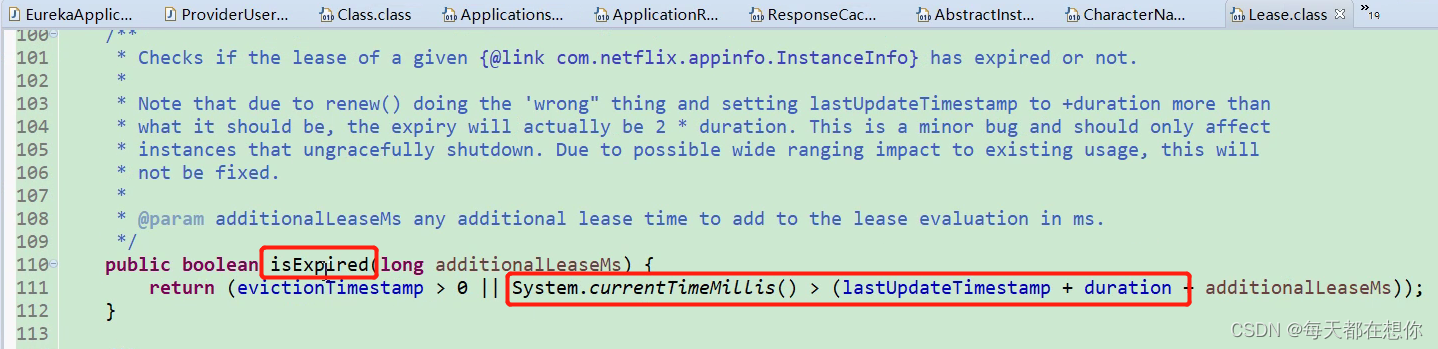
这里就导致eureka官方写的,超时剔除时间是90s(超过90s没有心跳续约则将该实例从服务端注册表中剔除掉),但是实际是180s
注册表结构
eureka注册表结构

以上就是注册表的双层Map的结构
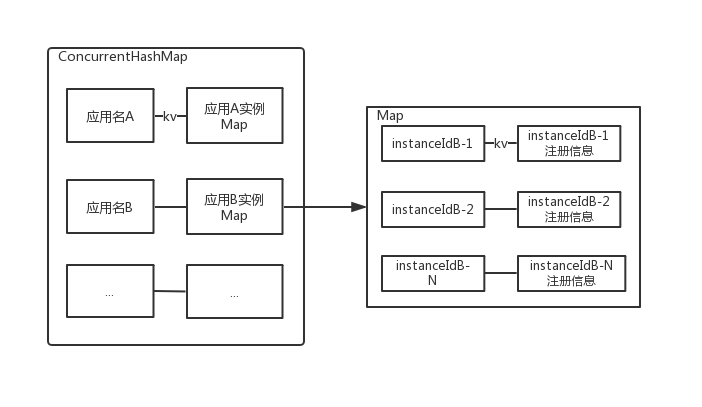
Lease就保存着某个微服务下的一台实例的实例信息,服务续约信息比如,Lease有一个isExperied()是否过期方法,evict服务剔除定时任务扫描注册表map进行服务剔除时,就是遍历注册表中的每一个Lease,调用每个Lease的isExperied()判断该Lease是否过期,过期的就将它剔除

Lease:租约,holder中还有服务名、ip、端口等信息
lastUpdateTimestamp :最后更新时间,每次续约的时候都会更新这个时间戳,在判断实例是否过期时需要用到这个属性
亮点技巧
动态扩容定时任务的超时时间
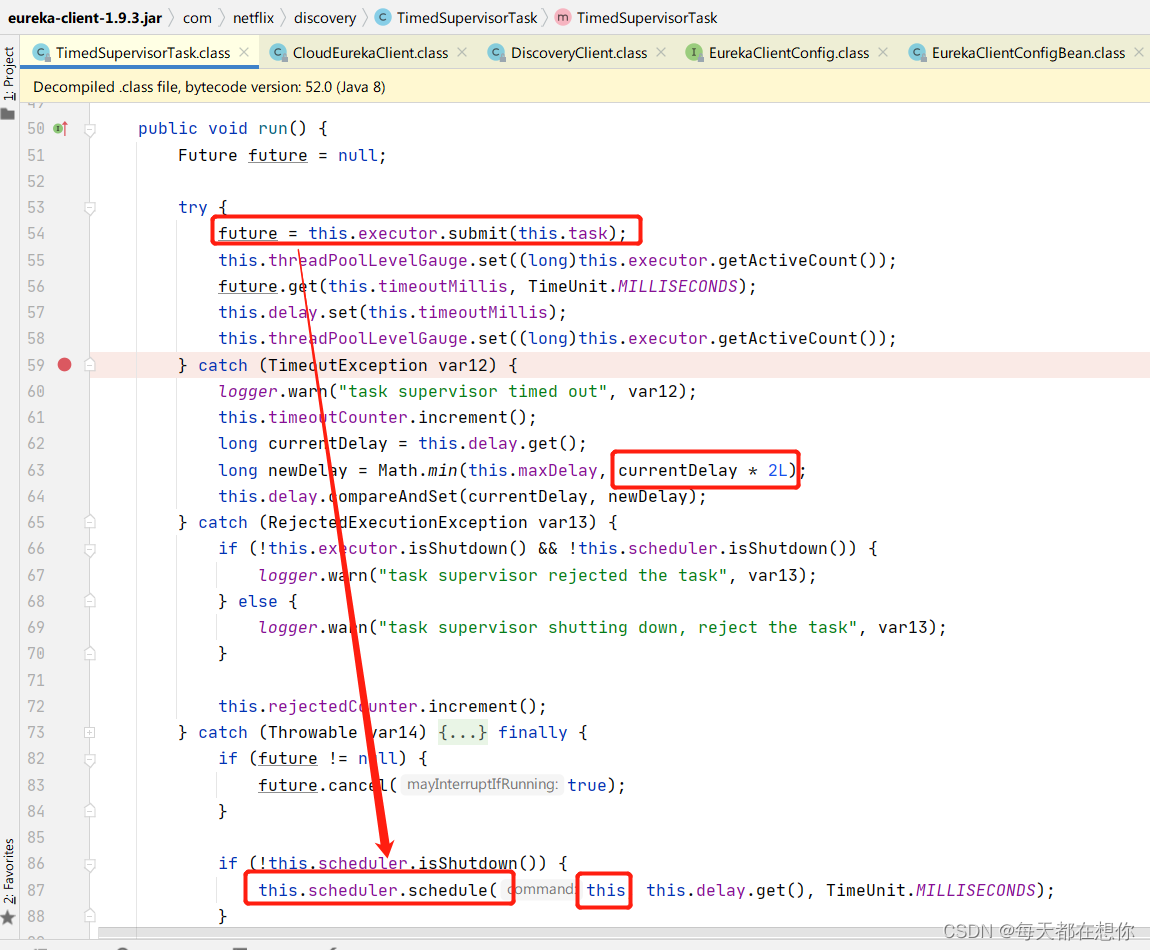
TimedSupervisorTask是一个Runnable接口实现,看下它的run方法
@Override
public void run() {
Future<?> future = null;
try {
future = executor.submit(task);
threadPoolLevelGauge.set((long) executor.getActiveCount());
//指定等待子线程的最长时间
future.get(timeoutMillis, TimeUnit.MILLISECONDS); // block until done or timeout
//delay是个关键变量,后面会用到,这里记得每次执行任务成功都会将delay重置
delay.set(timeoutMillis);
threadPoolLevelGauge.set((long) executor.getActiveCount());
} catch (TimeoutException e) {
logger.warn("task supervisor timed out", e);
timeoutCounter.increment();
long currentDelay = delay.get();
//任务线程超时的时候,就把delay变量翻倍,比如从30s变成60s
//但不会超过外部调用时设定的最大延时时间
long newDelay = Math.min(maxDelay, currentDelay * 2);
//设置为最新的值,考虑到多线程,所以用了CAS
delay.compareAndSet(currentDelay, newDelay);
} catch (RejectedExecutionException e) {
//一旦线程池的阻塞队列中放满了待处理任务,触发了拒绝策略,就会将调度器停掉
if (executor.isShutdown() || scheduler.isShutdown()) {
logger.warn("task supervisor shutting down, reject the task", e);
} else {
logger.warn("task supervisor rejected the task", e);
}
rejectedCounter.increment();
} catch (Throwable e) {
if (executor.isShutdown() || scheduler.isShutdown()) {
logger.warn("task supervisor shutting down, can't accept the task");
} else {
logger.warn("task supervisor threw an exception", e);
}
throwableCounter.increment();
} finally {
//这里任务要么执行完毕,要么发生异常,都用cancel方法来清理任务;
if (future != null) {
future.cancel(true);
}
//只要调度器没有停止,就再指定等待时间之后在执行一次同样的任务
if (!scheduler.isShutdown()) {
45 //假设外部调用时传入的超时时间为30秒(构造方法的入参timeout),最大间隔时间为50秒(构造方法的入参expBac
kOffBound)
46 //如果最近一次任务没有超时,那么就在30秒后开始新任务,
47 //如果最近一次任务超时了,那么就在50秒后开始新任务(异常处理中有个乘以二的操作,乘以二后的60秒超过了最大
间隔50秒)
48 scheduler.schedule(this, delay.get(), TimeUnit.MILLISECONDS);
}
}scheduler.schedule(this, delay.get(), TimeUnit.MILLISECONDS),
从代码注释上可以看出这个方法是一次性调用方法,但是实际上这个方法执行的任务会反复执行,秘密就在this对应的这个类TimedSupervisorTask的run方法里,run方法任务执行完最后,会再次调用schedule方法,在指定的时间之后执行一次相同的任务,这个间隔时间和最近一次任务是否超时有关,如果超时了则下一次执行任务的间隔时间就会变大;
future.get()超时后,就会抛出TimeoutException:如果第一次future.get()超时,那么delay从30s变成了60s,然后第二次就是等60s再去服务端拉取注册信息,如果这第二次拉取时future.get()没有超时,那么future.get()的下一行代码delay.set(timeoutMillis)又会给它还原回30s拉取一次
源码精髓:
- 指数避退机制,从整体上看TimedSupervisorTask是固定间隔的周期性任务,一旦遇到超时就会将下一个周期的间隔时间调大,如果连续超时,那么每次间隔时间都会增大一倍,一直到达外部参数设定的上限为止,一旦新任务不再超时,间隔时间又会自动恢复为初始值
- 另外还有CAS来控制多线程同步,这些是我们看源码需要学习到的设计技巧
增量同步时通过全量同步来兜底
解决方案:一致性hash比对,也就是类似于外面的“签名验证”,用于增量同步的场景
eureka用了两块内存,分别来存放Delta增量数据,和Full全量数据。默认180s会执行一次增量数据的失效逻辑。有了这个180s的增量数据失效逻辑,如果客户端因为指数避退超时,超过180s没有拉取服务端的增量注册信息,那么下一次去拉取增量时返回就是null,此时,就会丢失一些增量的数据
客户端只有刚启动时第一次进行服务拉取时调用全量数据拉取接口,后面正常情况下都调用增量同步接口
客户端调用服务端的增量数据同步接口时除了返回增量Delta数据,还会返回全量数据的一个压缩hashCode码,拿到返回数据后,客户端会先执行增量数据和本地已有的全量数据的合并,合并完后生成本地的全量数据的新的hashCode码,再比较这个新的本地全量数据对应的hashCode码,和服务端返回的hashCode码,比对不一致,则会立马重新调用服务端的全量同步接口,做一个兜底
注意,762行在合并远端的增量数据和本地的已有全量数据时,需要先在760行加锁,因为可能存在并发修改本地数据的情况,当然就需要先加锁了
多级缓存提高读写性能
Eureka Server 的数据存储分了两层:数据存储层和两级缓存层。注册中心,读取肯定是要互斥的。eureka是使用的多级缓存,来解决读写互斥的问题。nacos是使用Copy On Write读写分离,来解决读写互斥的问题
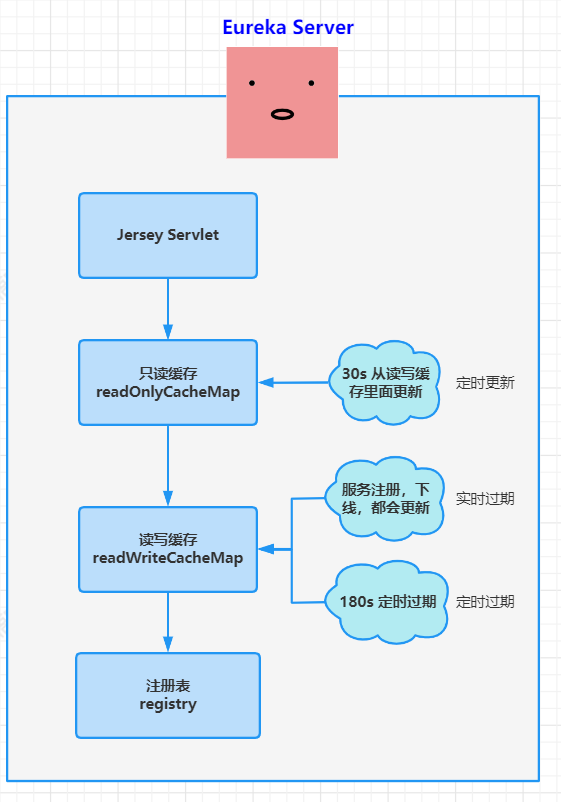
这里就有一个最终一致性的体现:
客户端注册使得读写缓存失效后,只读缓存依然保存的是老数据,需要30s后才去读写缓存中拉取一次,这就是最终一致性,也就是eureka的AP的体现

为什么默认要一开始从readOnlyCashMap缓存中读取?
- 为了保证在高并发的情况下高可用,不至于写的时候,不让读
- 如果有大量的服务进来,不影响从readOnlyCashMap缓存中读取配置信息,而进来的服务是往registry里写的,减少了读写冲突。
既然这个缓存叫做只读缓存,怎么还能被更新,不应该是不变的吗?
其实这里的不变是相对于客户端来说的,客户端获取注册表信息时,最开始访问的就是只读缓存,类似数据库或 Redis 的主从架构,主负责读写,从负责读。然后系统内部会把主节点的信息同步给从节点。大家明白了吗?
疑问:
1. 既然大家都推荐关闭只读缓存,说明其实只读缓存存在的意义不大?
只读缓存作为“从缓存”,读写缓存作为“主缓存”,从缓存的引入就带来了数据的更多不一致性的可能,但是能更提高并发访问的能力?
关于三级缓存的参考文章
Eureka服务发现慢的原因_不疯魔不成话的博客-CSDN博客_eureka 发现慢
Eureka服务发现慢的原因_黄土地的孩子的博客-CSDN博客_eureka 服务发现时间
图文详述Eureka的缓存机制/三级缓存_eureka多级缓存作用_秃秃爱健身的博客-CSDN博客
增量时间窗口实现
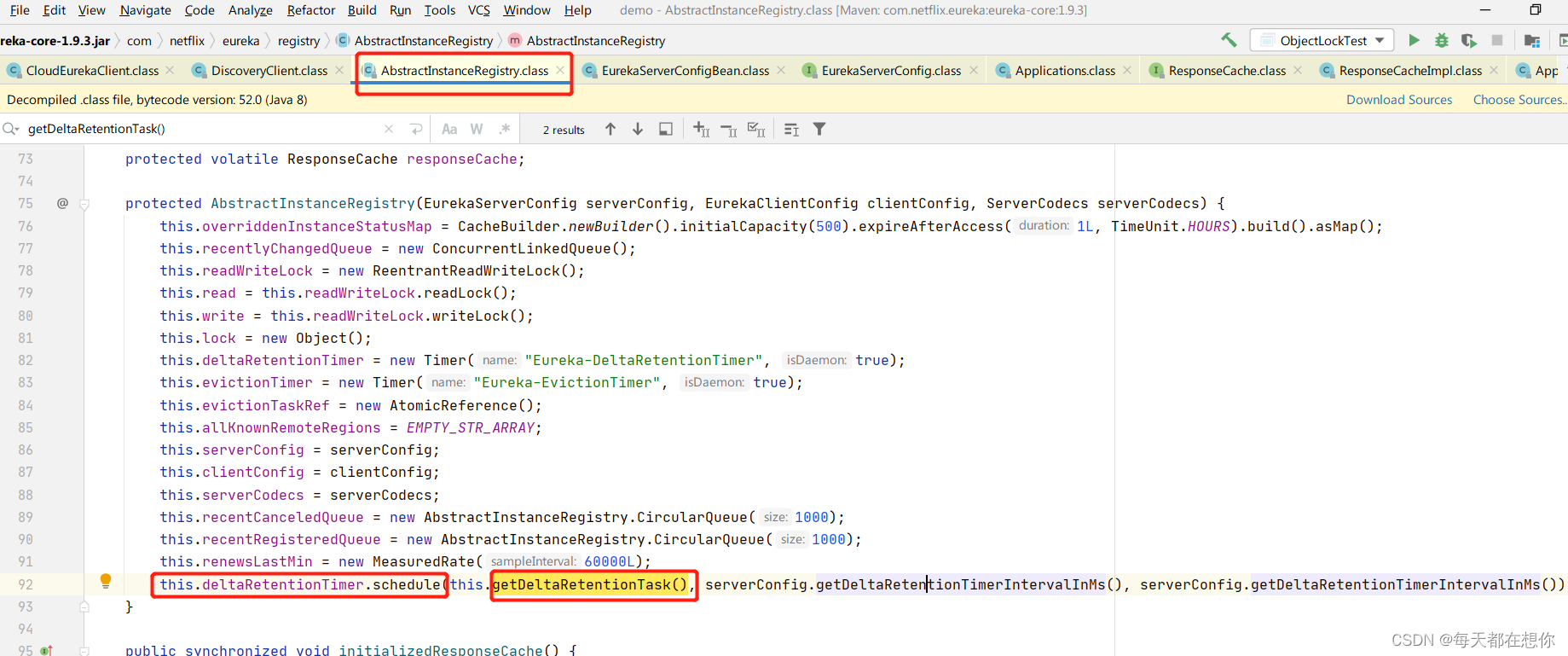
动态时间窗口
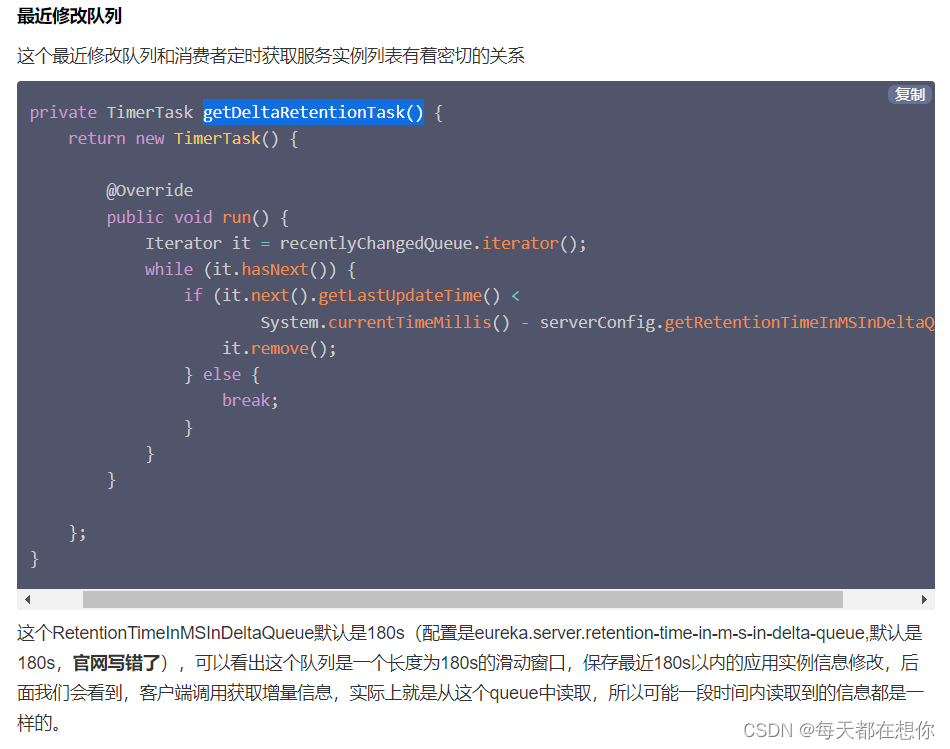
可以看到动态时间窗口,就是靠一个每30s执行一次的定时任务来实现的