文章目录
- 文件操作
- 打开文件
- 关闭文件
- 读文件
- 写文件
- 使用上下文管理器
文件操作
打开文件
open函数
open函数的作用是打开一个文件,并返回打开的文件对象。该函数的常见调用方式如下:
f = open(file, mode, encoding)
参数说明:
- file:待打开文件的路径,可以是绝对路径或相对路径。
- mode:打开文件的方式,默认以文本读方式打开。
- encoding:打开文件的编码方式。
打开文件的方式
打开文件的方式有以下几种:
| 打开方式 | 含义 |
|---|---|
| ‘r’ | 以读方式打开文件(默认) |
| ‘w’ | 以覆盖写方式打开文件,如果文件不存在则先创建再打开 |
| ‘a’ | 以追加写方式打开文件,如果文件不存在则先创建再打开 |
| ‘x’ | 创建文件并以写方式打开,如果文件已存在则会抛出异常 |
| ‘b’ | 以二进制方式打开文件 |
| ‘t’ | 以文本方式打开文件(默认) |
| ‘+’ | 打开磁盘文件进行更新(读取与写入) |
打开文件的编码方式
文件的编码方式一般为“utf-8”,为了避免程序报错或者读取到的内容出现乱码,需要在打开文件时将encoding设置为“utf-8”。比如:
f = open('d:/Python环境/test.txt', 'r', encoding='utf-8')
说明一下:
- encoding参数其实并不是open函数的第三个参数,open函数还有其他的一些参数,这些参数都带有默认值,因此在调用open函数时可以不用设置这些参数。
- 因此如果在调用open函数时要设置encoding参数,就需要通过关键字参数的方式将
‘utf-8’参数指定传递给encoding形参。
关闭文件
打开文件个数的上限
一个程序能同时打开的文件个数是有上限的,可以通过以下代码进行测试:
flist = []
count = 0
while True:
f = open('d:/Python环境/test.txt', 'r')
flist.append(f)
count += 1
print(f'打开文件的个数: {count}')
运行后程序后会发现,当程序打开了第8189个文件后,再使用open打开文件程序就会抛出异常。

算上一个程序默认打开的标准输入流、标准输出流和标准错误流,那么在我当前的运行环境下一个程序最多能同时打开的文件个数就是8192。
一个程序最多能同时打开的文件个数,其实也是可以通过设置某些系统选项来配置的,但无论把这里的文件个数设置得多高,一个程序能同时打开的文件个数终究是有上限的,因此为了避免文件资源泄露,程序员需要及时将不再使用的文件进行关闭,释放文件资源。
说明一下:
- 上述代码中用列表对所有打开的文件对象进行了保存,如果不进行保存,那么Python内置的垃圾回收机制会在文件对象销毁的时候自动关闭文件。
- 虽然垃圾回收机制能够自动关闭文件,但垃圾回收机制关闭文件不一定及时,所以仍然需要程序员手动对文件进行关闭,尽量避免依赖自动关闭。
close函数
close函数是文件对象的一个成员函数,其作用就是将打开的文件进行关闭。该函数的调用方式如下:
f = open('d:/Python环境/test.txt', 'r', encoding='utf-8')
f.close()
注意: 不能使用被关闭后的文件对象再对文件进行任何操作,否则程序会抛出异常。
读文件
下面用如下内容演示文件的读取操作:
床前明月光
疑是地上霜
举头望明月
低头思故乡
注意: 读文件时需要以'r'的方式打开文件。
read函数
使用read函数可以从文件中读取指定个数的字符。比如:
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
print(f.read(5)) # 床前明月光
f.close()
说明一下: 如果没有设置指定读取的字符个数,或指定读取的字符个数超过文件中的字符总数,则直接读取整个文件。
readline函数
使用readline函数可以从文件中读取一行字符。比如:
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
print(f.readline()) # 床前明月光
print(f.readline()) # 疑是地上霜
f.close()
说明一下: 再次调用readline函数则继续读取下一行。
readlines函数
使用readlines函数可以读取整个文件的内容。比如:
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
print(f.readlines()) # ['床前明月光\n', '疑是地上霜\n', '举头望明月\n', '低头思故乡']
f.close()
说明一下: readlines函数返回的是一个列表,列表中的每个元素即为文件的一行内容。
for循环遍历
使用for循环对文件对象进行迭代,可以每次循环读取文件中的一行内容。比如:
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
for line in f:
print(line)
f.close()
需要注意的是,由于文件中的每一行末尾都带有换行符'\n',而print函数每次打印后也会打印一个换行符'\n',因此这里打印出来的每行文件内容之间会多出一个空行。
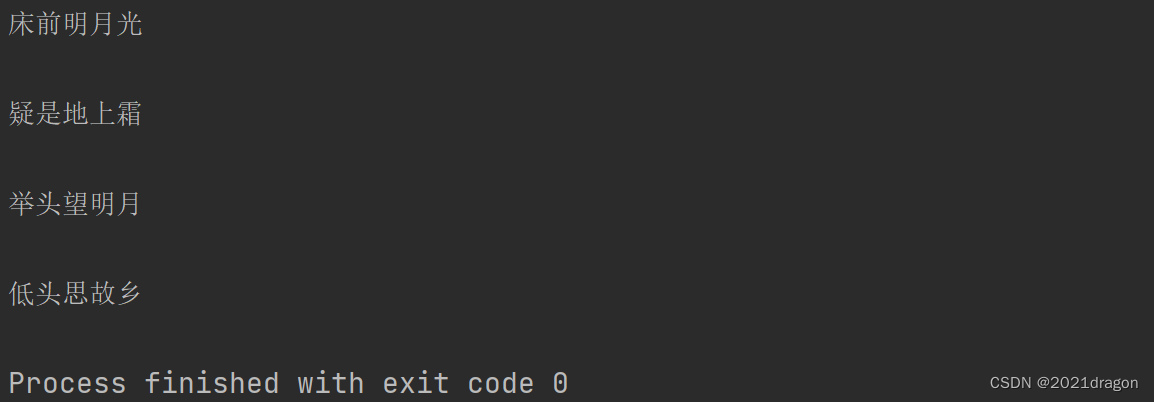
其实print函数有一个参数叫做end,该参数就是用来设定print输出的内容以什么结尾,而end参数的默认值就是'\n',如果不想让print每次输出完数据后再输出换行符,就可以将end的值设置为空字符串。比如:
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
for line in f:
print(line, end='')
f.close()
此时打印输出内容就和文件中的内容一致了。
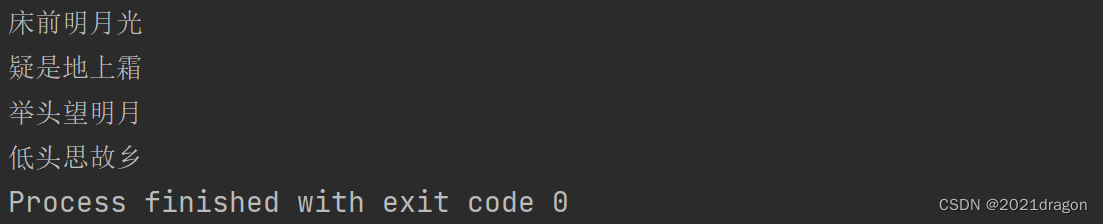
写文件
write函数
使用write函数可以将指定内容写入到文件中。比如:
# 第一次写入
f = open('d:/Python环境/test.txt', 'w', encoding='utf8')
f.write('2021')
f.close()
# 第二次写入
f = open('d:/Python环境/test.txt', 'w', encoding='utf8')
f.write('dragon')
f.close()
# 读取
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
print(f.read()) # dragon
f.close()
需要注意的是,如果以'w'的方式打开文件进行写入,那么每一次写入的内容会覆盖文件中原有的内容,因此这里写入两次后读取到的只有第二次写入的数据。
如果想写入的数据不会覆盖文件中的原有数据,就需要以'a'的方式打开文件。比如:
# 第一次写入
f = open('d:/Python环境/test.txt', 'a', encoding='utf8')
f.write('2021')
f.close()
# 第二次写入
f = open('d:/Python环境/test.txt', 'a', encoding='utf8')
f.write('dragon')
f.close()
# 读取
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
print(f.read()) # 2021dragon
f.close()
这时在读取文件内容时,就能读取到两次写入的数据。
使用上下文管理器
为了避免程序员忘记关闭文件,Python提供了上下文管理器:
- 使用with语句打开文件。
- 当with内部的代码块执行完毕后,就会自动调用close关闭文件。
代码示例:
with open('d:/Python环境/test.txt', 'r', encoding='utf-8') as f:
line = f.readline()
print(line)
说明一下: 在执行with内部的代码块时,无论因为什么原因而跳出with内部的代码块,都会自动调用close将对应的文件关闭。