R-trees: a dynamic index structure for spatial searching 1984
1 介绍
- R树可以看作B树再高维空间的扩展。它很好的解决了在高维空间搜索等问题。
- 采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解结点的方法,保证树的平衡性
- R树就是一棵用来存储高维数据的平衡树
2 R树数据结构
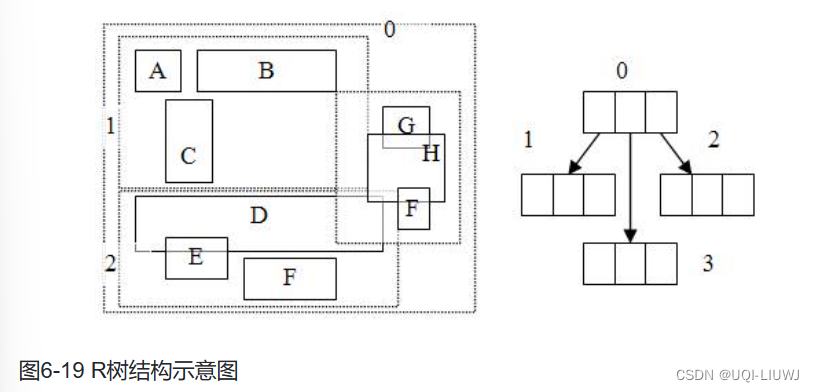
- R树采用了一种称为MBR(Minimal Bounding Rectangle,最小边界矩形)的方法,来分割空间
- 从叶子结点开始用矩形(rectangle)将空间框起来,结点越往上,框住的空间就越大,以此对空间进行分割
- R树的每个结点不存放空间要素的值。叶结点中存储该结点对应的空间要素的外包络矩形和空间要素标识
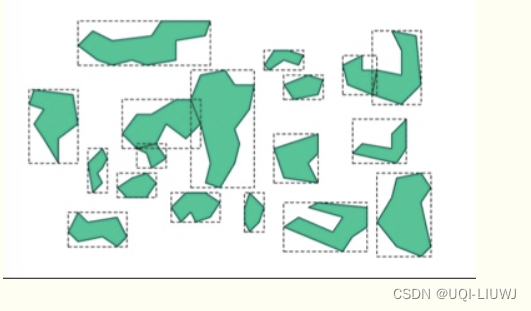
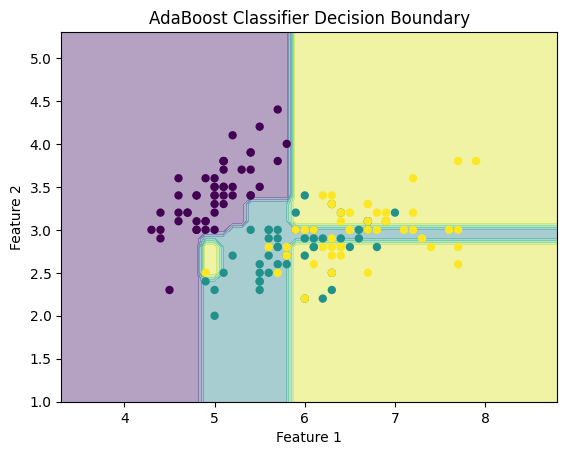
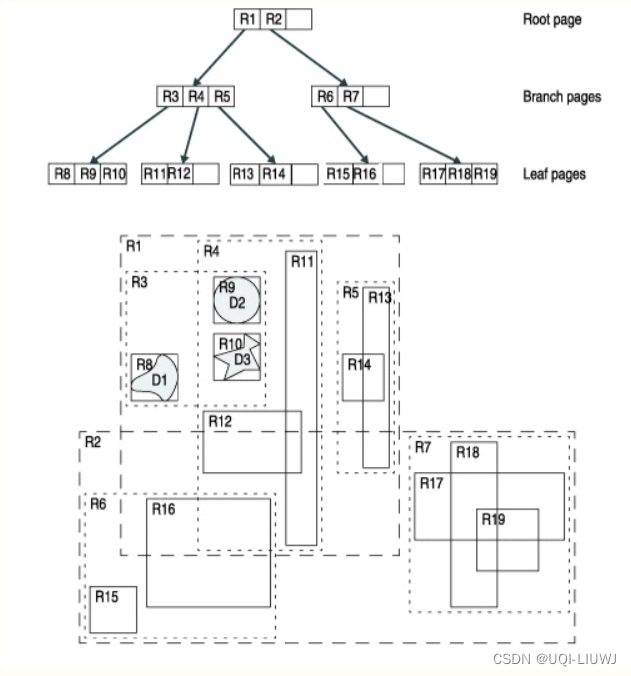
- 首先假设所有数据都是二维空间下的点,图中仅仅标志了R8区域中的数据,也就是那个shape of data object
- 为了实现R树结构,用一个最小边界矩形恰好框住这个不规则区域
- 这样就构造出了一个区域:R8
- 其他实线包围住的区域,如R9,R10,R12等都是同样的道理
- 一共得到了12个最最基本的最小矩形。这些矩形都将被存储在子结点中
- 下一步操作就是进行高一层次的处理。我们发现R8,R9,R10三个矩形距离最为靠近,因此就可以用一个更大的矩形R3恰好框住这3个矩形
- 同样道理,R15,R16被R6恰好框住,R11,R12被R4恰好框住
- 所有最基本的最小边界矩形被框入更大的矩形中之后
- 再次迭代,用更大的框去框住这些矩形
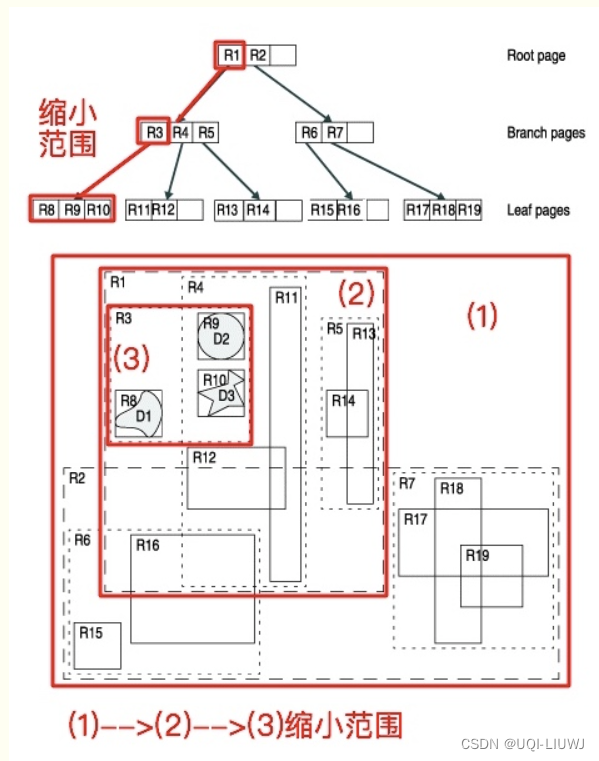
- 根据R树的这种数据结构,当我们需要进行一个高维空间查询时,我们只需要遍历少数几个叶子结点所包含的指针,查看这些指针指向的数据是否满足要求即可。
- ——>这种方式使我们不必遍历所有数据即可获得答案,效率显著提高
3 R树的查找
4 R树性质
-
除非它是根结点之外,所有叶子结点包含有m至M个记录索引(条目)。
-
作为根结点的叶子结点所具有的记录个数可以少于m。通常,m=M/2。
-
-
每一个非叶子结点拥有m至M个孩子结点,除非它是根结点
-
所有叶子结点都位于同一层,因此R树为平衡树
5 叶子节点的结构
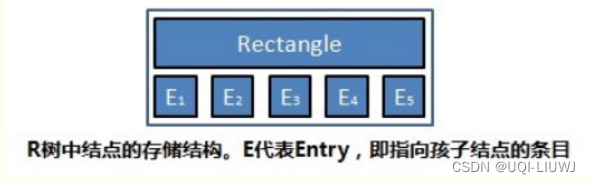
- 叶子结点所保存的数据形式为:(I, tuple-identifier)
- tuple-identifier表示的是一个存放于数据库中的tuple,也就是一条记录,它是n维的。
- I是一个n维空间的矩形,并可以恰好框住这个叶子结点中所有记录代表的n维空间中的点。
- I=(I0,I1,…,In-1)
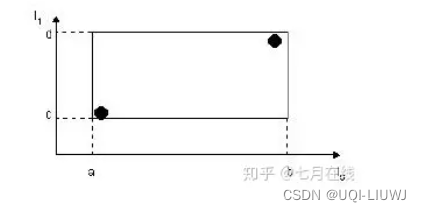
- I所代表的就是图中的矩形
- 有两个tuple-identifier,在图中即表示为那两个点
5 非叶子节点的结构
- R树的非叶子结点存放的数据结构为:(I, child-pointer)
- child-pointer是指向孩子结点的指针
- I是覆盖所有孩子结点对应矩形的矩形
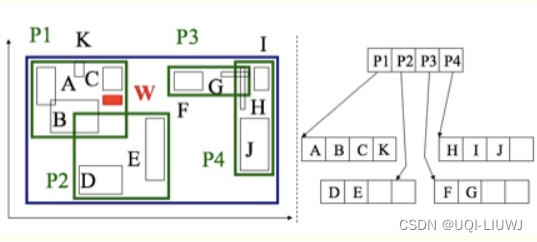
6 R树的插入
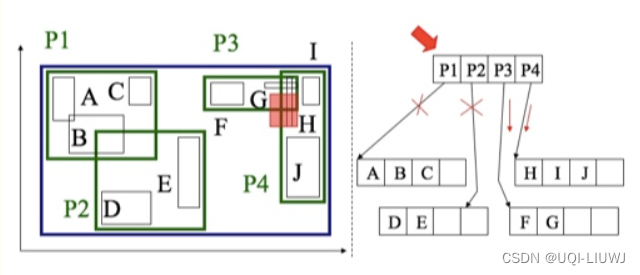
6.1 有足够的空间插入
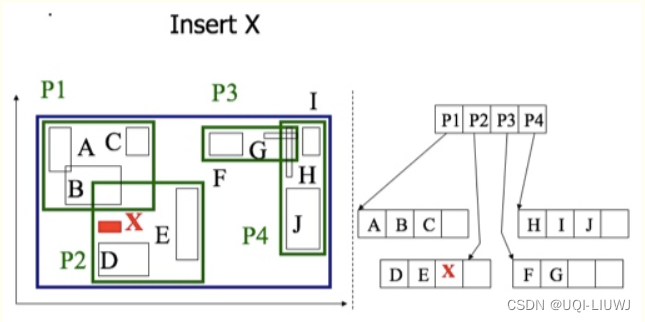
- 由于插入的x所在的区域P2的数据条目仍然有足够的空间容纳条目x,且x的区域面积即MBR也位于区域P2之内
- 所以这种情况下,我们认为x拥有足够的插入空间。
 ’
’
6.2 增大MBR
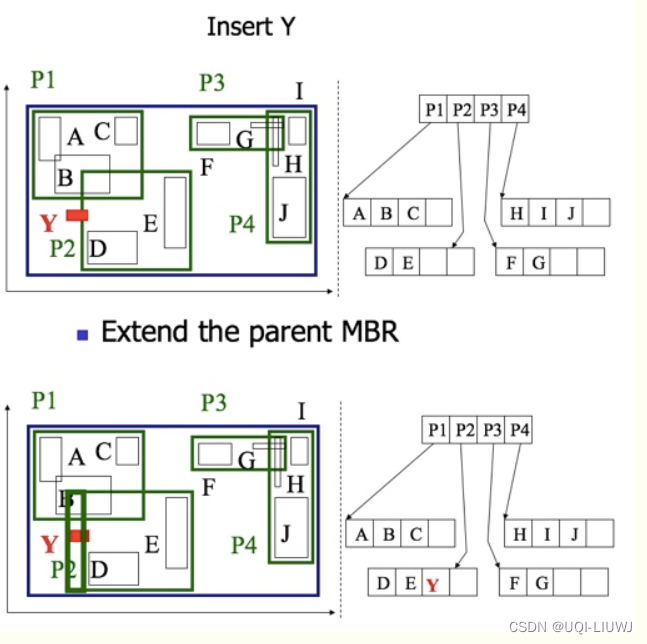
由于插入的y所在的区域P2的数据条目仍然有足够的空间容纳条目y,但是y的区域面积即MBR并不完全位于P2的区域之内,因此我们在插入数据y后会导致P2区域的相应扩大
6.3 需要进行分裂的插入
- 由于插入的w所在的区域P1的数据条目已经没有足够的空间容纳条目w,因为假设我们定义R树的阶m=4,而区域P1已经容纳了四个条目「A,B,C,K」了,插入w后孩子数为5,已经超过m=4了
- 所以要进行分类操作,来保证树的平衡性
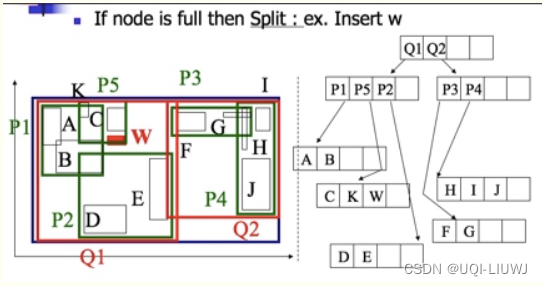
- 采用分裂算法对结点(区域)P2进行合理地分裂
- 使其分裂成P1(包含A,B)和P5(包含k,w)两个结点
- 由于分裂之后原来根结点「P1,P2,P3,P4」变成了「P1,P2,P3,P,P5」,因此根结点的孩子数由4变成5,超过了阶数m=4.
- 所以根结点也要进行分裂,分裂成Q1(包含P1,P5,P2)和Q2(包含P3,P4)两个结点
-
由于此时分裂已经传递到根结点,所以生成新的根结点记录Q1,Q2。
7 分裂
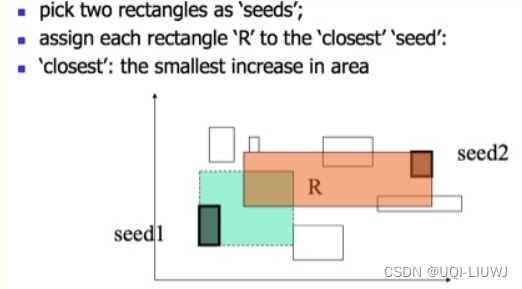
7.1 挑选seed
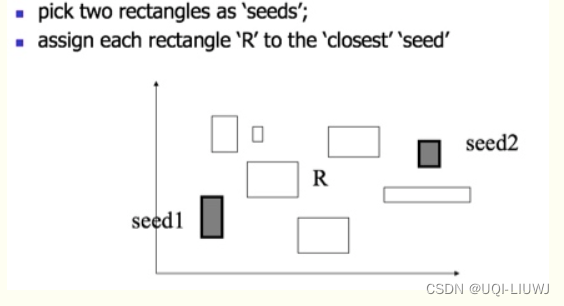
- 对于所有条目中的每一对E1和E2,计算可以包裹着E1,E2的最小限定框J=MBR(E1, E2) ,
- 然后计算增量d= J-E1-E2.
- 从 J 的面积中减去E1 和 E2 的面积,以找到包含两者所需的额外空间。
- 这个增量 d 反映了将E1 和E2 放在同一个边界矩形中所需的“额外”空间。
- 计算结束后选择d最大的一对(即增量最大)
- 选择增量 d 最大的一对条目的原因是,这样可以保证分裂后,生成的两个分组之间的重叠区域最小
- 然后计算增量d= J-E1-E2.
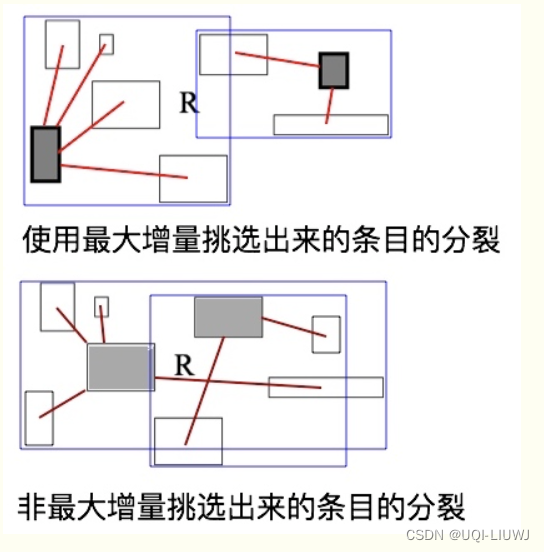
7.2 分类条目分组
- 挑选出seed1和seed2后,就将剩下的要分配的分裂条目分给这两个seed使它们各称为一个组
- 这个分配的原则就是离谁比较“近”就和谁一组
- 近指的是,对于条目E,分别计算可以包裹着E和seed1的最小限定框J1=MBR(E,seed1), 可以包裹着E和seed2的最小限定框J2=MBR(E,seed2)
- 再分别计算增量d1=J1-E-seed1,d2=J2-E-seed2。d1,d2哪个小就说明哪个“近”
- 这个分配的原则就是离谁比较“近”就和谁一组
8 删除
- B树删除过程中,如果出现结点的记录数少于半满(即下溢)的情况,则直接把这些记录与其他叶子的记录“融合”(两个相邻结点合并)
- R树却是直接重新插入
举例:
以下是原始的空间分割和R-tree
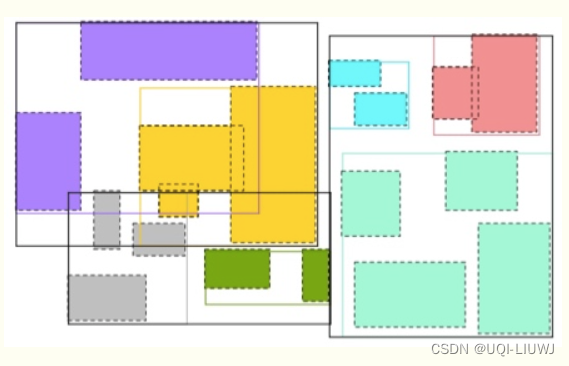
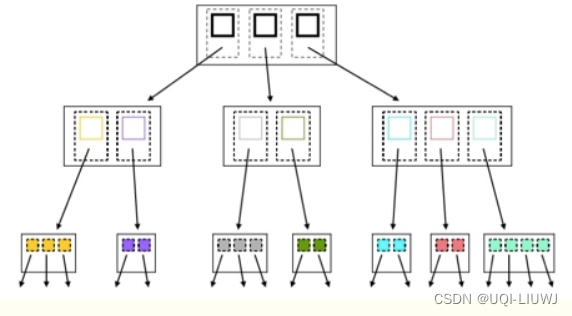
现在删除一个绿色的区域
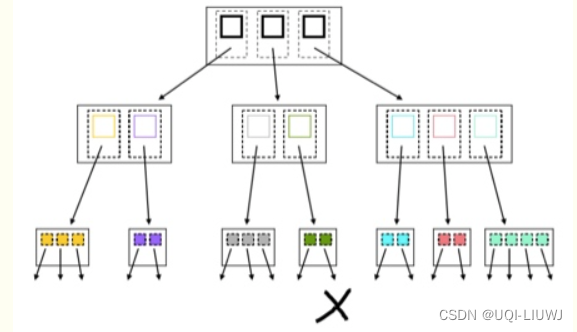
此时对应的MBR中只有一条记录,不满足R树性质,发生下溢,将另一个绿色的区域放入链表中
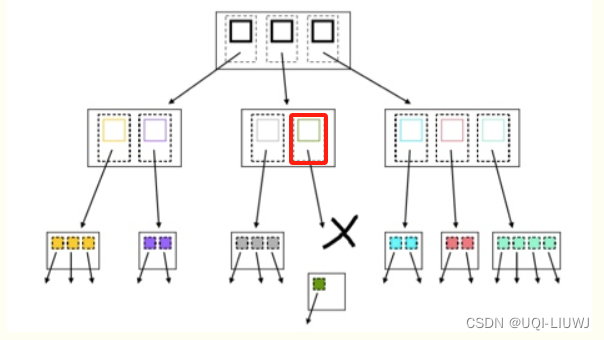
放入链表后,上层MBR也只有一条记录,所以也放入链表中
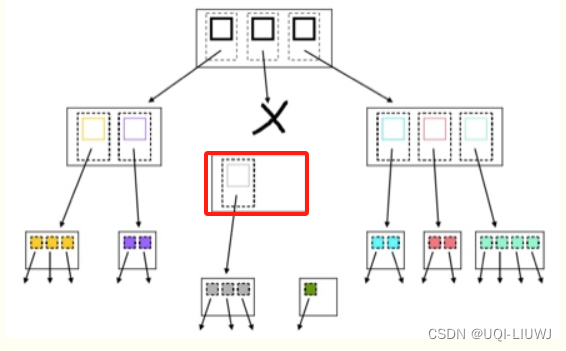
分别进行插入操作(也是一样,先找到矩形应该插入的位置,然后判断是否需要分裂)
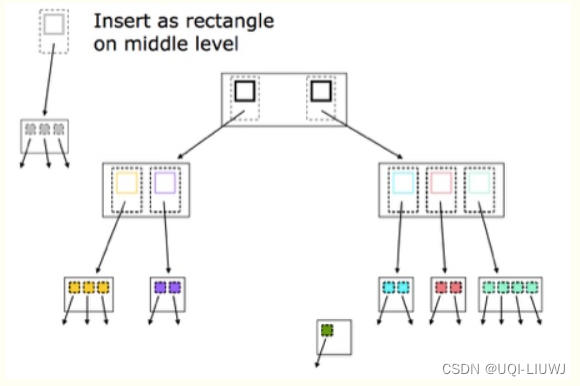
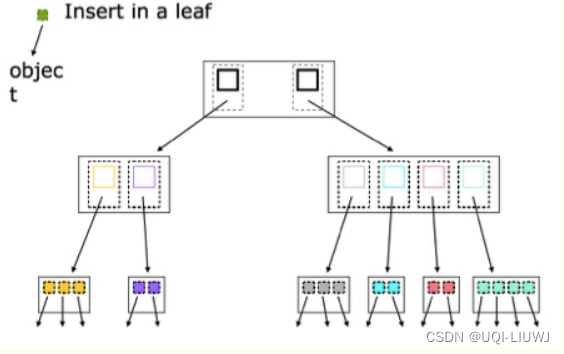
参考内容:什么是R树? - 知乎 (zhihu.com)
空间数据索引RTree(R树)完全解析及Java实现 - 佳佳牛 - 博客园 (cnblogs.com)