执行环境: Google Colab
1. 下载数据
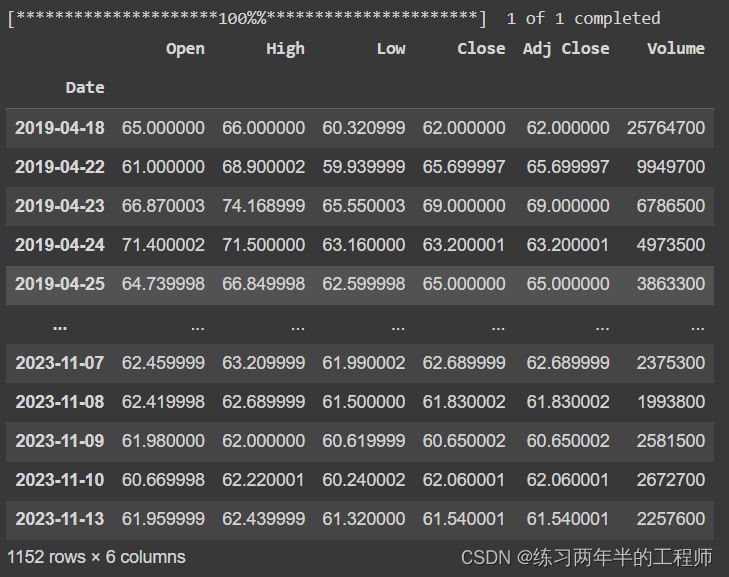
import yfinance as yf
ticker = 'ZM'
df = yf.download(ticker)
df
2. 数据预处理
df = df.loc['2020-01-01':].copy()
- 使用了
.loc方法来选择索引为 ‘2020-01-01’ 以后的所有行数据。 - 通过
.copy()方法创建了一个这些数据的副本,确保对副本的操作不会影响原始数据框。

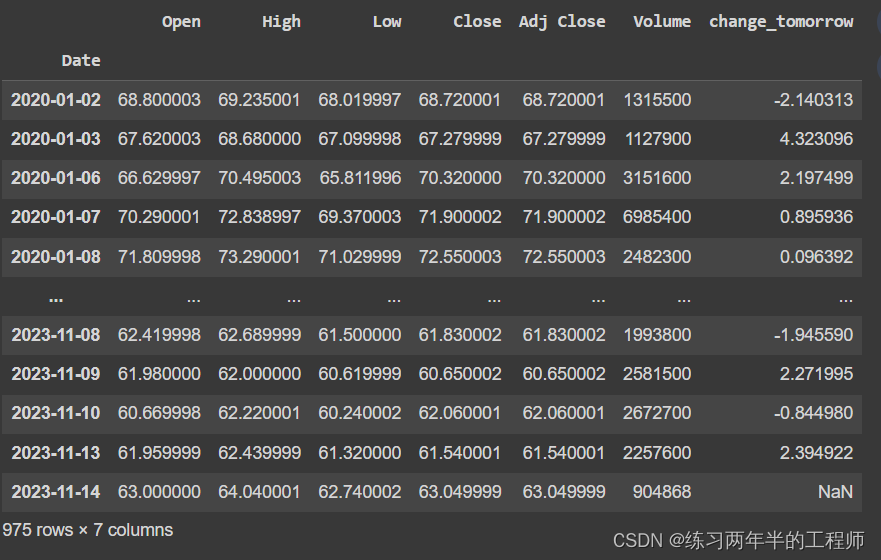
df['change_tomorrow'] = df['Adj Close'].pct_change(-1)
df.change_tomorrow = df.change_tomorrow * -1
df.change_tomorrow = df.change_tomorrow * 100
df
.pct_change(-1)这部分使用了pct_change方法来计算当前行与后一行的变化率,传入参数 -1 表示计算与后一行的变化率。- 将 ‘
change_tomorrow’ 列中的数值乘以 -1,将变化率转换为相反的方向。 - 将 ‘
change_tomorrow’ 列中的数值乘以 100,将变化率转换为百分比形式。
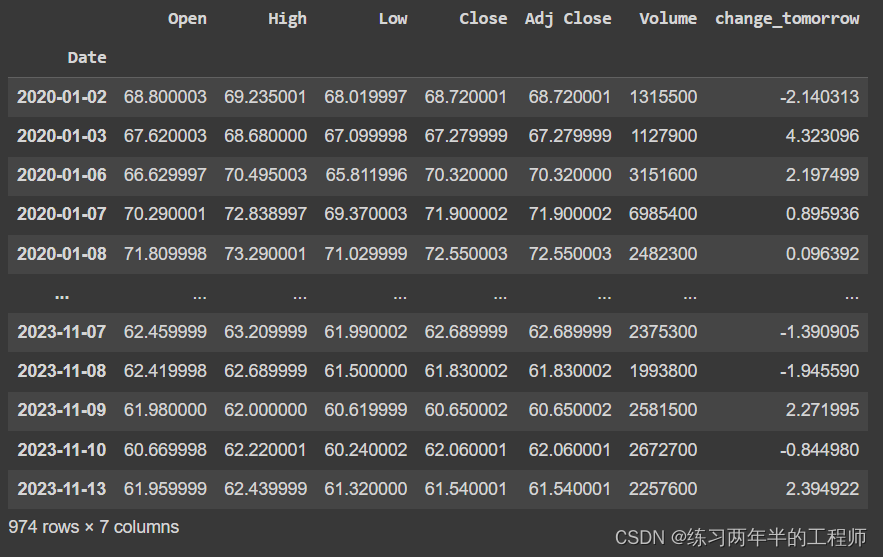
df = df.dropna().copy()
df
!pip uninstall scikit-learn
!pip install scikit-learn==1.1.3
3. 建立模型
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(max_depth=20, random_state=42)
y = df.change_tomorrow
X = df.drop(columns='change_tomorrow')
model.fit(X, y)

model.score(X, y)
0.7973700550772351
4. 创建一个名为 Regression 的策略类
!pip install Backtesting
from backtesting import Strategy
class Regression(Strategy):
limit_buy = 1
limit_sell = -5
def init(self):
self.model = model
self.already_bought = False
def next(self):
explanatory_today = self.data.df.iloc[[-1], :]
forecast_tomorrow = self.model.predict(explanatory_today)[0]
if forecast_tomorrow > self.limit_buy and self.already_bought == False:
self.buy()
self.already_bought = True
elif forecast_tomorrow < self.limit_sell and self.already_bought == True:
self.sell()
self.already_bought = False
else:
pass
limit_buy和limit_sell分别是买入和卖出的阈值init方法是初始化方法,在这里设置了模型和一个标记already_bought,用于追踪是否已经买入next方法是每个交易周期调用的方法。在这里,首先通过self.data.df.iloc[[-1], :]获取了最近一天的数据作为当天的解释变量。然后使用模型self.model对明天的预测值进行预测,forecast_tomorrow = self.model.predict(explanatory_today)[0]这行代码就是进行了明天的预测。- 如果预测值高于买入阈值且尚未买入(
self.already_bought == False),则执行买入操作并将already_bought标记为已买入。 - 如果预测值低于卖出阈值且已经买入(
self.already_bought == True),则执行卖出操作并将already_bought标记为未买入。
5. 创建一个交易回测的实例
!pip install scikit-optimize
from backtesting import Backtest
bt = Backtest(
X, Regression, cash=10000,
commission = .002, exclusive_orders=True
)
X: 这是指定的交易数据或特征数据,用于执行交易策略的数据Regression: 这是之前定义的策略类,表示将使用哪个策略来进行交易cash=10000: 这个参数表示初始资金,设置为 10000commission=.002: 这个参数表示交易佣金,设置为 0.2%exclusive_orders=True: 这个参数表示交易订单是否独占性,设置为True,意味着同一时间只能有一个买入或卖出订单执行
6. 进行交易回测优化的过程
stats_skopt, heatmap, optimize_result = bt.optimize(
limit_buy = [0, 10],
limit_sell = [-10, 0],
maximize = 'Return [%]',
method = 'skopt',
max_tries = 500,
random_state = 0,
return_heatmap = True,
return_optimization = True
)
limit_buy的范围设置在 0 到 10 之间,而limit_sell的范围设置在 -10 到 0 之间,这表示优化的目标是在这个区间内找到最佳的参数值maximize = 'Return [%]'指定了要最大化的指标,这里是 ‘Return [%]’,即回报率的百分比。优化的目标是使得回报率最大化method = 'skopt'指定了优化的方法为 ‘skopt’,这是基于scikit-optimize库的一种优化方法max_tries = 500设置了最大尝试次数为 500 次,意味着在尝试寻找最优参数值时,会进行最多 500 次的尝试return_heatmap = True和return_optimization = True分别指定了返回热图和优化结果
import numpy as np
dff = heatmap.reset_index()
dff = dff.pivot(index='limit_buy', columns='limit_sell', values='Return [%]')
dff.sort_index(axis=1, ascending=False)\
.style.format(precision=0)\
.background_gradient(vmin=np.nanmin(dff), vmax=np.nanmax(dff))\
.highlight_null(props='background-color: transparent; color: transparent')
dff = heatmap.reset_index(): 这行代码是将名为heatmap的数据重新设置索引,将原先的索引变为列,并将结果保存在dff中- 使用
pivot方法将dff数据重新构造成一个以 ‘limit_buy’ 列为行索引,‘limit_sell’ 列为列索引,‘Return [%]’ 列为值的新数据框,并将结果保存在dff中 dff.sort_index(axis=1, ascending=False): 这行代码对列进行降序排序.style.format(precision=0): 这部分代码是对样式进行格式化,将数值的显示精度设置为整数(precision=0)- 使用了
background_gradient方法,根据数值的范围进行颜色渐变。vmin和vmax参数指定了颜色渐变的最小值和最大值,使用了np.nanmin()和np.nanmax()函数来忽略NaN值并确定渐变的范围 - 对空值(
NaN值)进行样式化处理,将其背景颜色和文本颜色设置为透明,以减少空值的影响。

7. 绘制优化过程中的评估结果
from skopt.plots import plot_evaluations
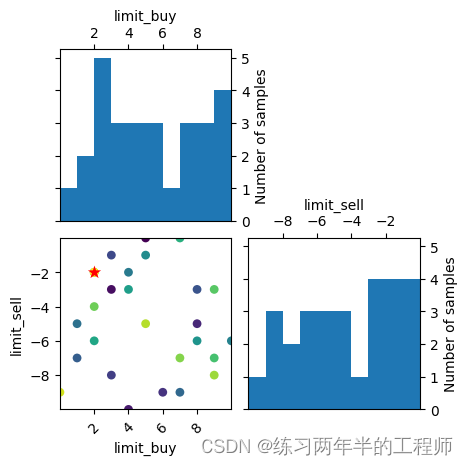
_ = plot_evaluations(optimize_result, bins=10)
- 参数
optimize_result是优化过程中获得的结果,bins=10表示将结果分成 10 份以展示评估结果的分布情况
8. 绘制优化过程中目标函数的图表
from skopt.plots import plot_objective
_ = plot_objective(optimize_result, n_points=10)
- 参数
optimize_result是优化过程中获得的结果,n_points=10表示在图表中显示的离散点的数量为 10 个,用于展示目标函数的走势和变化情况