警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。 Elastic 将努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束。目前的最新发行版为 Elastic Stack 8.11。
Elasticsearch 查询语言 (ES|QL) 提供了一种强大的方法来过滤、转换和分析存储在 Elasticsearch 中以及未来其他运行时中的数据。 它旨在易于最终用户、SRE 团队、应用程序开发人员和管理员学习和使用。
用户可以编写 ES|QL 查询来查找特定事件、执行统计分析并生成可视化效果。 它支持广泛的命令和功能,使用户能够执行各种数据操作,例如过滤、聚合、时间序列分析等。
Elasticsearch 查询语言 (ES|QL) 使用 “管道”(|) 逐步操作和转换数据。 这种方法允许用户组合一系列操作,其中一个操作的输出成为下一个操作的输入,从而实现复杂的数据转换和分析。
ES|QL 计算引擎
ES|QL 不仅仅是一种语言:它代表了对 Elasticsearch 内新计算功能的重大投资。 为了同时满足 ES|QL 的功能和性能要求,有必要构建全新的计算架构。 ES|QL 搜索、聚合和转换功能直接在 Elasticsearch 本身内执行。 查询表达式不会转换为查询 DSL 来执行。 这种方法使 ES|QL 具有极高的性能和多功能性。
新的 ES|QL 执行引擎在设计时充分考虑了性能 - 它一次对块(block)而不是对每行进行操作,以向量化和缓存局部性为目标,并支持专业化和多线程。 它是一个独立于现有 Elasticsearch 聚合框架的组件,具有不同的性能特征。
让我们开始吧
在接下来的部分我们将展示了如何使用 ES|QL 查询和聚合数据。
前提条件
我们必须安装 Elastic Stack 8.11 及以上版本。
要遵循下面的查询,首先使用以下请求提取一些示例数据:
PUT sample_data
{
"mappings": {
"properties": {
"client.ip": {
"type": "ip"
},
"message": {
"type": "keyword"
}
}
}
}PUT sample_data/_bulk
{"index": {}}
{"@timestamp": "2023-10-23T12:15:03.360Z", "client.ip": "172.21.2.162", "message": "Connected to 10.1.0.3", "event.duration": 3450233}
{"index": {}}
{"@timestamp": "2023-10-23T12:27:28.948Z", "client.ip": "172.21.2.113", "message": "Connected to 10.1.0.2", "event.duration": 2764889}
{"index": {}}
{"@timestamp": "2023-10-23T13:33:34.937Z", "client.ip": "172.21.0.5", "message": "Disconnected", "event.duration": 1232382}
{"index": {}}
{"@timestamp": "2023-10-23T13:51:54.732Z", "client.ip": "172.21.3.15", "message": "Connection error", "event.duration": 725448}
{"index": {}}
{"@timestamp": "2023-10-23T13:52:55.015Z", "client.ip": "172.21.3.15", "message": "Connection error", "event.duration": 8268153}
{"index": {}}
{"@timestamp": "2023-10-23T13:53:55.832Z", "client.ip": "172.21.3.15", "message": "Connection error", "event.duration": 5033755}
{"index": {}}
{"@timestamp": "2023-10-23T13:55:01.543Z", "client.ip": "172.21.3.15", "message": "Connected to 10.1.0.1", "event.duration": 1756467}我们有两种方法可以运行查询:
- 在 Dev Tools 中运行
- 在 Discover 中运行
在 Dev Tools 中运行查询
我们需要在 Kibana 的界面中,进入到 Dev Tools。通常一个 ES|QL query API 的命令格式是这样的:
POST /_query?format=txt
{
"query": """
"""
}在两组 """ """之间输入实际的 ES|QL 查询。 例如:
POST /_query?format=txt
{
"query": """
FROM sample_data
"""
}
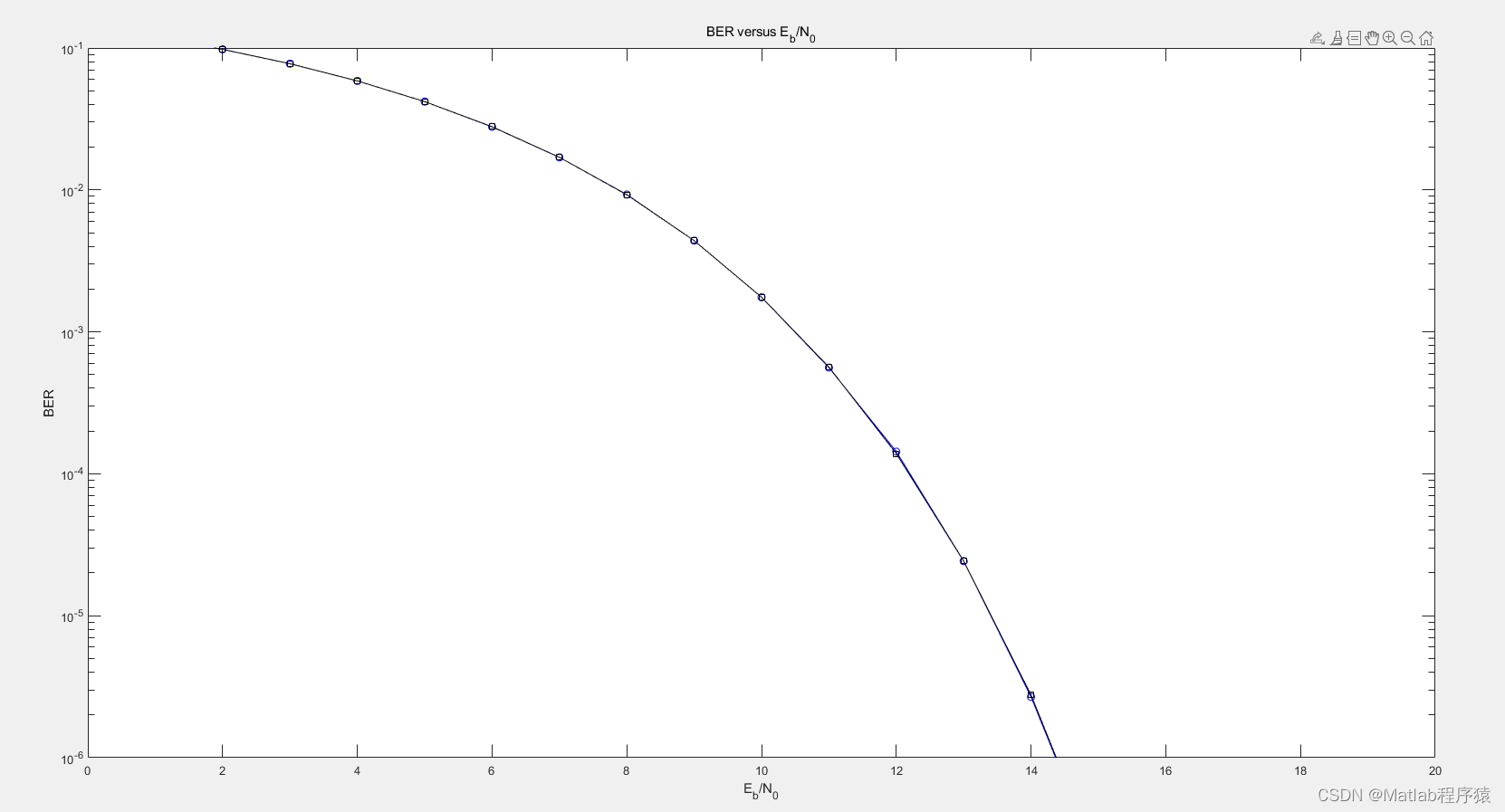
我们也可以使用 JSON 的格式来返回结果:
POST /_query?format=json
{
"query": """
FROM sample_data
"""
}
在 Discover 中使用 ES|QL
我们首先为 sample_data 这个索引创建一个 data view:
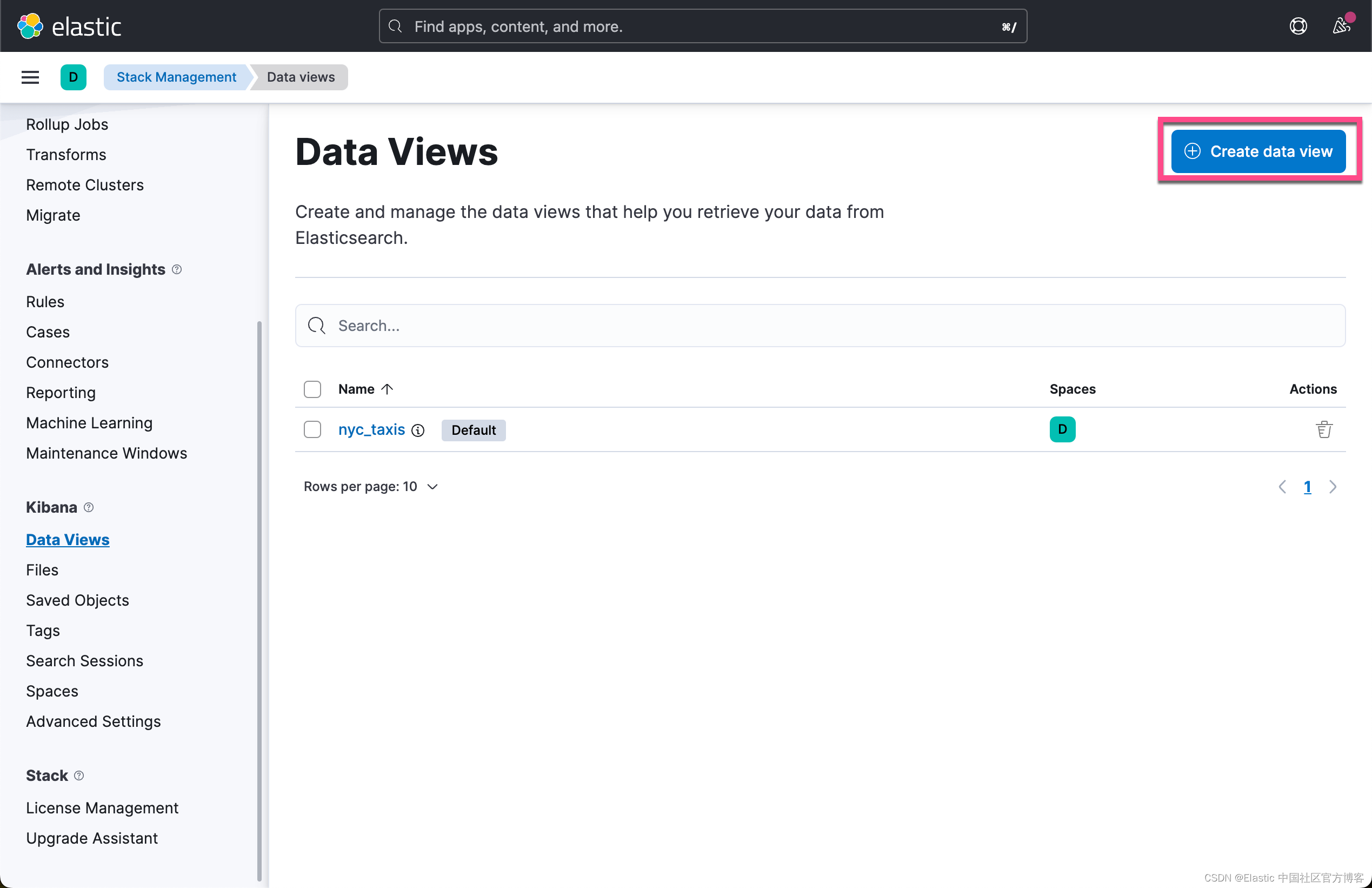
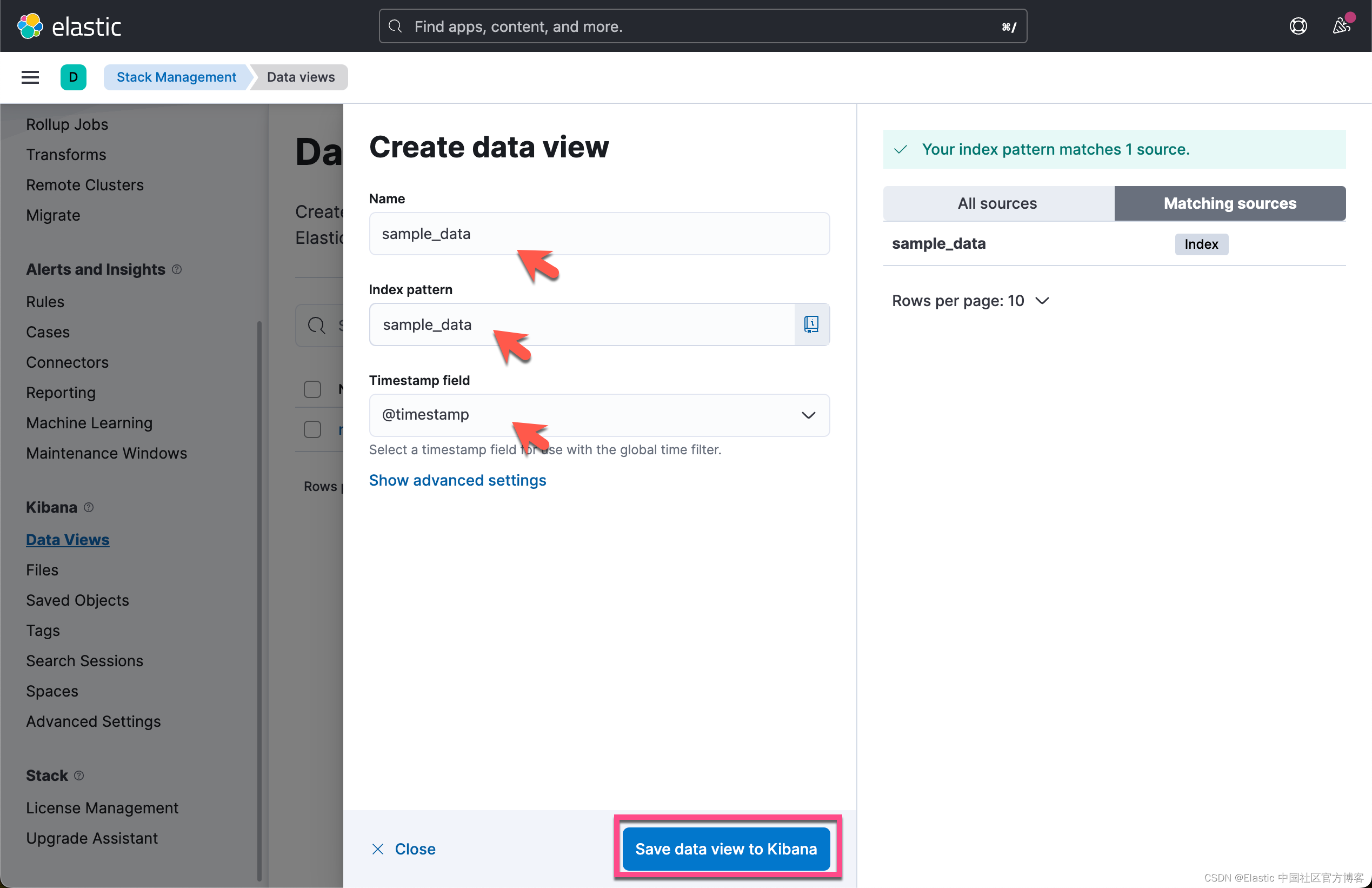

这样我们就创建了一个 sample_data 的 data view。
我们打开 Discover 界面:
我们首先选中 sample_data,然后选中合适的时间窗口:
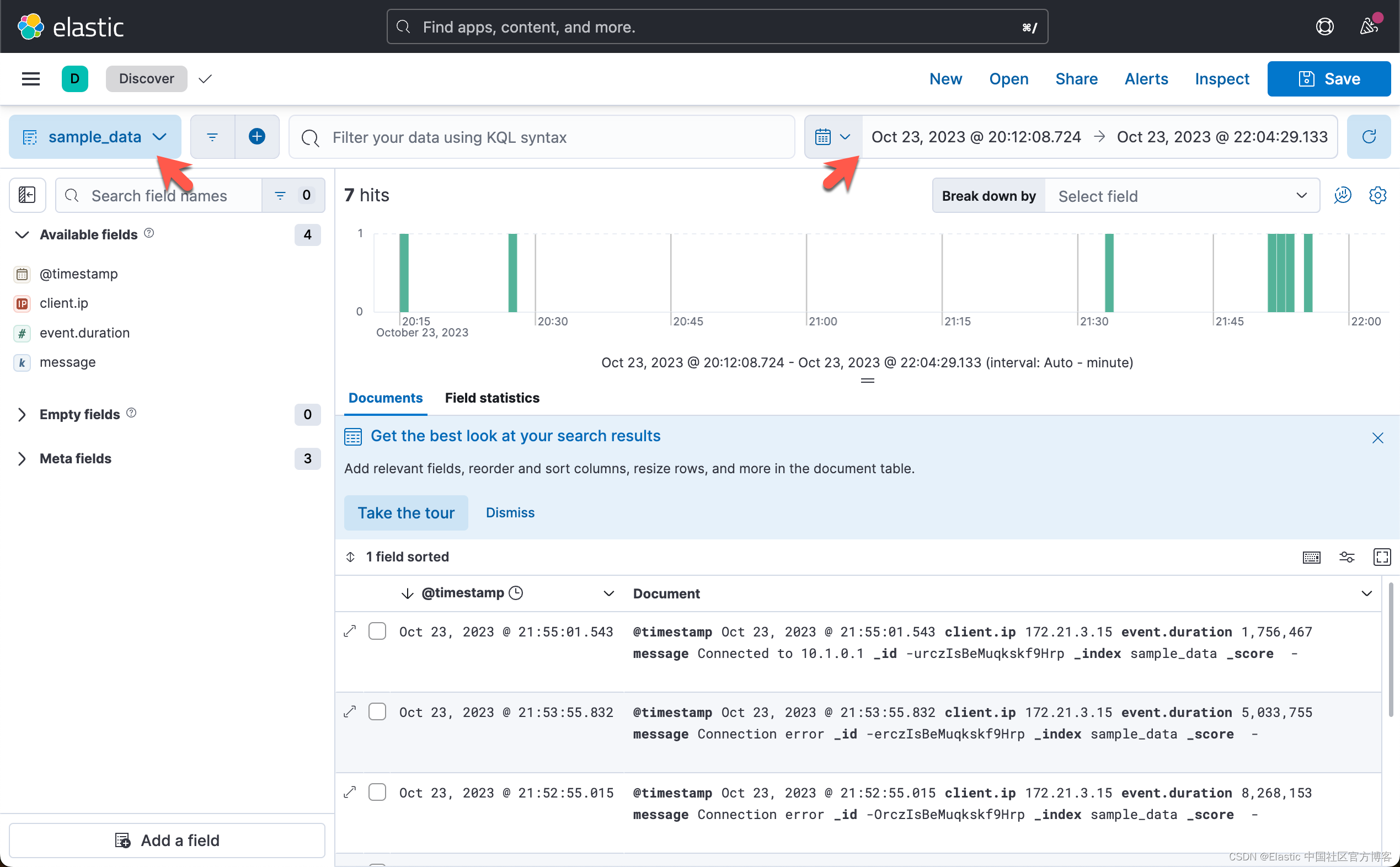

在默认的情况下,它显示 10 个文档。我们也可以看到一个可视化图。为了更方便地编写多行查询,请单击双头箭头按钮(![]() )来展开查询栏:
)来展开查询栏:
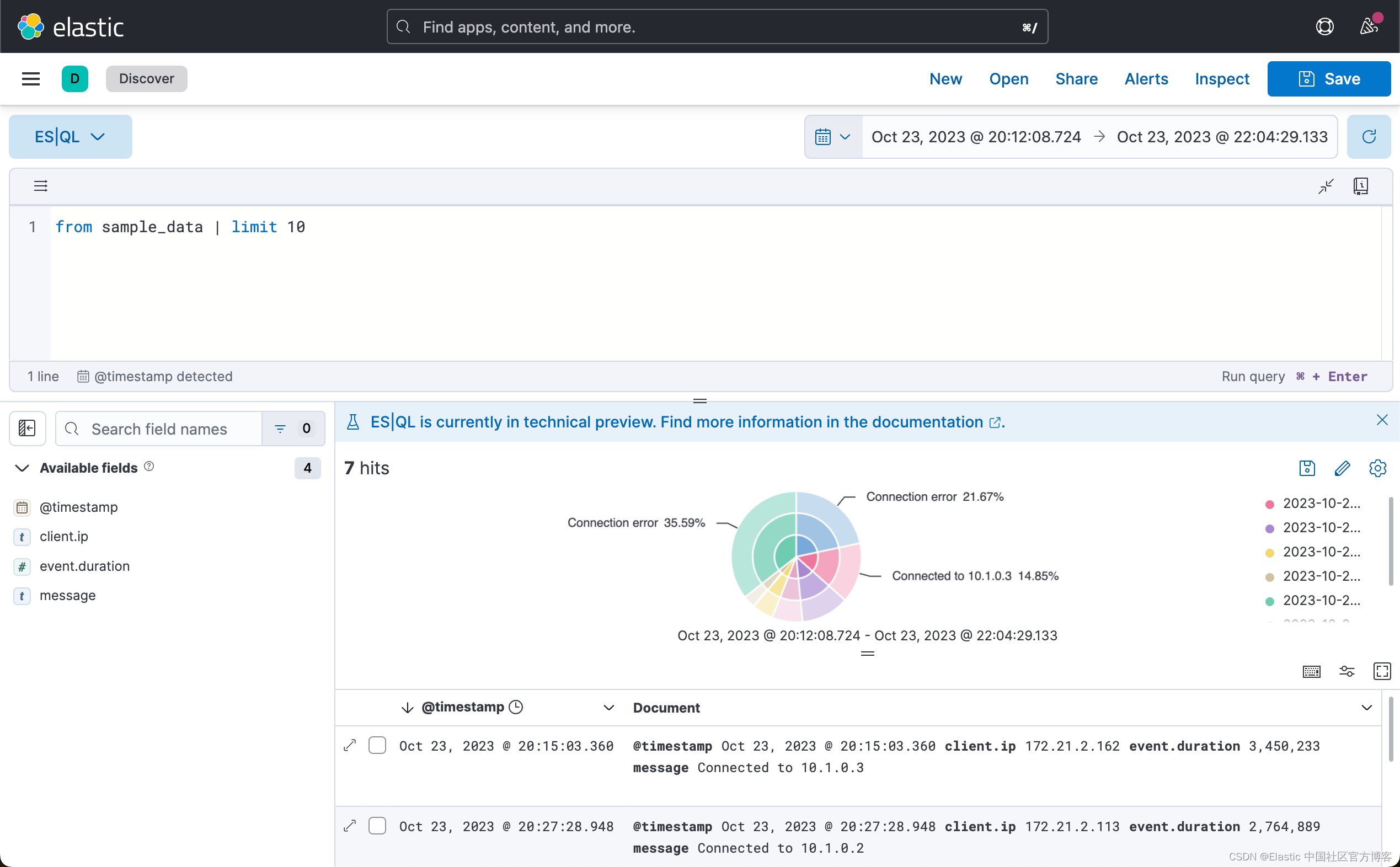
我们的第一个 ES|QL 查询
每个 ES|QL 查询都以源 (source) 命令开头。 源命令会生成一个表,通常包含来自 Elasticsearch 的数据。
FROM source 命令返回一个表,其中包含来自数据流、索引或别名的文档。 结果表中的每一行代表一个文档。 此查询从 sample_data 索引中返回最多 500 个文档:
FROM sample_data每列对应一个字段,并且可以通过该字段的名称进行访问。
提示:ES|QL 关键字不区分大小写。 以下查询与前一个查询相同:
from sample_data
处理命令
源命令后面可以跟一个或多个处理命令,用竖线字符分隔:|。 处理命令通过添加、删除或更改行和列来更改输入表。 处理命令可以执行过滤、投影、聚合等。
例如,你可以使用 LIMIT 命令来限制返回的行数,最多为 10,000 行:
FROM sample_data
| LIMIT 3提示:为了便于阅读,你可以将每个命令放在单独的行上。 但是,你不必这样做。 以下查询与前一个查询相同:
FROM sample_data | LIMIT 3
对表格进行排序
另一个处理命令是 SORT 命令。 默认情况下,FROM 返回的行没有定义的排序顺序。 使用 SORT 命令对一列或多列上的行进行排序:
FROM sample_data
| SORT @timestamp DESC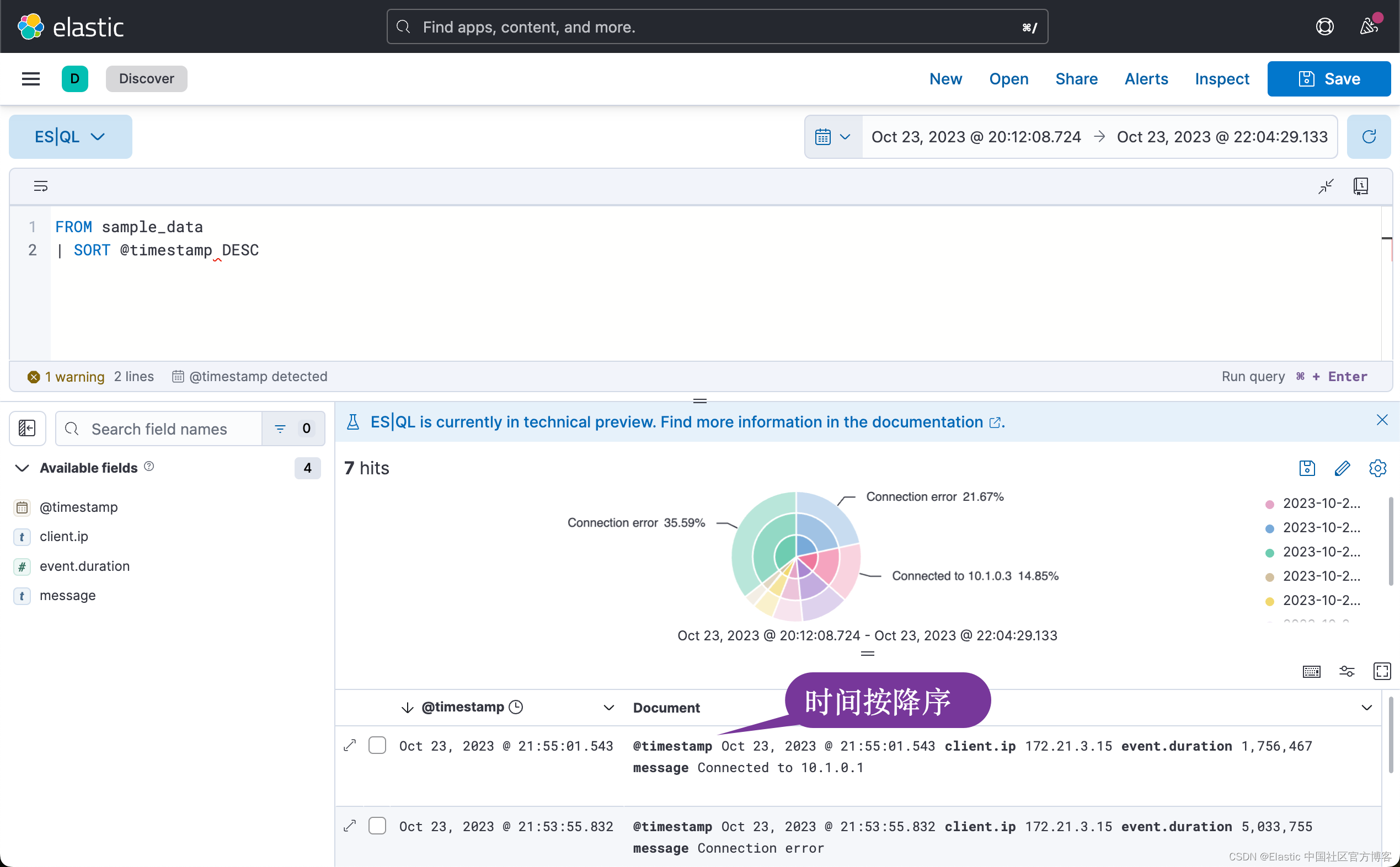
查询数据
使用 WHERE 命令来查询数据。 例如,要查找持续时间超过 5 毫秒的所有事件:
FROM sample_data
| WHERE event.duration > 5000000WHERE 支持多个运算符。 例如,你可以使用 LIKE 对消息列运行通配符查询:
FROM sample_data
| WHERE message LIKE "Connected*"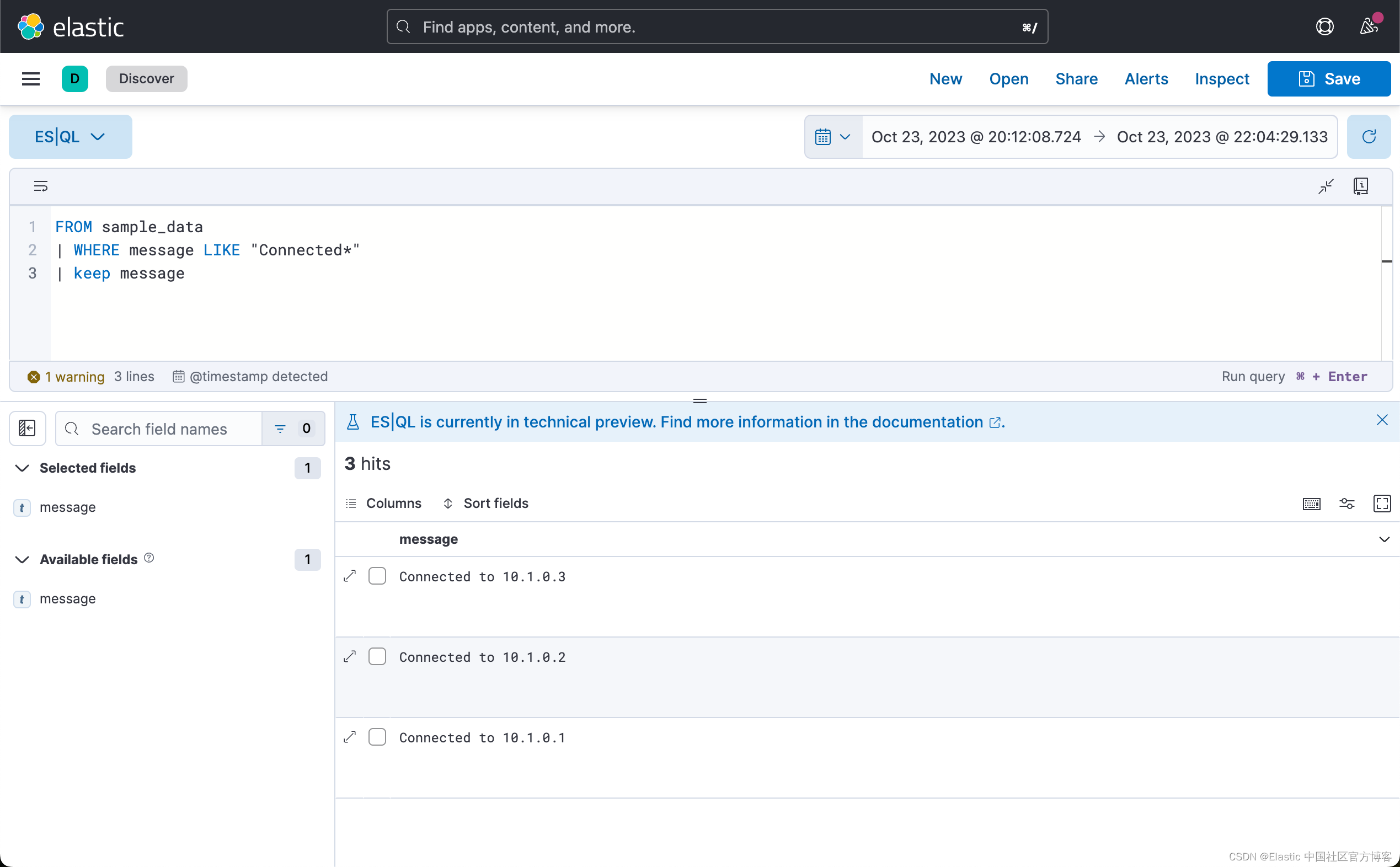
更多处理命令
还有许多其他处理命令,例如用于保留或删除列的 KEEP 和 DROP、用于使用 Elasticsearch 中索引的数据丰富表的 ENRICH 以及用于处理数据的 DISSECT 和 GROK。 有关所有处理命令的概述,请参阅 “Elasticsearch:ES|QL 查询语言简介”。
链式处理命令
你可以链接处理命令,并用竖线字符分隔:|。 每个处理命令都作用于前一个命令的输出表。 查询的结果是最终处理命令生成的表。
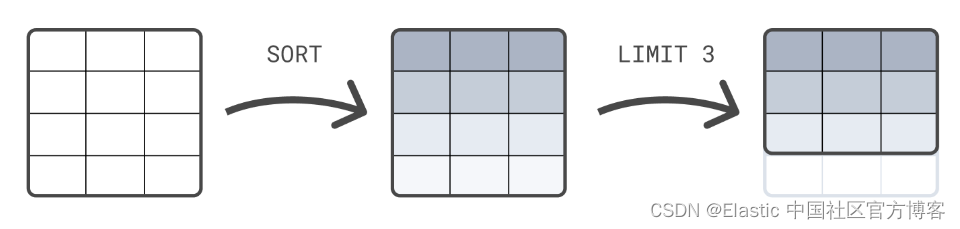
以下示例首先根据 @timestamp 对表进行排序,然后将结果集限制为 3 行:
FROM sample_data
| SORT @timestamp DESC
| LIMIT 3注意:处理命令的顺序很重要。 首先将结果集限制(LIMIT)为 3 行,然后再对这 3 行进行排序,很可能会返回与此示例不同的结果,其中排序在 LIMIT 之前。
计算值
使用 EVAL 命令将包含计算值的列追加到表中。 例如,以下查询附加一个 duration_ms 列。 该列中的值是通过将 event.duration 除以 1,000,000 计算得出的。 换句话说: event.duration 从纳秒转换为毫秒。
FROM sample_data
| EVAL duration_ms = event.duration / 1000000.0
EVAL 支持多种 functions。 例如,要将数字四舍五入为最接近指定位数的数字,请使用 ROUND 函数:
FROM sample_data
| EVAL duration_ms = ROUND(event.duration / 1000000.0, 1)计算统计数据
ES|QL 不仅可以用来查询你的数据,你还可以使用它来聚合你的数据。 使用 STATS ... BY 命令计算统计数据。 例如,中位持续时间:
FROM sample_data
| STATS median_duration = MEDIAN(event.duration)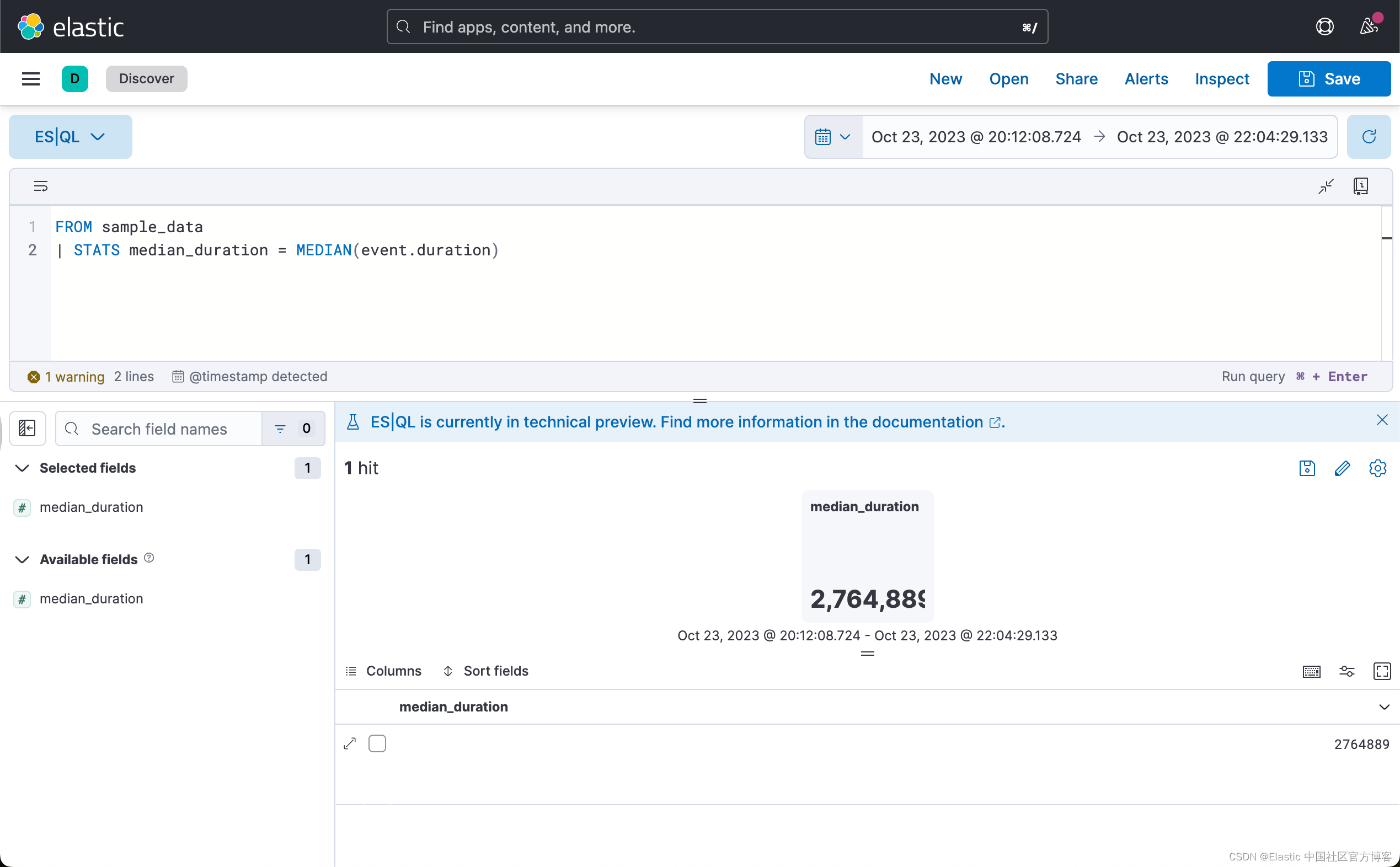
你可以使用一个命令计算多个统计数据:
FROM sample_data
| STATS median_duration = MEDIAN(event.duration), max_duration = MAX(event.duration)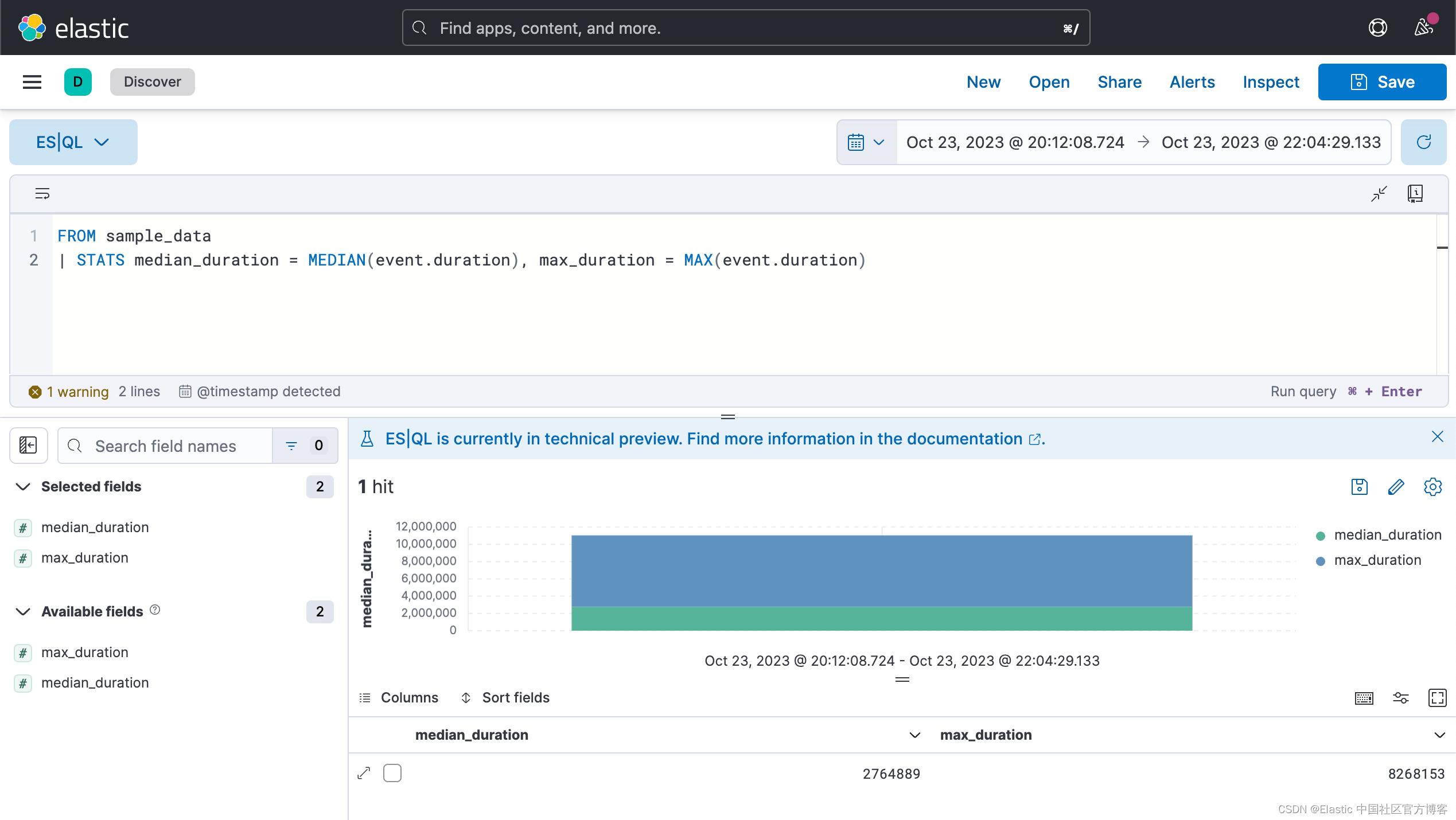
使用 BY 按一列或多列对计算的统计数据进行分组。 例如,要计算每个客户端 IP 的中位持续时间:
FROM sample_data
| STATS median_duration = MEDIAN(event.duration) BY client.ip
创建直方图
为了跟踪一段时间内的统计数据,ES|QL 允许你使用 AUTO_BUCKET 函数创建直方图。 AUTO_BUCKET 创建人性化的存储桶大小,并为每行返回一个与该行所属的结果存储桶相对应的值。
例如,要为 10 月 23 日的数据创建每小时存储桶:
FROM sample_data
| KEEP @timestamp
| EVAL bucket = AUTO_BUCKET (@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")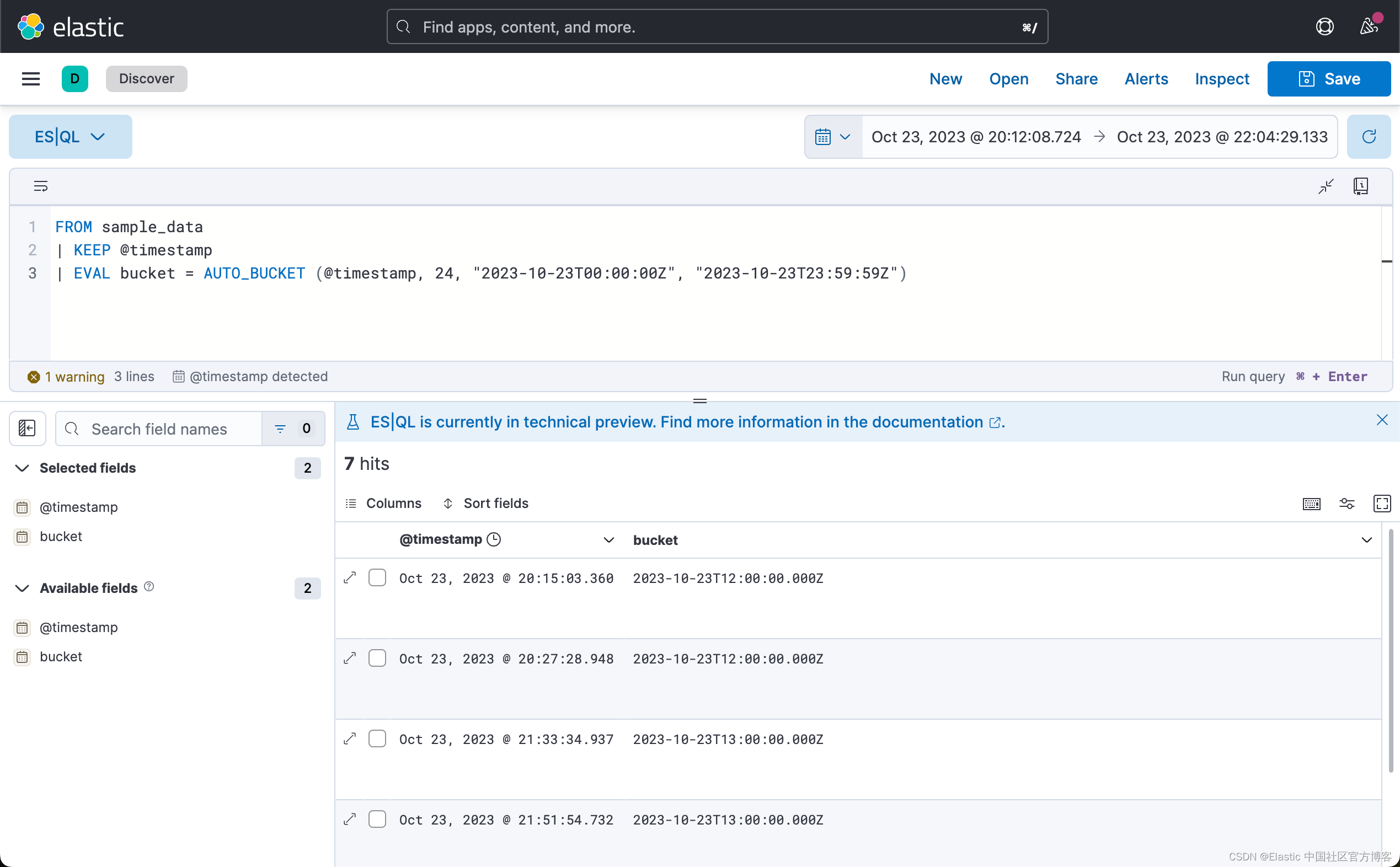
将 AUTO_BUCKET 与 STATS ... BY 结合起来创建直方图。 例如,要计算每小时的事件数:
FROM sample_data
| KEEP @timestamp, event.duration
| EVAL bucket = AUTO_BUCKET (@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
| STATS COUNT(*) BY bucket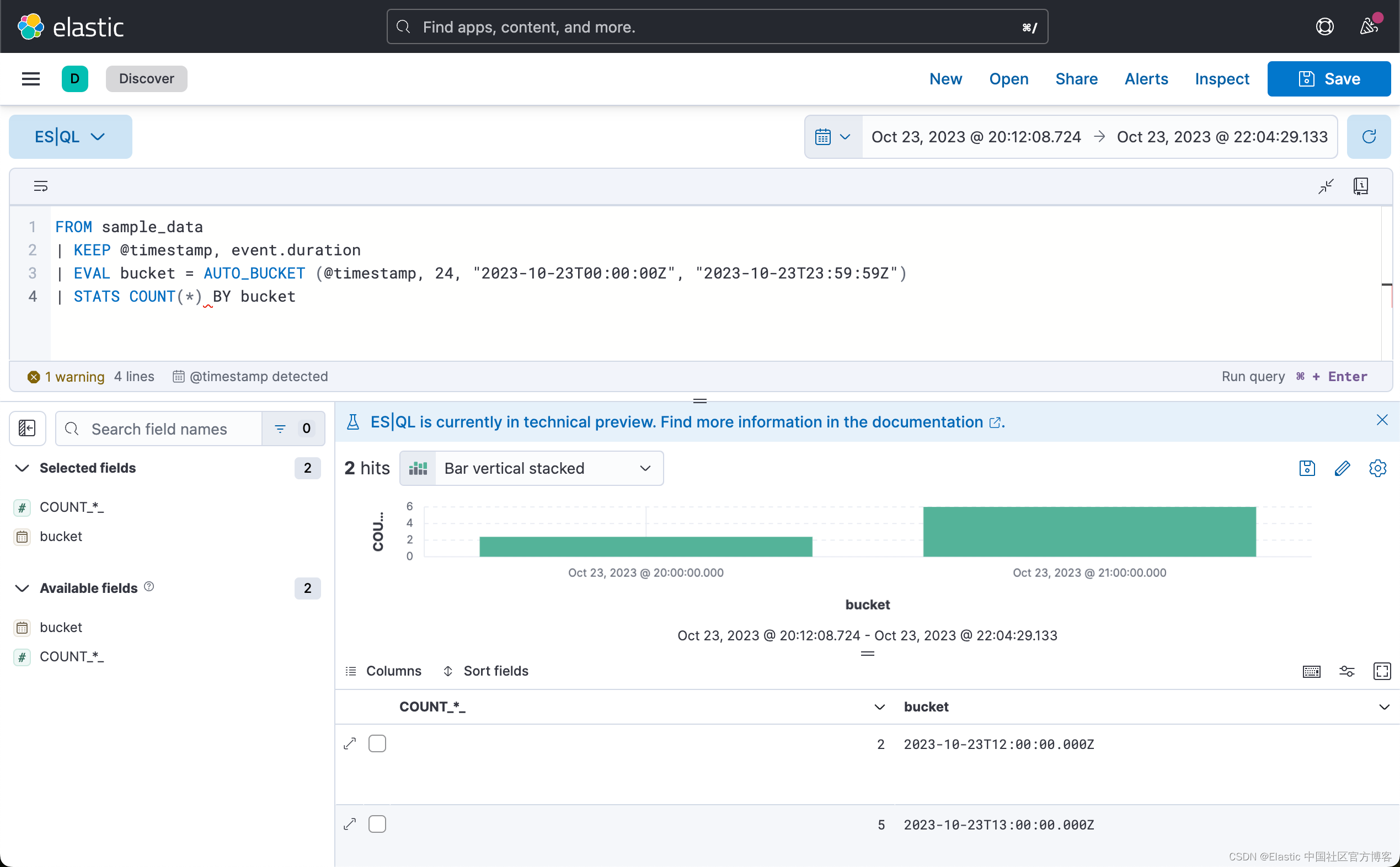
或每小时的中位持续时间:
FROM sample_data
| KEEP @timestamp, event.duration
| EVAL bucket = AUTO_BUCKET (@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
| STATS median_duration = MEDIAN(event.duration) BY bucket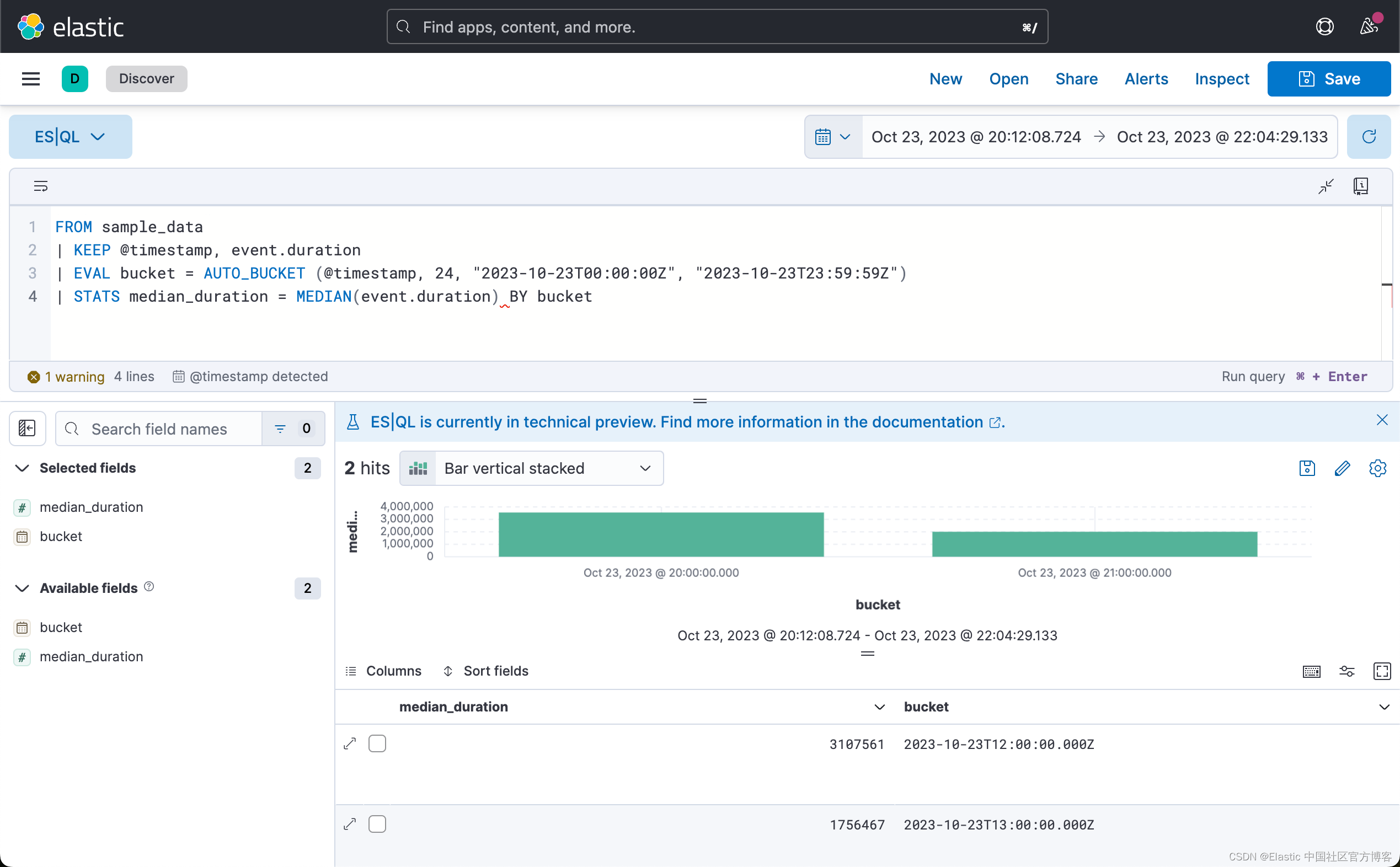
丰富数据
ES|QL 使你能够使用 ENRICH 命令使用 Elasticsearch 中索引的数据来丰富表。
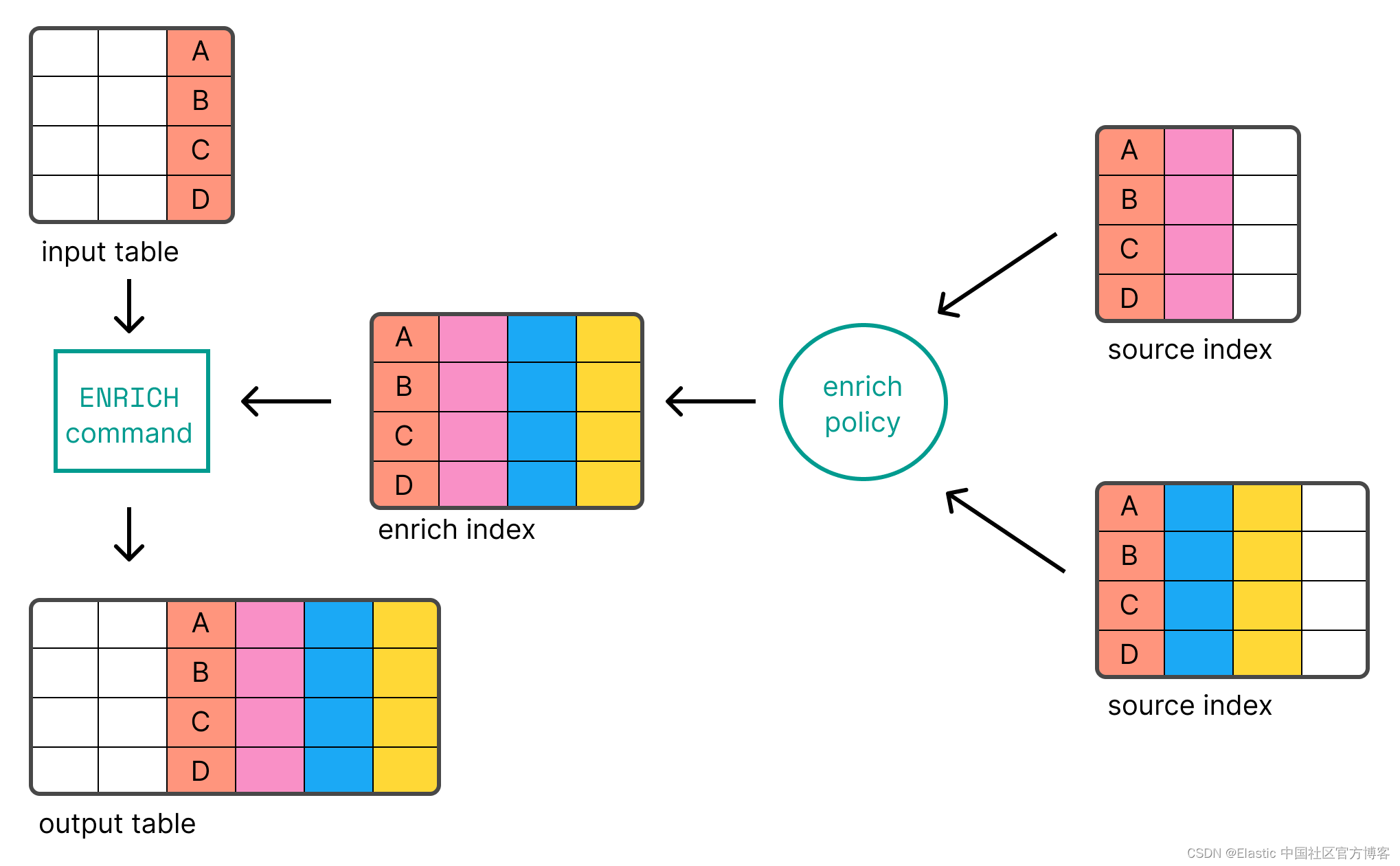
在使用 ENRICH 之前,你首先需要 create 并 execute 你的 enrich policy。 以下请求创建并执行将 IP 地址链接到环境(“Development”、“QA” 或 “Production”)的策略:
PUT clientips
{
"mappings": {
"properties": {
"client.ip": {
"type": "keyword"
},
"env": {
"type": "keyword"
}
}
}
}PUT clientips/_bulk
{ "index" : {}}
{ "client.ip": "172.21.0.5", "env": "Development" }
{ "index" : {}}
{ "client.ip": "172.21.2.113", "env": "QA" }
{ "index" : {}}
{ "client.ip": "172.21.2.162", "env": "QA" }
{ "index" : {}}
{ "client.ip": "172.21.3.15", "env": "Production" }
{ "index" : {}}
{ "client.ip": "172.21.3.16", "env": "Production" }PUT /_enrich/policy/clientip_policy
{
"match": {
"indices": "clientips",
"match_field": "client.ip",
"enrich_fields": ["env"]
}
}PUT /_enrich/policy/clientip_policy/_execute创建并执行策略后,你可以将其与 ENRICH 命令一起使用:
FROM sample_data
| KEEP @timestamp, client.ip, event.duration
| EVAL client.ip = TO_STRING(client.ip)
| ENRICH clientip_policy ON client.ip WITH env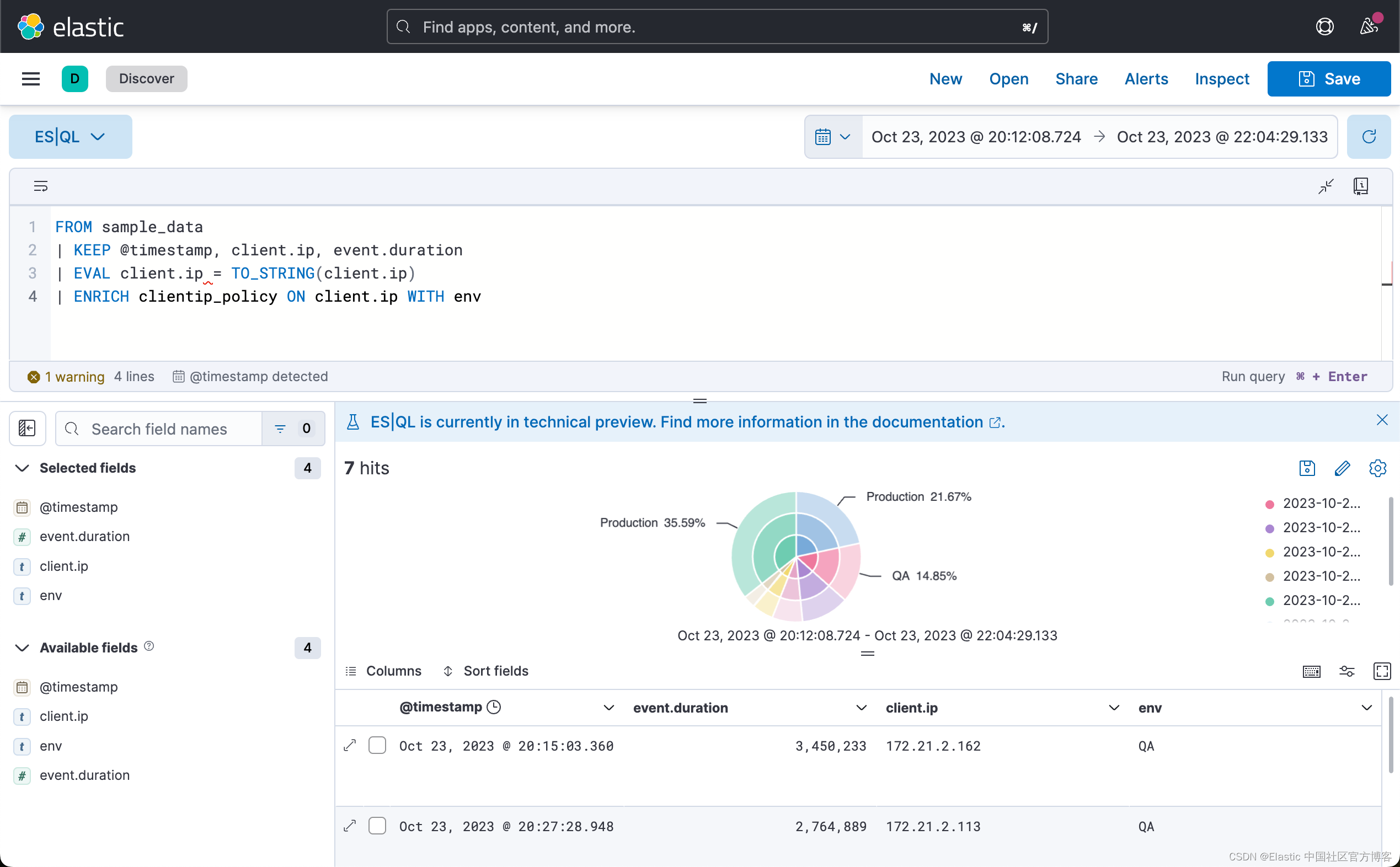
你可以在后续命令中使用 ENRICH 命令添加的新 env 列。 例如,要计算每个环境的中位持续时间:
FROM sample_data
| KEEP @timestamp, client.ip, event.duration
| EVAL client.ip = TO_STRING(client.ip)
| ENRICH clientip_policy ON client.ip WITH env
| STATS median_duration = MEDIAN(event.duration) BY env有关使用 ES|QL 进行数据丰富的更多信息,请参阅 “ES|QL 中的数据丰富”。
处理数据
你的数据可能包含非结构化字符串,你希望将其结构化以便更轻松地分析数据。 例如,示例数据包含如下日志消息:
"Connected to 10.1.0.3"通过从这些消息中提取 IP 地址,你可以确定哪个 IP 接受了最多的客户端连接。
要在查询时构建非结构化字符串,你可以使用 ES|QL DISSECT 和 GROK 命令。 DISSECT 的工作原理是使用基于分隔符的模式分解字符串。 GROK 的工作原理类似,但使用正则表达式。 这使得 GROK 更强大,但通常也更慢。
在这种情况下,不需要正则表达式,因为 message 很简单:“Connected to ”,后跟服务器 IP。 要匹配此字符串,你可以使用以下 DISSECT 命令:
FROM sample_data
| DISSECT message "Connected to %{server.ip}"这会将 server.ip 列添加到具有与此模式匹配的消息的那些行。 对于其他行,server.ip 的值为空。
你可以在后续命令中使用 DISSECT 命令添加的新 server.ip 列。 例如,要确定每个服务器已接受多少个连接:
FROM sample_data
| WHERE STARTS_WITH(message, "Connected to")
| DISSECT message "Connected to %{server.ip}"
| STATS COUNT(*) BY server.ip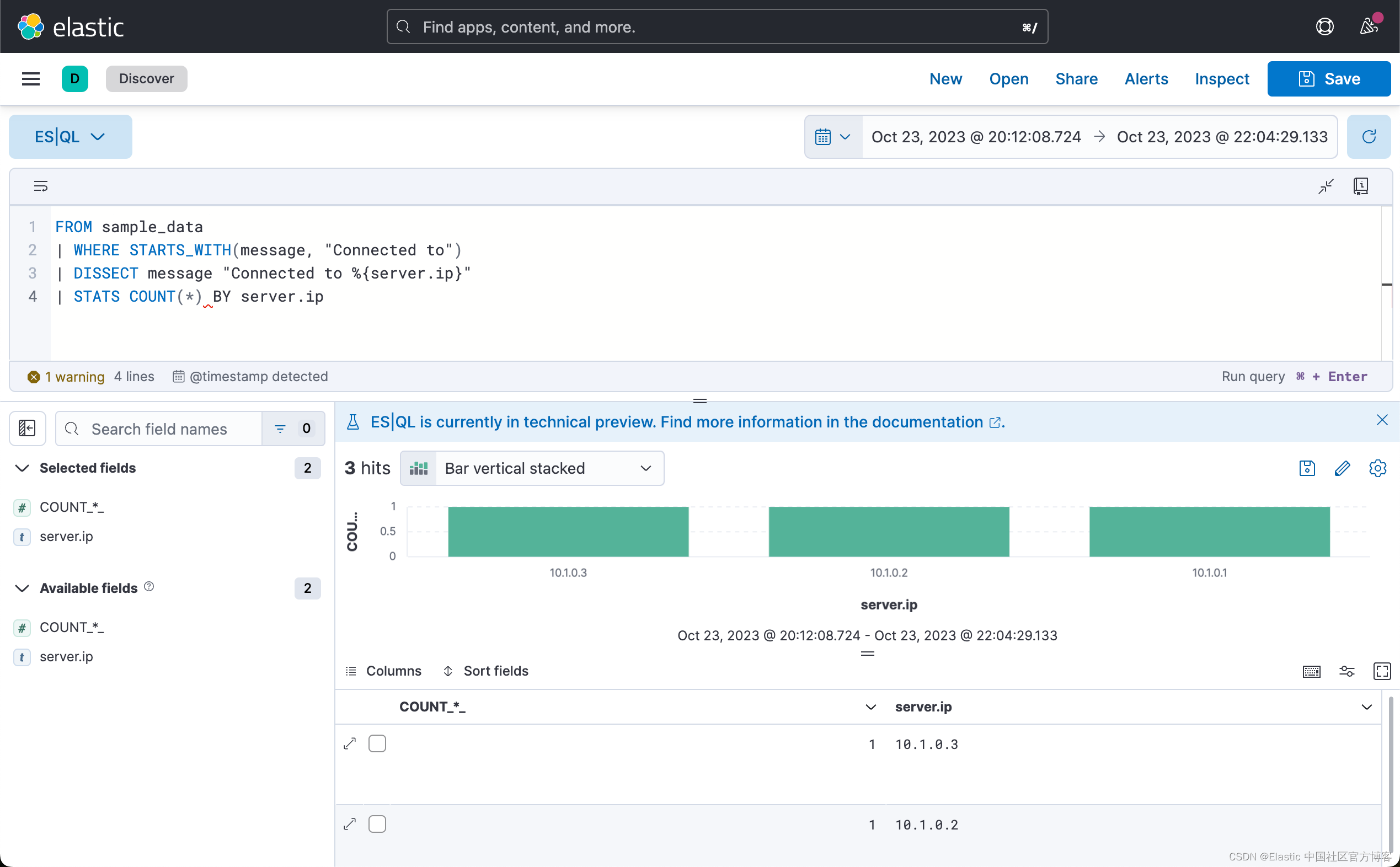
有关使用 ES|QL 进行数据处理的更多信息,请参阅使用 DISSECT 和 GROK 进行数据处理。