转载:C++设计实现日志系统 - 知乎 (zhihu.com)
日志系统几乎是每一个实际的软件项目从开发、测试到交付,再到后期的维护过程中极为重要的 查看软件代码运行流程、 还原错误现场、 记录运行错误位置及上下文等的重要依据。一个高性能的日志系统,能够准确记录重要的变量信息,同时又没有冗余的打印导致日志文件记录无效的数据。本文Jungle将用C++设计实现一个日志系统。
1.为什么需要日志
为什么需要日志?其实在引言中已经提到了,实际的软件项目的几乎每个过程,都离不开日志。初学代码时,Jungle的第一行代码是实现打印“hello world”,打印到控制台。在后来的学习中,Jungle又学会了设断点调试代码,在适当的地方通过断点来观察变量的值。但在实际的软件项目中,试想一下,通过输出到控制台或者通过设断点来调试代码,可能吗?

- 客户现场,会让你现场打印到控制台上调试吗?
- 报了error的软件项目,你能够明确知道软件crash的位置吗?
- 你能保证设断点可以还原error时候的现场吗?
- 概率性的error事件,设断点还奏效吗?
- 如果是时效性的代码(比如USB连接) ,设断点调试还合理吗?
- ……
日志,可以记录每一时刻软件的运行情况,记录error或者crash时的信息(时间、关键变量的值、出错位置、线程等);另一方面,对于概率性error事件,可以在重复测试时通过日志来查询错误复现时候的情况。简言之,日志是跟踪和回忆某个时刻或者时间段内的程序行为进而定位问题的一种重要手段。
2.日志系统设计
软件运行过程中,需要记录的有什么呢?前述已经提到,关键变量的值、运行的位置(哪个文件、哪个函数、哪一行)、时间、线程号、进程号。本文Jungle采用C++设计了LOG类,介绍LOG类的设计之前,需要提及的是log的级别和log位置。
2.1.1.log级别
Log级别是什么意思呢?在开发阶段,Jungle可能想尽可能详细地跟踪代码运行过程,所以可以打印尽可能多的信息到日志文件中;测试过程中,测试部可能不需要这么详细的信息,所以这时候有的信息可能不必输出到Log文件;产品交付客户使用时,为了软件运行更快、客户体验更好,这时候就只需打印关键信息到日志文件了,因为过多的写文件会耗费大量时间,影响软件运行速度。所以Jungle为LOG类定义了如下级别:
enum LOGLEVEL
{
LOG_LEVEL_NONE,
LOG_LEVEL_ERROR, // error
LOG_LEVEL_WARNING, // warning
LOG_LEVEL_DEBUG, // debug
LOG_LEVEL_INFO, // info
};在软件设计中,可以通过某些方法或者预留一些开关来设置Log级别,方便在开发、调试、测试和客户现场灵活地调整日志级别,以获取到有用的日志信息。
2.1.2.log输出位置
Log文件可以输出到控制台(其实也是不错的方法),也可以输出到指定路径下的某个文件里,也可能有别的需求。比如,开发或调试时,简单的信息直接就打印到软件某个界面上;测试或者交付客户时,最好将日志保存到文件里,这样可以保存尽可能多的信息。因此,Jungle进行了如下设计:
enum LOGTARGET
{
LOG_TARGET_NONE = 0x00,
LOG_TARGET_CONSOLE = 0x01,
LOG_TARGET_FILE = 0x10
};2.1.3.log的作用域
一个软件系统,要在哪儿输出日志呢?Everywhere!只要是你想打印日志的地方,任何一个函数、任何一个文件,都应该而且必须可以打印。也就是说这个log类的对象(不妨叫做日志记录器),日志记录器必须是全局的!
光是全局的就够了吗?你这个文件里有一个全局的日志记录器,输出日志到file.log文件里;另一个文件里也有一个日志记录器,也输出到file.log文件里……多个日志记录器同时往一个文件里写日志,这显然不合理。所以还必须保证日志记录器全局且唯一!
怎么保证日志记录器唯一呢?即Log类在具体的软件系统中有且仅有一个实例化对象。答案是采用单例模式!(设计模式(九)——单例模式)
2.2.日志类的设计
综上所述,Jungle设计的日志类LOG如下:
class LOG
{
public:
// 初始化
void init(LOGLEVEL loglevel, LOGTARGET logtarget);
//
void uninit();
// file
int createFile();
static LOG* getInstance();
// Log级别
LOGLEVEL getLogLevel();
void setLogLevel(LOGLEVEL loglevel);
// Log输出位置
LOGTARGET getLogTarget();
void setLogTarget(LOGTARGET logtarget);
// 打log
static int writeLog(
LOGLEVEL loglevel, // Log级别
unsigned char* fileName, // 函数所在文件名
unsigned char* function, // 函数名
int lineNumber, // 行号
char* format, // 格式化
...); // 变量
// 输出log
static void outputToTarget();
private:
LOG();
~LOG();
static LOG* Log;
// 互斥锁
static mutex log_mutex;
// 存储log的buffer
static string logBuffer;
// Log级别
LOGLEVEL logLevel;
// Log输出位置
LOGTARGET logTarget;
// Handle
static HANDLE mFileHandle;
};其中,互斥锁log_mutex是用于在多线程环境下保证只创建一个LOG类的实例 (设计模式(九)——单例模式);mFileHandle是log文件的句柄。
2.3.日志类的实现
2.3.1.初始化
LOG* LOG::Log = NULL;
string LOG::logBuffer = "";
HANDLE LOG::mFileHandle = INVALID_HANDLE_VALUE;
mutex LOG::log_mutex;
LOG::LOG()
{
// 初始化
init(LOG_LEVEL_NONE, LOG_TARGET_FILE);
}
void LOG::init(LOGLEVEL loglevel, LOGTARGET logtarget)
{
setLogLevel(loglevel);
setLogTarget(logtarget);
createFile();
}
void LOG::uninit()
{
if (INVALID_HANDLE_VALUE != mFileHandle)
{
CloseHandle(mFileHandle);
}
}
LOG* LOG::getInstance()
{
if (NULL == Log)
{
log_mutex.lock();
if (NULL == Log)
{
Log = new LOG();
}
log_mutex.unlock();
}
return Log;
}
LOGLEVEL LOG::getLogLevel()
{
return this->logLevel;
}
void LOG::setLogLevel(LOGLEVEL iLogLevel)
{
this->logLevel = iLogLevel;
}
LOGTARGET LOG::getLogTarget()
{
return this->logTarget;
}
void LOG::setLogTarget(LOGTARGET iLogTarget)
{
this->logTarget = iLogTarget;
}初始化工作设置了日志的级别和输出位置(代码中提供了日志级别和输出位置的setter、getter方法)。函数createFile()是创建日志文件位置,并获取日志文件的句柄mFileHandle。代码如下:
int LOG::createFile()
{
TCHAR fileDirectory[256];
GetCurrentDirectory(256, fileDirectory);
// 创建log文件的路径
TCHAR logFileDirectory[256];
_stprintf_s(logFileDirectory, _T("%s\\Test\\"), fileDirectory);// 使用_stprintf_s需要包含头文件<TCHAR.H>
// 文件夹不存在则创建文件夹
if (_taccess(logFileDirectory, 0) == -1)
{
_tmkdir(logFileDirectory);
}
TCHAR cTmpPath[MAX_PATH] = { 0 };
TCHAR* lpPos = NULL;
TCHAR cTmp = _T('\0');
WCHAR pszLogFileName[256];
// wcscat:连接字符串
wcscat(logFileDirectory, _T("test.log"));
_stprintf_s(pszLogFileName, _T("%s"), logFileDirectory);
mFileHandle = CreateFile(
pszLogFileName,
GENERIC_READ | GENERIC_WRITE,
FILE_SHARE_READ,
NULL,
OPEN_ALWAYS,
FILE_ATTRIBUTE_NORMAL,
NULL);
if (INVALID_HANDLE_VALUE == mFileHandle)
{
return -1;
}
return 0;
}其中,需要介绍的是下述函数:
- GetCurrentDirectory:在一个缓冲区中装载当前目录
- _stprintf_s:将若干个参数按照format格式存到buffer中
- _taccess:判断文件是否存在,返回值0表示该文件存在,返回-1表示文件不存在或者该模式下没有访问权限
- _tmkdir:创建一个目录
2.3.2.写日志
以下是writeLog()方法的实现:
int LOG::writeLog(
LOGLEVEL loglevel, // Log级别
unsigned char* fileName, // 函数所在文件名
unsigned char* function, // 函数名
int lineNumber, // 行号
char* format, // 格式化
...)
{
int ret = 0;
// 获取日期和时间
char timeBuffer[100];
ret = getSystemTime(timeBuffer);
logBuffer += string(timeBuffer);
// LOG级别
char* logLevel;
if (loglevel == LOG_LEVEL_DEBUG){
logLevel = "DEBUG";
}
else if (loglevel == LOG_LEVEL_INFO){
logLevel = "INFO";
}
else if (loglevel == LOG_LEVEL_WARNING){
logLevel = "WARNING";
}
else if (loglevel == LOG_LEVEL_ERROR){
logLevel = "ERROR";
}
// [进程号][线程号][Log级别][文件名][函数名:行号]
char locInfo[100];
char* format2 = "[PID:%4d][TID:%4d][%s][%-s][%s:%4d]";
ret = printfToBuffer(locInfo, 100, format2,
GetCurrentProcessId(),
GetCurrentThreadId(),
logLevel,
fileName,
function,
lineNumber);
logBuffer += string(locInfo);
// 日志正文
char logInfo2[256];
va_list ap;
va_start(ap, format);
ret = vsnprintf(logInfo2, 256, format, ap);
va_end(ap);
logBuffer += string(logInfo2);
logBuffer += string("\n");
outputToTarget();
return 0;
}2.3.3.输出日志
void LOG::outputToTarget()
{
if (LOG::getInstance()->getLogTarget() & LOG_TARGET_FILE)
{
SetFilePointer(mFileHandle, 0, NULL, FILE_END);
DWORD dwBytesWritten = 0;
WriteFile(mFileHandle, logBuffer.c_str(), logBuffer.length(), &dwBytesWritten, NULL);
FlushFileBuffers(mFileHandle);
}
if (LOG::getInstance()->getLogTarget() & LOG_TARGET_CONSOLE)
{
printf("%s", logBuffer.c_str());
}
// 清除buffer
logBuffer.clear();
}- SetFilePointer:将文件指针移动到文件指定的位置
- FlushFileBuffers:把写文件缓冲区的数据强制写入磁盘
为了使用方便,可以定义一些宏来简化函数的使用,本文不再赘述。
3.测试
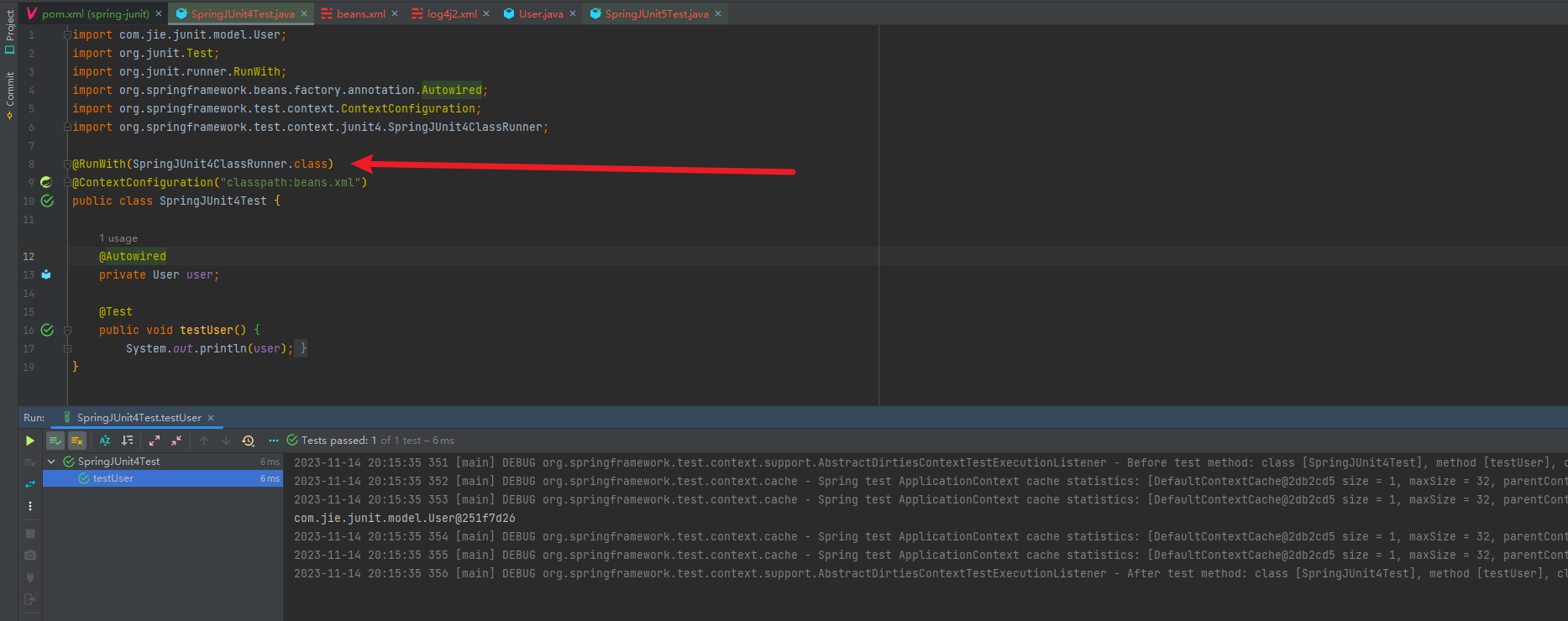
Jungle将上述设计实现的日志系统应用到了之前写的一些小程序里,比如在之前的“欲戴王冠,必承其重”——深度解析职责链模式的代码。如何添加呢?就是将两个文件(头文件和源文件)加入工程,包含头文件,再在需要打log的地方加上Jungle在日志类里定义的宏即可。下列是示例log:

因为程序比较简单,代码量很小,所以只有一个线程(log中TID都是一样的)。但上述测试结果验证了Jungle设计的日志系统是可行的。
4.多线程环境
4.1.多线程环境测试
接下来Jungle设计一个简单的多线程环境,测试一下上述日志系统,测试代码如下:
#define THREAD_NUM 5
// 全局资源变量
int g_num = 0;
unsigned int __stdcall func(void *pPM)
{
LOG_INFO("enter");
Sleep(50);
g_num++;
LOG_INFO("g_num = %d", g_num);
LOG_INFO("exit");
return 0;
}
int main()
{
LOG *logger = LOG::getInstance();
HANDLE handle[THREAD_NUM];
//线程编号
int threadNum = 0;
while (threadNum < THREAD_NUM)
{
handle[threadNum] = (HANDLE)_beginthreadex(NULL, 0, func, NULL, 0, NULL);
//等子线程接收到参数时主线程可能改变了这个i的值
threadNum++;
}
//保证子线程已全部运行结束
WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
return 0;
}上述代码中,Jungle一共开启了5个线程,理论上打印的日志文件里,TID应该出现5个不同的数值。每个线程里打印全局变量(即全局共享资源)的值。下面是输出的日志,一共运行了两次(第5、6行隔开):

问题来啦!
首先,在第一次运行输出的日志里,出现了乱码!(第1行和第4行),而且看起来该输出log的地方没有完全输出(真的吗?)
其次,在第二次运行输出的日志里,一行log里好像打印了两次日志(第8行)!
问题出在哪里呢?
为什么会出现乱码?仔细看第8行log,其实打印的都是同一个时刻、同一个位置,都是在调用writeLog函数(宏LOG_INFO即是调用writeLog函数)时出现的问题,也就是说在这个时刻,两个线程都跑到函数writeLog里写log,导致logBuffer缓冲区里存放了两次信息。只不过第8行运气较好,每次的编码都保存完整。而第1行和第4行就没这么走运了!(logBuffer里已经完全乱了!)所以根本问题是,多个线程在同一个时刻访问了同一个资源!所以针对多线程环境,我们需要做到共享资源的互斥!
4.2.线程安全的日志系统
在单例模式的设计实现里已经提到了线程安全,Jungle用互斥锁达到了互斥的目的。本文也可以使用互斥锁(并且在日志对象实例的单例模式中已经使用),但在这里Jungle想用另一种方法:临界区。
在Log类成员里声明一个CRITICAL_SECTION对象criticalSection,初始化时:
InitializeCriticalSection(&criticalSection);当然,最好在释放资源时加上下述代码:
DeleteCriticalSection(&criticalSection);而在进入writeLog时和离开writeLog时加上下述代码:
int LOG::writeLog(...)
{
int ret = 0;
EnterCriticalSection(&criticalSection);
// do something
LeaveCriticalSection(&criticalSection);
return 0;
}需要提及的是,最好是在LeaveCriticalSection之后再DeleteCriticalSection。
接下来再在多线程环境里测试,Jungle测试了几次,但为了缩短篇幅,只展示一次的结果:

可以看到,日志完整记录了每个线程的运行过程(线程号TID不同)。
5.注意事项
尽管上述已经基本实现了日志系统,但仍有很大的改进空间,在调试代码和查阅资料的过程中,Jungle发现需要注意以下几个问题:
(1)字符编码问题:宽字符、ANSI编码等多种不同编码的兼容;
(2)Visio Studio版本的差异:Jungle本想将日志系统应用到之前设计的一个机器人仿真控制器里,但遗憾的是编译不通过,因为那个代码是用Visio Studio 2008写的,而Mutex是C++2011标准的内容,需要用支持该新标准的编译器,比如VS2012及以上版本。(当然了,可以用临界区等其他方法实现互斥,这里Jungle只是提出这个需要注意的问题);
(3)关于宏_CRT_SECURE_NO_WARNINGS:是的,需要在预处理器里加上这个宏或者代码里显示声明这个宏,否则编译不通过,如下图。原因是代码中使用的wcscat等函数不安全,可能会造成内存泄露等。解决方法除了前述提到的声明宏以外,还可以使用更安全的函数
源码地址:
日志系统几乎是每一个实际的软件项目从开发、测试到交付,再到后期的维护过程中极为重要的 查看软件代码运行流程、 还原错误现场、 记录运行错误位置及上下文等的重要依据。一个高性能的日志系统,能够准确记录重要的变量信息,同时又没有冗余的打印导致日志文件记录无效的数据。本文Jungle将用C++设计实现一个日志系统。
1.为什么需要日志
为什么需要日志?其实在引言中已经提到了,实际的软件项目的几乎每个过程,都离不开日志。初学代码时,Jungle的第一行代码是实现打印“hello world”,打印到控制台。在后来的学习中,Jungle又学会了设断点调试代码,在适当的地方通过断点来观察变量的值。但在实际的软件项目中,试想一下,通过输出到控制台或者通过设断点来调试代码,可能吗?
- 客户现场,会让你现场打印到控制台上调试吗?
- 报了error的软件项目,你能够明确知道软件crash的位置吗?
- 你能保证设断点可以还原error时候的现场吗?
- 概率性的error事件,设断点还奏效吗?
- 如果是时效性的代码(比如USB连接) ,设断点调试还合理吗?
- ……
日志,可以记录每一时刻软件的运行情况,记录error或者crash时的信息(时间、关键变量的值、出错位置、线程等);另一方面,对于概率性error事件,可以在重复测试时通过日志来查询错误复现时候的情况。简言之,日志是跟踪和回忆某个时刻或者时间段内的程序行为进而定位问题的一种重要手段。
2.日志系统设计
软件运行过程中,需要记录的有什么呢?前述已经提到,关键变量的值、运行的位置(哪个文件、哪个函数、哪一行)、时间、线程号、进程号。本文Jungle采用C++设计了LOG类,介绍LOG类的设计之前,需要提及的是log的级别和log位置。
2.1.1.log级别
Log级别是什么意思呢?在开发阶段,Jungle可能想尽可能详细地跟踪代码运行过程,所以可以打印尽可能多的信息到日志文件中;测试过程中,测试部可能不需要这么详细的信息,所以这时候有的信息可能不必输出到Log文件;产品交付客户使用时,为了软件运行更快、客户体验更好,这时候就只需打印关键信息到日志文件了,因为过多的写文件会耗费大量时间,影响软件运行速度。所以Jungle为LOG类定义了如下级别:
enum LOGLEVEL
{
LOG_LEVEL_NONE,
LOG_LEVEL_ERROR, // error
LOG_LEVEL_WARNING, // warning
LOG_LEVEL_DEBUG, // debug
LOG_LEVEL_INFO, // info
};在软件设计中,可以通过某些方法或者预留一些开关来设置Log级别,方便在开发、调试、测试和客户现场灵活地调整日志级别,以获取到有用的日志信息。
2.1.2.log输出位置
Log文件可以输出到控制台(其实也是不错的方法),也可以输出到指定路径下的某个文件里,也可能有别的需求。比如,开发或调试时,简单的信息直接就打印到软件某个界面上;测试或者交付客户时,最好将日志保存到文件里,这样可以保存尽可能多的信息。因此,Jungle进行了如下设计:
enum LOGTARGET
{
LOG_TARGET_NONE = 0x00,
LOG_TARGET_CONSOLE = 0x01,
LOG_TARGET_FILE = 0x10
};2.1.3.log的作用域
一个软件系统,要在哪儿输出日志呢?Everywhere!只要是你想打印日志的地方,任何一个函数、任何一个文件,都应该而且必须可以打印。也就是说这个log类的对象(不妨叫做日志记录器),日志记录器必须是全局的!
光是全局的就够了吗?你这个文件里有一个全局的日志记录器,输出日志到file.log文件里;另一个文件里也有一个日志记录器,也输出到file.log文件里……多个日志记录器同时往一个文件里写日志,这显然不合理。所以还必须保证日志记录器全局且唯一!
怎么保证日志记录器唯一呢?即Log类在具体的软件系统中有且仅有一个实例化对象。答案是采用单例模式!(设计模式(九)——单例模式)
2.2.日志类的设计
综上所述,Jungle设计的日志类LOG如下:
class LOG
{
public:
// 初始化
void init(LOGLEVEL loglevel, LOGTARGET logtarget);
//
void uninit();
// file
int createFile();
static LOG* getInstance();
// Log级别
LOGLEVEL getLogLevel();
void setLogLevel(LOGLEVEL loglevel);
// Log输出位置
LOGTARGET getLogTarget();
void setLogTarget(LOGTARGET logtarget);
// 打log
static int writeLog(
LOGLEVEL loglevel, // Log级别
unsigned char* fileName, // 函数所在文件名
unsigned char* function, // 函数名
int lineNumber, // 行号
char* format, // 格式化
...); // 变量
// 输出log
static void outputToTarget();
private:
LOG();
~LOG();
static LOG* Log;
// 互斥锁
static mutex log_mutex;
// 存储log的buffer
static string logBuffer;
// Log级别
LOGLEVEL logLevel;
// Log输出位置
LOGTARGET logTarget;
// Handle
static HANDLE mFileHandle;
};其中,互斥锁log_mutex是用于在多线程环境下保证只创建一个LOG类的实例 (设计模式(九)——单例模式);mFileHandle是log文件的句柄。
2.3.日志类的实现
2.3.1.初始化
LOG* LOG::Log = NULL;
string LOG::logBuffer = "";
HANDLE LOG::mFileHandle = INVALID_HANDLE_VALUE;
mutex LOG::log_mutex;
LOG::LOG()
{
// 初始化
init(LOG_LEVEL_NONE, LOG_TARGET_FILE);
}
void LOG::init(LOGLEVEL loglevel, LOGTARGET logtarget)
{
setLogLevel(loglevel);
setLogTarget(logtarget);
createFile();
}
void LOG::uninit()
{
if (INVALID_HANDLE_VALUE != mFileHandle)
{
CloseHandle(mFileHandle);
}
}
LOG* LOG::getInstance()
{
if (NULL == Log)
{
log_mutex.lock();
if (NULL == Log)
{
Log = new LOG();
}
log_mutex.unlock();
}
return Log;
}
LOGLEVEL LOG::getLogLevel()
{
return this->logLevel;
}
void LOG::setLogLevel(LOGLEVEL iLogLevel)
{
this->logLevel = iLogLevel;
}
LOGTARGET LOG::getLogTarget()
{
return this->logTarget;
}
void LOG::setLogTarget(LOGTARGET iLogTarget)
{
this->logTarget = iLogTarget;
}初始化工作设置了日志的级别和输出位置(代码中提供了日志级别和输出位置的setter、getter方法)。函数createFile()是创建日志文件位置,并获取日志文件的句柄mFileHandle。代码如下:
int LOG::createFile()
{
TCHAR fileDirectory[256];
GetCurrentDirectory(256, fileDirectory);
// 创建log文件的路径
TCHAR logFileDirectory[256];
_stprintf_s(logFileDirectory, _T("%s\\Test\\"), fileDirectory);// 使用_stprintf_s需要包含头文件<TCHAR.H>
// 文件夹不存在则创建文件夹
if (_taccess(logFileDirectory, 0) == -1)
{
_tmkdir(logFileDirectory);
}
TCHAR cTmpPath[MAX_PATH] = { 0 };
TCHAR* lpPos = NULL;
TCHAR cTmp = _T('\0');
WCHAR pszLogFileName[256];
// wcscat:连接字符串
wcscat(logFileDirectory, _T("test.log"));
_stprintf_s(pszLogFileName, _T("%s"), logFileDirectory);
mFileHandle = CreateFile(
pszLogFileName,
GENERIC_READ | GENERIC_WRITE,
FILE_SHARE_READ,
NULL,
OPEN_ALWAYS,
FILE_ATTRIBUTE_NORMAL,
NULL);
if (INVALID_HANDLE_VALUE == mFileHandle)
{
return -1;
}
return 0;
}其中,需要介绍的是下述函数:
- GetCurrentDirectory:在一个缓冲区中装载当前目录
- _stprintf_s:将若干个参数按照format格式存到buffer中
- _taccess:判断文件是否存在,返回值0表示该文件存在,返回-1表示文件不存在或者该模式下没有访问权限
- _tmkdir:创建一个目录
2.3.2.写日志
以下是writeLog()方法的实现:
int LOG::writeLog(
LOGLEVEL loglevel, // Log级别
unsigned char* fileName, // 函数所在文件名
unsigned char* function, // 函数名
int lineNumber, // 行号
char* format, // 格式化
...)
{
int ret = 0;
// 获取日期和时间
char timeBuffer[100];
ret = getSystemTime(timeBuffer);
logBuffer += string(timeBuffer);
// LOG级别
char* logLevel;
if (loglevel == LOG_LEVEL_DEBUG){
logLevel = "DEBUG";
}
else if (loglevel == LOG_LEVEL_INFO){
logLevel = "INFO";
}
else if (loglevel == LOG_LEVEL_WARNING){
logLevel = "WARNING";
}
else if (loglevel == LOG_LEVEL_ERROR){
logLevel = "ERROR";
}
// [进程号][线程号][Log级别][文件名][函数名:行号]
char locInfo[100];
char* format2 = "[PID:%4d][TID:%4d][%s][%-s][%s:%4d]";
ret = printfToBuffer(locInfo, 100, format2,
GetCurrentProcessId(),
GetCurrentThreadId(),
logLevel,
fileName,
function,
lineNumber);
logBuffer += string(locInfo);
// 日志正文
char logInfo2[256];
va_list ap;
va_start(ap, format);
ret = vsnprintf(logInfo2, 256, format, ap);
va_end(ap);
logBuffer += string(logInfo2);
logBuffer += string("\n");
outputToTarget();
return 0;
}2.3.3.输出日志
void LOG::outputToTarget()
{
if (LOG::getInstance()->getLogTarget() & LOG_TARGET_FILE)
{
SetFilePointer(mFileHandle, 0, NULL, FILE_END);
DWORD dwBytesWritten = 0;
WriteFile(mFileHandle, logBuffer.c_str(), logBuffer.length(), &dwBytesWritten, NULL);
FlushFileBuffers(mFileHandle);
}
if (LOG::getInstance()->getLogTarget() & LOG_TARGET_CONSOLE)
{
printf("%s", logBuffer.c_str());
}
// 清除buffer
logBuffer.clear();
}- SetFilePointer:将文件指针移动到文件指定的位置
- FlushFileBuffers:把写文件缓冲区的数据强制写入磁盘
为了使用方便,可以定义一些宏来简化函数的使用,本文不再赘述。
3.测试
Jungle将上述设计实现的日志系统应用到了之前写的一些小程序里,比如在之前的“欲戴王冠,必承其重”——深度解析职责链模式的代码。如何添加呢?就是将两个文件(头文件和源文件)加入工程,包含头文件,再在需要打log的地方加上Jungle在日志类里定义的宏即可。下列是示例log:
因为程序比较简单,代码量很小,所以只有一个线程(log中TID都是一样的)。但上述测试结果验证了Jungle设计的日志系统是可行的。
4.多线程环境
4.1.多线程环境测试
接下来Jungle设计一个简单的多线程环境,测试一下上述日志系统,测试代码如下:
#define THREAD_NUM 5
// 全局资源变量
int g_num = 0;
unsigned int __stdcall func(void *pPM)
{
LOG_INFO("enter");
Sleep(50);
g_num++;
LOG_INFO("g_num = %d", g_num);
LOG_INFO("exit");
return 0;
}
int main()
{
LOG *logger = LOG::getInstance();
HANDLE handle[THREAD_NUM];
//线程编号
int threadNum = 0;
while (threadNum < THREAD_NUM)
{
handle[threadNum] = (HANDLE)_beginthreadex(NULL, 0, func, NULL, 0, NULL);
//等子线程接收到参数时主线程可能改变了这个i的值
threadNum++;
}
//保证子线程已全部运行结束
WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
return 0;
}上述代码中,Jungle一共开启了5个线程,理论上打印的日志文件里,TID应该出现5个不同的数值。每个线程里打印全局变量(即全局共享资源)的值。下面是输出的日志,一共运行了两次(第5、6行隔开):
问题来啦!
首先,在第一次运行输出的日志里,出现了乱码!(第1行和第4行),而且看起来该输出log的地方没有完全输出(真的吗?)
其次,在第二次运行输出的日志里,一行log里好像打印了两次日志(第8行)!
问题出在哪里呢?
为什么会出现乱码?仔细看第8行log,其实打印的都是同一个时刻、同一个位置,都是在调用writeLog函数(宏LOG_INFO即是调用writeLog函数)时出现的问题,也就是说在这个时刻,两个线程都跑到函数writeLog里写log,导致logBuffer缓冲区里存放了两次信息。只不过第8行运气较好,每次的编码都保存完整。而第1行和第4行就没这么走运了!(logBuffer里已经完全乱了!)所以根本问题是,多个线程在同一个时刻访问了同一个资源!所以针对多线程环境,我们需要做到共享资源的互斥!
4.2.线程安全的日志系统
在单例模式的设计实现里已经提到了线程安全,Jungle用互斥锁达到了互斥的目的。本文也可以使用互斥锁(并且在日志对象实例的单例模式中已经使用),但在这里Jungle想用另一种方法:临界区。
在Log类成员里声明一个CRITICAL_SECTION对象criticalSection,初始化时:
InitializeCriticalSection(&criticalSection);当然,最好在释放资源时加上下述代码:
DeleteCriticalSection(&criticalSection);而在进入writeLog时和离开writeLog时加上下述代码:
int LOG::writeLog(...)
{
int ret = 0;
EnterCriticalSection(&criticalSection);
// do something
LeaveCriticalSection(&criticalSection);
return 0;
}需要提及的是,最好是在LeaveCriticalSection之后再DeleteCriticalSection。
接下来再在多线程环境里测试,Jungle测试了几次,但为了缩短篇幅,只展示一次的结果:
可以看到,日志完整记录了每个线程的运行过程(线程号TID不同)。
5.注意事项
尽管上述已经基本实现了日志系统,但仍有很大的改进空间,在调试代码和查阅资料的过程中,Jungle发现需要注意以下几个问题:
(1)字符编码问题:宽字符、ANSI编码等多种不同编码的兼容;
(2)Visio Studio版本的差异:Jungle本想将日志系统应用到之前设计的一个机器人仿真控制器里,但遗憾的是编译不通过,因为那个代码是用Visio Studio 2008写的,而Mutex是C++2011标准的内容,需要用支持该新标准的编译器,比如VS2012及以上版本。(当然了,可以用临界区等其他方法实现互斥,这里Jungle只是提出这个需要注意的问题);
(3)关于宏_CRT_SECURE_NO_WARNINGS:是的,需要在预处理器里加上这个宏或者代码里显示声明这个宏,否则编译不通过,如下图。原因是代码中使用的wcscat等函数不安全,可能会造成内存泄露等。解决方法除了前述提到的声明宏以外,还可以使用更安全的函数
源码地址:
https://github.com/FengJungle/Loggithub.com/FengJungle/Log
![[Linux] DHCP网络](https://img-blog.csdnimg.cn/73d05537fc194b188963ec926ada891a.png)


![[文件读取]webgrind 文件读取 (CVE-2018-12909)](https://img-blog.csdnimg.cn/13cf9c30dda1464e9d75f4b7f02afbee.png)