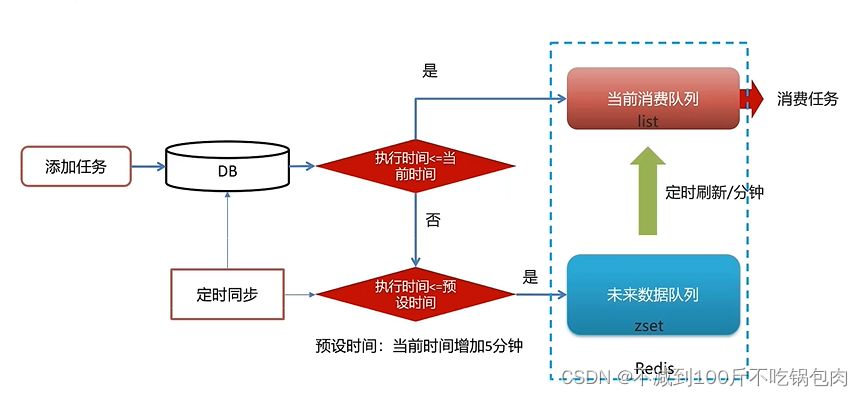
一.背景&目标
1.1 常见的压测场景
-
电商大促:一众各大厂的促销活动场景,如:淘宝率先推出的天猫双11,而后京东拉出的京东 618 .还是后续陆陆续续的一些年货节, 3.8 女神节等等.都属于一些常规的电商大促
-
票务抢购:常见的如承载咱们 80,90 青春回忆的 Jay 的演唱会,还有普罗大众都参与的 12306 全民狂欢抢票.
-
单品秒杀:往年被小米抢购秒杀带起来的红米抢购,还有最近这几年各大电商准点的茅台抢购;过去这三年中抢过的口罩,酒精等.这都属于秒杀的范畴.
-
toB 私有化服务:这个场景相对特殊.但是随着咱们 toC 的业务饱和,很多软件服务商也开始做 toB 的业务. toB 的业务特点其中有一个相对比较特别的就是存在私有化部署的诉求.主要的一些目的也是基于一些数据安全,成本这些因素来考虑的.
如上是在工作过程接触到的一些场景,书不尽言.下面就针对这些场景做一个压测的的梳理.
1.2 目标
稳是第一位的,不久前某猫厂云事故,以及刚出现的某雀文档事故,历历在目.从大了说,整个产品的公信力被质疑将是后续用户是否持续购买的最大障碍;往小了说咱们这些小兵严重就是直接被离职,直接决定房贷,车贷下个月能不能交上的事情.所以除了稳,我们没别的.

那其实从实际场景来说,除了稳定性是我们要求的第一位.还有一个整体的成本也是常用来被考虑的.所以压测的目标就是在稳定性和成本中间尽可能做一个权衡.
如上在这些场景中前三的这种场景优先都是以稳定性是第一位,特别是电商大促,涉及的流程和各模块繁杂.在具体实施的过程中尽可能的去保证稳定性,资源优先度可以先往后放一放.
其中稳定性的部分.我理解有两个部分.首先是面对峰值流量的时候的稳定性,一个是整个系统全链路的系统业务流程的稳定性.如:整体的交易的黄金流程.保证从用户的商详,购物车,结算,订单,支付都能够完整的走下来,这是业务流程的稳定性.
最后一个私有化的场景相对比较特殊,更多的是一个私域的流量场景,流量相比公域要少的多.这时候尽可能要去压榨机器的性能,在尽可能少的资源成本下去提供更多的流量支持.因为成本就直接面临了产品的竞争力.
二.流程
将流程划分为三个阶段压测前的一些前置准备;压测进行过程中的主要是测试和研发的具体的配合操作,以及监控观测;压测后的一些结果沉淀以及复盘,优化,复压.
2.1 压测前
2.1.1 流量预估
这个是压测前第一项工作也是非常重要的一项工作,直接决定了本次压测的一个目标,而目标的准确制定就决定了本次的压测的最终目的—保证大促的稳定的直接成功与否.所以这里的流量预估显得非常重要.一般来说的话常用的有这两种形式.
-
流量同比规则粗估
如: 2012年6月1日 42w(qps) , 2013年6月1日 24w(qps) .同比下滑 42% .在得到 2012年11月1日 49w(qps) .以此推算 2013年11月1日 49w*0.57=28w .这是一个大概的量,如果压测的话按照这个量上浮 20% .压测按照 28*1.2= 34(w).
-
GMV 原则预估
从业务侧拿到2013年11月1日 11.11 的 dau 的预估的量. 比如: dau 相比 618 的增长 1.2 倍.从监控里得到 618 的查车的量 20w ,占比 40% .得到整体流量为 50w. 得到 11.11 整体的量 50w*1.2 得到整体双 11 的量为 60w . 如果压测的话按照这个量上浮 ** 20%** .压测按照 60*1.2=72(w)
.
2.1.2 限流对齐以及配置
限流毋庸置疑都是需要配置的,防止系统在承载能力之外的流量冲击下直接崩溃,造成xue’peng
2.1.2.1 限流配置原则
在整个流量预估完成之后,各模块基本上可以基于所域系统服务在流量预估的数值来进行设置.来保证峰值以上的一些突发情况也能够在系统承受范围.
2.1.2.2 限流的配置
- 单机维度
一般单机房维度设置限流有两个方面. cpu 维度和 qps 维度.
- 机房维度
每个机房的压测流量不一样,如张北,中云信.需要根据机房来进行限流配置,因为一般场景下优先保障同机房调用.
2.1.2.3 机器配置
- 单机核心配置
机器配置.16c32g 50G SAS硬盘. SAS [既有的机械硬盘升级]
export maxParameterCount="10000"
export acceptCount="1000"
export maxSpareThreads="750"
export maxThreads="1000"
export minSpareThreads="50"
export URIEncoding="UTF-8"
export JAVA_OPTS=" -Xms16384m -Xmx16384m -XX:MaxMetaspaceSize=512m -XX:MetaspaceSize=512m -XX:ConcGCThreads=4 -XX:ParallelGCThreads=16 -Djava.library.path=/usr/local/lib -server -Xmn4096m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=75 -XX:+CMSScavengeBeforeRemark "
- 集群机房资源配比及配置
2.1.2.4 监控配置
监控配置主要分两个方面.
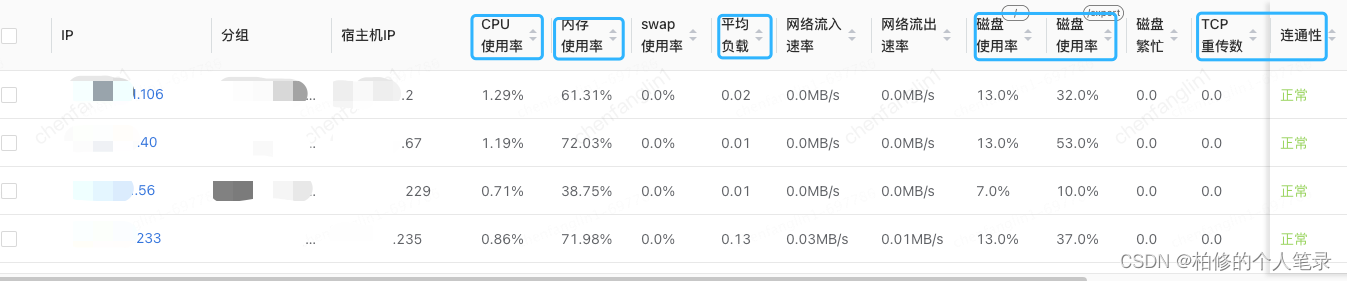
本身系统的机器的物理监控.
主要的指标[ CPU 使用率, load 负载.内存使用率,磁盘使用率, TCP 重传,连通性.].示例如下:
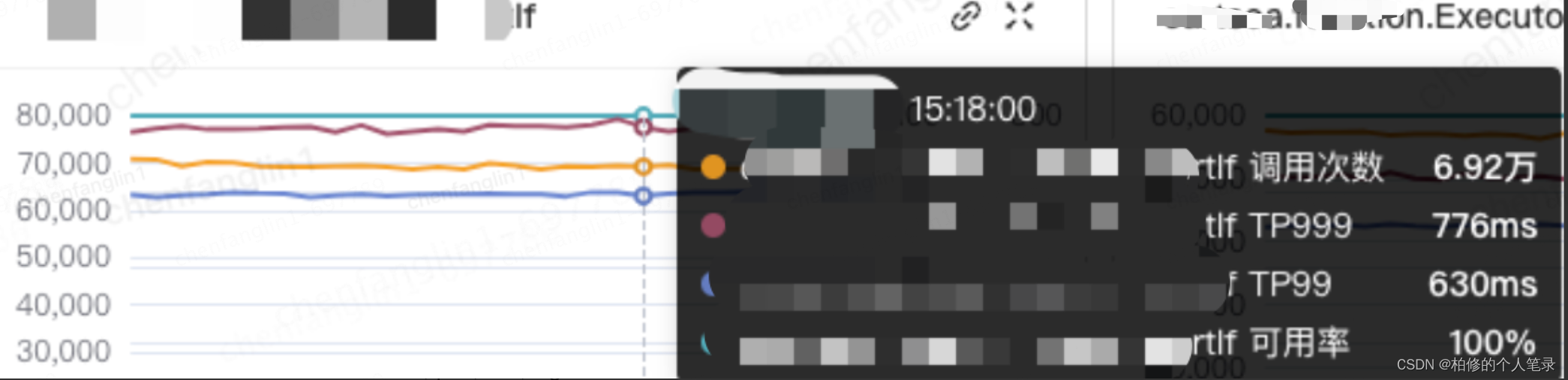
- 接口服务监控.主要指标.
调用次数(秒级,分钟级),平均响应时长,TP99,TP999,可用率.示例如下:
核心的监控面板:
1.自身系统依赖的服务接口监控面板.
2.常见上游/自身/下游error状态码监控面板.
3.自身系统核心接口监控面板
2.1.3 流量切割
- 入口流量切割
从域名到压测机器的流量,保证生产环境和压测环境进行流量切分
- *DB *流量切割
一般通过识别压测上下文指标的路由标,来判定是否需要重新切换数据源.这个技术很常见.常见的做法就是通过 AbstractRoutingDataSource 的重写来实现 determineCurrentLookupKey 方法来切换数据源.动态数据源切割.压测的数据源一般会重新 copy 一遍现有的数据库 schema 建立一个影子库,保证线上数据不受影响,有时候为了压测还需要进行一些线上数据的一些冲入,保证测试场景的完整进行.
- MQ 流量切割
主要是消费和发送都需要增加识别压测标来进行消息的发送和消息的消费.如:原有 topic .rd_product_add ,通过识别 isForceBot
标来增加 rd_product_add_shadow .
- cache 流量切割
方案基本同上.通过识别标来具体使用具体的 cacheClient 不同.
- 其他的中间件具体改造
如: es,ck,blink 等.
如上的流量切割后要进行小流量的试跑来保证改造的方案是可行的.防止出现压测过程的流量逃逸.影响线上真实的环境,污染生产数据等.
2.1.4 压测前的机器状态检查
这一步主要是 check 机器指标异常的,主要指标有 CPU, 硬盘, 内存, 连通性.防止一些特别的机器造成压测一直压不上去.出现指标异常的机器进行流量摘除的处理或者重启能消除隐患也可以继续使用.
2.1.5 测试的数据&脚本准备
- 数据准备
这里的数据准备要充分的模拟生产的环境数据,例如:加车的数据多样性每个维度都要充分的添加到.常见的加车数量6-10.
常见的重要的生产数据模拟.用户数据,订单数据,产品数据,购物车数据.
- 脚本
要保证基本的用例case能通
2.2 压测中
2.2.1 单场景压测
特定的场景压测,比如商详.这种场景下的压测因为是单场景的,所以在压测过程中不能够按照打满的场景去操作.比如说:整体商详压测的目标机器 cpu 目标是 60% .单场景的时候可能要留一些 buffer 去给全链路的场景做一些预留.
2.2.2 全链路压测
2.2.3 故障演练
通过演练做到面对故障时的响应机制.目标:完成3分钟内发现,5分钟内应急处理.10分钟定位原因.
大致分为这几个方面.
2.2.3.1 系统及硬件
系统方面涉及: CPU ,硬盘, TCP 重传,内存,磁盘可用率.
JVM :频繁 GC ,高频 YGC .
应对预案:快速通过监控平台完成具体IP机器定位,通过IP摘除流量完成,机器流量下线.通知运维定位原因. JVM 相关 DUMP 响应日志进行分析.
2.2.3.1 中间件相关演练
在服务中间件出现异常时系统能够正常提供服务,对应接口的指标能够满足目标要求.常见的中间件故障.
存储类: ES,DB,cache.
中间件: MQ
应对预案:中间件能够做到手动预案热备数据源切换,缓存中间件降级. MQ 停止消费等.
2.2.3.2 上下游服务异常演练
通过观察上下游服务监控面板快速定位上下游接口超时.
应对预案:非核心链路接口,主动通过开关进行降级.核心链路接口快速联系上下游进行相关原因排查.
2.6 限流演练
- 单机限流演练
在日常qps 平均值的前提上浮一些,保证生产的正常流量能够进行正常访问而不会触发限流. - 集群演练
2.3 压测后
- 压测后机器挂载流量回切
- 压测复盘
2.3.1 压测优化
- 代码优化
- 资源扩缩容
- 针对场景复压测
2.3.2 压测其他收官
- 完成压测报告
- 沉淀操作手册
- 沉淀压测记录
- 动态扩缩容规则确认,资源确认
- 流量回切
如果在整个压测过程中是使用的同样的生产环境,保证压测后机器及时归还线上.避免影响线上集群性能和用户体验.
三.压测中遇到的问题
3.1 硬件相关
首先定位具体硬件 IP 地址,优先进行流量摘取.出现大面积故障时同时保留现场同时立即联系运维同学协助排查定位.
3.2 接口相关
首先通过接口监控得到相关接口的tp99或avg,观测到实际的接口耗时已经影响主接口的调用时,进行主动的开关降级做到不影响主接口和核心逻辑.
3.3 其他
- tomcat 6 定期主动回收问题
tomcat6.0.33为防止内存泄露周期性每 1 小时触发 1 次System.gc(),导致tp周期性波动。tomcat源码JreMemoryLeakPreventionListener fullgc触发位置:
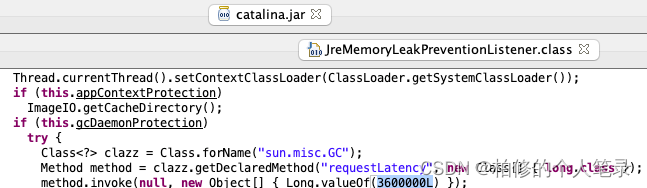
修复方案:从fullgc平均耗时200ms左右来看,fullgc耗时引发接口超时导致图文详情h5超时风险较小。计划618后升级tomcat版本解决。