虽然现有的 LLM 应用程序工具(例如 LangChain 和 LlamaIndex)对于构建 LLM 应用程序非常有用,但在初始实验之外不建议使用它们的数据加载功能。 当我构建和测试我的LLM应用程序管道时,我能够感受到一些尚未开发和破解的方面的痛苦。 如果你计划构建一个生产就绪的数据管道来为你的 LLM 应用程序提供支持,应该认真考虑使用专为该工作而构建的 EL 工具。
在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、介绍
自 OpenAI 发布 ChatGPT 以来的去年,人们兴奋不已,基于其技术构建的新内容和应用程序似乎无穷无尽。 随着最初的炒作尘埃落定,我们看到开发者生态系统开始后退一步,评估我们目前所处的位置。 Meltano 社区最近分享的两篇帖子激起了我们的兴趣,并激励我们进行更深入的研究。
第一篇是 a16z 的“LLM 应用程序的新兴架构”文章,重点介绍了构建大型语言模型 (LLM) 应用程序的新兴模式,其中重点介绍了数据预处理/嵌入阶段以及“这部分堆栈相对不发达,并且 有机会专门为 LLM 应用程序构建数据复制解决方案”
第二个是名为“Langchain Is Pointless”的 Reddit 帖子,后来也成为黑客新闻热点:

“为什么这不是 ETL,为什么你需要这里的东西? 这里不需要新的类别或产品。”

“这是毫无意义的—LlamaIndex 和 LangChain 正在重新发明 ETL—当你已经拥有强大的技术时为什么还要使用它们呢?”
Langchain 由 a16z 归入编排阶段,是 LLM 应用程序开发人员使用的主要工具之一,用于执行从源中提取数据、嵌入文档并将其存储在向量数据库中、为基于聊天的应用程序提示链接和存储内存等所有操作 ...如果你不理解其中一些术语,请不要担心,我将在下一节中解释它们。
受到这些帖子的启发,我进行了深入研究,以更好地了解正在发生的事情。 我阅读了大量文章,观看和收听了大量 YouTube 视频和播客(速度为 2 倍),并基于 Meltano SDK 文档构建了自己的 LLM 聊天应用程序来回答问题。
在这篇博文中,我将介绍以下内容:
- 我将总结我在深入研究 LLM 应用程序生态系统时发现的内容以及随之而来的挑战
- 我将从数据工程的角度亲自解读我们过去如何解决类似问题并提出理想的架构
- 我将解释使用 Meltano 构建的 POC 以及 Meltano 如何帮助解决未来这些挑战的愿景
2、 LLM 应用程序生态系统摘要
我将尽力以简洁的方式总结我所发现的内容,以便你对 LLM 应用程序生态系统有足够的背景知识来理解术语。 我发现,就像许多其他生态系统一样,有很多缩写和行话,但一旦你剥开层层,它开始看起来像你以前见过的常见模式。
2.1 上下文学习与微调
我遇到的第一个概念是使用微调与上下文学习+检索增强生成(RAG)。 这两种技术试图解决的问题是,预先训练的 LLM —例如 OpenAI 的 GPT 模型或 Hugging Face 等开源替代方案 — 是在静态数据集上进行训练的,而这些数据集现在已经过时了,这就是为什么当你向 ChatGPT 询问当下问题时,它会给你一个预设的回复,比如“对不起,我是在 2021 年之前的数据上训练的……”。
两者之间的高级差异在于,上下文学习将上下文作为运行时提示的一部分发送给预先训练的模型,以帮助其更多地了解你的问题。 虽然微调是进一步训练预训练模型以考虑一组新的上下文数据,但所有未来的提示都会直接进入模型的新迭代。
我的结论是,对于大多数用例来说,上下文学习方法是最受欢迎的。 有关上下文学习的更多详细信息,我建议你参阅 a16z 摘要,但我的要点是:
在上下文学习中:
- 作为 RAG 管道的一部分,对于大多数 LLM 用例来说,表现相当不错,并且是首选方法
- 利用 OpenAI 的 API 等“现成”工具和 Pinecone 等矢量数据库,因此小型数据团队可以构建 LLM 应用程序,而无需雇用专门的 ML 工程师
而微调:
- 当数据集很大且质量很高时,在充分聚焦的上下文中表现更好
- 需要更多关于如何对数据进行适当加权的专业知识,即不要对内容建立过度或不足的索引
- 要求你托管自己的模型和基础设施来为其提供服务
出于这些原因,我选择在余下的探索中主要关注情境学习应用程序。
2.2 矢量数据库和嵌入
下一个主题是矢量数据库和嵌入。
矢量数据库是存储上下文数据的地方,以便可以在运行时快速搜索它,为上下文提示找到语义相似的数据。 这是你的知识库。 矢量数据库并不是 LLM 浪潮期间出现的一项新技术,但它们在这个用例中确实获得了广泛的欢迎。 一些常见的有 Pinecone、Weaviate、Chroma、pgvector Postgres 扩展等等。
我不会详细介绍它们的工作原理,主要是因为我了解得不够😀,但也因为我发现矢量数据库的内部工作原理太低级,超出了本教程的范围。 了解如何使用它们。 这是我的淡化解释或如何在LLM应用程序的背景下使用矢量数据库......
这个概念是,你使用嵌入模型(如 OpenAI 的嵌入 API)将源文本数据(即我们的 SDK 文档 html 文本)转换为高维嵌入向量,然后将其与用于生成的源文本一起加载到矢量数据库中。 为了构建 LLM 应用程序,你不一定需要了解有关什么是嵌入以及它们如何生成的详细信息。 这些文本块有大小限制,因此这里有一个中间步骤将它们分成更小的子集。 然后,当想要在聊天应用程序中搜索类似文本时,你只需嵌入输入文本(再次使用 OpenAI API)并将向量作为查询传递到数据库即可。 数据库负责检索相似向量并最终返回附有原始文本 blob 的结果。 此时,你可以收集所有相关的文本片段,并将它们用作新的丰富聊天提示的上下文。
2.3 Langchain
在构建 LLM 应用程序时,这是最受关注的工具。 它抽象出了一些复杂的工作流程,并为开发人员提供了更简单的界面来进行构建。 关于它是否做得很好还有争议,但这就是目标。 在我看来,LangChain 似乎是应用程序层的一个很好的抽象,其中需要提示链、内存和从矢量数据库检索上下文数据等功能。 尽管 Langchain 的范围开始超出其数据连接能力的范围,但感觉就像以不太生产级别的方式重新发明轮子。
2.4 LlamaIndex
同样,LlamaIndex 也被大量提及,它在功能方面与 LangChain 有很多重叠,并且实际上在底层使用了 LangChain 相当多。 LlamaIndex 显然还有一些其他不错的应用程序级别功能,用于构建聊天应用程序,例如上下文搜索、缓存等。LlamaIndex 还拥有一个数据加载器和工具库,这些功能在名为 LlamaHub 的兄弟项目上进行了广告。 我再次遇到的主要问题是它们的范围渗透到了数据移动工具的范围,他们的文档在“为什么是 LlamaIndex?”中说了以下内容:
基于LLM构建的应用程序通常需要使用私有或特定领域的数据来增强这些模型。 不幸的是,这些数据可能分布在孤立的应用程序和数据存储中。 它位于 API 后面、SQL 数据库中,或者隐藏在 PDF 和幻灯片中。
所以看起来他们在某种程度上将其作为数据移动工具来营销🤔,但问题是他们正在以较低生产级别的方式重新发明轮子。 请参阅仅使用 while 循环的 slack reader,其作者批评道:
来自 Llama 的 Confluence 数据加载器只是 html2text Python 库的包装器,并将整个 Confluence 页面转储到字符串变量中
2、我们可以从数据工程中学到什么
感觉这些项目和世界变化得如此之快,以至于没有人有时间停下来考虑开发库的范围以及边界应该在哪里。 从我的角度来看,这些工具渗透到数据工程领域,并试图解决具有独特挑战的问题,最好留给专门构建的数据工程工具。
多年来,数据生态系统一直在解决许多类似的问题,因此让我们比较两个工作流程并找到重叠之处。 也许我们可以从DE中吸取一些教训。
当我思考大多数 LLM 应用程序正在做什么的摘要时,我会将它们分类如下:
- 数据提取:例如 从 slack API 中提取消息文本
- 数据清理:例如删除某些字符、多余空格、编码等。
- 数据丰富:向量嵌入
- 数据加载:写入矢量数据库
- 应用程序用户体验,例如提示链、检索、推理、记忆、聊天 UI 等。
这些存储桶看起来很像传统数据团队多年来一直在做的事情:
- 数据提取:例如从各种来源提取数据
- 数据丰富和转换:例如删除重复项、添加一致的名称、将复杂数据聚合为可用的业务指标等。
- 数据加载:写入数据仓库
- 数据可视化和消费:讲述数据故事的图表和仪表板
出于我的论证目的,我们可以放弃应用程序用户体验,因为在我看来,这是像 LangChain 这样的工具的核心能力,而且他们做得很好,使用 LangChain 来实现这一点。 在数据方面,我们也可以放弃数据可视化阶段,因为对于许多数据团队来说,可视化步骤被传递给分析师和 BI 工程师,他们需要与数据消费者合作,以很好地解释和呈现数据。
这让我们剩下的步骤在这两种情况下都可以缩小到以下范围:
- 数据提取
- 数据转换,即清洁和丰富
- 数据加载
在数据世界中,我们多年来一直在迭代这个过程,最初将其称为提取转换加载(ETL),现在过渡到提取加载转换(ELT)。 我们学到的教训是,提取缓慢且昂贵,因此我们只想执行一次,而转换和富集步骤则成本较低,并且需要更多迭代。 此外,随着时间的推移,存储成本显着降低。 将存储与计算分离成为主要的设计考虑因素。 有了这些认识,我们重新设计了我们的系统,以解耦两个工作流程,现在大多数数据团队一次提取+加载原始数据,然后对其进行多次转换。
这直接转化为LLM应用程序世界,因为许多团队正在试验和迭代构建其知识库和应用程序的最佳方法。 他们以不同的方式清理原始数据,或者使用不同的模型嵌入,或者使用不同的向量存储。
2.1 LLM 数据移动中最昂贵的部分是什么?
如果我们采用这种 ETL 与 ELT 学习并将其应用到 LLM 应用程序开发工作流程中,我们就会开始看到它几乎可以直接翻译。 当数据社区迭代 ETL 与 ELT 时,我们评估了最昂贵的步骤并设计了模式和工具来减少它们的影响。 在我看来,LLM 数据处理步骤中最昂贵的部分是:
- 数据提取
- 数据丰富
与传统数据工程一样,从数据库或 API 中提取数据速度慢、成本高,有时甚至很痛苦。 除了提取步骤之外,丰富步骤也很昂贵,特别是如果你使用 OpenAI 的嵌入 API 等 API。 富集步骤几乎开始看起来像第二个提取步骤。 当然,有一些方法可以减少这些昂贵步骤的影响,但重要的是要确定我们正在尝试优化的流程。
2.2 相关数据工程挑战
从表面上看,创建一个从 API 提取数据、清理和丰富数据、然后将其写入某个数据源的脚本似乎很简单。 我真的同意。 困难的部分是让它在生产中可靠、高效地运行所需的所有额外功能。 数据工程师经常思考和处理的一些事情是:
- API 速率受限和中断
- 分页
- 元数据和日志记录
- 模式验证和数据质量
- 个人身份信息 (PII) 处理、混淆、删除等。
- 在运行之间保持增量状态,以便您可以从上次中断的地方继续
- 架构变更管理
- 回填数据
这些 LLM 库目前能够从 API 中提取数据,但它们是否能够应对与将这些管道投入生产相关的所有挑战? 答案是不。 但公平地说,我不认为他们打算这样做,他们构建了用户当时需要的功能,这只是快速发展的开源项目的本质。
2.3 我们如何设计一个系统来应对这些挑战?
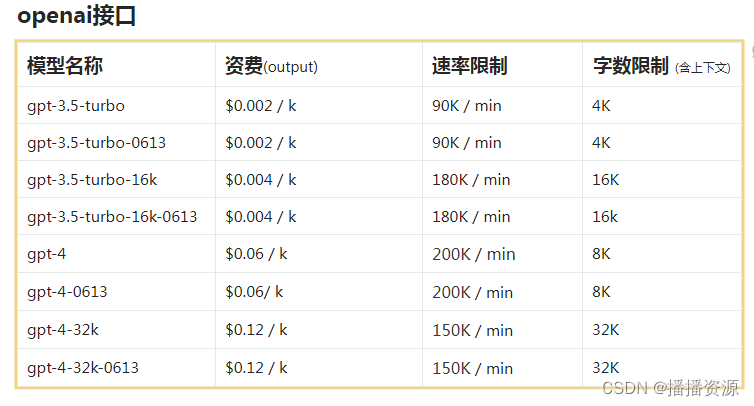
考虑到所有这些信息,我草拟了一个示例架构,感觉适合这样的工作流程。 该图从左到右阅读; 从源中提取数据,清理和嵌入文本,然后将其加载到矢量数据库中,而 LLM 应用程序本身目前超出了范围。

大家可以看到,大前提是我们每一步都坚持进步。 乍一看,这似乎是额外的开销,但特别是在我们可能想要迭代清理和嵌入步骤的世界中,我们会很高兴不必每次都重新提取或重新清理所有源数据。 此外,如果有合适的工具,应该很容易增量更新工作流程中的每个步骤,仅获取自上次运行以来的新数据,即仅检索昨天的 API 数据。 通过增量工作流程,你不必太担心 API 速率限制和处理性能,因为数据集要小得多。
此外,每个步骤中检查点进度的性质使你可以更轻松地随着时间的推移替换组件。 如果你今天使用 Pinecone,明天可以将其替换为 Weaviate,而无需重新提取所有数据并再次创建新的嵌入。
3、Meltano 和 LLM 应用程序
如果我让你相信使用数据工程模式和工具来处理这些工作负载是一个好主意,那么我们现在可以讨论为什么我认为 Meltano 很适合。 我将解释我使用 Meltano 构建的概念验证以及支持它的功能。 然后我将讨论我们如何对其进行迭代以使其在未来变得更好。 你还可以在 GitHub 上探索功能齐全的演示项目。
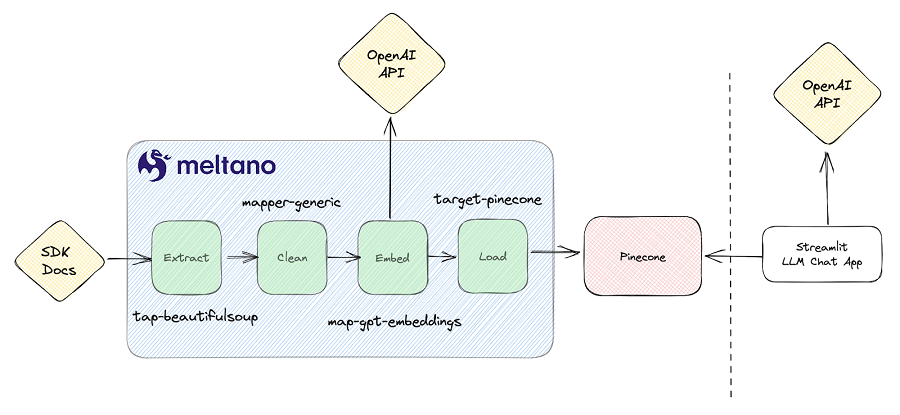
我构建了一个简单的管道来抓取 Meltano SDK 文档网站、清理 html、使用 OpenAI 的嵌入 API 嵌入它,然后将其加载到 Pinecone 中。 这是对原始版本的迭代。 为了验证我的输出,我最终还找到了一个示例 Streamlit LLM 聊天应用程序,该应用程序从我的 Pinecone 索引中检索数据以获取上下文,并根据我的需求进行调整。 所有这些都以演示项目中的代码形式表示,并且也包含在 Meltano Squared 项目中,该项目部署在 Meltano Cloud 的生产中。
由于我的 POC 的时间限制,我只实现了一个简单的端到端同步,没有检查点功能,尽管每个组件都是不同的插件这一事实将使我将来可以轻松扩展项目以包括强大的检查点功能。 其他竞争工具选择在幕后使用 Langchain 来分块、嵌入和加载矢量数据库数据,所有这些都在一个紧密耦合的步骤中进行,我认为这是一个设计缺陷。 紧密耦合所有这些步骤并且不允许你随着时间的推移迭代出更稳健的设计。
每个组件都是一个可以在 Meltano 项目中安装和运行的插件,因此你可以重新创建此 POC,而无需编写任何代码。 只需添加插件并根据你的用例进行配置即可。 MeltanoHub 还拥有 600 多个插件,可帮助你从任何其他来源提取数据。 让我们逐步完成每个步骤。
3.1 数据抽取
提取步骤使用配置为抓取 SDK 文档的 tap-beautifulsoup。 它会在本地下载所有相关的 html 页面,然后使用 beautifulsoup 库将它们处理成单独的记录:
- name: tap-beautifulsoup
variant: meltanolabs
pip_url: git+https://github.com/MeltanoLabs/tap-beautifulsoup.git@v0.1.0
config:
source_name: sdk-docs
site_url: https://sdk.meltano.com/en/latest/
output_folder: output
parser: html.parser
download_recursively: true
find_all_kwargs:
attrs:
role: main要预览输出,你可以运行 Meltano invoke Tap-beautifulsoup 并查看如下输出:
2023-08-17T15:28:57.408509Z [info ] Environment 'dev' is active
2023-08-17 11:28:58,886 | INFO | tap-beautifulsoup | Beginning full_table sync of 'page_content'...
{"type": "SCHEMA", "stream": "page_content", "schema": {"properties": {"source": {"type": ["string", "null"]}, "page_content": {"description": "The page content.", "type": ["string", "null"]}, "metadata": {"properties": {"source": {"type": ["string", "null"]}}, "type": ["object", "null"]}}, "type": "object"}, "key_properties": []}
{"type": "RECORD", "stream": "page_content", "record": {"source": "output/sdk.meltano.com/en/latest/typing.html", "page_content": "JSON Schema Helpers#\nClasses and functions to streamline…..[Trimmed Content]", "metadata": {"source": "output/sdk.meltano.com/en/latest/typing.html"}}, "time_extracted": "2023-08-17T15:29:38.975515+00:00"}
3.2 数据净化
为此,我选择编写一个带有一些自定义解析逻辑的小脚本,以删除多余的空格和换行符。 该脚本由名为 generic-mapper 的 Meltano 映射器针对通过管道传递的每条记录执行:
def map_record_message(self, message_dict: dict) -> t.Iterable[Message]:
page_content = message_dict["record"]["page_content"]
text_nl = " ".join(page_content.split("\n"))
text_spaces = " ".join(text_nl.split())
message_dict["record"]["page_content"] = text_spaces
return message_dict
该映射器允许你运行任意 python 脚本,因此可以选择安装非结构化库作为依赖项或 Langchain 本身,以帮助以你理想的方式准备数据。
3.3 生成嵌入
在此步骤中,我们还使用映射器来处理管道中的每个记录,但这次我们使用 map-gpt-embeddings。 该映射器将输入记录分割成块(如果需要),然后使用 OpenAI 嵌入 API 生成嵌入。 映射器在底层使用 Meltano 提取器 SDK,以最少的代码利用所有出色的功能,例如分页、速率限制处理等。
- name: map-gpt-embeddings
variant: meltanolabs
pip_url: git+https://github.com/MeltanoLabs/map-gpt-embeddings.git
mappings:
- name: add-embeddings
config:
document_text_property: page_content
document_metadata_property: metadata
3.4 数据加载
最后,管道使用 target-pinecone 将这些记录写入你的 Pinecone 索引:
- name: target-pinecone
variant: meltanolabs
config:
index_name: target-pinecone-index
environment: asia-southeast1-gcp-free
document_text_property: page_content
embeddings_property: embeddings
metadata_property: metadata
pinecone_metadata_text_key: text
load_method: overwrite这些步骤全部拼接在一起作为单个计划的 Meltano 作业,但可以使用简单的命令(如 meltano run tap-beautifulsoup clean-text add-embeddings target-pinecone)手动运行。 如果你愿意,可以自行托管它,或者使用 Meltano Cloud 来处理运行预定义计划所需的基础设施。
4、未来发展方向
在下一次迭代中,我计划利用 Singer JSONL 提取器和加载器来实现前面讨论的检查点功能。 这将解锁从检查点快速重新加载、保留数据备份以及在清理+嵌入步骤中快速进行实验的能力(例如尝试不同的嵌入模型、清理技术等)。
5、结束语
虽然现有的 LLM 应用程序工具(例如 LangChain 和 LlamaIndex)对于构建 LLM 应用程序非常有用,但不建议在初始实验之外使用它们的数据加载功能。 当我构建和测试我的LLM应用程序管道时,我能够感受到一些尚未开发和破解的方面的痛苦。 如果你计划构建一个生产就绪的数据管道来为你的 LLM 应用程序提供支持,应该认真考虑使用专为该工作而构建的 EL 工具。
原文链接:LLM App ≈ 数据管线 - BimAnt