大致流程:将nginx 服务器(web-filebeat)的日志通过filebeat收集之后,存储到缓存服务器kafka,之后logstash到kafka服务器上取出相应日志,经过处理后写入到elasticsearch服务器并在kibana上展示。
一、集群环境准备
4c/8G/100G 10.10.200.33 Kafka+ZooKeeper+ES+Filebeat+ES-head
4c/8G/100G 10.10.200.34 Kafka+ZooKeeper+ES+Kibana
4c/8G/100G 10.10.200.35 Kafka+ZooKeeper+ES+Logstash二、搭建zookeeper集群
前提条件:三台机器分别修改时区、关闭防火墙、安装JAVA环境变量、修改主机名
[root@kf-zk-es-fb_es-head logs]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.10.200.33 kf-zk-es-fb_es-head
10.10.200.34 kf-zk-es-kibana
10.10.200.35 kf-zk-es-logstash
[root@kf-zk-es-fb_es-head logs]# java -version
openjdk version "1.8.0_382"
OpenJDK Runtime Environment (build 1.8.0_382-b05)
OpenJDK 64-Bit Server VM (build 25.382-b05, mixed mode)
[root@kf-zk-es-fb_es-head logs]# cat /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64/
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$PATH:$JRE_HOME/bin:$JAVA_HOME/bin
2.1 安装zookeeper(三台机器同步)
[root@kf-zk-es-fb_es-head ~]# wget http://dlcdn.apache.org/zookeeper/zookeeper-3.8.3/apache-zookeeper-3.8.3-bin.tar.gz
[root@kf-zk-es-fb_es-head ~]# tar -zxvf apache-zookeeper-3.8.3-bin.tar.gz -C /usr/local/
[root@kf-zk-es-fb_es-head ~]# mv /usr/local/apache-zookeeper-3.8.3-bin/ /usr/local/zookeeper-3.8.3
[root@kf-zk-es-fb_es-head ~]# cp /usr/local/zookeeper-3.8.0/conf/zoo_sample.cfg /usr/local/zookeeper-3.8.0/conf/zoo.cfg
修改配置文件
本机IP设置成0.0.0.0
节点一:
[root@kf-zk-es-fb_es-head ~]# vim /usr/local/zookeeper-3.8.3/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-3.8.3/data
dataLogDir=/usr/local/zookeeper-3.8.3/logs
clientPort=2181
server.1=0.0.0.0:2888:3888
server.2=10.10.200.34:2888:3888
server.3=10.10.200.35:2888:3888
节点二:
[root@kf-zk-es-kibana ~]# egrep -v '^#|^$' /usr/local/zookeeper-3.8.3/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-3.8.3/data
dataLogDir=/usr/local/zookeeper-3.8.3/logs
clientPort=2181
server.1=10.10.200.33:2888:3888
server.2=0.0.0.0:2888:3888
server.3=10.10.200.35:2888:3888
节点三:
[root@kf-zk-es-logstash ~]# egrep -v '^#|^$' /usr/local/zookeeper-3.8.3/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-3.8.3/data
dataLogDir=/usr/local/zookeeper-3.8.3/logs
clientPort=2181
server.1=10.10.200.33:2888:3888
server.2=10.10.200.34:2888:3888
server.3=0.0.0.0:2888:3888
其中dataDir和dataLogDir需要手动创建,否则启动服务会报错目录完成后新建myid文件:
节点一:
[root@kf-zk-es-fb_es-head data]# pwd
/usr/local/zookeeper-3.8.3/data
[root@kf-zk-es-fb_es-head data]# cat myid
1
节点二:
[root@kf-zk-es-kibana data]# cat myid
2
节点三:
[root@kf-zk-es-logstash data]# cat myid
3
主要是要跟各自的配置文件的server.1.2.3对应2.2 配置zookeeper启动脚本
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
设置开机自启:
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper2.3 启动zookeeper
节点一:
[root@kf-zk-es-logstash data]# service start zookeeper
[root@kf-zk-es-fb_es-head data]# service zookeeper status
---------- zookeeper 状态 ------------
/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.8.3/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower #从节点
节点二:
[root@kf-zk-es-logstash data]# service start zookeeper
[root@kf-zk-es-kibana data]# service zookeeper status
---------- zookeeper 状态 ------------
/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.8.3/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader #主节点
节点三:
[root@kf-zk-es-logstash data]# service start zookeeper
[root@kf-zk-es-logstash data]# service zookeeper status
---------- zookeeper 状态 ------------
/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.8.3/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower #从节点
三、部署Kafka
3.1 安装Kafka
以下所有步骤三节点都要执行,可下载好包scp过去
[root@kf-zk-es-fb_es-head ~]# wget http://archive.apache.org/dist/kafka/2.8.2/kafka_2.13-2.8.2.tgz
[root@kf-zk-es-fb_es-head ~]# tar xf kafka_2.13-2.8.2.tgz -C /usr/local/
[root@kf-zk-es-fb_es-head ~]# mv kafka_2.13-2.8.2 kafka
[root@kf-zk-es-fb_es-head ~]# cp /usr/local/kafka/config/server.properties /usr/local/kafka/config/server.properties_bak
编辑配置文件:
节点一:
[root@kf-zk-es-fb_es-head ~]# vim /usr/local/kafka/config/server.properties
broker.id=1
listeners=PLAINTEXT://10.10.200.33:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
节点二:
[root@kf-zk-es-kibana ~]# egrep -v '^#|^$' /usr/local/kafka/config/server.properties
broker.id=2
listeners=PLAINTEXT://10.10.200.34:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
节点三:
[root@kf-zk-es-logstash ~]# egrep -v '^#|^$' /usr/local/kafka/config/server.properties
broker.id=3
listeners=PLAINTEXT://10.10.200.35:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
配置环境变量:
[root@kf-zk-es-logstash ~]# tail -2 /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@kf-zk-es-logstash ~]# source /etc/profile
3.2 启动Kafka
三节点同时执行
[root@kf-zk-es-logstash ~]# sh /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
[root@kf-zk-es-logstash ~]# netstat -lntup|grep 9092
tcp6 0 0 10.10.200.35:9092 :::* LISTEN 7474/java
3.3 Kafka常用命令
#查看当前服务器中的所有topic
kafka-topics.sh --list --zookeeper 10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181
#查看某个topic的详情
kafka-topics.sh --describe --zookeeper 10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181
#发布消息
kafka-console-producer.sh --broker-list 10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181 --topic test
#消费消息
kafka-console-consumer.sh --bootstrap-server 10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181 --topic test --from-beginning
--from-beginning 会把主题中以往所有的数据都读取出来
#修改分区数
kafka-topics.sh --zookeeper 10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181 --alter --topic test --partitions 6
#删除topic
kafka-topics.sh --delete --zookeeper 10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181 --topic test
3.4 Kafka命令创建topic
[root@kf-zk-es-fb_es-head ~]# kafka-topics.sh --create --zookeeper 10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181 --partitions 3 --replication-factor 1 --topic test
Created topic test.
--zookeeper: 定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor: 定义分区副本数,1 代表单副本,建议为 2
--partitions: 定义分区数
--topic: 定义 topic 名称
查看topic信息
[root@kf-zk-es-fb_es-head ~]# sh /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 10.10.200.33:2181
Topic: test PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: test Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1
3.5 测试Kafka-topic
[root@kf-zk-es-fb_es-head ~]# kafka-console-producer.sh --broker-list 10.10.200.33:9092,10.10.200.34:9092,10.10.200.35:9092 --topic test
>1
>hello
>my
>name
>is
>world
[root@kf-zk-es-kibana ~]# kafka-console-consumer.sh --bootstrap-server 10.10.200.33:9092,10.10.200.34:9092,10.10.200.35:9092 --topic test --from-beginning
1
hello
my
name
is
world
3.6 Kafka问题总结
重启服务需要先杀掉进程。如果重新创建topic时报错,需要删掉/tmp/kafka-logs/meta.properties才能正常启动,另外配置文件中一定要写好zookeeper的连接属性:zookeeper.connect=10.10.200.33:2181,10.10.200.34:2181,10.10.200.35:2181
4、搭建Elastic search并配置
三台主机都安装并修改配置文件后启动
以节点一为例,另外两台机器同步执行:
[root@kf-zk-es-fb_es-head ~]# wget http://dl.elasticsearch.cn/elasticsearch/elasticsearch-7.9.2-x86_64.rpm
[root@kf-zk-es-fb_es-head ~]# rpm -ivh elasticsearch-7.9.2-x86_64.rpm
[root@kf-zk-es-fb_es-head ~]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml_bak
[root@kf-zk-es-fb_es-head elasticsearch]# egrep -v '^#|^$' /etc/elasticsearch/elasticsearch.yml
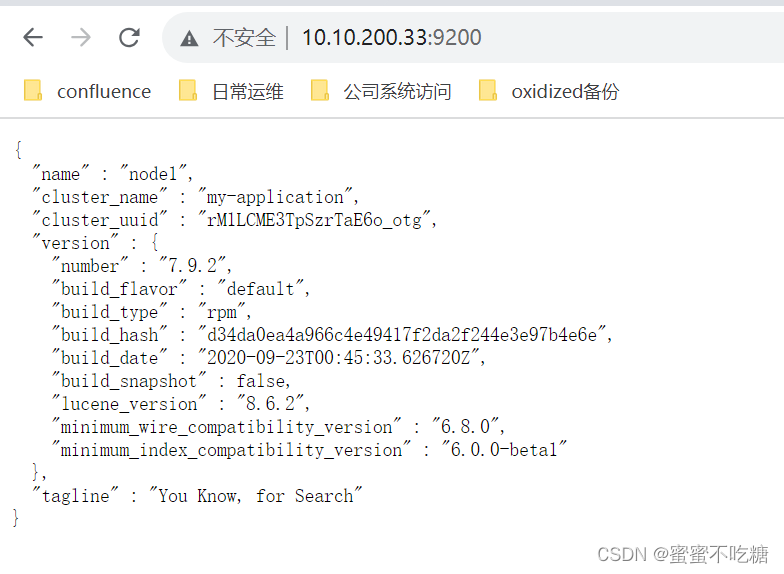
cluster.name: my-application
node.name: node1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.10.200.33","10.10.200.34","10.10.200.35"]
cluster.initial_master_nodes: ["node1","node2","node3"]
http.host: [_local_, _site_]5、启动Elastic search并设置开机自启
三台机同步执行
[root@kf-zk-es-fb_es-head ~]# systemctl start elasticsearch
[root@kf-zk-es-fb_es-head ~]# systemctl status elasticsearch
● elasticsearch.service - Elasticsearch
Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; disabled; vendor preset: disabled)
Active: active (running) since Fri 2023-11-10 09:27:14 CST; 8s ago
[root@kf-zk-es-fb_es-head ~]# systemctl enable elasticsearch
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
6、页面访问
7、部署logstash消费kafka数据写入到ES
下载地址:http://dl.elasticsearch.cn/logstash/logstash-7.9.2.rpm
[root@kf-zk-es-logstash ~]# rpm -vih logstash-7.9.2.rpm
[root@kf-zk-es-logstash ~]# vim /etc/logstash/conf.d/logstash.conf
input {
kafka {
codec => "plain"
topics => ["hello"]
bootstrap_servers => "10.10.200.33:9092,10.10.200.34:9092,10.10.200.35:9092"
max_poll_interval_ms => "3000000"
session_timeout_ms => "6000"
heartbeat_interval_ms => "2000"
auto_offset_reset => "latest"
group_id => "logstash"
type => "logs"
}
}
output {
elasticsearch {
hosts => ["http://10.10.200.33:9200", "http://10.10.200.34:9200","http://10.10.200.35:9200"]
index => "hello-%{+YYYY.MM.dd}"
}
}
[root@kf-zk-es-logstash ~]# cd /usr/share/logstash/
[root@kf-zk-es-logstash logstash]# mkdir config
[root@kf-zk-es-logstash logstash]# cp /etc/logstash/pipelines.yml config/
[root@kf-zk-es-logstash logstash]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
[root@kf-zk-es-logstash logstash]# logstash -t
无报错则启动logstash
[root@kf-zk-es-logstash logstash]# systemctl start logstash && systemctl enable logstash
Created symlink from /etc/systemd/system/multi-user.target.wants/logstash.service to /etc/systemd/system/logstash.service.
查看日志是否有消费kafka信息
[root@kf-zk-es-logstash logstash]# tail -f /var/log/logstash/logstash-plain.log
9、部署Filebeat
http://dl.elasticsearch.cn/filebeat/filebeat-7.9.2-x86_64.rpm
[root@kf-zk-es-fb_es-head ~]# rpm -vih filebeat-7.9.2-x86_64.rpm
[root@kf-zk-es-fb_es-head ~]# vim /etc/filebeat/filebeat.yml
配置收集日志信息
filebeat.inputs:
- type: log
enabled: true
paths:
#收集日志地址
- /usr/local/logs/*.log #此日志为nginx的路径日志,事先在本机安装了nginx
output.kafka: #只新增kafka这的output,把elasticsearch的注释掉,否则报错
#配置Kafka地址
hosts: ["10.10.200.33:9092","10.10.200.34:9092","10.10.200.35:9092"]
#这个Topic 要和Kafka一致
topic: 'test'
启动filebeat
[root@kf-zk-es-fb_es-head ~]# nohup filebeat -e -c filebeat.yml &
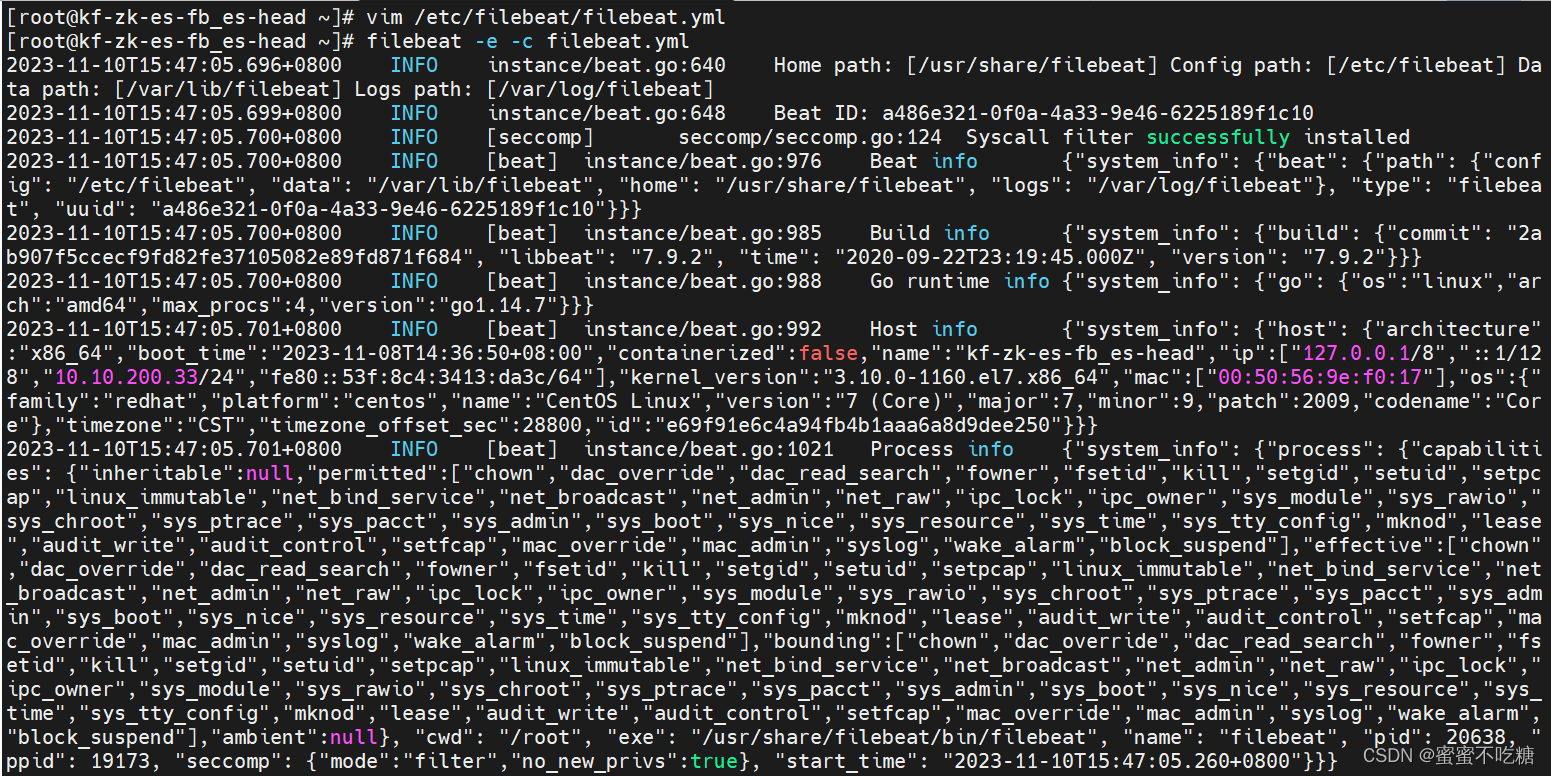
10、安装kibana展示日志信息
下载地址:http://dl.elasticsearch.cn/kibana/kibana-7.9.2-x86_64.rpm
[root@kf-zk-es-kibana ~]# rpm -ivh kibana-7.9.2-x86_64.rpm
[root@kf-zk-es-kibana ~]# vim /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://10.10.200.33:9200","http://10.10.200.34:9200","http://10.10.200.35:9200"]
kibana.index: ".kibana"
启动服务
[root@kf-zk-es-kibana ~]# systemctl start kibana && systemctl enable kibana
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.
[root@node2 ~]# journalctl -u kibana #查看启动正常确认端口已启动后网页访问:

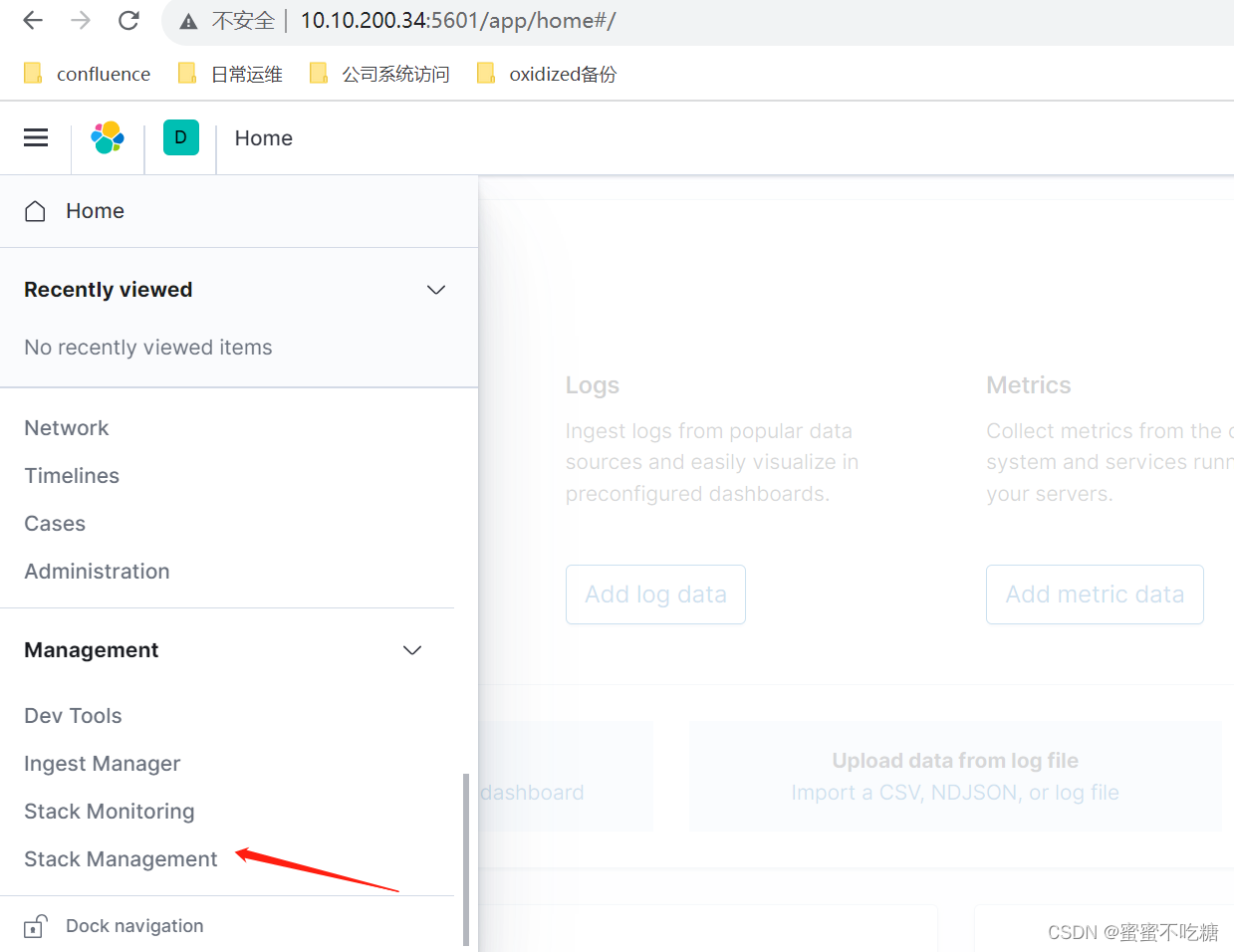
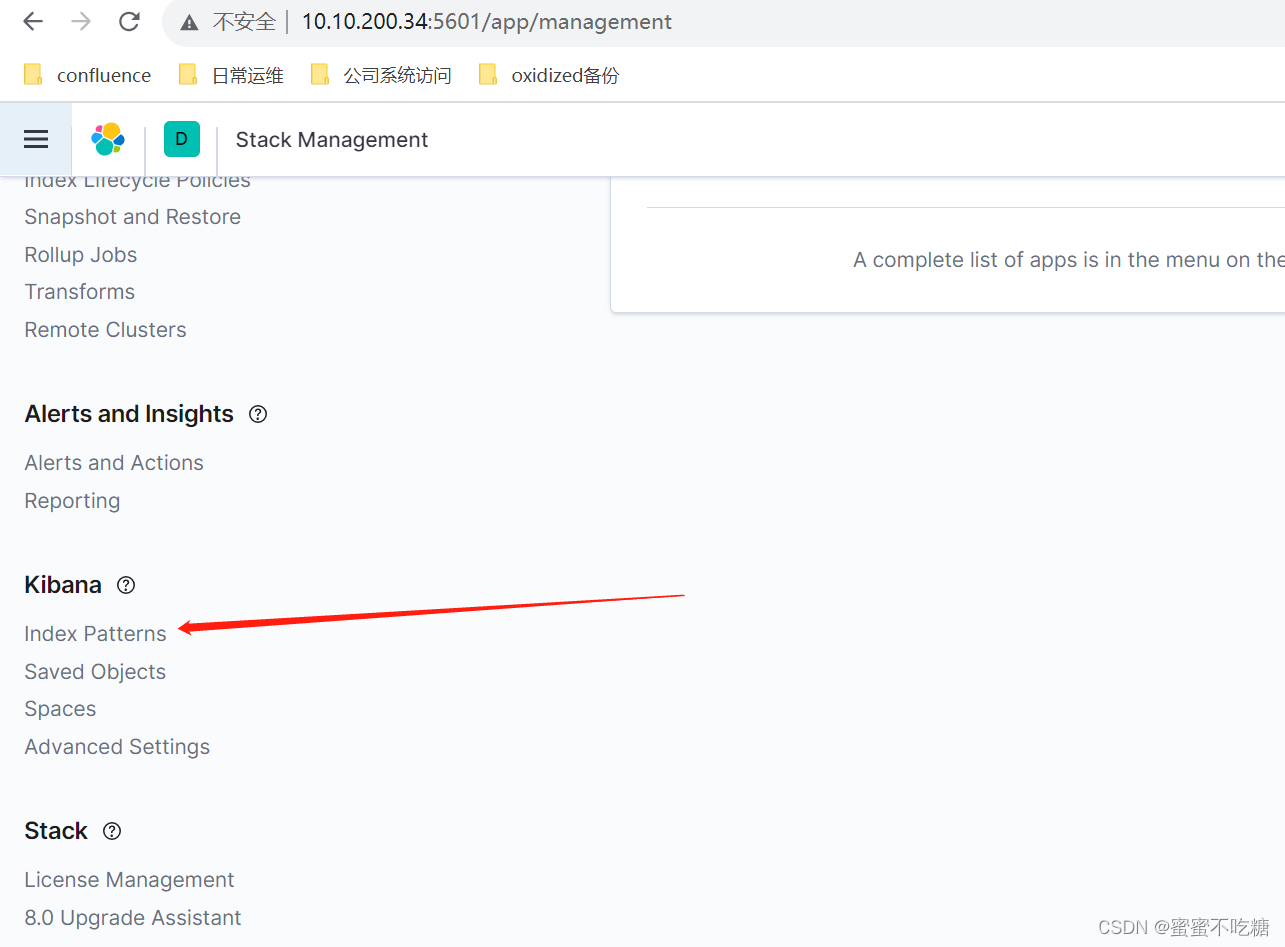
点击后创建index,如果提示:You'll need to index some data into Elasticsearch before you can create an index pattern. Learn how 的话,原因是因为没有任何数据,任何索引,可在机器后台执行以下命令模拟新建数据:
[root@node1 ~]# curl -H "Content-Type: application/json" -XPOST 'http://10.10.200.33:9200/ruizhi-log-2023-11-13/test-log' -d '{"code":200,"message":"测试"}'
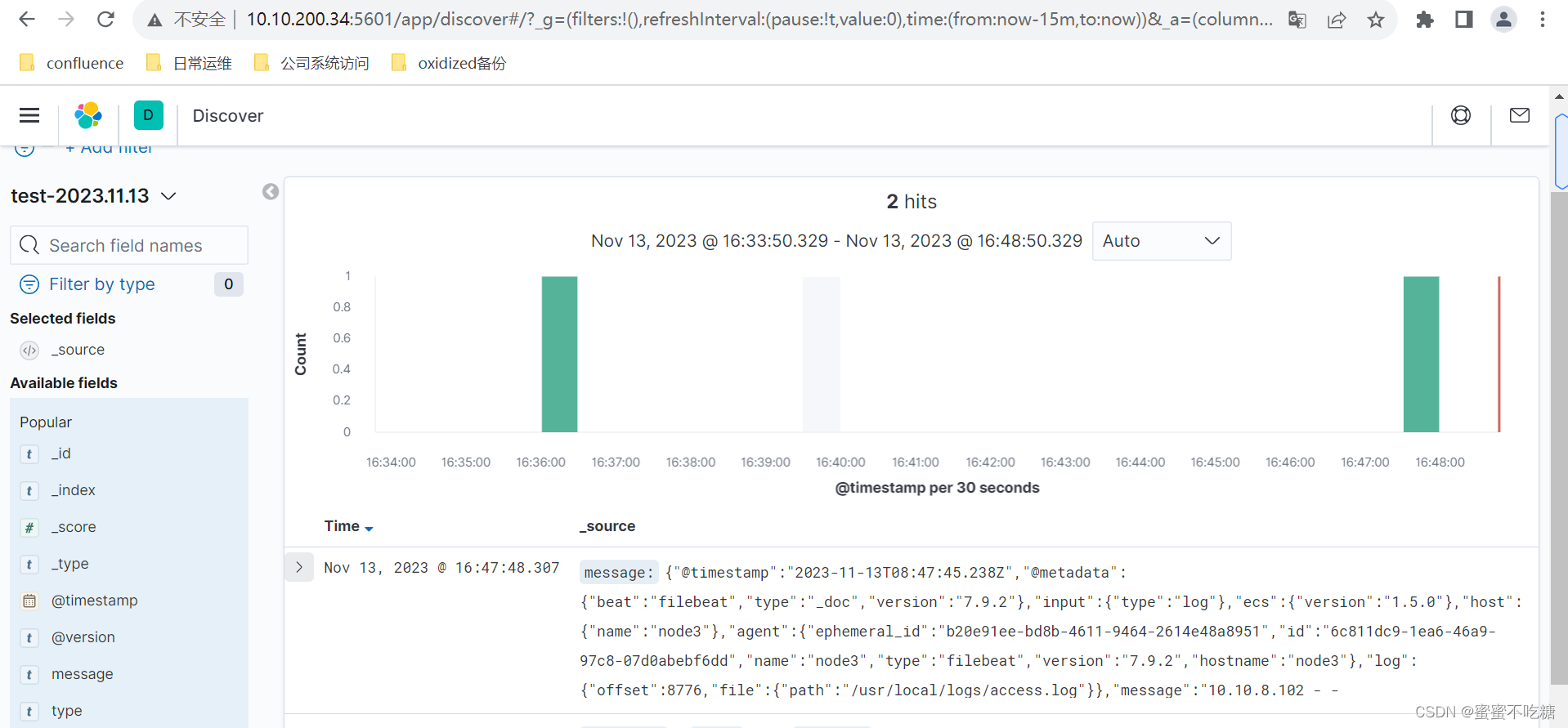
{"_index":"ruizhi-log-2023-11-13","_type":"test-log","_id":"mfRRx4sBE7vjRIscdoqf","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}之后,刷新网页,如下图:
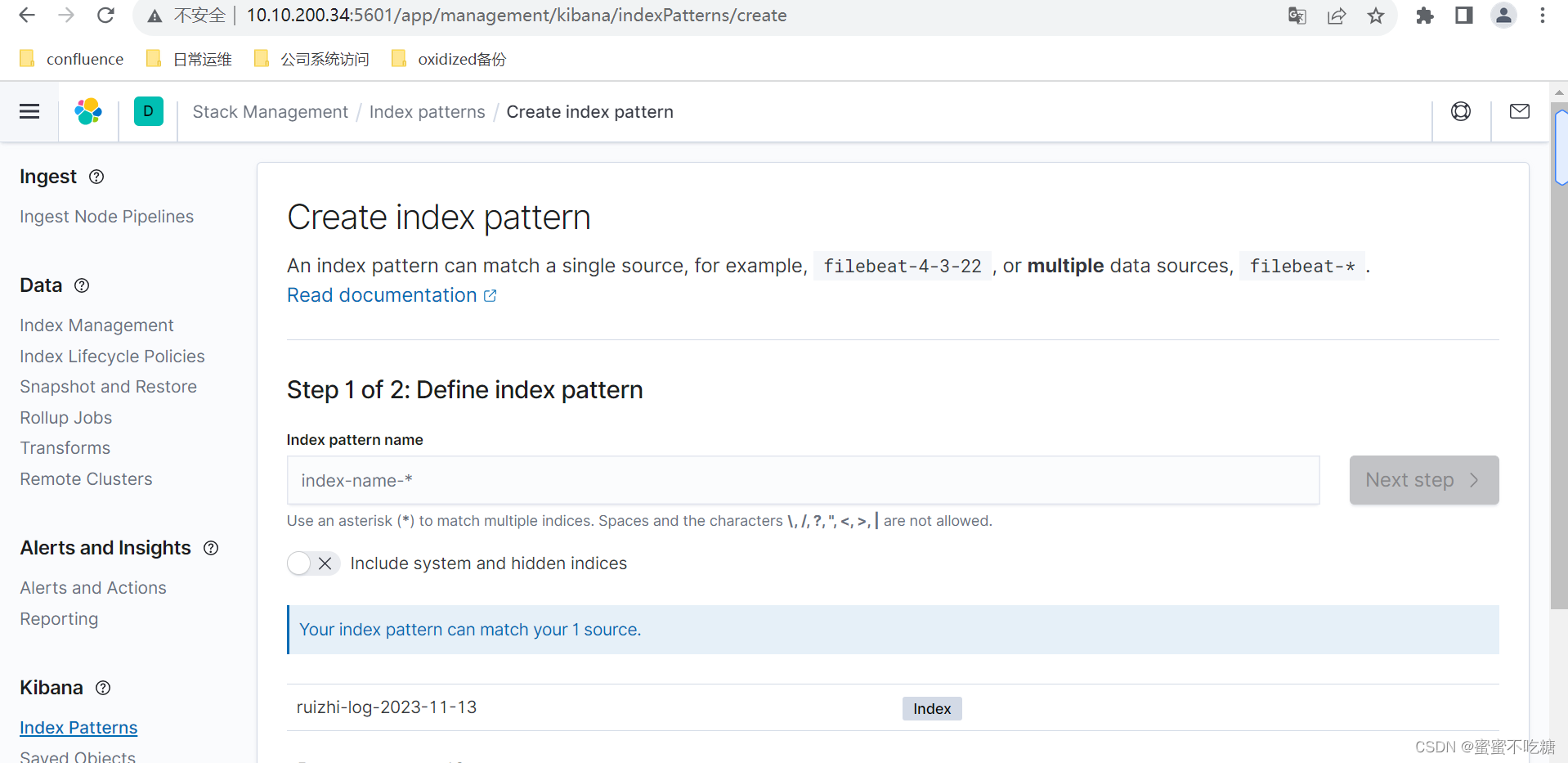
选择test-2023.11.13,之后模拟访问nginx:
刷新此页面

可在后台kafka的消费消息命令输出中,查看到nginx的日志已被传递到kafka:

kibana上也同步了日志,内容是一模一样的