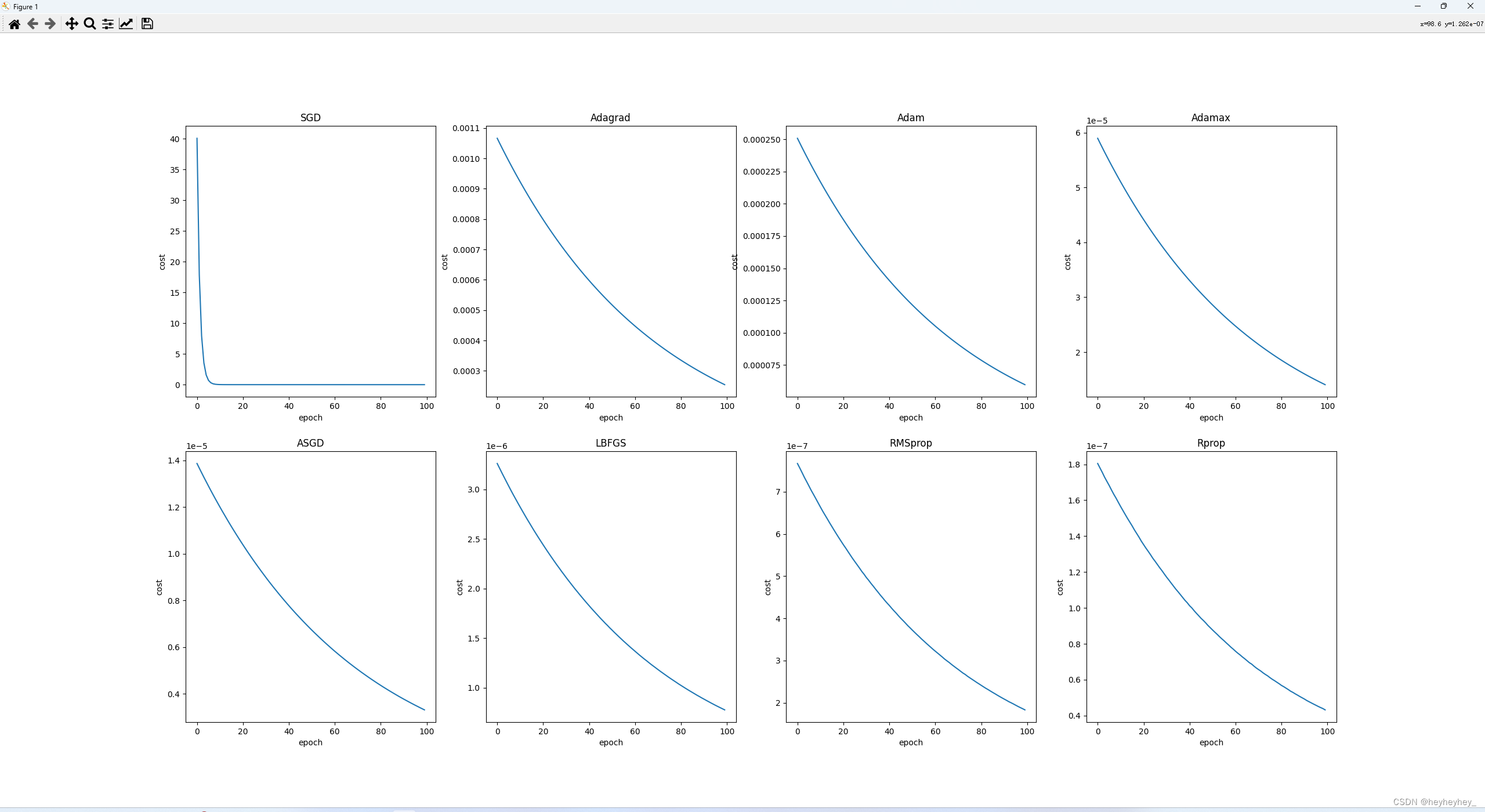
简单用用,优化器具体参考
深度学习中的优化器原理(SGD,SGD+Momentum,Adagrad,RMSProp,Adam)_哔哩哔哩_bilibili
收藏版|史上最全机器学习优化器Optimizer汇总 - 知乎 (zhihu.com)
import numpy as np
import matplotlib.pyplot as plt
import torch
# prepare dataset
# x,y是矩阵,3行1列 也就是说总共有3个数据,每个数据只有1个特征
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
loss_SGD = []
loss_Adagrad = []
loss_Adam = []
loss_Adamax = []
loss_ASGD = []
loss_LBFGS = []
loss_RMSprop = []
loss_Rprop = []
class LinearModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.Linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = self.Linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(reduction='sum')
optimizer_SGD = torch.optim.SGD(model.parameters(),lr=0.01)
optimizer_Adagrad = torch.optim.SGD(model.parameters(),lr=0.01)
optimizer_Adam = torch.optim.SGD(model.parameters(),lr=0.01)
optimizer_Adamax = torch.optim.SGD(model.parameters(),lr=0.01)
optimizer_ASGD = torch.optim.SGD(model.parameters(),lr=0.01)
optimizer_LBFGS = torch.optim.SGD(model.parameters(),lr=0.01)
optimizer_RMSprop = torch.optim.SGD(model.parameters(),lr=0.01)
optimizer_Rprop = torch.optim.SGD(model.parameters(),lr=0.01)
epoch_list = []
# optimizer_SGD
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
epoch_list.append(epoch)
loss_SGD.append(loss.data)
optimizer_SGD.zero_grad()
loss.backward()
optimizer_SGD.step()
# optimizer_Adagrad
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
loss_Adagrad.append(loss.data)
optimizer_Adagrad.zero_grad()
loss.backward()
optimizer_Adagrad.step()
# optimizer_Adam
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
loss_Adam.append(loss.data)
optimizer_Adam.zero_grad()
loss.backward()
optimizer_Adam.step()
# optimizer_Adamax
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
loss_Adamax.append(loss.data)
optimizer_Adamax.zero_grad()
loss.backward()
optimizer_Adamax.step()
# optimizer_ASGD
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
loss_ASGD.append(loss.data)
optimizer_ASGD.zero_grad()
loss.backward()
optimizer_ASGD.step()
# optimizer_LBFGS
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
loss_LBFGS.append(loss.data)
optimizer_LBFGS.zero_grad()
loss.backward()
optimizer_LBFGS.step()
# optimizer_RMSprop
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
loss_RMSprop.append(loss.data)
optimizer_RMSprop.zero_grad()
loss.backward()
optimizer_RMSprop.step()
# optimizer_Rprop
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
loss_Rprop.append(loss.data)
optimizer_Rprop.zero_grad()
loss.backward()
optimizer_Rprop.step()
x_test = torch.tensor([4.0])
y_test = model(x_test)
print('y_pred = ', y_test.data)
plt.subplot(241)
plt.title("SGD")
plt.plot(epoch_list,loss_SGD)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.subplot(242)
plt.title("Adagrad")
plt.plot(epoch_list,loss_Adagrad)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.subplot(243)
plt.title("Adam")
plt.plot(epoch_list,loss_Adam)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.subplot(244)
plt.title("Adamax")
plt.plot(epoch_list,loss_Adamax)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.subplot(245)
plt.title("ASGD")
plt.plot(epoch_list,loss_ASGD)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.subplot(246)
plt.title("LBFGS")
plt.plot(epoch_list,loss_LBFGS)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.subplot(247)
plt.title("RMSprop")
plt.plot(epoch_list,loss_RMSprop)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.subplot(248)
plt.title("Rprop")
plt.plot(epoch_list,loss_Rprop)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()运行结果: