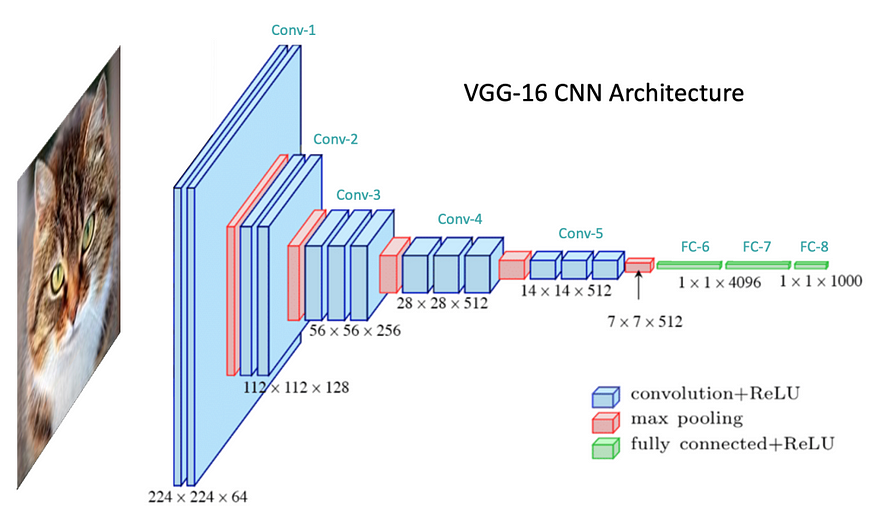
VGG-16 卷积神经网络。来源:LearnOpenCV
参考资料:这篇文章可以在 Kaggle Notebook 🧠 Convolutional Neural Network From Scratch上更好地阅读。路易斯·费尔南多·托雷斯
一、说明
本文详细介绍在tf2.0上,使用ceras实现基本的神经网络过程,并指明CNN在图像,在语言处理等的应用场景,并且对各个层进行具体阐述,此文对于初学者有极大参考意义。
二、介绍
卷积神经网络(CNN 或 ConvNet)是专门的神经架构,主要用于多种计算机视觉任务,例如图像分类和对象识别。这些神经网络利用线性代数的力量,特别是通过卷积运算来识别图像中的模式。
卷积神经网络具有三种主要类型的层,它们是:
• 卷积层
• 池化层
• 全连接层
卷积层是网络的第一层,而全连接层是最后一层,负责输出。第一个卷积层后面可能跟着几个附加的卷积层或池化层;每增加一层,CNN 就会变得更加复杂。
随着 CNN 变得越来越复杂,它在识别图像的更大部分方面就越擅长。早期的层侧重于简单的特征,例如颜色和边缘;随着图像在网络中传播,CNN 开始识别更大的元素和形状,直到最终达到其主要目标。
下图显示了 CNN 的结构。我们有一个输入图像,然后是卷积层和池化层,其中发生特征学习过程。之后,我们有负责对输入数据中的车辆是否是汽车、卡车、货车、自行车等进行分类的任务的层。
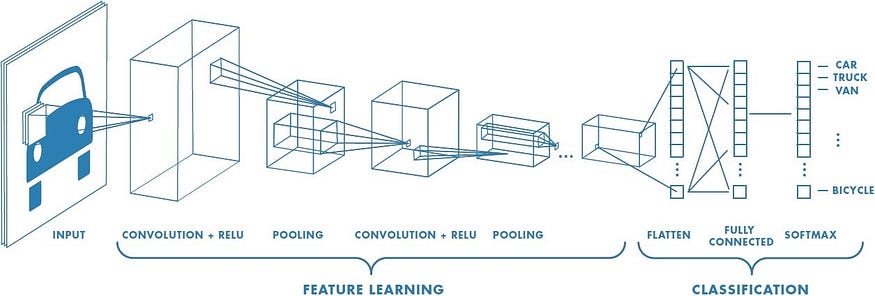
显示卷积神经网络结构的图像。
来源:理解卷积神经网络(CNN)——深度学习
卷积层
卷积层是CNN最重要的层;负责处理主要计算工作。卷积层包括输入数据、滤波器和特征图。
为了说明它是如何工作的,我们假设我们有一个彩色图像作为输入。该图像由 3D 像素矩阵组成,代表图像的三个维度:高度、宽度和深度。
过滤器(也称为内核)是一个二维权重数组,通常是一个3×3矩阵。它应用于图像的特定区域,并计算输入像素和滤波器中的权重之间的点积。随后,滤波器移动一步,重复整个过程,直到内核滑过整个图像,产生输出数组。
生成的输出数组也称为特征图、激活图或卷积特征。

显示卷积过程的 GIF。首先,我们有一个 5×55×5 矩阵(输入图像中的像素)和一个 3×33×3 滤波器。运算的结果是输出数组。
来源:卷积神经网络
值得注意的是,当滤波器在图像上移动时,滤波器中的权重保持固定。由于反向传播和梯度下降,权重值在训练过程中进行调整。
除了过滤器中的权重之外,我们还需要在训练开始之前设置其他三个重要参数:
• 过滤器数量:该参数负责定义输出的深度。如果我们有三个不同的过滤器,我们就有三个不同的特征图,创建深度为三。
• 步长:这是滤波器在输入矩阵上移动的距离或像素数。
• 零填充:当滤镜不适合输入图像时,通常使用此参数。这会将输入矩阵之外的所有元素设置为零,从而产生更大或同等大小的输出。共有三种不同类型的填充:
■ 有效填充:也称为无填充。在这种特定情况下,如果维度不对齐,最后一个卷积就会被丢弃。
■ 相同的填充:此填充可确保输出层与输入层的大小完全相同。
■ 完全填充:这种填充通过向输入矩阵的边界添加零来增加输出的大小。
在每次卷积操作之后,我们应用修正线性单元(ReLU)函数,它转换特征图并引入非线性。

资料来源:ResearchGate
如前所述,初始卷积层后面可以跟着附加的卷积层。
随后的卷积层可以看到先前层的感受野内的像素,这有助于提取和解释附加模式。
池化层
池化层负责降低输入的维度。它还在整个输入上滑动一个过滤器(没有任何权重)以填充输出数组。我们有两种主要的池化类型:
• 最大池化:当过滤器在输入中滑动时,它会为输出数组选择具有最高值的像素。
• 平均池化:通过计算感受野内的平均值来获得为输出选择的值。
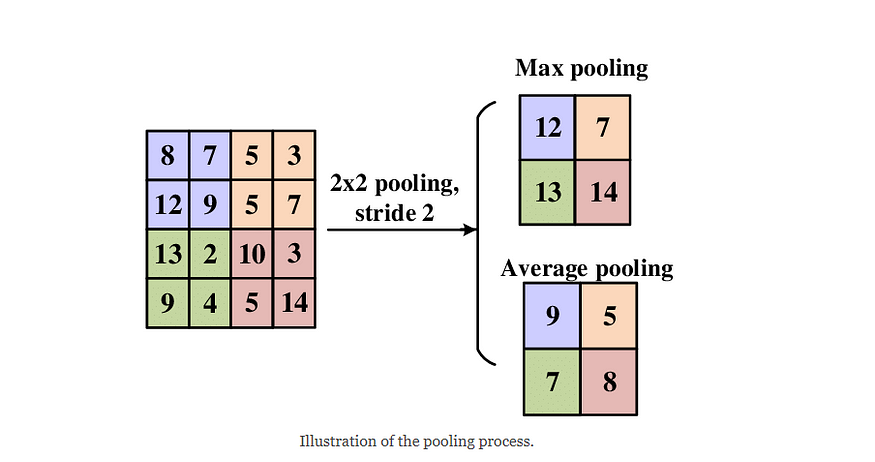
资料来源:ResearchGate
池化层的目的是降低复杂性、提高效率并限制过度拟合的风险。
全连接层
该层负责根据前面各层提取的特征执行任务分类。虽然卷积层和池化层都倾向于使用ReLU函数,但全连接层使用Softmax激活函数进行分类,产生从0到1的概率。
资料来源:ResearchGate
三、CNN和计算机视觉
由于其在图像识别任务中的强大功能,CNN 在计算机视觉相关的许多领域都非常有效。
计算机视觉是人工智能的一个领域,它使计算机能够从数字图像、视频和其他视觉输入中提取信息。如今,计算机视觉的一些常见应用可以在多个行业中看到,包括:
• 社交媒体: Google、Meta和Apple使用这些系统来识别照片中的人物,从而更轻松地组织相册和标记朋友。
• 医疗保健:计算机视觉模型已用于帮助医生识别患者的癌性肿瘤以及其他病症。
• 农业:配备摄像头的无人机可以监测大片农田的健康状况,以确定需要更多水或肥料的区域。
• 安全:监控系统可以实时检测异常和可疑活动。
• 金融:计算机视觉模型可用于识别烛台图中的相关模式以预测价格变动。
• 汽车:计算机视觉是自动驾驶汽车研究的重要组成部分。
四、本文
如今,有几种预训练的CNN 可用于许多任务。ResNet、VGG16、InceptionV3以及许多其他模型在我们目前跨行业执行的大多数计算机视觉任务中都非常高效。
然而,在本文中,我想探索从头开始构建一个简单但有效的卷积神经网络的过程。对于这个任务,我将使用Keras帮助我们构建一个神经网络,可以通过图像准确识别植物中的疾病。
我将使用植物病害识别数据集,其中包含 1,530 张图像,分为训练集、测试集和验证集。这些图像被标记为“健康”、“锈色”和“粉状”来描述植物的状况。
简而言之,每个类的含义如下:
• 锈病:这些是由柄锈菌引起的植物病害,会导致植物严重畸形。
• 白粉病:白粉病是由白粉菌属真菌引起的,通过降低作物产量对农业和园艺业构成威胁。
• 健康:当然,这些植物是没有疾病的。
五、探索数据
在构建我们的卷积神经网络之前,对我们手头的数据进行简短而有效的分析会很有帮助。让我们首先加载每组的目录。
# Loading training, testing, and validation directories
train_dir = '/kaggle/input/plant-disease-recognition-dataset/Train/Train'
test_dir = '/kaggle/input/plant-disease-recognition-dataset/Test/Test'
val_dir = '/kaggle/input/plant-disease-recognition-dataset/Validation/Validation'我们还可以计算每个子文件夹内的文件数,以计算用于训练和测试的数据总数,并测量类别不平衡的程度。
* * * * * Number of files in each folder * * * * *
Train/Healthy: 458
Train/Powdery: 430
Train/Rust: 434
Total: 1322
--------------------------------------------------------------------------------
Test/Healthy: 50
Test/Powdery: 50
Test/Rust: 50
Total: 150
--------------------------------------------------------------------------------
Validation/Healthy: 20
Validation/Powdery: 20
Validation/Rust: 20
Total: 60
-------------------------------------------------------------------------------- 我们的目录中共有1,322 个文件Train,并且类之间没有大的不平衡。它们之间的微小变化是可以的,并且诸如准确性之类的简单指标可能足以衡量性能。
对于测试集,我们总共有150 张图像,而验证集总共由60 张图像组成。两组都具有完美的类别平衡。
卷积神经网络要求我们输入的所有图像都有固定的大小。这意味着数据集中的每个图像必须具有相同的大小,可以是 128×128128×128、224×224224×224 等等。
我们还可以检查我们的数据是否满足这个要求,或者在建模之前是否有必要在这方面进行一些预处理。
Found 8 unique image dimensions: {(4032, 3024),
(4000, 2672), (4000, 3000), (5184, 3456), (2592, 1728),
(3901, 2607), (4608, 3456), (2421, 2279)}我们的数据集有 8 个不同的维度。在下一个单元格中,我将检查这些维度在数据中的分布。
Dimension (4000, 2672): 1130 images
Dimension (4000, 3000): 88 images
Dimension (2421, 2279): 1 images
Dimension (2592, 1728): 127 images
Dimension (4608, 3456): 72 images
Dimension (5184, 3456): 97 images
Dimension (4032, 3024): 16 images
Dimension (3901, 2607): 1 images看起来大多数图像的尺寸为4000×2672,这是一个矩形。我们可以得出结论,由于维度的差异,我们需要对数据进行一些预处理。
首先,我们将调整图像的大小,使它们具有相同的形状。然后,我们将输入从矩形转换为正方形。
另一个重要的考虑因素是验证图像的像素值范围。在这种情况下,所有图像的像素值应介于0到255之间。这种一致性简化了预处理步骤,因为我们经常将图像中的像素值标准化为 0 到 1 的范围。
- Not all images are of data type uint8
- All images have pixel values ranging from 0 to 255尽管并非所有图像都具有相同的数据类型,uint8但一旦我们将图像加载到数据集中,就很容易保证它们具有相同的数据类型。不过,我们确认所有图像的像素值范围都在 0 到 255 之间,这是个好消息。
在继续进行预处理步骤之前,让我们绘制每个类别的一些图像,看看它们是什么样子的。


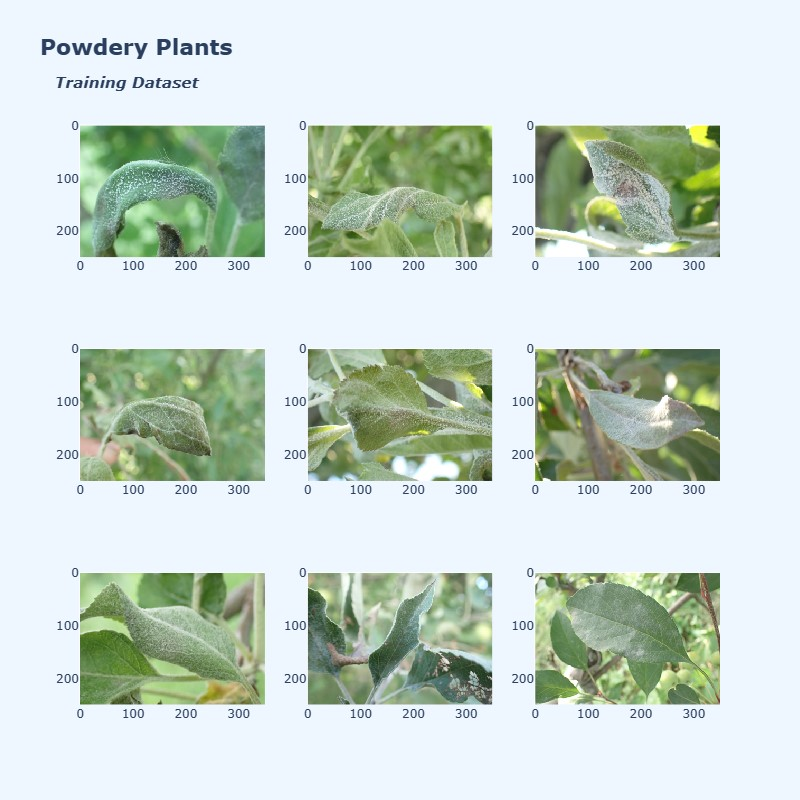
六、预处理
对于熟悉表格数据的人来说,预处理可能是处理神经网络和非结构化数据最令人畏惧的步骤之一。
通过使用 TensorFlow 可以相当轻松地完成此任务image_dataset_from_directory,它从目录中加载图像作为TensorFlow 数据集。可以对生成的数据集进行操作以进行批处理、洗牌、增强和其他几个预处理步骤。
我建议您查看此链接以获取有关该功能的更多信息image_dataset_from_directory。
# Creating a Dataset for the Training data
train = tf.keras.utils.image_dataset_from_directory(
train_dir, # Directory where the Training images are located
labels = 'inferred', # Classes will be inferred according to the structure of the directory
label_mode = 'categorical',
class_names = ['Healthy', 'Powdery', 'Rust'],
batch_size = 16, # Number of processed samples before updating the model's weights
image_size = (256, 256), # Defining a fixed dimension for all images
shuffle = True, # Shuffling data
seed = seed, # Random seed for shuffling and transformations
validation_split = 0, # We don't need to create a validation set from the training set
crop_to_aspect_ratio = True # Resize images without aspect ratio distortion
)Found 1322 files belonging to 3 classes.# Creating a dataset for the Test data
test = tf.keras.utils.image_dataset_from_directory(
test_dir,
labels = 'inferred',
label_mode = 'categorical',
class_names = ['Healthy', 'Powdery', 'Rust'],
batch_size = 16,
image_size = (256, 256),
shuffle = True,
seed = seed,
validation_split = 0,
crop_to_aspect_ratio = True
)Found 150 files belonging to 3 classes.# Creating a dataset for the Test data
validation = tf.keras.utils.image_dataset_from_directory(
val_dir,
labels = 'inferred',
label_mode = 'categorical',
class_names = ['Healthy', 'Powdery', 'Rust'],
batch_size = 16,
image_size = (256, 256),
shuffle = True,
seed = seed,
validation_split = 0,
crop_to_aspect_ratio = True
)Found 60 files belonging to 3 classes.我们已成功捕获三个类中每个类的每组中的所有文件。我们还可以打印这些数据集以进一步了解它们的结构。
print('\nTraining Dataset:', train)
print('\nTesting Dataset:', test)
print('\nValidation Dataset:', validation)Training Dataset: <_BatchDataset element_spec=(
TensorSpec(shape=(None, 256, 256, 3), dtype=tf.float32, name=None),
TensorSpec(shape=(None, 3), dtype=tf.float32, name=None))>
Testing Dataset: <_BatchDataset element_spec=(
TensorSpec(shape=(None, 256, 256, 3), dtype=tf.float32, name=None),
TensorSpec(shape=(None, 3), dtype=tf.float32, name=None))>
Validation Dataset: <_BatchDataset element_spec=(
TensorSpec(shape=(None, 256, 256, 3), dtype=tf.float32, name=None),
TensorSpec(shape=(None, 3), dtype=tf.float32, name=None))>让我们更深入地探讨一下上述所有信息的含义。
• _BatchDataset:表示数据集批量返回数据。
• element_spec:描述数据集中元素的结构。
• TensorSpec(shape=(None, 256, 256, 3), dtype=tf.float32, name = None):这表示数据集中的特征(在本例中为图像)。None表示批量大小,这里为None,因为它可能会根据最后一批中的样本数量而变化;256, 256表示图像的高度和宽度;3是图像中的通道数,表示它们是 RGB 图像。最后,dtype=tf.float32告诉我们图像像素的数据类型是32位浮点。
• TensorSpec(shape=(None, 3), dtype=tf.float32, name=None):这表示我们数据集的标签/目标。这里,None指的是批量大小;3指数据集中的标签数量;whiledtype=tf.float32也是一个 32 位浮点数。
通过使用该image_dataset_from_directory函数,我们已经能够自动预处理数据的某些方面。例如,所有图像现在都具有相同的数据类型,tf.float32. 通过设置image_size = (256, 256),我们确保所有图像具有相同的尺寸,256×256256×256。
预处理的另一个重要步骤是确保图像的像素值在 0 到 1 的范围内。该image_dataset_from_directory方法已经执行了一些转换,但像素值仍然在 0 到 255 范围内。
Minimum pixel value in the Validation dataset 0.0
Maximum pixel value in the Validation dataset 255.0为了使像素值达到 0 到 1 的范围,我们可以轻松使用 Keras 的预处理层之一tf.keras.layers.Rescaling。
scaler = Rescaling(1./255) # Defining scaler values between 0 to 1
# Rescaling datasets
train = train.map(lambda x, y: (scaler(x), y))
test = test.map(lambda x, y: (scaler(x), y))
validation = validation.map(lambda x, y: (scaler(x), y))现在我们可以再次可视化验证集中的最小和最大像素值。
Minimum pixel value in the Validation dataset 0.0
Maximum pixel value in the Validation dataset 1.0七、数据增强
在处理图像数据时,通过对训练中使用的图像应用随机变换,人为地向样本引入一些多样性通常是一个很好的做法。这很好,因为它有助于让模型接触更广泛的图像并避免过度拟合。
Keras 有大约七个不同的层用于图像数据增强。这些都是:
• tf.keras.layers.RandomCrop:该层随机选择一个位置将图像裁剪为目标大小。
• tf.keras.layers.RandomFlip:该层根据mode属性随机水平和/或垂直翻转图像。
• tf.keras.layers.RandomTranslation:该层在训练期间根据fill_mode属性随机应用翻译到每个图像。
• tf.keras.layers.RandomBrightness:该层随机增加/减少输入RGB 图像的亮度。
• tf.keras.layers.RandomRotation:该层在训练期间随机旋转图像,并根据fill_mode属性填充空白空间。
• tf.keras.layers.RandomZoom:该层在训练期间独立地随机放大或缩小每个图像的每个轴。
• tf.keras.layers.RandomContrast:该层在训练期间独立地在每个图像的每个轴上进出训练期间通过随机因子随机调整对比度。
对于此任务,我将应用RandomRotation、RandomContrast、 以及RandomBrightness我们的图像。
# Creating data augmentation pipeline
augmentation = tf.keras.Sequential(
[
tf.keras.layers.RandomRotation(
factor = (-.25, .3),
fill_mode = 'reflect',
interpolation = 'bilinear',
seed = seed),
tf.keras.layers.RandomBrightness(
factor = (-.45, .45),
value_range = (0.0, 1.0),
seed = seed),
tf.keras.layers.RandomContrast(
factor = (.5),
seed = seed)
]
)我们还可以使用一个input_shape示例来构建上面的管道,并在下面绘制它来说明它的外观。

数据增强管道的架构
八、构建卷积神经网络
为了使用 Keras 构建卷积神经网络,我们将使用该类Sequential。这个类允许我们构建线性的层堆栈,这对于创建神经网络至关重要。
除了我们之前探讨过的卷积层、池化层和全连接层之外,我还将向网络添加以下层:
• BatchNormalization:该层应用一种变换,使平均输出保持接近 00,标准差接近 11。它对其输入进行归一化,对于帮助收敛和泛化非常重要。
• Dropout:该层在训练期间随机将一部分输入单元设置为00,这有助于防止过度拟合。
• Flatten:该层将多维张量转换为一维张量。它在从特征学习部分(卷积层和池化层)过渡到全连接层时使用。
我计划使用不同的内核大小,3×33×3 和 5×55×5。这可能允许网络捕获多个尺度的特征。
随着流程的推进和内核数量的增加,我也会逐渐提高退出率。
话虽如此,让我们继续构建我们的卷积网络。
# Initiating model on GPU
with strategy.scope():
model = Sequential()
model.add(augmentation) # Adding data augmentation pipeline to the model
# Feature Learning Layers
model.add(Conv2D(32, # Number of filters/Kernels
(3,3), # Size of kernels (3x3 matrix)
strides = 1, # Step size for sliding the kernel across the input (1 pixel at a time).
padding = 'same', # 'Same' ensures that the output feature map has the same dimensions as the input by padding zeros around the input.
input_shape = (256,256,3) # Input image shape
))
model.add(Activation('relu'))# Activation function
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same'))
model.add(Dropout(0.2))
model.add(Conv2D(64, (5,5), padding = 'same'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same'))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3,3), padding = 'same'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same'))
model.add(Dropout(0.3))
model.add(Conv2D(256, (5,5), padding = 'same'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same'))
model.add(Dropout(0.3))
model.add(Conv2D(512, (3,3), padding = 'same'))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same'))
model.add(Dropout(0.3))
# Flattening tensors
model.add(Flatten())
# Fully-Connected Layers
model.add(Dense(2048))
model.add(Activation('relu'))
model.add(Dropout(0.5))
# Output Layer
model.add(Dense(3, activation = 'softmax')) # Classification layer 通过使用 Keras 的compile方法,我们可以准备神经网络进行训练。该方法有几个参数,我们这里重点关注的是:
• 优化器:在此参数中,我们定义调整权重更新的算法。这是一个重要的参数,因为选择正确的优化器对于加速收敛至关重要。我们将使用RMSprop,这是我在运行测试期间发现的最好的优化器。
• 损失:这是我们在训练期间试图最小化的损失函数。在本例中,我们使用categorical_crossentropy,这对于具有两个以上类别的分类任务来说是一个不错的选择。
• 指标:此参数定义将用于评估训练和验证期间性能的指标。由于我们的数据并不是严重不平衡,因此我们可以使用accuracy它,这是一个非常简单的指标,由以下公式给出:

# Compiling model
model.compile(optimizer = tf.keras.optimizers.RMSprop(0.0001), # 1e-4
loss = 'categorical_crossentropy', # Ideal for multiclass tasks
metrics = ['accuracy']) # Evaluation metric编译模型后,我将定义一个Early Stopping和一个Model Checkpoint。
提前停止的目的是当某个指标在一段时间内停止改善时中断训练过程。在这种情况下,我将配置EarlyStopping方法来监控测试集的准确性,如果 5 个 epoch 后没有任何改进,则停止训练过程。
模型检查点将确保只保存最佳权重,并且我们还将根据测试集中模型的准确性定义最佳权重。
# Defining an Early Stopping and Model Checkpoints
early_stopping = EarlyStopping(monitor = 'val_accuracy',
patience = 5, mode = 'max',
restore_best_weights = True)
checkpoint = ModelCheckpoint('best_model.h5',
monitor = 'val_accuracy',
save_best_only = True)>我们现在可以用来model.fit()启动培训和测试过程。
<span style="background-color:#f9f9f9"><span style="color:#242424">Epoch 1/50
83/83 [================================] - 82s 760ms/步 - 损失:6.5686 - 准确度:0.5182 - val_loss:3.1508 - val_accuracy:0.3333
Epoch 2/50
83/83 [================================] - 69s 768ms/步 - 损失:3.0173 - 准确度:0.5908 - val_loss:8.8087 - val_accuracy:0.3333
Epoch 3/50
83/83 [====================== ========] - 70s 774ms/步 - 损失:2.1228 - 准确度:0.6082 - val_loss:4.1579 - val_accuracy:0.3733
Epoch 4/50
83/83 [============ ==================] - 67s 727ms/步 - 损失:1.3750 - 准确度:0.6460 - val_loss:6.5757 - val_accuracy:0.3333
Epoch 5/50
83/83 [== ============================] - 67s 744ms/步 - 损失:1.1113 - 准确度:0.6838 - val_loss:3.7178 - val_accuracy:0.4733
Epoch 6/50
83/83 [================================] - 68s 746ms/step - 损失:0.8958 - 准确度:0.7421 - val_loss:5.7915 - val_accuracy:0.4467
Epoch 7/50
83/83 [================================] - 70s 765ms/步 - 损失:0.7605 - 准确度:0.7716 - val_loss:3.9076 - val_accuracy:0.6733
Epoch 8/50
83/83 [====================== ========] - 72s 792ms/步 - 损失:0.6549 - 准确度:0.7988 - val_loss:2.6928 - val_accuracy:0.7867
Epoch 9/50
83/83 [============ ==================] - 72s 794ms/步 - 损失:0.6207 - 准确度:0.8404 - val_loss:0.8642 - val_accuracy:0.8800
Epoch 10/50
83/83 [== ============================] - 73s 803ms/步 - 损失:0.5761 - 准确度:0.8593 - val_loss:1.0055 - val_accuracy:0.9000
Epoch 11/50
83/83 [================================] - 73s 800ms/步 - 损失:0.5478 - 准确度:0.8480 - val_loss:0.6780 - val_accuracy:0.9133
Epoch 12/50
83/83 [================================] - 68s 749ms/步 - 损失:0.4660 - 精度:0.8850 - val_loss:1.3640 - val_accuracy:0.8733
Epoch 13/50
83/83 [====================== ========] - 68s 744ms/步 - 损失:0.4503 - 准确度:0.8865 - val_loss:0.7057 - val_accuracy:0.9200
Epoch 14/50
83/83 [============ ==================] - 69s 766ms/步 - 损失:0.4796 - 准确度:0.8684 - val_loss:0.5319 - val_accuracy:0.9267
Epoch 15/50
83/83 [== ============================] - 69s 757ms/步 - 损失:0.4338 - 准确度:0.8956 - val_loss:1.1171 - val_accuracy:0.8733
Epoch 16/50
83/83 [================================] - 69s 763ms/步 - 损失:0.3859 - 准确度:0.9138 - val_loss:0.6008 - val_accuracy:0.9200
Epoch 17/50
83/83 [================================] - 71s 781ms/步 - 损失:0.3487 - 准确度:0.9153 - val_loss:0.6137 - val_accuracy:0.9400
Epoch 18/50
83/83 [================================] - 68s 747ms/步 - 损失:0.2876 - 准确度:0.9206 - val_loss :0.7538 - val_accuracy:0.9267
Epoch 19/50
83/83 [================================] - 68s 754ms/步- 损失:0.3202 - 准确度:0.9304 - val_loss:1.6988 - val_accuracy:0.8333
Epoch 20/50
83/83 [============================ ====] - 70s 772ms/步 - 损失:0.3956 - 准确度:0.9085 - val_loss:0.5439 - val_accuracy:0.9533
Epoch 21/50
83/83 [================ ==============] - 65s 708ms/步 - 损失:0.2890 - 准确度:0.9244 - val_loss:0.5971 - val_accuracy:0.9467
Epoch 22/50
83/83 [====== ========================] - 65s 716ms/步 - 损失:0.3251 - 准确度:0.9160 - val_loss:0.6507 - val_accuracy:0.9600
Epoch 23/50
83/83 [================================] - 70s 762ms/步 - 损失:0.2763 - 准确度:0.9349 - val_loss :0.6323 - val_accuracy:0.9400
Epoch 24/50
83/83 [================================] - 69s 760ms/步- 损失:0.3304 - 准确度:0.9145 - val_loss:1.0590 - val_accuracy:0.9133
Epoch 25/50
83/83 [============================ ====] - 69s 763ms/步 - 损失:0.2737 - 准确度:0.9372 - val_loss:0.9529 - val_accuracy:0.9200
Epoch 26/50
83/83 [================ ==============] - 69s 769ms/步 - 损失:0.2629 - 准确度:0.9274 - val_loss:0.8064 - val_accuracy:0.9267
Epoch 27/50
83/83 [====== ========================] - 68s 754ms/步 - 损失:0.2416 - 准确度:0.9349 - val_loss:0.5537 - val_accuracy:0.9600</span></span>测试集的最高准确率在第 22 个 epoch 时达到了 0.9600,即 96%,此后就没有提高。
有了这个history对象,我们可以绘制两个线图,显示两个集合在历元内的损失函数和准确性。
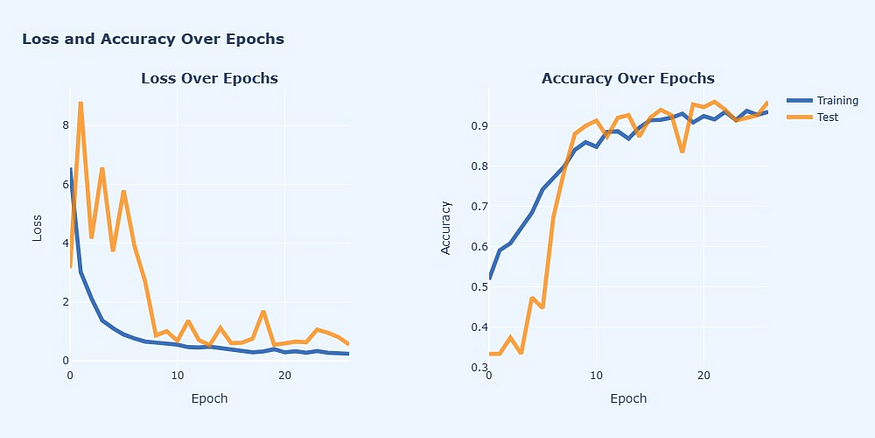
两组的历元损失和准确度
可以看到,训练集的损失在历元内不断减少,而其准确性却在增加。发生这种情况是因为,在每个时期,模型开始越来越意识到训练集的模式和特殊性。
然而,对于测试集,这个过程要慢一些。总体而言,测试集的最低损失发生在第 14 个时期,为 0.5319,而准确率在第 22 个时期达到峰值,为 0.9600。
现在我们的模型已经构建、训练和测试,我们还可以绘制其架构和摘要以更好地理解它。

我们构建的 CNN 架构
在图像中,可以可视化卷积神经网络的顺序过程。首先,我们有一个带有ReLU激活函数的 2D 卷积层,然后是 BatchNormalization 层,然后是 MaxPooling 2D 层。最后,我们有一个 Dropout Layer 来避免过度拟合。同样的模式重复几次,直到我们到达扁平层,该层将特征学习过程的输出连接到密集层以完成最终的分类任务。
使用model.summary(),我们可以提取神经网络上的一些额外信息。
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (None, 256, 256, 3) 0
conv2d (Conv2D) (None, 256, 256, 32) 896
activation (Activation) (None, 256, 256, 32) 0
batch_normalization (BatchN (None, 256, 256, 32) 128
ormalization)
max_pooling2d (MaxPooling2D (None, 128, 128, 32) 0
)
dropout (Dropout) (None, 128, 128, 32) 0
conv2d_1 (Conv2D) (None, 128, 128, 64) 51264
activation_1 (Activation) (None, 128, 128, 64) 0
batch_normalization_1 (Batc (None, 128, 128, 64) 256
hNormalization)
max_pooling2d_1 (MaxPooling (None, 64, 64, 64) 0
2D)
dropout_1 (Dropout) (None, 64, 64, 64) 0
conv2d_2 (Conv2D) (None, 64, 64, 128) 73856
activation_2 (Activation) (None, 64, 64, 128) 0
batch_normalization_2 (Batc (None, 64, 64, 128) 512
hNormalization)
max_pooling2d_2 (MaxPooling (None, 32, 32, 128) 0
2D)
dropout_2 (Dropout) (None, 32, 32, 128) 0
conv2d_3 (Conv2D) (None, 32, 32, 256) 819456
activation_3 (Activation) (None, 32, 32, 256) 0
batch_normalization_3 (Batc (None, 32, 32, 256) 1024
hNormalization)
max_pooling2d_3 (MaxPooling (None, 16, 16, 256) 0
2D)
dropout_3 (Dropout) (None, 16, 16, 256) 0
conv2d_4 (Conv2D) (None, 16, 16, 512) 1180160
activation_4 (Activation) (None, 16, 16, 512) 0
batch_normalization_4 (Batc (None, 16, 16, 512) 2048
hNormalization)
max_pooling2d_4 (MaxPooling (None, 8, 8, 512) 0
2D)
dropout_4 (Dropout) (None, 8, 8, 512) 0
flatten (Flatten) (None, 32768) 0
dense (Dense) (None, 2048) 67110912
activation_5 (Activation) (None, 2048) 0
dropout_5 (Dropout) (None, 2048) 0
dense_1 (Dense) (None, 3) 6147
=================================================================
Total params: 69,246,659
Trainable params: 69,244,675
Non-trainable params: 1,984
_________________________________________________________________ 摘要显示每层的输出形状以及参数数量。例如,我们可以清楚地看到,第一层的输出形状是(None, 256,256,3)256,256表示高度和宽度,而3表示 RGB 颜色。然而,在最后一个密集层中,输出形状为(None, 3),其中3表示用于分类的三个类别。
我们还可以看到该模型有超过 6900 万个参数,其中 99.99% 是可训练的。不可训练的参数是来自 BatchNormalization 层的参数。
九、验证性能
完成训练和测试阶段后,我们可以继续在验证集上验证我们的模型。为了加载训练期间达到的最佳权重,我们只需使用该load_weights方法。ModelCheckpoint当我们设置 时,这些权重将以我们在配置期间指定的相同名称保存ModelCheckpoint('best_model.h5')。
# Loading best weights
model.load_weights('best_model.h5')preds = model.predict(validation) # Running model on the validation dataset
val_loss, val_acc = model.evaluate(validation) # Obtaining Loss and Accuracy on the val dataset
print('\nValidation Loss: ', val_loss)
print('\nValidation Accuracy: ', np.round(val_acc * 100), '%')4/4 [==============================] - 3s 108ms/step
4/4 [==============================] - 3s 14ms/step - loss: 0.7377 - accuracy: 0.9667
Validation Loss: 0.7376963496208191
Validation Accuracy: 97.0 %的输出model.predict()由每个类别的概率组成,同时model.evaluate()返回损失和准确度值。
很明显,该模型正确预测了验证集中97%的图像标签。
我将从验证测试中加载一些图像并单独对它们运行预测,这样我们就可以看到模型如何根据每张图片执行。
Picture of a Powdery Plant:
1/1 [==============================] - 0s 283ms/step
Predicted Class: Powdery
Confidence Score: 0.9999980926513672该模型大约 99.9% 的置信度认为图片中的植物属于粉状植物,这是正确的。
Picture of a Rust Plant:
1/1 [==============================] - 0s 71ms/step
Predicted Class: Rust
Confidence Score: 1.0该模型 100% 确定图中的植物属于Rust类,这也是正确的。
Picture of a Healthy Plant:
1/1 [==============================] - 0s 64ms/step
Predicted Class: Healthy
Confidence Score: 1.0模型 100% 确定图中的植物属于Healthy类,这也是正确的。
在对其他图片进行多次测试后,我可以确定当前模型在对所有三个类别进行分类方面表现得相当好。
要保存当前权重,以便您可以部署此模型或稍后继续使用它,您可以简单地使用 Keras 的.save()方法。这会将您的模型保存为 HDF5 文件。
model.save('plant_disease_classifier.h5') # Saving model十、结论
在本文中,我们探讨了卷积神经网络的基础知识。我们深入研究了主要层(卷积层、池化层等)、激活函数以及许多其他处理图像数据和 CNN 进行图像分类的技术。
尽管现在的许多任务都可以使用预先训练的模型来高效完成,并且可以通过 TensorFlow Hub 和 HuggingFace 等平台轻松访问这些模型,但仍然有必要了解卷积神经网络中每一层的作用以及它们如何发挥作用。彼此互动。这就是为什么本文旨在引导您完成从头开始构建 CNN 的过程,并且我计划为其他深度学习任务和架构带来更多这样的笔记本。
我们的模型在预测验证数据集标签时的准确率达到了 97.0%,这是一个很好的性能,并且它能够识别数据集中所有类的相关模式。
我希望这篇文章可以为那些刚刚开始探索 ConvNets 的人提供一个介绍,甚至帮助退伍军人完善他们的一些基础知识。请随意复制此笔记本并根据需要进行编辑,特别是尝试自己的改进以获得更高的性能和测试。