前言
在计算机科学的世界中,数据结构是构建强大和高效算法的基石。Python作为一门广泛应用的编程语言,以其丰富的数据结构模块为程序员提供了强大的工具。本文旨在深入研究Python的collections和heapq模块,通过更丰富的示例和详细的解释,让读者对这两个模块的使用和原理有更深刻的理解。
文章目录
- 前言
- 一. `collections`模块:数据结构的瑞士军刀
- 1.1 `deque`:双端队列
- 1.1.1 操作示例:插入、删除、迭代
- 1.1.2 高效性能:与列表比较
- 1.1.3 应用场景:广度优先搜索(BFS)等
- 1.2 `Counter`:计数器
- 1.2.1 统计频率:文本处理、数据分析
- 1.2.2 更新计数器:可迭代对象的应用
- 1.2.3 实用技巧:找出最常见的元素
- 1.3 `OrderedDict`:有序字典
- 1.3.1 保持插入顺序:操作演示
- 1.3.2 移除最后/最前元素:`popitem`方法
- 1.3.3 用途:记录操作历史等
- 1.4 `defaultdict`:默认值字典
- 1.4.1 默认工厂函数:`int`、`list`、`lambda`
- 1.4.2 键不存在时的处理:自动返回默认值
- 1.4.3 适用场景:缺失键的字典操作
- 1.5 `namedtuple`:命名元组
- 1.5.1 字段化元组:定义和使用
- 1.5.2 字段访问:代替索引
- 1.5.3 实际应用:简单数据对象
- 二. `heapq`模块:优先队列与排序的利器
- 2.1 堆的基本概念
- 2.2 `heapq`模块的使用
- 2.3 小顶堆与大顶堆实例
- 2.4 实际应用场景
- 三. 拓展阅读
- 3.1 `array`模块:紧凑数组
- 3.2 `functools`模块:高阶函数
- 3.3 `itertools`模块:迭代器工具
- 总结
一. collections模块:数据结构的瑞士军刀
1.1 deque:双端队列
deque是collections模块中提供的一种数据结构,代表了一个双端队列(double-ended queue)。它可以在两端高效地插入和删除元素,具有较好的性能。
deque支持以下主要操作:
append(x):将元素x添加到队列的右侧(末尾)。appendleft(x):将元素x添加到队列的左侧(开头)。pop():从队列的右侧(末尾)弹出并返回一个元素。popleft():从队列的左侧(开头)弹出并返回一个元素。extend(iterable):在队列的右侧(末尾)追加可迭代对象中的所有元素。extendleft(iterable):在队列的左侧(开头)追加可迭代对象中的所有元素。rotate(n):向右循环移动队列中的元素,若n>0,则右侧的n个元素将移动到左侧;若n<0,则左侧的abs(n)个元素将移动到右侧。
1.1.1 操作示例:插入、删除、迭代
from collections import deque
# 创建一个双端队列
queue = deque()
# 添加元素到队列的末尾
queue.append(1)
queue.append(2)
# 从队列的开头弹出元素
item = queue.popleft()
print(item) # 输出: 1
1.1.2 高效性能:与列表比较
# 对比使用列表和deque进行频繁插入和删除操作的性能差异
from collections import deque
import timeit
# 使用列表进行插入和删除
def list_operations():
my_list = []
for i in range(10000):
my_list.append(i)
for _ in range(10000):
my_list.pop(0)
# 使用deque进行插入和删除
def deque_operations():
my_deque = deque()
for i in range(10000):
my_deque.append(i)
for _ in range(10000):
my_deque.popleft()
# 计算列表操作时间
list_time = timeit.timeit(list_operations, number=1000)
# 计算deque操作时间
deque_time = timeit.timeit(deque_operations, number=1000)
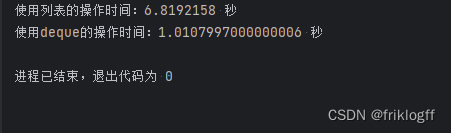
print(f"使用列表的操作时间:{list_time} 秒")
print(f"使用deque的操作时间:{deque_time} 秒")
1.1.3 应用场景:广度优先搜索(BFS)等
# 演示在广度优先搜索算法中使用deque的场景
from collections import deque
# 定义图的邻接表表示
graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': ['F', 'G'],
'D': [],
'E': [],
'F': [],
'G': []
}
def bfs(graph, start):
visited = set()
queue = deque([start])
while queue:
node = queue.popleft()
if node not in visited:
print(node, end=' ')
visited.add(node)
queue.extend(set(graph[node]) - visited)
# 从顶点'A'开始进行广度优先搜索
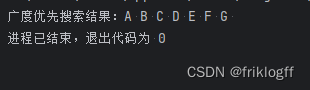
print("广度优先搜索结果:", end='')
bfs(graph, 'A')
以上代码演示了deque相对于列表在频繁插入和删除操作中的性能优势,并展示了在广度优先搜索算法中使用deque处理状态空间遍历的场景。deque在这些场景中表现出色,是一个高效的数据结构选择。
接下来,我们将深入探讨上述内容,逐一展开具体的细节和代码示例。
1.2 Counter:计数器
Counter是collections模块中提供的一种数据结构,用于计数可哈希对象的出现次数。它可以方便地统计元素的频率。
Counter是一个字典(dict)的子类,其中元素作为键,它们的出现次数作为值。它支持基本的字典操作,例如添加元素、删除元素和迭代访问等。
Counter支持以下主要操作:
update(iterable):从可迭代对象中更新计数器,将每个元素视为一个计数项。elements():返回一个迭代器,按照计数的重复次数重复每个元素。most_common(n=None):返回一个列表,包含计数最高的前n个元素及其对应的计数,按计数从高到低排序。
1.2.1 统计频率:文本处理、数据分析
Counter是一个强大的工具,用于统计可哈希对象的出现次数。这在文本处理、数据分析等领域非常有用。以下是一个简单的示例:
from collections import Counter
# 创建计数器
counter = Counter()
# 计数元素
counter.update([1, 1, 2, 3, 3, 3])
# 获取元素出现次数
count = counter[1]
print(count) # 输出: 2
在这个例子中,我们创建了一个计数器 counter,然后使用 update 方法更新计数器的内容。最后,我们通过索引获取特定元素的出现次数。
1.2.2 更新计数器:可迭代对象的应用
Counter通过 update 方法支持从可迭代对象中更新计数。这使得处理大规模数据时变得非常方便:
from collections import Counter
# 创建计数器
counter = Counter()
# 使用update方法从可迭代对象更新计数
data = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
counter.update(data)
print(counter)
# 输出: Counter({4: 4, 3: 3, 2: 2, 1: 1})
1.2.3 实用技巧:找出最常见的元素
most_common 方法返回计数最高的前 n 个元素及其对应的计数,按计数从高到低排序。这在需要确定数据中频繁出现的元素时非常有用:
from collections import Counter
# 创建计数器
counter = Counter()
# 计数元素
counter.update([1, 1, 2, 3, 3, 3])
# 获取最常见的元素
most_common = counter.most_common(2)
print(most_common) # 输出: [(3, 3), (1, 2)]
通过这些实用技巧,Counter在处理数据频率统计时表现出色,为数据分析和处理提供了便捷的工具。
1.3 OrderedDict:有序字典
OrderedDict是collections模块中提供的一种数据结构,它是一个有序的字典(dict)。与普通字典不同,OrderedDict记住了元素插入的顺序,因此可以按照插入的顺序遍历和访问元素。
除了支持普通字典的所有操作,OrderedDict还提供以下额外的功能:
popitem(last=True):移除并返回最后一个(默认)或第一个键值对。move_to_end(key, last=True):将指定的键移动到字典的末尾(默认)或开头。clear():清空字典中的所有键值对。
1.3.1 保持插入顺序:操作演示
OrderedDict是一个有序字典,可以按照元素插入的顺序进行遍历。这在需要记住操作历史等场景非常有用:
from collections import OrderedDict
# 创建有序字典
ordered_dict = OrderedDict()
# 添加键值对
ordered_dict['a'] = 1
ordered_dict['b'] = 2
ordered_dict['c'] = 3
# 按照插入顺序遍历键值对
for key, value in ordered_dict.items():
print(key, value) # 输出: a 1, b 2, c 3
1.3.2 移除最后/最前元素:popitem方法
OrderedDict提供了 popitem 方法,可以移除并返回最后一个或第一个键值对,为字典操作提供了额外的操作灵活性:
from collections import OrderedDict
# 创建有序字典
ordered_dict = OrderedDict()
# 添加键值对
ordered_dict['a'] = 1
ordered_dict['b'] = 2
ordered_dict['c'] = 3
# 移除并返回最后一个键值对
last_item = ordered_dict.popitem(last=True)
print(last_item) # 输出: ('c', 3)
# 移除并返回第一个键值对
first_item = ordered_dict.popitem(last=False)
print(first_item) # 输出: ('a', 1)
1.3.3 用途:记录操作历史等
OrderedDict在需要保持元素顺序的情况下非常有用。它可以用于构建记录操作顺序的日志、维护缓存中最近访问的元素等场景。通过记录操作历史,我们可以更好地理解和追踪程序的执行流程。
1.4 defaultdict:默认值字典
defaultdict是collections模块中提供的一种数据结构,它是一个字典(dict)的子类,可以为字典中的键提供默认值。当访问一个不存在的键时,defaultdict会自动返回指定的默认值,而不会抛出KeyError异常。
要使用defaultdict,需要提供一个可调用对象作为默认工厂函数。这个工厂函数将在访问不存在的键时被调用,以生成默认值。常见的默认工厂函数包括int、list和lambda等。
1.4.1 默认工厂函数:int、list、lambda
defaultdict是一个带有默认值的字典,可以为字典中的键提供默认值。我们可以使用内置类型(如 int、list)或自定义函数作为默认工厂函数:
from collections import defaultdict
# 创建带有默认值的字典,默认值为0
default_dict_int = defaultdict(int)
# 创建带有默认值的字典,默认值为空列表
default_dict_list = defaultdict(list)
# 创建带有默认值的字典,自定义默认值生成规则
default_dict_lambda = defaultdict(lambda: 'default_value')
1.4.2 键不存在时的处理:自动返回默认值
defaultdict通过指定的默认工厂函数,在访问不存在的键时自动生成默认值。这样,我们可以避免在代码中频繁检查键是否存在:
from collections import defaultdict
# 创建带有默认值的字典,默认值为0
default_dict = defaultdict(int)
# 访问不存在的键,返回默认值
count = default_dict['a']
print(count) # 输出: 0
1.4.3 适用场景:缺失键的字典操作
defaultdict非常适合在处理字典中缺失键的情况下使用。它可以简化对键是否存在的检查并提供默认值,避免了频繁使用 if-else 语句的麻烦。这在处理各种数据时非常实用,特别是在数据处理流程中,当我们需要为缺失的键提供默认值时,defaultdict可以提供一种更加简洁和高效的解决方案。让我们来看一些具体的应用场景和代码示例:
from collections import defaultdict
# 1. 创建带有默认值的字典,默认值为空列表
default_dict_list = defaultdict(list)
# 2. 向字典添加数据,无需检查键是否存在
default_dict_list['fruits'].append('apple')
default_dict_list['fruits'].append('banana')
default_dict_list['vegetables'].append('carrot')
# 输出带有默认值的字典
print(default_dict_list)
# 输出: defaultdict(<class 'list'>, {'fruits': ['apple', 'banana'], 'vegetables': ['carrot']})
在这个例子中,我们创建了一个 defaultdict,其默认值为一个空列表。然后,我们向字典中添加水果和蔬菜的数据,而无需检查键是否存在。这简化了代码,并使我们能够更专注于数据操作而不是键的存在性检查。
1.5 namedtuple:命名元组
namedtuple是collections模块中提供的一种数据结构,它是一个具有字段名称的元组。与普通元组不同,namedtuple中的每个元素都可以通过字段名称进行访问和使用,而无需依赖索引。
使用namedtuple时,首先需要定义一个命名元组类,并指定字段的名称。然后可以使用该类来创建命名元组的实例。每个字段在创建实例时都可以赋值,方便地访问和操作字段值。
1.5.1 字段化元组:定义和使用
namedtuple提供了一种更具可读性的元组,通过字段名称而不是索引来访问元素。这在表示简单数据对象时非常有用:
from collections import namedtuple
# 定义第一个命名元组类
Person = namedtuple('Person', ['name', 'age'])
# 创建第一个命名元组实例
person = Person(name='Alice', age=25)
# 访问第一个命名元组实例的字段
print(person.name) # 输出: Alice
print(person.age) # 输出: 25
1.5.2 字段访问:代替索引
通过给元组的各个字段赋予名称,我们避免了依赖于位置索引的问题,提高了代码的可读性和可维护性:
from collections import namedtuple
# 定义第二个命名元组类
Point = namedtuple('Point', ['x', 'y', 'z'])
# 创建第二个命名元组实例
point = Point(x=1, y=2, z=3)
# 访问第二个命名元组实例的字段
print(point.x) # 输出: 1
print(point.y) # 输出: 2
print(point.z) # 输出: 3
1.5.3 实际应用:简单数据对象
namedtuple常用于表示简单的数据对象,例如二维坐标、日期记录等。通过字段名称,可以更清晰地表达数据的含义,提高代码的可读性:
from collections import namedtuple
# 定义日期记录的命名元组类
DateRecord = namedtuple('DateRecord', ['year', 'month', 'day'])
# 创建日期记录的命名元组实例
date = DateRecord(year=2023, month=11, day=13)
# 访问日期记录的字段
print(date.year) # 输出: 2023
print(date.month) # 输出: 11
print(date.day) # 输出: 13
通过这些例子,我们可以看到 namedtuple 如何提高代码的清晰度和可读性,特别是在表示简单数据结构时。这使得代码更易于维护和理解。
二. heapq模块:优先队列与排序的利器
heapq是Python中的一个模块,提供了对堆数据结构的支持,以及在堆上执行的一些常见操作。堆是一种特殊的二叉树结构,具有以下特点:
- 堆是一个完全二叉树,即除了最底层外,其他层都被元素填满,并且最底层从左到右填入。
- 堆中的每个节点的值大于或等于(最大堆)或小于或等于(最小堆)其子节点的值。
heapq模块提供了一系列函数来创建和操作堆:
heappush(heap, item):将元素item添加到堆heap中。heappop(heap):从堆heap中弹出并返回最小(或最大)的元素。heapify(x):将可迭代对象x转换为堆数据结构。heappushpop(heap, item):将元素item添加到堆heap中,并弹出并返回堆中的最小(或最大)元素。heapreplace(heap, item):弹出并返回堆中的最小(或最大)元素,然后将元素item添加到堆中。
2.1 堆的基本概念
-
2.1.1 完全二叉树:堆的基本结构
堆是一种完全二叉树,节点排列方式确保在插入和删除元素时保持堆的性质。# 示例:创建一个小顶堆 import heapq heap = [] heapq.heappush(heap, 5) heapq.heappush(heap, 2) heapq.heappush(heap, 10) print(heap) # 输出: [2, 5, 10] -
2.1.2 小顶堆与大顶堆:堆的种类
小顶堆:每个节点值不大于其子节点值。大顶堆:每个节点值不小于其子节点值。
# 示例:创建一个大顶堆 import heapq heap = [] for num in [5, 2, 10]: heapq.heappush(heap, -num) largest = -heapq.heappop(heap) print(largest) # 输出: 10
2.2 heapq模块的使用
-
2.2.1
heappush与heappop:插入与删除import heapq heap = [] heapq.heappush(heap, 5) heapq.heappush(heap, 2) heapq.heappush(heap, 10) min_element = heapq.heappop(heap) print(min_element) # 输出: 2 -
2.2.2
heapify函数:转换为堆import heapq x = [3, 1, 6, 4] heapq.heapify(x) print(x) # 输出: [1, 3, 6, 4] -
2.2.3
heappushpop与heapreplace:替换元素import heapq heap = [5, 7, 9, 4, 3] new_element = 6 # 替换并返回堆中的最小元素 replaced = heapq.heappushpop(heap, new_element) print(replaced) # 输出: 4 # 插入元素并返回堆中的最小元素 replaced = heapq.heapreplace(heap, new_element) print(replaced) # 输出: 5
2.3 小顶堆与大顶堆实例
-
2.3.1 操作示例:插入、弹出等
import heapq # 小顶堆示例 min_heap = [] heapq.heappush(min_heap, 5) heapq.heappush(min_heap, 2) heapq.heappush(min_heap, 10) min_element = heapq.heappop(min_heap) print(min_element) # 输出: 2 # 大顶堆示例 max_heap = [] for num in [5, 2, 10]: heapq.heappush(max_heap, -num) largest = -heapq.heappop(max_heap) print(largest) # 输出: 10 -
2.3.2 独立文件示例:
min_heap.py与max_heap.py
小顶堆和大顶堆的操作分别存储在独立的文件中,提高代码可维护性。
min_heap.py
import heapq
def main():
# 初始化小顶堆
min_heap = []
# 待插入小顶堆的元素
elements = [1, 3, 2, 5, 4]
print("小顶堆:")
for element in elements:
heapq.heappush(min_heap, element)
print(f"插入 {element} 到小顶堆:", min_heap)
# 获取小顶堆的顶部元素
min_peek = min_heap[0]
print(f"\n小顶堆顶部元素:{min_peek}")
print("\n小顶堆弹出元素:")
while min_heap:
popped_element = heapq.heappop(min_heap)
print(f"弹出元素: {popped_element},当前小顶堆:", min_heap)
if __name__ == "__main__":
main()
max_heap.py
import heapq
def main():
# 初始化大顶堆
max_heap = []
# 待插入大顶堆的元素
elements = [1, 3, 2, 5, 4]
print("大顶堆:")
for element in elements:
heapq.heappush(max_heap, -element)
print(f"插入 {-element} 到大顶堆:", [-x for x in max_heap])
# 获取大顶堆的顶部元素
max_peek = -max_heap[0]
print(f"\n大顶堆顶部元素:{max_peek}")
print("\n大顶堆弹出元素:")
while max_heap:
popped_element = -heapq.heappop(max_heap)
print(f"弹出元素: {popped_element},当前大顶堆:", [-x for x in max_heap])
if __name__ == "__main__":
main()
你可以单独运行 min_heap.py 和 max_heap.py 来观察小顶堆和大顶堆的行为。打印语句将在执行每个操作后显示堆的内容。
小顶堆和大顶堆是一种特殊的二叉堆,它们具有以下性质:
- 小顶堆:每个节点的值都不大于其子节点的值,即父节点的值小于或等于左右子节点的值。
- 大顶堆:每个节点的值都不小于其子节点的值,即父节点的值大于或等于左右子节点的值。
这里我们使用了Python的heapq模块来实现堆操作。
小顶堆的原理及操作步骤:
- 初始化一个空列表作为小顶堆:
min_heap = []。 - 使用
heappush函数将元素插入小顶堆。插入元素时,会保持堆结构的性质,即依次比较新元素与当前堆中的元素,并进行必要的交换,以保证小顶堆的性质。 - 通过访问
min_heap[0]可以获取小顶堆的最小值,也即堆顶元素。 - 使用
heappop函数弹出小顶堆的堆顶元素。弹出操作会移除堆顶元素,并且会重新调整剩余元素的顺序,使其满足小顶堆的性质。 - 可以使用
heapify函数将一个普通列表转换为小顶堆。 - 重复步骤2到5,直到小顶堆为空。
大顶堆的原理及操作步骤:
- 初始化一个空列表作为大顶堆:
max_heap = []。 - 在插入元素时,我们需要将元素的值取负值来实现大小关系的颠倒。即使用
heappush函数将-element插入大顶堆中。 - 通过访问
-max_heap[0]可以获取大顶堆的最大值,也即堆顶元素。 - 使用
heappop函数弹出大顶堆的堆顶元素时,需要再次取负值才能得到正确的值,即-heapq.heappop(max_heap)。 - 其余操作与小顶堆相同。
这样,我们就可以利用小顶堆和大顶堆进行高效的数据处理,包括插入、删除和查找等操作。
2.4 实际应用场景
-
2.4.1 优先队列:任务调度等
小顶堆常用于实现优先队列,用于任务调度等场景。import heapq class PriorityQueue: def __init__(self): self.heap = [] def push_task(self, priority, task): heapq.heappush(self.heap, (priority, task)) def pop_task(self): priority, task = heapq.heappop(self.heap) return task # 示例 priority_queue = PriorityQueue() priority_queue.push_task(2, 'Task 1') priority_queue.push_task(1, 'Task 2') priority_queue.push_task(3, 'Task 3') next_task = priority_queue.pop_task() print(next_task) # 输出: Task 2 -
2.4.2 排序算法:堆排序实现
import heapq
def heap_sort(arr):
heap = arr.copy()
heapq.heapify(heap)
sorted_arr = [heapq.heappop(heap) for _ in range(len(heap))]
return sorted_arr
# 示例
unsorted_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sorted_list = heap_sort(unsorted_list)
print(sorted_list) # 输出: [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
三. 拓展阅读
3.1 array模块:紧凑数组
-
3.1.1
array的创建与基本操作
array模块提供了一种紧凑的数组结构,可以在性能和内存占用之间找到平衡。from array import array # 创建一个双精度浮点数数组 double_array = array('d', [1.2, 3.4, 5.6]) # 访问数组元素 first_element = double_array[0] print(first_element) # 输出: 1.2 -
3.1.2 与列表的比较与应用
比较array和列表的性能特点,并介绍array在某些场景下的应用。from array import array import time # 使用列表存储一百万个双精度浮点数 list_numbers = [i * 0.1 for i in range(1000000)] # 使用数组存储一百万个双精度浮点数 array_numbers = array('d', [i * 0.1 for i in range(1000000)]) # 比较列表和数组的索引操作性能 start_time = time.time() for _ in range(100000): _ = list_numbers[500000] list_time = time.time() - start_time start_time = time.time() for _ in range(100000): _ = array_numbers[500000] array_time = time.time() - start_time print(f'列表索引操作耗时: {list_time} 秒') print(f'数组索引操作耗时: {array_time} 秒')
3.2 functools模块:高阶函数
-
3.2.1
functools.partial:部分应用函数
functools.partial允许我们部分应用函数,固定部分参数,从而派生出新的函数。from functools import partial # 定义一个简单的函数 def power(base, exponent): return base ** exponent # 使用partial固定exponent参数 square = partial(power, exponent=2) # 调用新的函数 result = square(5) print(result) # 输出: 25 -
3.2.2 使用示例:定制排序函数
演示如何使用functools.partial创建定制的排序函数,以便满足不同的排序需求。from functools import partial # 列表中的元素是字典 students = [ {'name': 'Alice', 'score': 90}, {'name': 'Bob', 'score': 85}, {'name': 'Charlie', 'score': 95} ] # 使用partial创建定制的排序函数 sort_by_score = partial(sorted, key=lambda x: x['score']) # 按分数排序学生 sorted_students = sort_by_score(students) print(sorted_students)
3.3 itertools模块:迭代器工具
-
3.3.1
count与cycle:无限迭代器
itertools.count生成无限递增的整数序列,而itertools.cycle则无限重复给定的可迭代对象。from itertools import count, cycle # 生成无限递增的整数序列 for i in count(1): print(i) if i == 5: break # 无限循环重复给定的可迭代对象 values = [1, 2, 3] for val in cycle(values): print(val) if val == 3: break -
3.3.2
zip_longest:等长迭代器
itertools.zip_longest用于将多个可迭代对象逐个组合成元组,确保结果的长度与最长的输入相等。from itertools import zip_longest # 等长迭代器 numbers = [1, 2, 3] letters = ['a', 'b'] zipped = zip_longest(numbers, letters, fillvalue=None) for item in zipped: print(item)
以上是对array、functools和itertools模块的简要介绍,包含了基本的使用和一些实际场景的示例。如有需要,可以进一步深入学习这些模块的更多功能。
总结
collections和heapq模块不仅是Python语言的标配工具,更是解决算法和数据处理难题的得力助手。通过深入学习这些模块提供的数据结构和操作,我们能够更加优雅地编写代码,提高程序的执行效率。从双端队列到堆的引入,本文将带领读者深入理解这些工具,并展示它们在实际场景中的强大应用。
希望读者通过本文的学习,能够在日常编程中更灵活地选择和使用适当的数据结构,从而提升代码的可读性和性能。




![Go,14周年[译]](https://img-blog.csdnimg.cn/img_convert/42a0b2818053eb95dedb1b1b9cee78c1.jpeg)