在这篇文章中,将介绍如何基于向量数据库,构建一个电商产品图片目录的向量相似度查询解决方案。我们将通过 Amazon SageMaker、pgvector 向量数据库扩展插件、小型语言模型助力 AI 图片搜索能力,从而在产品目录中查找到最符合条件的产品,提高查询的准确性、效率性和便利性。该方案尤其适合垂直行业使用,可覆盖电商、游戏、短视频,甚至法律、医疗、制造业、人力资源等场景。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点 这里让它成为你的技术宝库!
构建背景介绍
各行各业都在探索 AIGC 创新方法,希望通过利用生成式 AI 的巨大潜力,来增强用户体验,探索垂直行业的无限可能。
在游戏美术、电商产品设计、建筑/家装设计等行业,AIGC 正在彻底改变图片方向创作过程。通过大数据分析用户喜好和行为数据,人工智能算法可以生成独特的游戏场景和角色、服装款式和设计、家装内饰和风格,将个性化和成本效益提升到一个新的水平。且通过图像识别,对最终生成的图片进行审查,实现对结果的鉴黄鉴暴功能。
视频网站、短视频平台同样可以从 AI 能力中获益,尤其是在视频相似度搜索和推荐方面,AI 算法可以分析用户行为,并推荐与他们的兴趣点密切相关的视频内容,从而提升用户的整体观感体验,从而增加用户粘性。此外,AI 驱动的图像和视频托管服务可以提供图像去重、图像相似度搜索和文本与图像相似度搜索等功能,从而实现搜索精度和搜索体验的整体改善。
生物信息行业也是 AI 应用探索的另一领域。在分子和 DNA 序列分类相似度搜索的应用,使得 AI 在药物发现和药物研究中发挥了关键作用,大大提升了药物研发的速度。无论是识别潜在的候选药物还是 DNA 序列分析,AI 都被证明是一种宝贵的工具。
在这篇文章中,您将学习如何构建一个类似的产品目录相似度搜索解决方案。该方案主要集成 Amazon SageMaker 和亚马逊关系数据库服务(Amazon RDS)PostgreSQL,而 PostgreSQL 通过启用 pgvector 扩展插件实现了数据的向量存储能力。
Pgvector 作为 PostgreSQL 的开源扩展插件,它提供了 ML 生成式向量的存储和搜索功能。还同时支持精确识别和近似最近邻算法识别(KNN)。它的设计初衷就是用于与 PostgreSQL 的其他功能无缝集成,包括了索引和查询等。您甚至可以使用 pgvector 存储来自 Amazon Bedrock 的 ML 生成式向量分片(目前 Bedrock 还处于限量预览版阶段)。
综述,无论您属于哪个行业,无论是以上提到的电商、游戏、视频服务、生命科学,还是法律、医疗、制造业、人力资源等行业,这篇文章都将为您将来进行相似度搜索提供有价值的见解。
Vector embeddings 概述
Embeddings(向量化表示/向量嵌入)是指将文本、图像、视频或音频等对象转换成高维向量空间中的数字表示的过程。该技术是通过使用机器学习算法实现,理解数据的含义和上下文的语义关系、句法关系。您可以将生成的 Embeddings 用于各种应用程序,例如信息检索、图像分类、自然语言处理等等。
Vector embeddings 之所以变得越来越受欢迎,是因为它们能够以易于计算和扩展的方式捕捉对象之间的语义含义和相似之处。下图直观地表示了 Word Embedding(词语向量化表示)的特征形态。
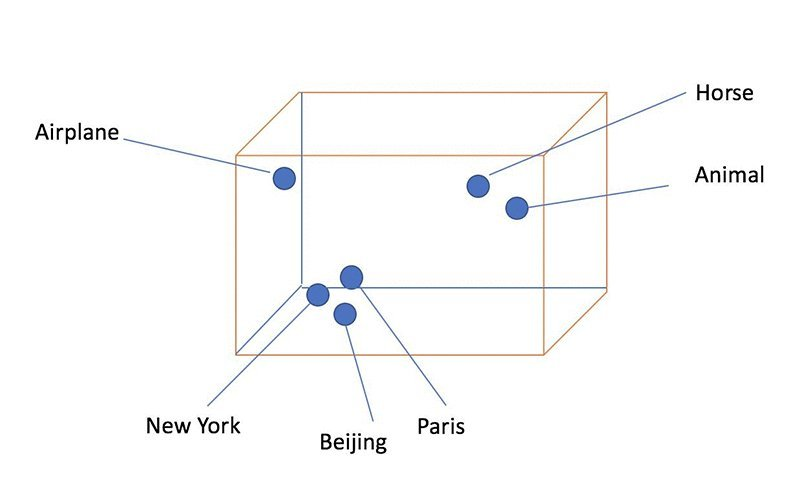
图 1 Word Embedding:语义相似的单词在 Embedding 空间中靠得很近
生成 Embeddings 后,我们可以在向量空间内执行相似度搜索。基于 Embedding 的相似度搜索能在许多行业的应用中受益,如电子商务、推荐系统和欺诈检测等。例如,系统可以识别产品或交易之间的数学相似之处,以创建相关的产品推荐,或识别潜在的欺诈活动。
使用 pgvector 实现高效的 Embedding 相似度搜索
通过使用 pgvector 扩展插件,PostgreSQL 可以有效地执行 Vector Embeddings 的相似度搜索,为企业提供快速查询的解决方案。
要为本文场景的产品目录生成 Embedding 向量化表示数据,您可以使用 Amazon SageMaker 等机器学习服务,为您轻松训练和部署机器学习模型,包括生成文本数据的 Embedding 模型。
在本文部署执行过程中,为了快速地呈现实验效果,我们使用 Hugging Face DLCs(深度学习容器) 和 Amazon SageMaker Python SDK 来创建一个实时推理节点,运行 All MiniLM-L6-v2(句子转换器模型),生成文档的 embedding 数据。使用 pgvector 扩展插件将 Vector Embeddings 存储在 RDS for PostgreSQL 数据库中。然后,我们使用 pgvector 的相似度搜索功能,在产品目录中查找最符合客户搜索查询意图的商品,并返回图片结果。
在上述过程中,pgvector 的索引功能将进一步增强搜索优化。通过对向量数据进行索引,可以加快搜索过程,并最大限度地减少识别最近的邻域对象所需的时间。我们深入研究了 pgvector 插件如何与 PostgreSQL 协同,为向量数据相似度搜索提供了一种简化而有效的解决方案。
pgvector 扩展插件的安装与使用验证
pgvector 扩展插件的安装
首先,我们创建并连接到 RDS for PostgreSQL V15.2 或以上版本的数据库。然后可以启用创建 pgvector 插件,并支持您可以在数据库中启动 vector embbeding 的存储并根据需要进行搜索(Amazon RDS for PostgreSQL 数据库自 15.2 版本起支持 pgvector 扩展插件,用户可以通过 SQL 规范语句调用 pgvector 插件)。
CREATE EXTENSION vector;
pgvector 扩展插件引入了一种名为 vector 的新数据类型。vector 数据类型在 SQL 语句中的使用如下:
SELECT typname FROM pg_type WHERE typname = 'vector';
您应该看到以下输出:
typname --------- vector (1 row)
Pgvector 扩展插件的使用验证
本文实验中,我们使用 sentence-transformers/all-MiniLM-L6-v2 模型来生成 vector embeddings 数据。它将句子和段落映射到 384 维的密集向量空间,因此我们在解决方案中使用它来表示向量大小。
代码示范:创建一个用于存储三维向量的测试表,插入一些样本数据,使用欧几里德距离(也称为 L2 距离)进行查询,然后删除测试表:
CREATE TABLE test_embeddings(product_id bigint, embeddings vector(3) ); INSERT INTO test_embeddings VALUES (1, '[1, 2, 3]'), (2, '[2, 3, 4]'), (3, '[7, 6, 8]'), (4, '[8, 6, 9]'); SELECT product_id, embeddings, embeddings <-> '[3,1,2]' AS distance FROM test_embeddings ORDER BY embeddings <-> '[3,1,2]'; DROP TABLE test_embeddings;
SELECT 语句应返回以下输出:
product_id | embeddings | distance ------------+------------+------------------- 1 | [1,2,3] | 2.449489742783178 2 | [2,3,4] | 3 3 | [7,6,8] | 8.774964387392123 4 | [8,6,9] | 9.9498743710662 (4 rows)
有关更多详细信息,请参阅 GitHub repo。
电商产品图片相似度搜索方案
基于上述如何使用 pgvector 构建向量相似度搜索的演示,接下来开始使用 pgvector 为电商的产品目录,构建搜索解决方案。我们将构建一个搜索系统,让买家通过描述来查找类似的商品。
接下来将逐步演示如何执行产品相似度查询。我们将在 SageMaker 实例上使用 Hugging Face 预训练的模型,为产品描述生成 vector embeddings 数据;使用 Amazon RDS for PostgreSQL 并集成 pgvector 扩展插件,对我们的 vector embeddings 数据进行存储和相似度搜索。
方案步骤
- 在 Amazon SageMaker notebook 实例中,创建 Jupyter notebook,由 SageMaker 负责管理创建实例和相关资源。
- 部署预先训练的 Hugging Face sentence transformer model (句子转换器模型)到 SageMaker,以便下一步利用实时推理和数据转换,生成物品描述的 embeddings 数据。
- 使用 Amazon SageMaker 实时推理为产品目录描述生成 Embeddings 数据。
- 使用 Amazon RDS for PostgreSQL 来存储原始产品描述和对应的文本 Embeddings。
- 使用 Amazon SageMaker 实时推理将需要查询的文本描述也生成 Embedding 数据。
- 使用 Amazon RDS for PostgreSQL 的 pgvector 插件,执行相似度搜索。
方案架构图
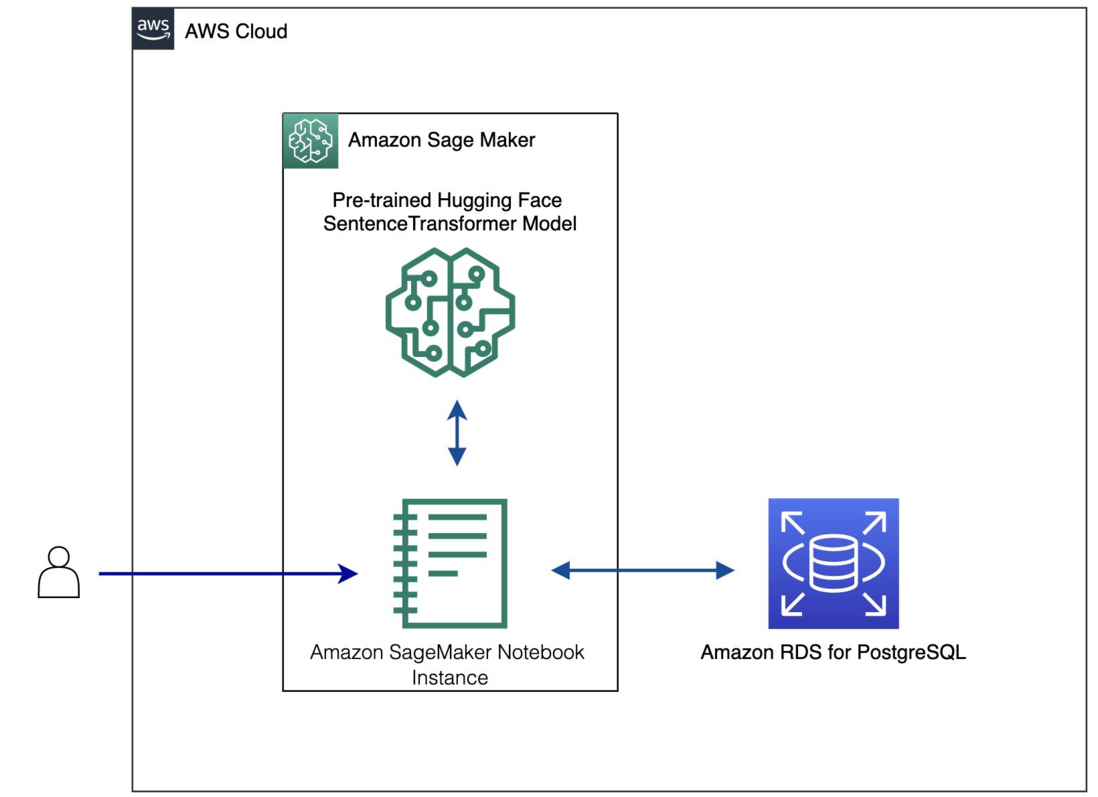
前置条件
若要完成本 Demo,您需要拥有一个亚马逊云科技账户,并具有相应的 Amazon IAM 权限,以启动提供的 Amazon CloudFormation 模板。此解决方案将产生一定成本,请参阅亚马逊云科技定价页面了解更多信息。
解决方案部署
我们将使用 CloudFormation Stack 来部署这个解决方案。该堆栈会自动在您的账户内创建所有必要的资源,包括以下资源:
- 网络组件,包括 VPC 、子网、路由,安全组等资源。
- 一个 SageMaker Notebook 实例,用于在 Jupyter Notebook 中运行 Python 代码。
- 与 Notebook 实例关联的 IAM 角色。
- 一个 RDS for PostgreSQL 实例,用于存储和查询商品目录的 Embedding 数据。
解决方案部署开始,请完成以下步骤:
- 使用您的 IAM 用户名和密码登录亚马逊云科技管理控制台。
- 选择 “启动堆栈 Launch Stack ”,并在新的浏览器标签页中打开。
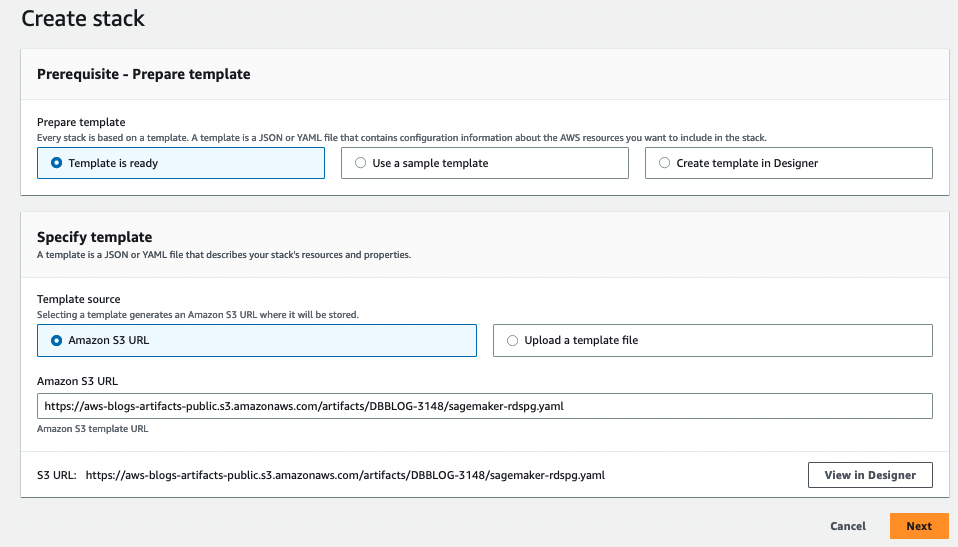
- 选择默认值,点击“Next”,在下一页选中复选框以确认 IAM 资源的创建,选择“Create Stack”。
- 等待堆栈创建完成,状态 CREATE_COMPLETE。您可以在 “Event” 选项卡上检查堆栈创建过程中的状态。
- 在“Outputs”选项卡上,打开 NotebookInstanceUrl。此链接将打开 Jupyter Notebook,来完成剩下的部分。
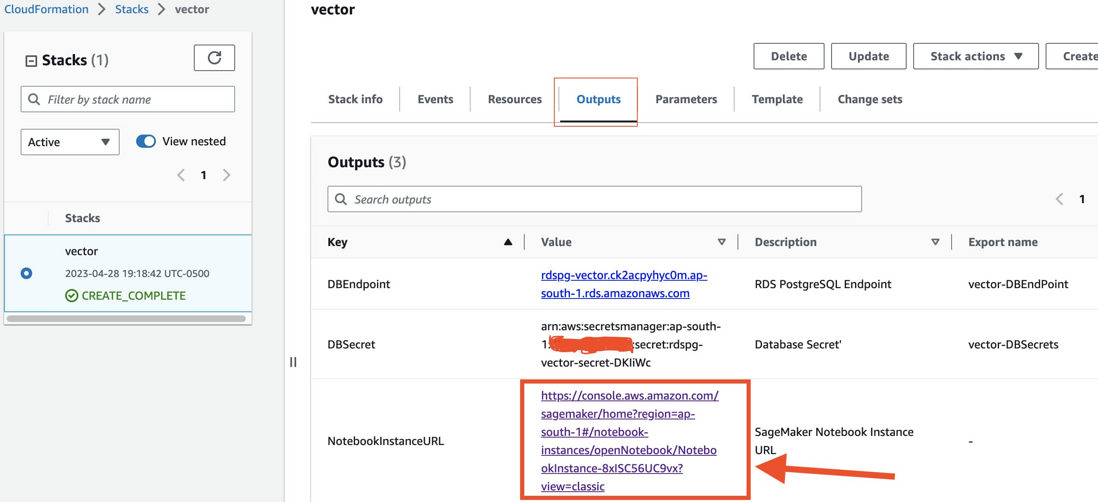
- 打开笔记本 rdspg-vector.ipynb,然后按顺序逐个在所有单元格中运行代码。
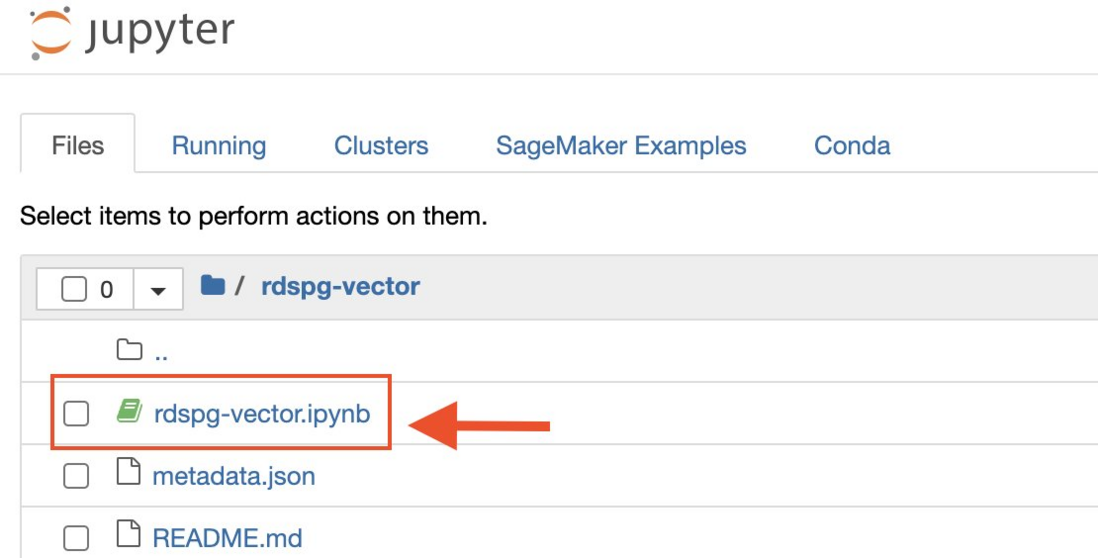
在以下部分中,我们将检查 Jupyter Notebook 中几个重要单元格的部分代码,以演示解决方案。
演示数据获取
我们使用 Zalando Research FEIDEGGER 数据,该数据由 8,732 张高分辨率的时尚图片和五张德语文字注释组成,每张都是由单独的用户生成的。我们已经使用 Amazon Translate 将每条着装描述从德语翻译成英语。代码如下所示:
import urllib.request
import os
import json
import boto3
from multiprocessing import cpu_count
from tqdm.contrib.concurrent import process_map
filename = 'metadata.json'
def download_metadata(url):
if not os.path.exists(filename):
urllib.request.urlretrieve(url, filename)
## The German text has been translated into English and the resulting translation has been stored in this repository for convenience.
download_metadata('https://raw.githubusercontent.com/aws-samples/rds-postgresql-pgvector/master/data/FEIDEGGER_release_1.2.json')
with open(filename) as json_file:
results = json.load(json_file)
results[0]
SageMaker 模型托管与向量化表示数据生成
在本节中,我们将预先训练的 Hugging Face all-MiniLM-L6-v2 句子转换器模型托管到 SageMaker 中,并为我们的产品目录生成 384 维向量化表示数据(Embedding)。步骤如下:
- 定义 SageMaker 的执行角色,工作 S3 桶和建立 SageMaker。
import sagemaker
import boto3
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
- 指定模型配置参数,部署模型推理节点。
from sagemaker.huggingface.model import HuggingFaceModel
# Hub Model configuration. <https://huggingface.co/models>
hub = {
'HF_MODEL_ID': 'sentence-transformers/all-MiniLM-L6-v2',
'HF_TASK': 'feature-extraction'
}
# Deploy Hugging Face Model
predictor = HuggingFaceModel(
env=hub, # configuration for loading model from Hub
role=role, # iam role with permissions to create an Endpoint
transformers_version='4.26',
pytorch_version='1.13',
py_version='py39',
).deploy(
initial_instance_count=1,
instance_type="ml.m5.xlarge",
endpoint_name="rdspg-vector"
)
print(f"Hugging Face Model has been deployed successfully to SageMaker")
- 调用 SageMaker 实时推理节点生成 Embeddings,结果将显示给定输入文本的 384 维向量的维度。
def cls_pooling(model_output):
# first element of model_output contains all token embeddings
return [sublist[0] for sublist in model_output][0]
data = {
"inputs": ' '.join(results[0].get('descriptions'))
}
res = cls_pooling( predictor.predict(data=data) )
print(len(res))
- 使用 SageMaker 推理,为我们的产品目录描述生成 384 维的向量化表示数据(embedding)。
def generate_embeddings(data):
r = {}
r['url'] = data['url']
r['descriptions'] = data['descriptions']
r['split'] = data['split']
inp = {'inputs' : ' '.join( data['descriptions'] ) }
vector = cls_pooling( predictor.predict(inp) )
r['descriptions_embeddings'] = vector
return r
workers = 1 * cpu_count()
chunksize = 32
# generate embeddings
data = process_map(generate_embeddings, results, max_workers=workers, chunksize=chunksize)
PostgreSQL 与 pgvetor 插件的存储与检索
- 连接到 RDS for PostgreSQL,使用向量数据类型创建产品表并提取数据。然后,为相似度搜索创建索引,以查找最近的 L2 距离邻域向量对象。
import psycopg2
from pgvector.psycopg2 import register_vector
import boto3
import json
client = boto3.client('secretsmanager')
response = client.get_secret_value( SecretId='rdspg-vector-secret')
database_secrets = json.loads(response['SecretString'])
dbhost = database_secrets['host']
dbport = database_secrets['port']
dbuser = database_secrets['username']
dbpass = database_secrets['password']
dbconn = psycopg2.connect(host=dbhost, user=dbuser, password=dbpass, port=dbport, connect_timeout=10)
dbconn.set_session(autocommit=True)
cur = dbconn.cursor()
cur.execute("CREATE EXTENSION IF NOT EXISTS vector;")
register_vector(dbconn)
cur.execute("DROP TABLE IF EXISTS products;")
cur.execute("""CREATE TABLE IF NOT EXISTS products(
id bigserial primary key,
description text,
url text,
split int,
descriptions_embeddings vector(384)
);""")
for x in data:
cur.execute("""INSERT INTO products (description, url, split, descriptions_embeddings)
VALUES (%s, %s, %s, %s);""",
(' '.join(x.get('descriptions', [])), x.get('url'), x.get('split'), x.get('descriptions_embeddings') ))
cur.execute("""CREATE INDEX ON products
USING ivfflat (descriptions_embeddings vector_l2_ops) WITH (lists = 100);""")
cur.execute("VACUUM ANALYZE products;")
cur.close()
dbconn.close()
print ("Vector embeddings has been successfully loaded into PostgreSQL")
- 使用 pgvector 插件,在 RDS for PostgreSQL 执行产品图片的最相似图片搜索。
import numpy as np
from skimage import io
import matplotlib.pyplot as plt
import requests
data = {"inputs": "green sleeveless summer wear"}
res1 = cls_pooling(predictor.predict(data=data))
client = boto3.client('secretsmanager')
response = client.get_secret_value( SecretId='rdspg-vector-secret' )
database_secrets = json.loads(response['SecretString'])
dbhost = database_secrets['host']
dbport = database_secrets['port']
dbuser = database_secrets['username']
dbpass = database_secrets['password']
dbconn = psycopg2.connect(host=dbhost, user=dbuser, password=dbpass, port=dbport, connect_timeout=10)
dbconn.set_session(autocommit=True)
cur = dbconn.cursor()
cur.execute("""SELECT id, url, description, descriptions_embeddings
FROM products
ORDER BY descriptions_embeddings <-> %s limit 3;""",
(np.array(res1),))
r = cur.fetchall()
urls = []
plt.rcParams["figure.figsize"] = [7.50, 3.50]
plt.rcParams["figure.autolayout"] = True
for x in r:
url = x[1].split('?')[0]
urldata = requests.get(url).content
print("Product Item Id: " + str(x[0]))
a = io.imread(url)
plt.imshow(a)
plt.axis('off')
plt.show()
cur.close()
dbconn.close()
大家可以修改查询用的描述文本,或 Limit 参数,尝试不同图片结果和输出图片的数量。本文的查询文本:“green sleeveless summer wear”,Limit 参数 3,返回产品 ID(Product Item Id)分别为:2328、5117、479。

现在,向量相似度搜索功能已为您返回最接近的匹配结果。
方案资源清理
- 在 Jupyter notebook 单元中运行以下代码以删除模型和节点。
predictor.delete_model() predictor.delete_endpoint()
- 在 CloudFormation stack 中,清理本 Demo 中创建的 Stack,清理剩余的资源。
结论
将 Amazon SageMaker,Amazon RDS for PostgreSQL 与 pgvector 开源扩展集成,配合小型语言模型(MiniLM),可以提供基于 Vector Embedding 的高精度 AI 图片智能数据检索。可以应用于电商产品目录的相似度搜索,优化查询体验。通过使用机器学习模型和 Vector Embedding,企业可以提高相似度搜索、个性化推荐和欺诈检测的准确性和速度,最终提高用户满意度和更个性化的体验。
Pgvector 的使用为大型多模态数据集(图片、文本)的查询提供了可扩展性,并且能够无缝集成 PostgreSQL 的存储功能。Amazon SageMaker 和 pgvector 的组合可在动态和数据驱动世界中取得更好的应用效果。
随着工作负载的持续发展,PostgreSQL 在向量数据库方向的可扩展性,使开发人员能够在垂直行业构建新的数据类型和索引机制。随着 AI/ML 创新的不断涌现,您未来可以在查询终端集成 LLM(大语言模型),进一步形成用户友好的智能查询 ChatBot,构建新的企业级智能化应用程序。
附录
1、有关本文中使用的代码示例的更多信息,请参阅 GitHub repo。
2、本文是在亚马逊云科技原有的英文 Blog 的基础上,进行更新和调整。原文作者为 Krishna Sarabu,原文链接:https://aws.amazon.com/cn/blogs/database/building-ai-powered-search-in-postgresql-using-amazon-sagemaker-and-pgvector/?trk=cndc-detail。
参考资料
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2?trk=cndc-detail
https://docs.aws.amazon.com/zh_cn/AmazonRDS/latest/UserGuide/USER_ConnectToPostgreSQLInstance.html?trk=cndc-detail
https://aws.amazon.com/cn/about-aws/whats-new/2023/05/amazon-rds-postgresql-pgvector-ml-model-integration/?trk=cndc-detail
文章来源:
https://dev.amazoncloud.cn/column/article/65489514de82943ae0ac4297?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN