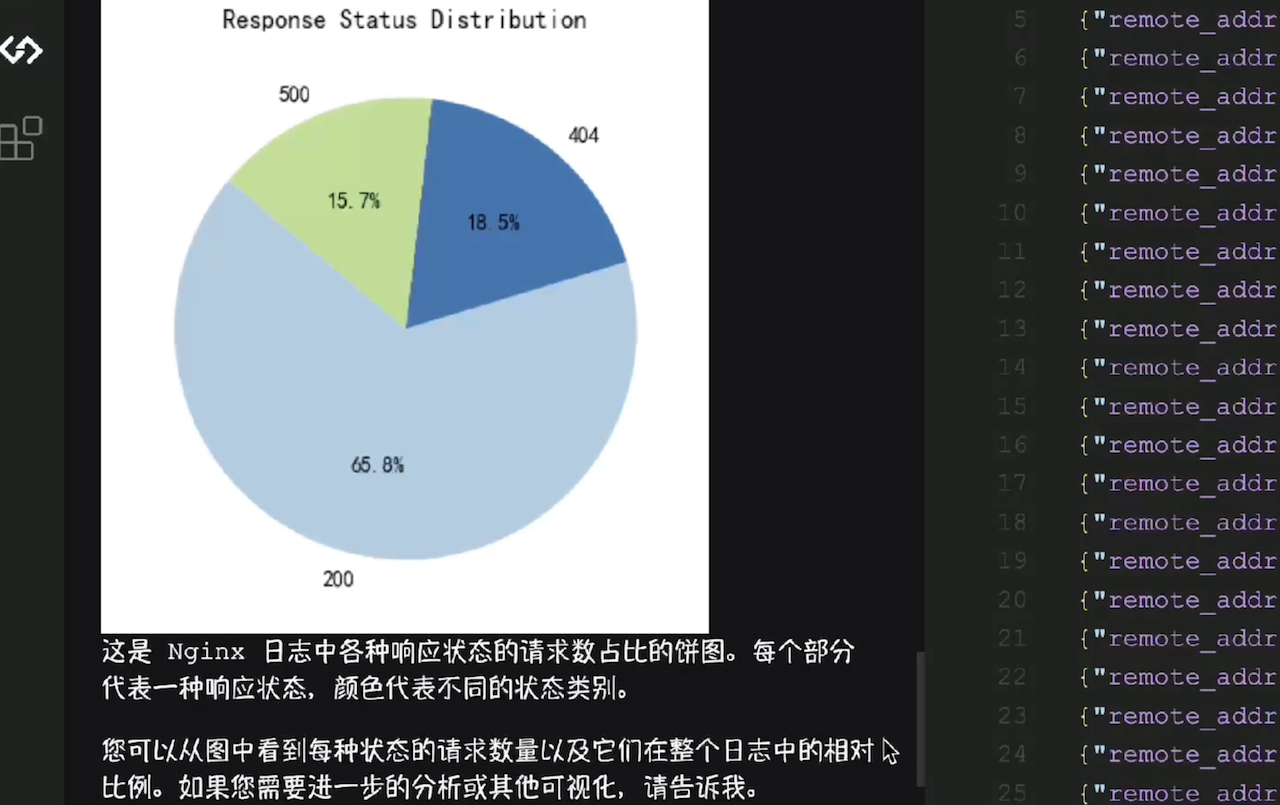
本期目录
- 1. 导入核心库
- 2. 初始化分布式进程组
- 3. 包装模型
- 4. 分发输入数据
- 5. 保存模型参数
- 6. 运行分布式训练
- 7. DDP完整训练代码
- 本章的重点是学习如何使用 PyTorch 中的 Distributed Data Parallel (DDP) 库进行高效的分布式并行训练。以提高模型的训练速度。
1. 导入核心库
-
DDP 多卡训练需要导入的库有:
库 作用 torch.multiprocessingas mp原生Python多进程库的封装器 from torch.utils.data.distributed import DistributedSampler上节所说的DistributedSampler,划分不同的输入数据到GPU from torch.nn.parallel import DistributedDataParallel as DDP主角,核心,DDP 模块 from torch.distributed import init_process_group, destroy_process_group两个函数,前一个初始化分布式进程组,后一个销毁分布式进程组
2. 初始化分布式进程组
-
Distributed Process Group 分布式进程组。它包含在所有 GPUs 上的所有的进程。因为 DDP 是基于多进程 (multi-process) 进行并行计算,每个 GPU 对应一个进程,所以必须先创建并定义进程组,以便进程之间可以互相发现并相互通信。
-
首先来写一个函数
ddp_setup():import torch import os from torch.utils.data import Dataset, DataLoader # 以下是分布式DDP需要导入的核心库 import torch.multiprocessing as mp from torch.utils.data.distributed import DistributedSampler from torch.nn.parallel import DistributedDataParallel as DDP from torch.distributed import init_process_group, destroy_process_group # 初始化DDP的进程组 def ddp_setup(rank, world_size): os.environ["MASTER_ADDR"] = "localhost" os.environ["MASTER_PORT"] = "12355" init_process_group(backend="nccl", rank=rank, world_size=world_size) -
其包含两个入参:
入参 含义 rank 进程组中每个进程的唯一 ID,范围是[0, world_size-1]world_size 一个进程组中的进程总数 -
在函数中,我们首先来设置环境变量:
环境变量 含义 MASTER_ADDR 在rank 0进程上运行的主机的IP地址。单机训练直接写 “localhost” 即可 MASTER_PORT 主机的空闲端口,不与系统端口冲突即可 之所以称其为主机,是因为它负责协调所有进程之间的通信。
-
最后,我们调用
init_process_group()函数来初始化默认分布式进程组。其包含的入参如下:入参 含义 backend 后端,通常是 nccl ,NCCL 是Nvidia Collective Communications Library,即英伟达集体通信库,用于 CUDA GPUs 之间的分布式通信 rank 进程组中每个进程的唯一ID,范围是[0, world_size-1]world_size 一个进程组中的进程总数 -
这样,进程组的初始化函数就准备好了。
【注意】
- 如果你的神经网络模型中包含
BatchNorm层,则需要将其修改为SyncBatchNorm层,以便在多个模型副本中同步BatchNorm层的运行状态。(你可以调用torch.nn.SyncBatchNorm.convert_sync_batchnorm(model: torch.nn.Module)函数来一键把神经网络中的所有BatchNorm层转换成SyncBatchNorm层。)
3. 包装模型
-
训练器的写法有一处需要注意,在开始使用模型之前,我们需要使用 DDP 去包装我们的模型:
self.model = DDP(self.model, device_ids=[gpu_id]) -
入参除了
model以外,还需要传入device_ids: List[int] or torch.device,它通常是由 model 所在的主机的 GPU ID 所组成的列表,
4. 分发输入数据
-
DistributedSampler在所有分布式进程中对输入数据进行分块,确保输入数据不会出现重叠样本。 -
每个进程将接收到指定
batch_size大小的输入数据。例如,当你指定了batch_size为 32 时,且你有 4 张 GPU ,那么有效的 batch size 为:
32 × 4 = 128 32 \times 4 = 128 32×4=128train_loader = torch.utils.data.DataLoader( dataset=train_set, batch_size=32, shuffle=False, # 必须关闭洗牌 sampler=DistributedSampler(train_set) # 指定分布式采样器 ) -
然后,在每轮 epoch 的一开始就调用
DistributedSampler的set_epoch(epoch: int)方法,这样可以在多个 epochs 中正常启用 shuffle 机制,从而避免每个 epoch 中都使用相同的样本顺序。def _run_epoch(self, epoch: int): b_sz = len(next(iter(self.train_loader))[0]) self.train_loader.sampler.set_epoch(epoch) # 调用 for x, y in self.train_loader: ... self._run_batch(x, y)
5. 保存模型参数
-
由于我们前面已经使用
DDP(model)包装了模型,所以现在self.model指向的是 DDP 包装的对象而不是 model 模型对象本身。如果此时我们想读取模型底层的参数,则需要调用model.module。 -
由于所有 GPU 进程中的神经网络模型参数都是相同的,所以我们只需从其中一个 GPU 进程那儿保存模型参数即可。
ckp = self.model.module.state_dict() # 注意需要添加.module ... ... if self.gpu_id == 0 and epoch % self.save_step == 0: # 从gpu:0进程处保存1份模型参数 self._save_checkpoint(epoch)
6. 运行分布式训练
-
包含 2 个新的入参
rank(代替device) 和world_size。 -
当调用
mp.spawn时,rank参数会被自动分配。 -
world_size是整个训练过程中的进程数量。对 GPU 训练来说,指的是可使用的 GPU 数量,且每张 GPU 都只运行 1 个进程。def main(rank: int, world_size: int, total_epochs: int, save_step: int): ddp_setup(rank, world_size) # 初始化分布式进程组 train_set, model, optimizer = load_train_objs() train_loader = prepare_dataloader(train_set, batch_size=32) trainer = Trainer( model=model, train_loader=train_loader, optimizer=optimizer, gpu_id=rank, # 这里变了 save_step=save_step ) trainer.train(total_epochs) destroy_process_group() # 最后销毁进程组 if __name__ == "__main__": import sys total_epochs = int(sys.argv[1]) save_step = int(sys.argv[2]) world_size = torch.cuda.device_count() mp.spawn(main, args=(world_size, total_epochs, save_step), nprocs=world_size) -
这里调用了
torch.multiprocessing的spawn()函数。该函数的主要作用是在多个进程中执行指定的函数,每个进程都在一个独立的 Python 解释器中运行。这样可以避免由于 Python 全局解释器锁 (GIL) 的存在而限制多线程并发性能的问题。在分布式训练中,通常每个 GPU 或计算节点都会运行一个独立的进程,通过进程之间的通信实现模型参数的同步和梯度聚合。 -
可以看到调用
spawn()函数时,传递args参数时并没有传递rank,这是因为会自动分配,详见下方表格fn入参介绍。入参 含义 fn: function 每个进程中要执行的函数。该函数会以 fn(i, *args)的形式被调用,其中i是由系统自动分配的唯一进程 ID ,args是传递给该函数的参数元组args: tuple 要传递给函数 fn的参数nprocs: int 要启动的进程数量 join: bool 是否等待所有进程完成后再继续执行主进程 (默认值为 True) daemon: bool 是否将所有生成的子进程设置为守护进程 (默认为 False)
7. DDP完整训练代码
首先,创建了一个训练器 Trainer 类。
import torch
import os
from torch.utils.data import Dataset, DataLoader
# 以下是分布式DDP需要导入的核心库
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
# 初始化DDP的进程组
def ddp_setup(rank: int, world_size: int):
"""
Args:
rank: Unique identifier of each process.
world_size: Total number of processes.
"""
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
init_process_group(backend="nccl", rank=rank, world_size=world_size)
class Trainer:
def __init__(
self,
model: torch.nn.Module,
train_loader: DataLoader,
optimizer: torch.optim.Optimizer,
gpu_id: int,
save_step: int # 保存点(以epoch计)
) -> None:
self.gpu_id = gpu_id,
self.model = DDP(model, device_ids=[self.gpu_id]) # DDP包装模型
self.train_loader = train_loader,
self.optimizer = optimizer,
self.save_step = save_step
def _run_batch(self, x: torch.Tensor, y: torch.Tensor):
self.optimizer.zero_grad()
output = self.model(x)
loss = torch.nn.CrossEntropyLoss()(output, y)
loss.backward()
self.optimizer.step()
def _run_epoch(self, epoch: int):
b_sz = len(next(iter(self.train_loader))[0])
self.train_loader.sampler.set_epoch(epoch) # 调用set_epoch(epoch)洗牌
print(f'[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_loader)}')
for x, y in self.train_loader:
x = x.to(self.gpu_id)
y = y.to(self.gpu_id)
self._run_batch(x, y)
def _save_checkpoint(self, epoch: int):
ckp = self.model.module.state_dict()
torch.save(ckp, './checkpoint.pth')
print(f'Epoch {epoch} | Training checkpoint saved at ./checkpoint.pth')
def train(self, max_epochs: int):
for epoch in range(max_epochs):
self._run_epoch(epoch)
if self.gpu_id == 0 and epoch % self.save_step == 0:
self._save_checkpoint(epoch)
然后,构建自己的数据集、数据加载器、神经网络模型和优化器。
def load_train_objs():
train_set = MyTrainDataset(2048)
model = torch.nn.Linear(20, 1) # load your model
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
return train_set, model, optimizer
def prepare_dataloader(dataset: Dataset, batch_size: int):
return DataLoader(
dataset=dataset,
batch_size=batch_size,
shuffle=False, # 必须关闭
pin_memory=True,
sampler=DistributedSampler(dataset=train_set) # 指定DistributedSampler采样器
)
最后,定义主函数。
def main(rank: int, world_size: int, total_epochs: int, save_step: int):
ddp_setup(rank, world_size) # 初始化分布式进程组
train_set, model, optimizer = load_train_objs()
train_loader = prepare_dataloader(train_set, batch_size=32)
trainer = Trainer(
model=model,
train_loader=train_loader,
optimizer=optimizer,
gpu_id=rank, # 这里变了
save_step=save_step
)
trainer.train(total_epochs)
destroy_process_group() # 最后销毁进程组
if __name__ == "__main__":
import sys
total_epochs = int(sys.argv[1])
save_step = int(sys.argv[2])
world_size = torch.cuda.device_count()
mp.spawn(main, args=(world_size, total_epochs, save_step), nprocs=world_size)
至此,你就已经成功掌握了 DDP 分布式训练的核心用法了。