自去年底ChatGPT发布后,大模型技术呈井喷式发展态势,学术界和工业界几乎每天都在刷新各个方向的SOTA榜单。随着大模型技术的发展,人们逐渐意识到多模态将是大模型发展的必经之路。其中,图文多模态大模型是一种结合了图像和文本两种模态信息的深度学习模型,本文将重点回顾这一领域的关键进展。
纵观多模态大模型的技术演进,也完全遵循了预训练-微调的整体方案。根据预训练模型中图文模态的交互方式,主要分为以下两种:
双塔结构:代表架构是 CLIP。双塔即一个视觉 Encoder 建模图片信息,一个文本 Encoder 建模文本信息,图像和文本的特征向量可以预先计算和存储,模态交互是通过图像和文本特征向量的余弦相似度来处理。这类模型的优点是处理多模态检索任务,但无法处理复杂的分类任务;
单塔结构:代表架构是ViLT。单塔即一个视觉-文本 Encoder 同时建模图片信息和文本信息,使用 Transformer 模型对图像和文本特征进行交互。这类模型的优点是可以充分地将多模态的信息融合,更擅长做多模态分类任务,检索任务较慢。
CLIP
CLIP由 OpenAI 构建,作为多模态领域的经典之作,被广泛应用于当今多模态模型的基础模型。CLIP通过自监督的方式,使用 4亿对(图像,文本)数据进行训练,它将图像和文本映射到一个共享的向量空间中,从而使得模型能够理解图像和文本之间的语义关系,这是一种从自然语言监督中学习视觉模型的新方法。
CLIP模型主要由两部分组成:Text Encoder 和 Image Encoder。这两部分可以分别理解成文本和图像的特征编码器。CLIP的预训练过程如下所示:
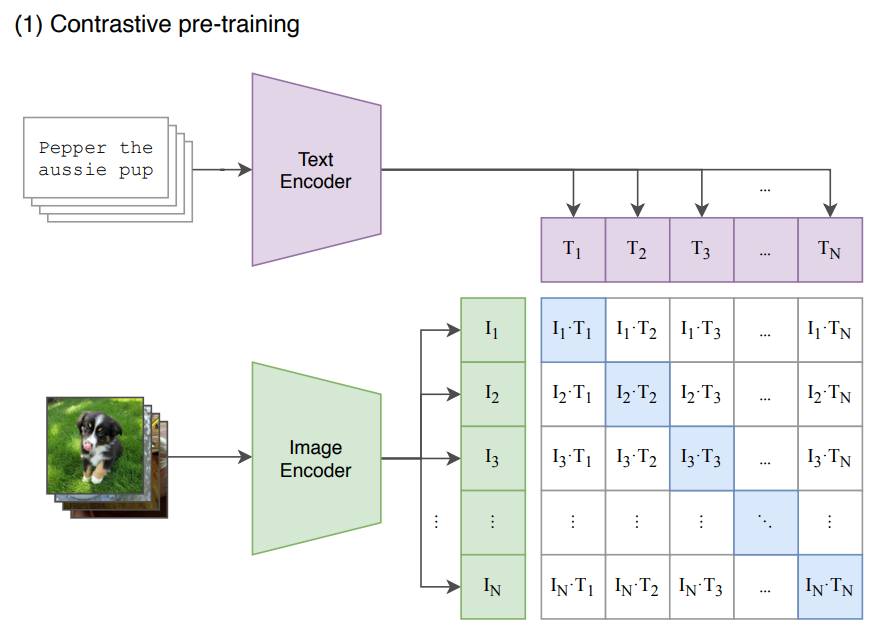
给定一个Batch的N个(图片,文本)对,图片输入给Image Encoder得到表征 , , ..., ,文本输入给 Text Encoder 得到表征 , , ..., ,(, ) 属于是正样本, (, ) 属于负样本。最大化 N 个正样本的 Cosine 相似度,最小化 N2 -N 个负样本的 Cosine 相似度。
CLIP是从头训练它的 Text Encoder(GPT-2) 和 Image Encoder (ViT),同时使用线性投影 (权重为, ) 将每个编码器的表征映射到多模态的嵌入空间。
ViLT
ViLT 受到 ViT 中 patch projection 技术的启发,希望最小化每个模态的特征提取,因此使用预训练的ViT来初始化交互的 Transformer,这样直接利用交互层来处理视觉特征,无需额外新增视觉 Encoder,把主要的计算量都集中在了 Transformer 的特征融合部分。
下图是ViLT的模型架构:
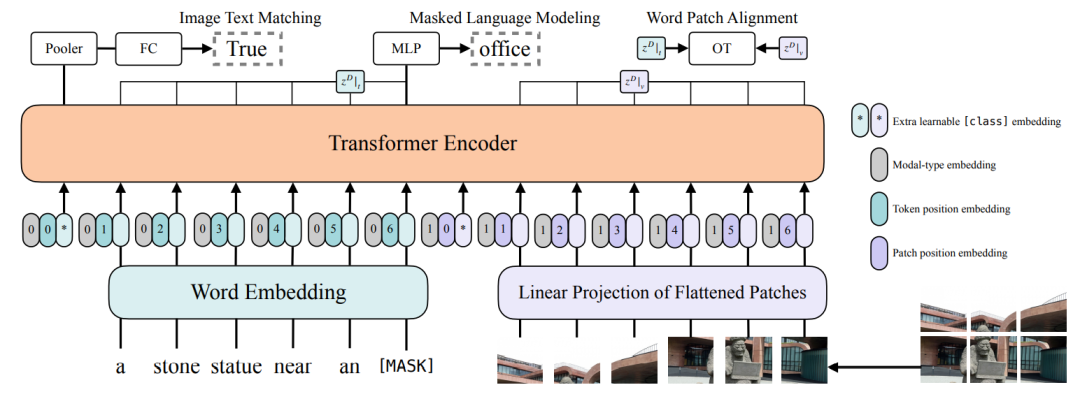
文本输入通过Word Embedding 矩阵 Embedding化,然后和 Position Embedding 相加,最后和 Modal-type Embedding Concate;
图像输入通过分块操作分成 C x P x P 大小的 N 个 Patch,通过线性投影矩阵Embedding化,然后和 Position Embedding 相加,最后和 Modal-type Embedding Concate;
文本和图像的 Embedding进行拼接,喂入 Transformer 模型。
ViLT 的预训练过程主要有两个优化目标:Image Text Matching (ITM) 和 Masked Language Modeling (MLM)。
Image Text Matching 就是随机以0.5的概率将对齐的图片替换为不同的图片,然后对文本标志位对应输出使用一个线性层将输出特征映射成一个二值logits。用来判断文本和图片是否匹配。
Masked Language Modeling 也就是 BERT 中的完形填空任务,随机以 0.15 的概率mask 掉 tokens,然后使用一个两层 MLP 得到输出。通过文本的上下文信息去预测mask掉的文本tokens。
VLMo
鉴于以上两类模型的优缺点,VLMo提出了一种统一的视觉语言模型——混合专家 Transformer 模型 (Mixture-of-Modality-Experts, MoME)。VLMo预训练完成后,使用时既可以是双塔结构,高效地对图像和文本进行检索;又可以是单塔结构,对融合的图像和文本的特征进行交互。
VLMo的架构如下所示:
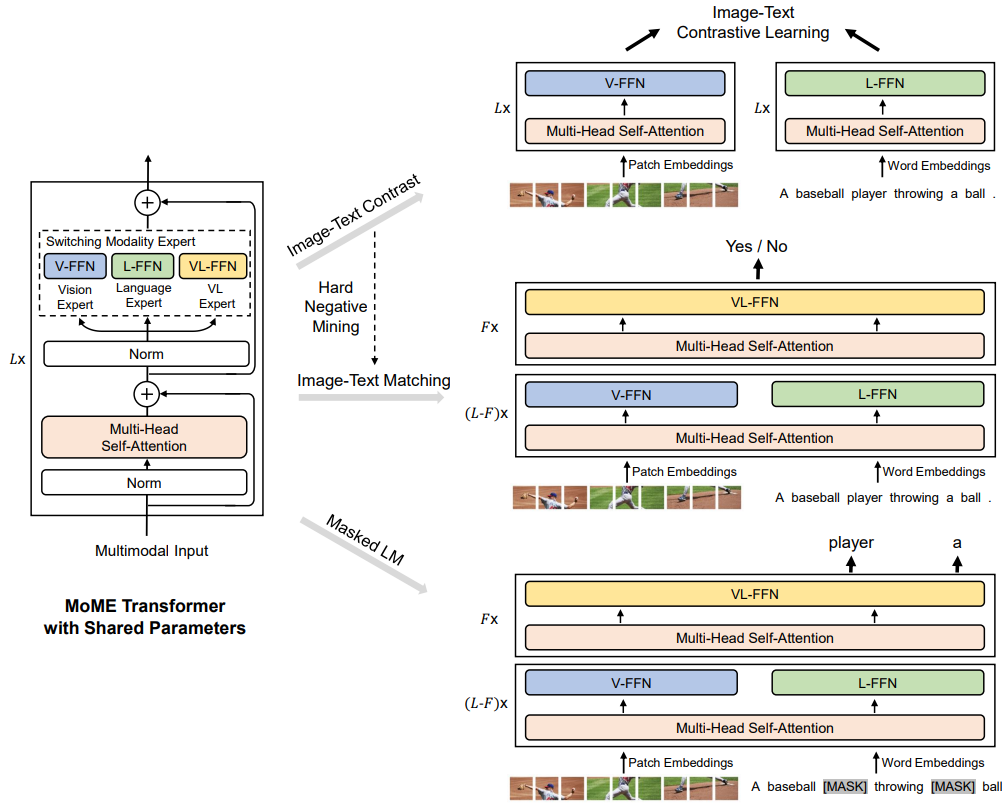
VLMo模型的输入表征与ViLT一致,之后是一个 Multi-Head Self-Attention 的子模块,再串联一个 FFN 的子模块。但是和正常 Transformer 不同的是,这个 FFN 子模块是由3个并行,独立的 FFN 并联得到的。这3个 FFN 分别是 Vision-FFN,Language-FFN 和 Vision-Language-FFN。它们可以看成是3个专家模型,所有的Multi-Head Self-Attention 共享权重参数。
预训练
预训练过程采用分阶段进行,其策略为:先使用易获得的海量数据进行训练,使模型优化到一个比较好的参数值后,再在比较难获得的数据上进行微调,从而使得模型在样本数较少的数据上也能获得不错的泛化能力。整个过程如下所示:
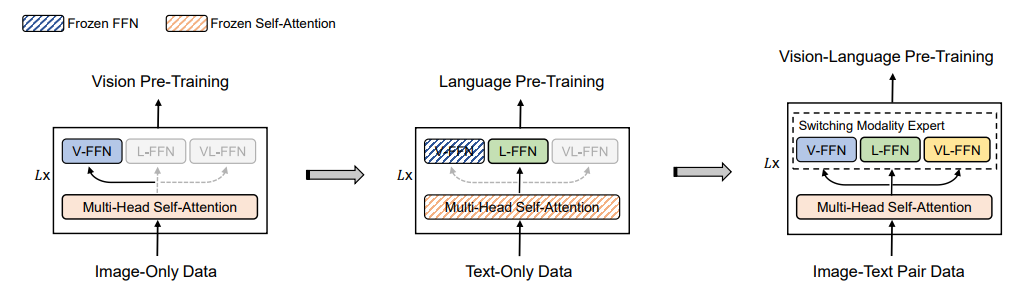
图4 VLMo预训练过程
第一阶段冻结语言专家和视觉-语言专家的参数,通过MIM预训练任务在纯图像数据上练视觉专家,同事更新共享的 Self-Attention 参数;
第二阶段冻结共享的MSA参数以及视觉专家和视觉-语言专家的参数,通过MLM预训练任务在纯文本数据上训练语言专家;
第三阶段解冻所有参数,通过ITC、ITM、MLM三个预训练任务在图文数据集上训练所有的参数。
微调
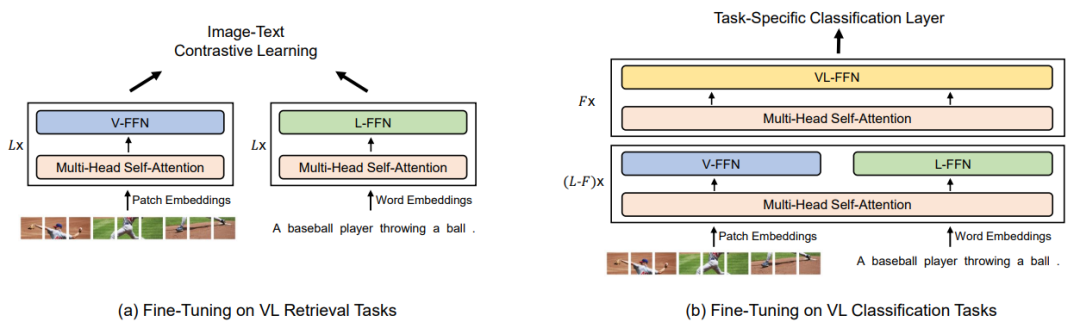
检索任务里面 VLMo 被用作上图 (a) 的格式,即双塔结构。在微调期间,使用图像-文本对比损失(ITC)来优化。在推理过程中,计算所有图像和文本的特征向量,然后通过矩阵乘法得到图文匹配的相似度矩阵。VLMo 的这个做法可以实现更快的推理速度。
分类任务主要包括:视觉问答 (Visual Question Answering, VQA) 和视觉推理 (Natural Language Visual Reasoning, NLVR) 等。这时候 VLMO 被用作图 (b) 的格式,即单塔结构。先通过视觉专家和文本专家建模各自特征,再联合送入多模态专家完成更复杂的交互,完成分类任务。
BLIP
BLIP 提出了一种编码器-解码器混合架构 (Multimodal mixture of Encoder-Decoder, MED),因此也是一种混合模型。MED 既可以作为单模态的编码器,又可以作为基于图像的文本编码器,或者基于图像的文本解码器。模型架构如下所示:
下图是BLIP的模型架构:

图6 BLIP模型架构
单模态编码器
第1列是图像编码器(ViT),将输入图像分割成 Patch 并编码为 Image Embedding,并带有额外的 [CLS] token 来表示全局的图像特征。
第2列是文本编码器(Bert),其中 [CLS] token 附加到文本输入的开头以概括句子。作用是提取文本特征做对比学习。
基于图像的文本编码器
第3列是视觉文本编码器,通过在文本编码器的每个 Transformer 块的自注意 (SA) 层和前馈网络 (FFN) 之间插入一个 Cross-Attention 层来注入视觉信息。作用是根据图片特征和文本输入做二分类,所以使用的是编码器,且注意力部分是双向的 Self-Attention。文本附加一个额外的 [Encode] token,作为图像文本的联合表征。
基于图像的文本解码器
第4列是视觉文本解码器,将基于图像的文本编码器中的双向自注意力层替换为Casual-Attention 层。作用是根据图片特征和文本输入做文本生成的任务,所以使用的是解码器,目标是预测下一个 token。在文本开头和结尾附加额外的 [Decode] token 和 [EOS] token。
BLIP 由三个视觉语言目标联合训练:
对比学习目标函数 ( ITC):ITC 作用于视觉编码器 和文本编码器,目标是对齐视觉和文本两个模态的的特征空间。
图文匹配目标函数 (ITM):ITM 作用于视觉编码器和视觉文本编码器,目标是学习图像文本的联合表征,以捕获视觉和语言之间的细粒度对齐。
语言模型目标函数 (M):LM 作用于视觉编码器和视觉文本编码器,目标是根据给定的图像以自回归方式来生成关于文本的描述。
BLIP-2
BLIP-2 提出了一种新的图文多模态预训练范式,该范式可以任意组合并充分利用两个预训练好的视觉编码器和 LLM,而无须端到端地预训练整个架构。这使得我们可以在多个视觉语言任务上实现最先进的结果,同时显著减少训练参数量和预训练成本。此范式为之后MMBench和MME榜单中的各种SOTA模型奠定了基础。
为了解决两类冻结预训练模型在视觉特征空间和文本特征空间的不对齐问题,BLIP-2 提出了一个轻量级的 Querying Transformer,该 Transformer 分两个阶段进行预训练,如下图所示。
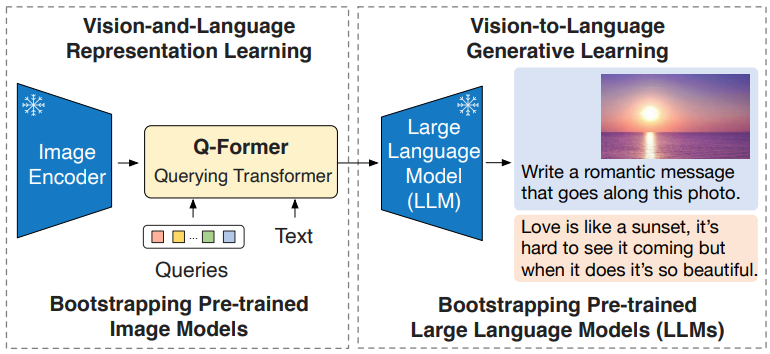
BLIP-2 由预训练好的,冻结参数的图像编码器(CLIP)和大语言模型(OPT、FlanT5),外加可训练的 Q-Former 构成。
固定的图像编码器从输入图片中提取视觉特征,Q-Former 架构是由2个 Transformer 子模块构成,其中 Self-Attention 的参数是共享的。
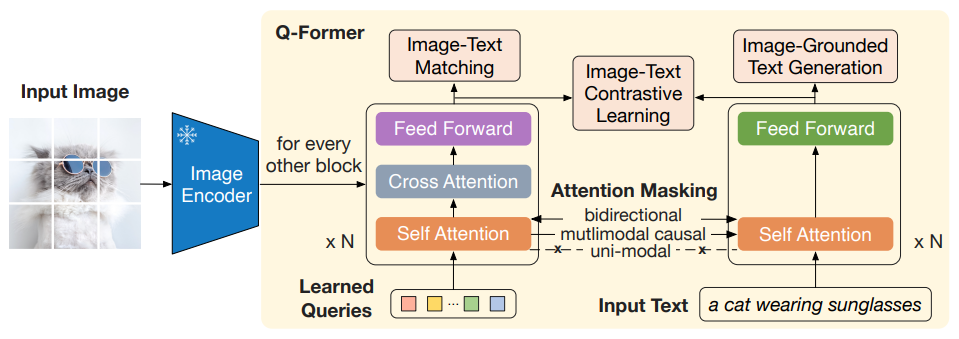
第1个 Transformer 子模块:是 Image Transformer,它与图像编码器交互,用于视觉特征提取。它的输入是可学习的 Queries,先通过 Self-Attention 建模互相之间的依赖关系,再通过 Cross-Attention 建模 Queries 和图片特征的依赖关系。因为两个 Transformer 的子模块是共享参数的,所以 Queries 也可以与文本输入做交互。
第2个 Transformer 子模块:是 Text Transformer,它既可以作为文本编码器,也可以充当文本解码器。
Q-Former的权重使用 BERT-Base 做初始化,Cross-Attention 的参数做随机初始化。Queries 随着预训练目标一起训练,促使它们提取到与文本最相关的视觉信息。
LLaVA
LLaVA的架构非常简单,其核心是构建高质量多模态数据集,利用GPT-4来生成训练数据。并验证在构建的数据集进行指令微调的有效性。
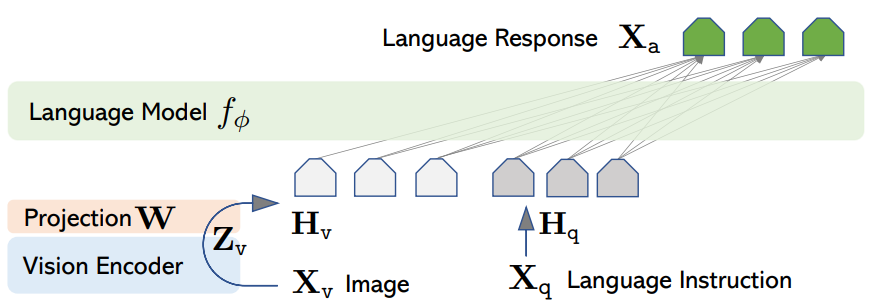
如上图所示,LLaVA 由三部分组成:视觉编码器(CLIP ViT-L/14)、大语言模型(Vicuna)、线性投影层(Hv = W · Zv,其中 Zv = g(Xv))。
在预训练阶段,冻结视觉编码器和大语言模型的权重参数,基于CC3M数据集的子集训练投影层(Linear Layer),此阶段目的是将i图片和文本特征对齐,使用相对简单、大量的单轮指令即可。
在精调阶段,冻结视觉编码器权重参数,精调投影层和大语言模型权重参数,此阶段目的是让大语言模型理解图片和文本,并具有多轮对话能力,是一个微调过程,需使用相对复杂、一定数量的多轮指令。
LLaVA的最大创新是构建高质量的多模式指示数据,其采用GPT-4/ChatGPT来生成数据集,这里并不是依赖GPT-4的多模态能力,而是只用GPT-4的文本理解和生成能力。模拟给GPT-4送入一张图像:用一个非常详尽的文本描述来替代图像输入。
下面的例子就是使用 Captions(从不同的维度描述图像内容)+ Boxes(用每个框定位图像中的物体,包括类别及空间位置)

这两方面的描述算是近似等价于图像。然后根据GPT-4产生3种类型的instruction-following data,分别是:
Conversation:构建视觉问答的多轮对话数据
Detailed description:根据图像生成详细的描述
Complex reasoning:前面的两种主要是和图像内容有关,这部分是构建复杂的推理问题,这里需要手工设计一些问题来让GPT-4来生成。
基于 COCO 数据集,与仅使用语言的 GPT-4 进行交互,总共收集了 158K 个独特的语言图像指令样本,其中对话数据58K、详细描述数据 23K 和复杂推理数据 77k。
总结
综上,图文多模态大模型的技术发展经历了多个重要阶段,现在基本形成了以大语言模型为核心,构建高质量数据集提升图文两模态融合的统一范式。多模态技术的发展,模态融合是关键,大量高质量数据将成为“胜负手”,谁能最先突破瓶颈,谁就能成为多模态大模型技术的领先者。多模态大模型已经成为深度学习领域的热点之一,其在图像和文本等多种模态信息的处理上具有广泛应用。随着不断的研究和发展,多模态大模型必将推动各领域的创新,为我们提供更多多样性的应用和解决方案。
参考
[1] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning. PMLR, 2021: 8748-8763.
[2] Kim W, Son B, Kim I. Vilt: Vision-and-language transformer without convolution or region supervision[C]//International Conference on Machine Learning. PMLR, 2021: 5583-5594.
[3] Bao H, Wang W, Dong L, et al. Vlmo: Unified vision-language pre-training with mixture-of-modality-experts[J]. Advances in Neural Information Processing Systems, 2022, 35: 32897-32912.
[4] Li J, Li D, Xiong C, et al. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation[C]//International Conference on Machine Learning. PMLR, 2022: 12888-12900.
[5] Li J, Li D, Savarese S, et al. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models[J]. arXiv preprint arXiv:2301.12597, 2023.
[6] Liu H, Li C, Wu Q, et al. Visual instruction tuning[J]. arXiv preprint arXiv:2304.08485, 2023.