Abstract.
现实世界中具有挑战性的照明条件(低光、曝光不足和曝光过度)不仅会产生令人不快的视觉外观,还会影响计算机视觉任务。现有的光自适应方法通常单独处理每种情况。更重要的是,它们中的大多数经常在 RAW 图像上运行或过度简化相机图像信号处理 (ISP) 管道。通过将光变换管道分解为局部和全局 ISP 组件,我们提出了一种轻量级快速照明自适应变换器(IAT),它包含两个变换器式分支:局部估计分支和全局 ISP 分支。虽然局部分支估计与照明相关的像素级局部分量,但全局分支定义了参与整个图像以解码参数的可学习要求。我们的 IAT 还可以在各种光照条件下进行对象检测和语义分割。我们在多个真实数据集上对 2 个低级任务和 3 个高级任务的 IAT 进行了广泛评估。仅 90k 个参数和 0.004s 的处理速度(不包括高级模块),我们的 IAT 始终取得优于 SOTA 的性能。代码可在 https://github.com/cuiziteng/IlluminationAdaptive-Transformer 获取。
1 Introduction
计算机视觉在拍摄精美的图像和视频方面取得了巨大成功。然而,现实世界中不断变化的光照条件对视觉外观和下游计算机视觉任务(例如语义分割和对象检测)提出了挑战。照明不足的图像(图 1)会受到光子计数有限和相机内噪声的影响。另一方面,室外场景经常暴露在强光下,例如直射阳光,由于传感器范围有限和相机图像管道的非线性,导致图像饱和。更糟糕的是,曝光不足和过度曝光可能同时存在,即阴影投射的空间变化照明可能使对比度达到 1000:1 或更高。
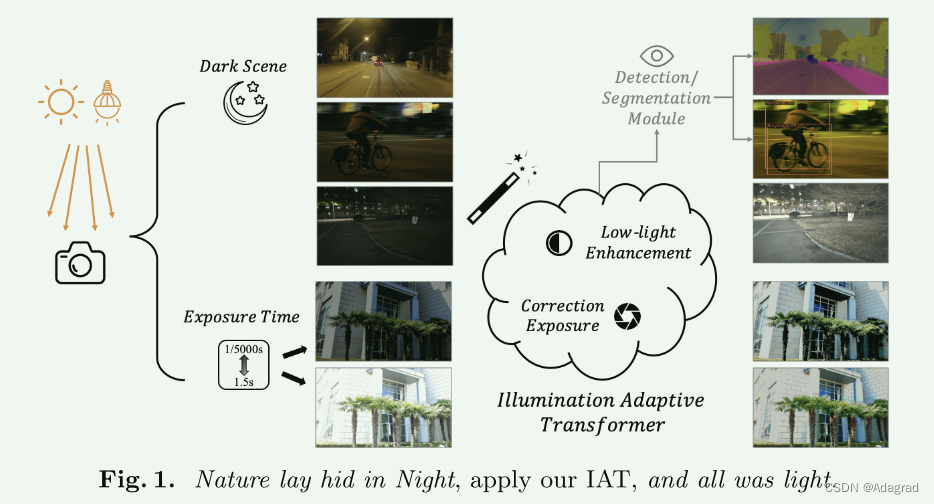
人们提出了多种技术,例如低光增强[37,59,25,47,52,48,24,73,35,62]、曝光校正[69,1]来适应困难的光照条件。低光增强方法可以恢复细节,同时抑制伴随的噪音。曝光校正侧重于调整曝光不足和曝光过度的情况,以在强烈的光照变化下重建清晰的图像。虽然上述算法侧重于改善以人为本的视觉感知,但也有几种方法将增强功能集成到高级任务中,例如对象检测,以提高针对弱光的鲁棒性[46,16,43,52]和过度曝光条件[49]。在本文中,我们的目标是提出一个统一的轻量级框架来解决现实世界中的这些低级和高级任务。
如图 1 所示,图 1 中的左侧 RGB 图像的照明不完美。然而,由于相机中的图像信号处理器(ISP)管道,这些图像的强度与实际场景辐照度不成线性比例。由于将这些图像转换为正常照明的 RGB 图像并不简单,现有方法要么直接对 RAW 图像进行操作 [9,3],要么通过伽玛校正 [48] 等过度简化 ISP 管道。
在这项工作中,我们分析了一个管道,该管道通过反向 ISP 将输入 RGB 图像传输到 RAW,然后将适应的正常光照 RAW 图像转换为目标 RGB。它表明该管道可以分解为像素级局部组件和全局 ISP 组件的组合。基于分析,我们提出了一种照明自适应变压器(IAT),如图1所示,它也由两个变压器式分支组成。两个分支都被设计为轻量级的,以估计生成适应的 RGB 图像的因素。局部分支估计与照明相关的逐像素局部分量,其中维持输入分辨率以保留信息细节。全局分支通过设计可学习查询来参与整个图像来估计全局 ISP 参数。此外,通过附加高级任务模块,我们可以联合优化 IAT,以在具有挑战性的光照条件下进行对象检测和语义分割。
在几个真实世界的数据集上进行了大量的实验,即用于低级任务的 LOL [65] 和 FiveK [6],以及用于高级任务的 EXDark [46]、ACDC [56] 和 TYO-L [29] 。结果表明,我们的 IAT 可以在一系列任务中实现最先进的性能。更重要的是,我们的 IAT 仅包含 0.09M 模型参数,比当前的 SOTA 模型小 100 倍(例如 MAXIM[62] 的 14.14M)。此外,它在 LOL 基准 [65] 上的平均推理时间每张图像只需要 0.004 秒,而 SOTA 方法通常每张图像需要 1 秒。
我们的贡献可总结如下:
– 我们提出了一种快速轻量级框架,照明自适应变压器(IAT),来处理现实世界中具有挑战性的光照条件。
– 我们提出了一种新颖的 Transformer 式结构来估计全局 ISP 参数以融合 RGB 目标图像,其中利用可学习的查询来关注整个图像。
– 对 2 个低级任务和 3 个高级任务的多个真实数据集进行的广泛实验表明,IAT 比 SOTA 方法具有优越的性能。 IAT 轻量级且适合移动设备,模型参数仅为 0.09M,每张图像的处理时间为 0.004 秒。我们将在发布后发布源代码。
2 Related Works
2.1 Enhancement against Challenging Light Condition
Low-light Enhancement.
早期的低光图像增强解决方案使用基于 RetiNex 理论 [37] 的方法和基于直方图均衡化 [22,59] 的方法。由于 LLNet [47] 首先利用深度自动编码器结构,基于深度学习的方法 [48,73,72,35,24,74,51,64,62,20] 已广泛用于此任务并获得 SOTA 结果在基准增强数据集上[6,65]。
图像增强还与多光源估计相关,可以纠正不期望的光色偏。假设照明在图像上平滑变化,则可以估计空间变化的光源[19,37]。利用局部信息,[21,23]对局部特征进行聚类以对独立的光源进行分组。深度学习解决方案也受到了关注。例如,比安科等人[3] 直接在 RAW 数据上应用 CNN 来估计单照明和多重照明。
Exposure Correction.与低光增强类似,传统的曝光校正算法[38,8]也使用图像直方图来调整图像强度。另一种策略是通过训练有素的深度学习模型调整色调曲线来纠正曝光错误[68,53]。最近,阿菲菲等人[1]提出了一种从粗到细的神经网络来校正照片的曝光。
High-level Task.现有的高级视觉框架 [7,54,12,45] 在大规模正常光数据集(即 MS COCO [42]、ImageNet [17])上进行训练。面对具有挑战性的光照条件,直接将弱光/强光数据作为输入会出现亮度不一致的情况[66,43],从而降低性能。另一种解决方案是在进行检测 [54,7] 或分割 [12] 之前使用增强方法 [48,73,51] 对图像进行预处理。然而,由于目标不一致[52,16,44],大多数增强方法都是为了改善人类视觉感知而设计的,这可能不一定有利于高级任务。
为了解决这个问题,YOLO-in-the-dark [57] 构建了一个师生模型来弥补低光 RAW 和正常光 RGB 之间的差距,以进行低光 RAW 物体检测。 MAET [16]提出了一种低光数据合成方法,并使用自监督学习策略[71]来训练目标检测器进行低光目标检测。 DB-GAN [49]使用GAN进行图像归一化,然后联合训练GAN模型和物体检测器来处理强光环境下的物体检测。
2.2 Vision Transformers
自ViT[18]以来,基于Transformer的模型在许多计算机视觉任务中获得了优越的性能,包括图像分类[45]、目标检测[7]等。对于低级视觉任务,基于Transformer的模型在图像超分辨率[41]、图像恢复[70]、图像着色[36]、图像增强[74]和恶劣天气恢复等多项任务上取得了很大进展[10,63]。此外,基于MLP-Mixer [58,60]的方法[62]也显示了MLP模型在低级视觉任务上的潜力。然而,直接使用 Transformer 作为图像到图像的结构会带来太多的计算成本,使得很难在移动和边缘设备上构建 Transformer 模型。
3 Illumination Adaptive Transformer
3.1 Light Adaption Model
对于空间可变光Li下的RGB图像Ii,光适应模型将其映射到与真实照片匹配的目标RGB图像It(在光Lt下)。现有的方法往往遵循过于简化的模型,要么是线性的,要么只考虑伽玛校正[48]。然而,相机中的实际处理涉及更复杂的非线性操作,例如去马赛克、白平衡、色彩空间变换、伽马校正等。这称为图像信号处理器(ISP)管道,它对原始 RAW 图像进行线性变换。与场景辐照度、计算机视觉数据集和任务中使用的 RGB 图像成正比。现有的光照估计或增强方法[3,9]往往选择直接对RAW数据而不是RGB图像进行操作,从而不可避免地限制了应用范围。
布鲁克斯等人[5]表明可以定义可逆双射函数 f(·) 将 RAW 数据空间中的数据点映射到 RGB 空间。如图 2 右侧所示,像素 x 处颜色通道 c ∈ {r, g, b} 的输入 RGB 图像 Ii(x) 首先通过逆 ISP 映射到 RAW 空间 Ri(x)程序:

我们将方程1和D(·)的复杂非线性变换简化为乘数因子M(x)和加法A(x)的组合。人们广泛认为光 L 的空间分布是平滑变化的,相邻位置之间不会突然变化 [37,19]。由于像素级因子 M(x) 和 A(x) 取决于 Lt(x) 和 Li(x) 的局部信息以及 ISP 过程的全局配置,因此像素值 M(x) 和 A(x) 也应该整个空间平滑变化,在空间分布上留下很小的自由度。
3.2 Model Structure
给定光照条件 Li 下的输入 RGB 图像 Ii ∈ RH×W×3,其中 H×W 表示尺寸维度,3 表示通道维度 ({r, g, b})。如图2所示,我们提出了照明自适应变换器(IAT),在适当的均匀光Lt下将输入RGB图像Ii传输到目标RGB It ∈ RH×W×3。通过结合下游检测或分割模块[ 7,54,12],我们的IAT还可以在不同的照明环境下实现高级视觉任务。
根据上面的讨论,如图2所示的传输RGB图像Iio RGB图像It的复杂管道可以简化为方程5。非线性操作被分解为局部像素分量 M、A ∈ RH×W×3 和全局 ISP 分量 W ∈ R3×3、γ ∈ R1×1。因此,我们设计了两个 Transformer 风格的分支:局部分支和全局 ISP 分支,分别估计局部像素分量和全局 ISP 分量。
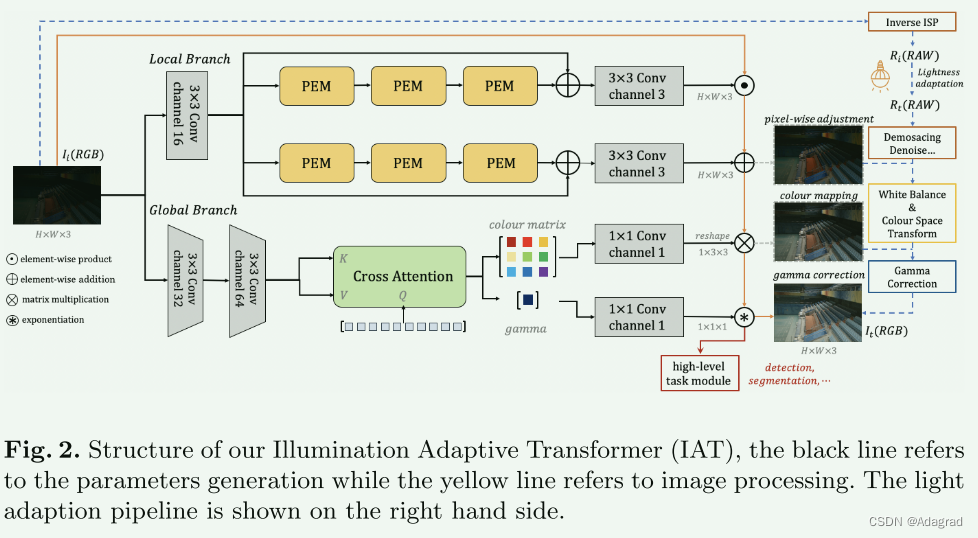

Local Branch.
在局部分支中,我们重点估计局部分量 M、A,以按照方程 5 校正光照的影响。我们没有采用 UNet [55] 风格的结构,即在上采样之前先对图像进行下采样,而是通过局部分支保持输入分辨率以保留信息细节。因此,我们为局部分支提出了一种新颖的变压器式架构。与流行的 U-Net [55] 风格结构相比,我们的结构还可以处理任意分辨率的图像,而无需调整它们的大小。
首先,我们通过 3×3 卷积扩展通道维度,并将它们传递给由逐像素增强模块(PEM)堆叠的两个独立分支。由于 M 和 A 应该在空间域上平滑变化,如第 3.1 节中讨论的那样,在我们的逐像素增强模块(PEM)中,我们按照之前的工作中的建议用深度卷积替换自注意力 [26,40,39 ]。如图3(a)所示,我们的PEM首先通过3×3深度卷积对位置信息进行编码,然后使用PWConvDWConv-PWConv增强局部细节。最后,我们采用两个 1×1 卷积分别增强 token 表示。特别地,我们设计了颜色归一化来代替图层归一化[2]。它通过两个可学习参数学习缩放 a 和偏置 b,并通过可学习矩阵融合通道,该矩阵最初是单位矩阵。此外,我们采用 Layer Scale [61] 来实现更好的收敛,它将特征乘以一个小数 k1/k2。
我们在每个分支中堆叠 3 个 PEM,然后通过逐元素加法将输出特征与输入特征连接起来。这种跳跃连接[27]有助于保持原始图像细节。最后,我们通过 3×3 卷积减少通道维度,并采用 ReLU/Tanh 函数生成式(5)中的局部分量 M/A。

Global ISP Branch.
在传输目标 RGB 图像 It 时,全局 ISP 分支占 ISP 管道 [28,32,34,5] 的一部分(即伽玛校正、颜色矩阵变换、白平衡)。具体地,目标图像中每个像素的值由方程5中定义的全局运算确定。
受检测变压器 DETR [7] 使用对象查询来解码位置和标签的启发,我们还设计了全局组件查询来解码和预测 W、γ,然后应用它来生成 RGB 图像。这种转换器结构允许捕获上下文和各个像素之间的全局交互。如图2所示,我们首先堆叠两个卷积作为轻量级编码器,以较低的分辨率对高维特征进行编码。然后这些特征被传递到全局预测模块(GPM),以进行有效的全局建模。如图3(b)所示,与DETR不同,我们的全局组件查询Q被初始化为零,没有额外的多头自注意力。 Q 是全局组件可学习嵌入,涉及从编码特征生成的键 K 和值 V。 K 和 V 的位置编码来自深度卷积,这对不同的输入分辨率很友好。在具有两个线性层 [18] 的 FFN 之后,我们添加两个具有特殊初始化的额外参数来输出颜色矩阵和伽玛。这样的初始化确保颜色矩阵是单位矩阵W并且伽玛值g在一开始就是1,从而有助于稳定的训练。
3.3 High-level Vision
如图4所示,通过将It传递给附加的下游任务模块,我们的IAT可以进行对象检测和语义分割。在 train3×3 1×1 5×5 1×1 Color Norm 1×1 GELU 1×1 Color Norm 3×3 FC LN FC GELU FC 训练过程中,我们的目标是最小化下游框架的损失函数(即目标检测损失 Lobj 之间通过联合优化整个网络的参数来预测 ˆt 和真实值 t)(见方程 7)。与后续的高级模块相比,我们的 IAT 主结构的时间复杂度和模型存储可以忽略不计(即 IAT 主结构与 YOLO-V3 [54],417KB vs 237MB)。
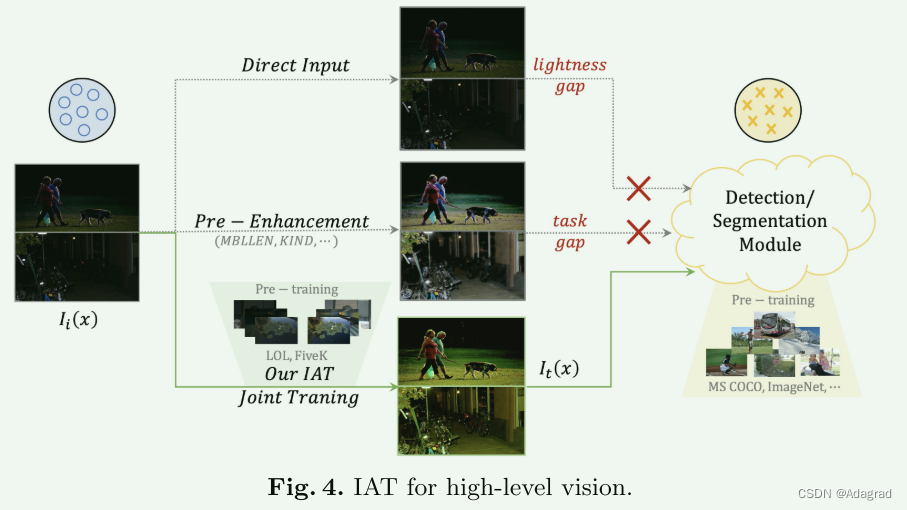

4 Experiments
我们在不同光照条件下的低级和高级视觉任务的基准数据集和实验设置上评估了我们提出的 IAT 模型。三个低级视觉任务包括:(a)图像增强(LOL [65]),(b)图像增强(MIT-Adobe FiveK [6]),(c)曝光校正[1]。三个高级视觉任务包括:(d)低光物体检测(e)低光语义分割(f)各种光物体检测。局部分支中生成M和A的PEM编号均设置为3,而PEM中的通道编号设置为16。
对于所有低级视觉实验:{(a)、(b)、(c)},IAT 模型在批量大小为 8 的单个 GeForce RTX 3090 GPU 上进行训练。我们使用 Adam 优化器来训练我们的 IAT 模型,同时使用 Adam 优化器来训练 IAT 模型。初始学习率和权重衰减分别设置为2e−4和1e−4。还采用了余弦学习计划来避免过度拟合。对于数据增强,水平和垂直翻转已被用来获得更好的结果。
4.1 Image Enhancement Results
对于 (a) 和 (b) 图像增强任务,我们在两个基准真实世界数据集上评估我们的 IAT 框架:LOL [65] 和 MIT-Adobe FiveK [6]。
LOL [65] 是一个小型数据集,由 789 个配对的正常光图像和低光图像组成。 689 张图像用于训练,另外 100 张图像用于测试。 LOL数据集训练的输入图像Ii和目标图像It之间的损失函数是混合损失函数[63],由smooth L1损失和VGG损失组成[33]。如方程式8所示,λ是权重参数,在我们的实验中设置为0.04。在训练和测试中,图像分辨率都保持在 600 × 400。我们将我们的方法与 SOTA 低光增强方法进行比较 [25,65,48,73,24,67,72,62,35]。对于图像质量分析,我们评估三个指标:峰值信噪比(PSNR)、结构相似性指数测量(SSIM)和NIQE [50]。为了分析计算复杂度,我们还报告了三个指标:FLOPs、模型参数和测试时间,如表 1 的最后一列所示。我们列出了不同模型在其相应代码平台上的测试时间(M表示Matlab,T表示TensorFlow,P表示PyTorch)。如表1所示,IAT(local)表示仅使用局部网络来训练模型,IAT表示使用整个框架。我们可以看到我们的 IAT 在图像质量和计算复杂度上都获得了 SOTA 结果。
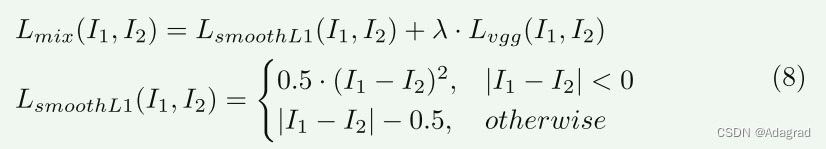
MIT-Adobe FiveK [6] 数据集包含 5000 张图像,每张图像均由五位不同的专家 (A/B/C/D/E) 手动增强。按照之前的设置[64,74,51],我们只使用专家C的调整图像作为地面实况图像。对于 MIT-Adobe FiveK [6] 数据集训练,我们使用单个 L1 损失函数来优化 IAT 模型。我们在 FiveK 数据集上将我们的方法与 SOTA 增强方法 [30,55,14,31,64,64,51,74] 进行比较,然后在表中报告图像质量结果(PSNR,SSIM)和模型参数。 2、IAT在质量和效率上也取得了令人满意的成绩。 LOL[65]和FiveK[6]的定性结果如图5所示,更多结果在补充中。
4.2 Exposure Correction Results
对于(c)曝光校正任务,我们在[1]提出的基准数据集上评估IAT。该数据集包含 24,330 张 8 位 sRGB 图像,分为 17,675 张训练图像、750 张验证图像和 5905 张测试图像。 [1] 中的图像由 MIT-Adobe FiveK [6] 数据集调整,具有 5 种不同的曝光值 (EV),范围从曝光不足到过度曝光条件。与[6]相同,测试集有5个不同专家的调整结果(A/B/C/D/E)。按照[1]的设置,训练图像被裁剪为 512 × 512 块,测试图像被调整为最大尺寸 512 像素。我们将测试图像与所有五位专家的结果进行比较。这里我们使用混合损失函数(方程8)进行曝光校正训练。
评价结果示于表3中,我们的比较方法包括传统图像处理方法(Histogram Equalization [22]、LIME [25])和深度学习方法(DPED [31]、DPE [14]、RetinexNet [65]、Deep-UPE [64],零 DCE [24]、MSEC [1])。评估指标与[1]相同,包括PSNR、SSIM和感知指数(PI)。图3显示我们的IAT模型在所有评估指标上都获得了最好的结果。此外,与第二佳结果 MSEC [1] 相比,IAT 的参数要少得多(0.09M 对 7M),评估时间也少得多(每幅图像 0.004 秒对每幅图像 0.5 秒)。定性结果如图5所示,更多结果在补充中。
4.3 Performance of High-level Vision
4.4 Ablation Analysis
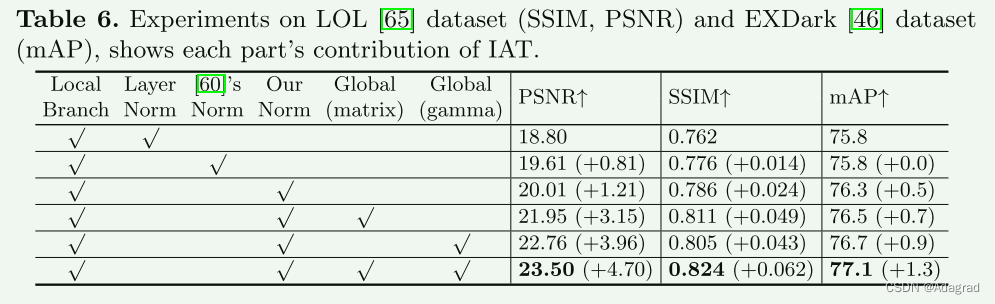
Contribution of each part.
为了评估 IAT 模型中每个部分的贡献,我们对 LOL [65] 数据集的低光增强任务和 EXDark [46] 数据集的低光目标检测任务进行了消融研究。我们报告了增强任务的 PSNR 和 SSIM 结果以及检测任务的 mAP 结果。我们将我们的归一化类型与 LayerNorm [2] 和 ResMLP 的归一化 [60] 进行比较,然后评估全局分支的不同部分的贡献(预测矩阵和预测伽玛值)。消融结果如表6所示。
Blocks & Channels Ablation.
为了评估 IAT 模型的可扩展性,我们在局部分支中尝试不同的块号和通道号。我们尝试不同的 PEM 数来生成 M 和 A。LOL [65]数据集上的 PSNR 结果如表 7 所示。它表明,保持相同的 PEM 编号来生成 M 和 A 将有助于 IAT 的性能。
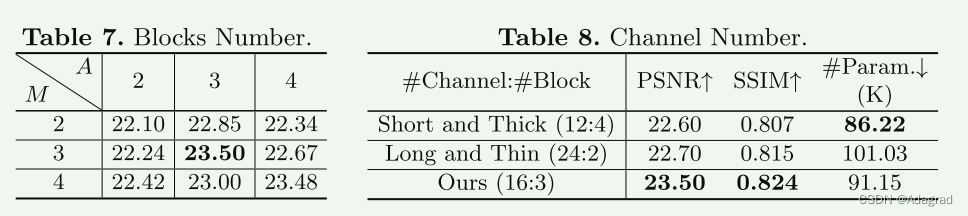
保持相同的块号来生成M和A,然后用相似的参数进行评估,以回答局部分支应该“短而粗”还是“长而细”。将局部分支的块号和通道号分别设置为2/24和4/12进行比较。 PSNR、SSIM 和模型参数的结果列于表8中。
5 Conclusion
明确考虑相机中的 ISP 管道,我们提出了一种新颖的 IAT 框架,用于应对具有挑战性的光照条件。尽管 IAT 在低级和高级任务的多个现实数据集上都具有卓越的性能,但它非常轻量级且速度很快。轻量级且适合移动设备的 IAT 有潜力成为计算机视觉社区的常备插件工具。