分布式数据库Schema 变更 in F1 & TiDB
【转载】TiDB 源码阅读系列文章(十七)DDL 源码解析 | PingCAP
上述文章主要叙述了从DDL语句发起到执行的过程,简单介绍了弄一套相同的模式来后台处理数据回填,从而提高DDL的并发度的一个方案。
Google F1
【转载】分布式 Schema 变更在 Google F1 的实践 - 知乎 (zhihu.com)
【转载】谷歌 F1 Online DDL的关键点:状态间兼容性 - 知乎 (zhihu.com)
TiDB
【转载】builddatabase/f1/schema-change-implement.md at master · ngaut/builddatabase (github.com)
新定义
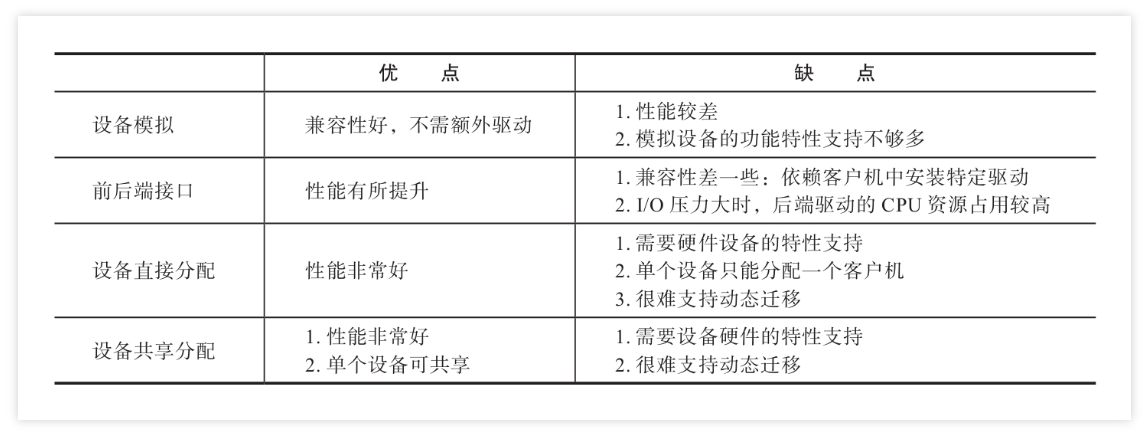
- 元数据记录:system database 和 system table 记录异步变更schema的元数据。
- State:根据F1,引入中间状态,none | delete-only | write-only | write reorganization | public(和F1基本一样),删除操作的状态与它的顺序相反,write reorganization 改为 delete reorganization,虽然都是 reorganization 状态,但是由于可见级别是有很大区别的,所以将其分为两种状态标记。
- Lease
- Job:每个单独的 DDL 操作可看做一个 job,放到job queue,等此操作完成时,会将此 job 从 job queue 删除,并在存入 history job queue,便于查看历史 job。
- Worker:每个节点都有一个 worker 用来处理 job。
- **Owner:**整个系统只有一个节点的 worker 能当选 owner 角色,每个节点都可能当选这个角色,当选 owner 后 worker 才有处理 job 的权利。owner 这个角色是有任期的,owner 的信息会存储在 KV 层中。worker定期获取 KV 层中的 owner 信息,如果其中 ownerID 为空,或者当前的 owner 超过了任期,则 worker 可以尝试更新 KV 层中的 owner 信息(设置 ownerID 为自身的 workerID),如果更新成功,则该 worker 成为 owner。在租期内这个用来确保整个系统同一时间只有一个节点在处理 schema 变更。
- Background operations:用于 delete reorganization 的优化处理,引入了 background job, background job queue, background job history queue, background worker 和 background owner,它们的功能跟上面提到的角色功能一一对应。
变更流程
介绍 TiDB SQL 层中处理异步 schema 变更的流程
MySQL client 发起change;
- Load schema:是在每个节点(这个模块跟之前提到的 worker 一样,便于理解可以这样认为)启动时创建的一个 gorountine, 用于在到达每个租期时间后去加载 schema,如果某个节点加载失败 TiDB Server 将会自动挂掉。此处加载失败包括加载超时。
- start job:是在 TiDB SQL 层接收到请求后,给 job 分配 ID 并将之存入 KV 层,之后等待 job 处理完成后返回给上层,汇报处理结果。
- worker:每个节点起一个处理 job 的 goroutine,它会定期检查是否有待处理的 job。 它在得到本节点上 start job 模块通知后,也会直接去检查是否有待执行的 job 。
- owner:可以认为是一个角色,信息存储在 KV 层,其中包括记录当前当选此角色的节点信息。
- job queue:是一个存放 job 的队列,存储在 KV 层,逻辑上整个系统只有一个。
- job history queue:是一个存放已经处理完成的 job 的队列,存储在 KV 层,逻辑上整个系统只有一个。
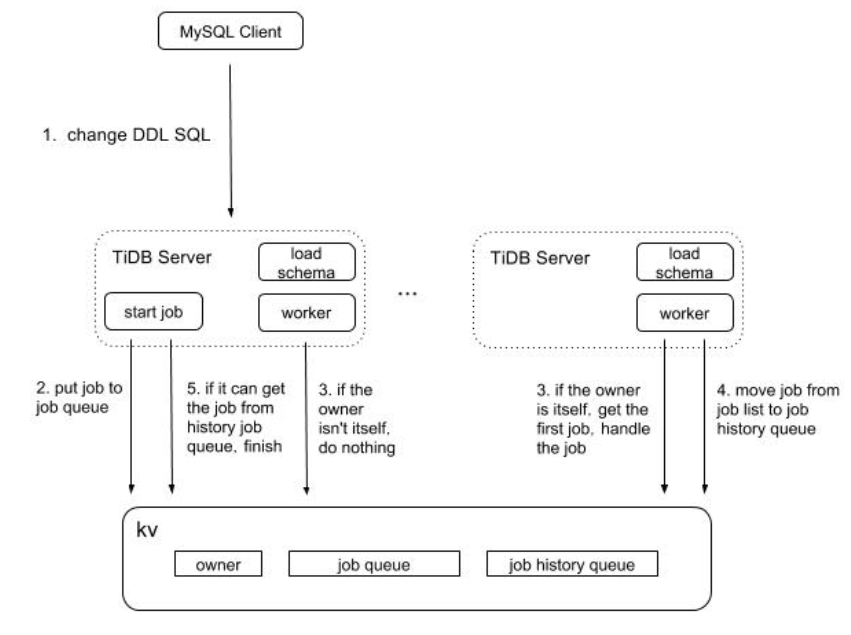
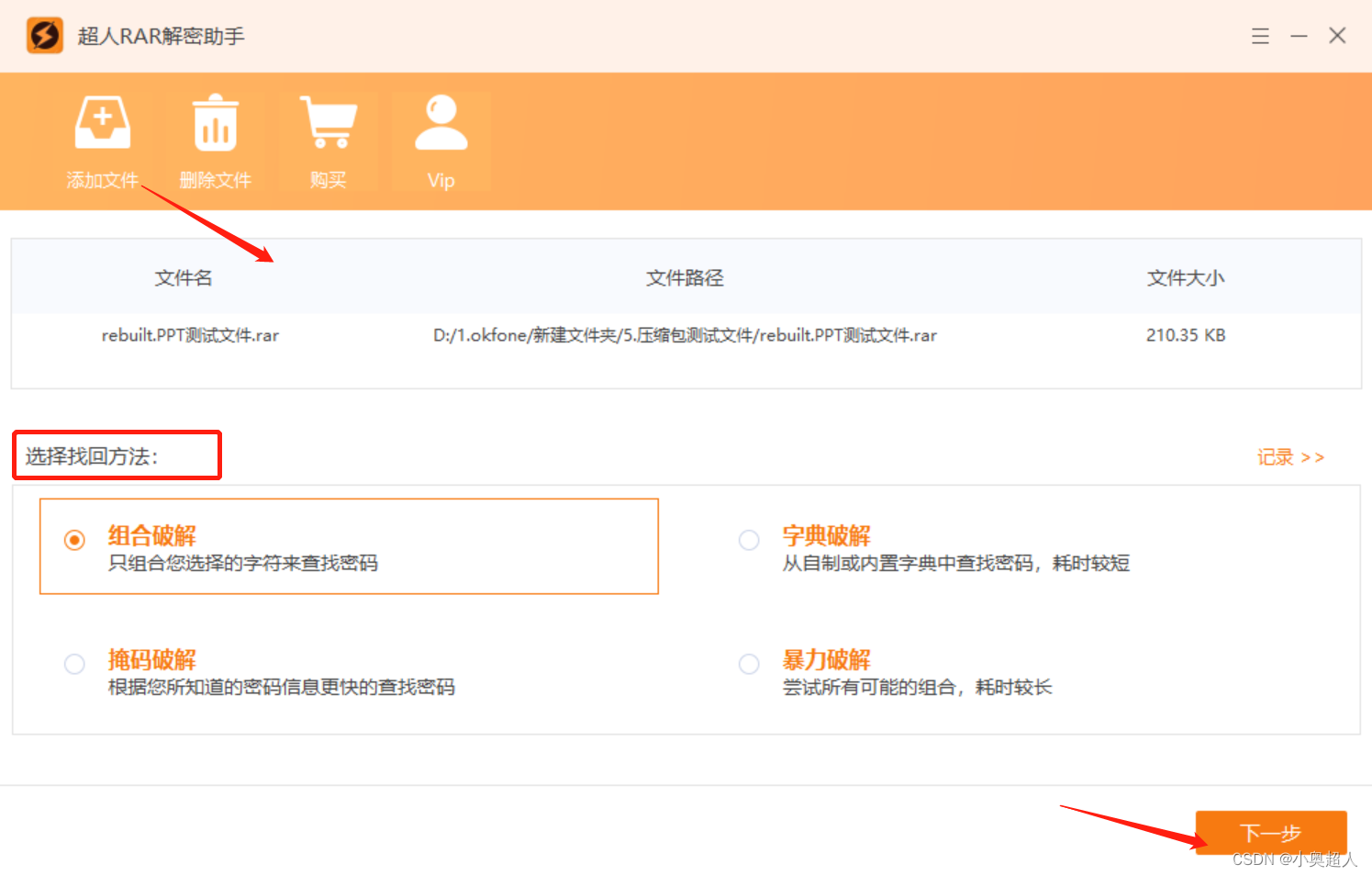
基本流程:
假设系统中只有两个节点,TiDB Server 1 和 TiDB Server 2。其中 TiDB Server 1 是 DDL 操作的接收节点, TiDB Server 2 是 owner。如下图 2 展示的是在 TiDB Server 1 中涉及的流程,图 3 展示的是在 TiDB Server 2 中涉及的流程。
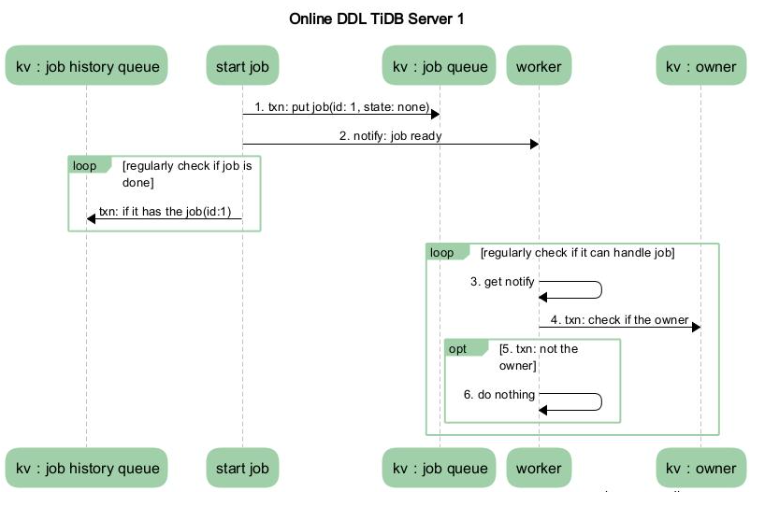
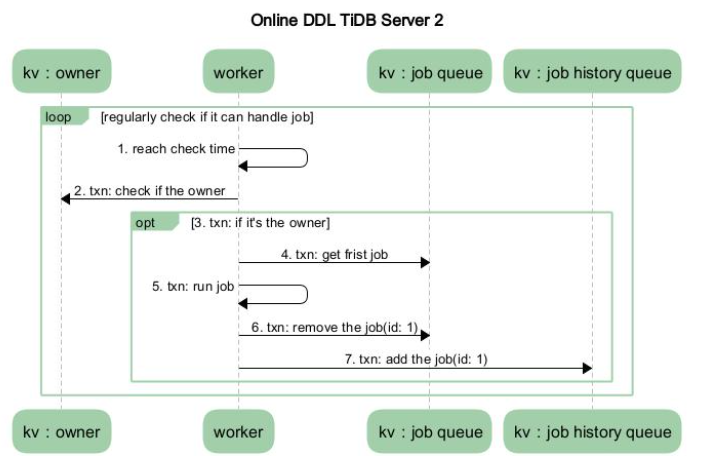
- MySQL Client 发送给 TiDB Server 一个更改 DDL 的 SQL 语句请求。
- 某个 TiDB Server 收到请求(MySQL Protocol 层收到请求进行解析优化),然后到达 TiDB SQL 层进行执行。这步骤主要是在 TiDB SQL 层接到请求后,会起个 start job 的模块根据请求将其封装成特定的 DDL job,然后将此 job 存储到 KV 层, 并通知自己的 worker 有 job 可以执行。
- 收到请求的 TiDB Server 的 worker 接收到处理 job 的通知后,判断自身是否处于 owner 的角色,如果处于 owner 角色则直接处理此 job,如果没有处于此角色则退出不做任何处理。图中我们假设没有处于此角色,那么其他的某个 TiDB Server 中肯定有一个处于此角色的,如果那个处于 owner 角色节点的 worker 通过定期检测机制来检查是否有 job 可以被执行时,发现了此 job,那么它就会处理这个 job。
- 当 worker 处理完 job 后, 它会将此 job 从 KV 层的 job queue 中移除,并放入 job history queue。
- 之前封装 job 的 start job 模块会定期去 job history queue 查看是否有之前放进去的 job 对应 ID 的 job,如果有则整个 DDL 操作结束。
- TiDB Server 将 response 返回 MySQL Client。
详细流程:以在 Table 中添加 column 为例详细介绍 worker 处理 job 的整个流程
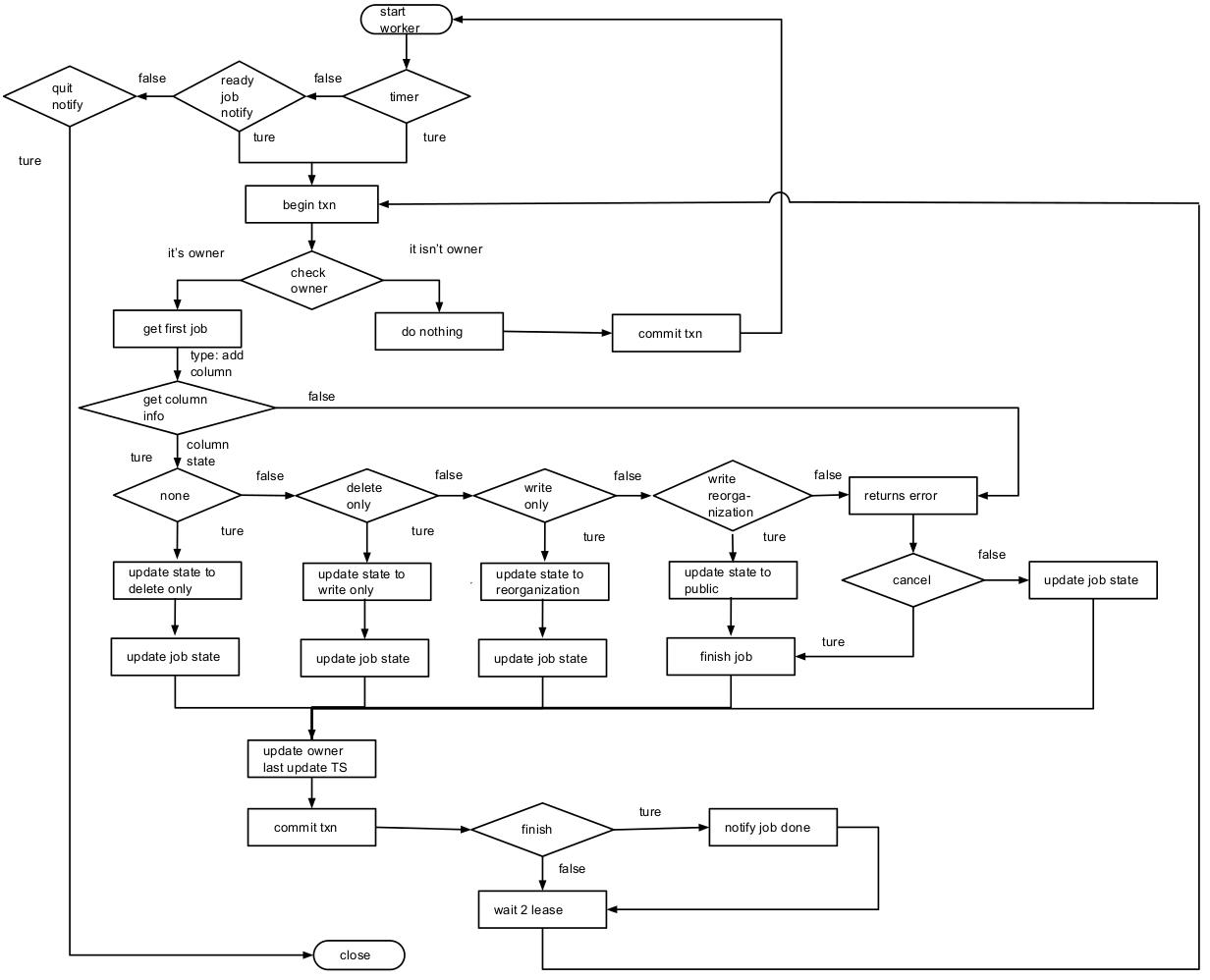
TiDB server1:
-
start job 给 start worker 传递了 job 已经准备完成的信号。
-
worker 开启一个事务,检查自己是否是 owner 角色,结果发现不是 owner 角色(此处跟先前的章节保持一致,假设此节点 worker 不是 owner 角色),则提交事务退出处理 job 的循环,回到 start worker 等待信号的循环。如果是owner,则是TiDB Server2的任务。
- start job 的定时检查触发后,会检查 job history queue 是否有之前自己放入 job queue 中的 job(通过 jobID)。如果有则此 DDL 操作在 TiDB SQL 完成,上抛到 MySQL Protocol 层,最后返回给 Client, 结束这个操作。
TiDB server2:
- start worker 中的定时器到达时间。
- 开启一个事务,检查发现本节点为 owner 角色。
- 从 KV 层获取队列中第一个 job(假设就是 TiDB Server 1 之前放入的 job),判断此 job 的类型并对它做相应的处理。
- 此处 job 的类型为 add column,然后流程到达图中 get column information 步骤。
- 取对应 table info(主要通过 job 中 schemaID 和 tableID 获取),然后确定添加的 column 在原先的表中不存在或者为不可见状态。
- 如果新添加的 column 在原先表中不存在,那么将新 column 信息关联到 table info。
- 在前面两个步骤中发生某些情况会将此 job 标记为 cancel 状态,并返回 error,到达图中 returns error 流程。比如发现对应的数据库、数据表的状态为不存在或者不可见(即它的状态不为 public),发现此 column 已存在并为可见状态等一些错误,这里就不全部列举了。
- schema 版本号加 1。
- 将 job 的 schema 状态和 table 中 column 状态标记为 delete only, 更新 table info 到 KV 层。
- 因为 job 状态没有 finish(即 done 或者 cancel 状态),所以直接将 job 在上一步更新的信息写入 KV 层。
- 在执行前面的操作时消耗了一定的时间,所以这里将更新 owner 的 last update timestamp 为当前时间(防止经常将 owner 角色在不同服务器中切换),并提交事务。
- 循环执行步骤 2、 3、 4.a、5、 6、 7 、8,不过将6中的状态由 delete only 改为 write only。
- 循环执行步骤 2、 3、 4.a、5、 6、 7 、8,不过将6中的状态由 write only 改为 write reorganization。
- 循环执行步骤 2、 3、 4.a、5,获取当前事务的快照版本,然后给新添加的列填写数据。通过应版本下需要得到的表的所有 handle(相当于 rowID),出于内存和性能的综合考量,此处处理为批量获取。然后针对每行新添加的列做数据填充,具体操作如下(下面的操作都会在一个事务中完成):
- 用先前取到的 handle 确定对应行存在,如果不存在则不对此行做任何操作。
- 如果存在,通过 handle 和 新添加的 columnID 拼成的 key 获取对应列。获取的值不为空则不对此行做任何操作。
- 如果值为空,则通过对应的新添加行的信息获取默认值,并存储到 KV 层。
- 将当前的 handle 信息存储到当前 job reorganization handle 字段,并存储到 KV 层。假如 12 这个步骤执行到一半,由于某些原因要重新执行 write reorganization 状态的操作,那么可以直接从这个 handle 开始操作。
- 将调整 table info 中 column 和 index column 中的位置,将 job 的 schema 和 table info 中新添加的 column 的状态设置为设置为public, 更新 table info 到 KV 层。最后将 job 的状态改为 done。
- 因为 job 状态已经 finish,将此 job 从 job queue 中移除并放入 job history queue 中。
- 执行步骤8,与之前的步骤一样 12, 13, 14 和 15 在一个事务中。
优化:
原本删除操作是:public → write only → delete only → delete reorganization → none,优化的处理是去掉 delete reorganization 状态,并把此状态需要处理的元数据的操作放到 delete only 状态时,把具体删除数据的操作放到后台处理,然后直接把状态标为 none。
好处:对删除数据库,删除数据表等减少一个状态,即 2 倍 lease 的等待时间。
实现:
在其处于 delete only 状态时,就会把元数据删除,而对起表中具体数据的删除则推迟到后台运行,然后结束 DDL job。
到后台运行的任务的流程跟之前处理任务的流程类似,详细过程如下:
- 在图 4 中判定 finish 操作为 true 后,判断如果是可以放在后台运行(暂时还只是删除数据库和表的任务),那么将其封装成 background job 放入 background job queue, 并通知本机后台的 worker 将其处理。
- 后台 job 也有对应的 owner,假设本机的 backgroundworker 就是 background owner 角色,那么他将从 background job queue 中取出第一个 background job, 然后执行对应类型的操作(删除表中具体的数据)。 如果执行完成,那么从 background job queue 中将此 job 删除,并放入 background job history queue 中。 注意步骤2和步骤 3需要在一个事务中执行。